基于多尺度分割的图像识别残差网络研究
2022-05-14袁单飞陈慈发董方敏
袁单飞,陈慈发,董方敏
(1.三峡大学 计算机与信息学院,湖北 宜昌 443000;2.湖北省建筑质量检测装备工程技术研究中心,湖北 宜昌 443000)
0 概述
深度卷积神经网络已被广泛应用于图像分类、目标检测、实例分割等领域。在此背景下,如何设计高效的网络模型成为提高网络性能的关键。早期的卷积神经网络(如AlexNet[1]和VGGNet[2])包含了简单的激活函数和卷积结构,使得多尺度特征的数据驱动学习成为可能。ResNet[3]中的残差结构使得更深的网络能够进行有效学习。WRN[4]通过增加残差网络的网络宽度来提高识别精度。Res2Net[5]使用了对残差结构进行多尺度分割的方法来提高识别精度。HS-ResNet[6]对多尺度分割方法进行改进,提出了参数量更小、识别速度更快的网络模型。
通过增加网络的深度和宽度能够产生丰富的特征信息,通过多尺度分割方法能够充分利用特征信息,减少冗余的特征信息。但在增加网络深度和进行多尺度分割的同时,也会减慢网络的识别速度。如何在保证识别精度的同时提高识别速度,成为设计高效网络模型的一个重要目标。本文对HS-ResNet 提出的多尺度分割方法进行改进,提出一种简单的多尺度分割方法,并通过减少网络层数和增加宽度的方法,在保证网络的识别精度和参数量相近的情况下,加快识别速度。
本文结合ResNet-D[7]的残差结构和WRN 增加网络宽度的方法对ResNet进行改进。通过减少网络层数的方法,在CIFAR 数据集上得到网络长度只有7 层的网络模型,并对HS-ResNet 的多尺度分割方法进行优化,得到基于多尺度分割的图像识别残差网络SSRNet。从识别精度和速度两个角度,将该网络与PyramidNet[8]进行比较,以验证网络性能。
1 相关工作
残差网络的出现使得深度学习被广泛应用于生产、生活的各个方面。残差网络通过求解预测值与观测值之间的差值来对拟合函数进行学习,使深层网络能够进行有效学习。近年来,基于残差网络的改进网络大幅提高了网络的识别精度。
1.1 ResNet
在深度学习中,网络层数的增多一般会伴随计算资源的消耗,网络模型容易过拟合,并造成梯度消失、梯度爆炸等问题。随着网络层数的增加,网络模型会出现退化现象,即随着网络层数的增多,训练损失逐渐下降,然后趋于饱和;如果再增加网络的深度,训练损失反而上升。当网络模型出现退化时,浅层网络模型能达到比深层网络模型更好的训练效果,这时如果把底层特征信息传到高层,那么效果应该至少不比浅层网络模型效果差。基于这种使用直接映射来连接网络模型不同层的思想,残差网络ResNet 应运而生。
当输出维度与输入维度不等时,ResNet 需要对输入维度进行升维操作。在ResNet 中直接使用步长为2 的1×1 卷积进行升维,当输入图像大小减半时,会造成特征信息丢失。ResNet-D 以ResNet 为基础,在残差结构升维操作之前加入步长为2 的2×2 均匀池化,然后使用步长为1 的1×1 卷积进行升维,使得网络识别精度大幅提升。
1.2 WRN
随着网络层数加深,训练深度卷积神经网络存在着梯度消失与梯度弥散等问题,实验结果也表明,越深的网络模型带来的识别精度提升并不明显,反而需要降低识别速度[9]。针对网络是否越深越窄效果越好,以及是否只要保证网络参数量,训练一个更宽更浅的网络即可的问题,WRN 提出了基于扩展通道数学习机制的卷积神经网络,以期通过更浅的网络模型来获得与深度网络模型相近的识别精度,以及更快的识别速度。
WRN 通过增加网络宽度能够提升精度,当参数量相同时,WRN 的速度更快。但与残差网络一样,当参数量过大时,其存在梯度消失与梯度弥散等问题。
1.3 Res2Net
在多个尺度上表示特征对视觉任务非常重要。卷积神经网络展示出更强的多尺度表示能力,在广泛的应用中实现一致的性能提升[10-16],如文献[10]提出的多尺度特征提取和多级别特征融合的显著性目标检测方法,文献[11]提出的结合超像素分割的多尺度特征融合图像语义分割算法,文献[13]提出的基于双向特征金字塔和深度学习的图像识别方法,文献[15]提出的轻量级多尺度融合的图像篡改检测算法。在Res2Net 之前的方法大多以特征金字塔[17]分层方式表示多尺度特征。Res2Net 在原有的残差单元结构中通过增加小的残差块来增加每一层的感受野范围,以更细的粒度表示多尺度特征,使得残差单元结构的中间主卷积从单分支变为多分支。
Res2Net 模块结构简单,性能优秀,其在卷积神经网络的3 个维度(深度、宽度和基数)之外,揭示了一个新的尺度维度。Res2Net 模块可以很容易地与其他模块结合,特征提取能力更强大,且不增加计算负载。
1.4 HS-ResNet
HS-ResNet 改进了对特征图多尺度分割的卷积和连接,在提升识别精度的同时,也提高了识别速度。HS-ResNet 主要考虑以下3 个问题:1)如何避免在特征图中产生冗余信息;2)如何在不增加计算复杂度前提下,使网络学习到更强的特征表达;3)如何在得到更高识别精度的同时,保持较快的识别速度。基于这3 个问题,本文设计HS-Block 模块来生成多尺度特征。
当通道数量较大时,Res2Net 方法计算复杂度也随之增加。GhostNet[18]实验结果显示,一部分特征图可以通过已有的特征图生成。HS-ResNet 借助这一思想,在HS-Block 内将S2组卷积得到的特征图部分连接到S3组,实现了特征图复用,降低了计算复杂度。
HS-ResNet 提出了HS-Block 模块,其可高效提取多尺度特征,在多个视觉任务(如图像分类、目标检测和实例分割)上取得了优秀的识别性能。HS-Block 具有即插即用特性,可以轻易嵌入到现有网络中并提升识别性能。
2 HS-ResNet 方法
HS-ResNet 的多尺度分割方法使不同组的特征信息享受不同尺度的感受野。在前面连接进来的特征信息中,卷积次数较少,感受野较小,更关注细节信息;在后面连接进来的特征信息中,卷积次数较多,感受野较大,更关注全局信息。通过不同大小的感受野增加特征信息的丰富性。本文提出的多尺度分割方法,对HS-ResNet 的多尺度分割方法中多次连接合并的操作进行优化,只保留了最后一次连接合并操作,使得识别速度大大提升。
WRN 提出基于扩展通道数学习机制的卷积神经网络,以期通过更浅的网络来获得与深度网络相近的精度,以及更快的识别速度。本文结合WRN 的增加通道数和对网络长度进行缩短的方法,构建长度只有7 层的网络模型,在保证识别精度的同时,进一步提升识别速度。
2.1 网络多尺度分割模块
本文提出3 种多尺度分割网络模型SSRNet,用新的多尺度分割模块SS-Block代替ResNet中的3×3卷积,如图1 所示。当特征信息输入时,执行以下步骤:

图1 SSRNet-a 的SS-Block 示意图Fig.1 Schematic diagram of SS-Block in SSRNet-a
步骤1把1×1 卷积输入的特征信息按通道数平均分割成相等的2 个部分(如果通道数为奇数,则向下取整)。
步骤2一半特征信息直接送到最后进行合并,另一半特征信息进行卷积。
步骤3重复上面步骤,直到最后一个特征信息。
步骤4把最后一个特征信息与前面得到的前一半特征信息进行合并,一起输出给1×1卷积。SSRNet-a的多尺度分割模块与ResNet 的瓶颈模块结构相似,只是把ResNet瓶颈模块中3×3 卷积用SS-Block 替代。其中,SS-Block 的卷积表示为3×3 卷积+批量正则化+Relu激活函数。
3 种多尺度分割网络模型在CIFAR 数据集[19]上的详细结构如表1 所示。其中:模型a 表示只替换了ResNet 瓶颈模块中的3×3 卷积;模型b 表示在模型a的基础上去掉了ResNet 瓶颈模块中2 个1×1 降维和升维卷积;模型c 表示在模型b 的基础上使每次下采样的特征通道数等于第1 组的特征通道数。模型a与模型b 相比,识别精度相似,参数量更小,速度稍慢;模型c 与模型b 相比,识别精度较低,参数量更小,速度更快。
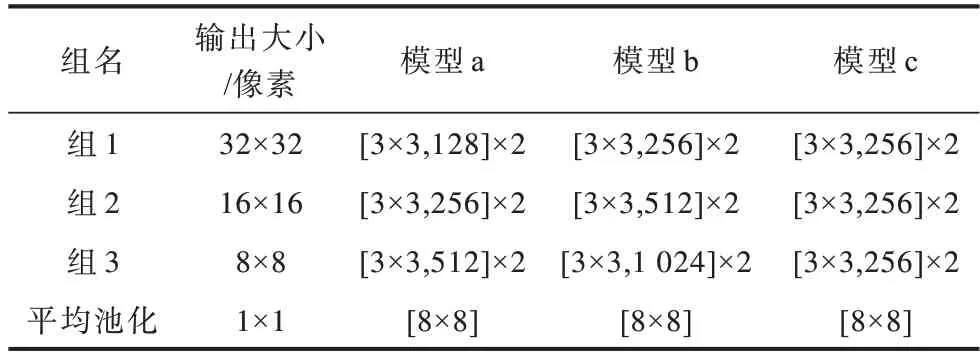
表1 3 种SSRNet 模型的结构Table 1 Structure of three SSRNet models
2.2 网络长度与分割尺度
从AlexNet 开始,深度卷积神经网络通过增加网络长度对多尺度特征信息进行学习来提高网络精度。然而在增加网络长度的同时,会产生减少特征重用的问题。WRN 通过增加网络宽度而不是网络长度来解决这个问题,使得识别速度更快,且网络长度越短,识别速度越快。随着网络长度的增加,卷积神经网络的感受野增大,但并不是全部感受野都对输出特征的贡献相同,感受野的中心区域对输出特征影响更大[20]。笔者通过实验发现,当网络长度设置为感受野大小与输入图像大小比例的1.5~2 倍时,网络的识别精度较高,同时识别速度较快,在精度和速度之间取得了较好的平衡。第k层感受野的计算公式如下:

其中:lk-1是第k-1 层的感受野大小;fk是当前层的卷积核大小;si是第i层的步长。
根据式(1)计算可得SSRNet-a 最后输出感受野大小为51×51 像素,经过3 次尺度分割后感受野为67×67 像 素,恰好为输入 图像大小32×32 像素的1.5~2 倍。该网络模型的长度能在识别精度和识别速度之间取得较好的平衡。
2.3 网络宽度与下采样率
通过增加网络宽度(即特征通道数),可以在保持网络识别速度的同时提高识别精度。但增加网络宽度的同时会增加参数量,所以,网络宽度需要根据具体情况进行设置。当计算能力充足时,可以设置每组的网络宽度相同,不同组的网络宽度依次递增(例如模型a 和模型b);当计算能力不足时,可以设置各组的网络宽度都相同,通过牺牲精度来减少网络模型的参数量(例如模型c)。
当输入图像过大时,通过下采样可以减少模型计算量。输入图像下采样到小尺寸(6×6 像素,7×7 像素,8×8 像素)时比较合适[21]。本文提出的多尺度分割网络模型在CIFAR 数据集上,通过2 次2 倍下采样把输入图像尺寸从32×32 像素缩小到8×8 像素,然后使用均匀池化,把输出特征尺寸变成1×1像素后,进行图像识别。
3 实验与结果分析
在网络模型训练上,本文算法使用飞桨深度学习框架进行实现。实验数据集为CIFAR 10和CIFAR 100,每幅图像都通过随机边缘填充裁剪4 个像素,并通过随机水平翻转进行数据增强,最后进行均值归一化。训练环境为百度的AI Stduio,GPU 为Tesla V100。
3.1 实验数据集
CIFAR 10 和CIFAR 100 被标记为8 000 万个微小图像数据集的子集,由Alex Krizhevsky、Vinod Nair 和Geoffrey Hinton 收集。
CIFAR 10数据集由10个类的60 000个32×32像素的彩色图像组成,每个类有6 000 幅图像,共50 000 幅训练图像和10 000幅测试图像。10个类别分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。
CIFAR 100 数据集与CIFAR 10 数据集类似,其中包含100个类,每个类包含600个图像。每类各有500个训练图像和100 个测试图像,共有50 000 幅训练图像和10 000 幅测试图像。CIFAR 100 中的100 个类被分成20 个超类。每个图像都带有一个“精细”标签(其所属类)和一个“粗糙”标签(其所属超类)。
3.2 训练策略
网络模型训练使用的是带动量的随机梯度下降法进行反向传播,在CIFAR 10 和CIFAR 100 训练集上共训练300 轮。初始学习率设置为0.000 01,进行10 轮线性预热训练。在此基础上,以0.1 的学习率开始290 轮的余弦衰减训练。卷积核的权重参数使用MSRA[22]进行初始化,权重衰减系数设置为0.000 05,动量系数设置为0.9,每批数据大小设置为128,同时使用了系数为0.05 的标签平滑策略。
3.3 结果分析
从CIFAR 10 数据集中随机抽取4 幅图像,SSRNet的识别结果如图2 所示。原图为32×32 像素的图像,左上角为识别结果对应的类别标签。

图2 SSRNet 识别结果Fig.2 Recognition result of SSRNet
SSRNet、ResNet 和HS-ResNet 以相同训练参数,在CIFAR 10 数据集上训练得到的识别速度与识别精度对比如图3 所示,其中:圆形面积表示模型参数量的大小,识别速度在Tesla V100 上批次大小为1 时测试得到:左上角3 个圆圈表示本文提出的多尺度分割网络模型SSRNet,右下角3 个圆圈表示残差网络模型ResNet,中间圆圈表示SSRNet 中的多尺度分割模块SS-Block 使用HS-Block 替代得到的网络模型HS-ResNet。SSRNet-c 的识别精度与ResNet-56相近,速度快于ResNet-20。使用缩短网络长度方法得到的HS-ResNet 与SSRNet-a 和SSRNet-b 相 比,识别精度略低,识别速度稍慢。由此可见,多尺度分割模块SS-Block 与HS-Block 相比,识别精度更高,识别速度更快。
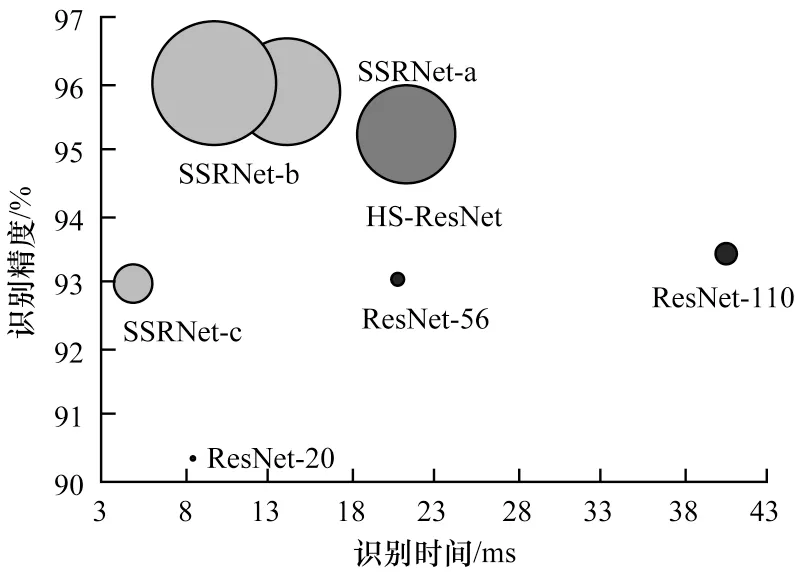
图3 不同网络模型的识别速度与识别精度对比Fig.3 Comparison of recognition latency and recognition accuracy of different network models
在本文的训练环境和训练策略下,不同网络模型在CIFAR 数据集上的实验结果如表2 所示,其中,加粗表示最优值。多尺度网络模型SSRNet-c 的识别速度最快,是ResNet-56 识别速度的4 倍;SSRNet-a和SSRNet-b 的识别错误率相近,分别为4.14% 和4.04%。前者模型参数量更少,后者识别速度更快。当对识别速度要求较高时,使用SSRNet-c 可以获得最快的识别速度。当对识别精度和模型参数量要求较高时,使用SSRNet-a 可以获得较高的识别精度和较低的模型参数量。SSRNet-b 是SSRNet-a 与SSRNet-c 性能的折中,在识别精度、识别速度和模型参数量之间取得了较好的平衡。

表2 CIFAR 数据集上不同网络模型的识别速度与错误率对比Table 2 Comparison of recognition latency and recognition error rates of different networks models on CIFAR datasets
表3 展示了不同的网络模型在CIFAR 数据集上的实验结果,本文网络模型的识别错误率与其他网络模型相近时,网络层数最少。目前用于图像识别的神经网络大都是基于深度卷积神经网络,网络层数远大于本文的网络层数,网络层数越少,识别速度越快。当识别错误率相近时,本文网络模型的识别速度快于其他网络模型。

表3 CIFAR 数据集上不同网络模型的错误率Table 3 Comparison of error rates of different network models on CIFAR datasets
在本文的训练环境和训练策略下,CIFAR 数据集上SSRNet-b 消融实验的结果如表4 所示。使用多尺度分割模块SS-Block 替换ResNet 中的残差模块后,错误率相近,但识别速度从25 frame/s 下降到11 frame/s。使用缩短网络长度方法改进ResNet 后,错误率相近,识别速度从25 frame/s提升到192 frame/s,提升7 倍多。同时使用多尺度分割方法和缩短网络长度方法改进ResNet 后,得到的SSRNet 的错误率大幅度下降,在CIFAR 10 和CIFAR 100 数据集上分别下降2.53%和8.81%,识别速度从25 frame/s 提升到100 frame/s,提升了3 倍左右。由此可见,缩短网络长度方法对识别速度有大幅提升,同时结合多尺度分割方法也可以提高识别精度。

表4 CIFAR 数据集上SSRNet-b 消融实验的识别速度与错误率对比Table 4 Comparison of recognition latency and recognition error rates of SSRNet-b ablation experiment on CIFAR datasets
4 结束语
本文提出的多尺度分割方法在对多尺度特征信息进行表示时,并没有增加很多模型参数量和计算量,而缩短网络长度的方法在保持识别精度的同时,大幅提高了识别速度。结合这2 种方法得到的基于多尺度分割的图像识别残差网络SSRNet,与其他网络模型相比,在识别精度相近时识别速度更快。下一步将把该网络模型应用到目标检测领域中,并进一步加快识别速度。
