基于XGBoost模型的入侵检测技术研究
2022-05-18郭靖宗薛有为申志军
郭靖宗,薛有为,申志军
(1.河南水利与环境职业学院,河南 郑州 450008;2.内蒙古农业大学 计算机与信息工程学院,内蒙古 呼和浩特 010000)
互联网发展离不开网络安全,随着互联网迅速发展,网络覆盖范围已经全球化,中国互联网络信息中心表示,2020年中国网民规模为9.89亿,较2020年3月提升5.9个百分点,移动通信速度也迈入了5G时代,网络入侵的频率也越来越频繁,入侵的手段也越来越复杂。根据第45次《中国互联网络发展状况统计报告》显示,截至2019年12月[1],国家计算机网络应急技术处理协调中心接收到网络安全事件报告107 801件。随着各个行业对于Internet需求的加大,对于各种网络攻击的入侵检测技术的需求也在进一步的提高。
智能化入侵检测的研究离不开数据集和分类模型。笔者基于最新的数据集CSE-CIC-IDS进行数据预处理,划分训练集和测试集,以之为基础通过XGBoost模型进行分类测试并进行综合对比分析。
1 CSE-CIC-IDS数据集
入侵检测数据集的研究可以追溯到20世纪90年代[2],麻省理工学院林肯实验室模拟美国空军局域网环境而建立的网络流量测试数据集,此数据集建立时加入了4种异常类型,在1999年由来自哥伦比亚大学的Sal Stolfo教授和来自北卡罗来纳州立大学的Wenke Lee[3]教授采用数据挖掘等技术,对KDD' 98数据集进行数据预处理和特征分析,生成了数据集KDD' 99。此数据集和它之后的改进版NSL-KDD数据集在入侵检测模型的训练时经常作为基准数据集使用。
近年来,随着网络攻击类型增加,KDD' 99数据集已不能有效地反映现代的网络流量特点和低占空间攻击,因此2015年由新南威尔士大学(UNSW)在澳大利亚网络安全中心(ACCS)的网络实验室中使用IXIA工具创建了UNSW-NB15数据集[4]。实验的攻击数据是从CVE网站受到的攻击数据中获取。该数据集使用Tcpdump抓取了100G数据。UNSW-NB15数据集具有9类攻击:24 246个模糊测试攻击(Fuzzers),2 677个分析攻击(Analysis),2 329个后门攻击(Backdoors),16 353个拒绝服务攻击(DoS),44 525个漏洞攻击(Exploits),215 481个通用攻击(Generic),13 987个侦察攻击(Reconnaissance),1 511个代码攻击(Shellcode)和174个蠕虫攻击(Worms),正常数据约220万条,共计254万条数据,没有进一步划分攻击类型。数据集包括原始流量包(pacp)和特征流量CSV文件,CSV文件被划分为训练集和测试集,文件共有49个特征。训练集有17万条数据,测试集有8万条数据[5]。
UNSW-NB15数据集的缺点是攻击类型没有进行二级划分,捕获时间较短,流量分布可能会与真实流量分布存在偏差,训练得到的模型可能不理想。因此,加拿大通信安全机构(Communications Security Establishment/CSE)和网络安全研究院(Canadian Institute for Cybersecurity/CIC)于2018年合并公布了入侵检测数据集CSE-CIC-IDS 2018[6,7]。该数据集获取的网络拓扑结构是由AWS搭建的拓扑结构。划分为5个子网。分别代表企业的5个部门,和服务器机房。除IT部门以外的部门,都安装了不同的Windows系统。对于IT部门的计算机安装了Ubuntu,对于服务器机房安装了不同的Windows服务器。该数据集一共模拟了七大类攻击,14种攻击数据,涉及了7种网络协议:HTTP、HTTPS、POP3、SMTP、IMAP、FTP和SSH。该数据集包含了原始流量包、主机日志记录和特征标签流文件。
CSE-CIC-IDS2018数据集获取时间相对于UNSW-NB15数据集时间较长,在现代流量中最符合真实流量分布情况。实验模拟环境较新,具有现代网络协议和攻击类型的数据集。
2 传统的机器学习分类算法
机器学习在入侵检测中就是通过对比训练好的模型之间的偏离度来区分是否异常。该模型是根据数据之间的关系来描述的,若模型S是基于监督学习的异常检测模型,则S=(M,D)。M是正常网络行为的模型,D是M允许的偏差。机器学习模型一般是由训练模块和检测模块构成。训练模块训练好模型M,然后根据M和D来对新的网络事件进行预测,如果超过D的范围,则该数据被标记为异常流量。
分类问题一直都是研究人员所探索的问题,如何使用机器学习高效而准确的判断数据之间的相关性,并且根据某些已知的特征来区分输入的样本是属于哪一种已知的类别,其本质是通过对特征进行模型计算得到一个对未分类数据的预测模型。机器学习发展至今,产生了许多经典的分类算法,比如逻辑回归、朴素贝叶斯、决策树、K最邻近和支持向量机等算法。
笔者以逻辑回归为例说明传统机器学习算法的工作原理。
逻辑回归的思路是把线性回归改为二分类。逻辑回归模型定义为如(1)和(2)所示概率分布的模型:

(1)
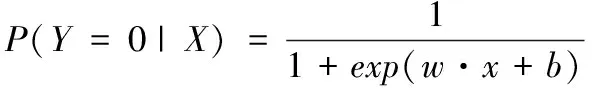
(2)
其中:x∈Rn是输入(特征空间)
Y∈{0,1是输出(标记)}
w∈Rn为模型参数——权值向量(weight)
b∈R为模型参数——偏执(bias)
为了简洁,将b扩充到w,然后x后边加入全1的列得到:
w·x+b⟹w·x
(3)
(4)
因此逻辑回归模型的对数几率函数为公式(5):
(5)
上式意味着输出Y=1的对数几率是输出x的线性函数,即逻辑回归模型。
3 CSE-CIC-IDS数据集的预处理过程
3.1 数据提取
在数据预处理过程的时候,由于特征流量文件内存过大,计算机内存经常溢出,会使得后续的数据预处理和模型训练效率降低,所以在数据合并之前,需要对10个CSV文件提取10%的数据集作为子集。由于每个文件中,都包含不同的攻击类型,所以,需要对每个文件进行随机提取,确保特征的分布稳定。代码如下:
import pandas as pd
data = pd.read_csv(`XXX.csv')
sample = data.sample(frac=0.1, random_state=5, axis=0)#Frac=0.1代表抽取其中10%的数据
sample.to_csv(`XXX.csv',encoding=`utf_8_sig')
3.2 数据集成
文件合并之前,需要统一格式,对于列数不同的文件,首先对比其中特征的区别。发现文件中多余的两列对于模型的训练没有意义,然后将多余的列进行删除,与其他8个文件的表头进行统一。删除指定列的代码如下:
df.drop([`typeMedium'],axis=1,inplace=True)
随着大数据的出现,需要处理的数据源越来越多,数据分析任务多半涉及将多个数据源数据进行合并。数据集成是指将多个数据源中的数据结合、进行一致存放的数据存储,这些源可能包括多个数据库或数据文件。在数据集成的过程中,会遇到一些问题,本文实验中遇到了数据值的冲突和处理,并且对冲突进行去重处理。接下来,需要将10个文件进行集成处理,然后进行表头去重。代码如下:
def marge(csv_list, outputfile):
for inputfile in csv_list:
f = open(inputfile, `r', encoding="utf-8")
data = pd.read_csv(f)
data.to_csv(outputfile, mode=`a', index=False)
#去重保留一个表头
def distinct(file):
df = pd.read_csv(file, header=None)
datalist = df.drop_duplicates()
datalist.to_csv(`result_new.csv', index=False, header=False)
3.3 数据清洗
数据清洗是通过将缺失值删除或者填补,纠正数据的不一致来达到清洗的目的。简单来说,就是把数据里面哪些缺胳膊腿的数据、有问题的数据给处理掉。总的来讲,数据清洗是一项繁重的任务,需要根据数据的准确性、完整性、一致性、时效性、可信性和解释性来考察数据,从而得到标准的、干净的、连续的数据。
数据集存在空值或者Infinity时,文件无法正常运行,需要对空值进行处理。处理方法有两种:删除空值和Infinity所在行,或者使用取均值进行填充。但是对于本文的上亿条数据,取均值意义不大。所以本文采用删除空值和Infinity行。首先需要判断数据集中是否存在空值,然后进行删除。代码操作如下:
df_n.dropna(axis=1, how=`any', inplace=True)
3.4 时间戳处理
数据有一列是日期,需要转换为时间戳。如图1(a)所示,文件中第三列包含一列是日期,在做模型训练的时候,此格式无法进行读取,所以需要将其转化成时间戳格式。转换以后的结果如图1(b)的Timestamp列所示。
代码如下所示:
data = pd.read_csv(`XXX.csv')
data[`Timestamp']=data[`Timestamp'].apply(lambda x:time.mktime(time.strptime(x,`%d/%m/%Y %H:%M:%S')))
data.to_csv(`XXXX.csv', sep=`,', header=True,index=False)
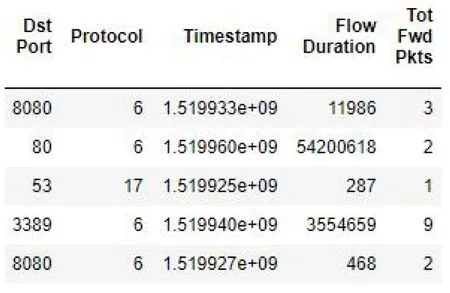
(a)处理前的时间样例
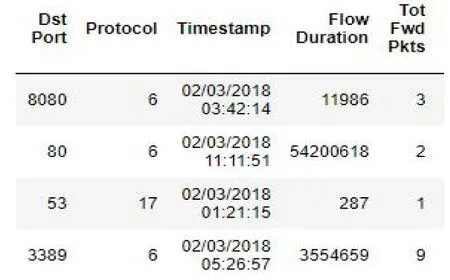
(b)处理过后的时间样例图1 时间样例
3.5 归一化处理
最后数据集需要进行归一化处理,归一化有两种形式:①把数据变为0~1之间的数;②把有量纲表达式变为无量纲表达式。主要是为了使得数据处理方便快捷。归一化是数据预处理中的一步操作,归一化的作用是缩小统一样本的分布。如果不进行归一化,数据的取值范围往往会非常大。在训练模型的时候,数值范围分布差异过大会使模型产生过拟合现象。因此归一化操作可以使得模型训练的效果更好,提升模型性能。
笔者使用的是Max-Min标准化,该方法将某个变量的观察值减去该变量的最小值,然后除以该变最大值与最小值的差,其标准化的数值落到[0,1]区间,max和min分别为最大样本值和最小样本值。
代码部分如下:
def data_norm(df,*cols):
df_n = df.copy()
for col in cols:
ma = df_n[col].max()
mi = df_n[col].min()
df_n[col] = (df_n[col] - mi) / (ma - mi)
return(df_n)
数据集处理完之后需要进行训练集和测试集的划分,划分的时候,要保证两部分互不相交,保持数据分布一致,训练集数据占到总数的2/3到4/5比较合理,为了保证数据集的随机性,将数据集进行随机打乱,多次划分结果取平均值。部分代码如下:
test = test_data.sample(int(test_data.shape[0]*0.2))
train = test_data.iloc[list(set(test_data.index.values)-set(test_data20.index.values)),]
4 基于XGBoost模型的入侵检测方法
XGBoost是在Gradient Boosting算法[8]基础上加以改进,模型和参数本身指定了给定输入和如何预测,但是没有告诉如何去寻找一个比较好的参数,这个时候就需要目标函数登场了。一般地如式(11)目标函数包含两项:第一项损失函数,它表示模型拟合数据的程度;另一项是正则化项(惩罚项),它使得模型更加简单,避免过拟合。
Obj(θ)=L(θ)+Ω(θ)
(6)
XGBoost的构建目标函数为(7),左边是损失函数,右边是正则化项,(8)是正则化项的展开式。
(7)
(8)
下文中式(9)—式(15)介绍了如何构造目标函数,对于给定xi个样本,都需要求一个f(x)的得分,当有k个样本时,第0个树的预测值为0,第1棵树的预测值为f1(xi),并且等于第0棵树预测值与第1棵树预测值相加。第二棵树的预测值为f2(xi),是第1棵、第2棵与第三课树的预测值的和。以此类推,第k棵树的预测值就是k-1棵树与k棵树的和。然后将得出的第k棵树的结果带入函数当中得出式(13),其中式(14)在预测第k棵树的时候,前k-1棵树的预测值已知,所以是常量,最终得出最小化目标函数。
(9)
(10)
(11)
(12)
(13)
(14)
(15)
XGBoost实验开始,对数据集大小对训练集评分和测试集评分做了比较,由图2可知随着训练集样本的增加,训练集得分会降低,而测试集得分会上升,但是随着训练集的上升,会导致模型的过拟合,使得模型训练的效率大大下降。
在训练的时候偶尔会出现过拟合。虽然模型可以准确地拟合训练数据,但是无法高效的预测除训练集以外的数据。如果此时使用测试集进行测试,测试集中的部分信息已经在训练集出现,因此可能会过拟合,因此需要从训练数据中取部分当作验证集,但不参与训练。因此,本文实验还在XGBoost模型上做了K折交叉验证(KFlod),K折交叉验证会将数据集划分为k个分组,成为折叠(fold)。使用该方法,对sample_influence、ntrees_estimators 、gamasolve、max_depthsolve这几个参数进行了K折交叉验证,并且绘制了分析图像,对它们参数的变化对结果影响进行了可视化分析。
XGBoost模型在训练之前,会对数据集的特征进行重要性的划分,因为效率是模型最重要的因素之一[9]。如果一次性读取所有特征,会导致复杂度提高,所以要精简特征。

图2 训练集个数影响
模型的参数对于算法的评分起着至关重要的作用,训练模型之前需要对模型的参数有一定的了解。XGBoost把参数分成了3类:Booster参数、通用参数和学习目标参数,表1举例说明了部分参数,其中在模型调参的时候,参数的学习率往往是被调试的参数。

表1 XGBoost参数说明
由图3可以看出随着生成的最大树的数目增加,模型的得分也会越来越高,但是n_estimators数量太大,会导致模型训练时间增加。所以n_estimators的值不能选最高点。图4可以看出不同的gamma参数得分,gamma参数从0一直下降,从3开始上升。所以还是将gamma参数设置成默认参数0的效果最好。模型对学习率进行了实验。
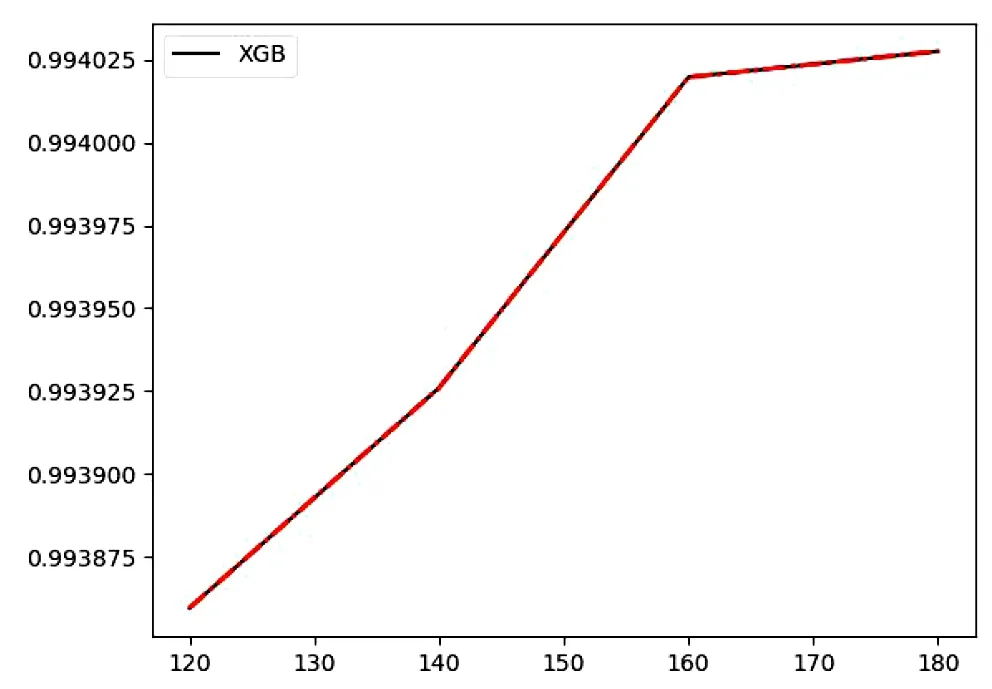
图3 不同n_estimators的得分
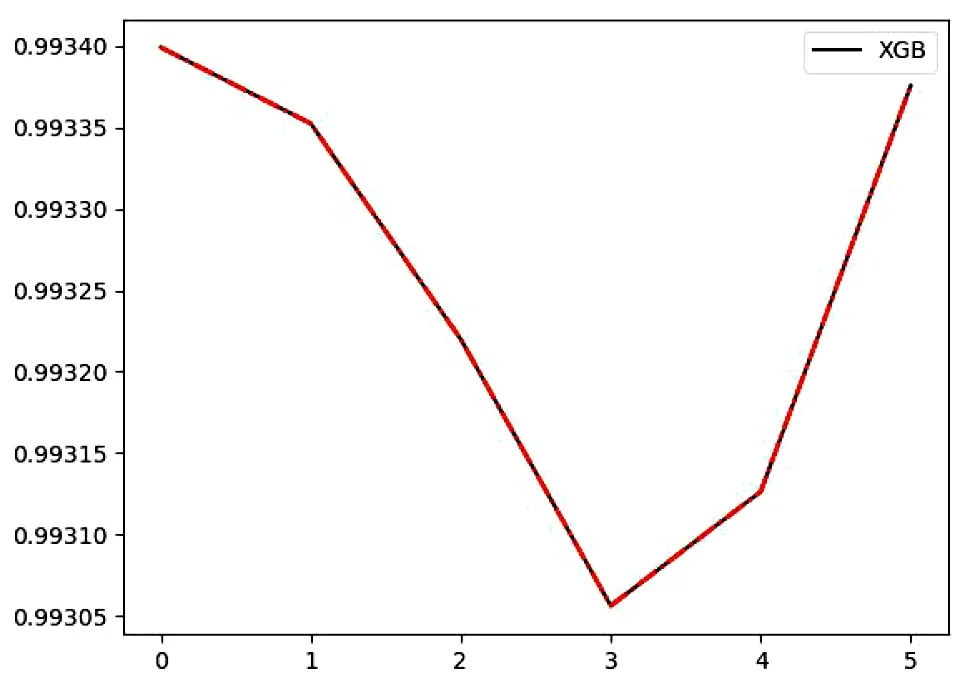
图4 不同数量gamma参数得分
由表2可以看出当学习率从0.02升至0.06时,各项得分都达到了最高,当学习率为0.08时,指标没有明显提升,所以为了避免网络不能收敛,最终将学习率设定为0.06。
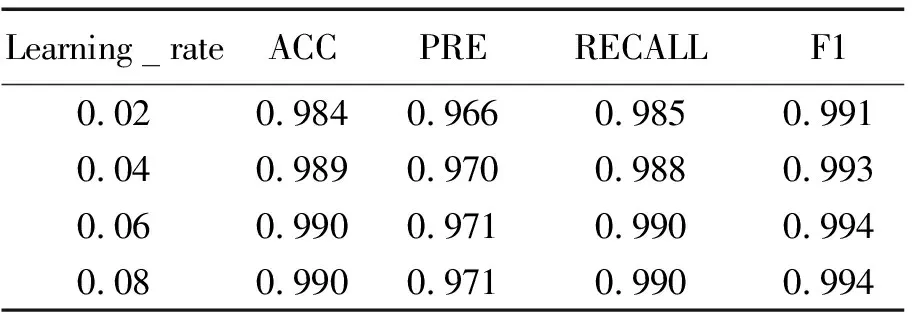
表2 XGBoost结果
笔者使用了CSE-CIC-IDS 2018数据集进行了逻辑回归等算法结果分析,然后与XGboost模型进行比较,表3是经典分类算法的评估表,其中KNN的得分综合最高,但是训练速度非常缓慢,可能导致过拟合。

表3 经典算法得分表
通过对XGBoost模型参数的交叉验证,得出不同参数对应准确率的曲线图,实验结果分析表明基于XGBoost模型的入侵检测模型能够较好地完成分类任务。
5 总结
笔者对最新的CSE-CIC-IDS入侵检测数据集进行数据预处理,创建了训练集和测试集,在此基础上基于XGBoost设计并开发了入侵检测模型。本模型可以对攻击和未被攻击数据进行区分。但是无法区分攻击数据的攻击类型。后续希望可以解决多分类问题。
