算法伦理研究:视角、框架和原则
2022-05-12陈昌凤吕宇翔
陈昌凤, 吕宇翔
(清华大学 新闻与传播学院, 北京 100084)
智能算法正在重新界定我们的生活理念,改变我们的决策方式。正在兴起的计算主义、数据主义技术思潮更是把算法当作支配世界的核心,将算法看成是这个世界最重要的概念,坚信21世纪是由算法主导的世纪。[1]随着算法的遍在化运用,算法中的伦理问题开始凸显。从根本上说,算法化、数据化成为一种普遍的认知范式,它们在重构和规训整个社会之时,还带来了人类以及个体主体性的根本丧失,人类有成为算法奴隶之虞。[2](PP.11~12)那么,算法伦理带来了怎样的框架性学术思考?算法运用中有哪些伦理问题,其核心又是什么?算法伦理如何汇入传播活动,从而挑战算法时代的媒介伦理呢?
一、算法的多元视角
通常意义上的“算法”(algorithm),指的是进行计算、解决问题、做出决定的一套有条理的步骤,是计算时采用的方法。[3](P.75)可见,“算法”较计算有着更广泛的含义,它是在解决计算或者其他问题时(尤其是借助计算机)所遵循的步骤或规则。[4](PP.149~150)当下使用的“算法”一词来自计算机科学,指解决问题的一套逻辑,即可以对特定的输入进行处理,获得符合预期的输出,是自动化执行人类意志的计算工具。[5]
算法出现以后,人类的决策模式便开始发生变革,过去由人类主导的决策,如今常常交由算法来完成。算法的运用情境包括个人、组织以及社会等不同层面。在个人层面,算法的影响至少包括个体对自身及所处环境的看法、理解与互动;在组织层面,算法影响着各个环节,如果是商业组织,它的影响则渗透到从商业决策到生产、制作、销售等各个环节;在社会层面,算法已经深层影响了社会治理的各个领域。赫拉利等人认为,世界包括人的生命都是算法运算的结果,不仅自然界是用算法语言写就的,宇宙也是一个巨大的计算系统,而且数据化成为一种普遍认知范式。生物也是算法,我们的感觉和情感各是一套算法。最终人类将赋予算法以权力,做出人生中最重要的决定。从物理世界、生命过程直到人类心智都是算法可计算的, 甚至整个宇宙也是完全由算法支配的。[6]但“算法”又是一个相当复杂的概念,对其理解常常迥然不同,因此带来了算法研究的多元视角。通过分析近年国内外学界有关算法研究的文献发现,传播领域对算法的解读至少形成了六类不同的视角和界定。[4](PP.149~150)
对于算法的不同界定源于不同的理念。其一,“算法是工具”,侧重于关注算法的形式、性能和交互如何被精心设计,使其更完美地执行人类的预期目标。在新闻传播领域,体现为算法辅助新闻生产、对新闻传播业的功能性渗透,即关注算法如何辅助人类进行数据挖掘与分析、自动化写作、个性化推荐分发、自动核查、智能化管理等。算法被人类视为自己掌控、操纵的自动化工具,是一种“工具理性”的思维,即推进传播效益最大化的生产实践。[7]其二,“算法是规则”,即参与塑造了算法实践的内在逻辑—智能催生的支配性新机制。在新闻传播领域,无论是新闻的生产还是分发,无论是反馈互动还是组织管理,整个行业都需要遵从新规则,生产或分发都要为适应算法规则作出调整,用户、生产者和平台都要回应算法规则,从而获得更大的效益。算法作为社会规则在技术领域的延伸,开始重塑信息规则甚至是社会规则,重塑用户、媒介和社会的交互关系。其三,“算法是权力”,算法的介入推动了权力的迁移,在重塑的新型关系中获取权力。在新闻传播领域,算法主导着信息传播秩序,通过商品化的方式凸显科技巨头的影响力,带来公共权力的让渡、个体用户的权力抗争,认知层面的“信息茧房”也受到关注。[8]算法权力成为新型标尺,重塑个体、媒介、平台、国家之间的力量格局。其四,“算法是主体”,人工智能与人类智慧相混糅,使得人与算法之间的复杂关系难解难分,算法作为动态行动者网络中的非人类行动者,可以成为改变事物状态的非人要素。[9]在新闻传播领域,算法正在消解建立在“人类中心主义”之上的传统传播观,机器正在以传播者的姿态进入该领域,“人机传播”理论得以诞生。这样,人与技术之间的本体论鸿沟正在被逾越,人机之间产生的具有社会意义的关系成为算法被视为主体的重要依据。其五,“算法是想象”,人类重视算法是什么、算法应该是什么以及算法如何运行,“算法意识”与客观事实形成了某种张力关系。在新闻传播领域,专业性的客观真实的内涵和外延再次被算法拓展。算法实践中以人为主的视角受到重视,普通人(不一定是技术精英)也会关注算法的社会意义,算法素养受到重视。其六,“算法是价值观”,算法作为人类思维的表达,本身即包含内在的价值观,包括来自历史数据集的观点汇总、工程师编程中的观点嵌入、平台设计中的逻辑彰显、技术逻辑的无意识体现等。[10]在新闻传播领域,它可能体现为价值的偏向[11]、算法逻辑的无意识偏差带来专业性的失守和伦理的困境[12]。算法实践的价值导向可能成为被争夺、被利用的对象,其公正性、透明度、责任观、可解释性受到质疑。[13]
算法界定视角的不同也会带来算法伦理观的差异。当然,无论持怎样的观点,对于算法,我们都需要有明确的哲学观。
二、算法伦理的哲学思想
在算法伦理中,保持人的独特性是首要问题,即坚持以人为本的伦理观。[14]由于因素复杂,要确定算法潜在和实际的伦理影响是很困难的,算法伦理的问题和潜在价值观只有在具体案例中才会显现出来。笔者将从其中一个视角,对算法伦理加以梳理和探讨。
数字革命让人类在宇宙中的角色发生了革命性的转变,哲学面临信息转向(informational turn)。当代信息哲学家、信息伦理学家弗洛里迪(Luciano Floridi)从语言理性主义的角度对当今的数字技术进行了多层次的描述。他将信息革命界定为对人类在宇宙中位置的根本性重估。过去,我们把自己置于信息圈(infosphere)的中心,以为没有任何其他地球生物可匹敌[15],如今这种自以为是的独特性已经不再可信,人类只是被网络化,成为一个信息环境(信息圈)的信息实体(信息体),人类的自然和人工代理彼此共享。互联网技术促进身体与信息的融合,并深度参与到人的心灵与自我的塑造中。因此,弗洛里迪将信息通信技术视作“自我创制技术”,认为“它们会显著地影响我们是谁,我们认为我们是谁,以及我们可能成为谁”。[16](P.309)弗洛里迪对智能时代现实的理解从物质转向了信息。在当今数字世界的信息体—信息圈中,人类的自我被赋予一种信息化的解释。[17]不过,弗洛里迪将技术决定论作为信息圈中的信息体的理论基础,将信息体定义为与信息能量装置相连的数据处理实体,反映了语言理性主义范式的心身二元论观点。弗洛里迪在《信息伦理学》(EthicsofInformation)一书中提出了四条道德法则,其中第四条是应该通过扩大(信息量)、提高(信息质量)、丰富(信息种类)信息圈的方式提升信息福祉,促进信息实体以及整个信息领域的繁荣。
2019年11月18日,“智能时代的信息价值观研究高层论坛”在清华大学举行,当代著名媒介伦理学家克里斯琴斯(Clifford G.Christians)教授发表了题为《哲学视野中的人工智能:语言的视角》的主旨演讲,从哲学层面对人工智能进行了高屋建瓴的思考。克里斯琴斯认为,算法遵循准确的形式化语言,可用于执行计算、数据处理等,但不能用于促进人们对美好生活或生活目标的感受。为了增强技术性,道德承诺和伦理目标都被牺牲了。基于计算机的传播本质,存在两个截然对立的传统,即“语言理性主义”和“人文主义逻辑”的语言哲学。
从笛卡尔(Rene Descartes)到维纳(Norbert Wiener)、弗洛里迪,再到基于计算机的智能,语言理性主义主导了数学模型,在认知上存在着重大缺陷——认为信息技术是中立的。这种传统预设了事实与价值分离的二元对立论(fact-value dichotomy),将技术视作与价值相分离的无意识的工具,即技术决定论(technological determinism),假定了心身二元论(mind-body dualism)。其间,香农(Claude Shannon)和韦弗(Warren Weaver)也认为,通信所传输的数据是中性的想法不证自明。
克里斯琴斯教授提出应以符号语言哲学作为更合理的传统,避免维纳语言理性主义中的控制难题和事实价值二元论。他反对将人工语言和自然语言混为一谈,认为人文主义的语言哲学呼唤智能时代的传播伦理。克里斯琴斯推崇卡西尔(Ernst Cassirer)的“人文主义的逻辑”(The Logic of the Humanities)[18],认为语言系统并不仅仅是中性数据的组合,而是被规范所引领的,人类的语言概念反映了人类生活的价值观,这些内在价值才是人类的立身之本。将人类紧密联系在一起的统一性是对认同和尊重的共同追求。作为道德主体的人类是准则性的,而不是基于笛卡尔传统的理性选择的个人主义。人文主义语言哲学视技术为一个文化过程,算法等互联网时代的媒体技术应被当作具体制度、历史和文化背景下的符号系统来进行分析。因此,算法伦理研究应从人类的生活世界和人的生活着手,而不是以机器为主并且用它的术语来定义人性。[14]
克里斯琴斯教授深入思考了智能算法时代媒介伦理的责任、权利、正当性、事实与价值等重要议题,并提出了以下问题。(1)具有学习能力的机器并不具备与人类相同的道德行动能力,但从某些合法性或正当性来考虑,它们是否应该承担责任?(2)在道德关怀的情境中,机器在什么程度上能够被视作另一个他者,并因此获得应该被尊重的正当权利?(3)强人工智能(Artificial General Intelligence)对公平正义、共同利益和文化资本的重新定义是否正当?(4)在将人类作为节点接入基于计算机的学习机器的神经网络连接中,我们传输的只是数据还是包括意识本身?这些问题需要我们在理论和实践中认真对待。在克里斯琴斯教授的论述中隐含着一个最重要的算法伦理思想,即算法人文主义。
算法人文主义从底线意义的“以人为本”出发,主张将人的行动限定在信仰、法律和道德伦理的价值体系之内,以保护人之为人的最为宝贵的尊严和自由。人与世界(包括与各种技术存在物的关系)并不是简单的主客体关系、目的和手段的关系,而是物我两忘、融为一体的共同存在。一方面,算法作为人的存在的重要维度,是对人之主体性的重要呈现;另一方面,由于人的存在是丰富的、多样的,算法应该在与人的共存之中,维护人之为人的尊严和主体性。从最底线的“以人为本”出发,算法人文主义提出了维护人的尊严、保护个体自由、维系社会公平正义、增进人类整体福祉和促进可持续发展等基本价值理念。在算法的研发设计与应用过程中,要求要有人的视角和人的在场;算法的研发和应用要划定“有所不为”的禁区,并将更多的精力和资源投入到与保护人的消极自由而不是扩展人的积极自由相关的领域;为了促进社会公平正义、防止算法权力对个体消极自由和社会公平的侵犯,要对算法的有效性、必要性和正当性进行衡量和评估;为了实现算法人文主义的整体主义的技术观和世界观,我们还必须将人类视作一个整体,从促进人类整体的自由和福祉出发,规制算法的研发和应用,不仅要防止算法沦为少数人统治多数人的暴政,更要防止因人工智能的研究和使用而导致的毁灭。[2](PP.63~83)
三、算法伦理的研究框架与核心原则
算法伦理是一个跨学科的概念,涉及哲学伦理学、信息科学等多个领域。下面结合世界范围内具有代表性的研究成果,从概念、框架及核心问题的角度加以阐释。
(一)算法伦理的概念架构
算法伦理的问题杂冗、学术话语广泛而且分散,难以形成系统。2016年,牛津大学互联网研究院(Oxford Internet Institute, University of Oxford)和图灵研究院(Alan Turing Institute, British Library)的五位学者,包括Brent Mittelstadt和弗洛里迪等人,基于算法运行的组织结构,尝试构建了算法伦理的问题架构图,旨在组织学术话语,为算法伦理的研究提供极具启发性的思路。
算法伦理在这项研究里被分成两大范畴的六个关注点,如图1所示。一是认知性范畴,包括不确定的证据、不可解读的证据、误导性证据三个方面的现象。算法使用推理统计学和(或)机器学习技术处理的数据得出的结论不可避免地具有不确定性,很少绝对可靠,不确定这一点对理解算法伦理非常重要;数据与结论之间的联系不明显时,包括众多数据点中的每一个如何被用来得出结论的内在复杂性,就存在无法解读的局限;算法在处理数据时的输出永远不会超过输入,结论只能与其所依据的数据一样受限,可能带来误导性。二是规范性范畴,包括不公平的结果、变革的影响两个方面。算法的操作标准和原则与行动和效果的“公平性”并不能保证一致,操作可能存在歧视,带来不公平;算法也可能以新的、意想不到的方式理解和概念化世界,带来变革。除了以上两个范畴,还有一个可追溯性的问题。算法不仅与新技术的设计和可用性有关,而且与大量个人和其他数据的操纵相关联,这意味着算法活动造成的伤害难以检测,很难确定谁应该对造成的伤害负责。[19]
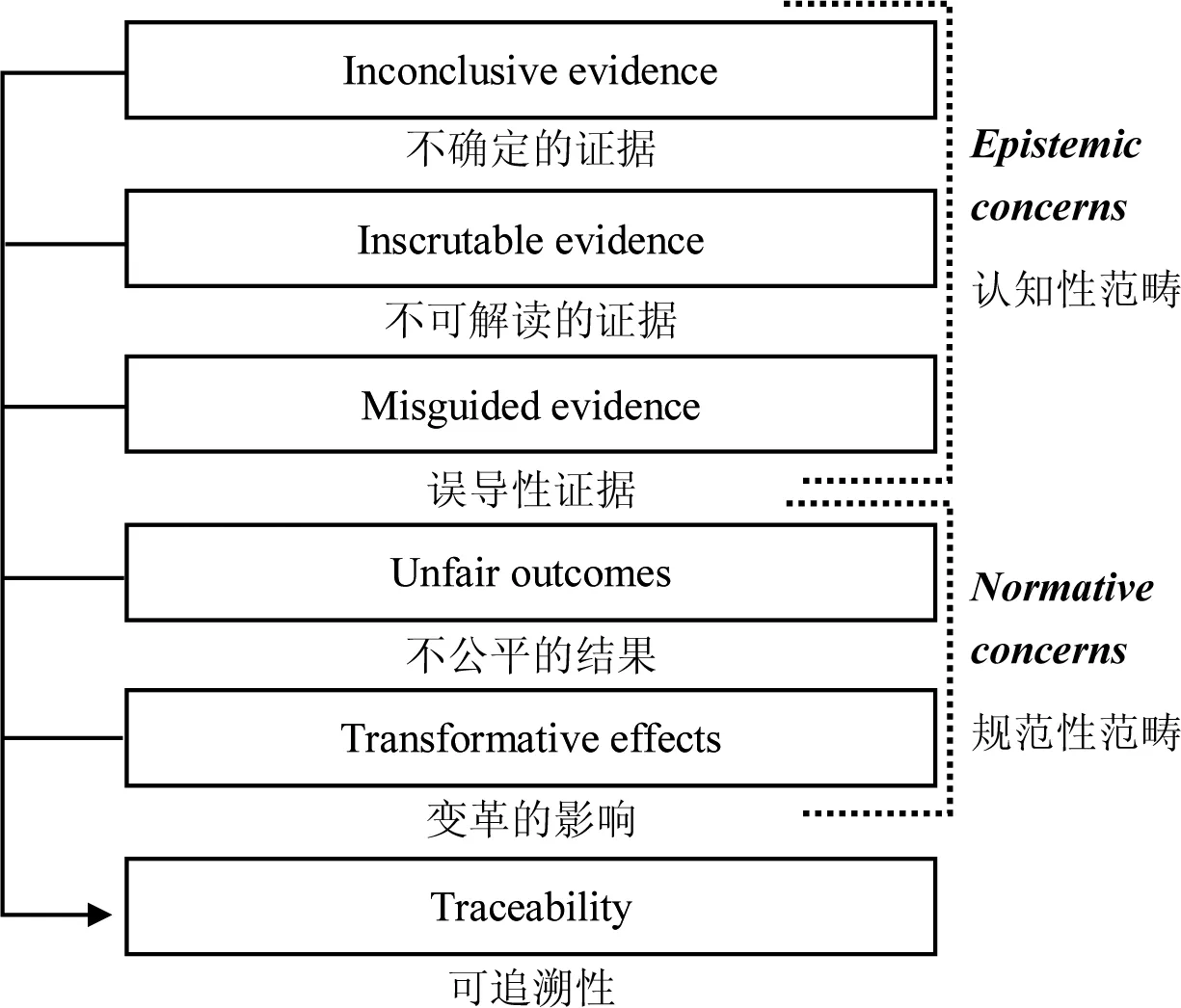
图1 算法伦理的六个关注点
上述六个关注点又进一步带来六类伦理问题,即不确定证据导致不正确的行动、无法解读的证据导致不透明度、误导性的证据导致偏见、不公平的结果导致歧视、变革的影响导致对自主权和信息隐私的挑战以及可追溯性导致道德责任。
算法对人类的信息获取、知识建构、思想形成都有着或显性、或潜在的重要影响,作为新兴的技术,人们对它的认知甚少,因此要确定其伦理框架确实是相当困难的。以上这些机构的知名学者们试图从哲学层面建构一个算法的伦理框架,考虑到算法的特性带来的不确定性、不可解读性和误导性,这些与算法知识相关的几个方面,即所谓的“认知性”(epistemic concerns)关注的内容的确有利于我们重视算法的内涵、特质,从而发现其中的伦理问题,比如“不确定证据”导致不正确的算法决策,等等。但是,算法的知识谱系是怎样的呢?哪些算法原理会产生认知性误区呢?如果对算法知识没有全面的、深层的理解和透析,想要概括、穷尽算法的“认知性”困境是很困难的。因此,相关表述也是零散的、含糊其词的,而且,这些认知层面的问题带来的后果又是简单划定的因果关系。“规范性”(normative concerns)是一个与判断、评价相关的方面,关涉价值判断,这一框架中仅列出“不公平的结果”和“变革的影响”,但可以涵盖诸如算法偏向、对人的自身及安全的影响等,这也是与算法相关的最重要的两个方面的价值问题。
(二)算法伦理的核心原则
人工智能算法运用的伦理问题在不同国家和地区基于不同主题有不同的面向。欧盟委员会的人工智能高级别专家组(AIHLEG)较早地确定了算法伦理原则。该专家组呼吁采用“以人为本的人工智能方法”,并将其界定为“可信赖的人工智能”。第一,人工智能应遵守现行法律法规;第二,人工智能应该以伦理为导向,即尊重基本权利并遵守核心原则和价值观;第三,算法必须具有技术上的稳健性和算法的可靠性。
关于人工智能的伦理原则,欧盟委员会的人工智能高级别专家组认为建立可信赖的人工智能应遵循四个伦理原则。(1)尊重人类自治的原则,即确保维护人类的自决权,这意味着人工智能技术增强了人类在工作中的能力,并且保持对这些技术操作的控制。(2)预防损害的原则,其中包括确保人工智能可靠且技术上稳健,以避免复制出现实世界中可能存在的偏见和不平等,避免对生命体与环境的潜在伤害。(3)公平原则,要求在人工智能的开发、部署和使用中享有平等机会,明确识别负责人工智能行为的实体,并且清楚地理解算法决策过程。(4)可解释性原则,强调必须公开披露有关算法目的和行为的信息,以便建立和维护信任。为满足人工智能系统的生命周期,这些原则可以遵循七项要求,即人为代理和监督,技术稳健性和安全性,隐私和数据治理,透明性,多样性、非歧视性和公平性,社会和环境福祉以及问责制。[20]
四、算法伦理的核心问题及求解
算法涉及人类伦理、科技伦理的多个面向。从科技的视角看,目前权威学者如科恩斯(Michael Kearns)关心的算法伦理问题包括隐私、公平、不可解释性等。[21]宾夕法尼亚大学计算机与信息科学系教授科恩斯是美国计算机领域的权威学者之一,2021年入选美国国家科学院院士、2012年入选美国艺术与科学研究院院士,在计算机学习伦理、算法博弈论等领域处于领先地位。2019年,他与同事罗斯(Aaron Roth)合作出版了《守伦理的算法:社会意识算法设计的科学》(TheEthicalAlgorithm:TheScienceofSociallyAwareAlgorithmDesign)。他们从技术角度探究的算法伦理问题,正是当前算法技术的核心伦理问题,以下分别加以介绍。
(一)隐私问题
从某种意义上说,隐私是一个人周围“不可接近的区域”,它显示的是个人的尊严,是一种社会安排,允许个人控制谁可以在物质和个人信息层面与其接近。[22](PP.204~205)在互联网时代的信息隐私保护上,匿名是数据平台最常用的手段,但是这种隐私保护的办法带来了一个算法困境。算法离不开个人数据,我们所有在网络上暴露过的个人信息,包括各类喜好厌恶、行动踪迹,都会被那些算法平台所收集和使用。这些信息虽然通常运用“匿名的”数据集,但实际上仍然能够识别出数据主的真实身份。
一个著名的例子就是流媒体平台奈飞奖(Netflix Prize)竞赛引发的数据暴露事件。2006年,在奈飞还只是一家DVD出租公司(尚未成为流媒体平台)时,它推出了一项具有高额奖金的竞赛,通过公共数据科学竞赛,寻找最佳的“协同过滤”算法(collaborative filtering algorithm),使奈飞原有的推荐系统的准确性提高10%。通过用户此前对影片的评分及评分日期为用户定制其可能喜欢的影片——“协同过滤”算法的目标是预测用户对其尚未看到的电影的评价,然后向用户推荐算法预测用户评级最高的影片。为了获得最佳的算法推荐系统,奈飞还公开发布了许多数据,一个超过1亿部电影评分记录的数据集相当于 50万用户对1.8万部电影的评分。在公布这些数据时,奈飞非常重视隐私问题,删除了所有数据中的用户身份信息,代之以无意义的数字标号,使其符合美国《视频隐私保护法案》(TheVideoPrivacyProtectionAct, 1988)对电影租赁业的严厉规定。然而,在数据公布的两周后,得克萨斯大学(奥斯汀分校)的一位博士生和他的导师就结合网络信息和公布的数据,还原了数据集中删除的标识化信息,并附上了匿名数据主的真实姓名。[21](PP.22~26)
所以说,算法时代的隐私保护是一个棘手的难题。现实中的隐私保护涉及个人、平台、社会等多个方面,仅从平台而言,对于这类去除了标识化的信息导致的算法的隐私困境,可以从技术角度做出努力。比如,科恩斯等人提出了使用“差分隐私”(differential privacy)的算法,避免匿名(去标识化的)用户信息的暴露。[21](PP.36~56)此外,他们还探讨了如何将人类的公正、责任、道德原则等嵌入到机器代码中,以技术的方式解决算法伦理的困境,带来人们对“道德机器”的期待。
(二)公平问题
算法的不公平、价值偏向(偏见)、歧视等一直饱受诟病。这些问题与技术、工程师的价值观、平台的利益驱动等相关。学习算法是将决策问题的历史实例(即训练数据)作为输入并生成决策规则或分类器,然后将其用于问题的后续实例的方法。运用现实数据集、经过人类行为训练的算法都将历史和文化习俗嵌入和编码于算法之中。
了解算法的工作原理有益于我们理解公平问题。算法的实施需要经过三重中介:一是设计算法方案的专家;二是作为计算目标的数据主体;三是算法本身。比如,通过对数字化的叙利亚难民安置算法的研究发现,经过算法自动决策之后的新数字景观虽然能够得出更好的经济和就业方案,但是难民认为社会文化特征在该空间中被低估,专家对该过程的透明性和归责问题也表示担忧。[23]算法可以对社会生活规则和规范进行重构、对社会秩序产生冲击并加以构建,对意识形态空间产生形塑作用。[24]
而且,算法是难以中立的。从技术层面而言,机器学习分类器会带来不公平,而算法的偏向和不公平常常是无意间造成的。首先,数据是人类现实社会的反映,人类现存的偏见以及由不公的现实数据训练出来的算法,本身就可能存在偏向和不公;其次,数据的样本量差异也会带来不准确性,分类器通常会随着用于训练它的数据点数量的增加而改善。也就是说,数据越多、越全面,建立的分类器可能就越准确,而数据量小通常会导致预测、决策的不准确,比如少数族裔、弱势群体的可用数据量相对比较少,因此可能带来较为严重的不公和偏见。除此之外,还有其他问题,如技术水平、文化差异等等。
在民族、性别等方面,算法还产生了一系列认知规范的不公正案例。比如卡内基梅隆大学研究人员的一项研究发现,谷歌的在线广告系统向男性展示高收入工作广告的频率要比向女性高得多[25];哈佛大学对在线广告投放的研究发现,有关逮捕记录的广告更有可能出现在具有明显黑人姓名或历史悠久的黑人兄弟情谊的广告中[26]。近年这些不公正性还扩展到了劳动关系之中,形成了对劳动工人的歧视。比如在我国,算法歧视性决策使得外卖骑手困在算法系统里,带来零工经济平台的人文主义缺失。[27]
(三)透明性问题
第二代人工智能属于数据驱动型,较之于第一代人工智能的知识驱动型而言,机器主要通过模拟人类的感知来进行计算。第二代智能技术先天地具有不可解释性、不透明性。算法专家们已经接受算法是黑箱这一事实,但他们并不认为低透明度意味着低可信度。对于非专家群体而言,增加算法透明性很难具有可操作性,尤其考虑到模型是复杂的、时刻处在动态发展中的。[28]
透明性主要包括信息的可访问性和可解释性。在新闻传播领域,透明性已然成为算法时代新闻业的核心原则。新闻媒体中的“算法透明性”可以被理解成“阐明那些与算法有关的信息可以被公开的机制”,包括“披露算法如何驱动各种计算系统从而允许用户确定操作中的价值、偏差或意识形态,以便理解新闻产品中的隐含观点”[29],也可以解释成阐明那些与算法有关的信息可以被公开的机制,包括信息透明、理念透明和程序透明。不少学者认为,实现“算法透明性”是解决新技术带来的伦理问题,尤其是算法偏见和歧视以及侵犯信息隐私等问题的重要途径。
“开放伦理”观即将用户纳入信息过程,可以作为实施算法透明度相关实践和话语的指导理念,在伦理原则的制定、伦理判断、伦理抉择以及信息公开等所有实施算法透明度的环节,都要考虑用户的认知、态度与需求,这对促进“异质新闻/内容实践网络”中各主体的对话,改善各主体在伦理话语权方面的不平等具有重要意义。[30]
开放的伦理观对将算法运用于媒介的伦理研究具有创新意义。有研究者发现,经过用户画像算法这一中介,传统意义上的身份定义方式被改变,转而成为算法与人类社会知识有机互动的过程,他们认为,对用户进行画像的聚类算法包括构建不具意义的类别、为类别重新赋予社会意义两个过程,前者不依赖于人类社会的意义,生成大量超越现有解释的未定义类别,后者将语言的、社会的知识重新引入类别的界定之中。[31]
结语
算法让我们的生活和工作更有效率、更有趣味,让我们获得更加丰富的信息。它已经在影响人们日常生活的大部分内容,如与他人的互动、人们的吃穿用等消费行为,以及人们所获取的信息、投资决策、职业选择,等等,人类甚至更相信算法。哈佛商学院的调研结果显示,人们更愿意采用被告知是算法的建议而不是人类的建议。总而言之,算法成了我们生活中不可或缺的技术,变成了日常生活中的强大中介。而且,算法也在重塑信息传播。人们将智能算法运用于信息传播的全过程,从数据挖掘、新闻生产到新闻发布与分发、信息核实与用户互动,它可以使新闻发掘更深入、触觉更敏锐、面向更广泛,不仅能呈现新闻,通过科学的算法还可以预测新闻;它不仅大大提升了新闻写作的数量和快捷性,而且还可以加强信息的可视性、拟态性和播报的精确性;它能够更精准地了解用户的个性化需求,不仅能够进行个性化的订制、优化和推送,而且还可以通过新闻机器人和聊天机器人与海量用户进行互动。在其他非新闻类信息生产上,智能同样产生了广泛且深远的影响。因此,我们不得不面对复杂的算法带来的越来越多的伦理问题,如侵犯个人的隐私权利、带来不公正、使我们生活于算法的黑箱之中等现实问题。在算法泛用的背景下,我们需要发现、面对乃至解决这些问题,提升认识和理解,促进算法善用。
算法伦理的核心原则是算法人文主义,即坚持人文主义的传统三个要素。一是智能算法时代,仍然要坚持人的主导价值,重视人的独特性即人的尊严;二是在将算法广泛应用于人类决策的同时,仍然要坚持以人为本,从人的视角出发;三是将人及人性视作一个丰富而又复杂的存在,在算法运行中尊重人和人性。算法人文主义是一种底线思维、协商伦理,它所主张的“以人为本”并不是那种积极、主动的自我主导、自我支配,而是从最底线的意义维护人之为人的独特价值,也就是人的尊严和自由。算法人文主义主张一种前科学的人性观和世界观,人并非算法,而是充满了各种可能性,具有独特的丰富性和复杂性。在人与算法的关系上,由于人的存在是一种非本质化却又饱含丰富性的存在,包括算法在内的外在技术以及人的理性、自由,甚至身体,都只是人类存在的一个维度或者面向,算法人文主义拒绝心身二元分离、主客体对立的价值观,而是将身体与心灵视作一个整体,将技术内置于人的存在之中,由此构建基于关切和照看的整体主义的技术观,人与技术不是主客体支配与被支配的关系,而是在人的存在之中,算法技术是作为人之存在的重要面向,并在使用和照看中展开和呈现人之主体性的关系。在算法运用中,要坚持和倡导社会的公平正义原则。算法以技术垄断、流量分配和话语影响等形式,构成一种与以往否定性的暴力权力、规训权力截然不同的肯定性权力,主导着社会资源和机会的分配,影响着社会公平正义的实现。人类必须通过对算法有效性、算法必要性和算法正当性的考量,用公平的价值理念指导算法的研发和应用,弥补算法内在的缺陷,实现算法的公平,而不是公平的算法。[2](PP.11~12)
