融合注意力机制与上下文密度图的人群计数网络
2022-05-14吴奇元王晓东章联军高海玲赵伸豪
吴奇元,王晓东,章联军,高海玲,赵伸豪
(宁波大学信息科学与工程学院,浙江宁波 315211)
0 概述
人群计数的主要任务是统计指定区域内的人数,其广泛应用在公共安全管理、商业信息采集、服务资源调度等领域。目前,人群计数主流方法是通过运用计算机视觉相关知识来统计一张图片中的人数。与传统的人力计数方法相比,该方法在节省人力物力资源方面成效显著。人群计数作为计算机视觉领域的研究热点,仍然面临着目标遮挡、尺度变化、分布不均、背景复杂、视角透视等难题。
基于计算机视觉的人群计数方法可以分为基于检测、基于回归、基于密度图的人群计数方法。基于检测的人群计数方法通过累加检测出的单个个体,以得到图片的最终人数。该方法[1-3]适用于低密度场景,但是难以解决中高密度或者目标遮挡场景下的人群计数问题。基于回归的人群计数方法[4-6]将图像模块内的人群作为一个整体,通过特征回归算法直接得到图像模块的对应人数,然后将包含人数信息的所有图像模块结果累计加和得到图片整体人数。此类方法能够解决背景部分遮挡的问题,提高适用场景的人群密度上限,但是受视角、背景等因素的制约,在高密度场景下的准确性较低。基于密度图[7]的人群计数方法是通过生成相应的人群密度图,进而将密度图中的像素密度值累加,累加值即为最终图片人数。此类方法能够充分利用像素级别的信息,普适性较强,广泛应用于各种密度场景,是当前人群计数领域的主流方法。
随着图像处理器(Graphics Processing Unit,GPU)计算能力的不断提高,基于深度学习的密度图人群计数方法应运而生。该方法充分利用计算机储存和算力,极大地提高了人群计数的准确性,同时提升了人群计数的实时性,在一定程度上解决了传统人群计数方法需要人工手动选取特征的难题,从而扩大适用场景的范围。文献[8]通过3 列包含不同尺寸卷积核的神经网络来提取多尺度特征,以融合提取到的多尺寸特征,从而获得最终的人群密度图。在此方法提出之后,一系列基于多列卷积神经网络的人群计数方法层出不穷。基于文献[9]在网络前端增加一个图片人群密度等级分类器,将分类成不同密度等级的图片输入到不同的列,以得到相应人群密度图。文献[10]在文献[8]方法的基础上,利用跳接操作将各列网络的特征图相融合,得到最终人群密度图。文献[11]在微调文献[8]方法的基础上,通过加入两列网络分别获取全局和局部上下文信息,从而有策略地融合多列网络特征,得到最终的人群密度图。以上所述的基于多列卷积神经网络的方法在一定程度上提高了人群计数的准确率,文献[12]提出密集场景识别网络(Congested Scene Recognition Network,CSRNet),并指出多列卷积神经网络存在一定的不足。虽然多列网络使用不同尺寸的卷积核来提取多尺寸特征,但是得到的特征图存在信息冗余,并且网络结构复杂,训练耗时久。同时包含膨胀卷积的CSRNet因使用相同的膨胀率,导致不能充分利用前端网络得到的特征图。
本文提出一种基于注意力机制与上下文密度图融合的人群计数网络CADMFNet。采用前端网络实现逐级特征融合[13],即使用上采样融合模块(Up-sampling Fusion Module,UFM)实现高层特征和低层特征的融合,得到不同层级的多尺寸特征,将互质膨胀率[14]交替使用的膨胀卷积作为后端网络,利用上下文注意力模块(Contextual Attention Module,CAM)融合不同层级的中间人群密度图,以充分利用上下文信息,从而提升最终生成人群密度图的质量。
1 本文网络
本文提出一种基于注意力机制与上下文密度图融合的人群计数网络CADMFNet。该网络结构如图1所示。

图1 本文网络结构Fig.1 Structure of the proposed network
前端网络包含VGG16的前13层卷积层,将其按照2、2、3、3、3 的层数分成5 个阶段,池化层连接于下一个阶段的开头。将5 个阶段的特征图依次输入到上采样融合模块(UFM)中进行上下文特征融合。其中,Ui(i=2,3,4,5)代表使用双线性插值的上采样操作模块,每次上采样操作后输出特征图的边长是原来输入特征图边长的2 倍。Fi(i=1,2,3,4,5)代表特征融合后的特征图。网络在经过上采样融合模块以后,将Fi(i=2,3,4,5)输入到后端网络中得到中间密度图Di(i=2,3,4,5),然后将中间密度图在通道维度堆叠得到最终的中间密度图M。网络将含有最充足上下文信息的特征图F1输入到系数网络中,以得到系数特征图C,并将其经过通道维度的Sigmoid 以及Softmax 操作得到最终的系数特征图X。最后采用逐个像素相乘并在通道维度相加的方法处理注意力系数X及中间密度图M,从而获得人群密度图。该网络模型除生成人群密度图的卷积层以外,其他卷积层后都跟有ReLU 激活函数。
1.1 上采样融合模块
低层特征信息的感受野比较小,其包含小尺寸图像信息,即离摄像头位置较远的人群信息。高层特征信息的感受野较大,其包含大尺寸图像信息,即离摄像头位置较近的人群信息。上下文融合模块利用高层语义信息和低层轮廓信息,得到较精细的人群密度图,从而获得较准确的人群计数结果。为得到包含高层语义信息和低层轮廓信息的上下文多尺寸特征,本文通过UFM 得到融合后的上下文特征,并将这些不同的多尺寸上下文特征输入到后端网络,以减少特征图之间的冗余,从而更充分地利用网络提取的特征,提高计数的准确性。
在经过上采样融合模块处理之后,网络可以获得含有上下文信息的特征图Fi(i=1,2,3,4,5)。这些特征图的生成除了需要图1 中的上采样操作以外,还需要通道堆叠以及卷积操作,其配置的详细情况如表1 所示。卷积层参数表示为“(卷积核大小)-(输出通道数)-(膨胀率)”,concat为通道堆叠操作。通道堆叠和卷积操作Ci(i=1,2,3,4,5)作用在生成相应特征图Fi(i=1,2,3,4,5)之前,例如,通过C3生成F3主要分为2 个步骤:1)在通道维度将F4上采样后的特征图(256通道)和VGG16 得到相应的特征图(256 通道)进行堆叠,得到512 通道的中间特征图;2)使用2 个卷积操作将通道数从512 先降为256,再降为128,从而得到最终的上下文特征图F3。
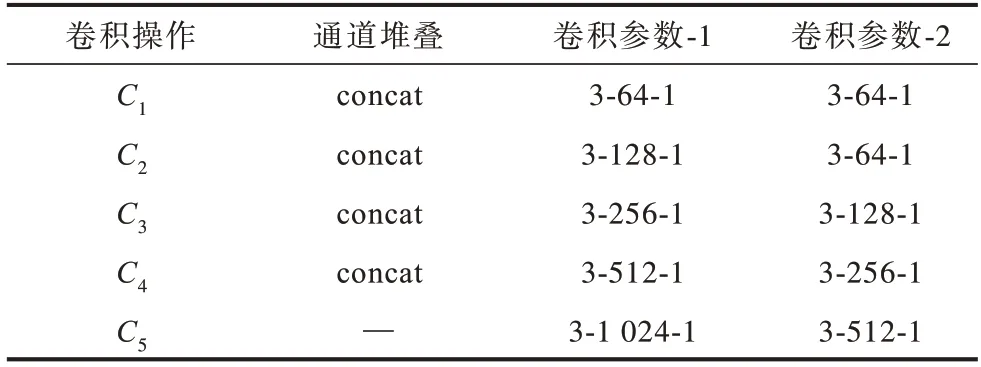
表1 上采样融合模块配置信息Table 1 Configurations information of up-sampling fusion module
1.2 互质膨胀率的膨胀卷积
膨胀卷积能够增大感受野,且提升计数准确率。膨胀卷积通过修改卷积核结构来扩大感受野,无需进行下采样操作,不会丢失空间信息,因此其效果要优于卷积+池化+反卷积的方法。二维膨胀卷积的计算如式(1)所示:

其中:d为膨胀率,当d=1 时,即为常见的普通卷积;w(i,j) 为卷积 核;x(m+d×i,n+d×j) 为二维输入;y(m,n)为二维输出。
不同膨胀率的膨胀卷积感受野效果图如图2 所示。图2 中由内而外依次包含3×3 卷积核1 次卷积、2 次卷积、3 次卷积所涉及的新像素位置。从图2 可以看出,膨胀率为2 的膨胀卷积经过3 次膨胀卷积以后,其感受野大于膨胀率采用1、2 交替的膨胀卷积,更要大于膨胀率等于1 的膨胀卷积。因此,膨胀卷积的膨胀率越大,经过相应膨胀卷积操作后的感受野也就越广。但是这并不意味着可以随意取膨胀卷积的膨胀率。如果膨胀率取值相同且不为1,则经过膨胀卷积之后,会出现“棋盘效应”,从图2(b)可以看出,如果连续使用膨胀率为2 的膨胀卷积,就不能充分利用特征图的每个像素信息,中间会滤掉很多像素信息。此外,如果膨胀率过大,则经过膨胀卷积作用后的特征信息之间相关性较差。从图2(c)可以看出,互质的膨胀率交替使用(1、2 交替)的膨胀卷积能够充分使用特征图的像素信息,以获得更准确的计数结果。因此,本文采用卷积率1、2 交替的膨胀卷积作为后端网络,生成中间密度图,既可以在扩大感受野的同时,避免产生“棋盘效应”,也可以降低特征信息相关性产生的负面影响。

图2 不同膨胀率的膨胀卷积感受野效果图Fig.2 Effect images of dilated convolution receptive field with different dilation rates
1.3 上下文注意力模块
上下文注意力模块(CAM)主要包括系数分支以及密度图分支2 个部分,如图1 所示。其中,密度图分支利用不同的上下文特征信息Fi(i=2,3,4,5)生成相应的中间人群密度图M,系数分支将具有最全上下文信息的特征F1作为输入,以生成系数特征图X,最终使用系数特征图给中间人群密度图打分,并将其对应的像素相加得到最终的人群密度图。
在密度图分支中,通过将不同的上下文信息输入到相应层级的多列后端网络,得到中间人群密度图。后端网络和系数网络的配置信息如表2 所示。

表2 后端网络和系数网络配置信息Table 2 Configurations information of back-end networks and coefficient-end network
在表2 中,卷积层参数表示为“(卷积核大小)-(输出通道数)-(膨胀率)”,up_2 表示通过上采样操作将边长变为原来2 倍,up_4 表示通过上采样操作将边长变为原来4 倍。后端网络包含逐级上采样操作和互质膨胀率的膨胀卷积操作,能够充分利用特征图像素级别的信息,在一定程度上提高网络的准确率。网络将每列后端网络得到的中间人群密度图在通道维度进行堆叠,从而得到最终的中间人群密度图M。
系数分支通过将具有不同层级上下文信息的特征图F1输入到系数网络,以得到中间系数特征图C,因此中间系数特征图具有全局上下文信息,进而将中间系数特征图输入到Sigmoid 函数和Softmax 函数中,经过相应通道间像素操作,获得最终系数特征图X。
2 实验结果与分析
2.1 实验设置
2.1.1 人群密度图的生成
人群密度图代表人在图像中出现的概率,既包含空间分布特征信息,又包含人数特征信息,通过对人群密度图中的像素密度值积分进行累加,获得对应图像或图像模块的人数。与基于回归的人群计数方法相比,基于密度图的人群计数方法优势在于能够更好地使用图像特征,进而提升计数准确度。此外,学习人头区域信息比学习人头中心点信息更容易,高斯核函数能够近似拟合不同尺寸的人头,在一定程度上模拟人群遮挡等现实场景可能出现的情况,从而解决目标遮挡等难题。因此,人群计数主流方法采用高斯核函数与冲激函数卷积生成真实人群密度图,并将其作为预处理准备工作。
假设人群标注的人头标签坐标为xi,则整幅图像所包含的人头位置如式(2)所示:

其中:N为整幅图像的总人数;x为整幅图像的像素点坐标;xi为图像中第i个人头的坐标;δ(x-xi)为冲激函数。将高斯核函数与式(2)进行卷积可得密度图函数,如式(3)所示:

高斯核函数Gσi(x)可表示为:

其中:σi为二维高斯分布的标准差;Gσi(x)为D(x)在x位置关于xi的高斯核函数值;D(x)在x处的取值由所有人位置xi的高斯核函数取值加和得到。
由高斯核函数性质可得:对应的标准差σi越大,第i个人在真实密度图中对应的图像区域越大,因此标准差与人头区域大小呈正相关。文献[8]提出一种适用于密集场景生成真实人群密度图的方法,使用与单个人距离最近的k个人之间的平均距离来代表σi,σi如式(5)所示:

2.1.2 损失函数
网络模型训练使用均方误差来衡量估计密度图与真实密度图之间的差异,因此,将均方误差作为损失函数来调整估计密度图的生成,如式(6)所示:

其中:θ为本文模型的网络参数;Ii为输入的第i幅图像;Dp(Ii,θ)为第i幅图像得到的估计密度图;Dgi为第i幅图像得到的真实密度图;N为数据集包含的图像总数。
2.1.3 训练设置
由于目前公开的公共数据集中图片数量不是特别多,为防止产生过拟合现象,因此本文使用数据增强技术来扩充数据集中的图片数量。在网络训练阶段,本文对数据集图片用0.5 的概率进行左右翻转,并从每张数据集图片中随机裁减出一个128×128 像素的图片补丁作为网络输入;相应真实人群密度图采取相同的操作。本文使用Adam 优化器,学习率被设置为固定的0.000 05,批量大小(batch size)设置为64。由于128×128 像素的图片补丁可能包含的人数为0,在一定程度上可以缓解数据集图片无人负样本不足的情况,因此能够帮助模型排除复杂背景噪声的干扰。
2.2 评价指标与数据集
本文实验环境为Windows 10 操作系统,配备16 GB NVIDIA Quadro RTX 5000 GPU 显卡。采用CUDA 11.0 版本的Pytorch 深度学习框架,分别在UCF_CC_50、ShanghaiTech 及Mall 数据集 上进行 实验,初步验证了本文网络在高、中、低各类密度场景下的计数效果。
2.2.1 评价指标
本文网络模型采用平均绝对误差(MAE)和均方根误差(RMSE)作为实验结果的性能指标,反映网络计数的准确性及稳定性。
1)平均绝对误差(MAE)。计算对象为测试集图片的估计人数和标签真实人数,如式(7)所示:

其中:N为测试图像数为第i幅图像的估计 人数;Ci为第i幅图像的真实人数。
2)均方根误差(RMSE)。计算对象为测试集图片的估计人数和标签真实人数,如式(8)所示:

其中:N为测试图片数为第i幅图片的估计 人数;Ci为第i幅图片的真实人数。
2.2.2 UCF_CC_50 数据集
UCF_CC_50数据集[15]的图片来源于互联网,总共有50张图片,每张图片中的人数为94~4 543个人,共计63 974个人。该数据集包含的场景人群密集程度高且图片数量稀少,是目前最具挑战性的人群数据集之一。本文采用五折交叉验证[15]方法进行实验:将数据集包含的50张图片随机等分为5个图片集,依次采用一个图片集作为测试集,剩余图片集打通合并后作为训练集,最终实验结果为5次实验结果的平均值。该数据集的平均人数为1 279.5个人,属于高密度场景,因此使用MCNN方法[8]生成人群密度图。在UCF_CC_50数据集上,本文对MCNN、MSCNN[16]、ResNeXtFP[17]、PACNN[18]、CSRNet[12]等网络的评价指标进行对比,结果如表3所示。

表3 在UCF_CC_50 数据集上不同网络的评价指标对比Table 3 Evaluation indexs comparison among different networks on UCF_CC_50 dataset
从表3 可以看出,在UCF_CC_50 数据集上,虽然本文网络CADMFNet 未取得最优的指标,但是相比CSRNet 方法,其MAE 下降了10.4%,RMSE 下降了8.7%,说明本文网络在一定程度上可以提高人群计数的准确度。此外,由于UCF_CC_50 数据集的划分方法具有一定的随机性,因此该数据集得到的计数结果虽然具备一定的参考意义,但是不具有绝对性的判断作用。
2.2.3 ShanghaiTech 数据集
ShanghaiTech数据集[8]分为2个部分,共有1 198张图片,包含330 165个人。Part A中包含的图片主要来源于互联网,该部分共有482张人数范围为33~3 193个人的图片,其中,300张为训练集,182张为测试集。Part B人群密度比Part A稀疏,是上海市区繁华街道的图片,该部分包含716张人数范围为9~578个人的图片,其中,400张为训练集,316 张为测试集。Part A 部分平均人数为501.4个人,Part B部分平均人数为123.6个人,均属中密度场景。因此,采用文献[8]网络生成人群密度图,在ShanghaiTech数据集上不同网络的评价指标如表4所示。

表4 在ShanghaiTech 数据集上不同网络的评价指标对比Table 4 Evaluation indexs comparison among different networks on ShanghaiTech dataset
从表4可以看出,在ShanghaiTech数据集上,相比CSRNet网络的结果,本文网络在ShanghaiTech Part A的MAE 下降了8.8%,RMSE 下降了12.5%;在ShanghaiTech Part B上的MAE 下降了25.5%,RMSE 下降了24.4%。
2.2.4 Mall 数据集
Mall 数据集[5]来源于安装在购物中心的监控摄像头拍摄得到的图片,总共包含2 000 张图片,共有62 325个人。在这2 000张图片中,前800张划分到训练集,后1 200张划分到测试集。该数据集包含人数为13~53 个人的图片,平均人数为31.2个人,属于低密度场景。此外,该数据集包含遮挡、光照、镜子成像等干扰。本文根据透视图生成真实密度图,透视图包含人群远近信息权重,主要采用式(9)的方法来生成二维高斯分布的标准差(σi,j),要求满足7 ≤σi,j≤25且向上取整:

其中:xi,j为透视图中第i行、j列的像素值;σi,j为图片中第i行、j列的人头对应的二维高斯标准差。在Mall 数据集上,本文对文献[5]、IFDM[24]、CNN-Boosting[25]、DRSAN[26]、E3D[27]、DecideNet[28]等网络的评价指标进行对比,结果如表5 所示。

表5 在Mall 数据集上不同网络的评价指标对比Table 5 Evaluation indexs comparison among different networks on Mall dataset
从表5 可以看出,在Mall 数据集上本文网络的评价指标基本取得了最优的结果。测试集平均每张图片对应的人数绝对误差为1.31,对应的人数均方根误差为1.59。
由以上结果分析可知,本文网络适用于高密度场景、中密度场景和低密度场景的人群计数。
2.3 实验结果
在不同数据集上本文网络的可视化结果如图3所示。图3 中第1 列为每个数据集中的原图,第2 列为真实人群密度图,包含真实人数,第3 列为本文网络的估计人群密度图,包含估计人数。在UCF_CC_50 数据集上本文网络的真实人数为1 037 个,估计人数为1 372.6 个。在ShanghaiTech Part A 数据集上本文网络的真实人数为502 个,估计人数为432.6 个。在ShanghaiTech Part B 数据集上本文网络的真实人数为181 个,估计人数为166.2 个。在Mall 数据集上本文网络的真实人数为33 个,估计人数为32.5 个。

图3 本文网络的可视化结果Fig.3 Visualization results of the proposed network
不同列密度图的可视化结果如图4 所示,网络输入为ShanghaiTech Part A 数据集中的图片,经过CADMFNet 后,不同列对应的密度图输出为密度图_i(i=2,3,4,5)。其中,密度图_i对应后端网络Back-end-i输出的密度图与相应系数特征图相乘,得到的特征图作为网络的输出。密度图_2 对应小尺寸的特征信息,重点关注离摄像头较远处的信息;密度图_3 对应尺寸稍大的特征信息,重点关注较小尺寸的信息;密度图_4 对应比较全局的信息,重点关注较大尺寸的信息;密度图_5 对应全局信息,重点关注大尺寸信息。将上述密度图叠加后得到最终密度图。本文网络估计的密度图人数为218.2 个,而真实密度图人数为223 个。因此。本文网络利用上采样融合模块(UFM)和上下文注意力模块(CAM)一定程度上可以解决多列网络中不同列提取的特征图之间冗余信息的问题,从而提高网络的准确率。

图4 不同列密度图的可视化结果Fig.4 Visualization results of different column density maps
CADMFNet网络取得较优的准确性与鲁棒性的同时,也存在一定的不足,比如参数量过大、运行速度较慢。CSRNet方法的参数量为62 MB,CADMFNet方法的参数量达到了145 MB。因此,CADMFNet网络适用于对准确率要求比较高但对实时性相对较低的场景,如学校、商场和景区的人流统计等。
2.4 消融实验
本文在ShanghaiTech Part A 数据集上进行消融实验,验证互质膨胀率交替使用(Alternating Dilation Rate,ADR)、上采样融合模块(UFM)、注意力模块(Attention Module,AM)和后端网络中逐级上采样(Step by step Up-sampling,SU)的有效性。其中,AM 和SU 包含上下文注意力模块(CAM),验证其有效性相当于验证了上下文注意力模块的有效性。注意力模块主要表现为图1 中Coefficient-end 所在的那一列。Baseline 为CADMFNet 去掉ADR、UFM、AM、SU 之后的网络(dilation rate=2)。在ShanghaiTech Part A 数据集上的消融实验结果如表6 所示。

表6 在ShanghaiTech Part A数据集上的消融实验结果Table 6 Ablation experimental results on ShanghaiTech Part A dataset
从表6 可以看出,本文提出的ADR、UFM、AM 和SU 使得人群计数的MAE 下降,具有提升计数准确性的效果。在Baseline 基础上增加相关模块后,虽然人群计数的RMSE 产生一定的波动,但是其相差不大且都比Baseline 的RMSE 小。因此,上述模块能够有效增强人群计数的稳定性。CADMFNet同时使用以上4 个模块,能够提高网络的准确性和稳定性,使整体效果达到最优。相比Baseline 网络,CADMFNet 的MAE 降低了10.8%,RMSE 降低了13.3%。
3 结束语
本文提出一种基于注意力机制与上下文密度图融合的人群计数网络CADMFNet。采用上采样融合模块、上下文注意力模块来减少多列网络中不同列之间的冗余信息,通过不同膨胀率的膨胀卷积生成高质量的中间密度图,以提高人群计数的准确度。在此基础上,将上述互补密度图相加得到最终的人群密度图。实验结果表明,相比CSRNet 网络,本文网络能够提高人群计数的准确性与稳定性,其在Mall 数据集上的平均绝对误差和均方根误差分别为1.31 和1.59。后续将从同比例减少网络通道数角度优化人群计数方法,以提高网络的运行效率。
