基于草原牲畜放牧轨迹的数据挖掘研究
2022-05-18邢光磊周李涌李宝山
邢光磊,周李涌,李宝山
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
近年来,随着大数据技术发展迅速,产生了海量的时空轨迹数据,时空轨迹数据挖掘的研究已成为国内外的一个研究热点[1]。Teimouri, Maryam等人[2]提出了一种利用从轨迹数据中提取的运动参数来推导动物的运动行为(行走,觅食和休息)的方法。对每只动物的个体运动路径进行量化。选择适当的运动参数表示。Clark, Patrick E.等人[3]对于麋鹿和牛的行为通过GPS跟踪系统进行分类,在两项随机试验中,识别成年牛和圈养麋鹿牧场的GPS记录喂食、行走和静态行为。在移动对象数据挖掘中,主要以移动对象的历史行为数据,即轨迹数据作为研究对象,发现其中潜在的信息和有用的知识,如:移动对象行为特征、行为模式、环境影响等[4]。
在大数据技术日益普及中,草原畜牧业也得到快速发展。牧羊人在放牧过程中使用定位系统产生大量轨迹数据。在处理轨迹数据上,结合传统轨迹挖掘技术并针对草原畜牧业牲畜运动轨迹特有特点,笔者提出了一种适合牧区的轨迹挖掘模型,并利用Hadoop开源平台的数据计算处理框架[5,6],对轨迹数据进行预处理,提高算法处理效率。最后通过真实轨迹数据对于该模型进行验证,结果证明了模型的有效性,对后续草原科学放牧的研究是具有重要意义的。
1 轨迹数据处理
对于放牧产生的轨迹数据可以提取数据中潜藏的信息。然而,并不是全部的数据都能应用于研究。在牲畜上GPS定位设备产生的轨迹数据中存在一些无效数据、重复数据和噪声数据。为了提高数据挖掘的准确性,必须剔除无效数据,并根据现有的轨迹数据提取有用数据,以便于后续分析。
1.1 实验数据来源
笔者使用的数据是苏尼特左旗某牧区放牧中产生的轨迹数据。数据时间是2021年5月—7月。通过牧区上头羊所佩戴定位项圈产生的连续定位信息,其中有定位项圈编号、定位状态、经纬度等。模型使用轨迹数据的格式,见表1。
1.2 数据预处理
满足草原牧区产生海量数据的存储和计算处理需求,搭建了hadoop[7,8]平台,可以通过平台对原始轨迹数据进行清洗。其中包括缺失值清洗、逻辑错误清洗、格式内容清洗。在平台上,对于草原数据进行不同主题区分,根据数据挖掘主题需求,抽取对应的数据做支撑。在预处理这个环节将直接影响轨迹数据挖掘的效果。

表1 轨迹数据模型
2 基于BP-DBSCAN的畜牧轨迹数据挖掘模型
根据实际需求将畜牧轨迹数据经过预处理后,由于羊群的轨迹比较缓慢、迂直的特点,对现有的轨迹挖掘所采用各种聚类算法进行分析后,最终采用DBSCAN算法[9]作为数据的处理分析。DBSCAN聚类算法有发现不同密度、尺度和形状聚类的能力。DBSCAN聚类算法发现类簇个数变化是基于使用者给出的最少样本点数和近邻半径两个参数[10]。但是,DBSCAN算法在使用者对数据集没有先验经验的情况下确定上述两个参数有一定困难。因此确定了一种BP-DBSCAN算法的模型,通过神经网络确定训练出最优参数,达到放牧产生轨迹数据聚类的准确性。
2.1 DBSCAN聚类算法
1996年由Ester M、Kriegel H P、Xu X.等人[11]提出了基于密度空间聚类算法——DBSCAN算法,该算法不用事先规定类簇的个数,当需要指定两个参数(Eps,MinPts),为了详细的描述DBSAN算法,须给出以下定义[12,13]:
定义1:(Eps领域)假设给出数据集D={x1,x2,x3,…,xm},对于xj属于D,xj的领域NEps(xj)定义为以xj为中心,以Eps为半径的区域内,即:
NEps(xj)={xj∈D|dist(xi,xj)≤Eps}
(1)
其中D是数据集;dist(xi,xj)表示D中两个数据对象xi和xj之间的距离;NEps(xj)在数据集D中对象xi与对象xj距离小于Eps的所有对象。
定义2:(核心点)对于数据xi∈D,设定MinPts最小阈值,如果|NEps(xj)≥MinPts|,称为核心点,不是核心点可是某核心点的Eps邻域内的对象称为边界点。
定义3:(直接密度可达)在数据集D中若对象xi在对象xj的Eps域内,并且是核心对象,称对象xi从对象xj出发是直接密度直达的(directly density-reachable)。
定义4:(密度可达)如果存在一个对象序列P1,P2,P3,…,Pn,满足P1=xj,Pn=xi,并且Pn+1由Pn直接密度可达,则对象xi从对象xj关于Eps和MinPts是密度可达的(density-reachable)。
定义5:(密度相连)如果存在对象xk=D使得点xj和xi都是从xk关于Eps和MinPts密度可达的,那么点xj到xi是关于Eps和MinPts密度连通的(density-connected)。
定义6:(噪声点)不属于在任何簇的样本点则标记成噪声点(noise)。
该算法流程图,如图1所示。

图1 DBSCAN算法流程
2.2 BP神经网络
BP神经网络[14,15]是1986年Rumelhart和Williams提出的,是应用较为广泛的人工网络模型。BP神经网络由输入层、隐含层与输出层3部分组成。BP神经网络模型,如图2所示。

图2 BP神经网络模型
BP神经网络通过信号的正向传播和误差的反向传播来降低误差函数的函数值,网络训练过程就是不断地调整优化权值和阈值。对于3层BP神经网络。算法计算公式如下:
隐含层第l个神经元输出:
(2)
输出层第m神经元输出:
(3)
误差反向传递更新隐含层到输出层权重:
φlm(m+1)=Φlm(m)+ΔΦlm
(4)
误差反向传递更新输入层到隐含层权重:
ωpl(m+1)=ωpl(m)+Δωpl
(5)
式中:ωpl和φlm是连接权值;θl和Φm是阈值;f为该层的激活函数。
2.3 BP-DBSCAN轨迹挖掘模型
目前DBSCAN聚类算法的结果会受到初始化参数Eps和MinPts的影响,笔者通过密度聚类算法和BP神经网络模型的优势,提出了基于密度聚类算法和BP神经网络相结合的草原畜牧轨迹数据挖掘模型。该模型主要由DBSCAN算法模块和BP神经网络模块两个部分组成。通过BP神经网络的得出最优参数,再进行对于放牧产生的轨迹数据进行聚类。
基于BP-DBSCAN轨迹挖掘模型的步骤如下:
step1 确定BP神经网络结构,初始化参数;
step2 输入参数进入BP神经网络,得到参数Eps和MinPts;
step3 以训练出Eps和MinPts为参数输入DBSCAN算法;
step4 扫描轨迹数据,依次访问所有轨迹点;
step5 判断此轨迹点是否被访问过;
step6 结合Eps和MinPts参数,判断此轨迹点是否为核心点;
step7 如果此点是核心点,访问其所有密度相连的轨迹点,将其与核心点定为一个类簇;
step8 继续循环,直至所有轨迹点访问完为止,得到分布E1;
step9 将E1和实际结果Y1输入损失函数中,得误差值;
step10 通过误差值对神经网络进行反向传播训练,得出最优Eps和MinPts;
step11以最优Eps和MinPts为参数的DBSCAN算法对再数据集进行聚类。
3 实验及结果分析
实验使用数据是苏尼特左旗某牧区放牧中产生的轨迹数据。BP-DBSCAN轨迹挖掘算法模型通过Python语言实现,在Win10系统运行,计算机硬件配置:Intel(R) Core(TM) i7-8550U CPU @ 1.80 GHz,8 GB内存,1 TB硬盘。通过训练出最优参数对轨迹数据进行聚类,从而提升轨迹数据聚类效果。
3.1 误差分析
鉴于目前基于草原畜牧轨迹的挖掘算法模型,是否能训练出最优参数。损失函数[16]可以判断模型预测与实际数据差距。如表2所示损失函数呈现递减趋势,说明预测值越来越接近实际数据,得到的参数越准确。
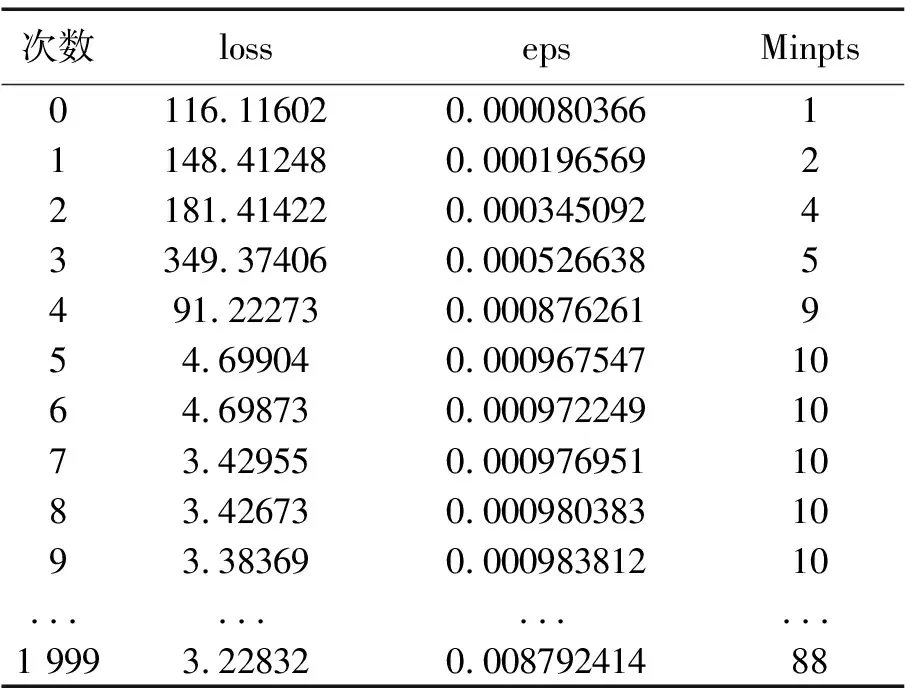
表2 BP-BDSAN模型误差值
3.2 聚类分析
本次实验抽取某类簇的数据和其他类簇少量数据对轨迹数据聚类,图3(a)图是对原始轨迹数据的聚类效果图,图3(b)图是通过模型训练出最优参数聚类出的效果图,实验结果表明通过神经网络结合DBSCAN算法模型,是可以满足自适应确定DBSCAN参数的需求,聚类效果图,如图3所示。

(a) (b)
4 结论
笔者对草原牧区牲畜放牧过程中产生的大量轨迹数据,确定一种基于BP-DBSCAN轨迹挖掘算法模型,对牲畜轨迹数据进行聚类,以满足牧区牲畜轨迹数据挖掘要求。为提升算法处理效率,搭建了大数据hadoop平台对海量数据进行预处理。BP-DBSCAN轨迹挖掘算法模型对于轨迹聚类效果提高,为后续牧区板块规划做基础,使草场数据信息化。科学放牧,可以达到羊群与草场之间的相对的生态平衡,减轻草场压力。
畜牧业属于基础产业同时也是重要产业,在畜牧业向现代化转型过程中,如何结合现有技术,更好地服务于畜牧业是研究人员所需要考虑的。草原牧区以其独特的特色和优势在畜牧业发展中占有重要地位。基于现研究背景,笔者依托于大数据结合轨迹挖掘技术,指导草原畜牧业生产科学发展,是具有非常重要意义的。
