区域瞄准性扶贫政策的民生效应
2022-05-12李茜
○ 李茜
(河南财经政法大学财政税务学院,河南 郑州 450046)
一、引言
区域瞄准性扶贫政策以县级单位为瞄准对象,是我国解决区域性贫困的重要手段,也是中国早期减贫取得重要突破的主要原因之一[1],在我国扶贫政策体系中占据重要地位。各类贫困县、集中连片贫困地区等就区域瞄准性扶贫政策的典型代表。一旦成为区域扶贫政策的瞄准对象,就拥有了包括信贷、财政、产业等一揽子国家优惠“政策包”,政策目标重点盯住经济增长、农民增收和缩小区域差距[2]。
长期以来,区域瞄准性扶贫政策得到了广泛关注,但对其政策效果和政策效应学术界仍存在一定的分歧[3-6]。从减贫理论上来说,贫困状况有诸多影响因素,如经济增长这一减贫的主要影响因素,其“涓滴效应”可自动实现贫困减缓[7]。相应地,有观点认为我国的减贫成果主要来自我国经济的持续高速增长而非扶贫政策[8]。因此,有必要区分扶贫政策效应与经济增长减贫效应,并识别区域扶贫政策的主要作用机制。与此同时,随着绝对贫困的全面消除,相对贫困成为贫困治理的主要内容,扶贫战略处于巩固脱贫攻坚成果、实现乡村振兴的战略转折期,在新时期,需要更加关注民生发展的多维度需求。而现有关于区域性扶贫政策的研究多集中于扶贫政策对县域经济发展或农业发展等经济绩效方面的研究,鲜有文献涉及区域扶贫政策的民生发展效应。
那么,区域瞄准性扶贫政策的民生政策效应如何?如果区域瞄准性扶贫政策改善了瞄准区域的民生状况,那这一政策效果发生的作用机制是什么?基于此,本文利用设立国家扶贫开发重点县所提供的准自然实验,采用PSM-DID方法,使用河南省2007-2019年县级面板数据,评估区域瞄准性扶贫政策对县域民生发展效应。在当前脱贫攻坚成果巩固拓展,全面接续推进乡村振兴战略的重要历史交汇期,本文的研究具有重要的现实意义。
本文的研究思路如下:第一,为避免不同类别政策效果的混淆,本文以民生发展指数为被解释变量,研究以重点县为瞄准对象的一揽子“政策包”的有效性;第二,为克服内生性,更好地识别两者之间的因果关系,采用倾向匹配得分双重差分方法(PSM-DID),进行实证检验;第三,采用中介效应模型,检验重点县政策作用于县域民生发展的机制和途径;第四,在实证检验的基础上,提出完善我国扶贫政策的对策建议。
二、政策背景与研究假说
贫困县由于受自身资源禀赋等限制,导致地区产业结构单一、财政收入水平较低,造成当地经济发展落后,居民收入水平低。较低的劳动生产率和人均收入水平,造成当地资本形成不足,缺少摆脱贫困必需的资本投入[9-10]。相对落后的经济发展水平,又使得贫困地区财政收入紧张,无法保证必要的公共基础设施建设,导致民生发展水平较为落后,而落后的民生发展水平,使得固有的经济贫困又放大到教育贫困、健康贫困、交通贫困等多个方面[11]。种种致贫因素层层叠加,极易使贫困地区陷入贫困陷阱而无法自拔。
扶贫开发重点县(以下简称重点县)政策主要针对欠发达地区,是一种瞄准县级行政单位的区域式扶贫模式[1],主要采取给予贫困地区政策优惠和财政资金方式,并以扶持、完善基础设施建设、改善生产生活条件为重点[12]。2012年河南省有31个县被设立为国家级扶贫开发重点县,这些重点县享受了包括教育、产业、财政、产业、公共服务等诸多方面的扶贫优惠政策。例如,持续推进“雨露计划”、劳动力转移培训、贫困家庭劳动力技术技能培训等教育扶贫政策;针对贫困县特点,编制贫困县、贫困村脱贫规划和产业发展规划,促进贫困地区综合开发和可持续发展等产业扶贫政策;促进农民增收致富并提升贫困地区基本公共服务和社会保障水平的健康、交通、水利以及网络扶贫和乡村环境整治等;创新县级金融中心和乡级、村级金融服务,金融扶贫小额信贷等金融扶贫政策。产业扶贫有助于贫困县培育特色优势产业,优化贫困县产业结构,促进当地经济发展水平;教育扶贫能够增强贫困人口脱贫技能,提升贫困者的收入水平;对贫困县生产和居民的信贷支持,有助于贫困县的资本积累。此外,重点县还可以得到大量的扶贫专项资金,用以改善当地的财政状况,从而保证贫困县教育、医疗等民生事业的发展以及公共基础设施的建设和运行。
通过对以上扶贫理论和扶贫政策的梳理,区域瞄准的扶贫政策首先瞄准于区域的经济增长,同时有大量政策瞄准盯住区域的民生发展。区域瞄准的扶贫政策,有利于将减贫的收入效应、分配效应及政策效应统一起来,共同促进重点县的经济社会全面发展。
基于以上分析,本文提出如下研究假说:
假说H1:国家扶贫开发工作重点县的设立有利于河南省贫困县的民生改善。
假说H2:国家扶贫开发工作重点县政策主要通过提升县域经济发展水平和农民的收入水平改善当地民生发展状况。
同时,扶贫政策大量涉及民生发展,这些政策在扶贫效果上具有滞后性,因此瞄准于重点县的扶贫政策的民生促进效果应具有持续性。为此,本文提出假说H3。
假说H3:国家扶贫开发重点县政策的民生促进效应具有持续性,持续促进重点县的民生发展。
三、模型设定与变量选择
(一)模型设定
设立国家扶贫开发重点县,可视作对中国欠发达县域的准自然实验,对于政策效果的评估,目前广泛采用双重差分法(DID)评估。使用双重差分法首先要满足处理组和控制组随机性和平行趋势的前提,但国家扶贫开发重点县政策在选择政策对象时,一般针对经济发展水平和公共服务水平较低的县域,因此处理组不具备随机性前提,如果直接对非随机样本进行双重差分估计,将导致结果受到选择性偏差的影响;同时重点县与非重点县在资源禀赋和经济发展中的差异明显,直接进行双重差分分析,可能无法满足平行趋势假设。而将双重差分和倾向匹配得分(PSM)相结合,采用倾向匹配得分—双重差分法(PSM-DID),用PSM 方法解决重点县和非重点县之间可能存在的系统性差异,使之具备可比性,可提高模型的适用性[13-14]。因此,本文采用PSM-DID方法分析国家扶贫开发重点县的设立对当地的影响。
具体地,首先对样本进行PSM 匹配,将河南省2012年由国家扶贫开发办公室设定的扶贫开发重点县(以下简称重点县)视为处理组,将非重点县视为控制组;其次,选取相应的协变量,通过Logit 模型计算处理组的条件概率,并根据所得到的倾向得分,剔除不合理的样本,得到匹配后的处理组和控制组;最后,根据倾向得分匹配得到的处理组和控制组样本进行双重差分估计,度量政策的效果。
为验证前述假说H1,本文构造如下面板回归模型估计重点县政策对当地民生发展的净效应:

其中,lnmsit为被解释变量,表示为扶贫开发重点县i在第t年的民生发展指数;treated为虚拟变量,用以区分处理组与控制组,treated=1即为处理组,treated=0即为控制组;t为时间虚拟变量,用以区分政策实施前后,其中,t=1表示政策实施后,t=0表示政策实施前;交乘项treated·t是模型核心解释变量,其系数β为政策效应系数,反映扶贫开发重点县政策的政策效果,系数β为正,则说明政策促进了当地民生发展,反之亦然;Xit为其他对县域民生有影响且随时间和个体变化的控制变量;μi为个体效应,用于控制其他影响区域创新且不随时间变化的不可观测的个体效应;γt为时间效应,用于控制其他随时间变化的因素;εit为随机误差项。
为验证假说2,即重点县政策效果的持续性,借鉴黄志平做法[16],引入变量tk(k=1,2,3,4,5),表示政策实施后的第k年,将公式(1)变形为公式(2)。

其中,交互项treated·tk为政策实施后的第k年的虚拟变量,在政策实施后的第k年,交互项treated·tk取1,其余年份取0。待估系数βk度量政策实施之后第k年的政策效果,用以评估重点县设立对县域民生发展的动态效应。
(二)变量选择与说明
1.被解释变量。本文的被解释变量为民生发展指数(ms)。为全面反映当地民生发展状况,本文采用熵值法测算了河南105 个县及县级市的民生发展状况。在测算指标的选取上,按照民生发展的主要维度和数据的可获得性,本文选择各县人均地区生产总值(pgdp)作为民生经济维度指标、选择医疗机构床位数和中小学在校生人数作为民生改善维度指标、选择农村居民人均纯收入和城乡居民收入比作为民生发展维度的指标,以熵值法测算结果衡量各县民生发展水平。
2.核心解释变量。公式(1)中的交乘项treated·t为核心解释变量,表示样本是否被设定为国家扶贫开发重点县。其中,treated为政策虚拟变量,如果样本县在2012 年被设定为国家扶贫开发重点县,则赋值为1,否则赋值为0;t为政策时间开始的虚拟变量,2012年及之后赋值为1,否则赋值为0,例如,某县2012 年被认定为国家扶贫开发重点县,且t≥2012 时,交乘项treated·t=1,反之则为0。交乘项treated·t的系数即为双重差分估计量,即国家扶贫开发重点县政策对县域民生发展的净效应。
3.控制变量。借鉴已有文献的一般做法,为控制县域间特征差异,并考虑数据的可得性,本文选择以下指标作为控制变量。选取第二产业增加值占地区生产总值的比重作为工业化水平(gongye)、第三产增加值与第二产增加值的比重作为产业结构高级化水平(indus-adv),第一产业增加值与地区生产总值的比重衡量地区农业发展水平(primary);选取县级政府财政收入与财政支出之和与地区生产总值的比重反映县域政府干预水平(gov);借鉴周迪和王明哲[16]的做法,选取当年金融机构贷款余额与地区生产总值的比重(loan)、居民储蓄存款余额与地区生产总值的比重(saving)两个指标来衡量县域经济状况。
4.中介变量。根据本文研究设计及河南省县域经济社会发展情况,民生水平的提高主要依赖地区总体经济水平的提高以及农民收入水平的提升,因此本文选取县域地区生产总值及当地农村居民人均纯收入的自然对数值作为中介变量,考察扶贫开发重点县政策促进地区民生发展水平的作用机制。
(三)数据来源与样本说明
基于数据的可得性,本文实证分析部分选取2007—-2019年河南省105个县及县级市的相关数据。样本数据来源于EPS 区域经济数据库及相关年份的《中国县域统计年鉴》,个别地区的缺失值采用均值法补齐。样本所涉及各项经济变量值均以2007年为基期的平减值调整为实际值。实证分析部分,为保持数据的平稳性,所有数值指标均取自然对数处理。表1为各变量的描述性统计结果。

表1 变量的描述性统计分析
四、实证分析
(一)倾向得分匹配
本文使用一比二近邻匹配法对扶贫开发重点县与非重点县样本进行倾向得分匹配。并采用政府规模(gov)、产业结构高级化(indus-adv)、农民人均纯收入的对数值(lnfar)、地区生产总值的对数值(lngdp)以及地区人均国民生产总值的对数值(lnpgdp)作为协变量对处理组和控制组进行样本匹配,并在匹配后进行了平衡性检验。匹配平衡性检验结果如表2所示。
由表2可知,匹配前协变量在处理组与控制组之间均存在显著差异。经过匹配,所有匹配变量标准偏差的绝对值均小于20,且变量间不再存在显著差异。表明匹配后各协变量和倾向得分在处理组和控制组样本间不存在系统性差异,分布的均衡性较好,从而支持了本文倾向匹配得分法的应用。

表2 倾向得分匹配平衡性检验结果
最终,匹配后的重点县和非重点县存在1 056个处于共同支撑区域的样本,损耗样本309个。
(二)双重差分分析
1.扶贫开发重点县政策的平均处理效应。通过前述倾向匹配得分法所得到的相似处理组与控制组的样本后,本部分采用模型(1)估计重点县设立对当地民生发展水平的净效应。双重差分回归结果如表3所示。
为保证双重差分回归结果的稳健性,本部分采用逐步回归法进行双重差分估计,同时所有模型均控制了时间效应和个体效应。第(1)列为未加入控制变量的估计结果。第(2)至(4)列为逐步加入控制变量之后的估计结果。由表3可知,无论是否加入控制变量,交乘项treated*t的系数均在1%的水平上显著为正,这表明国家扶贫开发县的设立显著推进了贫困县的民生发展。具体地,在未控制其他影响地区民生发展状况的变量时,处理组的民生发展水平高于控制组6.1个百分点。而控制其他变量后,处理组民生发展水平依然高于控制组4.4个百分点。
从控制变量上看,大部分控制变量的系数和显著性符合预期。值得注意的是,产业结构高级化(indus-adv)对民生发展的影响并不显著,这表明重点县的产业结构仍存在优化空间;而金融机构贷款余额对民生发展的影响则显著为正,据现有文献的结论,出现这一情况的原因可能是,当前县域经济发展主要依赖于固定资产的投资,而大部分地区固定资产投资的主要来自金融机构的贷款。此外,居民储蓄存款额对当地民生发展具有显著的抑制作用,这表明当地居民的存款未能有效转化为投资[4]。
综上所述,国家扶贫开发重点县的设立对民生发展指数具有显著作用,有利于民生状况的改善,从而验证了假说H1。
2.扶贫开发重点县政策的动态边际效应。扶贫开发政策是否具有持续性是扶贫政策有效性的关键[17-18]。表3的结果仅仅表明扶贫开发重点县政策对于当地民生发展的平均效应,但并没有反映该政策对当地民生状况是否具有持续改善作用。因此,为验证假说H2,本文利用公式(2)评估重点县的设立对当地民生发展的动态效应(见表4)。

表3 扶贫开发重点县政策的平均效应(基准回归)
表4中,第(1)列和第(2)列分别是加入和未加入控制变量的估计结果,由表4 可知,无论是加入还是未加入控制变量,交乘项treated*tk的系数均为正,且大部分结果显著,表明国家扶贫开发重点县的设立对当地民生发展具有持续的促进作用。与此同时,与扶贫开发重点县政策实施之初相比,交乘项的系数和显著性有较大幅度提高,这表明,随着时间的推移,政策效果变大。根据现有文献的解释,出现这一情况可能的原因是,国家赋予扶贫开发重点县的各种政策优惠,帮助贫困县累积了大量有利于民生发展的因素,出现了经济发展优势循环累积的效应[4,16],并在一定程度上摆脱了“贫困陷阱”,假说H3得到验证。
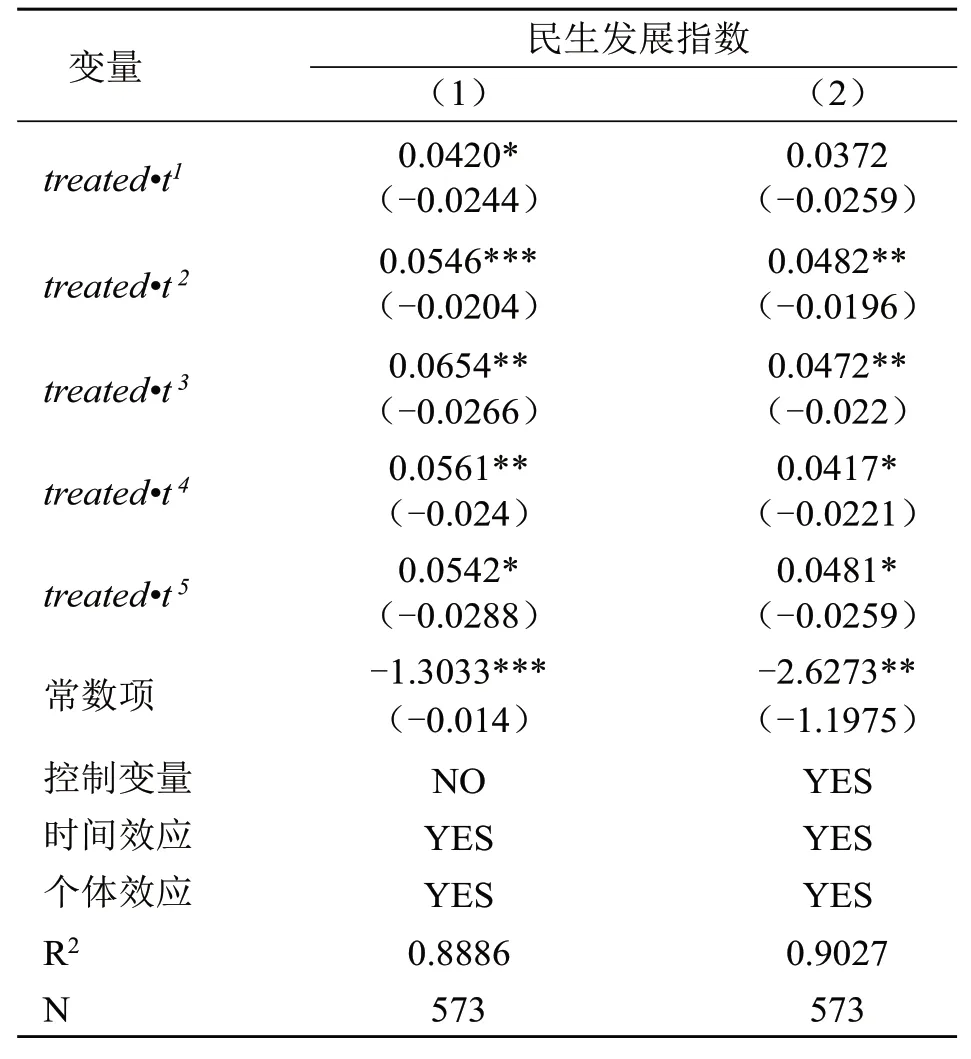
表4 扶贫开发重点县政策的动态效应
3.稳健性检验。除设立国家扶贫开发重点县这一政策之外,其他的政策或随机事件都有可能影响当地的民生发展。为排除其他因素的干扰,保证回归结果的稳健性,本部分采用更改被解释变量、删除样本内省直管县样本以及更改匹配方法进行稳健性检验,以保证估计结果的稳定性。
第一,本文的被解释变量民生发展采用熵值法确定,综合反映了各个县(市)的民生发展状况,但对于贫困县来说,经济发展就是最大的民生问题,基于重点县的区域特点和数据的可得性,本文选择当地人均国民生产总值的自然对数值(lnpgdp)作为被解释变量,重新估计重点县的政策效果,以验证基准回归结果的稳健性;第二,省直管县政策减少了行政层级,县级政府具有更大的经济管理权限,有利于县域的经济发展,为排除省直管县政策的可能干扰,本部分排除河南省十个省直管县样本,重新估计重点县政策的效应;第三,考虑到不同的匹配方法会得到不同的匹配结果,从而对估计结果造成影响。因此,本部分选择半径匹配法对数据进行重新匹配,并使用重新匹配后的样本,重新进行双重差分回归。回归结果如表5所示。
由表5的稳健性检验结果可知,无论是更改被解释变量、剔除省直管县样本还是更换匹配方法,最终交乘项treated*t的系数均显著,且方向与基准回归结果一致,这表明了基准回归结果的稳健性。

表5 稳健性检验结果
(三)机制分析
前述双重差分基准回归分析部分已经验证重点县设立对县域地民生发展的促进作用,并且通过稳健性检验验证了估计结果的可靠性。但前述实证分析部分并未清楚交代设立重点县如何推动当地民生状况改善,重点县的设立与民生改善之间的传导机制是什么?为解释该问题,本部分进一步考察两者之间的作用机理。
通过对文献的梳理和经济理论的分析,本文认为重点县政策主要通过提升当地的经济发展水平和提高农民收入水平[19],实现相应的经济社会发展目标。因此,本文选择各地地区生产总值的自然对数值(lngdp)和当地农民人均纯收入的自然对数值(lnfar)作为中介变量来验证国家扶贫开发重点县政策的民生发展促进机制。为此本文设计如下中介效应模型进行机制分析:第一步,以各县地区生产总值的自然对数值为被解释变量,重点县政策为解释变量,检验重点县政策对地区生产总值的影响,验证其中介效应;第二步,以各地民生发展指数为被解释变量,以政策变量和各地区生产总值的自然对数值为解释变量,验证其直接效应。中介效应模型方程如下:


公式(3)表示中介效应,公式(4)表示直接效应。其他变量定义同公式(1)。如果重点县政策通过促进当地经济发展水平改善了民生发展状况,则待估系数β2、β3均应当显著,且其乘积符号也应与β1一致为正。反之,则表明当地经济发展水平并没有影响贫困县政策对地方民生发展水平的替代效应。机制检验的结果如表6所示。表6的第(1)列和第(2)列为农村居民人均纯收入的中介效应结果,验证了重点县政策是否提高了当地农民居民的收入水平;第(3)列和第(4)列汇报了地区生产总值的中介效应结果,验证重点县政策是否提升了当地的经济发展水平。中介效应模型与基准回归分析思路一致,同时控制了时间效应和个体效应。
表6的回归结果表明,国家扶贫开发重点县政策通过提高地区经济发展水平和当地农民的人均纯收入改善了当地民生发展状况。这一结果与扶贫开发政策的具体政策手段和政策目标相一致。同时也验证了前文的假说H2。

表6 机制分析
五、结论与启示
本文采用2007—2019 年河南省105 个县(市)的面板数据,利用倾向匹配得分—双重差分法研究了2012年国家扶贫开发工作重点县的设立对河南县域民生发展状况的影响。结果显示:第一,国家扶贫开发工作重点县的设立对县域民生发展具有显著且持续的推动作用,且这一结果经过稳健性检验之后仍然成立;第二,国家扶贫开发重点县的设立主要通过提升县域内经济发展水平和农民的收入水平改善当地民生状况。
综上所述,国家扶贫开发重点县的设立能够改善当地民生状况,因此,得出如下政策启示:第一,有必要持续推进和推广区域瞄准性扶贫政策。在当前我国绝对贫困全面消除,相对贫困成为主要矛盾的背景下,汲取相关成功经验,继续精准盯住贫困问题,为防止返贫,巩固扶贫攻坚工作的成果,实现乡村振兴提供新的经验和智慧;第二,有必要进一步促进贫困县产业结构优化升级、培育经济内生动力。现阶段正处于巩固扶贫攻坚成果与乡村振兴战略有效衔接的关键节点,产业结构的优化升级与经济发展内生动力有助于贫困县摆脱贫困陷阱,尤其是在贫困县政策退出之后,仍能保持脱贫县的经济社会持续进步。
