基于PCIe总线的FPGA与PC间数据传输系统设计
2022-05-11杨佳丽
杨佳丽
(西安财经大学行知学院, 管理学院, 陕西, 西安 710038)
0 引言
信息技术的发展为各类复杂的数据采集系统提供了便捷,对于多个领域的各类复杂系统来说,数据传输的实时性与准确性都至关重要,是一切统计分析的基础。FPGA在处理数据时由于并行处理具备速度优势,PCI Express总线由于采用串行互联技术以及高带宽,具备数据同步传输功能且具有高扩展性、成本低。2种技术各有优势,为高速有效的数据传输提供了技术保障。
1 关键技术简介
1.1 PCI Express结构
PCI Express(PCIe)是第三代互联网通信的I/O总线,具有速率高、兼容性高等优势。采用事务处理层、链路层、物理层的分层体系:事务处理层接收数据请求并将其封装为数据包,转换为总线事务;链路层用于数据包的正确接收与发送,确保数据可靠与完备;物理层发送链路层的数据包以及本身产生的数据包,接收另一端发送设备传输过来的数据上传至链路层[1]。层次结构如图1所示。
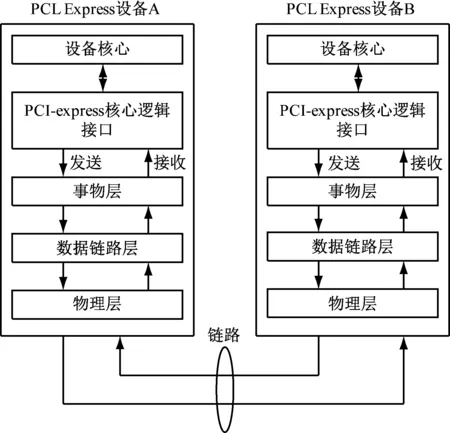
图1 PCIe层次结构
1.2 可编程门阵列FPGA
FPGA全称为现场可编程门阵列,已成为高速处理系统的主流平台,集成以往可编程器件优点的同时还解决了门阵列有限及开发周期过长的问题,在使用过程中需要不停擦写,基于查找表技术,集成各类硬核管理单元提升性能,常规芯片结构包括可编程I/O单元、嵌入式RAM、基本可编程逻辑、布线以及时钟管理。
2 DMA控制器设计
2.1 控制器逻辑原理
相对于标准编程的数据输入与输出传输,DMA具有大数据传输时高吞吐量以及占用CPU更低的优势。因此系统设计时为了提高系统性能选用DMA传输。根据DMA的实现原理,设计控制器逻辑如图2所示。
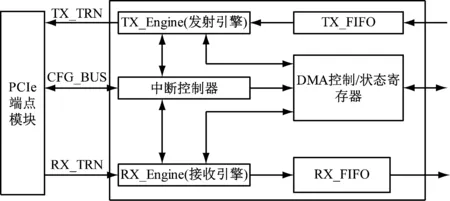
图2 DMA控制器
2.2 数据收发时序
2.2.1 发送过程
数据的发送过程主要包括以下步骤。
(1)PC端将寄存器配置好,启动DMA传输之后,在FPGA端数据就位后,TX引擎中将trn_tsrc_rdy_n、trn_tsof_n声明为有效,同时将TLP数据包存储于trn_td[63:0],在IP核将trn_tdst_rdy_n声明有效之后,将数据发送至缓存进而传输至PC内存。
(2)在核声明trn_tdst_rdy_n有效时,若应用程序声明trn_tsrc_rdy_n、trn_tsof_n有效,则将剩余TLP数据包都进行发送。若64 bit数据均有效,则存于trn_td[63:0]发送并将trn_trem_n[7:0]更新为00h,反之,将剩余32 bit有效数据存于trn_td[63:32]进行发送并将trn_trem_n[7:0]更新为0Fh。
(3)下一时钟,若应用程序声明trn_tsrc_rdy_n无效,则结束传输。
2.2.2 接收过程
数据的接收过程主要包括以下步骤。
(1)PC端将寄存器配置好,启动DMA传输之后,FPGA端数据发送请求数据包之后PC端会发送应答,应用程序准备好进行接收时声明trn_rdst_rdy_n有效。
(2)IP核准备好之后声明trn_rsrc_rdy_n、trn_rsof_n有效,将第一个应答包存于trn_rd[63:0]发送
(3)接下来的时钟里,若应用程序声明trn_rdst_rdy_n有效、IP核声明trn_rsrc_rdy_n有效trn_rsof_rdy_n无效,则将剩余数据包存于trn_rd[63:0]进行发送。
(4)IP核声明trn_rsrc_rdy_n、trn_reof_n有效,若64 bit数据均有效,则存于trn_rd[63:0]发送并将trn_rrem_n[7:0]更新为00h,反之,将剩余32 bit有效数据存于trn_rd[63:32]进行发送并将trn_rrem_n[7:0]更新为0Fh。
(5)若IP核缓存中不存在可发送TLPs,则声明trn_rsrc_rdy_n无效,结束数据接收[2-3]。
3 数据传输系统设计
3.1 整体结构
根据DMA控制器的结构,将系统功能模块划分为2个部分:FPGA端和PC端。FPGA端基于Xilinx LogiCorePCIe IP Core,实现对数据时序的控制以及PCIe事务的处理;PC端利用WinDriver的API函数设计驱动以及应用程序。
3.2 FPGA端
FPGA端的主要功能模块包括PCIe IP Core、RX接收引擎、TX发送引擎、寄存器及存储读写、接收发送的FIFO控制模块,逻辑框架如图3所示。PCIe Endpoint Core为PCIe逻辑核,处理协议层的各项配置及事务;TX Engine为发送引擎,实现TLP数据包的发送并管理时序;RX Engine为接收引擎,实现TLP数据包的接收并管理时序;寄存器及存储读写模块为Registers_Access,实现DMA的操作以及寄存器的管控;TX FIFO接收外界数据并缓存,提交TX发送引擎进而传输至PC;RX FIFO缓存从PC接收到的数据包,等待用户调用[4-5]。
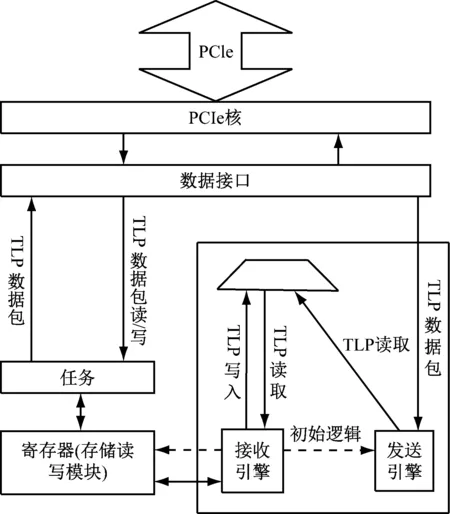
图3 FPGA端总体逻辑
3.3 IP核配置
FIFO核在接收与发送引擎上的位宽有所不同,TX端读写同步,位宽均是64位,为避免全满、全空标志因时序关系导致丢数,满标志选择almost_full,空标志选择almost_empty。RX端读写异步,写入位宽为64位,读取位宽为32位,为了避免传输时由于写满导致丢数,需将读取时钟设置为写入时钟的2倍。如此一来,需引入PLL(锁相环)实现倍频,选择一个CLKOUT0,反馈源设置为CLKFBOUT without BUFG,由于写入时钟的频率为62.5 MHz,因此调节倍频系统实现输出频率为125 MHz。
PCIe IP Core设置系统时钟为100 MHz,subclass值设置为0X80,设备ID等其他基本信息采用默认值即可。基址寄存器参数包括6个BAR(Base Assress Redister),由于地址寻址为32位,故选择BAR0,其分配1 MB空间。性能寄存器的TLPs最大负载Max Payload Size设置为512 Bytes,其他选项保持默认值。生产PCIe核后从工程中移除,将源文件添加至ipcore_dir路径下对应的文件夹[6-7]。
3.4 PC端驱动与应用程序设计
PC端主要采用WinDriver生成PCIe驱动,并利用其自带的API函数实现数据接收与发送的应用程序设计。WinDriver在诊断硬件及寄存器可正常读写之后,只需开发人员进行简单的参数设置即可自动生成驱动程序的源码。PC端应用程序调用的API函数主要包括如下。
(1) DMAWriteMenAlloc:实现内存分配并进行锁定,避免其他程序占用。包括需分配内存块数menBlocknum、每块内存大小Block Size 2个参数。
(2) StartDMATransfer:实现DMA传输,包括传输方向choice、读写文件名fp、数据包大小tlp_size、数据包个数tlp_count、传输次数cyclenum 5个参数。
(3) W_WaitForComplete/R_WaitForComplete:实现多次连续传输,包括数据包大小tlp_size、数据包个数tlp_count、传输次数cyclenum 3个参数[8]。
应用程序首先初始化PCIe函数库,然后打开设备分配一段内存并锁定,配置寄存器参数后开始DMA传输,完成后由FPGA向PC端发送一个中断,PC判断中断类型后对寄存器标志位进行更新,如果是多次传输,则进入多次传输线程。所有数据均完成传输之后关闭PCIe设备,释放系统资源。处理过程如图4所示。
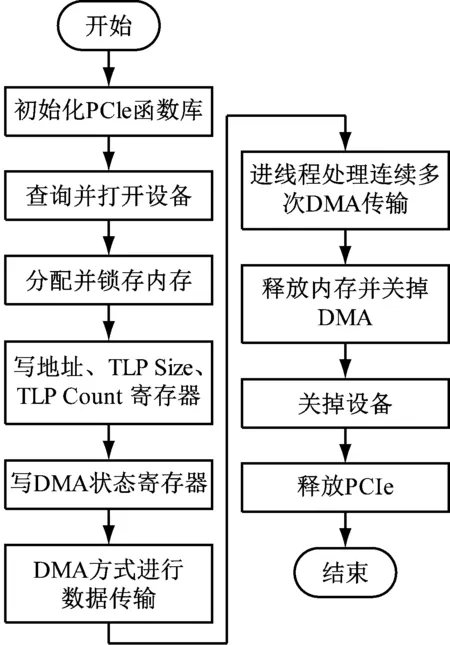
图4 应用程序处理流程
4 系统传输性能测试
4.1 测试环境准备
采用Xilinx Virtex-5 ML507开发板、WinDriver驱动、Windows 系统、VS开发环境。将板卡插入A电脑的PCIe槽后上电。B电脑打开Verilog工程进行UCF文件配置,编译好烧写入板卡。A电脑安装WinDriver工具以及PCIe驱动,在VS中运行程序进行数据传输测试[9]。
4.2 传输性能分析
由FPGA连续向PC写入20G递增数据,PC接收后利用MATLAB验证数据传输准确。同样地,PC端向FPGA也发送递增数据,利用传输的数据总量与耗时的比值计算数据传输的速度,测试结果如表1所示。
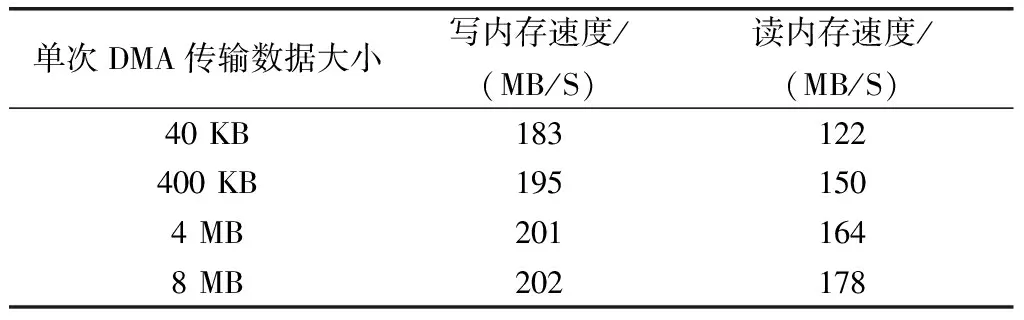
表1 PCIe传输速度测试结果表
由测试结果可知,随着单次传输数据大小的递增,读写速度并未降低,当单次传输8 MB时写入速度可达202 MB/s,读取速度可达178 MB/s。而且,因为耗时取的是第一次开始到最后一次结束的间隔且每次DMA后有中断处理,相当于每次都进行了4次BAR空间的写操作,因此得出的时间间隔更长,由此计算出来的传输速度比实际的传输速度要低,实际传输效果更佳[10]。
5 总结
本研究介绍了DMA的控制逻辑与数据时序,采用PCIe总线技术设计了FPGA与PC间的以太网数据传输系统,经过测试数据传输准确且读写性能优异。但标准FIFO接口未考虑到多种数据格式的转换,PC的配置性能对传输性能的影响,作为下一步的研究方向,力求进一步提升传输效率。
