改进SSD 算法的道路小目标检测研究
2022-05-14邹慧海
邹慧海,侯 进
(1.西南交通大学 唐山研究生院,河北 唐山 063000;2.西南交通大学 信息科学与技术学院,成都 611756)
0 概述
随着深度学习技术的发展,语义分割、目标跟踪、目标检测、车道线检测在计算机视觉领域得到广泛关注,尤其是无人驾驶汽车。目标检测任务是对车辆前方道路环境的目标进行识别检测及定位,因实际道路环境的复杂多变性,使得该任务面临诸多挑战。
传统的目标检测方法通常分为区域选择、特征手工提取、分类回归3 个步骤。文献[1]提出一种差异训练、多尺度的目标检测方法DPM。该方法通过计算模型梯度方向直方图(Histogram of Οriented Gradients,HΟG),利用支持向量机(Support Vector Machine,SVM)对模型进行分类训练,从而得到物体的梯度信息。但是,在网络选择区域时因耗费大量时间,导致检测速度慢,而且手工提取的特征语义信息比较少,导致检测精度差。
近年来,将深度学习与目标检测相结合的方法成为研究热点。相比传统目标检测方法,深度学习方法的模型网络层数深、参数多。在目标检测领域中,该方法具有较高的检测精度和较优的实时性。基于此,研究人员将深度学习理论融入到目标检测工作中。深度学习目标检测方法分为[2]单阶段(one-stage)检测方法和双阶段(two-stage)检测方法。基于区域候选框的two-stage检测方法提取输入图像的候选区域,并对其进行候选区域的分类与修正,从而实现目标检测。代表模型有R-CNN系列,包括R-CNN[3]、Fast R-CNN[4]、Faster R-CNN[5],以及Mask R-CNN[6]等,都具有较优的检测精度,但是检测速度较慢,从而无法满足实时性要求。与此相反,one-stage检测方法是一种端到端的目标检测方法,基于回归分析的原理,利用卷积神经网络提取图像的特征信息,以识别检测目标的位置和类别,能够有效加快检测速度。代表模型有YΟLΟ 系列,包括YΟLΟv1[7]、YΟLΟ9000[8]、YΟLΟv3[9]及YΟLΟv4[10]算法、SSD[11]和EfficientDet[12]等。YΟLΟv4[10]检测模型作为单目标检测模型类别中的最优模型,在主干部分引入跨阶段局部网络(CSPNet)[13]和特征融合金字塔网络(PAN)[14],以解决梯度信息重复问题,从而提高同一物体在不同尺度上的识别精度,还可以通过数据增强等训练方式,提高检测精度和实时性。
在汽车行驶过程中,目标检测方法不仅对近距离的大目标进行精准实时检测,而且还要对远距离的小目标进行位置检测。针对道路前方行人和车辆类别的小目标检测问题,本文提出一种基于改进SSD 的道路小目标检测算法。通过引入改进特征金字塔网络,融合不同层感受野特征信息,利用深层特征网络ResNet50代替VGGNet16,同时在残差结构中引入批量归一化,从而提高检测精度并加快收敛速度。
1 相关工作
1.1 SSD 算法
SSD 是单阶段多类别的目标检测算法,具有较优的检测精度和较快的检测速度,但是小目标检测效果并不理想。SSD[11]网络结构如图1 所示。SSD 网络结构主要分为2 个部分:1)VGGNet16 特征提取网络,通过提取图片目标的特征信息,得到特征图;2)分类回归层,对每个候选框进行分类与回归,从而识别检测出图片目标。

图1 SSD 网络结构Fig.1 Structure of SSD network
SSD 算 法分别在尺度为38×38、19×19、10×10、5×5、3×3、1×1的特征图上产生候选框,以检测不同尺度的目标大小。本文是在这些尺度特征图后通过连接特征金字塔融合结构进行消融实验,提高小目标的检测性能。SSD 算法候选框的数量为38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8 732。先验框尺度的计算如式(1)所示,位置计算如式(2)所示:

其中:h、w为先验框的长、宽;sk为面积;αr为系数因素;d为距离;cx、cy为距离x、y轴系数。
边界框位置的计算如式(3)所示:

研究表明,匹配先验框与边界框遵循的原理是:首先计算边界框与先验框的所有IoU 值,当IoU 值大于等于设定的阈值时,说明匹配成功,即为正样本;反之为负样本。若存在一个先验框与多个边界框的IoU 值超过设定阈值时,此时匹配其中最大的边界框为正样本,剩余的边界框为负样本。
SSD 的损失函数采用多任务损失函数,由分类损失值和边框回归损失值2 个部分相加得到。其中分类损失采用交叉熵函数,回归损失采用SmoothL1loss 函数,整体损失函数如式(4)所示:
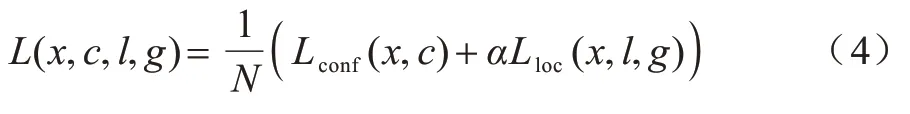
其中:Lconf为分类损 失;Lloc为回归损 失;α为权重系数,系数越大,表明回归损失在整体损失中占比越大,在训练过程中正样本的边框坐标优化效率越高。
1.2 ResNet50 特征网络模型
ResNet(Residual Network)[15-16]是一种用于深度学习目标检测的卷积神经网络主干特征提取网络,因其高效性和实用性,广泛应用于计算机视觉检测、分割、识别等领域。层数越深的网络可以提取到更加复杂的特征信息,效果也越好,但是网络层数的增加导致深层梯度在反向传播过程中越来越小甚至消失,从而阻碍网络的收敛,即网络退化问题。网络退化问题不仅增大了训练误差和测试误差,也降低了网络精度。
ResNet网络中的残差结构(Residual Block)可以解决网络退化问题,残差网络结构对比如图2 所示。
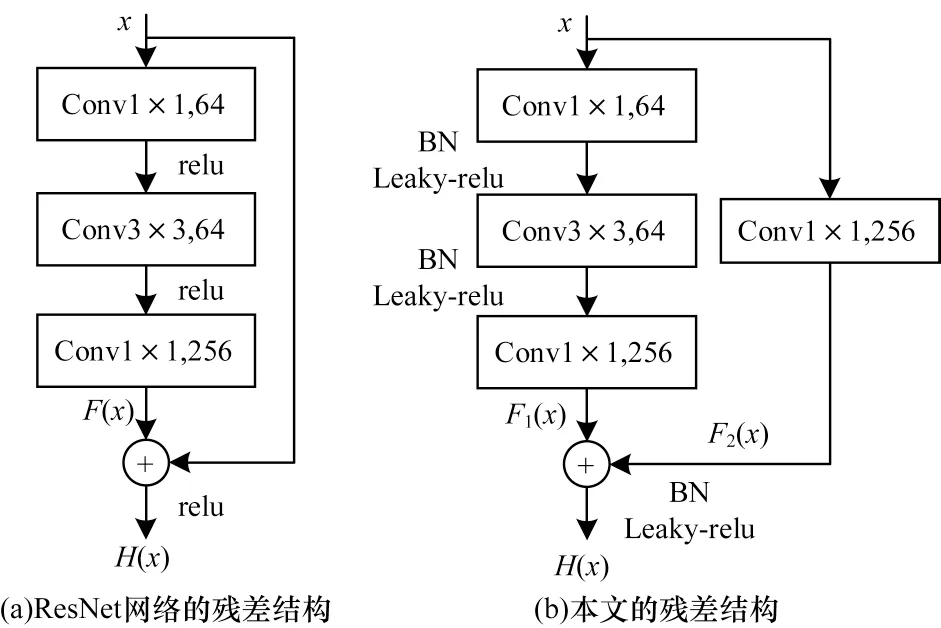
图2 不同的残差网络结构对比Fig.2 Comparison of different residual networks structure
在残差网络结构中,当输入为x时,残差学习特征为H(x),网络层的原始学习特征为F(x)。则残差结构的学习特征H(x)如式(5)所示:

相比原始学习特征F(x),残差网络能够学习残差特征H(x),其原因是当卷积网络层数加深时,特征随网络层向下传递,而梯度随网络层向上回传。在此过程中,因网络层数太深导致梯度消失。然而,本文的残差网络可以解决此类问题,即使左边深层网络向上回传的梯度值过小甚至消失,但是右边原始梯度值向上回传,整体梯度值等于两边梯度值相加,从而解决梯度消失的问题。
本文使用的改进残差结构如图2(b)所示,在原残差结构的基础上,将relu[17]激活函数替换为Leaky-relu[18]激活函数,并加入批量归一化(Batch Normalization,BN)[19]。在网络训练过程中,当relu函数在部分输入小于0 的情况下,输出恒为0,导致对应权重难以更新,从而无法训练学习特征。Leaky-relu 函数在输入小于0 的情况时,输出持续变化,以更新权重并继续学习。BN 是对特征图进行归一化处理,加快收敛速度。同样在训练时,部分输入只通过直线连接前向传播,导致整体结构变成一条直线结构。因此,在残差结构右侧加入1×1 卷积核操作,可以解决上述整体直线结构问题。
2 本文算法
2.1 特征金字塔结构改进
随着网络层数的加深,主干特征网络提取特征图的感受野逐渐增大,导致小目标的有效信息缺失,从而无法检测出小目标。由于不同深度对应不同层次分辨率的语义特征信息,因此通过学习不同层之间相同的特征信息,提高网络识别目标的精确度。特征金字塔融合结构如图3 所示。增加双向融合的特征金字塔网络(Path Aggregation Network,PAN)[14]结构能够有效解决小目标检测的问题,PAN 结构如图3(a)所示。通过自底向上和自顶向下融合不同网络层提取的特征图,整合不同感受野大小和语义强度的特征信息,以得到目标信息更加丰富的特征图,从而提高检测精度。
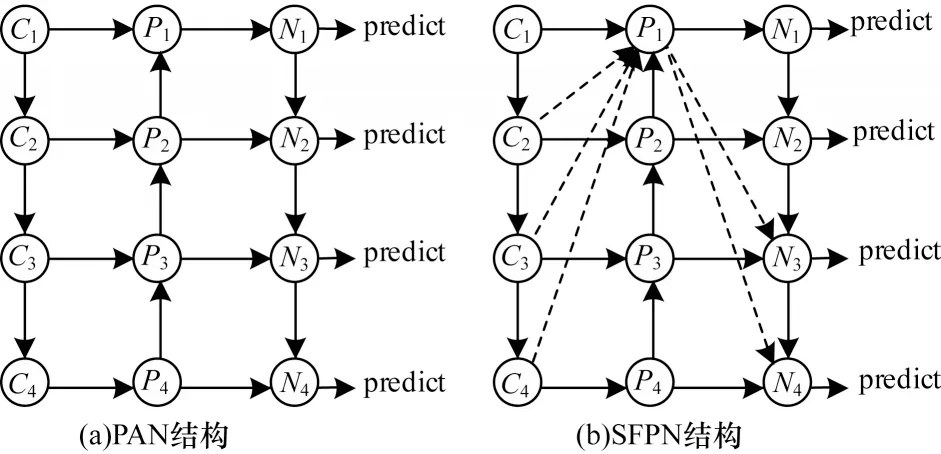
图3 特征金字塔融合结构Fig.3 Structure of fusion feature pyramid
PAN 的提出验证了双向融合的有效性,但是其结构较简单。因此,针对实际小目标检测场景,本文提出更复杂的SFPN 特征融合结构,如图3(b)所示。首先进行第1 次自底向上的特征融合,将每层特征网络提取的特征图进行相应倍数的上采样,并分别与第1 层、上一层特征图级联相加融合得到特征图Pi(i表示层数),然后再进行第2 次自顶向下特征融合,在此过程中,将第1 层特征图P1分别与每层特征图Pi级联相加融合得到2 次融合特征图Ni,其他结构保持不变。SFPN 特征融合结构的目的是为了融合浅层特征图感受野小(包含全部小目标)的有效信息,得到小目标语义特征信息更丰富的特征图,从而提高小目标检测性能。
2.2 RFG_SSD 网络结构改进
为提高小目标检测性能,改进的SSD 网络是通过引入特征融合金字塔SFPN 网络,并加载在原SSD特征提取网络之后,对不同尺度分辨率的特征图进行融合,利用融合浅层和深层的特征图感受野,以提高小目标检测性能,进而分类回归预测目标。同时为提升整体RFG_SSD 网络性能,改进RFG_SSD 网络结构选用ResNet50 替换VGGNet16,并将其作为改进模型的主干特征提取网络,通过加深网络层数提升性能。改进RFG_SSD 网络结构分为主干特征提取结构、SFPN 特征融合结构、分类回归检测层结构3 个部分,如图4 所示。
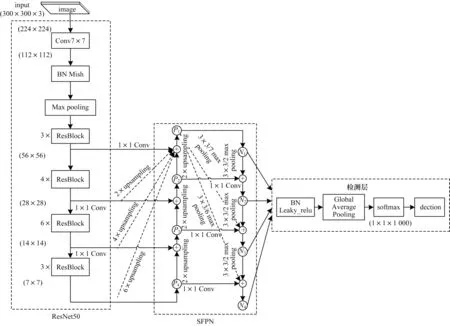
图4 RFG_SSD 网络结构Fig.4 Structure of RFG_SSD network
在主干网络中,输入图片尺寸为300×300×3,首先通过ResNet50 网络对输入图片进行特征提取,每经过一个残差块将提取的特征图送入SFPN网络中并进行特征金字塔融合操作,尺度分别为56×56、28×28、14×14 和7×7。在ResNet50 网络结构中主要使用改进残差结构(ResBlock),引入批量归一化(BN)和Leaky-relu 激活函数。BN 操作是在特征图的批量大小、长、高3 个维度上进行归一化处理,目的是通过规范化方法将偏离的分布拉回到标准化,使梯度变大,以加快学习收敛速度,从而解决梯度消失的问题。Leaky-relu 激活函数操作是向上回传梯度,以避免网络退化现象的出现,从而为网络增加了非线性表达能力且提高了网络检测性能。
在2 次纵向融合过程中,SFPN 特征融合结构将下一层特征图进行2 倍上采样、上一层特征图进行1×1 卷积,进而将两者级联相加连接,得到融合不同层语义信息的特征图,使得网络学习特征更加精准,如图4中SFPN模块实线连接。为提取更多的小目标特征信息,在第1 次融合过程中,将各层不同感受野大小的特征图Ci做2 倍、4 倍、6 倍上采样后,并与C1特征图融合得到P1,在第2 次融合过程中,将P1进行核为3×3 大小、步长分别为2、4、6 的3 种最大池化方式降采样后,并与各层Pi融合得到Ni,如图4 中SFPN 模块虚线连接。最后分别将各层融合得到的高语义信息特征图Ni传入到检测层进行分类回归,以预测目标。
在检测层结构中,依次经过批量归一化BN 和Leaky-relu 激活函数操作层、全局平均池化层(Global Average Pooling,GAP)[20]、softmax 层[21],最终得到目标检测结果。标准目标检测网络模型在特征提取后连接全连接层(Full Connected,FC),其目的是将前面学习得到的特征语义表示映射到样本空间,降维得到一维向量组,并将其输入到softmax 层进行分类,以得到相应类别目标。由于FC 层参数冗余,占据整个网络参数量的80%以上,导致运算量过大,且容易过拟合,因此使用代替FC 层,如图4 中检测层结构。全局平均池化方式不仅能够降维得到与FC 相同的结果,而且可以降低50%以上的参数量,同时去除了对输入图片大小的限制,以提高网络运算速度。
3 实验结果与分析
3.1 实验平台配置
本文选用pytorch 开源框架进行训练、测试,基于ubuntu16.04 操作系 统,CPU 为Inter Core i7-9700K,3.60 GHz,显卡为NVIDIIA GTX2080。编译环境为torch-1.2、torchvision-0.40,cuda10.0、cudnn10.0,python 3.7语言编程。
3.2 BDD100K 数据集
针对道路行驶过程中车辆前方的行人和车辆目标,本文选用的数据集必须满足车辆行驶过程中有足够多的行人和车辆,并且是真实的路况环境。因此,本文使用BDD100K 数据集[22],该数据集是2018 年伯克利大学发布的大规模、内容多样性的公开驾驶数据集。其中道路目标数据有1×105张图片,包括城市街道、高速公路等路况场景,包含晴天、阴天、雨天等天气环境。这些因素使得数据集具备丰富多样性的行人、车辆路况场景,网络能够学习更丰富的特征,从而适用于道路上各种复杂场景,保障无人驾驶汽车的安全出行。
该数据集的道路目标数据包含训练集7×104张图片、测试集2×104张图片、验证集1×104张图片,包括多种目标类别标签数据。编写代码提取两个数据集的行人、车辆类别标签,并保存得到训练集、测试集、验证集txt 格式。同时使用式(1)计算每个类别标签框尺度大小,设定尺度小于或等于19×19 的标签框为小目标,统计类别标签个数和小目标标签个数,以得到小目标框个数约占所有框个数的40%,各标签框数目统计如表1 所示。
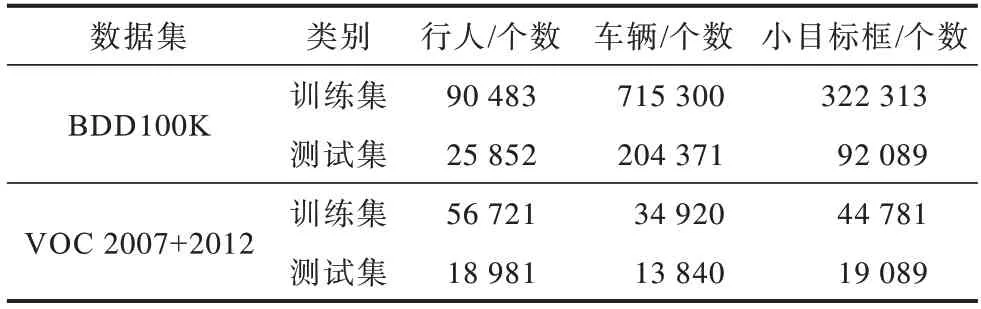
表1 标签框数目Table 1 The number of label boxes
3.3 训练与消融实验
本文通过控制变量法(不同模块组合)进行消融实验,以对比各模块作用程度。各网络的结构模块如表2所示。本文使用BDD100K 训练集对4 种网络进行模型训练实验。训练过程中批次大小为8,迭代次数为500,初始学习率为0.000 1,权值衰减为0.000 5。其中学习率决定得到最优值参数的速度,如果学习率过大,参数可能会跳过最优值,从而导致网络无法收敛甚至发散;如果学习率过小,则优化效率过低,网络长时间无法收敛,可能得到局部最优。因此,在训练中权值衰减系数的设置是根据模型训练情况来动态改变学习率大小,使得网络在训练迭代中得到最优值参数。
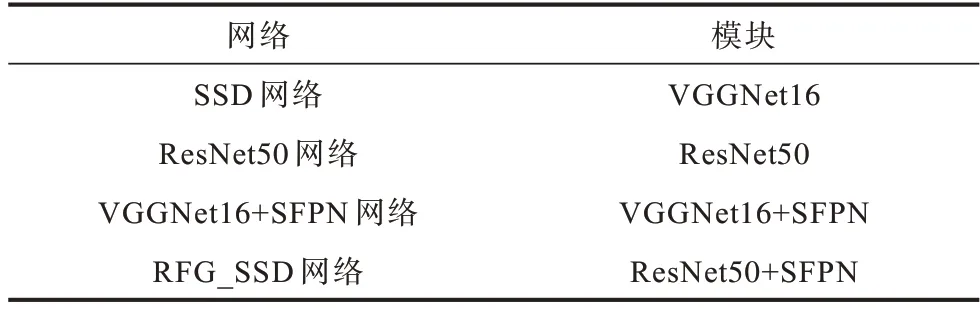
表2 不同网络的模块结构Table 2 Module structure of different networks
训练时调用原SSD 在VΟC2007 数据集上训练得到的权重并进行初始化,并且在训练中将训练损失值变化绘制成曲线,如图5 所示。损失值越小表示模型预测目标越接近真实目标,模型的性能越好。
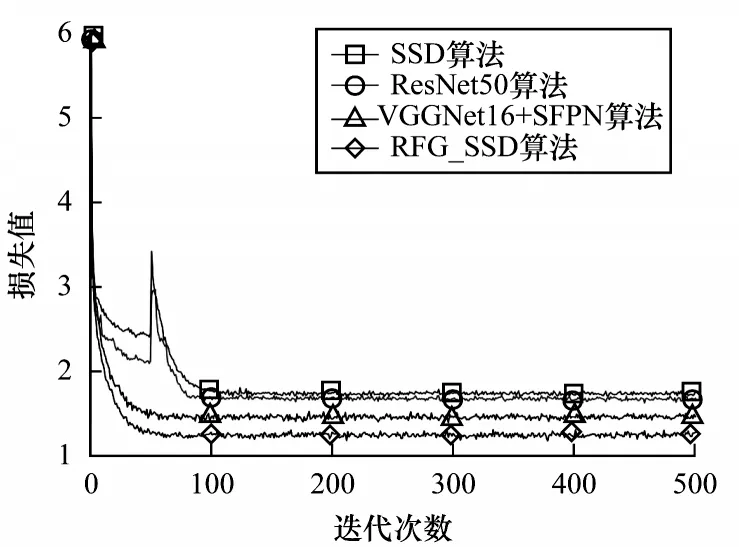
图5 不同算法的损失值对比Fig.5 Loss values comparison among different algorithms
从图5 可以看出,各算法经过迭代100 次后损失变化趋于稳定,曲线波动不大。SSD 算法使用VGGNet16 特征提取网络,损失值最大;只将原SSD结构中特征提取网络替换为ResNet50,损失值排在第2;在原SSD 结构中只增加SFPN 特征融合网络,损失值排在第3;同时替换ResNet50 网络和增加SFPN 网络设计得到RFG_SSD 网络,损失值最小,相对应的性能最优。
3.4 实验结果
3.4.1 消融实验精度评估
在目标检测领域中,本文选用准确率和召回率来评估系统的性能。准确率是指在所有正样本中,正确目标所占的比例,衡量查准率;召回率是指在所有真实的目标中,被模型正确检测出来的目标所占的比例,衡量查全率。精确率和召回率如式(6)和式(7)所示:

其中:P为准确率;R为召回率;TTP为模型正确检测的目标个数;FFP表示模型错误检测的目标个数;FFN为模型漏检的正确目标个数。
在实际过程中,准确率和召回率相互关联,因此将计算得到的P、R值绘制成P-R 曲线,综合考虑P-R 曲线下的面积AAP值来评估各类别检测性能,AAP值越大,表示模型检测精度越高,即性能越好,如式(8)所示:

针对多个类别N,本文使用平均值mmAP评估模型整体性能,如式(9)所示:

本文分别使用原SSD 算法、ResNet50 算法、VGG16+SFPN 算法和RFG_SSD 算法对BDD100K测试集测试检测精度。编写代码利用各个算法训练得到的权重模型计算P、R值,并绘制成P-R 曲线,得到各个算法类别AP 值,如图6 所示。

图6 不同算法的P-R 曲线对比Fig.6 P-R curves comparison among different algorithms
不同算法的检测精度对比如表3所示。从表3可以看出,ResNet50算法相对于SSD算法mmAP提高了6.42个百分点,表明深层特征提取模块ResNet50能够有效提高模型的检测精度。VGG16+SFPN算法相对于SSD算法mmAP提高8.6个百分点,表明SFPN结构有效提高模型的检测精度。最终改进算法RFG_SSD 是将ResNet50模块和SFPN 模块相结合得到,与SSD 相比,其mmAP提高12.69个百分点,与单独使用ResNet50模块或SFPN 模块相比,其mmAP分别提高6.72和4.09个百分点,表明2个模块结合使用能够有效提高模型的检测精度。

表3 不同算法的检测精度对比Table 3 Detection accuracy comparison among different algorithms %
3.4.2 不同算法的性能对比
算法性能的评估不仅要考虑平均检测精度mmAP值,同时也需要评估检测速度,即实时性(FFPS)的快慢情况。实时性表示目标检测网络检测一张图片需要的时间,假设网络检测一张图片需要s,FFPS值越大,表示检测时间越少,速度越快。FFPS如式(10)所示:

本文分别使用SSD 算法、YΟLΟv4 算法及改进SSD 算法对VΟC2007+2012 测 试集 与BDD100K 测试集进行测试评估,并对比各类算法的检测精度和速度。其中文献[23]算法在原SSD 浅层网络结构上设计浅层特征增强模块,以提高浅层小目标的特征提取能力,文献[24]算法在检测识别时利用小目标强化检测模块与原SSD 级联方式,提高小目标的检测效果。这2 种改进算法都只是针对小目标部分结构,虽然小目标检测效果有所提高,但是整体检测性能并没有显著提高。本文改进算法RFG_SSD不仅能够提高小目标检测性能,还提高了整体性能。
本文利用编写代码计算各类算法在两个数据集上的平均精度和实时性表现,同时使用式(1)计算模型检测的目标框尺度大小,并统计尺度小于19×19 的小目标框检测个数。在VΟC2007+2012 和BDD100K 测试集上不同方法的检测结果及适用场景对比如表4所示。从表4 可以看出,在VΟC2007+2012 和BDD100K 测试集上,VGG16+SFPN 算法相对文献[22]、文献[23]及SSD 算法的检测精度和速度都有所提高,并且小目标检测个数增多,验证了SFPN 模块结构提升小目标检测性能的有效性,但是与YΟLΟv4 算法相比,VGG16+SFPN 算法的性能优势并不明显。在BDD 100K 数据集上,本文提出的改进算法RFG_SSD 在检测精度和速度上相对于其他算法都具有明显优势,与目前性能最优的检测算法YΟLΟv4 相比,其整体性能相差不大,精度降低了0.97 个百分点,检测速度加快1.8 frame/s,小目标检测数目相差约600 个。与原SSD 算法相比,RFG_SSD 算法精度提高了12.69 个百分点,检测速度提高34.33 frame/s,小目标框检测数高出3 倍以上。与文献[23]、文献[24]算法相比,RFG_SSD 算法的检测效果得到明显提高,表明ResNet50+SFPN 模块能够有效提高检测准确度。
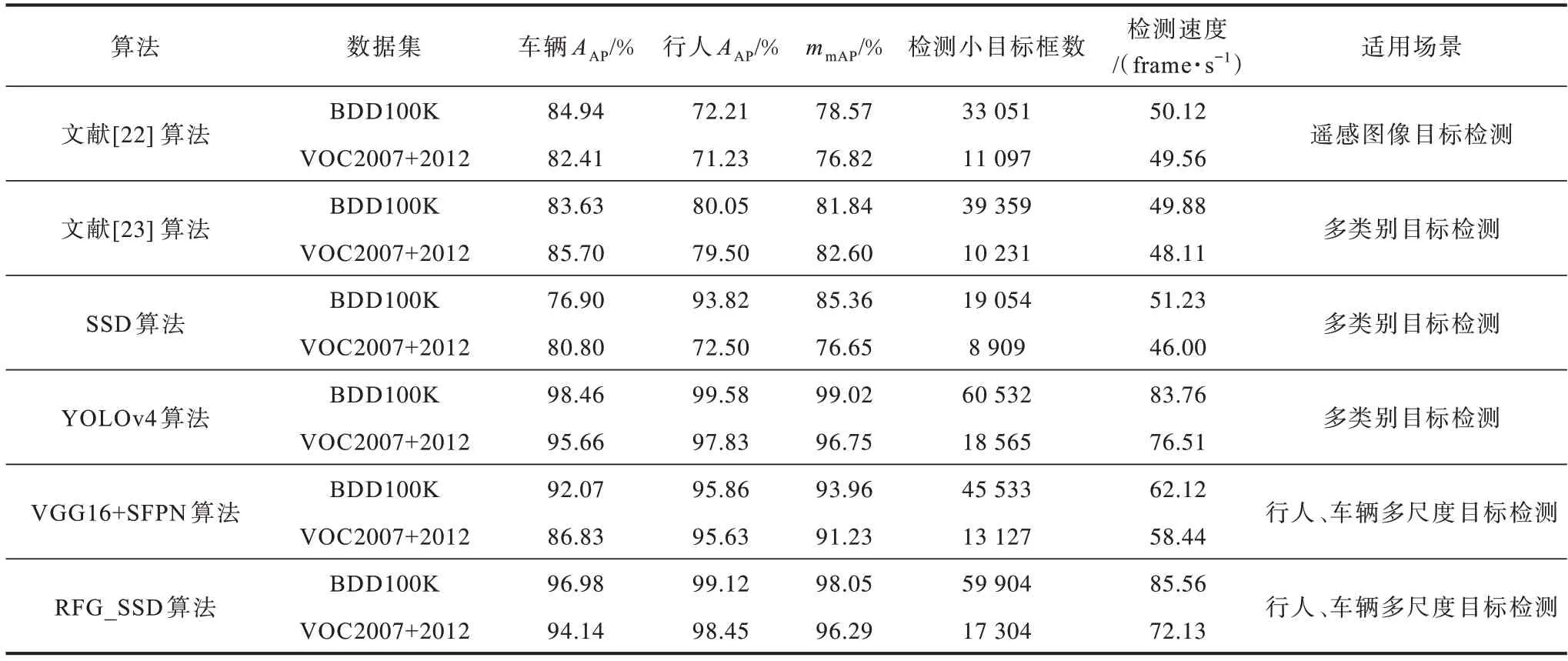
表4 不同算法的目标检测结果与适用场景对比Table 4 Target detection results and applicable scenarios comparison among different algorithms
本文RFG_SSD 算法和SSD 算法对数据集图片进行目标检测对比,如图7 所示。

图7 不同算法的目标检测结果Fig.7 Target detection results of different algorithms
从图7可以看出,对于图片中行人和汽车目标,SSD算法未识别检测出小目标,只检测出部分大目标,RFG_SSD 算法能够精准检测出大、小目标。结果表明,RFG_SSD 算法能够精准检测出图片中任意尺度的目标,并且速度更快,性能得到显著提升,以达到预期行人、汽车多尺度检测的效果。
4 结束语
本文提出一种改进SSD 算法的道路小目标检测算法。在SSD 网络结构基础上,通过引入改进特征金字塔结构SFPN 融合不同层特征的语义信息,将特征网络VGGNet16 替换为网络层数较多的ResNet50,以提高整体网络性能,并通过增加批量归一化、全局平均池化等结构,从而降低参数量。实验结果表明,相比SSD、VGG16+SFPN 算法,该算法能够显著提高检测精度,并加快检测速度,实现多尺度目标检测,其在BDD100K 数据集上的精确度达到98.05%。由于本文算法仅对道路行人、车辆进行检测,因此后续将改进检测模型,使其适用于道路多类别、多尺度的检测。
