基于改进BiGRU-CNN 的中文文本分类方法
2022-05-14陈可嘉
陈可嘉,刘 惠
(福州大学 经济与管理学院,福州 350116)
0 概述
PC 互联和移动互联的深入发展使得互联网文本数据呈现指数级增长的态势。文本分类作为高效的自然语言处理技术,在用户个性化新闻推荐[1]、文本内容检索[2]、在线评论情感分析[3]中发挥着重要作用,为进一步处理和挖掘文本信息奠定了基础。传统基于机器学习的文本分类算法,如K 近邻、支持向量机、朴素贝叶斯、决策树等,不仅需要依靠人工对文本特征进行标注,而且容易出现维度过高或者局部最优等问题,同时参数的变化对分类结果的影响较大,算法鲁棒性较差,文本分类效果有待提升。随着深度学习技术在图像处理和语音识别领域的发展应用中取得显著效果,近年来以深度学习为基础的文本分类算法层出不穷[4]。基于深度学习的神经网络模型,如卷积神经网络(Convolutional Neural Network,CNN)、循环神 经网络(Recurrent Neural Network,RNN)等,通过多层次网络的学习和训练,能够实现对文本深层次特征的自动提取,并提供了一种端到端的解决方案。深度学习模型如CNN 在文本分类任务中不仅能够自动学习和提取文本的关键特征,而且在多层次网络的训练过程中涉及的参数相对较少,可以避免出现过拟合的现象。因此,基于深度学习的文本分类方法相较于基于机器学习的分类方法,在多种自然语言处理任务中取得较好表现,具有高效和准确的特点。CNN 和双向门控循环单元(BiGRU)是目前在文本分类领域应用较为广泛的两种神经网络模型,但这两种模型在文本分类任务中都存在着缺陷,CNN 对上下文语义信息关注较少,忽视句子间的长期依赖关系,而BiGRU 在文本特征提取方面能力不足,不能考虑到文本间存在的局部依赖关系。
注意力机制是一种提高特定区域观测精度的机制,可以有选择性地聚焦于观察区域的某些部分,能够对稀疏数据的关键特征进行快速提取。自注意力机制是注意力机制的一种特殊变体,更擅长获取数据内部的相关性,在文本局部关键信息的提取上表现良好,能够弥补BiGRU 在特征提取方面的不足,然而传统的自注意力机制在训练过程中不能有效对文本特征向量进行权重调整,存在权重分配局限的问题。
针对上述问题,本文结合CNN、BiGRU 和自注意力机制三者的优点,提出一种基于改进自注意力机制的BiGRU 和多通道CNN 文本分类模型SAttBiGRU-MCNN。引入位置权重参数对自注意力机制进行改进,降低信息量较低的文本向量权重值,对权重值进行重新分配,以增强文本特征的表达能力,提升文本分类的准确性。
1 相关工作
近年来,针对CNN 在文本分类任务中的应用和改进得到了广泛关注。文献[5]首先通过构建层次模型识别文本的主题句,再将主题句引入CNN 中对文本的句子向量表示分配权重,进一步提高CNN 在文本分类中的监督学习能力;文献[6]提出基于语句层面的CNN 分类方法,通过结合改进的TF-IDF 算法和Word2vec 技术,采用CNN 实现文本的分类;文献[7]采用奇异值分解方法对CNN 的池化层进行特征降维,避免传统CNN 池化过程中语义损失的问题,进而获取更多的特征信息;文献[8]通过采用多个CNN 构建多通道CNN 对中文微博进行情感分类,从多方面对文本特征进行提取,捕捉更多隐藏的文本信息;文献[9]提出基于CNN 的文本分类模型,将CNN 应用于微博文本的多标签分类任务中,取得较好效果;文献[10]通过评价输出特征的识别能力对卷积滤波器性能进行评估,以此进行特征修剪,提高CNN 的文本分类效果;文献[11]提出一种基于范围的卷积神经网络模型(LSS-CNN)实现大规模文本的分类,与基于窗口的CNN 相比,能够实现更深层的文本信息表示。基于CNN 的文本分类模型虽然能够实现文本特征的自动抽取,但没有考虑到句子间存在的长距离依赖关系。
RNN 是一种具有记忆性的神经网络,可以捕捉句子间的上下文语义信息,但容易出现梯度弥散的问题。GRU 和LSTM 虽然在RNN 的基础上加入了门机制,弥补了RNN 的缺陷,但未能识别文本的上下文语义关系。而BiGRU 和BiLSTM 模型则在GRU 和LSTM 的基础上充分利用了过去和未来的相关信息,不仅能够考虑到句子间的长距离依赖关系,而且能够避免梯度弥散现象发生,在文本分类任务中表现良好。文献[12]将BiGRU 应用于文本情感分类任务中,采用BiGRU 神经网络层捕捉文本特征依赖,提出基于BiGRU 的文本分类模型完成文本的情感分析;文献[13]通过引入密集连接卷积网络对双向门控循环单元进行改进,提出DC-BiGRU-CNN模型对文本进行分类,提高文本分类效果;文献[14]采用长短时记忆网络(Long Short-Term Memory,LSTM)、门控循 环单元(Gated Recurrent Unit,GRU)、BiGRU 和双向 长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络方法对用户在线评论进行特征提取分析,有效实现了文本的情感分类;文献[15]提出一种CNN 和RNN 相结合的分类模型,将其应用于文本特征的提取中,得到较好的效果;文献[16]将双向门控循环单元和CNN 相结合,提出一种字符级的文本分类模型,实现对文本全局和局部语义的提取。由于BiGRU 模型相比BiLSTM 模型具有更简单的结构和更好的收敛效果,因此选取BiGRU 模型应用于文本分类任务中。基于BiGRU 的文本分类模型虽然能够识别句子的长距离依赖关系,但是在文本的局部特征提取方面却能力不足。
近年来,自注意力机制在文本分类任务中受到广泛关注。文献[17]将注意力机制应用于比较句识别中,提出端到端的层次多注意力网络模型进行文本的分类;文献[18]在文本分类任务中引入注意力机制,并结合CNN 和BiGRU 各自在文本信息提取上的优点,提出基于注意力机制的多通道CNN 和BiGRU 模型(MC-AttCNN-AttBiGRU)完成文本分类;文献[19]将注意力机制应用于文本的情感特征提取任务上,与多通道CNN 以及BiGRU 相结合,完成文本的情感分类任务;文献[20]将注意力机制应用于词语级别中,以此实现文本的多角度特征提取,并采用CNN 和BiGRU 对文本深层次语义进行挖掘,在此基础上实现文本分类;文献[21]提出一种基于词性的自注意力机制网络模型对文本进行分类,采用自注意力机制学习文本的特征表达并结合词性信息实现文本分类;文献[22]通过在双向RNN 中引入自注意力机制,提出用于句子分类任务的基于自注意力机制的双向RNN 模型架构,进一步提高文本分类效果;文献[23]结合BiLSTM 和自注意力机制,提出基于自注意力机制的BiLSTM 模型进行文本分类;文献[24]采用基于自注意力机制和多通道特征的BiLSTM 模型用于文档级的文本分类任务中,通过自注意力机制增强文本特征的表达能力。
自注意力机制虽然在文本分类任务中表现优异,然而由于在传统自注意力机制训练过程中,输入的文本向量训练位置不同,导致位置靠前的文本向量在训练过程中存在初始观察窗口较小及信息量较低的问题。因此,直接顺序地对输入的文本向量进行注意力得分计算存在一定的局限性。
基于此,本文提出基于改进自注意力机制的双向门控循环单元(BiGRU)和多通道CNN 的文本分类模型。引入位置权重参数对自注意力机制进行改进,对文本深层次序列重新分配权重,改善传统自注意力机制存在的权重分配局限问题,通过对多通道CNN 进行优化,采用不同大小、个数的卷积核进行不同粒度的文本特征提取,得到更丰富、更准确的文本特征,同时引入批标准化处理对经过卷积运算的特征向量进行调节,提升模型的学习能力。最后将改进的自注意力机制、BiGRU 和优化的多通道CNN相结合应用于文本分类任务,避免传统RNN 梯度弥散或梯度爆炸的现象发生,同时捕捉文本的长期依赖关系,加强文本的局部特征提取能力,进一步提高分类模型的总体性能。
2 SAttBiGRU-MCNN 文本分类模型
2.1 整体模型架构
SAttBiGRU-MCNN 文本分类模型主要由两个部分组成,包括改进的自注意力机制和BiGRU 构成的神经网络通道,以及由3 个CNN 拼接组成的并行通道。BiGRU 通道主要用于获取文本信息中的长距离依赖关系,而CNN 通道主要对文本的局部特征信息进行抽取。模型整体结构如图1 所示。

图1 SAttBiGRU-MCNN 模型整体结构Fig.1 Overall structure of SAttBiGRU-MCNN model
2.2 嵌入层
通过嵌入层可以实现文本的向量化转换,提取文本基础语义信息,将文本表示为向量形式进行存储。假设输入样本L由l个句子组成,其中l个句子由n个词构成,则输入样本表示为L={s1,s2,…,sl},输入样本中的第i个句子表示为si={wi1,wi2,…,win},对输入样本进行文本向量化转换,得到词向量w∈wL。这一过程中包括对输入样本的数据预处理、数据转换等操作,输入样本经过文本向量化后,生成相应的词向量矩阵。将样本中第i个句子中的第j个词向量表示为Wij,则第i个句子的词向量矩阵可以表示为:

其中:Wi1:iN指第i个长度为N的句子对应的词向量矩阵,表示Wi1,Wi2,…,WiN;⊕为级联操作符,表示词向量之间的连接关系。通过文本向量转化,每一条文本数据都被转化为长度相同的索引向量,以此生成对应的词向量矩阵。
2.3 BiGRU 层
这一层的输入为经过嵌入层处理后输出的文本向量。BiGRU 层的主要作用是对句子间的长距离依赖关系进行识别和提取,进一步提取文本的深层次特征。BiGRU 模型由两个独立的GRU 模型构成,GRU 的模型结构如图2 所示。

图2 GRU 模型结构Fig.2 GRU model structure
GRU 相比LSTM 模型在结构上更为简单,模型参数更少,可以降低训练过程中的过拟合风险,同时模型训练需要的时间更短,其计算公式如式(2)~式(5)所示:
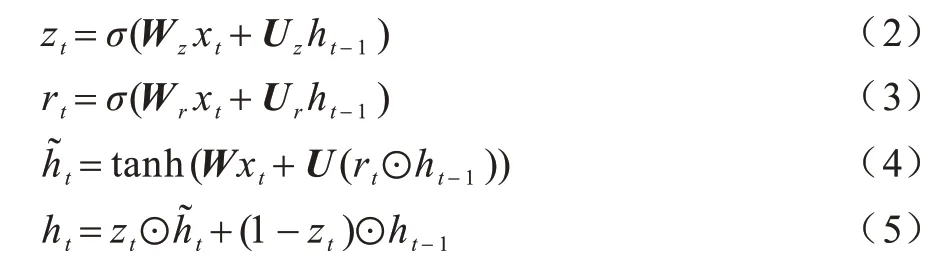
其中:Wz、Wr、W、Uz、Ur、U为GRU 的权值矩阵;ht为模型当前的隐藏状态;ht-1为上一状态的输入;⊙代表元素相乘表示候 选状态;zt和rt分别表示更新门和重置门;xt为在t时刻模型的输入状态;σ和tanh分别表示sigmoid 激活函数和tanh 激活函数。
在BiGRU 模型中,两个GRU 使用同一个词向量列表,但两者的参数相互独立。可以将输入样本转换的文本向量理解为输入序列,输入序列以正向和反向的顺序分别通过前向GRU 和后向GRU,每一时刻得到的文本特征信息都包括上文与下文之间的相关性。BiGRU 的模型结构如图3 所示。
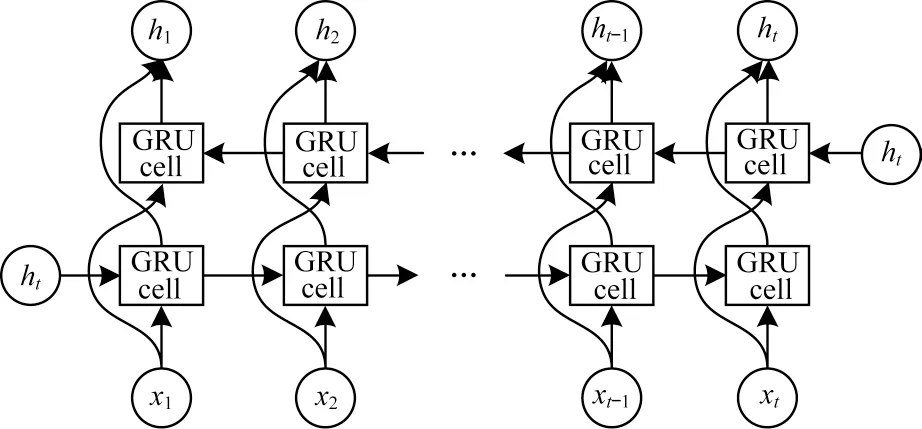
图3 BiGRU 模型结构Fig.3 BiGRU model structure
在某一时刻t,BiGRU 的隐藏输出由两个相互独立的GRU 共同决定,计算公式如式(6)~式(8)所示:

2.4 改进的自注意力机制层
在文本分类任务中,每个词对分类结果的影响程度是不同的,为了区别每个词的重要程度,引入自注意力机制层对经过BiGRU 处理后的输出向量进行权重分配。自注意力机制是注意力机制的一种特殊变体,为了更好地理解自注意力机制的原理,首先对注意力机制的计算过程进行分析。注意力机制可以理解为由多个Query 和Key-Value 构成的映射函数,计算公式如式(9)~式(11)所示:

其中:Q表示查询;V为对应的键值;K-V为向量键值对;ai表示经过softmax 函数归一化处理后得到的权重值。
自注意力机制的加入可以在保留原始特征的基础上突出文本的关键特征,得到更准确的文本特征向量表示。传统的注意力机制在训练过程中需要参考部分外部元素,而自注意力机制的计算只需依靠自身内部的元素。考虑输入序列中不同位置的文本向量对输出结果的贡献度有所不同,例如位置靠前训练的文本向量,由于观测窗口较小,在训练过程中获取的信息相对有限,因此训练得到的自注意力权重值总体上会偏大。为了避免这一现象,引入位置权重参数Weight 对自注意力机制进行改进,根据文本向量训练的位置,对计算得到的自注意力权重概率值进行重新分配,降低训练位置靠前的文本向量权重,适当提高训练位置靠后的文本向量权重值,以此进一步优化文本特征向量的表示,增强文本特征的表达能力。Weight 是一个parameter 迭代器,其为Tensor 的一个子类,初始值为1,在训练过程中会不断进行优化,从而实现训练时降低靠近开头特征的自注意力整体权重,靠后的特征获取更高的权重。具体计算公式如式(12)~式(14)所示:

其 中:m为文本 词长 度;X∈Rn为BiGRU 层输出的n维向量;为函数的调节因子,通常表示输入向量的维度,调节因子可以对X·XT的内积进行调节,避免函数得到的值差距过大导致结果分布不均匀。
2.5 多通道CNN
CNN 通道的输入是经过嵌入层映射得到的文本向量。模型采用3 个并行的CNN 通道分别进行文本的局部特征提取操作,3 个CNN 通道的参数相互独立。为了进一步提高多通道CNN 的特征提取能力,获取文本的多元特征,分别在3 个CNN 通道中再加入一层卷积对CNN 进行优化,增强文本的局部特征表达能力,同时引入批标准化层进一步加强模型的学习能力。
2.5.1 卷积层
卷积层使用卷积核对输入的文本向量进行卷积运算,通过固定尺寸的窗口完成向量的特征映射,得到文本的局部特征信息。在CNN 中,通常采用h×n维大小的过滤器进行卷积运算,其中h表示设定的卷积核尺寸,n表示选取的词向量维度。本文设置h分别为3、4、5,同时在第一个卷积层中将过滤器个数设置为256,第二个卷积层的过滤器个数设置为128。将输入的文本向量表示为矩阵H∈Rk×n,其中k表示句子的词向量个数,n为词向量维度,将卷积核定义为S∈Rh×n,则卷积层的运算过程可以表示为:

其中:ci表示通过卷积运算输出的文本的第i个特征值;f为非线性激活函数,本文采用Relu 函数;·表示两个矩阵点乘;Hi:j表示从 第i个词到 第j个 词的词向量矩阵;b为偏置项。对文档中各个窗口的特征矩阵进行卷积运算,能够得到相应的特征图c,将其表示为:

2.5.2 批标准化层
为了提高模型的自适应能力和表达能力,加入批标准化层对上层输出向量进行处理,标准化处理不仅可以提高神经网络的训练速度,加快收敛速度,同时能够对输出的特征分布进行调整使其更加稳定,有助于增强模型的学习能力,进一步提高分类效果。
2.5.3 池化层
池化层通过设置固定的步长stride 对文本特征进行采样。池化操作主要包括最大池化层和平均池化层两种策略,本文采用最大池化策略进行池化处理。这一过程主要是将不重要的文本特征进行丢弃,保留最关键的文本特征信息,池化操作不仅能够实现特征向量的降维,同时能够避免训练过程中发生过拟合现象。经过池化操作,输出固定长度向量:

2.6 全连接层
全连接层的作用是把经过池化操作得到的多个特征向量进行重新组装拟合,并将其作为全连接层的输入,并通过激活函数实现文本的分类。这一过程可以有效降低文本特征信息的损失。
2.7 输出层
模型采用激活函数softmax 实现文本的分类。使用softmax 对上层输出的特征向量进行计算,以此得到文本分类结果,具体计算过程如式(18)所示:
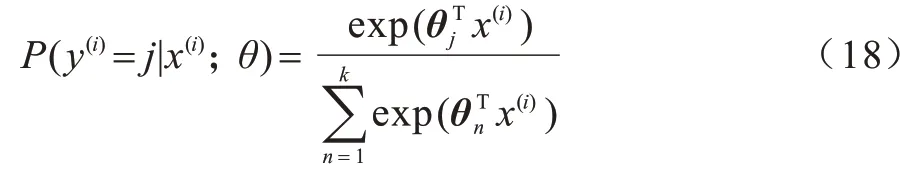
其中:P指的是输入文本x被分到类别y的概率值;θ表示模型训练的参数。
3 实验
3.1 实验环境
实验平台为Windows10 20H2 版本以及Ubuntu 18.04 操作系统,硬件为Intel i7-10750、8×2.6 GHz 处理器、16 GB 内存、GTX1650Ti 显卡,模型采用Python编程语言实现,Python 版本为3.7,使用的深度学习库包括 tensorflow2.3.0、keras2.4.3、gensim3.8.3、numpy1.18.5,编码工作通过Pycharm 开发工具完成。
3.2 实验数据集
实验选取搜狗语料库和THUCNews 两个数据集作为实验数据集。SogouCS 是由搜狗实验室提供的新闻数据集,下载地址为:http://www.sogou.com/labs/resource/cs.php;THUCNews 是由新浪新闻RSS订阅频道的历史数据整理生成,下载地址为:http://thuctc.thunlp.org/。分别将两个数据集划分为训练集和测试集,其中80%用于模型训练,20%用于模型测试,实验数据集统计信息如表1 所示。

表1 实验数据集统计信息Table 1 Statistics of experimental datasets
3.3 实验预处理与模型超参数设置
模型具体超参数设置如表2 所示。

表2 超参数设置Table 2 Hyperparameter settings
首先采用Jieba 分词工具对输入的两个数据集分别进行中文分词操作,删除标点符号后,再进行停用词的过滤处理,这一过程采用哈尔滨工业大学停用词表,然后将输出文本中无实际含义的单个字进行去除,得到词向量的训练语料。实验中设置两个数据集文本句子的最大长度分别为300 和40,当句子过长时采取截断操作,当句子过短时则进行补零操作。词向量的训练采用GloVe 模型。
3.4 评价标准
本文采用准确率(A)、精确率(P)、召回率(R)以及F1 值作为实验的评价标准。相关的混淆矩阵结构如表3 所示。

表3 混淆矩阵Table 3 Confusion matrix
在表3 中,矩阵的行为样本的真实类别,矩阵的列为样本的预测结果。
准确率(A)是分类正确的样本占总样本的比重,计算公式为:

精确率(P)是被正确预测的样本占所有预测类别正确的样本的比重,计算公式为:

召回率(R)是被正确预测的样本占所有真实类别正确的样本的比重,计算公式为:

F1 值是基于精确率和召回率的调和平均值,计算公式为:

3.5 实验对比
为了验证提出的文本分类模型的合理性和有效性,分别在两个实验数据集下进行不同分类模型的对比测试。将提出的模型和以下11 种文本分类模型进行对比评估:
1)CNN[25]。基于单层CNN 的文本分类模型,将经过数据预处理得到的词向量作为CNN 的输入,将卷积核时域窗长度设置为3,词向量维度设置为300,经过一层卷积后是池化操作,然后是全连接层和输出层。
2)FastText[26]。由Facebook 在2016 年发表的一种简单快速实现文本分类的模型。将词向量作为输入,经过一个平均池化层作为隐藏层,最后通过softmax 输出分类结果。
3)MCNN(Multi-channel CNN)。即多通 道CNN,将经过嵌入层处理得到的300 维词向量分别输入到卷积核时域窗长度为3、4、5 的卷积层中,然后将这3 个CNN 通道得到的词向量拼接在一起,经过全连接层后再通过激活函数输出分类结果。
4)RCNN[27]。由RNN 和CNN 相结合的 文本分类模型。首先采用BiLSTM 对文本的特征向量进行提取,再将其与嵌入层输出的词向量进行拼接,然后经过一层卷积后实现对文本的分类。
5)Self-Attention-CNN。使用自注意力机制和卷积神经网络结合的方法实现文本分类,将模型的嵌入层输出使用自注意力机制进行特征加权,然后使用单层CNN 进行特征提取,再通过输出层输出文本分类结果。
6)BiGRU。采用BiGRU 模型对文本进行分类。BiGRU 模型中前后向GRU 的隐藏层神经元个数均设置为128 层,Dropout 设置为0.2。
7)SAttBiGRU。通过BiGRU 模型获取文本的全局特征向量,再利用自注意力机制对BiGRU 输出的特征向量进行加权,增强文本特征的表达能力,在此基础上进行文本分类。
8)BiGRU-MCNN。分别使用BiGRU 模型和多通道CNN 模型对嵌入层的输出向量进行文本语义特征提取,得到对应的特征向量表达并将其进行拼接操作,经过全连接层后使用激活函数进行分类。
9)MC-AttCNN-AttBiGRU[18]。首先采用注意力机制分别对多通道CNN 和BiGRU 进行加权,再将得到的文本特征向量进行拼接后输入全连接层,最后采用softmax 实现文本分类。
10)BiGRU-SAtt-MC-CNN。首先使用BiGRU训练得到文本的语义特征表示,然后引入自注意力机制对BiGRU 的参数进行加权后,再与经过多通道CNN 得到的文本特征向量进行拼接,作为全连接层的输入,最后实现文本分类。
11)BiGRU-SAtt-MCNN。这一模 型和上 述BiGRU-SAtt-MC-CNN 模型流程一致,不同的是采用本文提出的优化的多通道CNN 对文本局部特征进行提取。优化的多通道CNN 由3 个CNN 通道构成,每个通道由两层卷积组成,卷积核的个数分别设置为256 和128,并引入Batch Normalization 函数进行批标准化处理。
3.6 结果分析
本文将提出的SAttBiGRU-MCNN 文本分类模型与上述11 种模型分别在SogouCS 和THUCNews 数据集进行对比实验,实验结果如表4、表5所示。结合表4、表5 的对比实验结果,可以看出提出的基于改进自注意力机制的BiGRU 和多通道CNN 的文本分类模型相比其他11 种分类模型,在两个实验数据集上都取得较好的分类效果,准确率分别达到98.95%和88.1%,相比其他分类模型分别最高提升了8.99 和7.31 个百分点,同时精确率、召回率和F1 值都取得较好表现,表明所提出的文本分类模型的优越性。

表4 SogouCS 数据集对比实验Table 4 Comparison experiment of SogouCS dataset %
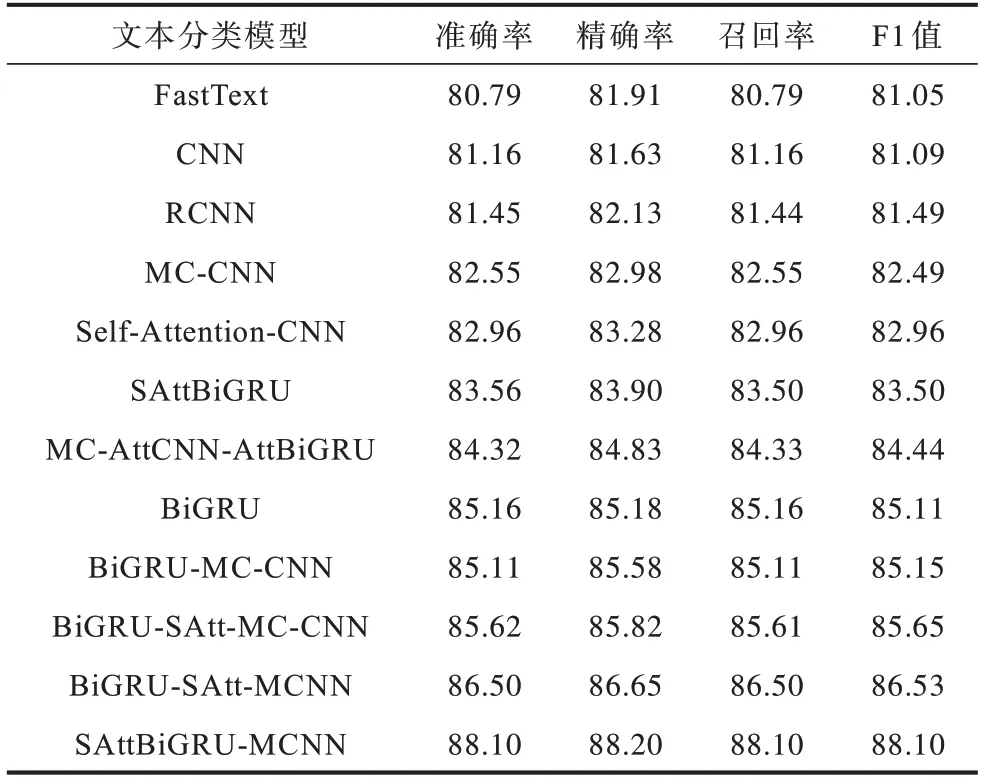
表5 THUCNews 数据集对比实验Table 5 Comparison experiment of THUCNews dataset %
对实验结果进行分析,可以发现在两个数据集的对比实验中,MC-CNN 的分类准确率都比单层的CNN 更高,表明MC-CNN 能够有效提高文本分类效果,这是因为在多个CNN 通道中可以进行不同粒度的文本特征信息提取,能够有效识别文本间的序列关系,在文本特征的提取上优于单层CNN。此外,对比CNN 模型和RCNN 模型的实验结果,发现在CNN 中加入RNN 同样可以提升分类准确率,这是因为RNN 可以弥补单层CNN 在文本特征提取任务中忽视上下文语义信息的缺陷,能够捕捉句子间的长期依赖关系,可以得到更为准确的语义表示。对Self-Attention-CNN 模型的文本分类结果进行分析,发现其分类性能优于CNN、FastText、多通道CNN 和RCNN 模型,验证了自注意力机制在文本分类任务中的优良性能。对比BiGRU-SAtt-MC-CNN 和MCCNN、BiGRU、Self-Attention-CNN 分类模型,可以发现三者相结合的文本分类方法总体评价上都优于单个模型,表明将多通道CNN、BiGRU 和Self-Attention 相结合应用于文本分类中能够有效发挥各自模型的优势,弥补模型的不足,验证了本文将3 种方法相结合用于文本分类的准确性。
为了验证本文提出的改进的自注意力机制以及优化的多通道CNN 能够有效提高文本分类的有效性和准确性,对BiGRU-SAtt-MC-CNN、BiGRUSAtt-MCNN 以及本文提出的SAttBiGRU-MCNN 文本分类模型的实验结果进行对比分析。通过对BiGRU-SAtt-MC-CNN 和 BiGRU-SAtt-MCNN 在SogouCS 和THUCNews 数据集上的实验结果进行分析可以看出,加入优化的多通道CNN 的模型分类效果都优于采用普通的多通道CNN 的分类模型,验证了优化的多通道CNN 可以提高文本分类的准确率。这是因为优化的多通道CNN 在原有的多通道CNN模型上,分别在各个通道中加入了一层不同卷积核数的卷积层,可以进一步提高模型的特征提取能力,得到文本的多元语义特征,增强CNN 对文本局部特征信息的捕捉能力,同时引入的批标准化处理层可以对卷积层输出的特征分布进行调整,增强模型的学习能力。对BiGRU-SAtt-MCNN 和SAttBiGRUMCNN 的实验结果进行分析,发现采用改进的自注意力机制的分类模型在准确率、精确率、召回率和F1值上都比采用传统自注意力机制的模型表现更好,因此说明本文提出的引入位置权重参数的自注意力机制可以有效提高文本分类性能,这主要是因为改进后的自注意力机制能对特征向量的权重值进行重新分配,有效降低信息量较少的向量权重值,以此提高文本特征的表达能力,进一步提升文本分类的准确性。
4 结束语
本文结合改进的自注意力机制、BiGRU 以及多通道CNN,提出一种SAttBiGRU-MCNN 文本分类模型。该模型通过BiGRU 对文本序列信息进行捕捉学习,给出文本的上下文语义信息,利用改进的自注意力机制对文本深层次序列权重进行重新分配,可获得更加准确的文本关键语义信息,同时采用多通道CNN 可以获取多特征的文本局部语义信息,得到更丰富的文本语义表示。将本文提出的文本分类模型应用于两个公开数据集上,并与其他11 种文本分类模型进行对比分析,实验结果验证了该模型的准确性和有效性,表明了该模型能够得到更准确的文本分类结果。考虑文本分类任务中词语的语义扩展对文本的特征表示存在重要影响,下一步将结合语义扩展和深度学习网络对文本分类模型进行优化,并在此基础上开展文本的细粒度分类研究。
