基于双向树多模态融合谣言检测方法的研究*
2022-05-19李进明王竹君
马 含,李进明,王竹君,关 威
(1.菏泽学院计算机学院,山东 菏泽 274105;2.山西财经大学信息学院,山西 太原 030006)
引言
社交媒体的迅速崛起,极大方便人类交流的同时也带来诸多社会安全隐患.由于网络体系缺乏有效的管理制度,导致谣言正在加重社会的信任危机.引导正确的舆论走向和营造积极健康的网络环境已成为关注的焦点.当前,信息交流已不再是纯文本的形式,丰富的音频、视频更能吸引眼球.一些短视频正是利用视觉、听觉来混淆视听,发布篡改后的不实讯息,传播谣言.为此,挖掘视听觉多源信息有助于对谣言进行预测.陈志毅[1]等人针对文本内容、图像以及用户属性的多模态网络谣言检测;刘中山[2]针对早期的谣言结合多个角度的特征提出基于LSTM的模型检测;李莎[3]等人针对网络谣言建立一个多层次编码器,输入文案和视觉图像,构建向量嵌入层,由大精度拆分为小精度,细化获取事件特征;张少钦[4]等人融合文本和图像特征,进行基于注意力机制的拼接完成多模态谣言检测.岳晨晨[5]等人从图像特征与多特征自适应融合两个方面开展研究,发现其算法适应目标在复杂背景中的运动,可有效提升算法性能;杨腾飞[6]等人利用图像关联信息从冗余图像信息中提取特征,也得到了部分成果.
本文提出一种基于双向树多模态融合谣言检测方法,使用预先训练好的模型得到数据的向量化,构建端到端的神经网络,以双向树完成文字与图像间的信息提取和转换.然后将提取后的特征输入全连接层,同时多模态拼接进行检测训练.整个流程可分为词嵌入处理与图像捕捉、特征抽取、多模态融合、检测分类等.
1 谣言检测的算法
1.1 特征提取
近几年在谣言检测中对特征提取方面,神经网络取得了不错的成绩,以 LSTM为代表的 RNN 网络有较强的特征提取能力[7],基于谣言检测的特性,本文将LSTM 网络作为特征抽取的网络结构.第一,事件的发酵存在时间序列,采用LSTM可保存内容位置;第二,LSTM自身有门控制,可有效避免出现上下文联系断层,词意不明确等问题.
LSTM[8]在RNN基础上增加一个状态,用其保存长期的状态,称为单元状态.LSTM有三个输入(当前时刻输入值,上一时刻LSTM输出值以及上一时刻的单元状态)两个输出(当前时刻LSTM输出值和当前时刻的单元状态).另外,社交媒体上的评论以及回复可视为树形结构的子节点与父节点.基于此,本文构建的树形长短记忆神经网络,用于解决三个问题.一是保存长期单元状态,二是将即时状态输入到长期状态单元,三是把长期状态作为当前的输出.考虑到全局上下文信息,将树形网络的传播方向改为双向完成信息的提取.
1.2 多模态融合
多模态特征融合[9]指的是模态与模态之间利用特征维度等相关性完成信息整合,合理利用资源互补解决在其之间存在的信息冗余来达到更高层次的特征融合.目前,深度神经网络已广泛用于视觉、听觉和文本数据,并且在多态领域也有涉猎.数据在训练时,将每个模态数据都分别经过几个单独的神经网络层,然后经过一个或多个隐藏层将模态映射到联合空间,得到联合特征.最后将联合特征再通过多个隐藏层或直接用于最终的预测.这类神经网络模型可通过端到端的训练.
当前在社交媒体流行的不仅是纯文本,更多的是图文并存.调查发现图像会影响事件的检测,基于此,将图像和文本融合以提高谣言检测的准确性.由特征提取获得的词特征和视觉对象特征放入多模态融合模块中,完成信息的传递和融合,最后将更新后的联合特征,用于谣言检测器中进行谣言检测.
2 基于双向树多模态融合谣言预测方法
为解决多态融合方法的局限性,提出一种基于双向树的多模态融合网络,该融合实现词-词层次、视觉对象-视觉对象层次的信息交互.将文本特征与图像对象向量化形成树神经网络,树采用双向传播信息更新获得深度特征提取.图文多元信息经过特征转换与提取输入全连接层,激活谣言检测器进行检测.整个模型结构图如图1所示.

图1 基于双向树的多模态融合谣言预测模型图
2.1 词嵌入处理与图像捕捉
2.1.1 词嵌入处理
在深度学习模型前,需将文本向量化.词嵌入处理是通过映射函数转化为几何矩阵,将文本中的词语合理表述.词嵌入的好坏程度必直接影响任务内容.
将文案进行词分解,这样它可看成是由若干个词语组成的列表.Glove训练方法的本质就是将句子文本映射为矩阵,再利用拆分矩阵句子向量得到词向量.本文使用预先训练的Glove词向量对文案句子进行编码(GRU),利用BERT模型获得词向量.输入文本为T,则
J=GRUT(δGRU)
(1)
W=BERTT(δpretrain)
(2)
式(1),式(2)中,输出句子向量J和词特征矩阵W,δGRU为训练权重,δpretrain为预训练的权重.
2.1.2 图像捕捉
图像可看为由若干个对象组成,将这些对象由预先训练好的模型进行检测提取,对象可以是图片中的一人、一物、一动作甚至是两者之间的交叉.利用 Faster RCNN[10]去获得图片V中的对象,再根据全连接层的特性将维度数调整至与文本词特征矩阵保持一致,最后形成由视觉特征组成的矩阵向量s,用式(3)表示,所获的每一个向量都将成为这幅图片的潜在特征,用作双向树模型的输入量.
s=RCNN(V;δpretrain)
(3)
2.2 基于双向树的特征提取
以LSTM为特征提取架构,把在2.1节中获取的词向量W和视觉向量s作为输入,基于端到端的特点,用二叉树表示模型,其中一个节点可以有很多子节点,每一个节点代表一个完整句或图片.将这个树形结构转换成另一个树形结构时(其中每个节点始终包含两个子树)会创建一致的格式,这对于训练神经网络所需的矩阵运算很方便.在每个树中的节点隐藏层都存在由底向上和由顶向下两种信息传递方式,由底向上传播更新过程如式(4)~(9)所示.同样进行由顶向下更新可得式(10),表示更新后的隐层状态.
(4)
(5)
(6)
(7)
(8)
(9)
(10)

为避免单向传播的局限性,利用各自的权重θ1,θ2创建两个方向上的信息融合.最终的隐层状态hti表示如式(11).
(11)
式(11)中,⊕表示两个更新方向上的交互函数-拼接.
2.3 多模态特征融合与检测
特征融合是指融合不同角度的特征为检测提供更可靠信息.基于2.2节,此时的双向树模型在最终的目标节点中包含全局图文信息,将文本-图像的潜在关系进行建模.由于不是所有的模态都会对谣言检测有利,本文将更新后的视觉特征和文本特征拼接在一起,利用权重矩阵θ1,θ2,在注意力机制下进行自适应权重训练,以增强重要特征的提取力度,获取最终的多模态融合特征.为避免丢失特征表示,注意力权重加1,则融合后的多模态特征F用式(13)表示.为了方便表达,引入式(12)做转置表述.
φ=G1(G2([htiS,htiJ];θ1);θ2)
(12)
F=(φT+1)[htiS,htiJ]
(13)
式(12),式(13)中,G1,G2分别为激活函数Tanh,Softmax.htis,htiJ为最终的句子隐层状态和视觉隐层状态.

(14)
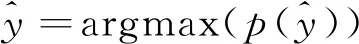
(15)
在训练阶段,模型通过不断更新参数获得最小损失函数,可通过最小化分类损失来优化整个检测过程.本文利用交叉熵计算全局的损失函数loss,定义如式(16).
(16)

3 基于双向树多模态融合谣言检测的实验
3.1 数据集
本文选择在不同的数据集上进行实验.一部分数据来自在文献[12]开源Twitter数据集,将数据集划分为样本集和测试集,对于是否为不实信息已做出说明.一部分来自文献[13]使用的数据集,数据集分为样本集和测试集.对数据进行预处理,剔除反复出现的劣质图像与文案.
3.2 实验设置
实验环境:使用Python编写,在Tensorflow平台上搭建神经网络模型.
对于词向量的嵌入,使用预先训练好的Glove模型,每组词语的维度数设为m,隐藏层数为n,经过端到端网络获取词特征.对于视觉捕捉,使用预先训练的Faster RCNN捕捉视觉对象特征,在这里需要注意的是本文捕捉的图片对象个数必须与词向量的文案长度保持一致,即每一幅图片有m个提取对象,然后利用n个全连接层嵌入特征提取.
在多模态融合过程中,发现训练次数到达100时,交叉熵值基本保持不变,在使用模型训练时最大值设为100,当然如果在训练时模型精度在允许的误差范围内(可自定义,本文设为5个误差)可提前结束训练输出结果.
3.3 实验模型
为了表现本文提出模型的性能,采用不同模型进行对比.
1)单模态:仅使用单一的状态,是纯文本或者纯图像.纯文本:采用纯文本进行谣言检测.依旧采用预先训练的Glove进行词向量的输入,然后输出向量进行信息分类.纯图像:与纯文本相似,只使用图像中的对象作为特征,送入预先训练好的模型中,然后送入到检测模型中进行谣言检测.
2)多模态:文本和图像进行融合.EANN[14]中的文本特征通过 TextCNN模型提取,图片特征使用预训练的 VGG-19 模型提取,直接进行拼接输入全连接层,进行谣言检测.
MVAE[15]采用一种编码-解码的完成多模态特征表达式.
基于文本与图像的潜在联系,利用端到端神经网络的特征构建二叉树进行文本和图像的深度特征提取,两态拼接输入全连接层,进行谣言的检测.
3.4 实验结果及分析
为了表现本文提出的模型具有良好的性能,将本文模型与单一模型在两个数据集上分别做实验,共8组实验.以分类问题中经常使用的评级指标做实验结果对比分析,分别是精确率(预测样本有多少实际是正确的),召回率(实际正确的样本有多少是成功被检测出来的)以及F1值(是前两者的综合,召回和精确的调和平均数).实验结果如表1所示.

表1 单态模型评价指标数值
观察表1,在对比单模态和多模态实验结果中,可以发现纯文本具有更好的F1值.精确率和召回率在融合后的模型有较好的反馈,也证实了图像中那些看似不突出的细节也会影响到谣言的求证,文案与图像两者结合有利于信息互补,得到更优的检测结果.
观察表2,MVAE拥有更好的F1值,进一步说明挖掘模态之间的相关性可有效地提高模型的检测效果.在对比微博和Twitter数据结果时发现Twitter数据中存在一对多的情况,导致具有较低质量的图片特征,而在微博数据中,文案和图片分布均匀.

表2 融合模型评价指标数值
由图2可知,融合方法具有更好的检测结果,性能在检查点为23时基本上趋于稳定,两个数据集上均有所体现.对比这两者发现图片和文案的融合交互会影响最终的谣言检测,也进一步说明双向树可促进不同模态间的有效特征提取,进而提升检测结果质量.

图2 模型准确率图
4 结论
本文提出了一种基于双向树多模态神经网络去检测谣言,基于词语与图片特征存在潜在的联系,从单独模态角度出发,基于双向树更新节点信息,突破传统单向的传播局限性,从两个模态角度出发,更新后的视觉特征和句子特征以自适应的权重完成两者之间的信息融合和交互.通过在两个数据集上进行实验,验证了两个模态进行融合的可行性,在单模态建模时易受到其他模态的影响,说明了探索多模态联合提高检测质量的必要性.
