一种基于区域权重平滑的弱监督目标定位方法
2022-05-13刘富,罗冰,裴峥
刘 富,罗 冰,裴 峥
(西华大学无线电管理技术研究中心,四川 成都 610039)
目标定位已被应用至监控、二维码识别等领域,它要求生成准确围绕目标的检测框[1−2]。目标定位以目标检测框作为监督信息,需要大量的训练数据。随着其应用领域的不断拓展,在新场景下制作准确且大量的标签便成为了一个棘手的问题,于是研究者探索弱监督下的解决办法[3−4],即仅使用图像类别标签。Class activation maps(CAM)[4]在图像分类网络[5]中引入全局均值池化并取消部分全连接层,在网络中间层得到与目标类别对应的激活区域,利用该区域,加以阈值筛选,完成目标定位。然而,CAM 所得的结果趋向于覆盖目标的显著性区域。这是因为在图像分类任务中,目标的显著性区域,如鸟的头、人的躯干等,能够提供强大的类别信息,这便导致网络在分类预测时会过于依赖它们。在这样的情况下,中间层特征往往仅在目标显著性区域激活,以致无法得到准确的定位结果。
针对上述问题,一系列擦除式方法[6−7]被提出。Adversarial erasing(AE)[6]将所得激活区域在原图像上进行擦除,在擦除后的图像上进行分类训练,迫使网络关注目标的其他部位。Attentionbased dropout layer(ADL)[7]通过注意力机制探索显著性区域并随机地擦除它们,其训练过程更为简便。当显著性区域被擦除后,网络只能从目标其余部位获取类别信息,其对这些部位的依赖程度越高,对应激活值也就越大,这样便达到了平衡显著性区域与其余部位的目的。不同于以往修正特征的方法,本文从损失函数上探索区域平衡策略。笔者发现,经卷积神经网络所提取的视觉特征通常在不同通道表征不同的区域,并且目标激活区域由这些通道及它们对应的分类层权重决定,但是极少数的通道却占据了较大的权重,而这些通道的视觉信息恰好对应显著性区域,这便导致了定位区域响应的稀疏性。为使网络在定位目标时充分考虑各个通道所携带的视觉信息,本文提出分类层权重的自适应标准差正则项(standard deviation regularization,SDR),通过控制正则项所涵盖的权重范围,分类层能够在学习到相近权重的同时保留分类能力,这样便能完成目标区域平滑。
1 相关工作
由于缺少检测框标签信息,弱监督目标定位无法如目标检测那般直接进行回归,更多的是采用由视觉特征生成检测框这样自下而上的方法。
1.1 弱监督目标定位
弱监督目标定位方法大多基于CAM[4]。CAM首先训练图像分类网络,然后将所得分类层权重与对应视觉特征进行卷积,得到定位区域。然而,这样的方法通常只能得到目标的显著性区域。为了解决该问题,AE[6]利用所得显著性区域对原图像进行擦除,迫使网络关注整个目标。Hide-and-seek(Has)[8]则采用了随机擦除图像块的方式,简便同时有效。在擦除后的图像上提取信息会导致性能下降,于是,Adversarial complementary learning(Acol)[9]融合显著性区域与擦除后结果,得到了更为整体的目标。上述方法需要先得到显著性区域后,才能进行擦除,训练步骤繁琐。ADL[7]则直接利用注意力机制[10]提取显著性区域,并随机擦除视觉特征,能够在减少训练步骤的同时提升准确率。不同于上述擦除式的方法,Divergent activation(DANet)[11]从相似的物种间提取共性并引入空间位置差异,迫使网络学习到更多视觉模式。然而,这些方法均从修正视觉特征的角度出发,并未关注到分类层权重对激活区域的影响。
1.2 目标检测
目标检测方法按回归次数可分为:一阶段检测方法、二阶段检测方法。整体上,一阶段方法仅进行单次回归,处理速度快,但准确率不如后者。You only look once(YOLO)[12]将特征谱分为数个网格,并在网格上进行回归。考虑到较小的目标在网络的最高层可能丢失,Single shot multibox detector(SSD)[13]采用了多级检测方法。Focal Loss[14]针对训练样例中正负例不均衡的问题,将focal loss用于平衡正负例损失。上述方法虽拥有较快的检测速度,但对设备性能的要求仍然较高,无法应用于轻量化终端。文献[15]使用MobileNetV2 替换YOLOv3 特征提取网络,并提出针对红外图像的增强算法,能够在提升检测精度的同时大大减少模型参数量。在二阶段检测方法中,R-CNN[16]首先提取候选区域,然后进行回归。在R-CNN 中,每个候选区域均会进行单独的特征提取,速度较慢。FAST R-CNN[17]针对整幅对象仅提取一次特征,并直接利用候选区域选择特征,能够大大加快检测速度。传统算法由于无法使用GPU 加速处理,提取候选区域的速度较慢。Faster R-CNN[18]则提出直接由卷积网络生成候选区域,速度更快。这类方法需要检测框标签,但标签制作较为繁琐。本文则考虑仅使用弱标签,意在减轻标注工作量。
2 基于区域平滑的弱监督目标定位方法
现有方法较少关注分类层权重对目标区域的影响。本文通过引入分类层权重的自适应标准差正则项,迫使网络学习到相近的权重,能够在降低显著性区域关注度的同时提升其余区域所占比重。网络框架图如图1 所示。图中GAP 表示全局均值池化,Conv 表示卷积操作。
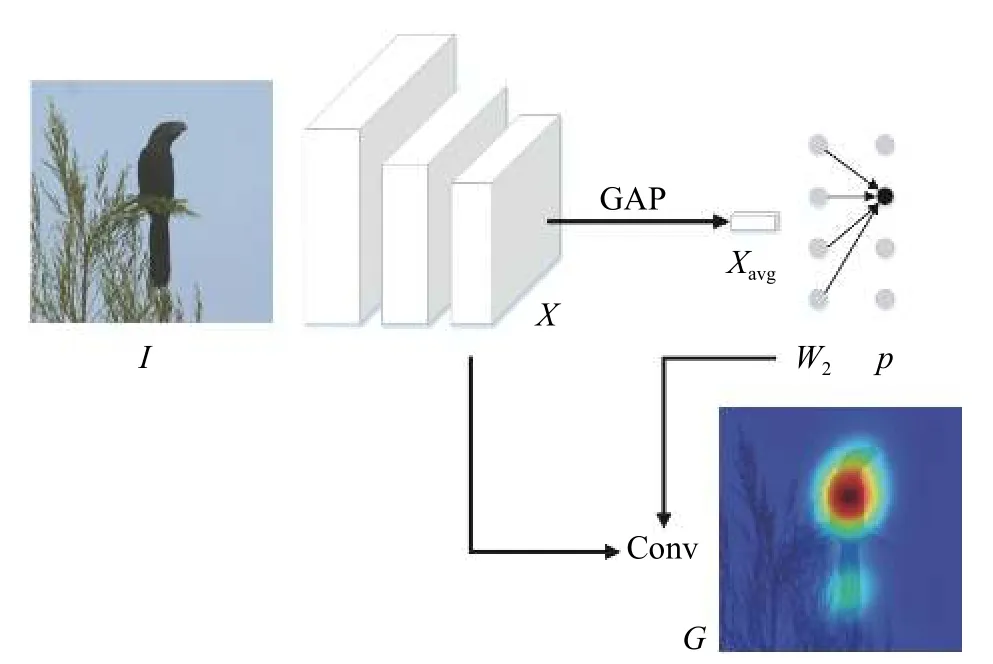
图1 网络框架图
2.1 目标区域生成
目标区域生成需要首先训练图像分类网络。对于一幅图片I,利用卷积网络提取其视觉特征X,X=f(I,W1),其中f、W1分别表示卷积网络及其参数。X∈RK×H×W,K、H、W分别表示视觉特征的通道数、高和宽。然后池化视觉特征并进行类别预测,其损失函数可表示为:
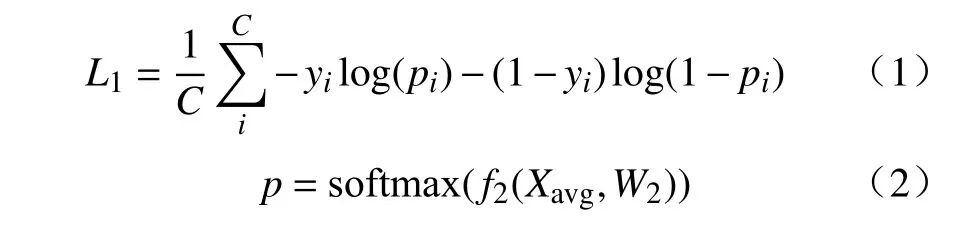
式中:yi表 示图像类别标签;pi表示图片属于类别i的 概率;C表示类别总数;Xavg∈RK,表示在特征谱X上进行全局均值池化的结果;f2、W2分别表示分类层及其权重,W2∈RC×K;softmax表示激活函数。W2表示了网络对各个通道所携带类别信息的依赖程度,值越高,表明对应通道池化前的视觉区域越能提供强大的类别信息,利用这样的对应关系便可得到目标区域。在具体实现上,使用W2在X上进行卷积,并进行归一化后,得到目标区域Gn,为
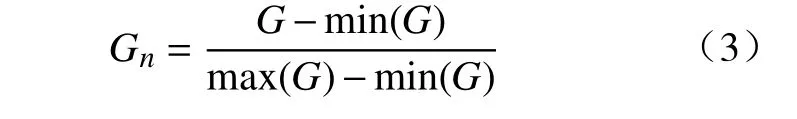
式中:G表 示卷积结果;min、max分别表示取最小值与最大值。此外,为剔除背景,需进行阈值筛选,其筛选结果为
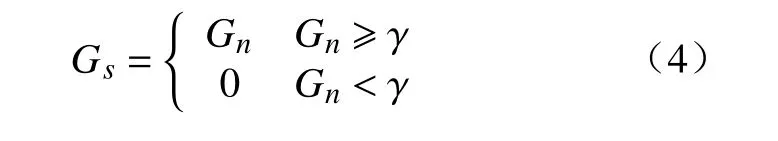
式中Gs表示目标区域经阈值 γ筛选后的结果。然而,这样的方法趋向于覆盖目标最具有显著性类别信息的部位。为得到覆盖目标全局的结果,本文提出了分类层权重的自适应标准差正则项。
2.2 自适应标准差正则项
分类层权重W2在 视觉特征X上的卷积可以拆分为乘积的和。记二者乘积的结果为M,则M∈RC×K×H×W。在M的通道维度求和,即可得到卷积结果G,G∈RC×H×W。该结果能够表示图像I中不同类别目标的激活区域。在M的空间维度求均值得到S,S∈RC×K。该结果能够表示特定类别下各个通道在生成激活区域时所占的比重。然而,在通道重要性S中,极少数通道产生了较大的值,并支配了最终定位区域。如图2 所示,S由大至小排序后,前3 个值远远大于其他,这表明激活区域易受少部分通道影响。它们对应通道的激活区域如图3 中第1 行所示,均落在了鸟的头顶位置。图3 中第2 行则是那些较小的值所对应的区域,它们虽然能够覆盖目标的其余位置,如鸟头、鸟嘴,但由于远远低于前3 个值,经阈值筛选后往往被视为背景。对激活区影响最大的3 个通道仅覆盖鸟的头部,而其他通道虽覆盖更多部位,但由于权重过低,往往被视为背景,这导致了激活区域的不平滑。缩小通道重要性S之间的差距,便可保留更多目标区域。引入分类层权重W2的标准差正则项能驱使网络学习到相近的权重,这样便能平衡各个通道所占比重,但是,当所有权重相近时,网络将无法进行类别判断。因此,本文仅考虑对生成激活区域贡献最大的前Q项。记S最大值与阈值 γ的乘积为通道阈值Ss,则大于Ss的项表征前景的可能性更高,那么将Q初步确定为S中大于Ss的项数便能将权重平滑控制在表征前景的通道上。在该情况下,引入的标准差正则项为
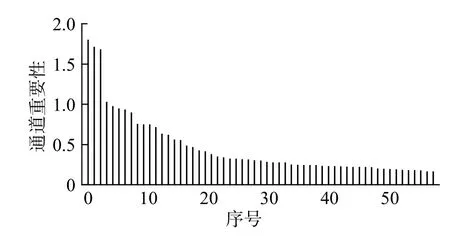
图2 通道重要性S
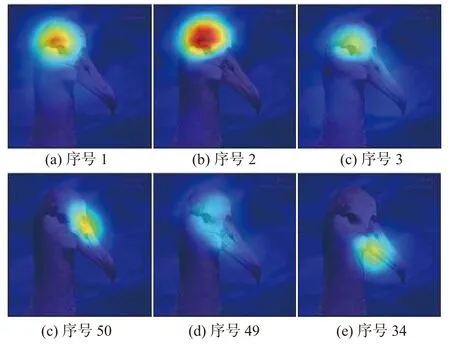
图3 通道重要性S 中各序号对应激活区域
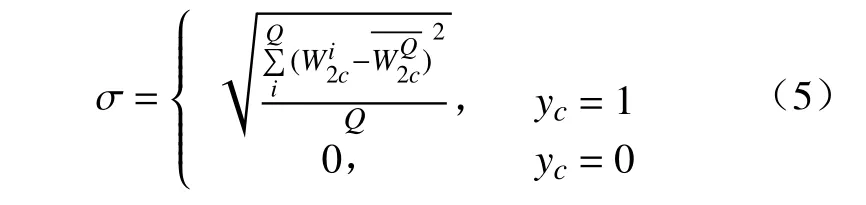

式中:λ表示超参数,用于控制正则项在损失中的比重。这样便能迫使网络在保持分类性能的同时学习到相近的权重。使用平衡后的权重在视觉特征上进行卷积便可得到更为整体的目标区域。与以往方法[4]相同,经阈值 γ筛选后,在所得区域上计算联通图便可得到检测框。
3 实验
本文在CUB200-2011[19]、OpenImages[20]数据集上进行实验。CUB200-2011 共有11 778 张图片,其中5 994 张图片用于训练,5 794 张图片用于测试,共涵盖200 个类别。在OpenImages 方面,有29 819 张图片用于训练,2 500 张图片用于验证,5 000 张图片用于测试,共涵盖100 个类别。与文献[4]中方法相同,量化指标选择TOP-1Loc、TOP-1Clas、MaxBoxAccV2[20](Max)、PxAP[20]。TOP-1Loc 表示预测检测框与真实检测框交并比超过50%且类别预测正确的图片比例。TOP-1Clas 表示图片分类预测的正确率。与TOP-1Loc 不同,Max 不考虑类别预测是否正确,并且在生成检测框时,Max 选择多个阈值筛选,并保留全体测试数据在不同阈值下效果最佳的一项。相较于TOP-1Loc,Max 更侧重体现与类别无关且最适合当前方法阈值的定位性能。PxAP 同样不考虑类别预测结果,但其测试数据不再是检测框,而是像素级的目标区域,其目的是探索不同方法间的细节差异。这4 个指标均是值越大,效果越好。
3.1 实验细节
本文选择Has[8]作为实验基准。为排除不相关因素的干扰,引入自适应标准差正则项(SDR)后,除新增的超参数Q、λ以外,其余结构及参数均保持一致。具体地,网络结构选择经ImageNet 预训练的VGG 分类网络。在训练阶段,网络执行分类任务并迭代50 次。参数设置方面,本文使用SGD Optimizer,并设置初始学习率为0.00016,冲量为0.9,权重衰减为0.0005。此外,网络每迭代15 次学习率降低90%。超参数设置方面,Q取 70,λ取0.5。在测试时,选择类别预测P最大的一项作为分类结果。之后以该项对应卷积核权重在全局池化前一层视觉特征上进行卷积,便可得到激活区域。检测框生成选择与CAM[4]相同的方法。
3.2 实验结果及分析
本文在CUB200-2011[19]、OpenImages[20]数据集上与近几年主流方法CAM[4]、CutMix[21]、Has[8]等进行了对比。网络结构方面,CAM、Has 及本文所提方法(SDR)均使用16 层的VGG 网络(VGG16),而CutMix、ACol 则是选择使用卷积层替换掉VGG 网络尾部的最大池化层(VGG16-L)用以获取更高分辨率的激活区域。这样的替换操作并非总是有效,因此后续的方法,如Has 并未采用该策略。此外,上述方法均使用了ImageNet 预训练权重。训练时,上述所有方法的输入图像大小调整为224×224,并将batchsize 设置为32。网络共迭代50 次,并且每迭代15 次,学习率降低90%。测试时,由于阈值 γ对TOP-1Loc 影响较大,各方法设定了不同值,如表1 所示,“*”表示本文实验所得结果。对于其他指标,各方法采用完全一致的参数设置。

表1 各方法在Top-1Loc 指标下阈值 γ的设定
CUB200-2011 上的实验结果如表2 所示,“*”表示本文实验所得结果,SDR 表示本文所提方法实验结果。在Top-1Loc 指标下,CutMix[21]相对于基准CAM[4]产生了较大提升,这是因为它在一幅图像中随机裁剪图像块对目标图像进行替换,以扰乱网络对目标图像关键区域的关注度,进而生成更为均匀的激活区域。Has[8]则是随机擦除图像中的多个块,在该情况下,网络为提取类别信息将更多地关注目标各个部位,因此其所得激活区域更为平滑,定位准确率也更高。CutMix 与Has 分别通过替换、擦除隐式地降低网络对目标显著性区域的关注度,而本文则是在擦除的基础上通过正则项显式地降低显著性区域关注度,因而获得了更好的定位性能。在Max 指标下,SDR 定位精度产生了较为明显地提升,这是因为对区域的平滑造成了区域最大值的下降,而表征背景像素的值并未产生相应变化,此时使用固定的背景筛选阈值 γ将导致更多像素被视为前景。因此,对于固定 γ的TOP-1Loc指标,Max 提升更为明显。
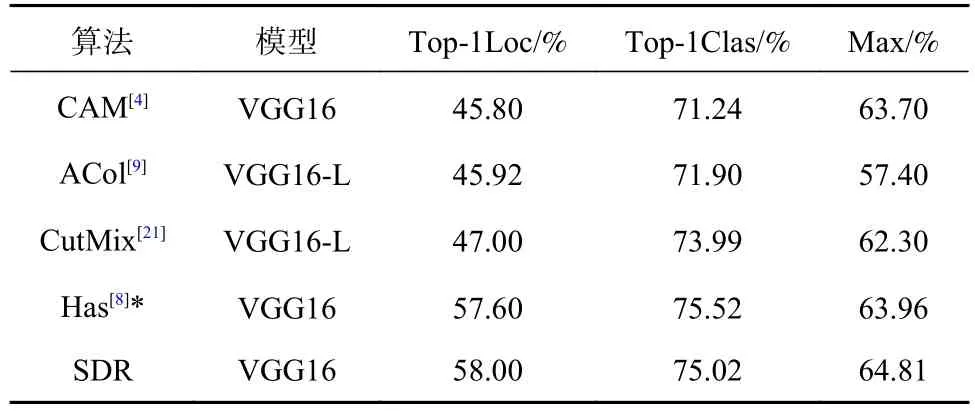
表2 CUB 数据集下的实验结果
考虑到背景像素筛选阈值 γ对Top-1Loc 指标影响较大,图4 示出了各个阈值下的定位精度。可以看出,定位精度随阈值增加呈现出先增大后减小的变化趋势。这是因为,当 γ较小时,过多的背景像素被视为前景,导致定位性能较差,而随着γ 逐渐增加,背景像素得以正确识别,因此定位性能不断上升;当 γ达到最佳值后,若继续增加,将导致本应是前景的区域被视为背景,因而定位精度产生了退化。SDR、Has 的最佳精度为58.81%、58.21%,分别在 γ取0.12、0.13 时得到,表明在平衡通道重要性后应当选取较低的γ。
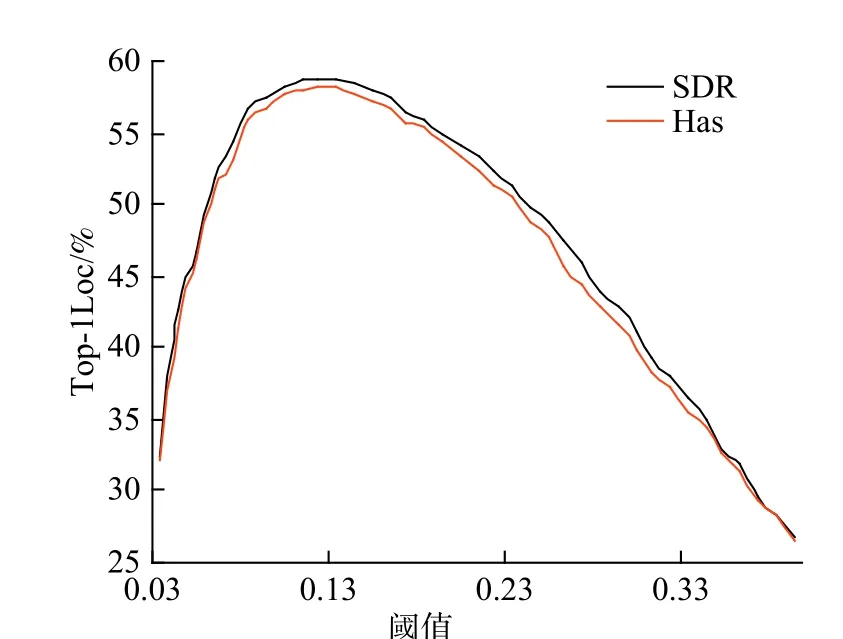
图4 CUB 数据集不同阈值γ 下定位精度
OpenImages 实验结果如表3 所示,其中SDRCAM 表示将本文所提标准差正则项引入CAM。在该指标下,SDR 较Has 提升了0.6%、SDR-CAM较CAM 提升了0.69%,表明本文所提方法在各个阈值下的综合结果更为准确。

表3 OpenImages 数据集下的实验结果
CUB200-2011 数据集下主观结果如图5 所示,每一幅子图中:第1 行表示激活区域,色彩深浅对应激活值大小,色彩越深表明该处存在目标的可能性越大;第2 行表示定位结果,其中绿色边界框表示测试标签,红色检测框表示预测结果,二者重合度越高表示定位效果越好。通过比较图5(a)、5(b)、5(c)能够发现:CAM 无法在鸟的头部激活,其对应检测框覆盖范围最小;Has 由于头部激活值较低,被视为了背景;本文所提方法(SDR)通过平衡通道权重缩小不同区域激活值之间的差异,在鸟头部分得到了较大值,所生成的检测框也更紧凑。
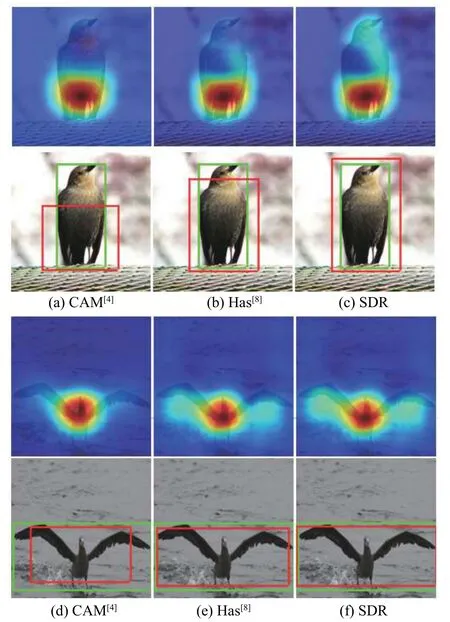
图5 CUB200-2011 数据集下各算法激活区域及定位结果
检测框由激活区域各方位顶点生成,虽能定位目标却无法精确评估激活区域。为了细致地探究各方法间的差异,OpenImages 提供了像素级的目标区域作为测试数据,该数据集下的测试结果如图6 所示。图像由左至右分别表示输入、Has 预测结果、SDR 预测结果、标签。从图中可以看出:Has 对目标中远离显著性类别信息的部位响应效果较差,如第1 行中热气球的左上角及第2 行中左侧的鞋子;本方法由于降低了对显著性区域的关注度,能够更多地从目标其余部位提取类别信息,因而所得响应区域更为准确。

图6 OpenImages 数据集下的定位区域
本方法中超参数Q、λ对预测结果具有显著的影响。表4 给出了固定正则项权重 λ=0.9,调整最大通道数Q时的实验结果。Q越大表示用于平衡的权重越多。当Q过高时,会导致不具有类别信息的通道产生较大的值,而原本具有类别信息的通道所对应权重反而会降低,从而造成性能下降。表5 示出固定Q=50,调整 λ 的实验结果。λ用于平衡分类损失与正则项。由于弱监督目标定位依赖分类网络所得的具有类别信息的视觉特征,需设置较小的λ。本文发现当Q=70且 λ=0.5时,效果最好。

表4 Q 对实验的影响

表5 λ 对实验的影响
4 结论
针对弱监督定位中激活区域趋向于覆盖目标局部的问题,本文提出了一种基于区域权重平滑的目标定位方法,使网络能够关注到视觉特征中不同通道所表征的区域信息,从而得到更为紧凑的目标检测框。
