基于空间通道注意力机制与多尺度融合的交通标志识别研究
2022-05-20黄志强
黄志强,李 军
(重庆交通大学机电与车辆工程学院,重庆 400074)
随着计算机技术的快速发展,L3级的自动驾驶汽车正在走进人们的生活。道路交通标志可以有效指引自动驾驶车辆规范驾驶,为车辆在复杂的道路环境中提供可靠的信息,进一步提高自动驾驶汽车的安全性。不同于其他的指示标志,交通指示牌具有固定的形状、颜色,并且种类相对较少,识别的复杂度较低。但是由于交通标志牌体积小,安装位置不固定,通常会受到遮挡,不同角度拍摄出的交通标志会产生相应的畸变,容易受到光线(光照强度)的干扰,对自动驾驶汽车识别交通标志时造成一定的困难[1]。自动驾驶汽车中交通标志识别系统主要包括交通标志检测、交通标志区域分割、交通标志分类和交通标志识别4个环节[2],而交通标志分类与识别是最重要的一环,交通标志的识别结果会对自动驾驶汽车后续的决策环节产生重要影响。
从自动驾驶汽车提出至今,交通标志识别研究获得了国内外的广泛研究,目前交通标志识别方法主要分为基于模板匹配的方法、基于机器学习的方法和基于深度学习的方法。Andrey等[3]提出了一种用于限制、警告信息路标的检测和识别算法,首先将颜色信息归一化处理,使其能够在深色图像中检测符号,通过形状分析识别符号,并使用模板匹配方法将识别的符号转换为二进制掩码,得到最终的结果。Xu[4]提出通过离散曲线来简化和分解交通标志的颜色边界,离散曲线的终止阶段由切线空间中的弧相似度确定。通过与模板直接匹配,实现对闭合候选形状的识别,最大程度地减少未封闭候选形状和模板之间的几何差异。Huang等[5]使用高斯彩色模型对交通场景图像进行颜色分割,获得YCbCr颜色空间中的交通标志区域,对分割后的图像进行形态学处理,提取出原始图像中具有矩形区域的候选交通标志作为其形状属性,再与模板匹配相结合。
由于以模板匹配为基础的交通标志识别方法必须在较为理想的环境条件下进行,并且对一些位置已经发生旋转或遮挡的交通标志的识别率较低,而以机器学习为基础的交通标志识别方法可以很好地克服以上缺陷。目前主流的机器学习方法需要人工提取被检测物体的特征,然后选择相应的模型使最终的表现效果达到最好,常见的机器学习方法[6]有决策树、支持向量机(SVM)、线性回归、非线性回归和Hierarchical聚类。
Chen等[7]提出一种基于交通标志特定的颜色、形状和空间信息的新的显著性模型,通过合并显著性信息,增强特征金字塔以学习AdaBoost模型,该模型从图像中检测出一组交通标志候选区域,再通过迭代代码字选择算法,将候选区域转换判别式密码本,并学习支持向量回归模型以从检测到的标志候补中识别出真实的交通标志。Chen等[8]使用Gabor滤波器提取特征向量,通过交通标志的几何特征进行仿射变换校正,最后使用SVM进行分类和识别。Wang等[9]提出从交通标志图像的不同光谱带中提取定向梯度直方图(HOG)特征,并使用线性支持向量机将其分类为主要类别,通过局部二进制模式(LBP)和 Gabor滤波特征的互补特征,馈入SVM和随机森林算法中进行分类。
进入21世纪后,高性能计算机的飞速发展和数据量爆炸式的增长为深度学习在自动驾驶领域的应用提供了可能。常见的深度学习识别方法分为单阶段和两阶段[10],以两阶段识别为代表的主要有RCNN、Fast-RCNN[11]和 Faster-RCNN[12]。 这些算法先对图像进行有条件扫描,生成大量的候选框,对每个候选框传入网络提取出特征,将该特征送入分类器中进行分类,最后生成正确的类别名,由于生成了大量的候选框,候选框之间存在重叠区域,造成整个网络运行缓慢,针对以上问题,研究人员提出了单阶段识别 方 法, 主 要 包 括 YOLO[13]、 YOLO9000[14]、YOLOv3[15]和 SSD[16],该类算法先使用聚类算法生成一定数量的先验框,通过这些先验框去寻找感兴趣区域,将感兴趣区域输入特征提取网络中,使用回归法获得物体的置信度概率,运行速度得到了极大提高,为实时检测提供了可能。但是单阶段神经网络通常网络层数较多,由此带来了巨大的参数量,曾雷鸣等[17]使用MobileNetv3-Large轻量网络替换YOLOv4中的主干网络,为了进一步减少网络的运行时间,采用深度可分离卷积提取目标的特征。Zhang等[18]先在教师网络中使用残差模块将不同通道信息进行融合,采用知识蒸馏法让只有6层的学生网络迁移学习教师网络的权重。Kang等[19]改进SqueezeNet网络的Fire模块,用不同的卷积结构搭建出不同的轻量化网络。张伟等[20]提出能够部署在小型无人机上的DS-YOLO算法,首先以密集连接的思想重新设计了YOLOv3-tiny的主干网络,接着通过使用改进型的空间金字塔池化模块提高对小目标的识别,最后利用批归一化去除未含有重要信息的网络层。交通标志在整个图片中所占的比例较低,图片的清晰度容易受自然因素的影响,如光照强度、拍摄角度、被遮挡等,由于算法识别的准确率和运行的速度会对车辆的控制产生较大的影响,现有的检测模型对较小的交通标志的识别率较低,并且运行速度也不能满足要求。
针对以上存在的问题,本文以YOLOV3单阶段识别模型的轻量级神经网络YOLOV3-tiny为基础,提出了改进型YOLOV3-3ctiny的交通标志识别模型。根据自然场景下交通灯的特点,为了进一步利用神经网络的浅层语义信息,提高对不同大小的交通标志的识别率,在特征提取金字塔中增加一层特征提取层,进行多尺度的特征融合。为了进一步提高交通标志的识别率和置信度,利用不同的通道信息和空间信息,在深层网络中添加空间通道注意力机制模块,在长沙理工大学开源的交通标志数据集(CSUST Chinese Traffic Sign Detection Benchmark,CCTSDB)中进行训练和测试。
1 YOLO网络模型
YOLO神经网络是一种采用端到端进行训练,能够实时检测的单阶段检测模型[21],先将图片划分为n*n个网格,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。在训练和测试时,每个网络预测B个边界框,每个边界框对应5个预测参数:边界框的中心点坐标(x,y),宽高(w,h)和置信度评分(confidence)。最后使用均方和误差作为损失函数来优化模型参数,即网络输出的S*S*(B*5+C)维向量与真实图像的对应S*S*(B*5+C)维向量的均方和误差,其中S为划分的网格数量,B为每个网格可以预测检测框的数量,C为类别总数。
由于YOLOV3神经网络的层数较深、实时性较差,对硬件的要求较高,本文采用YOLOV3神经网络的轻量化模型YOLOV3-tiny。YOLOV3-tiny网络模型的主干提取网络由改进的残差模块Darknet构成:6个最大池化层和13个卷积层,特征金字塔网络中生成两个YOLO层,分别输出13*13和26*26两个不同大小的特征图,每层的激活函数变为sigmoid。虽然YOLOV3-tiny神经网络运行速度较快,但是其网络深度较浅,当目标物体之间的特征相差比较复杂或者在复杂的环境下时,识别率较低。YOLOV3-tiny网络模型如图1所示。

图1 YOLOV3-tiny网络模型
2 YOLOV3-tiny的改进网络模型
为了使YOLOV3-tiny在具有较快识别速度的同时具有较高的识别精度,根据交通标志具有不同形状、颜色和文字的特点,本文提出了适合检测交通标志的改进型网络模型YOLOV3-3ctiny,其网络结构如图2所示。

图2 YOLOV3-3ctiny网络模型
根据图2可知,YOLOV3-3ctiny网络模型主要由特征提取网络和分类回归网络两部分构成。特征提取网络由3种网络层构成:卷积层、最大池化层和空间通道注意力机制,分类回归网络由上采样层和连接层构成,以此输出目标的概率和定位框。根据交通标志的特点,YOLOV3-3ctiny在特征提取网络中利用空间通道注意力机制能够在深层网络中增强特征的表达能力,同时抑制背景对目标物的干扰的特点,分别在不同的分类回归层增添一个空间通道注意力机制模块,虽然这样会增加网络的参数量,但是大大增加了网络的深度。由于交通标志在整个图像上所占的比例变化较大,当比例较小时,网络的准确率较低,YOLOV3-3ctiny增加一层回归网络,采用特征金字塔多尺度融合的方式,将第二层回归网络的输出与特征提取网络中的第7层相连接,以此增加对低比例交通标志的识别率。
2.1 注意力机制的改进
深度学习中的注意力机制仿造了人类的视觉系统,当人类观察物体时,首先会快速地扫描全部区域,再从该区域中选取目标物并投入更多的视觉资源,以获得更加详细的信息,只是神经网络在扫描图像时需要对图像的每个像素进行扫描[22]。滑动窗口、局部图像特征提取等[23]方法可以看作是早期的注意力机制模型,随着深度学习的发展,在交通标志识别中引入注意力机制可提高神经网络的识别率。
本文采用空间通道注意力机制(CBAM),该注意力机制由两个部分组成[24]:通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spartial Attention Module,SAM),两个模块的结合可以对神经网络特征图中交通标志分配较高的权重,背景分配较低的权重,从而提高YOLOV3-3ctiny神经网络对交通标志的关注度,解决交通标志局部被遮挡、光线暗淡和所占比例较小的问题。
在卷积神经网络中,通道信息一般代表着图像不同的特征信息,因此通过对通道进行选择可以使网络更能注意到图像中对检测有用的信息。为实现对通道的选择,本文采用SENet网络模型中的挤压激励模块 (Squeeze and Excitation, SE)[25], 如图3(a)所示。通道注意力模块由压缩、激发及特征重标定3部分组成,在压缩阶段先通过第一个全局平均池化层将各通道的全局空间特征作为网络输出的通道特征,并使特征图的输出变为1*1*C/r(r为降维倍数),再通过全连接层将特征图的特征映射到样本标记空间中,接着使用ReLu激活函数加入非线性因素,提高神经网络对模型的表达能力。使用第二个全连接层将特征图的通道数由原来的C/r维升至C维,再采用sigmoid激活函数优化网络,最后和原始主干网络的输出相连接,通过压缩、激发及特征重标定,不仅加深了原始网络的深度,获得较为丰富的语义信息,也极大地控制了增加的参数量。
通道注意力机制主要是为了增加不同通道之间的相关性,提高被识别物体的权重,不能将不同空间中关键区域的特征相关联,通过在原始的通道注意力模块中衔接一个空间注意力模块[26](SAM,如图3(b)所示),利用通道注意力机制中的全局平均池化层与空间注意力机制中的全局最大池化层,生成两个包含不同信息的特征图,将这两个特征图通过一个7*7的卷积模块进行特征融合,得到一个H*W*1的特征图,最后再通过sigmoid激活函数生成权重图,叠加回原始的输入特征图中,最终使被检测物体的区域得到了加强,背景区域得到相应抑制。空间通道注意力机制如图3(c)所示。
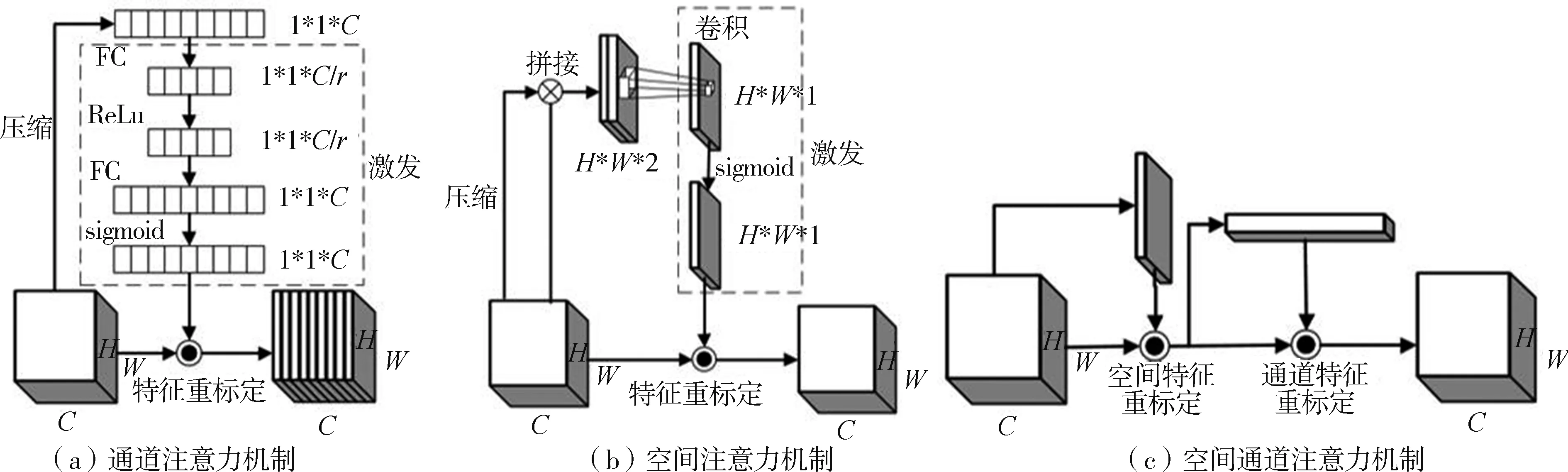
图3 注意力机制
如图2所示,将衔接后的空间通道注意力机制CBAM模块加入到神经网络模型中。CBAM模块由空间注意力机制(SAM)衔接到通道注意力机制(SE)中组成。由于特征金字塔网络负责对目标物进行识别和预测,并且处于网络的深处,考虑到神经网络的参数量过多会降低网络的运算速度,故在原神经网络模型中每个YOLO预测层前添加一个空间通道注意力机制,使每个YOLO预测层将更多的权重分配给被检测区域。
2.2 多尺度预测网络的改进
神经网络的深层特征图的感受野比较大,包含目标丰富的语义信息,但是分辨率较低,物体的空间几何特征细节缺失严重,而浅层特征图中几何细节信息表征能力强,虽然分辨率高,但是语义信息少[27]。如图4所示,对每一种尺度的图像进行特征提取,能够产生多尺度的特征图像,每层的输出都具有较强的语义信息,甚至可以包含一些高分辨率的特征图。为了尽可能多地检测出不同形状的交通标志,本文提出一种改进型的多尺度网络预测模型[28],如图2所示,在原网络模型的第4个卷积层后分别增加一个1*1和3*3的卷积模块,通过降维和升维操作,在保持特征图不变的情况下增加了网络的非线性特征,加深网络的深度,交换不同通道之间的信息。在第5个卷积层后通过一个3*3的卷积层、一个上采样层与上一个卷积层的输出相连,形成一个新的YOLO预测层,其输出的大小为52*52,这一层主要负责预测较小的目标物体。

图4 多尺度特征融合原理
2.3 Kmeans聚类算法
被检测物体在图片中的大小和位置均不固定,若直接使用算法进行定位将产生较大的误差。通过预先设置几个固定大小的先验框作为初始预测框,在定位时首先判断被检测物体的中心点出现在哪个预测框中,再利用该预测框定位出当前物体。为了加速预测框的回归,提高定位精度,本文采用一种静态的数据分析方法Kmeans聚类[29]对 CSTDB数据集进行聚类分析,如图5所示,数据集中大多数的边界框在(0.05,0.1)附近,只有少量的边界框尺寸较大,位于(0.3,0.4)附近,其中(0.05,0.1)为相对于图像的归一化位置。Kmeans聚类算法表达如下:
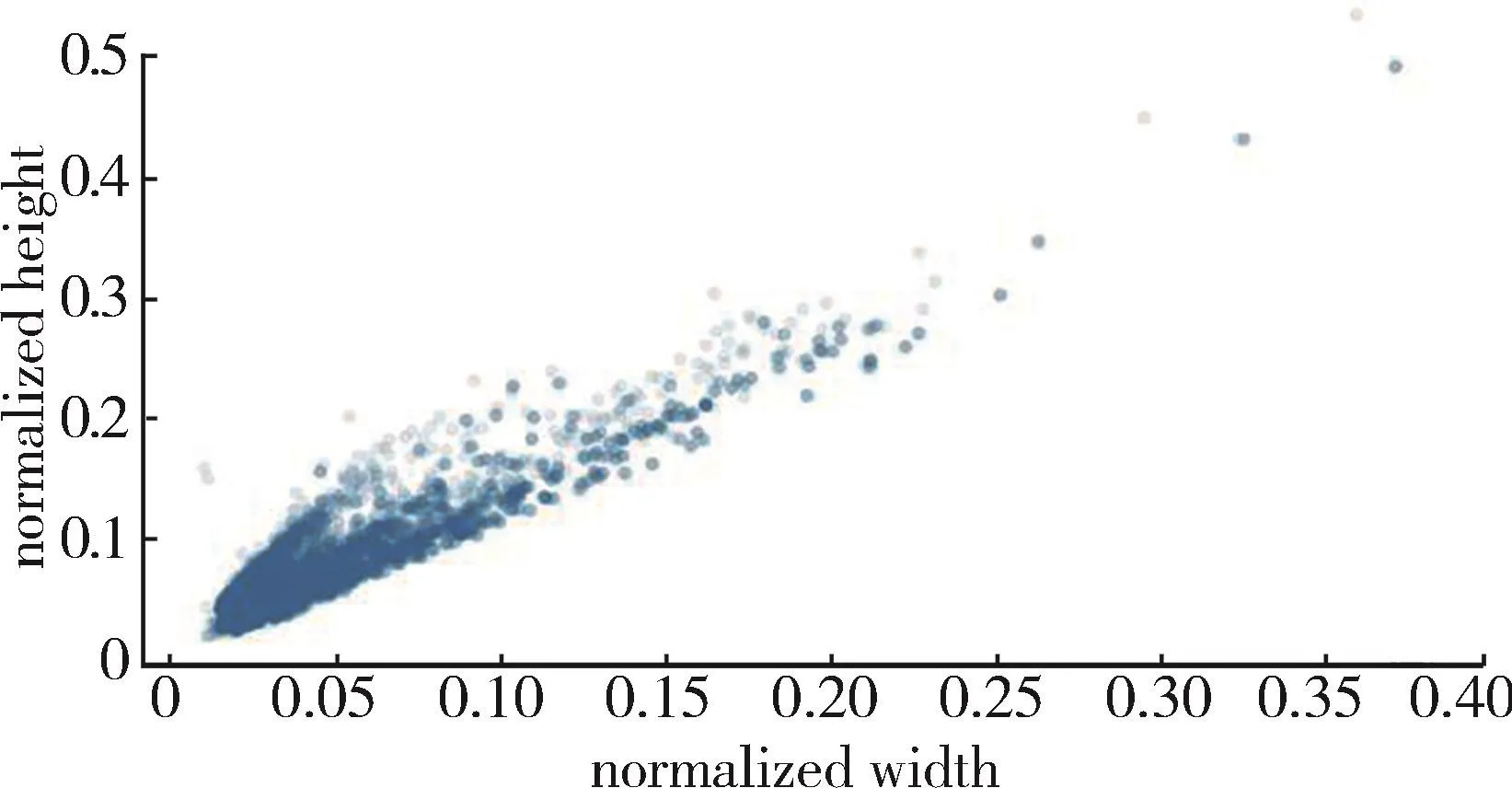
图5 数据集聚类分析
(1)根据数据集,先随机设置K个聚类中心。
(2)将数据集中的每个样本点与设置的聚类中心做欧氏距离运算
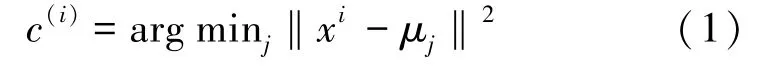
式中,xi为数据集中的每一个样本,第一次计算时μj为随机选取的质心,此后为每次更新后的质心。
(3)根据欧氏距离的值将数据中的点划分到数值最小的聚类中心所在的簇中。
(4)更新每个聚类中心重新计算该聚类中心的质心,质心更新公式为

式中,j为划分的类,m为划分的聚类个数,c(i)代表样例i与m个类中距离最近的类。质心μj代表对属于同一个类的样本中心点的猜测。
(5)通过畸变函数确定每个样本点到聚类中心点的距离最小,从而得到一组最优聚类中心值,畸变函数为
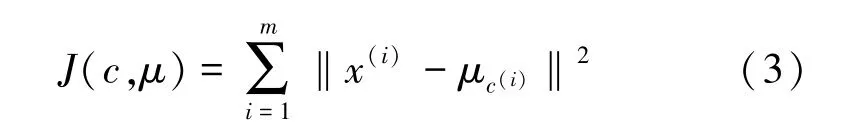
由于Anchor Box自身的大小会产生一定的欧氏距离误差,本文将训练集中的真实框与Anchor Box之间的IoU作为优化的目标函数,目标函数D的表达式为

式中,A、B分别为真实框与预测框,IoU为A和B的交并比,box为数据集中的真实框,cen为聚类中心,m为数据集中的种类个数,n为数据集中样本个数。当K的取值范围在1~12时,得到K与平均重叠度之间的关系如图6所示。当K取值大于9时,聚类点的平均重叠率趋于平缓,考虑到预测网络中K值较大时,会增加神经网络的预测时间,因而本文聚类中心点数值设置为9,这样可以加快神经网络损失函数的收敛,获得较高的定位精度,降低神经网络的预测时间,最终的聚类中心位置如图7所示,先验框分别取值为(7,21)、( 8,15)、(10,29)、(12,20)、(16,26)、(18,35)、(27,40)、(37,55)、(62,87)。

图6 聚类中心数与平均重叠度的关系
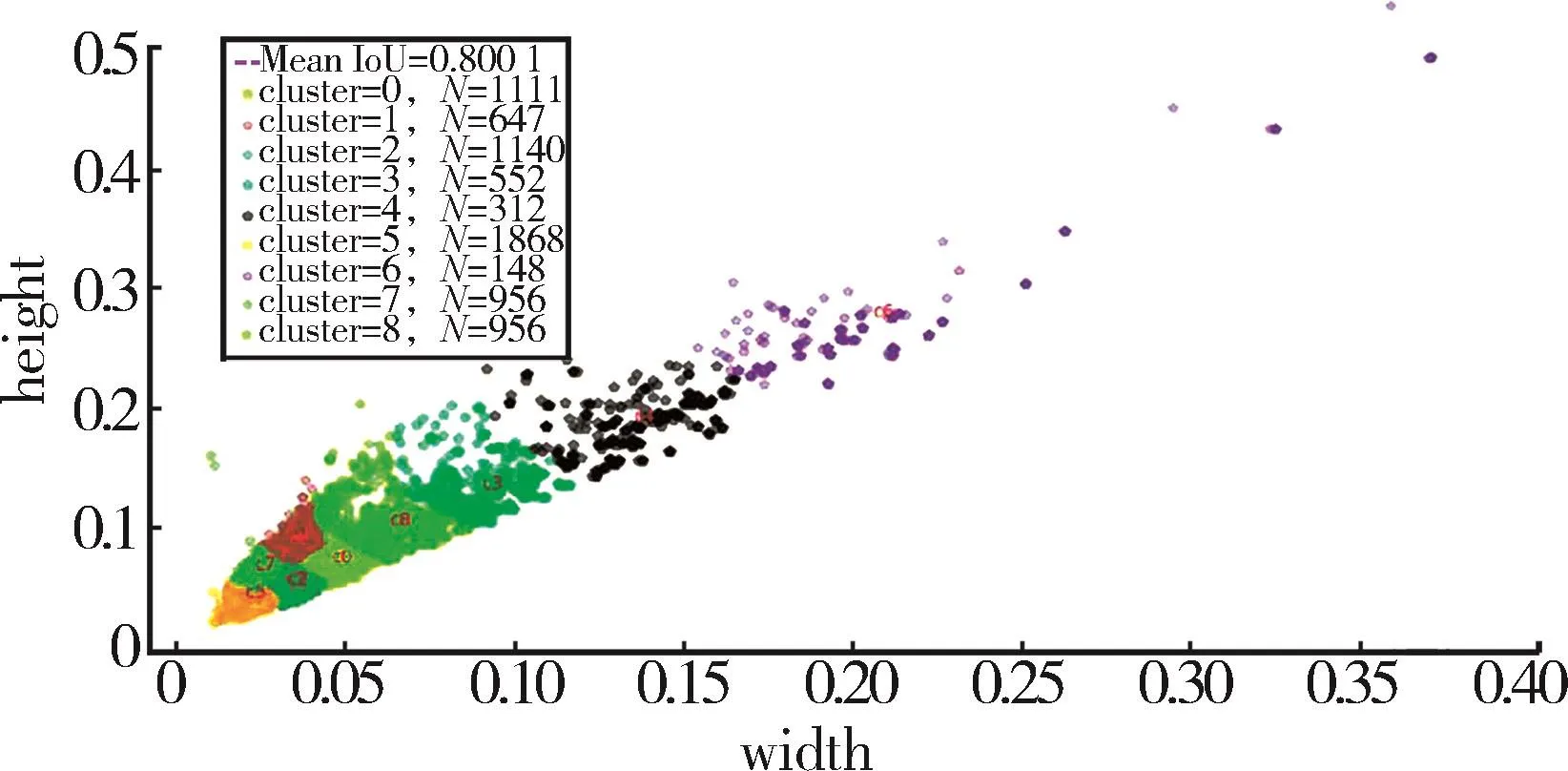
图7 聚类中心分布
3 实验及结果分析
3.1 实验数据集及实验环境
本文选择由长沙理工大学制作的中国交通场景数据集[30](CCTSDB),该数据集是在道路上通过连续拍摄随机选出的15 712张图片,包含城市道路和高速道路,将交通标志分为指示、禁止、警告三类,本文采用了该数据集的一部分,具体类别数量如表1所示,数据集的格式调整为PAS-CAL VOC。为了使CCTSDB数据集中的图片包含更加复杂的交通标志场景,增强YOLOV3-3ctiny网络模型在不同环境下对交通标志的检测能力,对输入网络的图片进行Mosaic和翻转两种图像增强[31]处理,将输入网络的图像先随机地进行翻转处理,然后从其中选择4张图片进行随机裁剪,再拼接到一张图上作为训练数据的输入,如图8所示。这样做可以扩大交通标志数据的类型,丰富图片的背景,并且4张图片拼接在一起变相地提高了batch_size,提高网络模型的鲁棒性。

图8 数据增强

表1 CCTSDB数据集类别数量
本文采用PyTorch深度学习框架搭建神经网络,在具有GPU环境的中科曙光服务器中训练神经网络,并使用apex库混合16位和32位计算,从而节约GPU显存和加速神经网络运算。具体参数如表2所示。

表2 实验环境参数
3.2 YOLOV3-3ctiny 网络训练
将CCTSDB数据集传入YOLOV3-3ctiny神经网络中进行训练,将数据集按照2∶1∶7的比例划分为测试集、验证集和训练集,输入图片的分辨率为608像素×608像素,一次性加载16张图片进入内存,然后分4次完成前向传播,每次4张图片,经过16张图片的前向传播以后,进行一次反向传播,梯度下降的动量参数设置为0.9,为防止发生过拟合,权重衰减正则项设置为0.000 5,采用动态学习率的方式,初始的学习率设置为0.001,调整策略设为在第150步和250步时分别乘上0.1。由图9可知,当迭代次数为200时,损失函数GIoU的值在0.9左右,当迭代至250次时,损失函数的值为0.86,可判定网络训练趋于稳定。

图9 训练损失值曲线
3.3 结果分析
本文选取目标检测中的平均精度均值(mAP)、查全率(Recall)、查准率(Precision)评估本文的模型性能[32],通过平均精度均值预测目标位置以及类别,查全率反映一个类别的预测正确率,查准率反映是否完全检测出目标物体。将数据集中的样本根据其真实类别与神经网络预测的类别组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)4 种情形,评价指标定义如下:

式中,Ntp表示正样本预测为正样本,Nfp表示负样本预测为正样本,Nfn表示正样本预测为负样本,k代表图片数目,p(k)表示识别出k个图片是Precision的值,Δr(k)表示识别的图片由k-1增加到k时recall值的变化情况,P代表Precision,R代表Recall,C为类别总数。
神经网络训练250次时模型达到稳定,选取前250次的训练数据,与未作任何修改的YOLOV3-tiny神经网络、只进行多尺度特征融合的YOLOV3-tiny-3FPN神经网络和只进行空间通道注意力机制改进的YOLOV3-tiny-cbam神经网络做比较,评价指标结果如图10所示,不同模型的最终对比结果如表3所示,其中time为检测一张图片需要的时间。

图10 评价指标结果图

表3 评价指标对比
通过表3可知,由于增加了特征融合网络和通道空间注意力机制,使得神经网络对较小的交通标志有更高的识别率。本文改进后的算法比YOLOV3-tiny的平均精度均值提高了24.9个百分点,而时间只增加了7.2%,FPS几乎不受影响,与YOLOV3相比平均精度只降低了1.7个百分点,检测时间降低了49.6%,FPS提高一倍,训练的权重文件的大小与YOLOV3-tiny相比仅少量增加。将测试图片传入不同的算法中进行检测,获得最终的分类结果,如图11所示,使用原始的YOLOV3-tiny算法会产生漏检、分类置信度较低和错检的情况,融合改进后的空间通道注意力机制后,YOLOV3-tiny-cbam算法适当地提高了目标物体的置信度,但是漏检和错检的情况并没有改变,融合改进后的多尺度特征金字塔后,YOLOV3-tiny-3FPN算法解决漏检和错检的情况,但是每个交通标志的置信度较低,因而在恶劣环境下会识别率不高,当将这两种改进算法同时融入YOLOV3-3ctiny后,每个交通标志的置信度都得到较大提高,同时未发生漏检和错检,检测速度为0.133 s,满足实时性检测的要求。

图11 不同算法检测效果对比图
4 结束语
本文以单阶段目标检测算法YOLOV3-tiny为基础,针对交通标志提出了改进型的YOLOV3-3ctiny神经网络检测模型,通过通道注意力机制与空间注意力机制相结合,自适应调整不同通道之间的特征信息,将不同空间上的通道特征做相同处理,使被检测区域获得更多的权重,降低背景区域的干扰;利用浅层神经网络包含丰富的几何细节信息和高分辨率的特点,与深层神经网络进行特征融合,提高对不同大小的交通标志的检测率,通过Kmeans聚类算法对交通标志数据集进行聚类分析,提高检测时目标框的定位精度。在CCTSDB交通标志数据集上进行训练和测试,实验结果表明,本文神经网络模型的mAP达到91.8%,与YOLOV3-tiny相比检测精度提高了24.9个百分点,比YOLOV3神经网络模型的检测时间减少了49.6%,达到每0.133 s检测一张图片,能够达到实时检测的目的。
