CEEMDAN和改进多尺度熵的声音信号故障诊断
2022-05-19付国梓
付国梓,吕 勇
(武汉科技大学机械自动化学院,湖北 武汉 430081)
1 引言
随着技术的进步,机械系统的复杂性增加导致系统故障概率增加。为了提高可靠性、降低维修成本和及时采取预防措施,基于声学、振动、涡流、热场和射线照相等动态响应的故障诊断系统已经发展起来。与振动信号相比,声音信号在工业环境中有着非接触式测量的优点和需求,而且声音传感器在高温和腐蚀的环境下有着更突出的优势。振动监测技术需要在指定方向上放置表面接触,以获得准确和有意义的信息,而声音传感器可以被放置在被监测系统的任何方向或外围。其次,采集声音信号过程中可以选取麦克风作为声音传感器,相对于加速度传感器的价格更有优势,因此使用声音信号进行故障诊断非常有意义。
目前有许多针对声音信号的处理方法:文献[1]利用独立分量分析提取了断齿声音信号中的故障特征,由于原始声音信号信噪比较低,独立分量分析分离完的特征信号依旧残留噪声;文献[2]将小波去噪结合有效性评估方法处理声音信号中得到制导信号,然后用制导滤波器对信号滤波降噪,但是小波系数选取会影响制导滤波器的响应曲线使降噪效果不明显;而文献[3]通过决策树降维方法对轴承声音信号提取特征信息并进行分类。行星齿轮箱[4]的声音信号通常表现出非线性非平稳的特性,使用线性的频谱分析方法会被降噪效果而影响[5]。文献[6]提出一种自适应噪声的完全集成经验模态分解(Complete Ensemble Empirical Mode Decom⁃posi-tion with Adaptive Noise,CEEMDAN)用于处理非线性非平稳的声音信号。CEEMDAN 通过消除EMD(Empirical Mode De⁃composition,EMD)和EEMD(Ensemble Empirical Mode Decompo⁃sition,EEMD)中存在的模式混叠问题[7-8],对声音信号进行精确的重构,更利于带有故障特征的固有模式函数分离开来。
近似熵是(Approximate Entropy,ApEn)用来度量时间序列的复杂性和统计量化,并将其应用于生理时间序列分析。而样本熵(Sample Entropy,SE)[9]作为近似熵的精化版本,样本熵的计算不依赖数据长度,并且有很好的一致性,从短数据中获得稳定的熵值,并具有适当的抗噪能力。样本熵将自身时间序列中的数据作为自匹配进行比较,并测量得到的时间序列的新信息,但有时会产生虚假信息。文献[10]提出了多尺度熵(Multi⁃scale Sample Entropy,MSE),分析了多尺度时间序列的复杂性和规律性,并对粗粒化过程进行了多尺度时间序列分析。但是传统多尺度熵会出现粗粒时间序列长度不同和粗粒化过程中数据丢失的情况。为此,提出一种改进的多尺度熵(Improved Mul⁃tiscale Sample Entropy,IMSE),引入平滑粗粒化处理,将IMSE应用于行星齿轮箱声音信号的故障诊断中,并验证了IMSE的有效性和优越性。
支持向量机(Support Vector Machine,SVM)是一种可以解决非线性问题的分类器,通过最大化分离数据之间的裕度来寻找最优的分离超平面。通过构建声音信号的多故障分类器,提出了一种CEEMDAN 和IMSE 的声音信号故障诊断。通过对比EEMD、CEEMDAN、MSE、IMSE之间的比较,实验结果表明,在声音信号识别上,CEEMDAN-IMSE有更高的故障识别率。
2 基本原理
2.1 CEEMDAN算法
CEEMDAN 分解得到的第一个IMF 等于EEMD 分解的第一个IMF,而第一个残差余量r1可以通过添加特定噪声来使每个分解的rk保持不变。CEEMDAN 的详细算法如下,其中Ek( · )定义为第k个IMF的算子,ω(i)定义为均值为零的高斯白噪声:
(1)用EMD 分解x(i)=x+β0ω(i)(i=1,…I),得到第一个IMF分量:

(2)计算第一个残差余量:

(3)用EMD 分解得到第一个IMF 分量r1+β1E1(ωi)(i=1,…,I),则第二个IMF分量为:

(4)对于k=2,3,...,K计算第k个残差余量:

(5)用EMD分解到第一个IMF分量r1+β1E1(ωi)(i=1,…,I),则第k+1个IMF分量为:
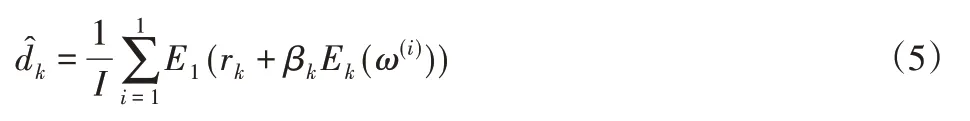
(6)返回步骤(4)并计算下一个IMF分量,重复步骤(4)到步骤(6)直到残差余量不能被EMD分解为止,系数βk=εkstd(rk)允许在每次迭代中选择信噪比,而std(·)是标准偏差算子。
2.2 改进的多尺度熵
对于传统的多尺度熵,粗粒时间序列的长度会随尺度的增大而减小。传统的粗粒化过程不能保证粗粒时间序列的长度不变;当时间序列长度不是尺度因子的整数倍时,粗粒化过程中会出现数据丢失。这两个主要缺点不可避免地影响了MSE算法的准确性和有效性。为了解决这两个缺点,采用平滑粗粒化对多尺度熵进行处理,提出了一种改进的多尺度熵。
(1)设存在一个以等时间间隔采样获得的N维的时间序列u(1),u(2),...,u(N)。
(2)定义算法相关参数m,r,其中m为整数,表示比较向量的长度,r为实数,表示“相似度”的度量值。
(3)重构m维向量X(1),X(2),...X(N-m+1),其中X(i)=[u(i),u(i+1),...,u(i+m-1)]。
(4)对于1 ≤i≤N-m+1,统计满足以下条件向量数:
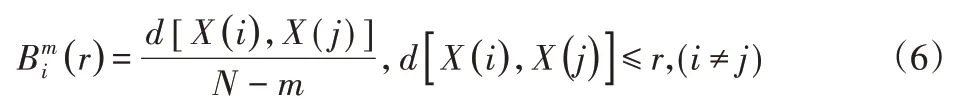
(5)Bm(r)为对所有i值的平均值:

(6)令k=m+1,重复步骤(3)、步骤(4)得:
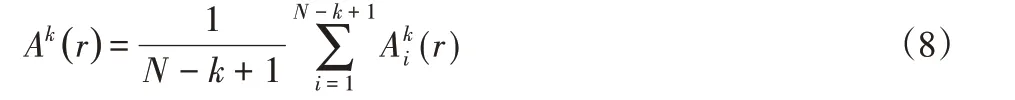
(7)则样本熵定义为:
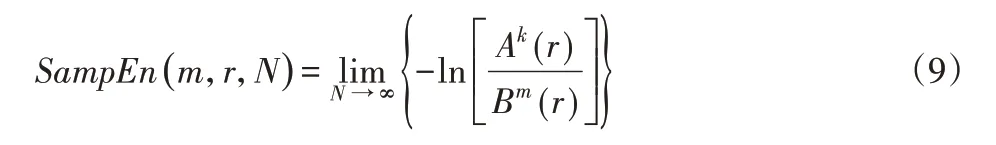
(8)实际过程中N为有限值,则样本熵为:
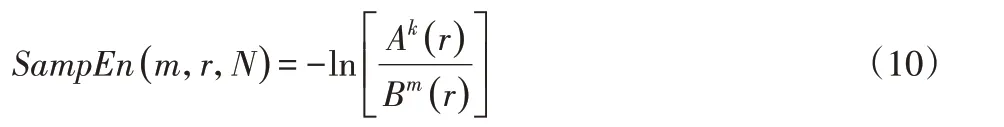
(9)传统多尺度熵对原始时间序列进行传统粗粒化处理:
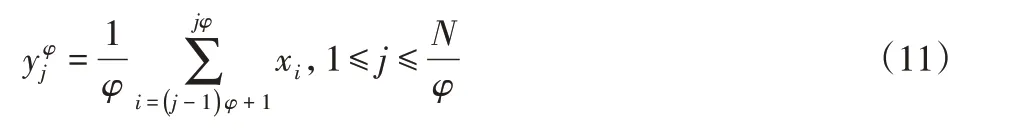
(10)改进多尺度的熵对原始时间的序列进行平滑粗粒化处理:
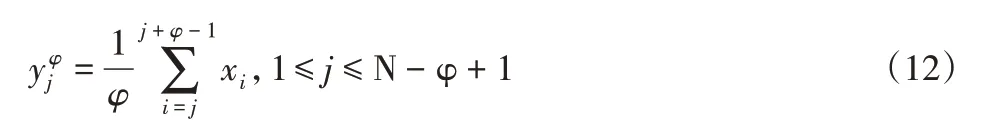
(11)计算每一个粗粒化序列的样本熵,并把它写成尺度因子的函数,则多尺度熵为:
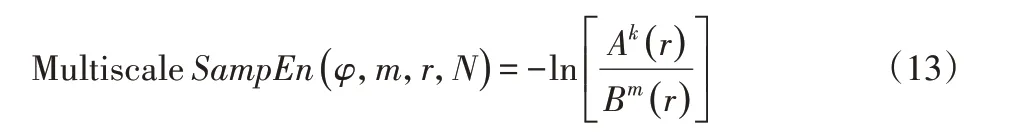
图1、图2显示了根据尺度因子通过两种粗粒化处理压缩时间序列的过程。当尺度因子φ=3时,传统的粗粒化过程,如图1所示。当尺度因数φ=3时,提出的平滑粗粒化过程,如图2所示。平滑粗粒化过程不仅保证粗粒时间序列的相同长度而且避免了数据丢失。
图1 传统粗粒化处理Fig.1 Traditional Coarse Graining Process

图2 平滑粗粒化处理Fig.2 Smoothed Coarse Graining Process
改进多尺度熵参数选择:尺度因子φ一般为(1~20);嵌入维数m一般为(1~5);相似容限r通常选择r=0.1SD~0.25SD,其中SD表示原时间序列的标准差;N为数据长度。
2.3 支持向量机
支持向量机是解决分类和回归问题的一种算法,通过SVM多分类器将多种不同类型的样本进行区分。支持向量机的核心思想是将原始数据空间通过非线性映射转换为高维特征空间。SVM回归的性能在很大程度上取决于核函数参数,所以选择好核函数参数也很关键。为了使行星齿轮箱的声音信号分析具有一般性,结合SVM多分类器对声音信号进行分类[11]。
3 CEEMDAN和改进多尺度熵的声音信号故障诊断方法
综合CEEMDAN 和改进多尺度熵的优势,提出了CEEM⁃DAN 和改进多尺度熵声音信号故障诊断方法,该方法流程,如图3所示。

图3 方法流程图Fig.3 Method Flow Chart
(1)采集正常、磨损、裂纹、断齿这四种声音信号各M组。训练样本M0组,则测试样本为M-M0组。
(2)对所有状态下的声音信号进行分解,得到若干IMF分量。
(3)对原始时间序列采用平滑粗粒化处理得到IMSE。
(4)对部分IMF分量进行量化处理,计算IMF分量的IMSE作为故障特征向量。
(5)将训练样本输入到支持向量机里进行训练。
(6)将测试样本输入到训练好的支持向量机对不同状态下的声音信号进行识别分类。
4 仿真实验
4.1 CEEMDAN仿真
机械运行的声音信号通常具有调频信号的特性,因此利用调频信号来验证CEEMDAN相对于EEMD的优势,行星齿轮箱的声音信号可以简化为调频仿真信号:

式中:f1=30Hz,f2=100Hz,f3=15Hz。s—信号中添加的方差为0.5,均值为0的高斯白噪声。
采样点为2048,采样频率为2048Hz。将EEMD 和CEEM⁃DAN应用于模拟信号,得到EEMD和CEEMDAN的IMF分量时域图和频域图。从图5中可以看到EEMD分解得到了10阶IMF,而CEEMDAN分解得到了9阶IMF,在图6(a)中,f1频率不仅在IMF4中显示,同时在IMF5中也显示,可以明显地看出EEMD分解存在模态混叠问题,且从图5(a)可以看出IMF4中有一定噪声残留;在图6(b)中,有效特征频率被分解到IMF3和IMF4中。通过对比可以得出结论:CEEMDAN比EEMD在改善模态混合问题方面优于EEMD,能够使IMF更精确。因此,CEEMDAN比EEMD可以更适合分解声音信号并提取特征信息。
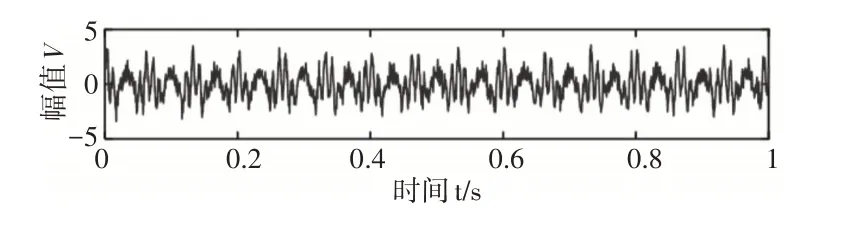
图4 原始仿真信号Fig.4 Original Simulation Signal
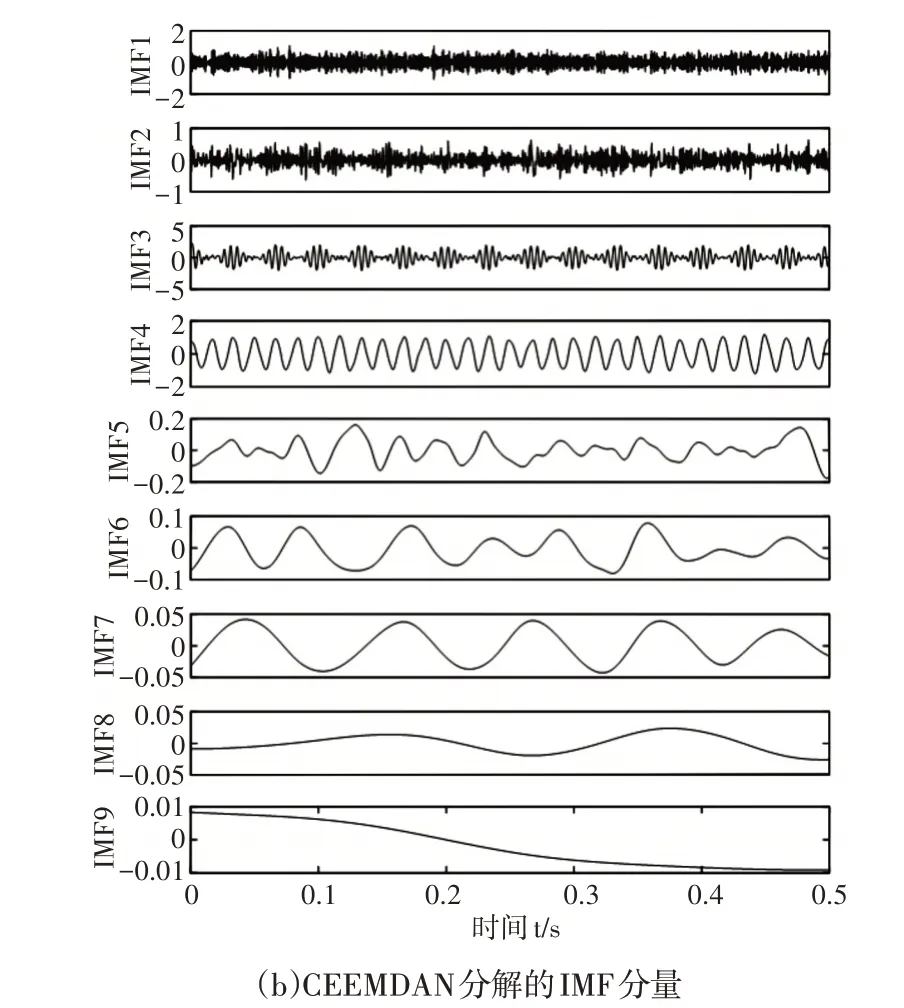
图5 EEMD和CEEMDAN分解的IMF分量Fig.5 Time Domain Plots of IMFs of EEMD and CEEMDAN
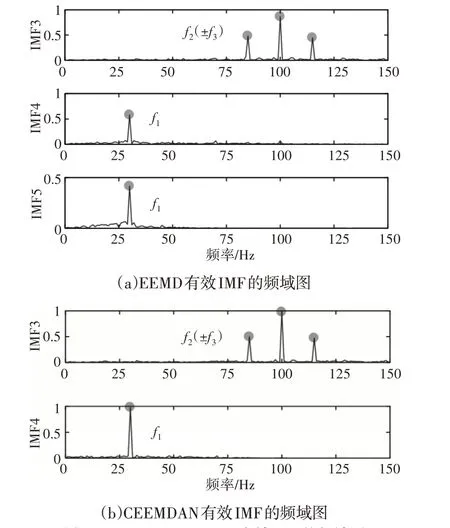
图6 EEMD和CEEMDAN有效IMF的频域图Fig.6 Frequency Domain Plots of Effective IMFs of EEMD and CEEMDAN

4.2 改进的多尺度熵仿真
为了验证IMSE 相对于MSE 的有效性和优越性,计算了式(14)中模拟信号的IMSE和MSE,并进行了数值仿真,其中,设置嵌入维数为4,相似容限r为0.2SD,得到IMSE 和MSE 随尺度因子变化趋势图,如图7、图8所示。在经过几次仿真试验后,考虑到信号的复杂性和计算效率,此次仿真试验选取尺度因子φ为20。从图7、图8 可以看出,仿真信号的MSE 和IMSE 值单调递减。MSE 采用传统的粗粒化处理,随尺度因子的增加呈波动趋势。从图7可以看出,当尺度因子为3、9和15时,MSE值显示总体变化趋势的波动。而IMSE值采用平滑粗粒化处理,在图8中,随着尺度因子的增加,总体趋势表现平稳。比较分析表明,IMSE在多尺度上实现了更稳定的熵值,以反映信号的复杂性和规律性。同时,平滑的粗粒化处理过程减轻了背景噪声的不利影响。通过对MSE 和IMSE 仿真比较,验证了所提出的IMSE 相对于优于MSE的优越性。因此,IMSE可以应用于行星齿轮箱声音信号的故障诊断中。
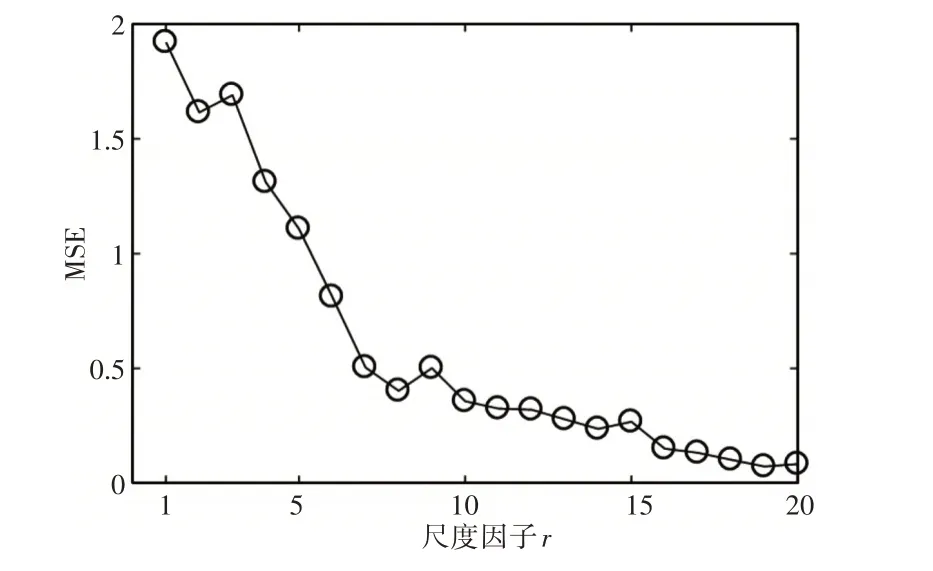
图7 传统粗粒化处理Fig.7 Traditional Coarse Graining Process
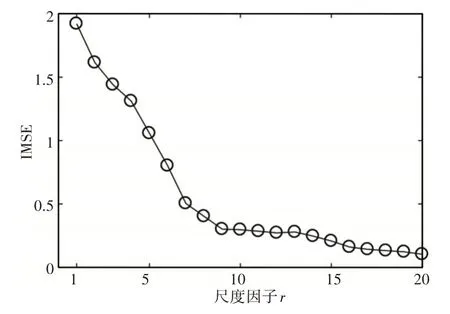
图8 平滑粗粒化处理Fig.8 Smoothed Coarse Graining Process
5 实验数据分析
为了验证CEEMDAN分解声音信号的可行性和IMSE的有效性,将对实验数据进行分析。实验采用机械多故障及转子动力学综合实验平台对行星齿轮箱太阳轮故障进行模拟。实验台结构,如图9所示。在距离行星齿轮箱太阳轮和行星轮啮合位置0.2m放置麦克风[12],麦克风类型为单指向柱体音头电容麦克风,放置麦克风时确保麦克风及线不接触到实验台,以防实验台振动对麦克风产生影响。实验中用到的三种故障齿轮类型,如图10所示。

图9 机械多故障及转子动力学综合实验平台Fig.9 Mechanical Multi-Fault and Rotor Dynamics Comprehensive Experimental Platform

图10 太阳轮故障类型Fig.10 Fault Types of Sun Gear
在电机转速为1500r/min,采样频率为8192Hz的情况下采集行星齿轮箱四种状态的声音信号。
实验中行星齿轮箱的参数为:行星轮齿数为27,行星轮个数为3,太阳轮齿数为18,齿圈齿数为72,模数为2。
齿轮四种状态下声音信号的时域图,如图11所示。分别为正常、磨损(齿厚小于正常齿轮)、裂纹、断齿。
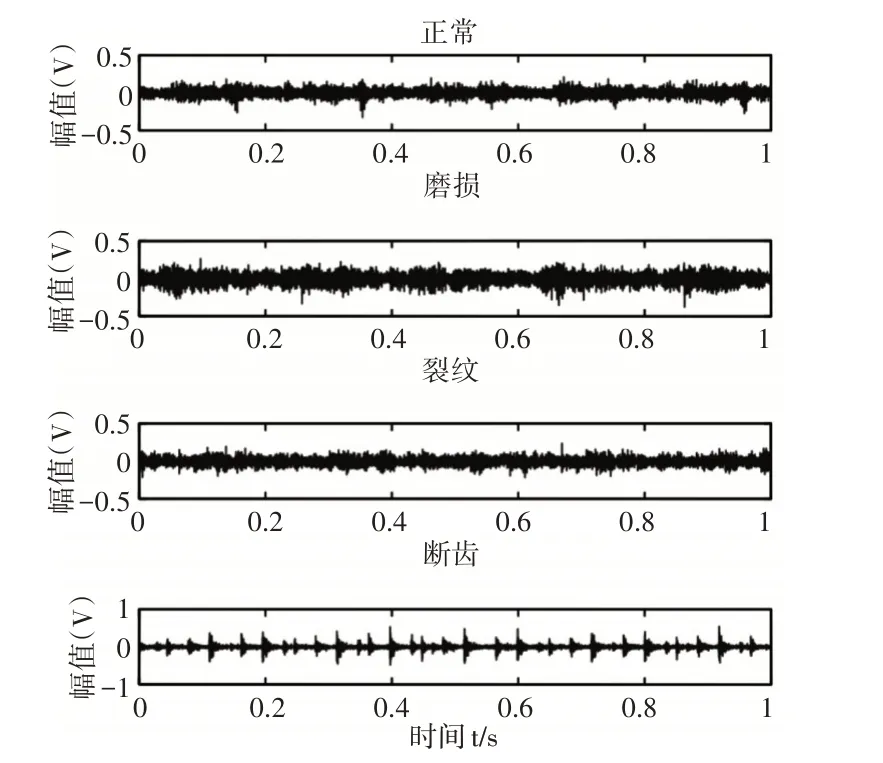
图11 四种状态声音信号时域图Fig.11 Time Domain Diagram of Four State Sound Signals
从时域波形图中我们无法直接识别四种状态下的声音信号,所以需要用到提出的方法步骤对声音信号进行分类。
随机选取磨损、正常、裂纹和断齿这四种状态的齿轮各一组,用CEEMDAN分解,计算CEEMDAN分解后分量的IMSE,对得到的CEEMDAN-IMSE进行分析。为了验证IMSE相对于MSE的有效性和优越性,同时保证信号在多尺度上包含更多信息,在计算MSE和IMSE时选取的尺度因数φ为3。
由于CEEMDAN前五个分量包含声音信号的主要信息,以下给出了声音信号四种状态下前五阶分量的熵值。
由图12 可以看出,对于正常的齿轮声音信号,其信号主要成分以啮合频率、啮合频率的倍频及谐波为主。在IMF3~IMF5中,当齿轮发生裂纹故障时,齿轮的声音信号仍以啮合频率、啮合频率的倍频及谐波为主,但是其频谱的幅值变大,信号的复杂性变低,所以裂纹故障时的熵值比正常齿轮低;而对于断齿故障时,由于声音信号表现出了较大的周期性的冲击,即断齿的声音信号的复杂性较于正常的声音信号变低,所以断齿信号各个分量的熵值较于其它信号低。由于IMF3~IMF5 的信号主要为啮合频率及其倍频频谱的幅值有变化,使得CEEMDANIMSE 情况下的这四个状态下的大小关系有明显区别:磨损>正常>裂纹>断齿。

图12 四种状态的改进多尺度熵Fig.12 Four States of IMSE
上述分析只是对随机样本进行分析,随机性较大,不具有一般性。为了更好区分四种声音信号,将构建支持向量机分类器对实验数据进行分析。
用实验台采取磨损、正常、裂纹和断齿这四种状态的声音信号各60组,每组时间为1s,采样长度为8192,总共得到240组样本。每种状态的声音信号中随机选取10组作为训练样本,另外50组作为测试样本。
对所有240 组样本声音信号用CEEMDAN 分解,分别选取240组声音信号CEEMDAN分解后的前五个分量,并计算前五个分量的IMSE,将这前五个分量的IMSE作为特征向量,选取每种状态各10 组训练样本输入到SVM 进行训练,其中,对“正常、磨损、裂纹、断齿”不同类型齿轮进行标记“1、2、3、4”标记。用训练好的SVM 分类器对剩下的200 组测试样本进行分类测试,得到CEEMDAN-IMSE的分类结果,如图13所示。可以看出只有1个正常样本被错分到磨损样本中,识别率达到了99.5%。
为了验证CEEMDAN和IMSE的优越性,采用了相似的方法进行了比较。得到EEMD-MSE、CEEMDAN-MSE 和EEMDIMSE 的分类结果,如图13 所示。在CEEMDAN-MSE 分类中,6个正常样本被错分到磨损样本中,3个磨损样本被错分到正常样本中,3 个裂纹样本被错分到正常样本中,识别率为94.0%;在EEMD-IMSE分类中,7个磨损样本被错分到正常样本中,6个磨损样本被错分到正常样本中,4个裂纹样本被错分到磨损样本中,识别率为91.5%;在EEMD-MSE 分类中,8个磨损样本被错分到正常样本中,7个磨损样本被错分到正常样本中,5个裂纹样本被错分到磨损样本中,2个断齿样本被错分到正常样本中,识别率为89.0%。从表1可以看出与EEMD和MSE等方法相比,这里所提出的方法与拥有最高识别率。
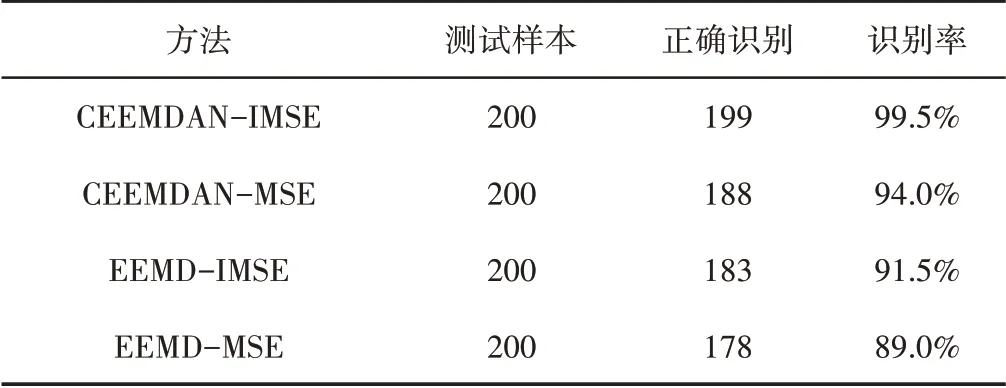
表1 四种方法分类识别率Tab.1 Recognition Rate of Four Methods
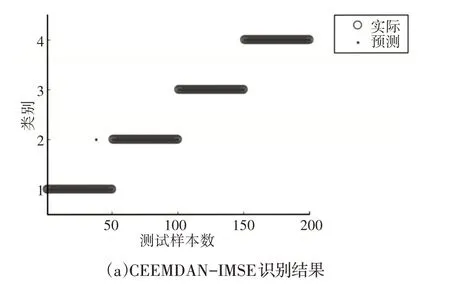
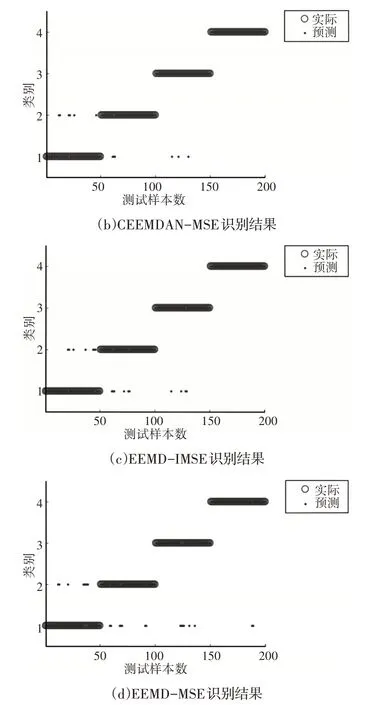
图13 四种方法分类结果图Fig.13 Classification Results of Four Methods
6 结论
为了更好的将信号处理应用于实际工业环境中,这里利用声音信号非接触式的优点进行故障诊断,提出一种CEEMDAN 和IMSE的声音信号故障诊断方法,通过仿真和实验分析得出了以下结论。
(1)通过CEEMDAN 仿真模拟实验表明CEEMDAN 可以缓解模态混叠问题,CEEMDAN 比EEMD 可以分解出精准的IMF分量。
(2)通过IMSE数值仿真表明,平滑粗粒化处理的多尺度熵可以使不同尺度下时间序列长度相同,避免了数据丢失,弥补了传统多尺度熵的不足。
(3)结合支持向量机去对声音信号进行识别,通过实验结果对比表明,提出的方法有很高的识别率,相对于其他方法优越。
