基于代价敏感度的改进型K近邻异常流量检测算法
2022-05-20李泽一
李泽一,王 攀
(南京邮电大学现代邮政学院,江苏南京 210003)
移动互联网时代,网络流量呈现爆发式增长,随之而来的是网络攻击事件频发,攻击形式呈现出复杂多变的特点。于是入侵检测系统不再局限于基于传统的DPI技术,开始采用有监督式的机器学习方法检测流量,例如卷积神经网络[1]、支持向量机等。尽管这些方法都表现出了良好的示范性能,但随着网络数据流量规模的急速扩大,使得有监督的机器学习方法识别的准确度下降,出现误报、漏报的情况。同时有监督的机器学习方法,存在数据标签困难、恶意样本少和无法检测未知恶意攻击的问题。而无监督的深度学习方法可以训练不带标签的数据集,并能成功检测未知的攻击。因此,使用无监督的机器学习方法检测恶意攻击流量已成为网络安全领域的一个热门研究方向。现阶段异常检测模型在图像领域取得令人瞩目的成就。但是基于图像的异常检测算法运用在网络流量上效果未可知。
在上述背景下本文使用无监督方法来检测网络异常流量。首先K近邻[2](KNN)算法作为传统的机器学习算法,在异常检测方面发展已较为成熟。该算法以数据样本与其邻居的距离为基准,对每个样本到其邻居进行距离排序,并将此排序中的前k个点声明为异常值。而自动编码器(AE)作为深度学习异常检测的最典型代表,最初起源于图像[3],现在被迁移到网络流量领域中。其算法旨在学习一组基向量,可以通过组合特征进行压缩,之后解压成一个新的向量。其可以生成接近原始输入的特征输出,反映相似数据的相似信息。在异常检测的应用中,AE通过计算样本的最大重构误差来判断样本是否异常。但是网络流量与图像的数据结构有着本质的差别,因此使用该模型会有一定的局限性。
本文为了识别异常网络流量,提出了一种基于改进KNN的无监督异常检测方法。本文的主要贡献:
(1)本文提出了一种基于改进型KNN的异常流量检测方法。该方法解决了恶意流量样本少、难以采集和标注的问题。
(2)文章提出了一种代价敏感性的指标体系,用于衡量异常检测模型的性能。基于此指标,改进的模型表现出色。
(3)实验使用了3种规模大小相异的数据集和两种经典的机器学习和深度学习方法,以印证本文提出的算法的性能。实验结果表明,本文提出的改进KNN异常检测算法相比深度学习方法和其他传统的机器学习方法,更加适合识别异常网络流量。
1 相关工作
1.1 异常检测研究
随着机器学习的不断发展,许多学者将机器学习应用到异常检测领域。Zhao等[4]提出一个Pyod开源框架,对各种异常检测算法进行归纳总结,供各位同行使用。深度学习由于其可以自动提取高级抽象特征,故利于处理大规模复杂数据。因此深度异常检测首先在图像领域发展起来,而且已在医学图像领域逐步发展成熟。Schlegl等[5]提出了一种深度卷积生成对抗网络(fast-ANOGAN)的无监督学习方法,以检测视网膜的解剖是否变异。其模型是根据特征空间中观察位置的局部密度确定异常值。Akcay等[6]提出一种较为新颖的异常检测模型(GANomaly),通过使用卷积生成对抗网络学习高维图像空间的生成和潜在空间的推理。当模型学习出数据分布的较大距离度量时,表明该分布存在异常值。2020年,Wolleb等[7]提出基于胸膜腔变化的异常检测模型。通过深度学习模型提取疾病高度特异性的特征,学者们能更详细地检测结构变化。在图像异常检测上,深度学习已经发展相当成熟。接下来,本文探讨异常检测模型在网络流量检测领域中的应用。
1.2 网络流量异常检测
应用传统机器学习和深度学习方法,网络异常检测目前也得到了长足的发展。目前已有学者将机器学习应用在网络流量检测中。Ramaswamy等[8]提出了基于KNN的进化推理系统(kENFIS)。该系统主要用于检测计算机蠕虫。Amer等[9]用数据集训练OCSVM,然后考虑数据点与确定的决策边界的归一化距离,对每个数据点进行分类。Falcão等[10]将6种不同种类的异常检测方法在网络流量上进行综合对比实验。同样他们也对各类数据集进行分析和整理,但并未对深度学习的异常检测进行对比实验,无法了解深度学习在网络流量上的效果。Chen等[11]提出使用卷积自动编码机(CAE)检测网络异常流量,实验在NSL-KDD数据集上表现较好,但是仅仅在单一数据集上不具有说服力,不能说明CAE就是适用网络流量的最佳选择。文献[12]提出了一种基于自动编码器的入侵检测系统,将模型收敛后的损失值作为阈值,形成一套端到端的入侵检测系统,但如果模型收敛性不够好,就不能保证检测效果。Zavrak等[13]使用无监督深度学习方法和半监督学习方法检测异常网络流量。具体地说,使用自动编码器和变分自动编码器方法来识别基于流特征的未知攻击。实验结果表明,VAE在很大程度上优于AE和One-Class SVM。但是他们只是使用ROC曲线和AUC值展示模型的好坏,并没有展示其具体的异常检测效果。文献[14]提出了一种基于改进重建概率的异常检测方法。其中作者重点凸显VAE模型的重建概率是一种概率度量,能考虑变量分布的可变性。生成对抗网络(GAN)能够对现实世界数据的复杂高维分布进行建模,这表明它们可以有效地进行异常检测。因此 Zenati等[15]使用GAN模型进行异常检测,通过在网络入侵数据集上的测试,表现出模型较好的性能。但是文献[14-15]实验的数据集使用 KDD cup[16],该数据集较小。因此这两种模型,在该数据上的实验效果不具有说服力。
2 模型与数据选择
2.1 算法建立
K近邻算法是基于邻居节点计算最近距离的算法(KNN),主要用于识别异常值[17]。该算法对一个新样本进行分类时,必须计算它与集合中每个样本点的距离。对于每个数据点,检查整个数据集,以提取具有最相似特征值的数据集,即最接近的邻居。本文提出的改进KNN算法使用欧几里得距离作为距离度量,其涉及的计算并不复杂,具体见式(1)。p表示一个数据样本,pi则代表该样本的第i个特征,[p1,p2,…,ps] 表示s维特征的数据样本,同时用dist(p,q)表示两个流样本p和q之间的距离。

基于近邻的异常检测算法的核心思想是对每个点计算它的k近邻距离,然后在测试集合中按照每个k近邻距离降序排序。前n个点即可认为是离群点。执行步骤见算法1。
算法1 基于改进KNN的异常检测
1.输入:训练数据集为train_data,测试数据集为test_data。
2.算法:
3.Begin:
4.forpin train_data:
5. 根据式(1)计算样本p的k近邻距离;
6. 对于p赋予异常得分;
7. 归一化p的异常得分;
8.end
9.预定阈值;
10.forpin test_data:
11. ifp归一化得分>阈值:
12.p为异常数据;
13. else:
14.p为正常数据;
15.end
图1展示了异常检测的流程,原始的网络流量特征先预处理,处理完成的数据进入KNN算法。在整个过程中,异常检测如何判断离群的样本,变成了问题的关键。目前的异常分数是根据不同的度量方法计算得出的,为了一致性,异常值被分配了更大的异常分数。本次实验不讨论异常分数的计算,重点讨论阈值选择的方法。由于目前阈值的设定还没有较好的选择。基于此,本文提出改进阈值选择方法,即把异常得分做最值归一化,将异常得分映射到[0,1]的区间内。利用验证集获取阈值,达到阈值修正的目的。同时为了更好地展现异常检测能力,传统的评价指标已不再适用。为了凸显模型异常检测性能,引入代价敏感度评价指标,即赋予良性精确率和恶意召回率更多的权重。
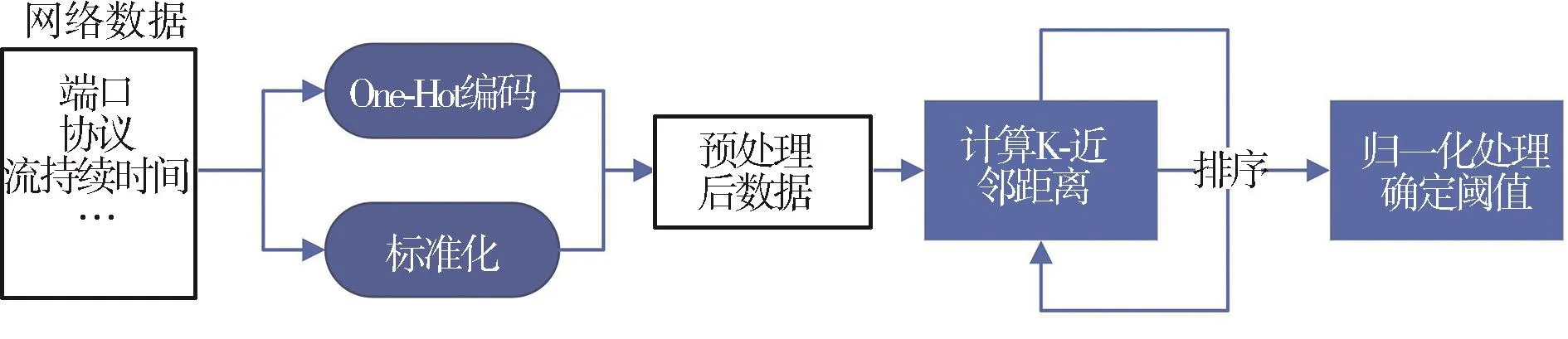
图1 算法流程图
2.2 数据集选择
本实验使用3种类型的数据集,分别是CICIDS2017[18]、UNSW-NB15[19]和 NSL-KDD[20]的 3个数据集。
(1) CICIDS2017:CICIDS2017是一个包含入侵检测和入侵防御数据的公共数据集。它还包括使用CICFlowMeter[21]的网络流量分析结果,使用基于时间戳、源IP、目标IP、源端口、目标端口和协议等特征组成的标签流。具体的攻击类型如表1所示。图2展现出t-SNE可视化中数据集的乱序性。
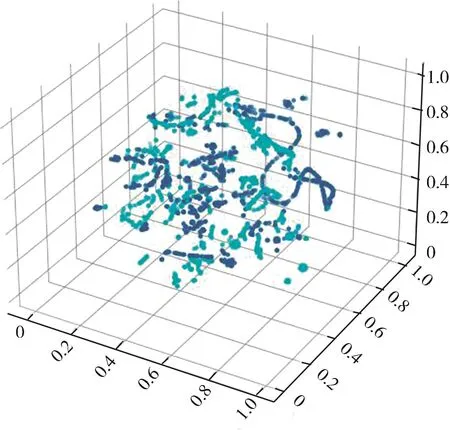
图2 CICIDS2017 t-SNE可视化
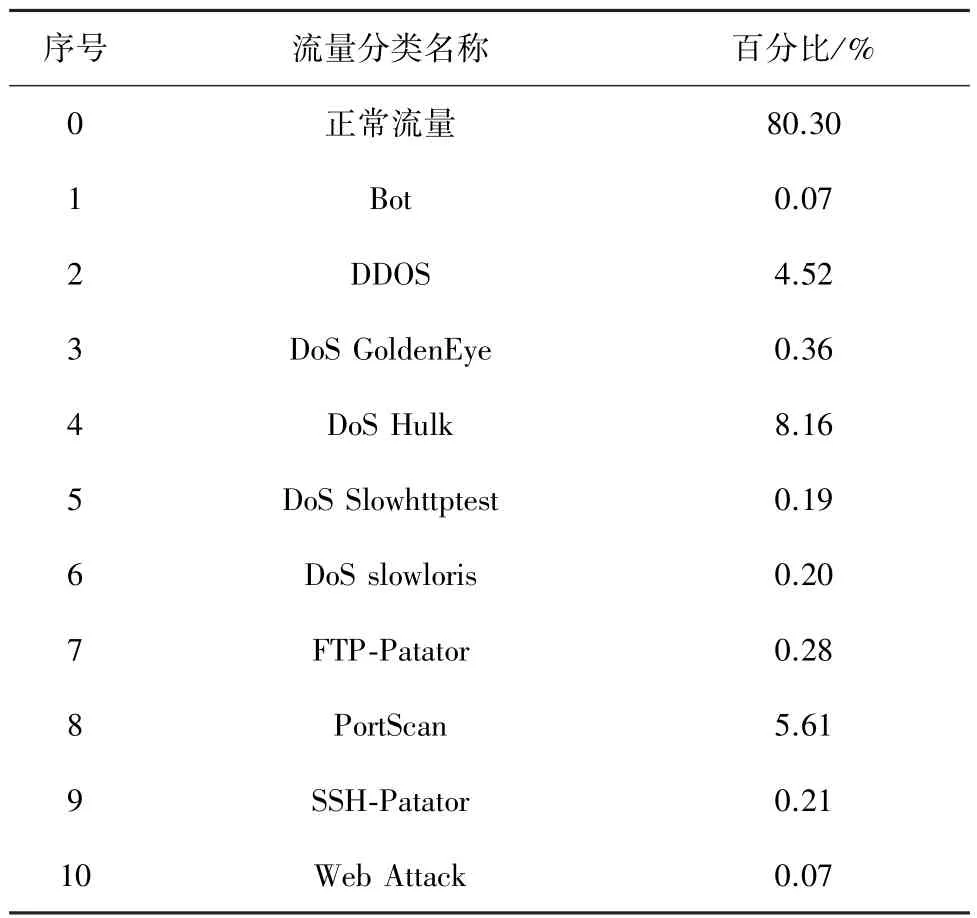
表1 CICIDS2017不同流量占比
(2)NSL-KDD:NSL-KDD是对 KDD99数据集的改进。NSL-KDD数据集的训练集不包含冗余记录,所以模型分类器不会受到冗余记录的影响。具体的攻击类型如表2所示。图3的可视化展现了该数据集未分离时的乱序性。同时NSL-KDD数据集的测试集中没有重复记录,使得检测率更加准确。

表2 NSL-KDD不同流量占比

图3 NSL-KDD t-SNE可视化
(3) UNSW-NB15:UNSW-NB15是澳大利亚网络安全中心(ACCS)2015年在LABS收集的正常网络活动和综合攻击活动的混合体。具体的攻击类型如表3所示。从图4可以清晰地看出该数据集的乱序性。

表3 UNSW-NB15不同流量占比

图4 UNSW-NB15 t-SNE可视化
为了模拟真实的网络环境,本次实验分别选取正常流量和恶意流量构成上述各数据集的测试集,比例为100∶1。实验将剩余的正常流组合成一个训练集进行模型训练。每个数据集中都有符号特征和数字特征。本文对于文字特征,使用one-hot编码格式进行处理,对于数字符号,使用最值归一化公式(2)进行处理。
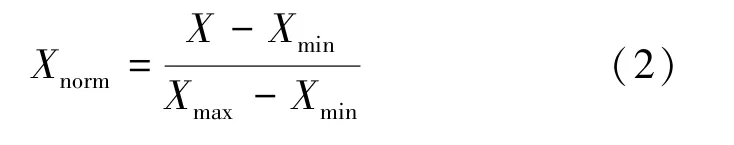
3 实验结果与分析
3.1 实验环境
本文以Python3作为主要编程语言。具体参数如表4所示。本文使用以下3种算法对网络入侵检测算法进行对比实验,包括 KNN、AE和 OCSVM。同时本次算法KNN的近邻参数默认选择为5。文章重点讨论模型结构对于网络流量的适用性,参数不过多讨论。

表4 设备参数
3.2 性能评价指标
性能评价指标包括接收者操作特征曲线(ROC)曲线下与坐标轴围成的面积(AUC)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、混淆矩阵(Confusion Matrix)等,这些指标来源于4个参数指标:预测正确正样本(True Positive,TP)的数量、预测错误的正样本(False Positive,FP)数量、预测正确的负样本(True Negative,TN)数量、预测错误的负样本(False Negative,FN)数量。下面对文章的绩效评价指标进行详细说明:
准确率(Accuracy)指的是正确预测的样本数占总预测样本数的比值,反映的是模型算法整体性能。其计算公式为:

精确率(Precision)指的是正确预测的正样本数占所有预测为正样本的数量的比值,反映的重点是正样本的比重。其计算公式为:

召回率(Recall)指的是正确预测的正样本数量占正样本数量总数的比值,反映的重点是预测正确的正样本的比重。其计算公式为:

曲线下面积 (AUC)。ROC曲线表示二元分类器在区分阈值变化时的性能的图形图:ROC曲线下方区域的面积值衡量识别算法对目标数据集的适合度。在异常检测算法的研究中,学者们着重评价全局的效果。因此在本文实验中,使用AUC作为衡量模型的重要因素。
3.3 代价敏感性处理
在异常检测领域,模型会存在将良性样本判断为恶意样本的问题。但是,出现模型将恶意样本判断为良性样本的问题更为严重。因此,从表5中可以看出,伪阳性值越小越好。根据表6发现,良性的精确率和恶意的召回率是由FP计算出。所以,在计算时存在FP的公式需要考虑更大的权重因素。本实验通过加权平均来评估精确率。由于良性样本的数量较多,加权平均的精度率会偏向良性流量。同时,本文选择宏平均计算召回率,这可以确保在计算召回率时更少的恶意流量样本,仍然获得更多的权重。

表5 评价系数1

表6 评价系数2
因此,根据式(3)使用加权平均精确率(WP)和宏平均召回率(MR)来计算F1。

3.4 阈值选择
以往KNN算法,使用异常得分的后10%作为离群的异常值,即阈值设置为10%的置信区间的横坐标点。本文采用验证集设置阈值。根据图5(a~c),本次实验在 CICIDS2017、NSL-KDD 和 UNSWNB15这3个数据集上,分别设置的阈值是0.025、0.05和0.19。根据表7可以发现,使用改进后的阈值效果更加出色。尤其是在CICIDS2017数据集上,原有选取阈值的方法不能检测恶意流量。通过采用改进阈值的方法,KNN达到一个很好的性能。从图5(b)来看,恶意流量除了在左侧有一个峰度难以区分以外,其他都可以很好地识别出来。
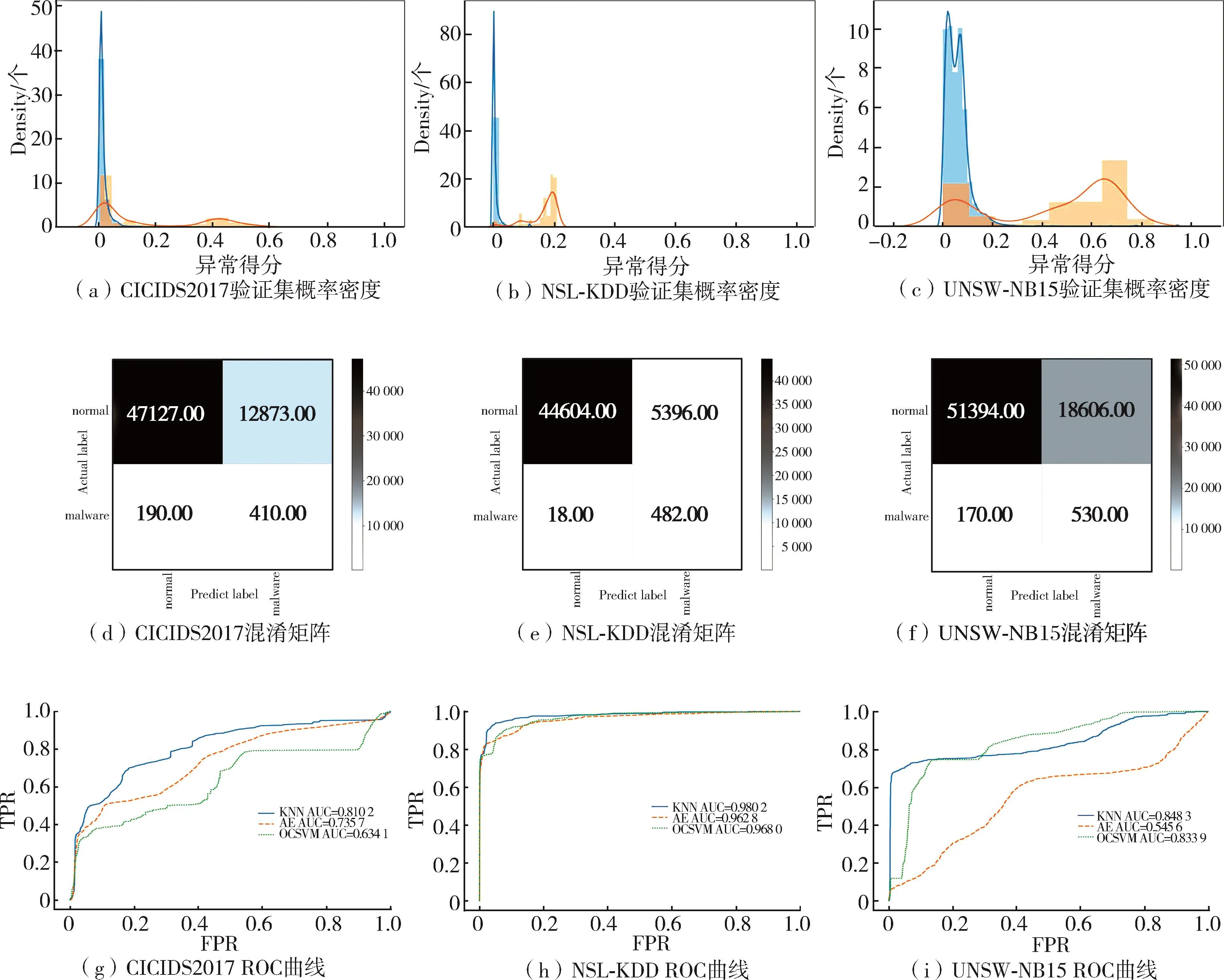
图5 各类数据集的效果

表7 阈值表现评价
最后通过混淆矩阵图5(d~f)可以看出经过改进的KNN算法能够很好地检测异常流量,为系统提供报警服务。在UNSW-NB15数据集上,模型能够识别530条恶意流量,170条恶意流量被忽略;CICIDS2017数据集中的410条恶意流量被模型识别,但仍有190条被遗漏;在NSL-KDD数据集中有482条流量被模型识别,效果最为显著。从表7可以看出,NSL-KDD数据集流量较为简单,并不复杂。所以模型在原始和改进阈值下,两者效果并没有特别大的差异。另外两个数据集经过改进阈值选择方法后,效果得到显著提升。最后本次实验使用NSLKDD测试集画出箱线图,如图6所示。在左列中正常流量的异常得分较低。右侧则展现出恶意流量异常得分的分位线比左侧正常流量高。由此可以看出,KNN能显著检测异常流量。

图6 NSL-KDD测试集异常得分箱线图
3.5 测试集结果对比分析
通过3种不同类型的异常检测模型在NSLKDD、UNSW-NB15和CICIDS2017数据集上的测试对比,由图5(g~i)可以看出,KNN模型在这3类基准数据集上都有很好的效果。在NSL-KDD数据集上,KNN算法相比AE和OCSVM,其AUC值仅仅高出约0.01,两者差距不大,并不能凸显KNN算法的优越性。由于NSL-KDD数据集构建时间较早,当时的网络流量较为简单,该数据集的流量不具有当前网络的时效性。因此,每个模型都能学习到其特征,可以达到较好的效果。但是在 UNSW-NB15和CICIDS2017这两个数据集上,本文算法则展现出强大的性能。
UNSW-NB15数据集是一个相对较新数据集。其中的流量种类也会更加丰富。在该数据集下,KNN和OCSVM都取得比较好的效果,但是AE表现却差强人意。AE从模型上来说仅仅是维度的压缩和解压缩,因此遇到未知的流量效果不一定好。
CICIDS2017数据集是3个数据集中最新的数据集,同时也是规模最大的数据集。在此数据集上,充分显现出不同模型的特点。AE作为深度学习模型在数据量特别大的情况下,依然还有一定成效。AE对比KNN算法的AUC值降低0.074 5。OCSVM效果最糟糕,说明该算法不适用较大规模的数据。
从表8可以看出KNN在CICIDS2017数据集上有着很好的准确性。尽管在F1指标上,与AE模型相比,少了0.022 8,但是在3类数据集上都保持较高的水准。由于AE的神经网络结构是由图像迁移到网络流量中,从UNSW-NB15的数据集中可以看出该模型的不稳定性,因此未必适合网络流量。反观OCSVM算法,在NSL-KDD和UNSW-NB15这两个数据集上效果不错,而运用到较大规模的数据集上,该算法的性能就会被限制,因此该算法也不适用于网络流量异常检测。实验结果表明,KNN算法在检测异常网络流量方面效果更优。

表8 3种算法在3类数据集中的表现评价
3.6 算法效率对比
随着基于人工智能的网络安全技术广泛运用,模型的轻便性也受到人们的关注。本文在考虑算法效果的同时,也对每一类算法在不同的数据集上做了效率评估。对每个数据集,都采用同样大小的数据让不同的模型进行训练,以此来检测不同模型所需要的时间。从表9来看,KNN在每个数据集中,相较于其他模型用时最少,效率最高,更加适合网络流量。
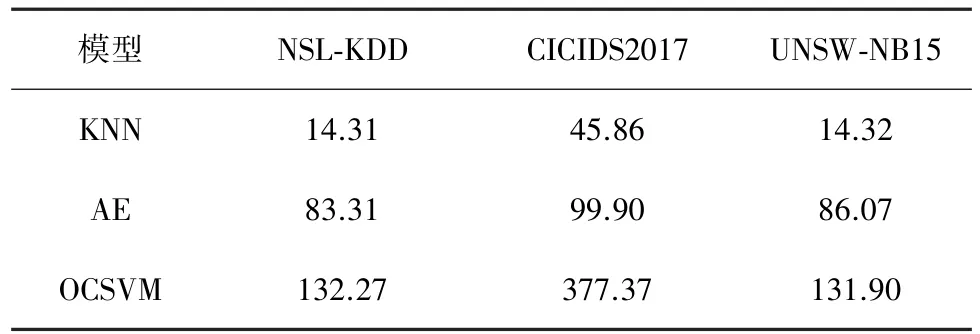
表9 模型时间参数 s
4 结束语
本文提出了一种改进的KNN算法来解决在网络流量结构复杂的环境下未知流量检测的问题。由于现网环境中捕获标记恶意流数据集具有挑战性,因此本文提出的无监督算法不需要数据标记,直接使用数据集进行训练,降低标注成本。通过实验证明,该算法在公共入侵检测数据集 NSL-KDD、UNSW-NB15和CICIDS2017上表现出比AE和OCSVM更高的性能。
然而,基于流的无监督检测算法研究还很少且不成熟。在本文中,无监督算法虽然取得了一些成绩,但仍有很大的改进空间。未来,在改进入侵检测模型方面,实验可以增加其他真实网络的流量数据集,以印证算法的泛化能力。例如,模型放入工业环境中,通过工业内复杂的网络环境鉴别其可靠性。同时,在精确率方面,尝试寻找更适合网络流量的深度学习模型,可以让其更好地学习正常流量的多维分布,以达到提高检测异常网络流量精确率的目的。
