多尺度特征增强的SSD目标检测算法
2022-05-16高娜,吴清张满囤
高娜, 吴清 张满囤

摘要 针对目标检测中多类别、多尺度和背景复杂而导致的SSD(Single Shot Multibox Detector)算法检测精度不高的问题,提出了一种多尺度特征增强的改进SSD目标检测算法。首先将SSD网络模型的高层特征依次向下与浅层特征融合,构造一种多尺度目标检测结构。然后利用注意力机制对特征进行进一步的优化,从而达到增强网络模型特征提取的目的。最后用DIoU-NMS来处理图像目标中冗余框的问题,减少目标的漏检。在公开的NWPU VHR-10遥感数据集上将该方法与其他算法进行对比实验,其mAP较传统的SSD算法提高了6.7%。最后将改进后的算法应用于地铁安检图片检测,并在此数据集上进行消融实验来验证此算法每一阶段的有效性。
关 键 词 目标检测;多尺度;特征融合;注意力机制;特征增强
中图分类号 TP391.41 文献标志码 A
Multi-scale feature enhancement based SSD algorithm
GAO Na, WU Qing, ZHANG Mandun
Abstract Aiming at the low detection accuracy of the SSD (Single Shot Multibox Detector) algorithm caused by the multi-category, multi-scale, and complex background in object detection, an improved SSD object detection algorithm with multi-scale feature enhancement is proposed. First, the high-level features of the SSD network model are sequentially merged with the shallow features to construct a multi-scale object detection structure. Then the attention mechanism is used to further optimize the features, so as to enhance the feature extraction of the network model. Finally, DIoU-NMS is used to deal with the problem of redundant boxes in the image object and reduce the missed detection of the object. In the public NWPU VHR-10 remote sensing data set, the method is compared with other algorithms, and its mAP is improved by 6.7% compared with the traditional SSD algorithm. Finally, the improved algorithm is applied to the subway security inspection image detection, and an ablation experiment is performed on this data set to verify the effectiveness of each stage of the improved algorithm.
Key words object detection; multiscale; feature fusion; attention mechanism; feature enhancement
引言
隨着深度学习在图像目标检测中的广泛应用,如何更有效地解决背景复杂度高、目标方向不确定、目标尺度多变、小目标居多且密集出现等情况下的检测精度和效率低的问题,成为一个极具挑战性的课题[1-2]。
基于深度学习的目标检测方法主要分为2类,一类是基于候选区域的深度学习目标检测算法(two-stage),典型的算法有Faster RCNN[3]、FPN[4]、Cascade R-CNN[5]、TridentNet[6]等。这类检测算法的精度较高,但是检测流程均包含多个阶段,实现过程复杂。另一类是基于端到端的深度学习目标检测算法(one-stage),与 two-stage类方法相比结构更简单,它将所有计算封装在一个网络中,可以实现端到端的优化。One-stage网络的典型的代表算法有SSD[7]、YOLO系列[8]、CornerNet[9]、CenterNet[10]、EfficentDet[11]等。
SSD算法是一种直接预测目标类别和边界框的多目标检测算法,它充分利用了多卷积层的优势来对目标进行检测,对目标的尺度变化具有较好的鲁棒性。主要是利用Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2这6个不同尺度的特征层做检测,将不同特征层得到的结果送入检测器,最后利用非极大值抑制方法(Non-Maximum Suppression,NMS)剔除图像中的冗余框。SSD中的6个特征层互相都是独立使用的,忽略了不同特征层之间的联系,并且没有用到足够低层的特征,导致SSD对小尺寸目标的识别比较差。为提高小目标的检测精度,DSSD[12]使用更加复杂的ResNet-101替换VGG16来增强网络的特征提取能力,但复杂的网络结构增加了参数量和计算量,导致检测的实时性较差。为了改善小目标检测效果和提升框架对多尺度目标的检测能力,出现了融合多层特征的思想。Feature Pyramid Network(FPN)和Top Down Modulation (TDM)[13]以自顶向下的方式融合不同的特征层,将语义信息从高层融合到低特征层,对小物体的识别起到了很大的帮助,说明了高层语义的细节特征提取的重要性。RSSD[14]采用rainbow连接的方式,结合pooling和反卷积来融合不同的特征层,在一定程度上解决了小目标的检测问题。FSSD[15]将不同尺度的特征层融合在一起,通过下采样子模块生成新的特征金字塔层用于目标检测,提高了SSD的精度。因此如何将低层和高层的特征层结合起来构造金字塔结构对目标检测性能有很大影响。另一方面,背景复杂及目标尺度小的问题,增加了获取需要重点关注的目标区域的难度。注意力机制源自于人类视觉感知,我们关注一幅图像时,总能被一些显著性区域所吸引,从而快速地专注于感兴趣的目标。受这种现象的启发,SENet(Squeeze and Excitation Networks)[16]在CNN分类网络上引入了通道注意力模块,赢得了最后一届ImageNet 2017竞赛分类任务的冠军。之后,Woo等[17]提出的卷积注意力机制(Convolutional Block Attention Module, CBAM)在通道和空间维度上学习关注什么,在哪里关注。2019年,SKNet(Selective Kernel Networks)[18]对SENet进行改进,提出了针对卷积核的注意力机制研究。马森权等[19]在SSD网络框架中引入注意力模块来有效提取小目标的特征信息,提升了检测精度。为此本文考虑使用注意力机制对特征进一步的优化,使SSD算法中的特征层更好的适应复杂背景中小目标检测。
1 本文方法
1.1 检测框架
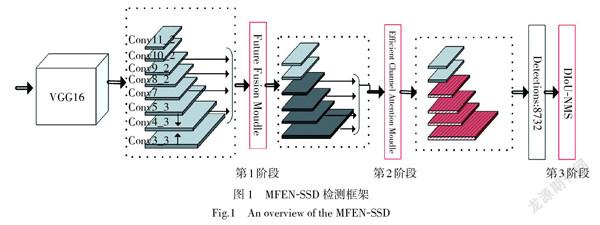
本文提出了一种多尺度特征增强的目标检测框架(Multiscale Future Enhanced Network,MFEN)。如图1所示,MFEN-SSD算法保留了SSD的前馈深度卷积网络VGG16,在SSD原有特征层的基础上新加入特征层Conv3_3和Conv5_3,这两个特征层的感受野相对较小,可以保留较多的细节信息,对小目标比较敏感。本文的网络结构分为3部分,第1阶段为特征融合(Feature Fusion,FF),新加入的特征层和基础骨干网络的特征层(包括Conv4_3、Conv7、Conv8_2、Conv9_2) 进行特征融合,融合后的特征层语义和定位特征表达能力均得到提升,除用于进行预测外,还将作为下一个阶段的初始特征。第2阶段为特征增强,在融合后的特征层后面嵌入ECA(Efficient Channel Attention)模块[20],通过适当的跨通道交互策略实现通道注意力的学习,以提高图像中目标物体的特征提取能力。它可以将注意力集中在需要关注的细节信息上,并且可以抑制背景等无关信息,极大的提高了信息处理的效率与准确性。第3阶段为冗余框的处理,使用DIoU-NMS[21]方法来解决漏检问题。
1.2 基于特征融合的特征提取网络
SSD网络结构与用于特征提取的图像金字塔类似,都属于多尺度网络结构。随着卷积层的数量增多,特征层的尺度越来越小。其中低层特征层分辨率高,具有丰富的位置信息,但由于缺乏高层特征的语义信息,导致低层特征对小目标的分类效果较差,影响最终的检测结果。高层特征层感受野大,语义信息表征能力强,适合检测大目标。本文受FPN特征融合思想的启发,将高层特征层通过反卷积操作依次向下与低层特征进行融合,使得低层特征的语义表征能力得到增强。融合后的多尺度结构如图2所示,将MFEN-SSD网络中的Conv3_3、Conv4_3和Conv5_3分别记为[D0]、[D1]和[D2]。为保持最终用于预测的特征图的大小和数量不变,先对这三个低层特征进行特征融合,即:
式中:Conv2D代表二维卷积算子;Resize表示上采样或者下采样的操作,用于分辨率的匹配;“+”表示特征在通道上的堆叠。将Conv7、Conv8_2、Conv9_2分别记为:[D4]、[D5]、[D6]。由于分辨率太小的特征层进行融合几乎不会提高检测精度,反而会降低检测速度,因此本文选取{[D3]、[D4]、[D5]、[D6]}作为特征金字塔网络结构自底向上的路径。为了使不同层次特征图的上下文信息进行有效的融合,本文增加了一个Top-Down神经网络作为自底向上前馈网络的补充,并使用侧向连接方式。自底向上的前馈网络获取的高层语义特征由自顶向上的网络反馈回来,经过侧向连接与中间特征层进行融合,同时继续向下传递。最终网络的输出特征层既捕获了细节特征又获取了高层信息,并且预测是在每个融合后的特征层上单独进行的。这些特征层的计算过程如下:
式(2)中的N = 3,4,5,6,式(3)和式(4)中的N = 3,4,5。[d]代表维度,在融合之前先将自底向上路线中的特征层维度统一成256-d,k表示卷积核尺寸的大小。为了减小参数量和计算量,使用分组卷积(Group Convolution)将标准的卷积分为g组,在对应的组内做卷积,并在分组卷积之后加入通道混洗(Channel shuffle)[22]操作使得組间的信息可以交流,最后得到通道混洗后的输出。[CN]表示自底向上线路中经过降维得到的特征层,[TN]表示自顶向下线路和侧面横向连接形成的新特征,[Q(?)]为将[Ti]通过反卷积操作调整到和特征层[CN]一样的尺寸。在进行特征融合之前都使用ReLU函数进行激活操作,在融合之后还会用3×3大小的卷积核对融合后的特征层[TN]进行卷积,目的是消除上采样带来的混叠效应。[FN]表示自顶向下线路的输出特征,随着N的减小,[FN]的特征信息被不断地丰富与完善,使得同一特征层上可以覆盖不同尺度的目标,增加了网络模型的泛化能力。其特征融合结构如图3所示,GConv代表分组卷积,采用的特征融合方式为Conact。与原SSD网络每层特征层检测特定尺寸的目标相比,本文提出的网络将上下文信息进行了有效融合,因而更适合图像中多类别多尺度目标的检测。
1.3 注意力机制ECA模块的使用
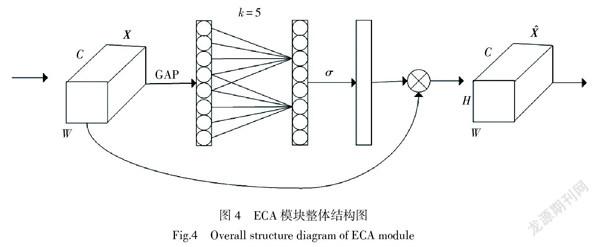
为了在不增加网络模型复杂度的同时解决图像中的小目标及背景复杂的问题,本文在运用特征融合后的网络架构上引入一种有效的通道注意力(Efficient Channel Attention, ECA)模块。该模块通过适当的跨通道交互策略实现通道注意力的学习,可以显著降低模型的复杂度同时保持性能。本文将ECA模块嵌入到融合后的特征层{F3、F4、F5、F6}后面,这1阶段为图1所示的第2阶段。如图4所示,对于给定的一个输出的特征[X∈RH×W×C],其中W、H和C分别表示特征层的宽度、高度和通道尺寸。首先采用不降维的全局平均池化(global average pooling)将一个通道上的整个空间特征编码为一个全局特征,之后通过快速一维卷积来实现每个通道及其k个相邻通道的局部跨通道信息交互,其公式为
式中:C1D表示一维卷积;[k]是卷积核的大小,表示局部跨通道交互的覆盖率,与通道的C成正比,计算公式为
式(6)表示C和k之间的映射关系,γ=2,b = 1。[todd]表示t的最接近奇数。最后将学习到的通道权重和原始的特征X相乘来进行特征通道加权,得到最后的输出特征层[X∈RH×W×C]。经过整个操作,模型可以将它的注意力集中到最有用的通道上,从而达到增强有用信息的作用。
1.4 用DIoU-NMS 替换NMS
在对图像进行目标检测时,多个特征层最后会产生大量的候选框,但是这些候选框中存在着大量错误的、重叠的和不确定的样本。传统的SSD算法是利用非极大值抑制算法(Non Maximun Suppression, NMS),通过设置交并比(Intersection-over-Union, IoU)阈值来去除多余的检测框,其只考虑了重叠区域。当2个物体离得很近时,由于IoU的值比较大,经过NMS处理后只剩下1个检测框,会导致漏检现象的发生,并且图像中经常会出现目标紧邻的问题。为了克服NMS在此应用场景中的不利,本文用Distance-IoU (DIoU) NMS替换原本的NMS。和原始的NMS相比,本文的DIoU-NMS不仅考虑了IoU的值,还考虑了2个候选框之间的距离,将这2个因素作为是否删除候选框的条件。其公式为
式中:[si]是分类置信度;[ε]为NMS阈值;M是最高置信度的框;[RDIoU]可以用式(9)来表示:
式中:[d=ρ(b,bgt)]是框b和框[bgt]的中心点之间的距离;[c]表示能够同时覆盖2个框的最小矩形的对角线的长度,如图5所示。
2 实验结果与分析
本文实验是基于Intel(R) Core(TM) i7-4790K CPU @ 4.0 GHZ处理器和单GPU NVIDIA GTX 1070 Ti,采用Pytorch开源深度学习框架完成的。
选择航天遥感目标检测数据集NWPU VHR-10作为实验数据集。此数据集是1个多类多尺度且小目标众多的目标检测数据集,提供了650张包含目标的光学遥感图像,共含有实例样本3 896个,包括飞机、油罐、车辆、篮球场等10个类别。NWPU VHR-10数据集属于小样本数据集,因此需要运用数据增强来人为的增加训练样本的数量。首先按照VOC2007数据集格式的标准,将数据集中的图片随机的分成了60%的训练集、20%的验证集和20%的测试集,图6为划分的训练集、测试集和验证集中包含的每个类别的目标数量。本文对其中的训练集进行水平翻转、旋转90°、180°和270°。
本实验使用VGG16作为预训练的模型,训练共迭代120 000次,批处理大小为32,初始学习率设置为0.001,随机梯度下降SGD的权重衰减为0.000 5,动量因子设置为0.9。
实验选择平均精确度均值(Mean Average Precision,mAP)和准确率-召回率(Precision-Recall)曲线图作为图像多个类别的目标检测的评价标准。AP即为PR曲线所包围的面积,可以表示为
式中:[P]和[R]分别表示准确率和召回率,可以根据TP(True Positive)、FP(False Positive)、TN(True Negative)和FN(False Negative)来计算:
根据衡量每个类别检测效果的AP即可得出
图7是SSD算法和本文的MFEN-SSD算法在NWPU VHR-10測试集下10个类别的PR曲线对比图,不同颜色的曲线表示不同的类别。可以看出本文的MFEN-SSD算法对应的PR曲线包围的面积更大,对车辆和网球场等类别的提升效果明显。
表1给出了本文算法和另外6种典型的目标检测算法在NWPU VHR-10数据集中对10个类别进行检测的精确度的对比。通过结果可以看出本文所提算法的平均准确率有着显著的提高,相比RICNN[23],FR(Faster R-CNN)[3],YOLOv3[24],Grid R-CNN[25],Cascade R-CNN[5]和SSD[7]分别提升15.3%,6.9%,3.7%,3.5%,0.2%和 6.7%,对尺寸差异过大的目标物体均有较好的检测效果。基于CNN的RICNN算法的检测效果最差,且运算时间最长,在网球场、篮球场和桥梁等类别的检测率很低,它采用的是选择性搜索算法,所以该算法的计算复杂度也比较高。SSD算法的检测精度比FR算法较高,验证了这种多尺度特征金字塔网络结构模型对于多类别多尺度目标的建模能力较强。YOLOv3采用了更深的网络层次以及多尺度检测,在飞机储油罐和车辆等小目标上检测结果比较好。Grid R-CNN和Cascade R-CNN是对FR算法的改进,检测精度比FR分别高3.4%和6.7%。本文提出的MFEN-SSD算法不仅构建了类似FPN结构的多尺度特征金字塔结构来适应图像的多尺度特征,而且引入的注意力机制对感兴趣区域投入更多的关注,在牺牲较小运算时间的同时大大的提高了目标的识别率与准确率,但需要进一步提升和改善在储油罐和车辆目标的检测精度。其部分可视化检测结果如图8所示。
表2是本文各模块在NWPU VHR-10数据集上的消融对比实验。从表中结果可以看出,本文对网络的3方面改进有效地提高了平均检测精度。
为了进一步验证MFEN-SSD算法的通用性和有效性,将本文算法应用于地铁安检图片检测。表3为在该数据集上对本文各模块的消融实验对比,可以看出本文算法比传统SSD的检测精度提高了13.9%。首先需要借助目标检测标注工具LabelImg将地铁安检数据集制作成Pascal VOC2007的格式,主要作用是对所有的原始图像中的目标位置进行标注,每张标注完的图片都会生成一个相应的xml文件,表示目标真实边界框的准确位置。本文所用的数据集将打火机、黑钉子、刀具、电池、剪刀5个类别分别用数字1、2、3、4、5来表示,最后共生成981个对应的xml文件。随后将981张图片随机的分成了60%的训练集、20%的验证集和20%的测试集,并在送入网络前对训练集进行水平翻转、旋转等数据增强操作来扩充训练集的图片数量。
表4为上述序号1~8的消融实验对应的每个类别的具体检测精度差异。可以看出本文所提算法的每1个阶段单独和任意2种组合使用时都对mAP有不同程度的提高,当3个阶段同时使用时,地铁安检图片的检测精度达到了最高值77.4 %。
图9 中a)是传统SSD算法的检测结果图,b)为本文MFEN-SSD算法的检测结果图。可以直观地看出,和传统的SSD算法相比,本文MFEN-SSD算法具有更好的检测结果。它可以检测到大部分SSD算法漏检的小目标,该算法降低小目标漏检率,同时也提高了平均检测准确率。
3 结论
本文提出了一种多尺度特征增强的改进SSD目标检测算法MFEN-SSD。该模型以VGG16作为基础的特征提取网络,首先将高层和低层的特征层进行融合,形成高分辨率高语义信息的特征层,使得模型能够更好地实现多尺度目标检测。随后通过注意力机制模块对特征进行进一步优化,将注意力集中在需要投入更多精力的细节信息上,并且抑制无用信息。最后对产生的冗余框进一步处理来减少目标的漏检。在遥感数据集NWPU VHR-10上进行了实验验证,并和SSD算法以及当前一些典型的目标检测算法进行分析与比较。实验结果表明MFEN-SSD的性能在平均精度上优于其他算法。在地铁安检数据集上的拓展实验也进一步证明了该算法的通用性和有效性,提高了对小目标的检测精度。
參考文献:
[1] 刘小波,刘鹏,蔡之华,等.基于深度学习的光学遥感图像目标检测研究进展[J].自动化学报,2021,47(9): 2078-2089.
[2] 寇大磊,权冀川,张仲伟.基于深度学习的目标检测框架进展研究[J].计算机工程与应用,2019,55(11): 25-34.
[3] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN: towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6): 1137-1149.
[4] LIN T Y,DOLL?R P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.July 21-26,2017,Honolulu,HI,USA.IEEE,2017: 936-944.
[5] CAI Z W,VASCONCELOS N.Cascade R-CNN: delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018: 6154-6162.
[6] LI Y H,CHEN Y T,WANG N Y,et al.Scale-aware trident networks for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27 - November 2,2019,Seoul,Korea (South).IEEE,2019: 6053-6062.
[7] LIU W,ANGUELOV D,ERHAN D,et al.SSD: single shot MultiBox detector[C]// Computer Vision – ECCV 2016,2016: 21-37.
[8] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[9] LAW H,DENG J.CornerNet: detecting objects as paired keypoints[J].International Journal of Computer Vision,2020,128(3): 642-656.
[10] DUAN K W,BAI S,XIE L X,et al.CenterNet: keypoint triplets for object detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27-November 2,2019,Seoul,Korea (South).IEEE,2019: 6568-6577.
[11] TAN M X,PANG R M,LE Q V.EfficientDet: scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020: 10778-10787.
[12] FU C Y,LIU W,RANGA A,et al.DSSD: deconvolutional single shot detector[EB/OL].(2017). https://arxiv.org/abs/1701.06659
[13] SHRIVASTAVA A,SUKTHANKAR R,MALIK J,et al.Beyond skip connections: top-down modulation for object detection[EB/OL].(2017).https://arxiv.org/abs/1612.06851
[14] JEONG J,PARK H,KWAK N.Enhancement of SSD by concatenating feature maps for object detection[C]// Proceedings ofthe British Machine Vision Conference 2017.London,UK.British Machine Vision Association,2017: 76.
[15] LI Z, ZHOU F. FSSD: feature fusion single shot multibox detector[EB/OL].(2018). https://arxiv.org/abs/1712.00960v3
[16] HU J,SHEN L,SUN G.Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018: 7132-7141.
[17] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European conference on computer vision. September 8-14,2018,Munich,Germany.Springer,2018: 3-19.
[18] LI X,WANG W H,HU X L,et al.Selective kernel networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 15-20,2019,Long Beach,CA,USA.IEEE,2019: 510-519.
[19] 麻森权,周克.基于注意力机制和特征融合改进的小目标检测算法[J].计算机应用与软件,2020,37(5): 194-199.
[20] WANG Q L,WU B G,ZHU P F,et al.ECA-net: efficient channel attention for deep convolutional neural networks[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:11531-11539.
[21] ZHENG Z H,WANG P,LIU W,et al.Distance-IoU loss: faster and better learning for bounding box regression[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7): 12993-13000.
[22] ZHANG X Y,ZHOU X Y,LIN M X,et al.ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018: 6848-6856.
[23] CHENG G,ZHOU P C,HAN J W.Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images[J].IEEE Transactions on Geoscience and Remote Sensing,2016,54(12): 7405-7415.
[24] REDMON J, FARHADI A. Yolov3: an incremental improvement[EB/OL].(2018). https://arxiv.org/abs/1804.02767.
[25] LU X,LI B Y,YUE Y X,et al.Grid R-CNN[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 15-20,2019,Long Beach,CA,USA.IEEE,2019: 7355-7364.
收稿日期:2020-10-31
基金項目:河北省自然科学基金(F2019202054)
第一作者:高娜(1994—),女,硕士研究生。通信作者:吴清(1965—),女,教授,wuqing@scse.hebut.edu.cn。
