融合联邦学习与区块链的医疗数据共享方案
2022-05-14温亚兰陈美娟
温亚兰,陈美娟
(南京邮电大学通信与信息工程学院,南京 210003)
0 概述
互联网、大数据分析、移动边缘计算等技术的爆发式增长推动了“共享经济”的发展。随着海量医疗数据的产生以及时代发展的需要,人们将共享经济的关注点转向医疗行业。若能利用大数据分析技术将分散在各个医疗机构的医疗数据应用到不同行业,将医学专家的宝贵经验转化为标准化的知识,形成数据驱动服务,那么将大幅提高整个公共医疗机构服务效率问题,给整个社会带来巨大的效益[1]。但由于医疗数据涉及了患者的隐私且独立存储于医疗机构的数据库中,因此,利用医疗数据需要考虑共享过程中的隐私保护与效率问题。针对隐私问题,文献[2-4]利用云服务制定管理与访问医疗数据的策略,以实现共享过程中的数据安全。文献[5]在医疗数据共享的最初阶段就严格设计了相关医院、病人的访问规则,并结合代理再加密技术和症状匹配机制实现了轻量级的医疗数据共享保护方案。文献[6]和文献[7]提出,由于云服务提供商面临内部和外部的安全威胁,如果不加强安全和隐私保护,而继续将敏感的健康数据外包给云,就可能会增加数据泄漏的风险。HAΟ 等[8]认为简单地将医疗数据移动到云端进行存储、管理和分析并不能完美解决共享过程中的隐私保护与效率问题。为提高数据共享的可搜索性和安全性,文献[9-10]提出将分布式去中心化的区块链技术结合不同的加密算法解决病人隐私泄露问题。但在实际应用中,数据请求方从区块链上下载密文并解密的过程增加了互操作性的难度[10]。
联邦学习(Federated Learning,FL)技术[11]的发展为解决数据共享中的隐私问题带来了新的曙光,其能够在没有数据共享或数据收集的情况下在多源分散数据库中学习,让数据请求者不再需要收集大量数据就可以研究和挖掘数据中的潜在价值。SILVA 等[12]提出联邦学习框架,在不需共享大量原始数据的情况下就可以安全地访问和分析任何生物医学数据。尽管联邦学习允许参与者在不被披露的情况下贡献他们的本地数据,但FL 并不验证系统中不同方的数据质量以及准确支付参与者高质量数据贡献方面的问题[13]。因此,具有较少公共实体的低质量数据集可以与其他数据集共同训练,但这可能会导致大量计算资源的浪费及作为联邦成员的恶意客户端对FL 模型的攻击。针对此问题,文献[14]提出将区块链技术与联邦学习结合并用于物联网场景下的数据共享,通过区块链技术对数据提供者进行身份验证,并将联邦学习训练的模型参数存储于区块链中以防止被篡改,保证数据的安全性。将联邦学习与区块链相结合[15-16]已成为数据共享领域中能够同时解决隐私保护和数据安全性问题的重要方法。文献[17-18]将联邦学习与区块链相结合并用于医疗数据的安全共享,但也指出从各种数据源收集数据并协同准确高效的训练模型是人工智能技术的一个巨大挑战。SHAYAN 等[19]指出移动设备可能会在模型更新过程中对其进行中毒攻击,或者对目标设备进行信息泄漏攻击,并利用抵御负面影响防御来删除中毒模型更新。同时,使用不同的隐私方案来保护隐私,并在区块链平台上进行存储和汇总。LI等[20]提出联邦近似的学习算法,在客户端奔溃的情况下依然拥有较高的学习精度。为提高联合学习的效率,NISHIΟ 等[21]考虑到具有异构资源的客户,提出一种基于贪婪算法的联合学习客户选择方案。
现有的大部分研究工作为了获得好的学习性能,主要集中在设计高级的联合学习算法上,而使用其他手段筛选联邦学习数据源来提高学习性能却很少被探索。虽然NISHIΟ 等[21]考虑了资源限制和工人选择问题,但参与联邦训练设备的可靠性被忽略了。LIU 等[22]提出将声誉机制运用于挑选数据源以及KANG 等[23]提出将激励机制和可靠联邦学习工人(即移动设备)相结合的方案来改进联邦学习算法,既保护了隐私也提高了算法效率。
为了将数据源的影响降至最低,保证医疗数据共享的安全和效率,本文提出一种区块链与联邦学习相结合的声誉选择候选医院方案。通过在训练前筛选数据质量高的成员,将数据共享过程转化为模型参数共享过程,避免原始数据上传至区块链而造成患者隐私泄露。同时,改进声誉方案,选择数据质量高和可靠的参与联邦学习的候选医院训练模型,并利用分布式的联盟链存储各医院的声誉值以及全局模型参数,对积极参与高质量数据贡献的医院进行奖励。
1 系统模型与问题分析
1.1 系统模型
本文设定了一种由N个参与数据共享的医院和请求数据的相关机构H组成的联盟链联邦学习系统来模拟现实中安全可靠的医疗共享场景,包括区块链层和应用层。
如图1 所示,应用层是由1 个数据请求者(例如某保险机构、政府机构)和一组医院组成的通用移动网络。其中,广泛部署在网络边缘的用于通信的基础设施称为边缘节点,联邦学习任务的物理基础设施包括医院的移动设备和边缘节点。移动设备利用本地数据培训本地数据模型。边缘节点有2 种用途:1)在联邦学习任务中作为中央聚合器聚合本地模型以形成全局模型并与参与培训的医院相互传输模型;2)作为联盟链上的节点与数据请求者进行通信,为数据请求者提供候选医院的声誉值。医院数据库存储和加密着病人的各种医疗数据。数据请求者是一个需要分析大量临床医疗数据以进行研究的第三方机构。
在应用层中,为了保护隐私,基于上述来自医院共享的数据对多个具有联邦学习任务的数据请求者进行模型训练。每个数据请求者设计合约条款,以激励作为工人的可靠移动设备进行模型培训(图1中的步骤1)。接着,每个医院根据其本地数据迭代地训练一个共享的全局模型,并生成本地模型更新(图1 中的步骤2~4)。然后,所有的医院将他们的本地模型更新上传到边缘节点以更新全局模型(图1中的步骤6)。最后,重复训练过程,直到全局模型的精度达到预定义的收敛值。广泛分布的边缘节点使医院能及时与数据请求者通信。数据请求者会评估局部模型更新的质量,并根据参与医院的模型更新质量,为参与医院生成声誉评价。更多的声誉计算方案将在本文第2 节给出。声誉意见将存储在联盟链上,具有不可篡改的特性,而数据请求者之间能公开透明地共享各医院之间的声誉值。
在区块链层,因边缘节点具有强大的计算能力、通信能力及存储能力,可以作为联盟链的矿工。声誉意见通过共识算法被矿工验证后存储到数据块中。由于区块链的去中心化和防篡改性质,即使发生纠纷和破坏[9],数据块中的声誉意见也是持久和透明的证据。对于参与共享的医院,数据请求者会将自己的直接声誉意见与其他数据请求者的间接声誉意见集合并生成综合声誉值上传到联盟链上。在联邦学习中,声誉值是可靠医院选择的重要指标。在此次任务结束后,通过区块链的准确支付机制对积极参与贡献的医院进行奖励。
1.2 数据共享的具体步骤
基于声誉机制的候选医院共享数据选择方案如图1 所示,本文提出以声誉为基础选择医院并进行可靠的联邦学习,由联盟链来管理医院的声誉值和模型参数的方案,由如下6 个步骤组成。
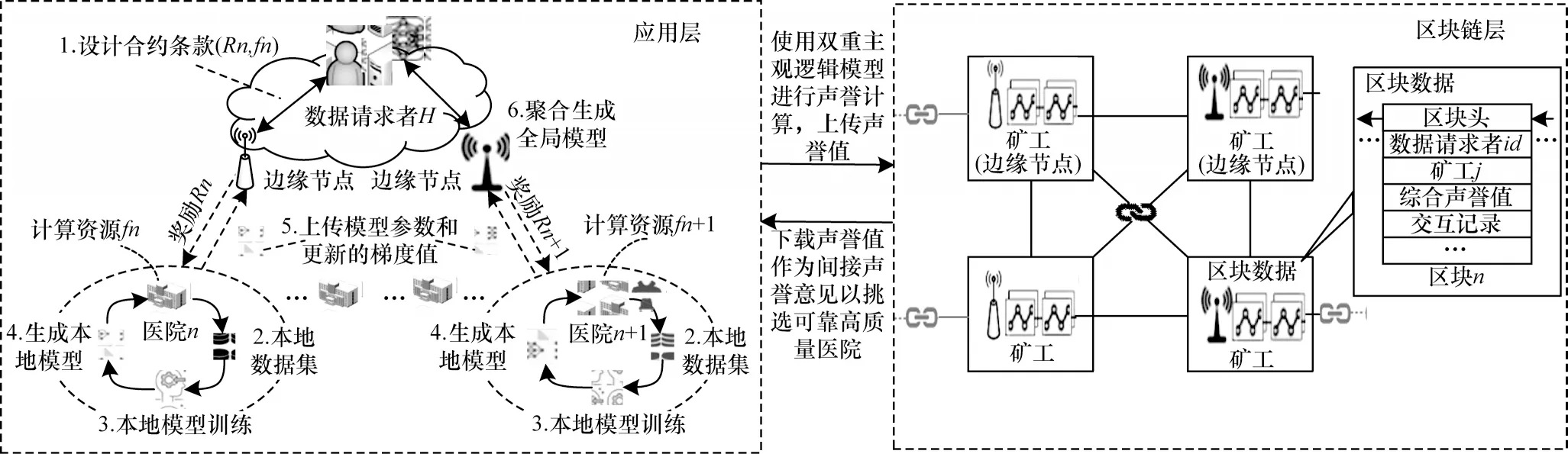
图1 系统模型Fig.1 System model
步骤1制定合约条款并发布联邦学习共享任务。数据请求者(如政府机构、医疗研究所、医疗保健院等)根据需求发布联邦学习任务以寻求满足合约的候选人。在发布任务之前,任务发布者需要根据实际需求制定一项智能合约,合约里面的内容包括需要的数据大小、数据类型、数据质量、声誉值及时间,CPU cycles 将合约传递给通信范围内的边缘节点,边缘节点再将合约发送给一定范围内的医院。满足合约要求的医院将作为此任务的候选人并将满足的资源信息发送给边缘节点,边缘节点再将其反馈给数据请求者。
步骤2核对候选医院声誉值并上传核对结果。在接收到边缘节点反馈的资源信息后,数据请求者需要估算相关候选人的声誉值来选择合适的医院来共享数据。声誉值由边缘节点对候选人的直接意见和其他与候选人交互过的边缘节点的声誉意见决定,并通过一种双重主观逻辑模型来计算。数据请求者首先从边缘节点反馈的资源信息中获得最新的候选人间接声誉值,再从存储声誉值的联盟链上下载候选人的声誉值并与之核对。每个候选人的声誉值都会被存储于联盟链的分布式数据区块中。若两值相同,则该声誉值将作为其他任务发布者对候选者的间接声誉值。反之,数据请求者会将比对结果上传至声誉链上,经过声誉链上的节点核实后候选医院的声誉值将会降低。最后,边缘节点根据与医院交互的直接声誉意见和间接声誉意见来生成候选医院综合声誉值,然后将综合声誉值上传至联盟链上,作为下一次其他数据请求者衡量医院的间接声誉意见。
步骤3根据声誉值选择候选医院并参与联邦学习任务。因为用户的数据集质量直接影响训练出的局部数据模型[12][23],而局部数据模型的质量又影响最终的数据模型质量。所以,数据请求者在估算出候选人的声誉值后并结合他们的资源选择合适的医院子集来执行联邦学习算法。
步骤4执行联邦学习算法和评估本地模型更新的质量。被选择的医院首先会在附近的边缘节点上下载最新的初始化模型,然后根据自己的资源使用不同的优化算法[15](例如,随机梯度下降算法SGD、小批量梯度下降算法Mini-batch gradient descent)进行联邦学习训练模型,在培训出局部模型后医院会将模型参数以及梯度值传至通信范围内的边缘节点,边缘节点接收到各个医院传过来的局部模型参数后聚合模型并形成全局模型,即完成一次迭代过程。若全局模型质量达不到要求,边缘节点会将最新聚合形成的全局模型下发给各个医院,医院接收到更新后的全局模型后会再次进行本地模型更新,完成多次迭代之后,当全局模型达到一定的精度即满足预定义的收敛条件时,则迭代结束。
步骤5将更新交互后的声誉意见上传至区块链。在每次上传模型中,与不可靠的医院或攻击者的交互均被视为负面交互[21]。与可靠医院的交互均被视为积极交互。边缘节点会依据每一次交互历史更新用户的直接声誉意见,迭代几次声誉意见就会被更新几次。迭代结束后,边缘节点会将直接声誉意见和间接声誉意见(间接声誉意见由其他边缘节点与医院的交互活动决定)综合形成一个综合值,该值会作为对下一次任务的候选医院的间接声誉值。边缘节点会将上传声誉综合值作为一笔交易上传到区块链上的区块中,在经过区块验证和执行共识过程后,该笔交易才会被写入联盟链中。因此,所有的数据请求者均可通过声誉联盟链来选择拥有高质量数据的医院来执行联邦学习算法。
步骤6完成医疗数据共享。在应用层完成上述步骤后,相关的数据请求者可以从联盟链上下载由边缘节点聚合的全局模型参数,并在不获取患者原始数据的情况下利用联邦学习训练的模型参数挖掘研究价值。由于区块链具有分散性、开放性、抗篡改性等安全特性,医疗数据模型可以被安全地访问和分析。
1.3 问题分析
本节将考虑多家医院合作进行联邦学习,为数据请求者提供数据模型。在真实的无线网络中,模型的传输受到传输的带宽、时间延迟的影响,因此只有当一部分符合要求的医院参与联邦算法来共享数据时才能提高模型的质量和共享效率。在下面环节中将阐述医院的选择对联邦学习算法性能的影响。
在所提模型中,当相关机构H想要请求A和B或者C医院病人的个人隐私数据并用于某项研究(例如请求病人的血检报告用于研究病人患乳腺癌几率),数据请求者H将任务发布在任务平台上,附近的边缘节点接收到该任务向A和B或者C医院发送数据请求者制定的合约条款,等待医院的资源信息反馈。任务发布者根据反馈信息选择合适的医院来参与培训模型。每个医院都有一个本地数据集Dn,i={xn,i∈Ti,yn,i∈Ti},xn,i是医院n参与训练的输入样本矢量,yn,i是输入样本矢量的标签。参与训练的数据量 为D=其中:i∈I是输入的第i个 样本。n∈N是参与培训的医院,N是参与共享数据的医院的集合。定义一个权重参数wn来表示医院n训练的局部模型参数,整个训练过程的目标是通过学习算法找到由Xn和Yn训练得到的参数来使模型收敛达到预测精度,并使损失函数最小化。Xn、Yn分别是输入样本矢量集合和输入样本矢量标签的集合。不同的优化方法损失函数的表达式不同。本文使用逻辑回归方法来描述联邦学习问题,局部模型的损失函数可表示为式(1)所示:

局部模型损失函数最小化的目标是:
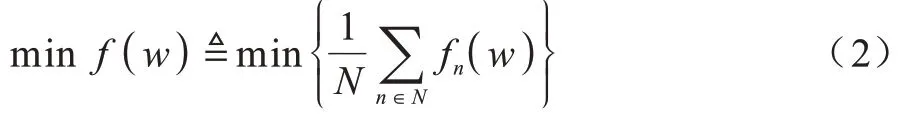
每个医院n在第e轮更新模型,表达式如式(3)所示:

其中:l是预定义的学习速率。将更新的模型参数传给边缘节点,由边缘节点训练出e轮全局模型参数如式(4)所示:

其中pn的表达式如式(5)所示:

其中:pn是每个医院被选择的概率。根据式(1)和式(2),具有高精度和可靠的本地训练数据的医院可以更快地收敛局部损失函数fn(w)和全局模型参数f(w)。从式(4)中可以看出边缘节点训练的全局模型参数取决于医院传送的局部模型参数,以及训练的数据集质量。反之,全局模型参数又决定局部模型的更新。因此,为了使局部和全局模型更新在更少的迭代次数内达到收敛目的,必须选择具有高精度和可靠的本地训练数据的医院才可以显著提高联邦学习的学习效率[17-18]。
2 基于区块链的声誉管理方案
虽然各医疗机构内部均拥有病人数据库,且对于某种疾病拥有相同的“基因组”,但是他们仍然可以提供不相关的信息,且提供数据的医院可能会因为电脑病毒感染、自私目的而分享虚假信息[8]。如果医院nj传输给通信范围内的边缘节点ei的数据模型质量被检测为有用的,那么就认为此次互动为积极交互。反之,为消极交互。此外,以往的研究也表明,在数据共享中提供的数据越全面、质量越好的用户声誉越高[16],所以基于声誉选择可靠的病人数据源提供者来提高联邦学习算法的精确度是一种值得考虑的方法。本文设计一种基于医院与数据请求者之间的互动及联合双重主观逻辑模型来量化医院声誉的机制。请求者接收到边缘节点反馈的医院候选人资源信息后获取到他们的最新声誉值,然后从区块链上下载医院候选人的声誉值并与之比对。若两值相同,则数据请求者同意候选医院为之服务;若不同,则数据请求者将收集到的证据以形式发送给边缘节点,边缘节点更新其对候选医院的声誉意见。其中,H(·)函数是对证据做哈希运算,sig 是数据请求者的签名,time 是交易的时间戳。边缘节点将选择声誉值高的医院为数据请求者服务,在交互过程中再利用双重主观逻辑模型计算候选医院的声誉,最终将医院的综合声誉值和训练的模型参数上传至联盟链上[21]。为了激励高质量的数据贡献者积极参与联邦学习,利用区块链技术准确无误地为高质量的数据贡献者支付奖励。由于激励机制不是本文重点,因此本文不对此展开详细阐述。
2.1 基于双重主观逻辑模型的节点声誉
2.1.1 直接声誉值
边缘节点在经过几次与候选医院的交互后,根据如图2 所示的流程图更新对医院的声誉意见。
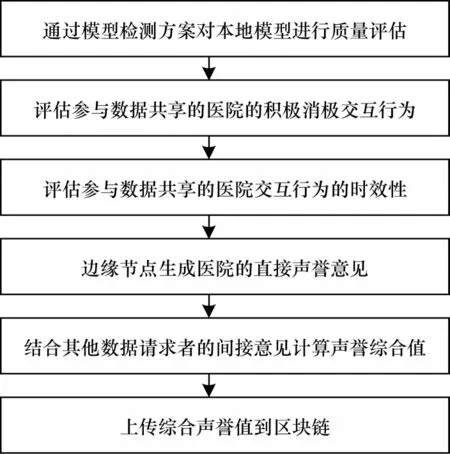
图2 声誉意见更新评估流程Fig.2 Procedure of the reputation opinion update evaluation

其中:α、β各自代表边缘节点ei与医院nj是该次任务中交互的积极事件和消极事件的次数;为成功传输数据模型参数的概率,即在无线网络中的通信质量决定了边缘节点对候选医院的不确定度。结合主观逻辑模型的矢量意见,可以得到直接声誉值如式(8)所示:

其中:μ代表不确定度对声誉值影响的相对系数。在实际情况中,影响边缘节点对候选医院的声誉意见的因素有很多,本文模型考虑了双方交互时效和正负交互因素的影响。为减少自私节点或恶意节点的攻击,增加消极交互事件对声誉意见影响的权重,即令θ<φ。其中:θ是参与联邦学习的医院正确传输模型参数后,与边缘节点完成积极交互的权重系数;φ是消极交互的权重系数。声誉意见公式可以更新为式(9):
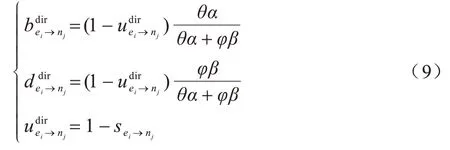
随着时间的推移,参与数据共享的医院不可能总是高度可信的。由于无线网络和不确定性因素的存在,因此在模型中考虑了交互时效性影响因子。
定义时效衰落函数t(γ)=FZ-z来描述时间对声誉的影响,其中:F∈(0,1)是交互新鲜度的衰退参数:z∈(0,Z]是决定交互新鲜度的时隙。根据时效衰落函数可以将一段时间γ内的声誉意见公式更新为式(10):

在该时间段内的直接声誉值如式(11)所示:
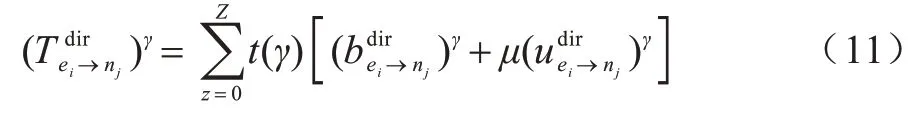
在该时间段γ内某一时隙的直接声誉值如式(12)所示:

2.1.2 间接声誉值
间接意见是由其他数据请求者对数据提供者提出的。在现实的无线移动网络中,作为提供医疗数据的数据提供者不会只服务一个任务。所以,每一个任务均会有一个数据请求者对应多个数据提供者。随着时间的推移,当一个数据提供者完成了与多个数据请求者之间的交互,且有新的任务发布时,当前数据请求者就可以从其他数据请求者那里获取他们对数据提供者的声誉意见。每个数据请求者对数据提供者的声誉意见都将使用2.1.1 节中的声誉矢量来表示。为了衡量其他请求者提供的间接声誉值重要性,利用式(13)来计算其他数据请求者的间接声誉意见的权重因子:
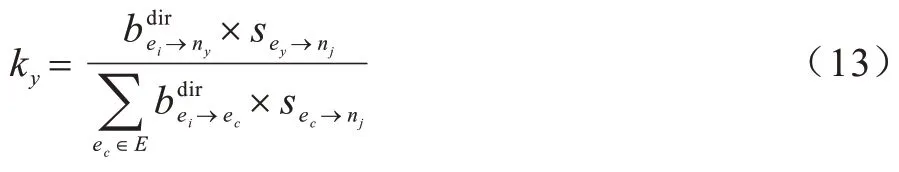
其他数据请求者ey∈Ε,Ε是其他数据请求者的集合,其他边缘节点对候选医院的不确定度的表达式如式(14)所示:

式(14)为其他边缘节点ey对医院nj的熟悉度,意味着其他边缘节点ey与医院nj的交互越频繁,则越大。在间接意见处考虑熟悉度参数,可使边缘节点ei获得对医院nj可靠性更高的声誉计算结果。其他边缘节点ey对医院nj的间接声誉意见通过矢量)表示。根据主观逻辑模型,形成的间接声誉意见如式(15)所示:

2.1.3 综合声誉值
为及时查询及核对参与数据共享过程中节点的声誉值,令每一个边缘节点均有一个本地声誉存储池,根据交互历史存储对各个医院或其他边缘节点的直接声誉值。为避免其他数据请求者[16]作弊,结合间接意见和直接声誉意见形成对数据提供者最终的声誉意见。最终的声誉意见表示如式(16)所示:
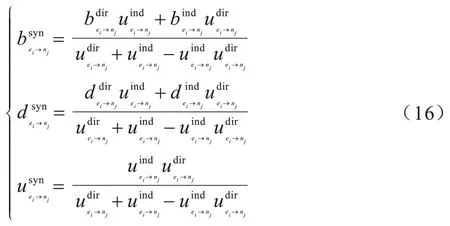
边缘节点ey更新对医院nj的最终声誉综合值的表达式如式(17)所示:

根据上述公式得到声誉后,若声誉综合值大于预先定义的阈值,则边缘节点ei可以选择具有高精度和可靠数据的高声誉候选医院nj作为联邦学习任务的模型培训工人。每一个边缘节点都有义务在更新其对各医院的声誉值后,将综合声誉值上传到区块链上以作为其他数据请求者的参考意见。这种方案能够挑选可靠性高且具有高精度数据的候选医院。
2.2 基于声誉机制的安全联邦学习
结合第1.3 节和第2.1.1~2.1.3 节的分析,单纯的联邦学习算法与区块链结合不能同时满足数据高质量且安全地共享,引入声誉机制的区块链管理方案可以为联邦学习算法挑选高质量的数据提供者。将该方案应用于医疗数据共享场景中既能保护患者隐私又能保证数据的高效利用。
算法1基于声誉机制的联邦学习算法

3 实验结果与分析
3.1 安全性分析
在复杂和充满开放性的无线网络机构中,作为参与联邦学习训练的工作者可能会执行恶意和不可靠的模型更新。本节主要从所提方案能够抵御中毒攻击、抵御共谋欺骗方面进行安全性分析。
3.1.1 中毒攻击的抵御
不可靠的模型更新可能是由恶意或篡改设备用欺骗性信息训练数据或不安全的通信渠道传输数据[12]这2 个故意原因导致的。因此,恶意数据所有者可能会故意发起严重攻击,例如中毒攻击[21]。中毒攻击是指恶意设备故意将有毒数据点注入训练数据集或修改训练数据集,以降低训练数据的准确性,从而增加错误分类的概率并操纵他们在式(3)中的本地模型更新结果。在这种情况下,恶意设备若试图使用伪造的样本信息(如身份证),通过在公共通信频道上窃听其他参与者训练的有用信息,则必须获得足够准确和常见的IDs。在传统的FL 中,通常采用同态加密[13]技术对本地模型参数和梯度更新进行加密,窃听者无法获取到任何信息。本文提出的声誉筛选数据源的方案为了减少恶意节点的攻击,增加了消极交互事件对声誉意见影响的权重φ,即使在前几次迭代交互的过程中恶意窃听者伪装成功,但经过多次迭代之后,他们的声誉值变低,抵押在区块链上的资产被没收,不当的行为被永久记录在链上,同时被取消学习训练的过程,这能够在一定程度上抵御中毒攻击。
3.1.2 共谋欺骗的抵御
本文方案中的声誉模型可以用于任何节点相互协作的服务中,每个任务发布者随机选择一个邻居。网络中有2 种可能的节点类型:合作医院节点和自私医院节点。即使网络中有新的FL 任务发布,恶意的授权医院nj试图与其他任务发布者串通,他们也无法参与此次的任务。附近的边缘节点ei从本地存储中检索其直接声誉意见同时ei向区块链上请求其他任务发布者关于医院nj的间接声誉意见,并等待时间间隔t(t=0.5 s)。在该时间间隔之后,节点ei开始进行声誉计算阶段,以计算综合声誉值如果不满足此次任务要求的医院nj想要参与此次任务就必须与之前服务过的任务发布者进行串通并修改区块链上的声誉意见。但由于区块链独特的数据结构特点,前一个区块的hash 值包含在后一个区块中,如果其中一个区块被修改,则之后的所有区块都将被重新计算,所以单个节点对数据库的修改是无效的。因此,之前的任务发布者想要篡改已有的数据几乎不可能,共谋欺骗也无法实现。同时,只有符合要求的数据模型参数和梯度更新被上传到联盟链上,而真实数据由每个数据提供者存储在本地。数据所有者可以控制他们自己的数据权限。此外,联盟链还使用了一系列的椭圆曲线数字签名和非对称等加密算法来保证数据的安全性。
3.2 结果分析
对比方案是文献[19]所提的典型联邦学习方案、文献[20]所提的现有性能较好的方案。文献[19]中提出的Fedavg 算法利用经典的加权聚合方法随机选择用户参与联邦学习。文献[20]中所提性能较好的FedProx算法能够妥善处理数据异构问题。在仿真实验中,利用著名的数字分类数据集MNIST 和广泛使用的软件环境TensorFlow1.10.0 执行数字分类任务来评估所提出的基于声誉机制的联邦学习方案,仿真参数的设置如表1 所示。在MNIST 数据集中有60 000 个训练示例和10 000 个测试示例。

表1 联邦学习的仿真参数Tabel 1 Simulation parameters of federated learning
图3、图4 所示为两种联邦学习方案学习精度的对比,在加入不同声誉值的情况下比较两种方案的学习精度和损失值。
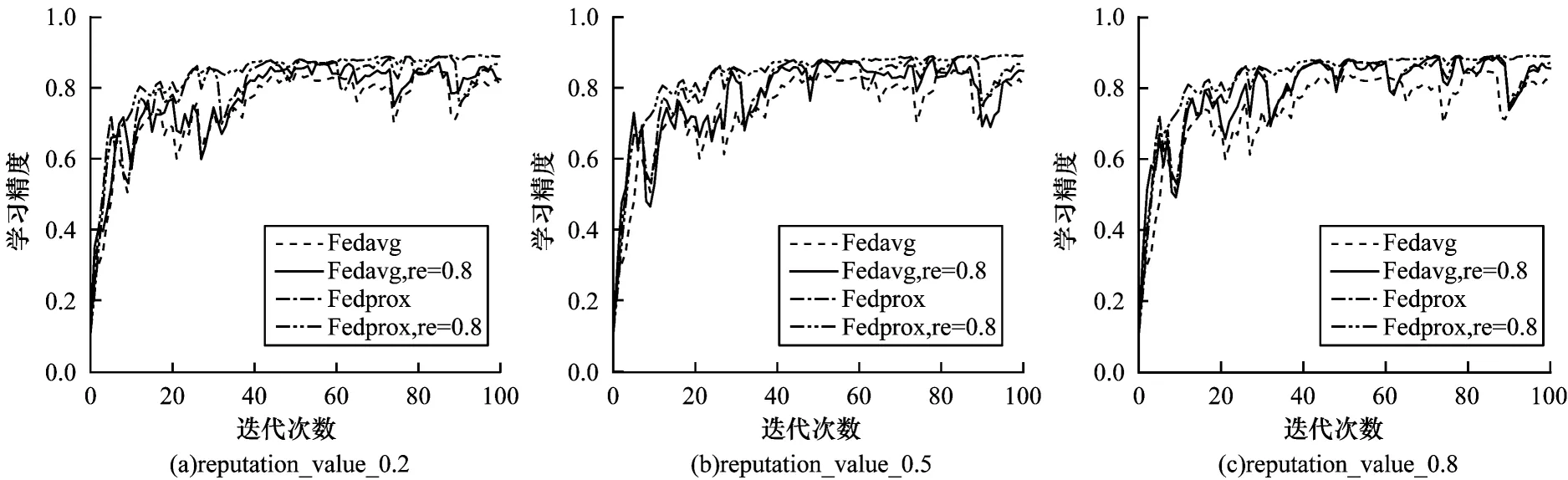
图3 不同经典方案的训练精度对比Fig.3 Comparison of the training accuracy of different classic schemes

图4 不同经典方案的训练损失值对比Fig.4 Comparison of the training loss of different classic schemes
为模拟现实网络中的设备异质性和数据异质性,在实验中将数据分布在1 000 个设备中,每个设备的样本数量遵循幂律,并且每个本地设备上的数据随机分为80%的训练集和20%的测试集。首先,每台设备被设定不同的声誉值,声誉值的取值范围为[0,1]。然后,在系统中通过设置不同的声誉阈值reputation_value_0.2/0.5/0.8 来模拟动态筛选设备参与训练的过程。在两种算法中均将Epoch 固定为20,每个Epoch 有100 个Rounds,即模型训练过程中医院使用batch_size为10的随机抽样样本连续进行100 次迭代本地模型来研究数据源声誉值差异对模型收敛的影响。如图3 所示,不加入声誉值的时候,两种经典方案的训练精度相差不大,但当引入了声誉值后,随着声誉阈值越高,对应的Fedavg 和FedProx 两种典型方案的损失值不断降低,学习精度不断提高。特别地,reputation_value_0.8 的FedProx 声誉值接近于1,可见其挑选出的医院几近完全可信且数据质量好,训练出的模型精度接近于1。引入声誉值之后,两种方案中参与FL 训练的设备更加灵活,不满足要求的设备容易掉出训练网络,因此系统异质性和更大的数据异质性(非同态分布)造成测试训练精度和损失值收敛较慢,同时收敛过程中震荡幅度较大,尤其是经典的Fedavg 方案。对于具有声誉管理的方案,当声誉值为0.2~0.5 时,本文的方案使联邦学习算法的性能提升明显。这是因为在声誉方案的帮助下,医院的声誉意见被及时更新,相关机构可以选择具有高精度数据的医院。因此,使用本文方案实现了高精度的声誉计算,保证了不同医疗机构之间的高质量数据共享。
图5 显示了基于不同声誉检测机制方案的医院声誉值的变化,分别为本文改进的声誉方案、基于提供服务节点不确定性的典型声誉方案2[22]以及基于任务发布者间相似性的声誉方案1[23]之间的对比。为了表征不同声誉方案识别不可靠医院的能力,假设前6 次交互任务中,不可靠医院假装表现良好以获取高的声誉值,此时所有的医院声誉平均值均急速增长,无法分辨好坏。设前6 次交互任务中,不可靠医院假装表现良好以获取高声誉值,此时所有的医院声誉平均值均急速增长,无法分辨好坏。之后,不可靠医院以0.8 的概率做出不当行为,整体声誉平均值开始下降,本文方案下降得更剧烈,幅度更大。而且,当不可靠医院再次表现良好时,整体声誉平均值也会增加。本文方案增加的幅度要比其他方案都要小,提供了更准确的衡量标准。值得注意的是,在6 次交互后,本文方案可以明确地展示在参与共享的医院中一直存在不可靠医院。然而,方案1、2 和无声誉方案的整体声誉平均值在0.5 以上,均无法完全检测出不可靠的医院。原因是不可靠的医院在一些交互任务中可以通过良好的行为很好地伪装自己,能够在短时间内不被发现。

图5 基于不同声誉检测方案的声誉值Fig.5 Reputation value based on different reputation detection schemes
图6 显示了在不同方案下当自私节点比例变化时孤立自私节点收敛时间的变化。由图6 可知,当自私节点的比例低于50%时,收敛时间随自私节点比例的增加而增加,这是因为随着自私节点的增加,系统对节点的可信任信息越少,诚实节点需要花费更多的时间收集证据来发现自私节点。也可以看出本文方案与对比方案相比节省了约6%的交互时间,这是因为本文方案综合考虑了经验、熟悉度、时效性等多个因素,可以通过更快收集节点的可信信息来判断节点的行为,因此本文方案性能更好。
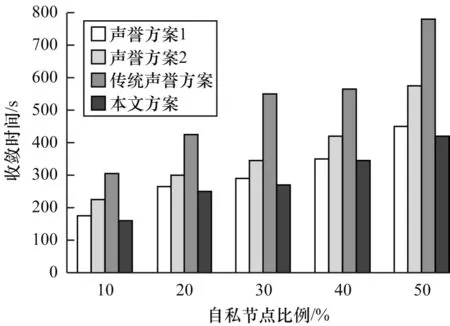
图6 基于不同声誉方案自私节点比例变化发现自私节点的收敛时间Fig.6 The convergence time of discovering selfish nodes when the proportion of selfish nodes changes based on different reputation schemes
区块链在本文方案中的重要作用是存储医院声誉值,由于声誉值是动态变化的,入链存储过程并不简单。为了将声誉值和参数上传至链上,简化入链存储过程,这些计算均在链下进行,所以上传至链上的是由参数和声誉值打包好的交易,这符合区块链的交易行为和数据结构特性。该实验部分通过在国产区块链FISCΟ BCΟS 上建立可靠的交易服务,并采用PBFT 作为运行在4 名预选矿工上的共识算法。同时,使用SHA-256 作为安全哈希算法,声誉意见的数据大小在100~300 KB 之间,信誉意见的块大小限制为1 MB。交易吞吐量是衡量分布式系统的一个重要的性能指标,TPS=trans_len/ΔT,系统的吞吐量通常由区块中包含的交易数量(trans_len)和生成一个区块的时间(ΔT)决定。使用它来测试在较短的间隔时间内发送大量交易区块链能否快速处理网络中交易的动态入链存储过程,实验结果取20 次实验的均值。
图7为模拟交易的动态存储过程,每间隔时间t=5 s时,分别向系统中发送500、1 000、2 000、3 000、4 000笔交易。当交易数量较少时,系统达到的TPS接近于系统中存在的交易。例如,当交易为1 000笔时,系统的平均TPS能达到995.29。但随着交易数量的明显增加,系统的TPS增长幅度却在降低,当交易最大值为4 000笔时,系统的平均TPS只有3 079.35。这是因为一个完整的入链存储的过程包括4个阶段:发送交易、预备块生成、块的共识和正式的块生成。当系统中的交易过多时,在预备块生成和共识阶段保持节点间的一致性所需的时间就越长,同时,节点与主节点的通信消耗就越高,共识过程所花费的时间就越多,系统吞吐量就越低。特别地,由于网络抖动和CPU性能的影响,即使在时间相同的情况下发送不同笔交易到系统中,系统中达到的TPS也不稳定。但从系统平均TPS可以看出,在区块链网络中同时并发大量将声誉值和模型参数打包成的交易入链存储过程是可以实现的,并且能满足一定的性能需求。

图7 不同交易数量达到的平均TPS 对比Fig.7 Comparison of average TPS of different transaction quantities
4 结束语
本文针对医疗数据共享场景中可靠数据源的选择问题,提出一种以声誉为基础的方案。使用联邦学习对数据建模,引入区块链技术实现对声誉的管理,利用双重主观逻辑模型改进声誉方案,并对医院声誉进行较全面计算。实验结果表明,改进的声誉方案可以吸引更多声誉高的医院,提供高质量的本地训练数据及提高联邦学习算法的效率。下一步将把本文方案运用于其他场景的数据共享中,并针对联盟链场景设计相应的区块链共识算法和激励机制以提高共享效率,加强区块链在数据共享中的作用。
