公共人工智能平台在膝关节骨性关节炎分期中的应用
2022-05-17赵晓阳许树林潘为领唐慧勇张守波
赵晓阳, 许树林, 潘为领, 唐慧勇, 张守波
(中国人民解放军第960医院淄博医疗区, 山东 淄博, 255300)
膝关节骨性关节炎(KOA)是常见的慢性退行性骨关节病,以疼痛和功能障碍为特征[1-2]。KOA严重影响患者生活质量,给其家庭和社会造成严重的经济负担[3]。KOA准确分期可避免患者病程的快速进展[4]。目前,骨关节炎(OA)常用的3种分期方法[5-6]中, Kellgren-Lawrence (KL)分期使用最广泛,其结果与疼痛及功能障碍相关,且术前KL分期能预测手术成功率。但人工分期不仅耗时,还会因个人主观偏倚存在差异。传统人工智能模型的建立需要大量的专家和资源,普通医师难以获得。近年来,谷歌、百度等集团提供了公共人工智能云平台,使普通医师能够在没有人工智能经验的情况下建立人工智能模型。但关于公共人工智能平台对KOA自动分期效果的研究较少。故本研究探讨利用公共人工智能平台对KOA严重程度自动分期的可行性。
1 资料和方法
1.1 一般资料
骨关节炎倡议(OAI)是有关KOA研究的公共数据库,其可供公众调阅使用。拍摄X线片: 由2名训练有素的肌骨放射学医师使用KL系统[7-9]对每张X线片的每个关节进行分期。如有分歧,则由第3位医师协议解决,最终公布的为共识结果。
本研究下载了一组按照KL分期完成分组的数据。训练模型最多时使用了其中5 777个关节X线片,并在训练过程中进行了不同数据集的多次训练,以求获得最佳的模型方案,模型训练在百度公共人工智能平台EasyDL(https: //ai.baidu.com/easydl/)中进行。该平台提供免费的人工智能培训、评估和基于图像的预测、分类。该平台计算能力出色,每个模型都可在20 min内完成训练并进行自我评估[11-14]。平台分别随机选择图像进行训练,并使用约为上传数据集30%的数据进行自我评估。之后,平台返回本研究模型整体的准确率、F1-score、精确率、召回率以及按照每一个KL分期的F1-score, 用以评价模型价值。训练过程中,本研究通过调整图像数据集,训练了多个迭代版本,最终得到效果最好的模型。其中不同的训练集以OAtrain加不同下标命名,例如OAtrain 5.0, 各版本所用训练及测试数据集详情见表1。
1.2 医师评价
为了判断OAI(作为标准)、人工智能模型和单个医师之间的评分一致性,本研究选取了2名高年资放射科副主任医师进行KL评分(在应用KL评分系统方面具有多年经验)。然后按照KL分期,从每个KL等级分别随机选择10张X线照片,构成总量为50张图像的测试集(命名为50-test), 以供上述医生评分。

表1 训练及测试数据集详细信息
50-test: 图像与训练数据集均无重复。
1.3 数据预处理及模型训练
训练使用的图像格式为PNG, 分辨率为299像素×299像素。利用多个不同的数据集和多个训练参数进行组合训练,得到多个迭代版本。
1.4 效能评估
使用F1-score和加权Kappa系数进行效能评估,其可反映整体及每个KL分类的效能,而且其他关于KL分期的研究中也使用了该参数,使得本研究能够与之进行比较。F1-score对某类别而言为精确率和召回率的调和平均数,范围为0~1, 其中1表示完全一致。对于多类分类,平台及本研究分别计算每个分类的F1-score, 并对结果进行平均。Kappa系数的大小用来衡量2种方法的一致程度,Kappa系数越大说明2种结果越一致,若Kappa≥0.75, 说明结果一致性较好,若Kappa<0.40, 说明缺乏一致性[14]。
1.5 统计学分析
使用SPSS 26.0及Python 3.8软件进行数据分析,计算加权Kappa系数、准确率、召回率和F1-score, 并对结果进行直接比较。
2 结 果
2.1 模型训练
以OAI的分期结果为标准,在百度公共人工智能平台,经过多次迭代训练,各版本效能结果显示, 5级V4版本效能最好,其中F1-score为0.72, 准确率为0.73, 见图1、表2。

图1 5级V4版本平台整体评估结果截图

表2 各版本效能统计
2.2 KL分期系统效能比较
对于50-test测试子集,本研究2位医师的F1-score和准确率分别为0.63和0.64。模型对该测试子集的F1-score为0.69,准确率为0.70。模型对单个KL分期0期、3期和4期的F1-score超过了医师,而医师的KL分期为2期的F1-score更高,另外对KL分期为1期的F1-score两者相等。这些结果可与THOMAS K A等[10]报告的F1-score进行直接比较。同时,因为子集包含来自每个KL分类的相等数量的图像,所以这些得分结果可以直接与ANTONY J等[12]研究中报告的加权F1-score进行比较。见表3。
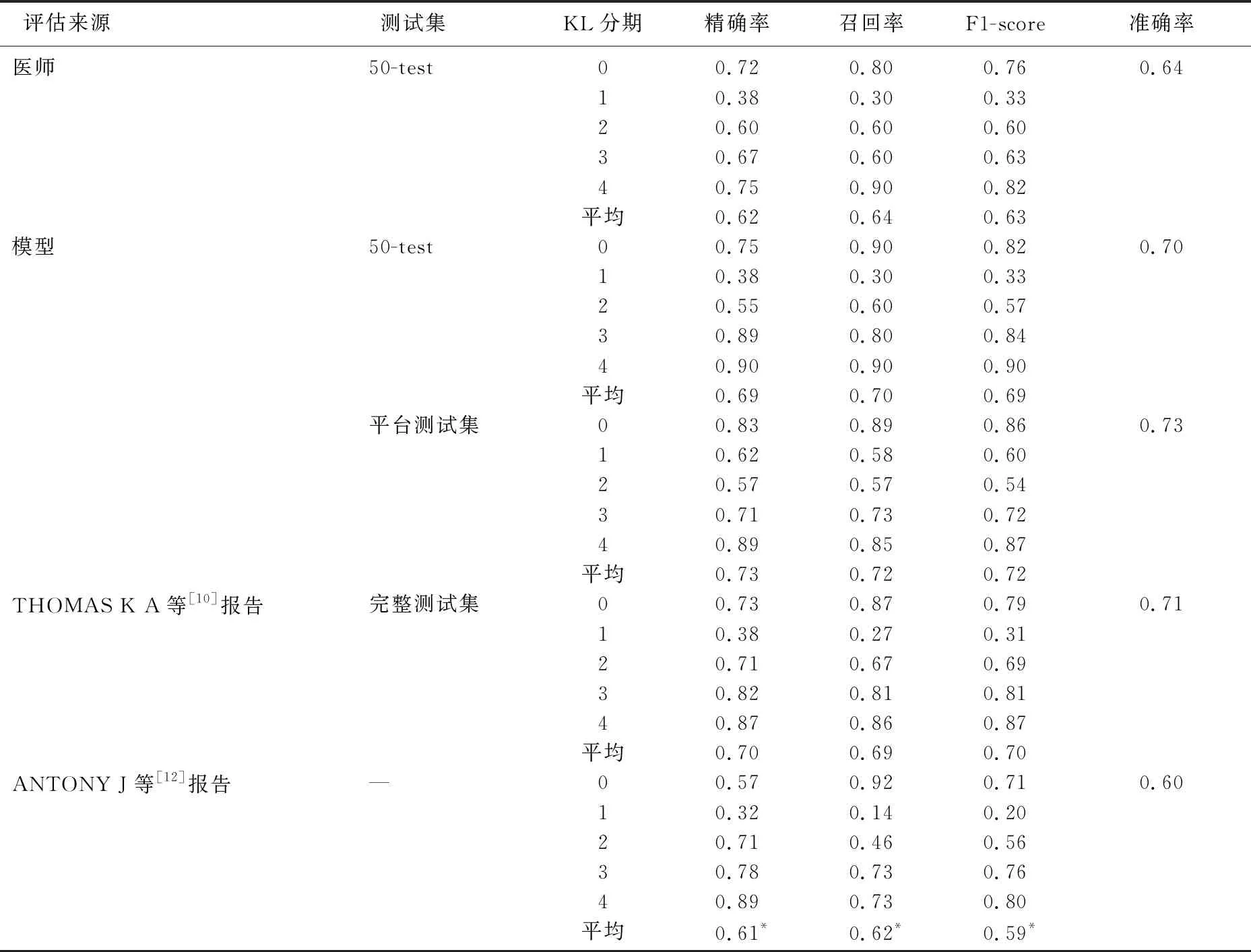
表3 在KL分期系统中医师及各模型效能比较
2.3 发病率效能比较
KL分期系统中2期特别重要,因为在使用KL分期系统进行队列选择时,其经常被用作确定OA发病率的阈值[10]。为了评估模型,确定OA发病率模型的效能,本研究将0期和1期的KL评分合并到一个类别中,并将2期、3期和4期的KL评分合并到另一个类别中。本研究对此在百度人工智能平台中重新训练了相应的模型,该模型的总体F1-score和准确率均达到了0.91, 而针对50-test测试子集, F1-score为0.89, 准确率为0.90。2位医师对此效能的得分为F1-score为0.87, 准确率为0.88。见表4。
平台测试集准确率原始数据为 308/424, 完整测试集准确率原始数据为2 890/4 090。

表4 在发病率判断中医师及各模型效能比较
2.4 一致性评估
在以OAI为标准一致性评估时,在50-test测试子集中医师的加权Kappa系数为0.76, 此测试子集的模型获得的加权Kappa系数为0.82, 模型对完整测试集的加权Kappa系数为0.82, 与THOMAS K A等[10]报告的0.86及TIULPIN A等[13]研究模型的最佳Kappa系数0.83相近,见表5。

表5 评价者与金标准一致性比较
在评估评价者之间一致性时,医师与模型之间的加权Kappa系数分别为0.75和0.74。医师之间的加权Kappa系数为0.76, 略低于THOMAS K A等[10]报告中的医师间加权Kappa系数0.79, 高于RIDDLE D等[15]报告中最一致的2个评价者之间的Kappa系数0.65, 见表6。

表6 不同研究医师间一致性比较
3 讨 论
目前, KOA的发病率日益增高,而其诊断和分期依据主要为影像学检查结果,因此进行准确的影像学分期,对KOA的治疗和预后有重要意义。本研究利用公共人工智能平台建立模型,实现对KOA的自动分期,并取得了良好的效果。
从本研究训练的模型的表现来看,无论是对KOA按照KL分期系统进行5期分期,还是在KOA发病率的判断上,本研究模型均取得较好的效能,许多表现达到甚至超过了本研究的高年资医师。本研究针对KL分期系统的整体效能达到F1-score为0.72, 准确率为0.73, 与之前研究中THOMAS K A等[10]模型的F1-score(0.70)、准确率(0.71)相近。在发病率模型测试中,本研究模型F1-score为0.91, 优于THOMAS K A等[10]报道的0.87, 说明本模型在发病率判断中的表现较优。在各项一致性评估中,本研究的模型加权Kappa系数为0.82, 略低于THOMAS K A等[10]报告的0.86及TIULPIN A等[13]研究模型的最佳Kappa系数0.83, 但仍可表明其具有较好的一致性,与之前的研究差异较小。
本研究提出的临床医师利用公共人工智能平台训练模型和利用X线片对KOA进行自动KL分期具有可行性和一定的优越性。首先,由于模型是在云平台上自动、迅速地进行训练,因此其在普通个人的计算机上便可运行,不需要专门的、价格高昂的计算机设备及人工智能专业知识储备。本研究在百度公共人工智能平台所建立的模型的效能可以达到甚至超出经验丰富的医师的评估效能。其次,既往研究往往依赖于手动标注,对图像进行标注可能会增加噪声和错误的发生,并且需要额外的时间和人力成本。而本研究模型只需上传图片数据即可,其操作简单、便捷,即使毫无人工智能经验的医师也可进行操作。既往研究往往需要大量的原始图片数据,比如THOMAS K A等[10]研究总共使用了40 280张图像,而本研究最终使用1 445张图像进行模型训练,且取得了与其模型相当的效能结果。本研究还发现,提高模型训练效果的重要因素除增大数据量,还需每个子分类的数据量相当,这一点百度公共人工智能平台在训练时也进行了相应提示。在本研究模型训练过程中,子分类数据量比例失调的数据集得到的结果更好,且选择AutoDL Transfer算法,在训练时间及效果上均具有良好表现,推荐在训练模型时选择此算法。
本研究使用的公共人工智能模型本质上是一个分类器,平台可以根据本研究提供的不同类别的图像进行模型训练。因此,公共人工智能平台的潜能不仅限于本研究范围内,在其他医疗领域范围同样具有巨大潜能。随着越来越多的公共人工智能平台出现,更多的基层普通医师可以获得人工智能服务。本研究认为,公共人工智能平台将促进医学和人工智能的共同发展。本研究仍具有一定局限性。首先,本研究使用相对较小的训练数据集来训练模型,随着训练数据集的增加,模型的性能可能会被影响。其次,本研究将模型性能与仅使用50张图像进行测试的医师的评估结果进行比较,医师测试样本相对较小,结果可能存在偏差。此外,本研究模型是针对标准的膝关节X线片设定,对一些特殊体位或不标准位置的图像的分类效果无法判断。
综上所述,本研究使用公共人工智能平台进行模型训练,利用X线图像进行KOA的自动KL分期,具有可行性和优越性,为利用人工智能平台进行临床研究与工作提供了良好依据。
