记忆推理的放射源抓取机器人运动规划
2022-05-20南文虎徐付民叶伯生
南文虎,徐付民,叶伯生
1)兰州理工大学机电工程学院,甘肃兰州 730050;2)华中科技大学国家数控工程中心,湖北武汉 430074
目前在工业中进行矿石密度检测时,从铅罐内抓取放射源并进行分装的过程仍主要是人工和半自动抓取.人工抓取危险性大,而半自动抓取时,因铅罐是半封闭结构,远程遥控抓取效率较低.非辐射环境下的抓取是机器人研究领域的热点之一,余玉琴等[1-2]提出基于模型的抓取策略;何涛[3]提出基于半模型和无模型的抓取策略.但由于难以估算现实世界物体的形状,基于模型的方法很难应用到实际抓取环境中,深度学习算法则为无模型抓取策略提供了广泛前景.当前基于深度学习的机器人抓取策略主要有端对端策略[4]与采样评估策略[5]两类.周祺杰等[6]针对固体放射性废物分拣作业,使用Q网络算法来训练抓取.薛腾等[7]结合视觉与力觉信息构建数据集训练抓取.崔少伟等[8-9]提出基于触觉先验知识的机器人稳定抓取方法.FALLAHINIA等[10]利用指甲成像技术对多个手指进行无约束的抓取力测量,研究人类的抓取行为.张磊等[11]采用预抓取技术对机器人所在环境的地图信息进行预抓取,再使用自适应样本的蒙特卡罗定位方法对机器人进行定位.本研究以腕力传感器为力觉反馈装置实现机器人与环境的交互,针对目前抓取铅罐内放射源颗粒的工程背景,设计基于记忆推理决策的强化学习抓取方法,每次抓取前先比对以前的抓取情况再规划当前抓取路径,以免造成动作浪费,从而实现铅罐内放射源颗粒的高效的自主抓取.
1 机器人抓取系统运动学模型
1.1 铅罐定位系统设计
从相机坐标系转换到图像坐标系是将3维点转换到2维点.假设目标物体在相机坐标系的坐标矩阵PC=[XC,YC,ZC]T,在图像坐标系上的投影坐标矩阵PP=[u,v,1]T,根据相似三角形法,得到相机坐标系到图像坐标系的转换关系为
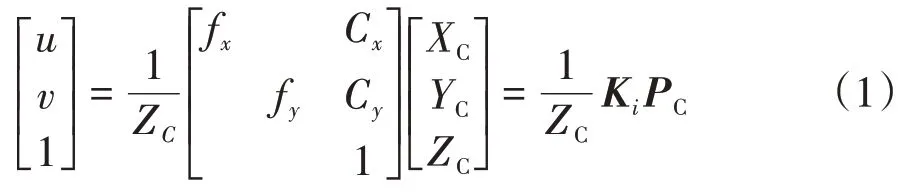
其中,fx和fy为单位尺寸的像素数;Cx和Cy为相机坐标系与图像坐标系的偏移量;Ki为3 × 3 的相机内参矩阵.
式(1)确定了像机坐标系到像素坐标系的转换关系.装有放射源的铅罐放置在世界坐标系中,因此,定位铅罐时需先将世界坐标系转换到相机坐标系中.令铅罐在世界坐标系的坐标矩阵PW=[XW,YW,ZW]T,则转换到相机坐标系为


对式(3)进行矩阵逆运算,解出在已知相机坐标值下像素点在世界坐标系下的值,转换关系为
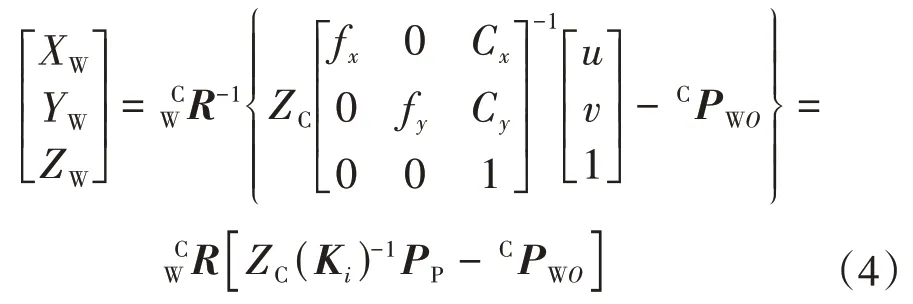
由式(4)确定铅罐中心位置点的像素坐标,进而求出该像素在世界坐标系下的位置点,为机器人抓取放射源提供铅罐定位基础.
1.2 机器人运动学模型建立
本研究以5 自由度串联机器人、摄像头、6 维力传感器、铅罐和分装器搭建机器人抓取系统的仿真模型.结合圆柱形的放射源形状,设计了圆柱三爪型放射源爪手,并在爪手和腕部的连接部位安装6 维力传感器,用于机器人与铅罐的环境交互检测.摄像头固定在距抓取台800 mm 高的支架上,视角向下.放射源抓取机器人系统三维模型如图1,机器人运动学Denavit-Hartenberg(D-H)参数如表1.其中,li-1为连杆长度;αi-1为连杆扭角;di为连杆偏距;θi为对应连杆的转角;i为图1所示机器人的连杆编号,从基座连杆1到腕部共5个连杆.

图1 放射源抓取机器人系统三维模型Fig.1 Three-dimensional model of radiation source grasping robot system

2 基于记忆推理决策的抓取方法
铅罐是半封闭结构,这令摄像机难以对铅罐内的放射源成像.抓取是一种模糊探索过程,建立机器人抓取过程的马尔科夫决策过程(Markov decision process,MDP),记为 MDP ={S,A,P,R,γ}.其中,抓取位置点状态为S=[x,y];动作空间为爪手移动量A=[Vx,Vy];P为从当前状态转移到下一个状态的概率;R为抓取回报值,γ为折扣因子.图2 为R的状态示意图.其中,虚线圆圈为爪手内部轮廓;实线圆圈为放射源外部轮廓.采用归一化尺寸,令放射源直径为1,则爪手的归一化直径为爪手直径与放射源直径的比值.采用此假设,根据爪手与放射源的位置关系,将R分为以下3种情况:

图2 抓取回报值状态示意Fig.2 The reward value status diagram of grasping
1)包含(R= 1):抓取位置刚好在放射源的抓取包络体内.通过爪手传感器判断为抓取成功.
2)交叉(R=-1):在实际作业中,通过机器人爪手高度及底部碰撞检测力,测得抓取位置部分与放射源位置发生交集,此情况判断为抓取失败.但是,此区域内抓取成功的概率较大,该位置的抓取数据S可为后续抓取提供参考.
3)空采样(R= 0):实际作业中,通过分析机器人爪手高度及爪手与铅罐底部碰撞力,检测抓取过程中机器人爪手位置是否与铅罐底部发生接触碰撞.若发生接触碰撞,则视为抓取失败,说明此区域内无放射源,即此区域抓取成功概率为0,同时将此位置相关数据存储到历史数据库中,避免下次进入其邻域,造成重复抓取.
本研究提出基于历史数据记忆推理学习的抓取方式,每次抓取前先比对以前的抓取情况,若有重复,则取消此次动作并重新规划,以免造成动作浪费,流程如图3.其中,n是小概率抓取个数;m是大概率抓取个数;N是总的放射源个数.抓取分为两阶段:①小概率抓取阶段判断放射源在铅罐中的粗略位置,并存储记忆数据库,为第2阶段抓取做准备;②大概率抓取阶段则是基于第1阶段的粗定位,高效完成局部抓取操作任务.
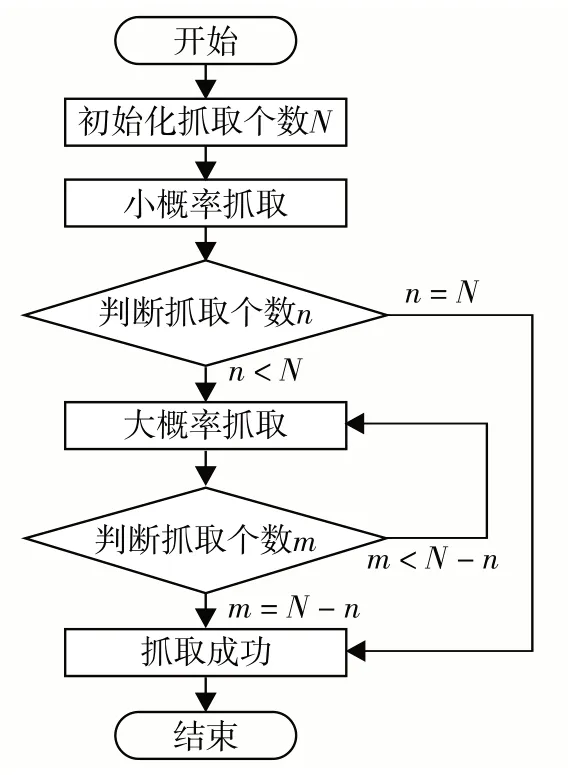
图3 基于记忆推理的抓取流程流程图Fig.3 The grasping flow diagram based on memory reasoning
2.1 小概率抓取学习阶段
由机器人图像定位系统,找到铅罐底部的中心位置,记为P0=[x0y0].根据蒙特卡罗原则,定义均匀抓取采样函数为

其中,r为采样点的极半径,r=rd× rand(1),rd为采样半径;α为采样点的极角,α= 2π × rand(1),函数rand(1)生成0 ~1的随机数.小概率抓取阶段旨在探索放射源的大概位置,每次探索完毕会记录当次抓取的状态及回报值,并构造状态集S={S1,S2,…,Sn},然后通过式(8)的小概率重复抓取检测函数,实现最优抓取策略的选择.

其中,λ为小概率抓取的排斥系数.若φ(Sn) > 0,说明第n次采样是重复采样,无需进行实际抓取,只需重新决策规划;若φ(Sn)= 0,表示第n次采样非重复采样,可进行实际抓取.每次实际抓取采样前,都要计算φ(Sn),以达到学习历史数据,探索下一次抓取空间的目的.
小概率抓取算法的程序代码请扫描论文末页右下角二维码见补充材料图S1 和图S2.首先,在抓取操作前,建立机器人抓取操作的环境模型.然后,进行抓取决策规划,若φ(Sn)= 0,则表示采样成功,先将状态抓取Sn和对应的回报值分别存入小概率抓取数据库H和抓取状况历史数据库K中,然后进行实际抓取.循环采样直到抓取成功个数与交叉抓取个数的和等于总放射源数N时,表示小概率采样抓取成功.若经过指定步数后,抓取成功个数与交叉抓取个数的和小于N,则表示抓取失败,需重新抓取.
2.2 大概率抓取操作
小概率抓取虽然全部抓取成功的可能性很小,但得到放射源邻近位置的概率很大,且能记忆历史操作.在大概率抓取作业阶段,机器人通过查询记忆库中的抓取情况来完成抓取任务,抓取过程伪代码请扫描论文末页右下角二维码查看补充材料图S3和图S4,算法步骤为:
1)初始化已抓取数据库h= ∅,判断2.1节的抓取状态历史数据库K的第i行,若K(i,:) = 1,表示机器人已经抓取了该位置的放射源.
2) 判断K(i,:) =-1 时,若此时h= ∅,则用均匀抓取采样函数locate(H(i,:))进行采样,获得新的抓取位置坐标,并存入h;若h≠∅,则采用中心移动采样函数进行采样.中心移动采样函数为

其中,g= sum(([h;H(i,:)],1)/size(h,1) + 1),g为新采样中心的位置矩阵,函数sum([h;H(i,:)],1)表示对矩阵按行求和,函数size(h,1)求得h的行数.中心移动式采样过程如图4.首先,机器人围绕放射源进行随机采样,得到第1 次采样结果S1.随后,采用中心偏移法将采样中心移至g1,在以g1为中心的圆C1内进行第2 次采样,得到采样结果S2.再次将采样中心偏移到g2位置,对以g2为中心的C2区域内以同样方法进行第3次采样.这样,每次采样都向放射源的方向移动,采样成功的概率逐渐加大,直至最后抓到放射源.
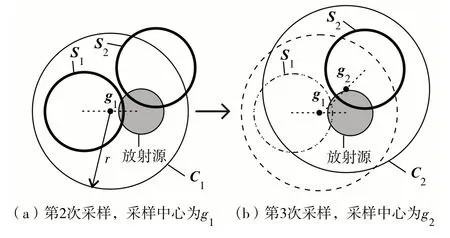
图4 中心偏移采样示意Fig.4 The schematic diagram of center offset sampling
3)基于对过去采样结果的推断,评估是否空抓取.定义大概率重复抓取判断函数为

其中,δ为大概率抓取的排斥系数.若φ(h,S) > 0,说明发生了重复采样,需重新采样.每次采样都要进行式(10)计算,以避免抓取历史空位置.
4)循环步骤1)—3),若在规定时间内抓取到所有放射源,则停止抓取;否则,重新抓取.
3 仿真研究
由于铅罐的半封闭性和强辐射性,机器视觉难以应用于铅罐内部放射源的定位,因此分别采用基于记忆推理决策的强化学习抓取方法和蒙特卡洛随机采样抓取方法[11],对不同数量的放射源进行抓取仿真实验,以验证本研究方法的有效性.实验基于机器人操作系统(robot operating system,ROS)及GAZEBO 仿真器插件,规划算法通过上层C++程序实现,运动执行与控制由ros_control 软件包实现,采用ROS Moveit软件进行仿真.
3.1 排斥系数对抓取效率的影响试验
在基于记忆推理决策的强化学习算法中,无论是小概率抓取排斥系数还是大概率抓取排斥系数都对学习效率有较大影响.图5给出了放射源数N分别为5、10 和12 个的情况下,不同λ值时执行500次抓取任务后平均抓取采样次数.

图5 排斥系数对抓取采样次数的影响Fig.5 The influence of repulsion coefficient λ on sample grasping times
由图5 可见,当λ< 1.5 时,σ随着λ的增加而减小;但当λ>1.5 时,抓取采样次数随λ值的增大而增大;当λ>2.0 时,算法不再收敛,因此可认为λ= 1.5是估计极值点.
不同δ值对学习效率有较大影响.图6 为N= 5、10 和12 时,不同δ值下采用基于记忆推理决策的强化学习抓取方法抓取500次后σ的变化曲线.由图6 可见,随着δ值的增加,所需采样次数减小,但当δ>2.5时,算法不再收敛.

图6 排斥系数δ对抓取采样次数的影响Fig.6 The influence of repulsion coefficient δ on sample grasping times
设N= 6,进行500 次抓取试验,分析平均抓取次数与λ和δ值的关系,结果如图7.由图7 可见,相比小概率抓取排斥系数λ,大概率抓取排斥系数δ值对平均抓取次数σ的影响更大,随着δ值的增加,σ逐渐减小,但δ= 2.5是极值点,超过会导致算法不收敛.综合图5至图7可见,当λ= 1.5且δ= 2.5时,算法收敛性最好.
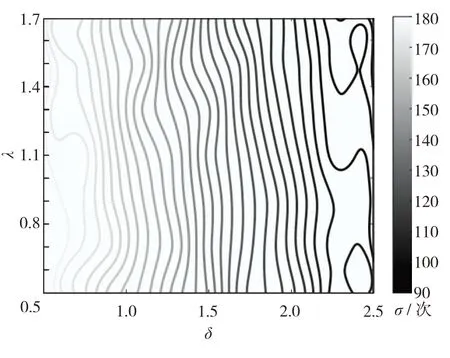
图7 排斥系数分布Fig.7 The distribution diagram of repulsive coefficient
3.2 不同环境下抓取试验
分别采用蒙特卡罗随机采样算法(以下简称采样法)和本研究提出的基于记忆推理决策的强化学习方法,对不同数量的放射源进行抓取试验,每种方法重复500 次,记录两种算法的平均抓取次数,并计算本研究方法相对蒙特卡罗采样法的抓取次数减少率(r),结果如表2.由表2可见,对应不同放射源个数,基于记忆推理决策的强化学习方法的平均抓取次数都少于蒙特卡罗采样法,这是由于前者在每次抓取后,都能利用历史数据进行推理,使下次决策更有效.该方法类似人类在封闭环境下的抓取活动,每次抓取的历史过程,都是学习和探索的过程.当N= 9 时,本研究方法的抓取次数比蒙特卡罗采样法减少了77.33%;当N= 1时,本研究方法的抓取效率比蒙特卡罗采样法提高了89.85%,综合抓取效率平均提高了84.67%,实验说明所提能高效地解决铅罐特殊工况下放射源的自主抓取问题.

表2 两种方法不同放射源数量下500次抓取试验的平均抓取次数Table 2 The average number of 500 grasping tests under different number of radioactive sources with two methods
结 语
设计了放射源容器及分装容器的自主定位系统,通过6维力传感器的反馈实现机器人和铅罐环境的交互,提出基于记忆推理的强化学习策略,实现机器人抓取模式的自主记忆学习.该抓取方法比蒙特卡罗随机采样法,平均抓取效率提高了84.67%,避免了因长时间抓取试探造成的机器人结构疲劳损伤和能量消耗.该系统稳定性高,对此类抓取问题的泛化性更好.
此外,由于此类黑盒子抓取问题需要高质量的触觉传感器,未来可引入类似人手触觉的传感器,并结合强化学习技术,实现黑盒子空间的丰富特征探索,进一步提高铅罐内放射源的抓取效率.
