基于机器学习的CNG加气站风险预警模型研究
2022-05-17赵君寇俊辉胡灿张轲
赵君 寇俊辉 胡灿 张轲
(1.中石化石油机械股份有限公司武汉江钻天然气分公司 武汉 430223;2.中国地质大学(武汉) 武汉 430074)
0 引言
天然气作为一种清洁高效的能源,在我国能源体系中占据着十分重要的地位。据国家统计局发布的报告显示,2020年我国天然气产量为1 888.5亿m3,比上年增长9.8%,连续4年增产超过100亿m3[1]。同时,天然气属于易燃易爆的介质,天然气加气站也属于高风险场所,因此天然气加气站风险预警研究对保障加气站及周边设施的安全起到至关重要的作用。
近年来,随着人工智能技术的蓬勃发展,基于人工智能的机器学习算法日渐成熟,且不需要人的交互,能自动获取信息并实时发布以防止重大或严重损坏,具有成本低、功耗低、信息可靠等优势[2]。因此,国内外众多学者对其在预警方面的应用展开了广泛研究。孙德亮[3]提出了基于机器学习的区域滑坡灾害预警模型的构建方法;胡安冬等[4]在机器学习的理论与基础上,设计训练出了一套用于常见震级范围的机器学习震级预估模型;SPYRIDIS P等[5]建立了混凝土扣件系统拉伸断裂能力的预测模型;刘燮鹏[6]对移动基站设备故障预警系统的需求分析、设计、功能实现作了详细的阐述;王晓春等[7]通过对大量数据的收集分析,提出了一种智能化故障预测系统,这种系统可以利用大数据和机器学习算法发现潜在故障。相较于传统专家打分导向的风险预警数学模型,运用机器学习技术构建的预警模型的通用预测能力较强,能从数据中学习到隐藏的模式,找到更深层次的规律[8-9]。结合信息采集系统,可以更加便捷地实现实时安全状态的监控和预警。随着大数据技术的进步,预警模型在实际应用过程中可以不断更新优化模型参数,提高预警的准确度。
目前,国内还没有将机器学习应用到加气站风险预警的研究。本文以CNG加气站为研究对象,运用机器学习技术和大数据理论,从风险预警指标体系构建、特征数据集采集与处理、加气站预警模型构建与优化三大方面,系统阐述了构建机器学习预警模型的方法,并运用SMOTE算法解决了正负样本不均衡的问题。结合CNG加气站的生产和管理情况,构建了基于机器学习技术的CNG加气站风险预警模型,在将机器学习和大数据技术应用到天然气加气站风险预警方面做出了探索性研究。
1 加气站风险预警指标体系
通过查阅、汇总与分析加气站近5年事故调查分析报告、相关文献资料、天然气加气站安全评价报告等,从人员、设备设施、安全管理和环境安全四大因素[10-11]出发,列出影响加气站安全的若干指标,并在安全生产专家的指导下选取导致事故发生的高频率指标,按照客观化、可量化、可数字化管理的原则建立了加气站风险预警指标体系。
1.1 人员因素
通过分析加气站近5年的事故案例发现,大多数事故的发生脱离不了人员因素,比如人员的管理不当、违章操作等。在建立加气站风险预警指标体系时,需要对加气站人员情况进行监测。人员因素的指标包括:
(1)员工技术水平达标率:
(1)
式中,ra为技术水平达标率;na为技术水平达标人数;Na为加气站员工总人数。
(2)员工文化程度:
(2)
式中,rb为员工文化程度;nb为拥有高中及以上学历人数;Nb为加气站员工总人数。有研究表明,企业员工文化程度越高,发生误操作的概率越小,企业意外事故发生的可能性也越小[12-13]。
(3)员工遵守劳动纪律率:
(3)
式中,rc为员工遵守劳动纪律率;nc为加气站违反劳动纪律的人数;Nc为加气站员工总人数。
1.2 设备设施因素
设备设施是生产作业活动的工具,如果设备存在安全问题不能得到及时解决,将可能导致人员伤亡和财产损失,因此设备设施也是预警指标需要考虑的重要因素。设备设施的指标包括:
(1)压缩设备综合合格率:
(4)
式中,rd为压缩设备综合合格率;nd为加气站存在问题的压缩设备数量;Nd为加气站压缩设备总数量。
(2)安全距离达标率:
(5)
式中,re为加气站工艺设备与周边环境的安全距离达标率;ne为安全距离不达标的工艺设备数量;Ne为加气站工艺设备总数量。《汽车加油加气站设计与施工规范》(GB 50156—2012)规定了加气站工艺设备与公共建筑物、道路、生产厂房等的安全距离。
(3)加气设备综合合格率:
(6)
式中,rf为加气设备综合合格率;nf为加气站存在问题的加气设备数量;Nf为加气站加气设备总数量。
(4)消防设备完好率:
(7)
式中,rg为消防设备完好率;ng为加气站中不合格的消防设备数量;Ng为加气站消防设备总数量。
1.3 安全管理因素
健全有效的安全管理制度是加气站安全生产与运行的基础保障。加气站安全管理不到位,很大程度上会增加事故发生的概率。安全管理因素指标包括:
(1)安全培训教育合格率:
(8)
式中,rh为安全培训教育合格率;nh为加气站员工按规定参与安全培训合格的人数;Nh为加气站员工总人数。
(2)安全规章制度落实率:
(9)
式中,ri为安全规章制度落实率;ni为已落实的安全规章制度数量;Ni为安全规章制度总数量。
(3)应急预案与演练:
(10)
式中,rj为应急预案与演练情况;nj为加气站实际应急演练情况;Nj为规定加气站应急演练情况。
(4)专业安全管理人员占有率:
(11)
式中,rk为专业安全管理人员占有率;nk为专业安全管理人员数量;Nk为加气站员工总人数。
(5)落实安全检查与隐患整改率:
(12)
式中,rl为落实安全检查与隐患整改率;nl为已落实的安全检查与隐患整改数量;Nl为安全检查与隐患整改总数量。
1.4 环境因素
环境因素也会影响加气站的安全运行。若工人岗位布局严重不适宜,会影响员工的情绪,对工人作业行为产生不良影响;雨雪雷电等恶劣天气也会影响加气站设备的正常运行。本文选取岗位环境、周边环境和自然环境作为预警指标,通过对加气站实地调研或专家指导打分获得。
(1)岗位环境。岗位环境的好坏会直接影响员工的工作状态,太差的环境如嘈杂的作业环境、狭小的作业空间等,会使员工感到不适,增加误操作的可能性,进而引发事故。
(2)周边环境。事故具有连锁效应,如果加气站的附近存在重要的公共建筑、人员密集场所,一旦加气站发生事故影响到周边,可能会扩大事故造成的伤亡和损失。
(3)自然环境。加气站所在地区的地质条件、气象条件,包括雷电、冰雹、涝灾等恶劣环境,都将影响加气站的安全和正常运行。
2 基于机器学习的CNG加气站风险预警模型构建
机器学习是目前实现人工智能的主要技术,其应用正逐渐推广到各行各业,机器学习模型的识别应用范围广、潜力大。应用机器学习算法构建加气站风险预警模型,结合前文构建的预警指标体系,采集对应的样本数据后训练模型,通过对风险场所重要指标的监控和分析,追踪预警结果,实现对事故的事前控制。本文建立的CNG加气站风险预警流程如图1所示。
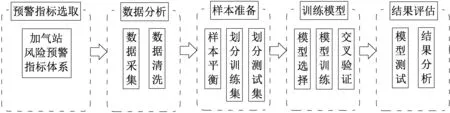
图1 CNG加气站风险预警模型构建流程
2.1 数据预处理
2.1.1 原始数据采集
本文选择武汉市某石化公司的12座CNG加气站为研究对象进行数据采集与统计,根据已建立的预警指标体系对指标层的16类数据进行调研收集与整理。本文构建的机器学习算法将实现对CNG加气站的风险预警分类功能。通过查阅CNG加气站的巡检和维修记录,收集了12座加气站7个月的运行状态数据,按月采集数据,标签设置为“高风险”和“低风险”两类。在某月内,将发生设备泄漏、加气事故等风险事件的加气站数据标签规定为“高风险”,作为负样本;将正常运行的加气站数据标签规定为“低风险”,作为正样本。经过数据清洗,删除部分数据后最终得到84组数据,其中正样本78组、负样本6组。
2.1.2 均衡样本数据
样本数据不均衡是普遍存在的现象,如本研究中加气站发生事故的情况是较少的,导致“高风险”样本的数量较少。样本数据不均衡会导致模型预测结果倾向于样本量更多的“低风险”样本,而采用简单复制样本的策略来增加少数类样本的方法容易产生模型过拟合的问题,使得模型泛化能力不足[14]。为解决这一问题,本文选用了SMOTE(Synthetic Minority Oversampling Technique)算法[15]对“高风险”样本进行过采样,提高分类模型的泛化能力。SMOTE算法的基本思想是对少数类样本进行分析,并根据少数类样本人工合成新样本添加到数据集中[16]。
通过对“高风险”样本进行SMOTE过采样后,得到新的72组负样本,这样正样本与负样本的数量便达到了1∶1,解决了训练样本不均衡的问题。
2.2 预警模型构建
通过数据预处理阶段获得训练样本后,便可以选择合适的机器学习分类算法进行预警模型的训练。为得到性能最优、预测效果最佳的模型,本文选用了多个流行的机器学习算法进行评估。模型训练均在MATLAB R2020a软件环境下完成,具体流程包括:
(1)划分训练集、验证集和测试集。本文随机选取了156组样本中的110组样本作为训练集(包含正、负样本),剩余46组样本作为测试集。因为本研究样本的特征数据数值均在[0,1],省去了数据标准化的过程。
(2)分别采用决策树[17](最大分裂数为100)、朴素贝叶斯[18]、支持向量机[19](线性核函数)、k近邻[20](邻点个数为5)4种机器学习分类算法构建分类模型,使用110组训练样本作为训练集训练模型。采用k折交叉验证(本研究中k=5)评估模型性能。4种分类算法训练出的模型结果如图2和图3所示。

(a)决策树 (b)朴素贝叶斯 (c)支持向量机 (d)k近邻图2 采用均衡样本训练出的模型准确度及混淆矩阵

(a)决策树 (b)朴素贝叶斯 (c)支持向量机 (d)k近邻图3 采用未均衡样本训练出的模型准确度及混淆矩阵
(3)使用训练好的模型对预留的测试集进行分类,根据式(13)将其用于计算分类准确性[21]。
(13)
式中,TP为正确识别的正样本数量;TN为正确识别的负样本数量;FP为正样本总数量;FN为负样本总数量。
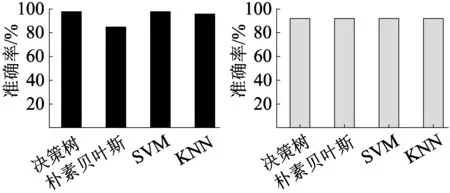
同时,本文也使用未均衡样本对上述4种机器学习算法模型进行了训练,采用59组样本数据(包含正、负样本)作为训练集训练模型,采用5折交叉验证法验证模型性能,最后使用训练好的模型对预留的测试集(25组样本数据)进行分类,计算分类准确性。最终的模型分类性能如图4~图6所示。

(a)决策树 (b)朴素贝叶斯 (c)支持向量机 (d)k近邻图4 采用均衡样本训练的模型预测测试集的准确度及混淆矩阵

(a)决策树 (b)朴素贝叶斯 (c)支持向量机 (d)k近邻图5 采用未均衡样本训练的模型预测测试集的准确度及混淆矩阵
(a)训练集1(均衡样本) (b)训练集2(未均衡样本)图6 均衡样本与未均衡样本训练集的预警模型训练结果
被预警模型分类为“高风险”的加气站在此时的状态下将有很高的概率发生事故,应及时采取措施降低安全风险。
2.3 结果分析
从结果来看,预测能力最好的是采用均衡样本训练的决策树算法和支持向量机算法构建的风险预警模型,两者准确度达到97.83%;而朴素贝叶斯算法构建的风险预警模型性能最差,其准确度仅为84.8%。
采用未均衡样本训练的模型准确率均为92%,但从混淆矩阵中可以明显看出,采用未均衡样本训练的模型对负样本的预测全部失败了,这说明未均衡样本训练的模型泛化性能非常差[22]。相比之下,采用均衡样本训练的模型,除朴素贝叶斯模型之外,其他3种模型均实现了对负样本的准确预测,准确率较高。样本经过SMOTE算法处理后解决了样本不均衡问题,在测试集和训练集中均有较高的准确率,能较好地识别加气站的风险状态。
3 结论
(1)按照人员、设备设施、安全管理、环境安全4个因素建立了加气站风险预警指标体系,选取了适用于人工智能技术解决方案的较全面、可量化、可采集、可监督的数据指标,为加气站风险预警研究进行了初步尝试,并为机器学习技术的引入提供参考。
(2)在数据采集过程中,难以避免会产生正负样本数据量不均衡的情况。在现实情况下,企业安全生产和运营的过程中不会经常发生事故,异常状态的样本往往是少数。本文通过SMOTE算法均衡样本数据,提高了模型的泛化能力,均衡样本后训练出的模型能很好地实现对负样本的预测。
(3)SMOTE算法均衡样本后,采用决策树算法和支持向量机算法构建的预警模型预测准确度达到97.8%,相比未均衡样本训练出的模型准确度提高了5.8%。采用k近邻算法构建的预警模型准确度也达到95.7%,可以很好地实现对加气站风险高低的识别与预警。
(4)本研究构建的预警模型在一定程度上依赖于大数据的训练,而受制于客观条件,本文在训练模型时采用的样本数据规模不大。随着预警模型在加气站的上线应用,采集的数据会越来越多,应用新的数据对预警模型进行训练和优化,可以不断提高模型的准确度。
(5)本文构建的预警模型监测的数据类型较多,但只能从宏观角度预测加气站的风险高低,一旦加气站被识别为“高风险”,则认为加气站正处于不安全状态,将会有较大可能性发生事故,也不排除可能存在与事实不符的情况。如何通过检测指标对可能转变为不安全状态的加气站进行提前识别仍有待深入研究。
