基于注意力机制的人脸表情识别网络
2022-05-12张 为,李 璞
张 为,李 璞
基于注意力机制的人脸表情识别网络
张 为,李 璞
(天津大学微电子学院,天津 300072)
人脸表情识别一直是计算机视觉领域的一个难题.近年来,随着深度学习的飞速发展,一些基于卷积神经网络的方法大大提高了人脸表情识别的准确率,但未能充分利用人脸图像中的信息,这是由于对于面部表情识别有意义的特征主要集中在一些关键位置,例如眼睛、鼻子和嘴巴等区域,因此在特征提取时增加这些关键位置的权重可以改善表情识别的效果.为此,提出一种基于注意力机制的人脸表情识别网络.首先在主干网络中加入了深浅层特征融合结构,以充分提取原始图像中不同尺度的浅层特征,并将其与深层特征级联,以减少前向传播时的信息丢失.然后在网络中嵌入一种基于两步法的通道注意力模块,对级联后的特征图中的通道信息进行编码,得到通道注意力图,再将其与级联特征图逐元素相乘,得到通道加权特征图,将多尺度特征提取与空间注意力相结合,提出多尺度空间注意力模块,对通道加权特征图的不同位置进行加权,得到空间加权特征图.最后将通道和空间均已加权的特征图输入到后续网络中继续进行特征提取和分类.实验结果表明,所提出的方法与现有的基于深度学习的方法相比,在扩展的Cohn-Kanada数据集上的表情识别准确率提高了0~3%,在OULU-CASIA NIR&VIS数据集上的表情识别准确率提高了1%~8%,证明了该方法的有效性.
人脸表情识别;卷积神经网络;注意力机制;深浅层特征融合
人脸表情识别是人脸识别技术的重要组成部分,近年来,在人机交互、自动驾驶、精准营销、课堂教学等领域得到了广泛应用,成为学术界和工业界的研究热点.根据特征提取方法的不同,人脸表情识别技术大致可以分为两种方法:手工特征提取方法和基于深度学习的特征提取方法.
在早期的人脸表情识别方法中,首先进行人工特征提取,然后将特征向量输入到分类器中进行训练.特征提取的质量直接影响到面部表情分类的效果.常用的人脸特征提取方法有局部二值模式(local binary pattern,LBP)[1]、局部定向模式(local directional pattern,LDP)[2]和Gabor小波变换等[3].传统的人脸特征提取方法虽然取得了一定的效果,但其缺点是人脸特征的提取是手工进行的,容易受到干扰.近年来,卷积神经网络(convolutional neural network, CNN)在计算机视觉研究中得到了广泛的应用,并在面部表情识别任务中取得了良好的效果.与传统方法相比,CNN的主要优点是网络的输入是原始图像,避免了前期复杂的预处理.文献[4]提出了一种身份感知的卷积神经网络,使用两个卷积神经网络进行训练,一个用于训练与面部表情相关的特征,另一个用于训练与身份相关的特征,提高了对不同人脸的表情识别准确率.Mollahosseini等[5]以Incepiton层为基础增加了网络的宽度和深度,在CK+等数据集上取得了良好的效果.文献[6]提出了一种融合卷积神经网络,通过改进的LeNet和ResNet分别提取面部特征,再将两个特征向量连接起来用于分类,提高了面部表情识别的准确性和鲁棒性.Lee等[7]设计了一种分别提取人脸和背景区域特征的双流编码网络,结合情景进行表情识别,使网络减少歧义并提高情绪识别的准确性.文献[8]提出了一种自我修复网络(self-cure network,SCN),通过排序正则化对训练中的每个样本进行加权,缓解了大规模面部表情数据集标注不准确的问题.虽然这些基于卷积神经网络的方法大大提高了人脸表情识别的准确率,但仍未能充分利用人脸图像中的信息.主要是由于对于面部表情识别任务,可用于识别的特征主要集中在一些关键位置,例如眼睛、鼻子和嘴巴,因此增加这些关键特征的权重有助于改善表情识别效果.
人类的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息.同样,在计算机视觉中,某些输入特征可能会比其他部分对决策更有帮助.因此可以通过学习中间注意力图,然后在注意力图和源特征图上采用逐元素乘积的方式来给不同特征增加权重,从而选择最具代表性的特征进行分类. Hu等[9]提出了压缩激励模块(squeeze-and-excitation block,SE block),证明了该模块能以很小的额外计算成本给现有的深度卷积神经网络带来显著的性能提升.文献[10]提出了一种自注意力编码网络,首先计算特征图每个通道的L2范数平方的倒数,然后将该值与每个通道相乘得到加权特征图,有效地增大了稀疏特征图的权重.Woo等[11]设计了卷积块注意力模块(convolutional block attention module,CBAM),将通道注意力和空间注意力结合起来,进一步提高了卷积神经网络的性能.虽然现有的注意力机制改善了网络的性能,但目前在计算通道注意力时,为了汇总空间信息,通常采用平均池化或最大池化一次性地将每个通道上的所有空间特征编码为一个全局特征.这种暴力的编码方式会损失较多的信息,从而使学习到的注意力不准确.
针对以上问题,本文提出一种分两步汇总空间信息的方法,可以更加精细地编码空间特征,从而使学习到的通道注意力更加具有代表性.为了给一张特征图的不同位置赋予不同的权重,本文还提出一种多尺度空间注意力机制,以关注人脸关键部位的特征.此外,卷积神经网络在前向传播过程中会丢失信息,而浅层特征包含了丰富的图像信息.因此,本文充分提取原始图像中不同尺度的浅层特征,然后与主干网络中的深层特征堆叠,进行深浅层特征融合,以提取出丰富的原始图像信息.
1 表情识别网络
1.1 网络整体结构
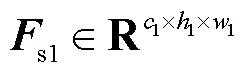
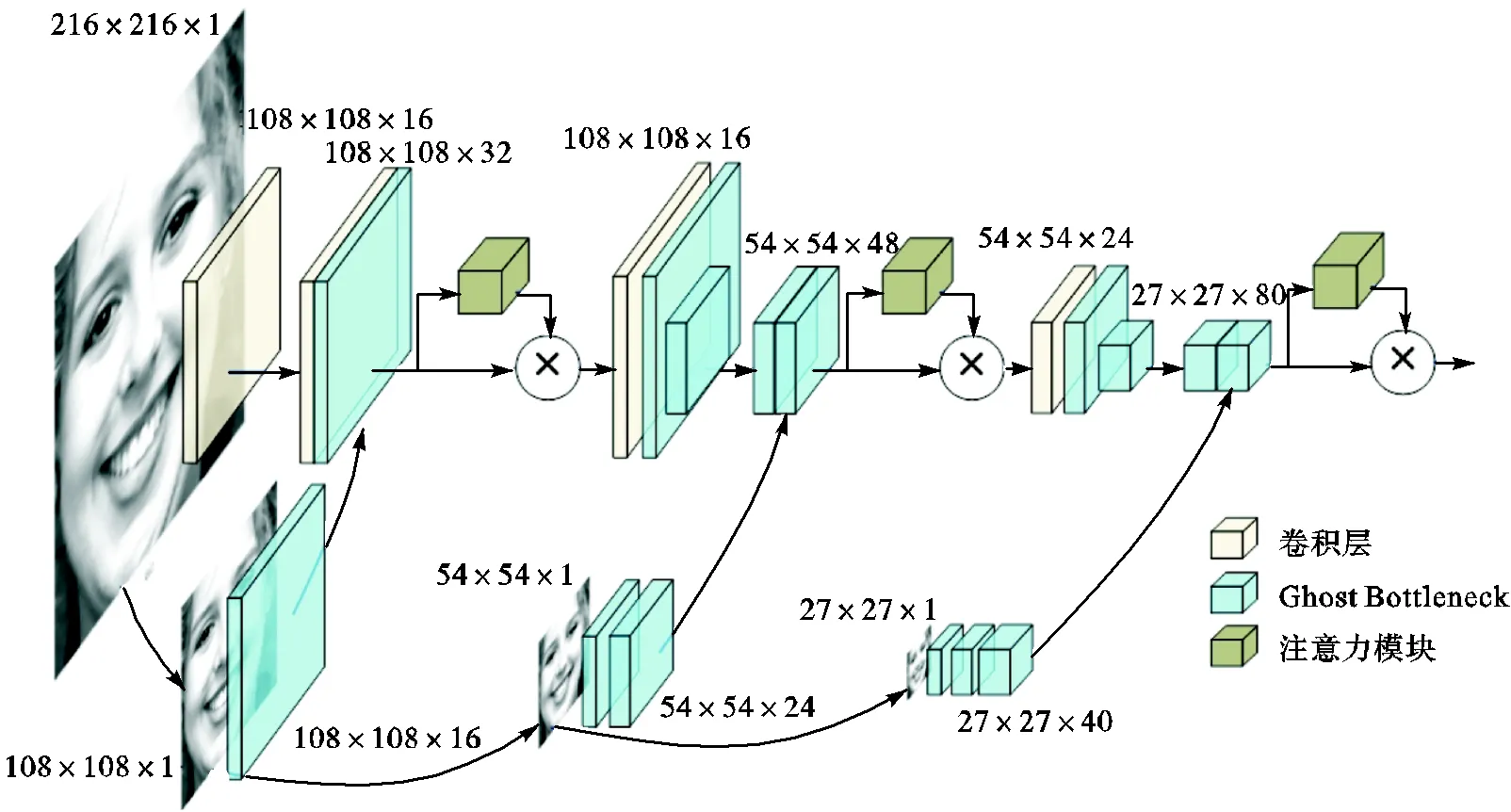
图1 本文网络结构示意
表1 主干网络的最后几个卷积层以及分类器
1.2 通道注意力模块
由于特征图的每个通道都可以视为一个特征检测器[14],因此可以赋予它们一个权重,给重要的通道更多的关注,给那些相对无用的通道较少的关注,可以提高网络的特征提取能力.为了有效地计算通道注意力,需要将每个通道内部的全局空间信息压缩到一个通道描述符中.传统的方法通常仅采用平均池化来压缩空间信息,文献[11]证明了采用平局池化和最大池化结合的方式可以更加精细地推断通道注意力.此外,目前的通道注意力模块大都采用暴力的编码方式汇总空间信息,即将特征图的尺寸从××直接压缩到×1×1(其中表示特征图的通道数,表示高,表示宽),这种压缩方式的优点是简单,但也会不可避免地损失较多信息.为了解决这个问题,本文提出一种新的基于两步法的通道注意力模块,可以更加精细地编码空间特征,将其插入到深浅层特征融合之后,以关注那些增益较大的通道,抑制无关特征.
所提出的通道注意力模块如图2所示.与现有的方法不同,该方法分两步汇总空间信息.首先通过平均池化和最大池化来聚合特征图的空间信息,先将特征图的维度压缩到×3×3,而非×1×1,因此保留的空间信息是原来的9倍,以便于进一步学习空间特征.然后将它们输入到无填充的3×3卷积层中,以进一步聚合空间信息,将每个通道编码为一个特征描述子.同时将特征维度降低到输入的1/(表示降维系数),以更好地拟合通道间的相关性,并减少参数量和计算量.然后特征图被输入到一个1×1卷积层后将通道维数恢复为,并将两个特征图逐元素相加.为减少参数量,3×3卷积层和1×1卷积层对每个特征图是共享的.最后采用sigmoid函数对合并后的特征图进行激活,将每个通道描述符压缩到0~1范围内,即得到了通道注意力图.通道注意力的计算公式为
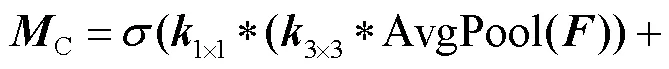

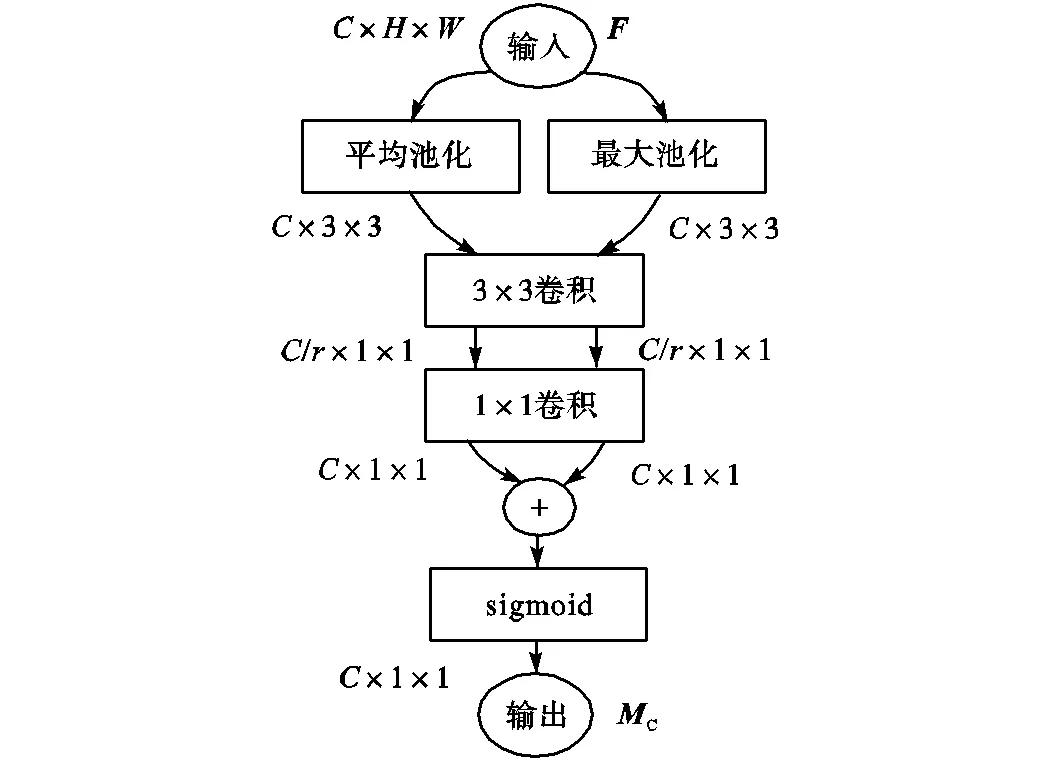
图2 通道注意力模块
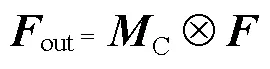
1.3 空间注意力模块
在面部表情识别任务中,对表情分类有意义的特征主要集中在眉毛、眼睛、鼻子和嘴巴等关键部位,这是由于这些位置包含的纹理信息较多,当人做出不同表情时,这些位置的特征(如梯度和灰度等)会发生剧烈变化,因此可以通过空间注意力模块在特征图上增加这些关键部位的权重,使网络更加专注于对表情识别至关重要的特征,提高网络的特征提取能力.而不同部位(如眼睛、鼻子、嘴巴等)的特征可能存在于不同大小的感受野中,并且根据人脸在输入图片中所占的比例不同,纹理特征也会存在于不同大小的感受野中,如果感受野太小,则只能观察到局部的特征,如果感受野太大,则获取了过多的无效信息,因此本文将多尺度特征提取与空间注意力结合,相比于单尺度注意力,可以更加鲁棒地提取权重特征.
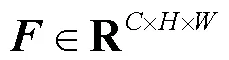
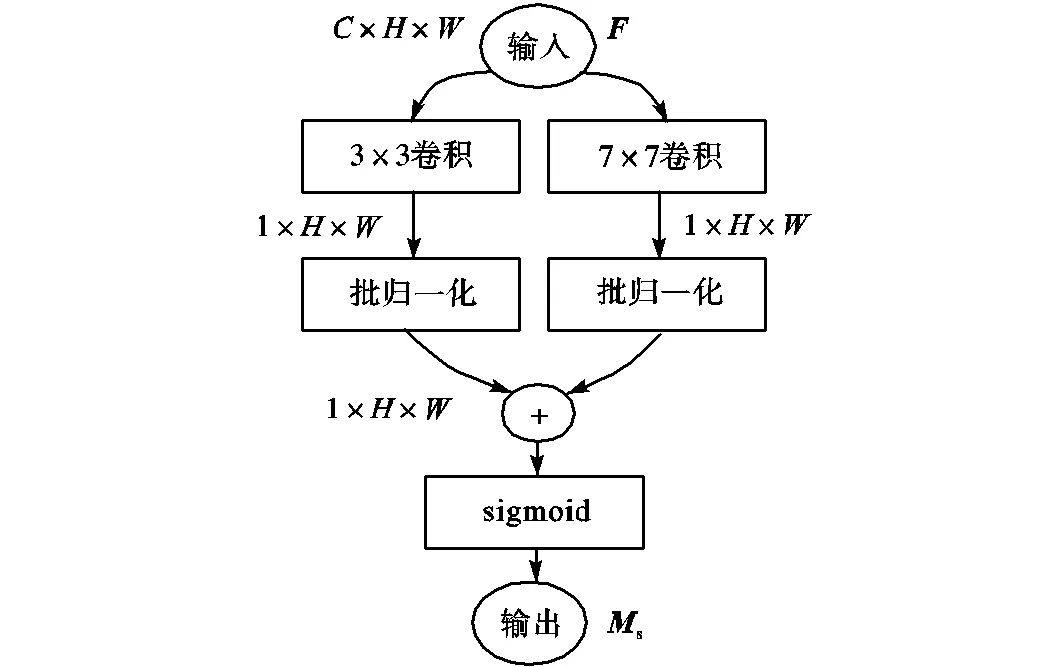
图3 多尺度空间注意力模块

2 实 验
2.1 数据集、预处理与训练
1) 扩展的Cohn-Kanada(CK+)数据集
扩展的Cohn-Kanada(CK+)数据集包含123名参与者的593个序列,其中118名参与者的327个序列有标签,共有6种基本面部表情(即愤怒、厌恶、恐惧、幸福、悲伤和惊讶).每个序列中包含了表情从平静到峰值的图片.从中选取927张峰值表情图片,并增加227张中性表情图片构成7类表情数据集.7类表情的图片数量分别为135、177、75、207、84、249和227,共1154张.
2) OULU-CASIA数据集
OULU-CASIA NIR&VIS面部表情数据集包含来自80名参与者的6种典型表情(高兴、悲伤、惊讶、愤怒、恐惧、厌恶)的视频.这些视频是通过近红外和可见光两种成像系统在正常照明、弱照明和暗照明3种不同的光照条件下拍摄的.在本实验中,只使用可见光摄像机在正常光照下拍摄的视频.一共有480个序列,每个序列同样包含表情从平静到峰值的一组图片.选择每个序列的后3帧进行评估,即共有1440张图片,构成6类表情数据集.
首先通过face_recognition库进行人脸检测,提取出图像中的脸部区域并统一缩放到220×220,然后将图像的3个通道合并,保存为灰度图,如图4所示.训练时将输入图片随机水平翻转,以增强网络的泛化能力.实验采用交叉熵损失函数和随机梯度下降法优化总体损失,损失函数计算公式为

图4 预处理后的人脸表情
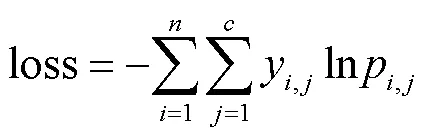
式中:为样本数;为标签类别数,、分别为样本和类别索引号;y,表示真实值向量;p,表示预测值向量.
批量大小设置为8,初始学习率设置为0.01,动量初始化为0.9,训练轮数设置为200,50轮后,学习率开始以每5轮0.9倍的速率衰减.计算公式为

式中:表示当前训练轮数;INT()表示向下取整.
测试时,通过裁剪左上角、左下角、右上角、右下角和中心,然后对每幅裁剪图像进行翻转,得到10张216×216大小的图片.取这10张图片的预测结果的平均值来做最终的决策,以减少分类误差.训练集与测试集的比值为4∶1.模型训练是在具有11Gb内存的GeForce RTX 2080Ti GPU上完成的,利用了Pytorch深度学习框架.
2.2 消融实验
所提出的模型由主干网络部分、深浅层特征融合结构、通道注意力和空间注意力模块4个部分组成.为了研究每个模块对网络性能的影响,本文将两个表情数据集合并为一个大数据集,进行消融研究.首先测试了基准网络(GhostNet)的性能.然后在基准网络中加入深浅层特征融合结构,构成深浅层特征融合网络(deep and shallow feature fusion network,DSFFNet).为了对比所提出的基于两步法的通道注意力与一步法通道注意力的性能,对所提出的通道注意力模块进行修改,利用平均池化和最大池化将特征图的维度直接压缩到×1×1,并将3×3卷积改为1×1卷积,将其嵌入到网络中,构成了基于一步法通道注意力网络(one-step channel attention module based network,OSCAM-Net).此外,为了对比所提出的通道注意力模块和目前最常用的注意力模块的性能,将上述网络中的注意力模块替换为SE block,构成了基于SE block的网络SE-Net.再将SE block替换为所提出的通道注意力模块(channel attention module,CAM),构成了基于CAM的网络CAM-Net.为了对比多尺度空间注意力与单尺度空间注意力机制的性能,首先在CAM-Net中加入单尺度空间注意力模块(即仅用3×3的卷积核提取空间注意力),构成网络Ours_1,然后将单尺度空间注意力模块替换为所提出的多尺度空间注意力模块(multiscale spatial attention module,MSAM),构成了本文最终的网络Ours_2.以上几个网络的消融实验结果如表2所示.
表2 不同网络的消融实验结果

Tab.2 Ablation experiment results of different networks
由表2可以看出,深浅层特征融合网络相比基准网络的表情识别准确率提高了1.23%.当在网络中加入基于一步法的通道注意力后性能又有所提升.而CAM-Net相比于OSCAM-Net识别准确率提高了1%以上,并且相对于目前常用的通道注意力模块SE block识别准确率提高了2.3%左右,进一步证明了所提出的通道注意力模块的有效性.而Ours_1与CAM-Net的分类准确率几乎相当,说明单尺度空间注意力无法准确地提取出空间权重特征,不同位置的权重差别不大,无法有效提高网络性能.对比之下,Ours_2相比于CAM-Net识别准确率有较大提升,证明多尺度特征提取与空间注意力结合具有可行性,能够更加精细地编码空间权重特征,提升网络性能.由此,可以得出所提出的每个模块对最终结果都有一定程度的改进.
此外,为了更加直观地观察学习到的空间注意力,将其做可视化处理,生成热度图,如图5所示,从左到右表情依次为愤怒、厌恶、恐惧、高兴、悲伤和惊讶.热度图清楚地显示了注意力区域.对于不同的表情,注意力区域有所不同.例如,对于愤怒的表情,网络的注意力更多地集中在眼睛和眉毛区域;对于高兴和惊讶的表情,网络的关注点主要在嘴巴上;而对于另外3种表情,眼睛眉毛和嘴巴都有一定的贡献.这也可以更好地帮助理解人类表情的表达方式.

图5 不同表情的空间注意力热度图
2.3 不同表情的识别效果
本文还研究了所提出的网络对不同表情的识别效果.由于CK+表情数据集中不同表情的样本数量不同,模型对于不同的表情拟合程度不同,对于样本数量较少的表情,模型训练会欠拟合,导致识别效果较差,因此结果不具有代表性.而OULU-CASIA表情数据集中各种表情的样本数量相等,因此可以更加公平地比较模型对不同表情的识别效果,故仅在该数据集上比较网络对不同表情的识别效果.混淆矩阵如图6所示,其中纵坐标表示真实标签,横坐标表示预测类别.可以看出,所提出的网络对于恐惧、高兴、惊讶3种表情具有很好的识别效果,基本可以达到95%以上,这是由于这几种表情特征比较明显(例如眼睛睁大、嘴巴张开等),而对愤怒、厌恶和悲伤的识别效果稍差,一些标记为愤怒的面部表情被识别为悲伤,一些标记为厌恶的表情被分类为愤怒,标记为悲伤的表情被分类为了厌恶,即这3种表情之间的分类出现了一些混淆现象.这些错误与笔者在查看数据集中的图像时看到的是一致的,即不同的人表达这几种情绪的方式有差异,有些表情具有一定的相似性以至于人类都无法准确地辨别.

图6 不同表情的识别准确率混淆矩阵
2.4 与其他方法的比较
本文还将所提出的方法与在CK+数据集和OULU-CASIA数据集上评估的最新方法进行了对比,对比结果如表3所示.其中加粗的数据分别为不同方法在该数据集上的最高准确率以及本文方法的准确率.可以看出,所提出方法的性能超过了大多数现有方法.在OULU-CASIA数据集上,与基于手工特征提取的算法相比提高了10%~20%,与基于深度学习的算法相比提高了1%~8%.在CK+数据集上,与基于手工特征提取的算法相比准确率提高了7%~10%,与现有的基于深度学习的方法相比大约提高了0~3%,虽然Fu等[16]的方法在此数据集上略高于本文方法,但在OULU-CASIA数据集上本文方法比其高了2%以上,证明了本文方法的有效性和先进性.
表3 两个数据集上不同方法的表情识别准确率

Tab.3 Expression recognition accuracy of different methods in the two datasets %
3 结 语
本文提出了一种新的人脸表情识别网络,将提出的深浅层特征融合结构、通道注意力模块以及多尺度空间注意力模块结合在一起,使它们成为一个相互促进的整体,提高了人脸表情识别的准确率和泛化性能.此外,所提出的基于两步法的通道注意力模块和多尺度空间注意力模块是即插即用的,可以作为一个组件嵌入到任何其他卷积神经网络中,以提升网络的性能.在CK+和OULU-CASIA两个数据集上的实验结果表明,本文方法对于表情识别的准确率优于大多数现有方法.未来希望继续改进网络,使网络不仅局限于对空间域的特征提取,也加入一些时间域的信息,从而进一步提高模型的泛化能力.
[1] Ojala T,Pietikäinen M,Harwood D. A comparative study of texture measures with classification based on featured distributions[J]. Pattern Recognition,1996,29(1):51-59.
[2] Jabid T,Kabir M H,Chae O. Facial expression recog-nition using local directional pattern(LDP)[C]//2010 IEEE International Conference on Image Processing. Hong Kong,China,2010:1605-1608.
[3] 龚 安,曾 雷. 基于Gabor变换与改进SLLE的人脸表情识别[J]. 计算机系统应用,2017,26(9):210-214.
Gong An,Zeng Lei. Facial expression recognition based on Gabor transform and improved SLLE[J]. Computer Systems & Applications,2017,26(9):210-214(in Chinese).
[4] Zhang C,Wang P,Chen K,et al. Identity-aware con-volutional neural networks for facial expression recogni-tion[J]. Journal of Systems Engineering and Electron-ics,2017,28(4):784-792.
[5] Mollahosseini A,Chan D,Mahoor M H. Going deeper in facial expression recognition using deep neural networks[C]//2016 IEEE Winter Conference on Applications of Computer Vision(WACV). Lake Placid,USA,2016:1-10.
[6] Liu K C,Hsu C C,Wang W Y,et al. Facial expression recognition using merged convolution neural network[C]//2019 IEEE 8th Global Conference on Consumer Electronics(GCCE). Osaka,Japan,2019:296-298.
[7] Lee J,Kim S,Kim S,et al. Context-aware emotion recognition networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul,Korea,2019:10143-10152.
[8] Wang K,Peng X,Yang J,et al. Suppressing uncertainties for large-scale facial expression recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:6897-6906.
[9] Hu J,Shen L,Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:7132-7141.
[10] 冀 中,柴星亮. 基于自注意力和自编码器的少样本学习[J]. 天津大学学报(自然科学与工程技术版),2021,54(4):338-345.
Ji Zhong,Chai Xingliang. Few-shot learning based on self-attention and auto-encoder[J]. Journal of Tianjin University(Science and Technology),2021,54(4):338-345(in Chinese).
[11] Woo S,Park J,Lee J Y,et al. Cbam:Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision(ECCV). Munich,Germany,2018:3-19.
[12] Han K,Wang Y,Tian Q,et al. Ghostnet:More features from cheap operations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:1580-1589.
[13] He K,Zhang X,Ren S,et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:770-778.
[14] Zeiler M D,Fergus R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision. Zurich,Switzerland,2014:818-833.
[15] Szegedy C,Liu W,Jia Y,et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston,USA,2015:1-9.
[16] Fu Y,Wu X,Li X,et al. Semantic neighborhood-aware deep facial expression recognition[J]. IEEE Transactions on Image Processing,2020,29:6535-6548.
[17] Zhao G,Pietikainen M. Dynamic texture recognition using local binary patterns with an application to facial expressions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(6):915-928.
[18] Guo Y,Zhao G,Pietikäinen M. Dynamic facial expression recognition using longitudinal facial expression atlases[C]//European Conference on Computer Vision. Firenze,Italy,2012:631-644.
[19] Zhong L,Liu Q,Yang P,et al. Learning active facial patches for expression analysis[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence,USA,2012:2562-2569.
[20] Liu M,Shan S,Wang R,et al. Learning expressionlets on spatio-temporal manifold for dynamic facial expression recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus,USA,2014:1749-1756.
[21] Jung H,Lee S,Yim J,et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago,Chile,2015:2983-2991.
[22] Sikka K,Sharma G,Bartlett M. LOMO:Latent ordinal model for facial analysis in videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:5580-5589.
[23] Meng Z,Liu P,Cai J,et al. Identity-aware convolutional neural network for facial expression recognition[C]//2017 12th IEEE International Conference on Automatic Face & Gesture Recognition(FG 2017). Washington,USA,2017:558-565.
[24] Kim J H,Kim B G,Roy P P,et al. Efficient facial expression recognition algorithm based on hierarchical deep neural network structure[J]. IEEE Access,2019,7:41273-41285.
[25] Li S,Deng W,Du J P. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hono-lulu,USA,2017:2852-2861.
[26] Yang H,Zhang Z,Yin L. Identity-adaptive facial ex-pression recognition through expression regeneration us-ing conditional generative adversarial networks[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition. Xi’an,China,2018:294-301.
[27] Kumawat S,Verma M,Raman S. LBVCNN:Local binary volume convolutional neural network for facial expression recognition from image sequences[C]// Pro-ceedings of the IEEE/CVF Conference on Computer Vi-sion and Pattern Recognition Workshops. Long Beach,USA,2019:207-216.
Facial Expression Recognition Network Based on Attention Mechanism
Zhang Wei,Li Pu
(School of Microelectronics,Tianjin University,Tianjin 300072,China)
Facial expression recognition has remained a challenging problem in computer vision. Recently,with the rapid development of deep learning,some methods based on convolutional neural networks have greatly improved the accuracy of facial expression recognition. However,these methods have not fully used the available information because the meaningful features for facial expression recognition are mainly concentrated in some key locations,such as eyes,nose,and mouth. Increasing the weight of these key positions can improve the effect of facial expression recognition. This paper proposed a facial expression recognition network based on an attention mechanism. First,a deep and shallow feature fusion structure was added to the backbone network. This structure was designed to fully extract the shallow features at various scales from the original image and cascade these features with deep features to reduce information loss during forward propagation. Second,a two-step-based channel attention module was embedded in the network to encode the channel information in the cascaded feature map and obtain the channel attention map. Then,this paper proposed a multiscale spatial attention module by combining multiscale feature extraction with spatial attention. Through this module,various positions of the channel-weighted feature map were weighted to obtain the spatial-weighted feature map. Finally,the feature map whose channels and spatial positions were weighted was input into the subsequent network for feature extraction and classification. Experimental results show that this method improves the expression recognition accuracy by 0—3% and 1%—8% on the extended Cohn-Kanada and OULU-CASIA NIR(near infrared)&VIS(visible light)datasets,respectively,which proves the effectiveness of this method.
facial expression recognition;convolutional neural network;attention mechanism;deep and shallow feature fusion
10.11784/tdxbz202105001
TP391
A
0493-2137(2022)07-0706-08
2021-05-01;
2021-10-17.
张 为(1975— ),男,博士,教授.Email:m_bigm@tju.edu.cn
张 为,tjuzhangwei@tju.edu.cn.
新一代人工智能科技重大专项资助项目(19ZXZNGX00030);应急管理部消防救援局科研计划重点攻关项目(2019XFGG20).
the Major Projects of New Generation Artificial Intelligence Technology(No.19ZXZNGX00030),the Key Research Project of Fire Rescue Bureau of Emergency Management Department(No.2019XFGG20).
(责任编辑:王晓燕)
