面向不均衡样本空间的工件表面缺陷检测方法
2022-05-20刘佳刘孝保阴艳超孙海彬
刘佳,刘孝保,阴艳超,孙海彬
(昆明理工大学 机电工程学院,昆明 650500)
工业作为国家经济的重要组成部分,工件质量检测是工业生产的重要工序,而工件表面缺陷检测作为该工序的重要工作之一,对工业产品的使用性能、外观性能与舒适性能有着极大的影响[1]。近年来,针对工件表面缺陷检测,主要有传统检测方法与机器视觉检测方法。其中传统检测方法主要通过人工实现对工件表面上的缺陷检测,然而人工检测抽检效率低下、准确率低、实时性差、效率低下、劳动强度过大、对检测人员经验要求较高、且易受主观性影响[2];机器视觉检测主要有传统数字图像处理检测方法与深度学习检测方法,机器视觉检测具有无接触性、无损伤性、客观性、效率高的特点。针对传统数字图像处理检测方法,针对太阳片表面数字图像,利用一维傅里叶变换构建缺陷列在小波域中的欠定方程,通过内积比较高频系数大值位置,实现图像中线型与点型缺陷的检测[3];利用改进的阈值迭代法实现缺陷特征的分割,结合分割图像与轴件表面缺陷特征模型,利用深度信息完成缺陷信息重构,消除水渍类伪缺陷[4];利用各向异性扩散模型消除伪缺陷,建立威布尔分布模型提取可靠背景,确定自适应阈值分割缺陷,完成对钢材表面缺陷的检测[5];通过激光扫描捕获光学元件表面图像,利用纹理分割完成表面缺陷轮廓特征的提取,结合角点监测算法完成对其表面缺陷的检测[6]。上述传统数字图像处理检测方法针对表面缺陷检测中,均存在缺陷背景单一、鲁棒性低、特征学习能力弱等问题。针对基于深度学习的表面缺陷检测方法,使用Adaboost级联分类器提取木材表面缺陷区域候选框,使用大量样本完成CNN模型的训练,完成对候选框的缺陷分类[7];构建实例层次特征卷积神经网络,利用不同卷积层生成特征缺陷掩膜图,随后利用全卷积网络实现各级卷积特征的提取与缺陷的识别[8];首先利用高斯滤波完成图像噪声的去除,随后建立深度CNN,通过利用CNN模型与特征字典实现图像重构与特征提取,通过图像分割确定缺陷位置[9];改进Mask RCNN模型,结合特征金字塔与深度卷积神经网络,利用区域建议网络生成回归框,随后完成分类[10]。常用的基于深度学习方法针对表面缺陷检测时,需要大量训练数据,样本数量丰富,类内分布均匀,才能使得CNN模型具有较好的鲁棒性与学习能力,然而在工业样本采样中,由于场景特殊导致样本采样困难,获取代价昂贵,且样本场景重复性大,场景单一,样本空间呈现小样本、非均匀状态时,由于样本数据单一且不足,特征背景不够丰富,增加CNN模型深度与训练次数会加重学习过程的过拟合现象,且模型鲁棒性较低。
针对上述基于传统检测方法对工件表面缺陷识别效率低下、准确率低、主观性强问题,基于机器视觉检测方法对非均匀小样本数据造成的模型过拟合,鲁棒性差问题。本文针对上述工件表面缺陷检测中存在的问题与研究现状,构建了一种基于样本空间均衡化的工件表面缺陷检测模型。该模型集成了基于图像融合与图像修复的样本空间均衡化结构,并融入基于残差结构的注意力机制,形成了包含样本空间均衡化与缺陷检测的模型结构,重点解决了在工件表面缺陷检测中,由于工业采样样本空间中的非均匀、小样本空间特性所导致的检测模型训练过程难以拟合、识别精度不足、鲁棒性低问题,为工件表面缺陷检测中的小样本、非均匀样本空间的检测模型构建提供了一种新的思路与方法。
1 工件表面缺陷样本分析
工件缺陷检测是工件加工过程的重要环节,而表面缺陷位于工件外部,可以通过图像的方式获取其特征,工业图像样本在初期采集过程中,由于工件取样环境复杂,生产工艺繁多,光线不均、背景不一等因素的影响,导致采样困难,且样本质量参差不齐,不同缺陷由于成因不同,采集难易程度差别较大,使得工件表面缺陷采样样本的空间分布呈现非均匀、小样本状态。综合上述因素使得工件表面缺陷样本具有以下特征。
1.1 样本空间分布特征
工业图像样本中由于小样本作为少数类样本与多数类样本数量比例相差过大,导致样本空间分布呈非均匀、小样本空间特征。非均匀即数据内类不平衡,标签数量比例相差较大;小样本即样本数量少。由于通过CNN构建的缺陷检测模型是通过对输入数据的反复训练与学习,因此模型的最终检测效果取决于样本质量的好坏,样本内类分布不均会导致CNN检测模型在参数更新的过程中偏向高比例样本,而低比例样本则无法完成有效的模型训练,导致检测模型失效,而样本空间的小样本空间状态将会使得训练数据严重不足,模型产生过拟合,且鲁棒性低。因此,本文通过均衡化采样使初始样本中少数类数量增加、各类样本分布均匀。
1.2 缺陷样本图像特征
图像特征主要有颜色特征、形状特征、纹理特征与空间关系特征这4类。而工件表面缺陷由于其生产环境复杂多变、工艺繁多、采样环境恶劣因素,使得缺陷样本在图像特征的4类表征上有着如下特点:对于颜色特征,缺陷特征部像素点变化明显,但其像素色彩直方图占比相差较大,非缺陷特征与特征背景占比较大,特征区域像素点空间相关性强;对于形状特征,同类缺陷轮廓特征与区域特征具有较大相似性,可以通过常用形状特征描述方法边界特征法、几何参数法、傅里叶描述子、形状不变矩对其典型特征完成描述,而非缺陷背景,形状特征更加突出易学习;对于纹理特征,二维图像在对三维表面完成的反映过程中,不能清晰反映真实纹理,只能通过图像像素点位置三通道数值的变化得以局限性表示;对于空间关系特征,缺陷特征在工件表面分布的随机性与图像样本的预处理方式,使得其特征旋转、缩放、镜像等相关操作对空间关系特征造成极大影响。工件表面缺陷图像特征的不确定性与非缺陷区域的特征突出性,导致样本在构建检测模型时所受无关区域特征影响大,无法更好的学习缺陷特征。因此构建基于残差机制的注意力分类模型,提升模型训练过程中对特征的学习权重,增强模型的分类能力。
2 基于样本均衡化采样的缺陷检测模型
提出的基于样本空间均衡化的缺陷检测模型,重点解决工件表面缺陷检测中的由于小样本作为少数类样本与多数类样本比例相差过大导致的样本空间不均衡问题,以及复杂图像背景样本使得模型对特征的学习能力不足问题,提升模型对工件表面缺陷检测的场景适应性与特征学习能力,模型结构如图1所示。
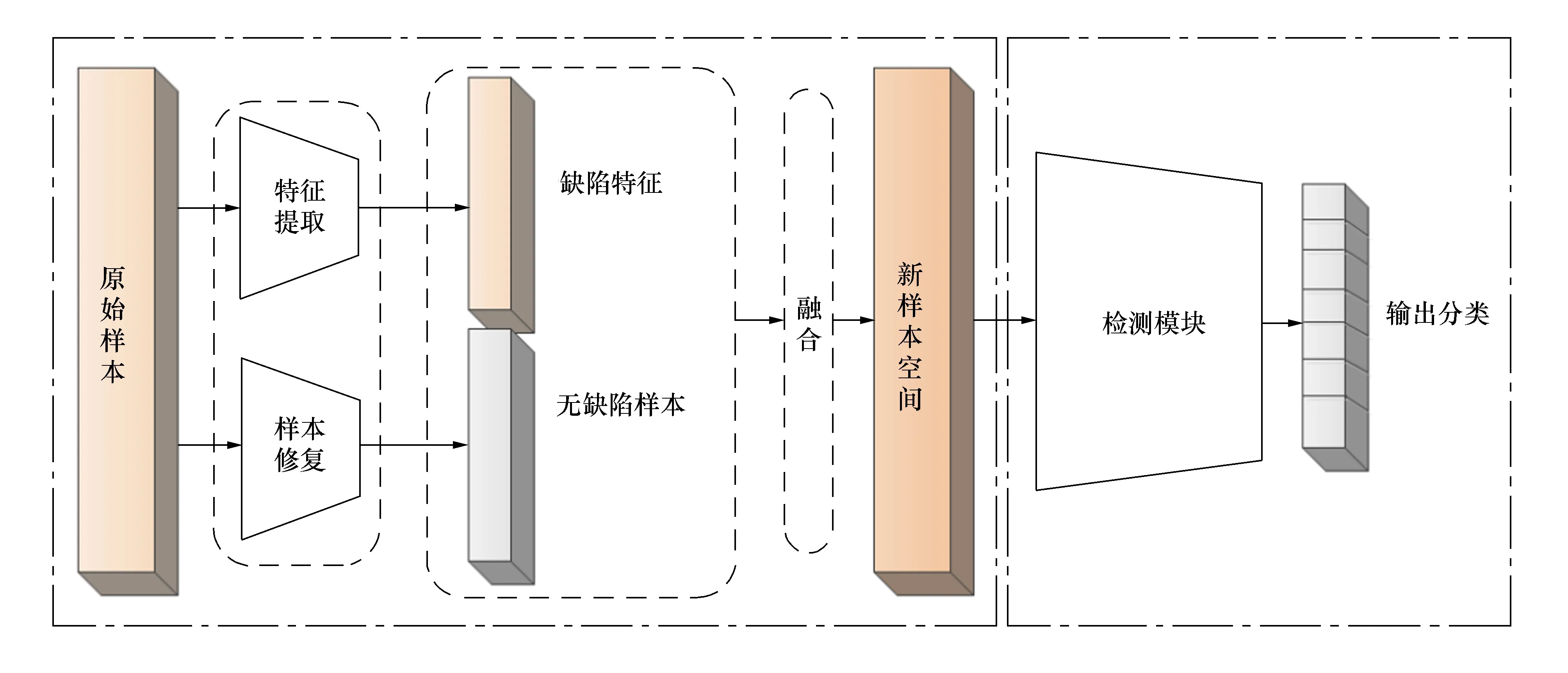
图1 基于样本均衡化采样的缺陷检测模型(SSE-D Model)
该模型主要分为两个部分,包括样本空间均衡化采样模型SSE Model(Sample space equalization sampling model)与缺陷检测模型A-C Model(Attention-CNN model)。其中SSE Model负责完成样本空间的均衡化,将原始样本作为模型输入,实现小样本数据的丰富与内类样本的均衡,生成新样本空间;缺陷检测模型A-C Model利用SSE Model生成的新样本作为输入数据完成模型的训练,用于实现工件表面缺陷的检测与分类。
2.1 样本空间均衡化采样方法
由于工件缺陷样本的小样本、非均匀空间状态使得检测模型构建失衡,因此需要对原始样本空间均衡化采样,以保证样本质量,通过SSE Model实现样本均衡化,模型结构如图2所示。该模型由3层结构组成,首先样本数据作为输入层负责数据输入;数据处理层为并行结构通路,分别完成样本的缺陷提取与样本修复;数据融合层用于对样本中的非均匀、小样本数据完成样本生成,实现样本空间的均匀化,丰富样本场景,并将均衡化后的样本数据作为此模型输出与缺陷检测模型A-C Model输入。
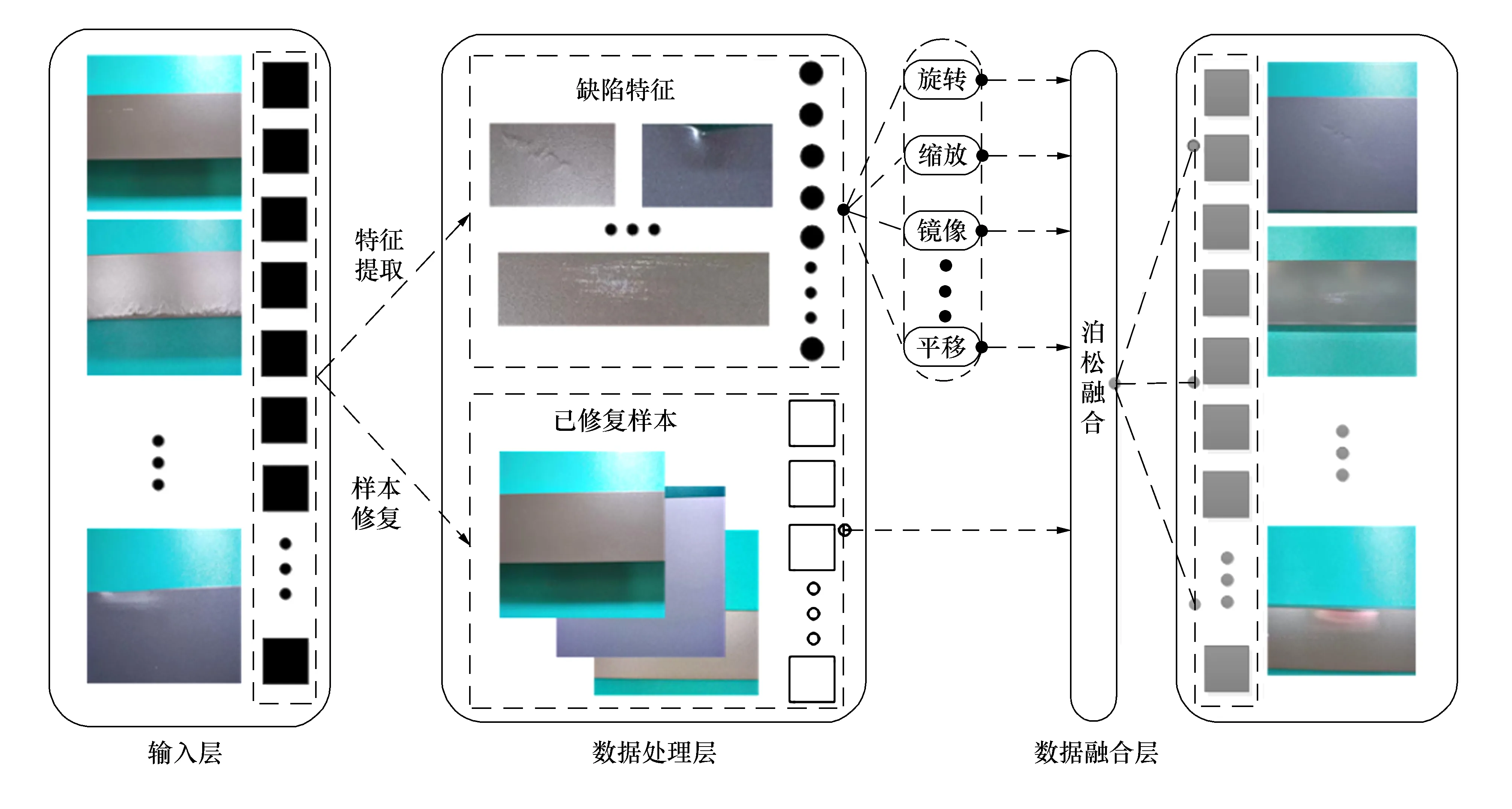
图2 样本均衡化采样方法(SSE Model)
2.1.1 样本修复
样本修复是对样本中存在的不符合正常样本数据分布的噪声数据实现替代与修复,使得数据分布特性更加接近自然数据[11]。在SSE Model中,数据处理层的下行通路为样本修复模块,通过对输入层样本数据完成图像修复,用以获取无缺陷样本,为数据融合层提供丰富的无缺陷特征背景。
由4类缺陷样本(擦花、凸粉、碰凹、漏底)特征分析可知,针对擦花、凸粉缺陷,其缺陷区域离散不连续,可视为单个微小缺陷集合,因此适用于快速行进法[12](FMM)完成区域样本修复,样本修复主要针对缺陷样本中的少数类样本,而擦花、凸粉缺陷作为主要的少数类样本。着重使用快速行进法完成样本修复,其中针对碰凹与漏底此类连续大区域样本修复,通过基于纹理合成结构的criminisi算法完成样本修复,由于少数类样本作为主要修复与合成目标,而漏底作为多数类样本,不需要生成新样本实现原始样本的数据扩增。因此,本文主要描述了快速行进法对文中少数类样本的修复,修复原理如图3,样本中包含缺陷区域Ω,缺陷区域边界∂Ω。Bε(p)为∂Ω上点p的固定半径邻域,q为Bε(p)内部一点,Bε(p)内部像素点加权平均用以估计p点像素值,藉此完成对p点的修复。

图3 样本修复原理图
FMM完成对缺陷区域的修复实际为对缺陷区域像素点求解Eikonal方程
|T|=1
(1)
式中T为缺陷区域内部点到缺陷区域边界点的距离。
由图3可见,样本图像中的像素点可分为3类:
1) 边界点。即∂Ω上的点,其T值正在被处理,即像素点正在修复中;
2) 已知点。即样本∂Ω外部点,其T值已知,像素值与灰度值已知;
3) 内部点。即缺陷区域内部点,其T值未知,像素值与灰度值未知。
令D±x、D±y分别为x与y方向的差分,差分方程的稳定解为
max(D-xT,-D+xT,0)2+
max(D-yT,-D+yT,0)2=1
(2)
式中:
D-xT(i,j)=T(i,j)-T(i-1,j);
D+xT=T(i+1,j)-T(i,j);
D-yT(i,j)=T(i,j)-T(i,j-1);
D+yT=T(i,j+1)-T(i,j)。
通过上式完成样本缺陷区域内部点到边缘的距离T,根据T值从小到大的顺序完成缺陷区域的修复,直到缺陷区域所有像素点完成修复。
由于样本空间中小样本作为少数类样本与多数类样本比例相差过大,因此样本空间均衡化采样主要通过平衡样本数量比例与增加原始样本数量。因此在SSE Model数据处理层的上行通路中需要对样本的特征完成提取,获取工件表面缺陷特征,为数据融合层提供特征前景。
2.1.2 特征判断与提取
针对样本中的表面缺陷特征的判断与提取,由于样本无关背景环境影响过大,其中环境影响因素主要包括非工件区域占比过大,不同区域特征差别明显,图像亮度不均衡,通过普通数字图像处理方式难以完成缺陷特征区域的精确提取,因此首先需要完成对样本的预处理裁剪,去除大量无关环境影响,获取包含缺陷的铝型材载体,由于铝型材质地光滑且纹理均匀,样本缺陷在主要的4类图像特征(颜色、形状、纹理、空间关系)中与铝型材正常表面有着较为明显的区别,因此通过迭代法阈值分割算法,获取样本缺陷区域最优分割阈值,完成对样本中缺陷特征的判断与分割提取,特征提取流程见图4。

图4 缺陷特征提取
迭代法阈值分割在对预处理裁剪后的缺陷样本完成特征分割具有一定的自适应性能:
1) 首先设定参数T0,计算缺陷样本的最大灰度值Zmax与最小灰度值Zmin,令初始估计阈值T1=(Zmax+Zmin)/2;
2) 随后利用T1完成样本的分割,将缺陷样本分割为两部分(G1、G2):G1为灰度值大于等于T1的所有样本像素,G2为灰度值小于T1的所有样本像素;
3) 完成对G1、G2所有像素点的平均灰度值计算(μ1、μ2),并计算新阈值T2=(μ1+μ2)/2;
4) 如果|T2-T1| 2.1.3 样本均衡化 本文通过图像融合的方式完成样本空间均衡化。在SSE Model中,数据处理层输出已修复样本与缺陷特征作为数据融合层输入数据,利用泊松图像编辑[13]完成缺陷特征与已修复样本的融合,并通过对缺陷特征完成旋转、缩放、镜像、平移等单样本数据扩增处理,在不添加无关噪声的情况下实现工件表面缺陷样本中小样本数据的扩增,丰富特征背景,完成样本的均匀化与扩增等空间优化处理。 数据融合层相关公式为 N-di,j=poisson(Ni,Xj,p) (3) 式中:N-di,j为融合后新样本;poisson表示泊松方程,poisson:Δf=Ω,Δ代表拉普拉斯算子,即图像在直角坐标系中的二阶微分(散度),Ω为通过输入参数获取的已知量(本文中的无缺陷背景Ni、缺陷特征前景Xj、融合位置参数p);Ni(i=1,…,n1,n1为无缺陷样本数量)为经过数据处理层下行通路样本修复后的无缺陷样本作为融合过程中的无缺陷背景;Xj(j=1,…,n2,n2为缺陷特征数量)为经过数据处理层上行通路特征提取后的缺陷特征作为融合过程中的特征前景;p为融合过程中的位置参数,即样本融合中心点。 样本空间均衡化完成后,需要构建缺陷检测模型学习新样本,在对工件表面缺陷检测的过程中,由于采样环境、光线、背景等相关因素造成图像内部非缺陷特征丰富,无关图像特征占比大,常规卷积神经网络检测模型提取图像全局特征,缺乏对相关缺陷的识别能力,因此利用注意力思想提升网络对相关缺陷的学习权重,并基于残差结构,构建深度学习模型,完成对工件表面缺陷检测模型的构建(A-C Model),模型结构如图5所示。 图5 缺陷检测模型(A-C Model) 2.2.1 分类神经网络构建 为了完成对工件表面缺陷的分类检测,构建了一个分类模型(A-C Model),如图5所示。图中数字分别表示特征图像的尺寸与维度,模型总体结构为:输入层输入尺寸为300×300×3的目标图像,通过利用卷积结构(Conv+BN+Relu)、残差注意力结构(Res-Attention)与最大池化结构(Maxpool)的反复堆叠,对图特征完成提取,获取特征图像。其中,卷积结构中卷积核尺寸为3×3,步长为1,卷积模式为same,卷积过后使用批量归一化(BN)与激活函数(Relu)完成非线性激活;残差注意力结构中卷积核尺寸为1×1与3×3,步长为1,卷积模式为same,残差网络结构内嵌注意力机制;最大池化结构池化窗口尺寸为2×2,反复堆叠上述结构,扩大高维特征图中特征感受野尺寸,整合图像中特征信息,直到获取的特征图形状为14×14×64,最后使用两层全连接实现类别的输出,第一层全连接层128维,并通过丢弃率0.5的Dropout实现随机半数神经元的丢弃用以避免网络过拟合,第二层全连接层作为分类网络输出层,神经元个数取决于输入样本数据的类别。 2.2.2 基于残差机制的注意力模型 为了使分类网络在学习过程中更多的拟合目标缺陷特征,并放弃无关特征,本文采用基于残差结构的注意力模型(Res-Attention)实现分类网络中主要的特征提取。 由于缺陷样本中存在大量的非缺陷特征,即图像内无关特征像元占比大,使得分类网络在学习过程中更多的拟合像元占比更大的无关特征,不能充分学习到更加重要的缺陷特征,注意力机制在特征图的获取中为特征赋予不同的权重,使得网络参数更新中更多的学习目标区域,残差网络通过逐层残差学习的方式使得构建深度网络并仍然能取得学习效果。本文基于残差网络中的Resnetv2[14]与空间通道注意力结构[15]构建残差注意力结构,Attention结构如图6所示。 图6 空间通道注意力机制(Attention) 对特征图串行使用空间与通道注意力机制,其中通道注意力模块对每个通道上的全局特征图分别取最大池化与平均池化操作,空间注意力模块对特征图上每个位置的全部通道分别取最大池化与平均池化操作,将通过空间与通道注意力模块获取的带有不同权重的矩阵按照先后顺序依次与输入特征图相乘,输出带有空间与通道权重的特征图,计算公式为: Mt(F)=σ(MLP(avg(F))+MLP(max(F))) (4) Mk(F)=σ(f7*7([avg(F);max(F)])) (5) F=Mk((Mt(F)*F))*F (6) 式中:Mt(F)表示通道注意力权重矩阵;σ表示激活函数;MLP为共享全连接操作;avg与max分别为平均池化与最大池化;Mk(F)表示空间注意力权重矩阵;f7*7为卷积核大小7×7的卷积操作。 通过使用Resnetv2结构模型并嵌入Attention机制作为检测模型中的Res-Attention模块,将Attention模块放置于旁路末端,旁路三次卷积操作获取特征图,随后利用注意力机制生成注意力模板为特征图加权,如图7所示。 图7 Res-Attention结构示意图 为验证面向不均衡样本空间的工件表面缺陷检测方法的有效性。本文以铝型材常见缺陷数据集作为样本数据,选择其中的4类常见缺陷数据(擦花、碰凹、漏底、凸粉)以及表面无缺陷,共5类标签(擦花、碰凹、漏底、凸粉、无缺陷)。经手动修正数据标注错误后,获取擦花26张、碰凹20张、漏底140张,凸粉64张、无缺陷42张,共292张原始样本数据,类间最大比例1∶7,符合不均匀样本空间特征,样本示意图如图8所示。 图8 5类样本示意图 基于上述的5类标签样本,经实验验证,原始样本的小样本与非均匀状态会影响模型拟合与训练结果[16-17],因此将上述样本原始数据使用数据扩增方法分别扩增至400张以实现样本类间比例1∶1的均衡状态,5类样本共2 000张图像,样本划分为训练集、验证集、测试集(8∶1∶1),训练过程利用文件名作为分类标签,使用正则表达式分割标签,训练中随机打乱数据保证训练过程的稳定状态。 1) 本文方法(SSE-D)。通过对上述5类样本中的4类缺陷完成样本修复与特征提取,获取无缺陷样本用以扩增均衡第五类无缺陷类样本,随后通过对无缺陷样本与缺陷特征的融合采样,对原始样本中的擦花、碰凹、凸粉实现数量均衡化; 2) 随机过采样(ROS[18])。过采样是通过创建新的少数类样本用以消除偏态分布,通过随机过采样(ROS)随机复制少数类样本实现样本内类数据的均衡化; 3) 随机欠采样(RUS[19])。欠采样是通过对多数类样本的随机移除以消除偏态分布,通过随机欠采样(RUS)随机移除多数类样本实现内类数据的均衡化。 表1 实验数据统计 以个人计算机作为硬件平台,利用TensorFlow平台作为深度学习后端,Python3.7.4作为编程语言实现本文方法与分类神经网络的训练,神经网络初始参数设置如表2所示。 表2 神经网络参数设置 为客观评估本文方法有效性与可行性,利用文献[18-19]中所用对比方法ROS与RUS实现样本的均衡化采样,并将两种方法实验结果与本文方法实验结果完成对比。准确率变化见图9,具体结果如表3、表4所示(1-擦花、2-碰凹、3-凸粉、4-漏底、5-无缺陷)。 图9 网络测试结果 表3 不平衡数据采样方法标签分类对比结果 表4 不均衡数据采样方法分类对比结果 本文通过3种采样方法完成样本空间的均衡化采样操作,而原始样本空间呈现不均衡状态,因此利用准确率、精确率、召回率与F1值、单类标签分类结果,实现全方位、多角度综合评判模型性能指标,F1值作为平衡精确率与召回率的性能指标,对不均衡样本空间有着较优的评价效果,本文方法在F1值上与ROS、RUS分别有着2%与10%的提升效果,是由于本文通过丰富样本背景,增加了样本的多样性,使得模型更加鲁棒,在对每一类样本的分类中效果更好,并且由于样本采样后是类分布均衡空间,因此准确率也可以作为模型总体分类效果评价指标,本文方法在准确率上与ROS与RUS方法分别有着2%与11%的提升效果,单类标签分类结果可以具体表达单类样本在使用不同采样方法后的具体分类效果,具体结果由表3可知,针对擦花、碰凹两类主要的少数类缺陷,本文方法分类准确率高达100%,而ROS与RUS两种方法均远低于本文方法,通过少数类单类样本准确率的大幅提高,实现总体分类效果的提升,且本文方法对模型的拟合能力也有着大幅提升,由图9网络测试结果可知,本文方法模型学习能力远高于ROS与RUS,训练过程收敛快速且稳定,准确率无剧烈跳动变化,可以看出,本文构建的分类模型,在完成样本空间的均衡化采样之后,使用注意力机制得以更好的学习模型特征,并且对特征背景的适应性更强,ROS与RUS方法在针对不均衡样本的分类任务时,ROS方法简单复制大量少数类样本会使得模型产生过拟合问题,而RUS在样本比例相差过大的情况下删除大量多数类样本使得模型丢失重要分类信息问题,本文方法在各个指标上的提升,证明了本文所提方法相较于传统方法在面对不均衡样本空间时能够更好的提升模型的鲁棒性与分类效果。 针对工业表面缺陷检测中的不均衡样本空间问题,基于样本空间与分类模型两个角度,构建基于样本均衡化采样的缺陷检测模型,通过实验对比,验证了本文方法与常规两种不均衡数据采样方法相比,通过融合的方式平衡少数类样本并藉此生成新样本空间,能够实现更好的数据空间均衡效果,提升了模型的学习能力与分类准确率。在下一个研究阶段中,计划利用少数类样本特征背景的数据概率分布,进一步优化本文的样本空间均衡化采样方法使得样本空间分布更加接近自然数据,提升模型的使用性能。2.2 缺陷检测模型



3 实验分析

3.1 实验数据准备

3.2 实验环境搭建与网络构建

3.3 实验验证与结果分析



4 结论
