改进YOLOv4 模型的车辆检测算法
2022-05-11罗素云陈杨钟
韩 帅, 罗素云, 陈杨钟
(1 上海工程技术大学 机械与汽车工程学院, 上海 201620; 2 大工科技(上海)有限公司, 上海 200000)
0 引 言
随着科技水平的不断发展,自动驾驶技术也不断成熟。 通过车辆自身的传感器,对车辆、行人、信号灯以及可行驶区域的检测,是自动驾驶的重中之重。 由于传统目标检测算法的实时性无法满足自动驾驶的需求,因此基于深度学习的目标检测算法,逐渐进入了人们的视野。
以RCNN 为代表的二阶段检测算法,具有更高的检测精度。 但需要经过候选区域筛选以及目标分类两大步骤,因此网络的实时性较差。 以YOLO 和CenterNet 为代表的一阶段检测算法,将感兴趣区域的筛选和目标分类集成到一个网络,在保证精度的同时,提升了网络的实时性。 与此同时,随着MobileNet 和ShuffleNet 等轻量化网络的提出,进一步降低了网络的参数量和计算量,使得网络可以在移动端进行部署。
1 YOLOv4 简介
1.1 YOLO 系列算法
YOLOv1和YOLOv2算法是YOLO 系列算法的开山之作,其检测思路不同于RCNN 系列的二阶段算法。 二阶段算法先利用RPN(区域生成网络)等方法选取目标位置所在的候选区域,然后在感兴趣区域中利用卷积神经网络的方法提取图像特征。 以YOLO 系列为代表的一阶段目标检测算法,其检测流程是一个单一的网络,创造性的把目标检测问题看成一个简单的回归问题。 在一个网络中,直接回归出检测框的位置,并得到框内物体的种类以及置信度,可以实现端对端的实时监测。
YOLOv3和YOLOv4算法的输出都是具有3种不同尺度、不同感受野的特征层,其主干网络均采用残差结构。 一般情况下,卷积层数越多,网络就越深,得到的特征信息也就越丰富。 但是,如VGGNet等网络,其加深到一定程度便无法继续加深。 因为随着网络深度的增加,其检测效果不但不会得到优化,反而可能会变的更差。 而残差网络可以在网络不断加深,得到更强语义信息的同时,避免出现梯度爆炸和梯度消失等情况。
1.2 主干特征提取网络
YOLOv3 在Darknet53 中,利用残差网络共进行了5 次特征提取。 当输入为416*416*3 的特征图时,分别得到208*208、104*104、52*52、26*26、13*13 5 层输出。 随着图片不断被压缩,特征层深度不断增加,得到的语义信息更加丰富。 同样,YOLOv4 的主干网络在其基础上改用了跨阶段局部网络(Cross Stage Partitial Network)。 CSPNet 是一个逐层的特征融合机制,通过截断方式可以有效避免同一梯度信息被反复学习,从而得到最大化梯度组合的差异。 残差网络基本结构如图1 所示。
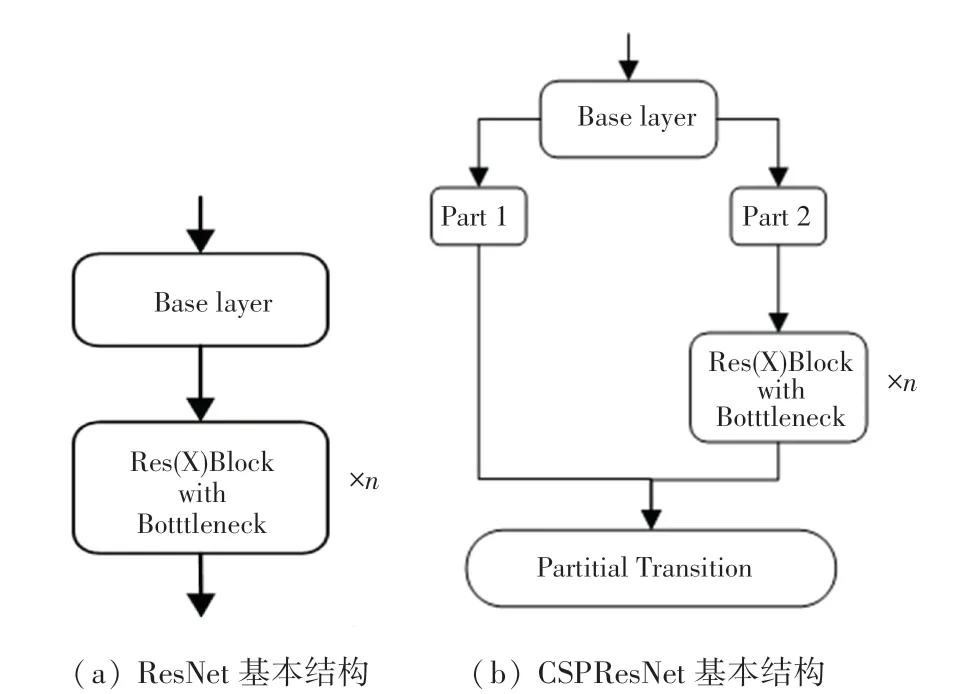
图1 残差网络示意图Fig.1 Schematic diagram of residual network
1.3 特征融合框架
主干特征提取网络获取的特征层需要进一步特征融合,才能得到语义信息和位置信息都强大的特征聚合。 YOLOv4 不仅包含与YOLOv3 相同的自顶向下的Feature Pyramid Networks 网络, 还在此基础上对13*13、26*26、52*52 的特征层利用Path Aggregation Network 进行下采样,提高了浅层特征图的信息利用率。 图2 为YOLOv4 网络中各部分代表的含义;YOLOv4 的整体框架如图3 所示。

图2 YOLOv4 框架组成模块Fig.2 YOLOv4 framework components
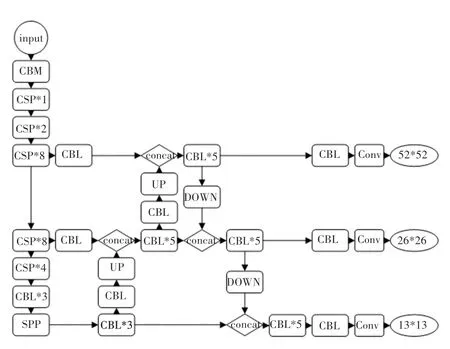
图3 YOLOv4 整体框架Fig.3 YOLOv4 overall framework
其中:CBL 模块由卷积层、归一化和Leaky Relu激活函数组成;CBM 模块由卷积层、归一化和Mish激活函数组成;Res_unit 由两个CBM 模块经过残差连接而成;CSP中代表包含几个Res_unit;UP 代表上采样的操作;DOWN 代表下采样的操作;SPP结构将4 次不同尺度的最大池化进行通道的堆叠,然后再输入特征融合网络。
1.4 损失函数及预测框
目前,多目标检测函数通常由两部分组成,即分类损失函数和回归损失函数。 近年来,随着回归损失函数的发展,目标检测的精度和速度也有了一定提升。 如: IOU_Loss 主要考虑检测框和目标框重叠面积;在IOU_Loss 的基础上,GIOU_Loss解决了边界框不重合时的问题;DIOU_Loss还将考虑边界框中心点距离的信息;而CIOU_Loss则将重叠面积、边界框不重合、边界框中心距离和边界框宽高比的尺度信息进行了融合,得到对于目标检测最优损失函数。
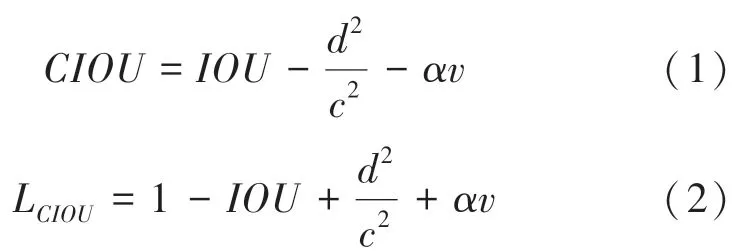
其中:代表纵横比一致性;
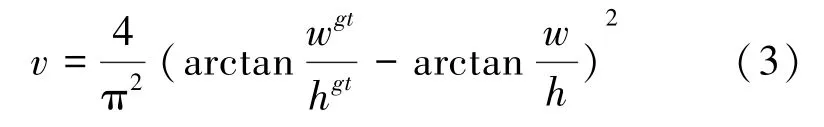
代表折中系数;
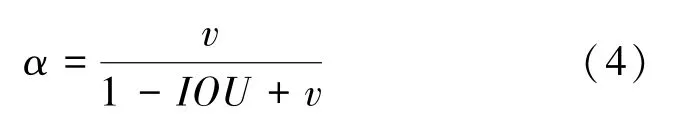
代表预测框和真实框的中心点的欧氏距离;

同时包含预测框和真实框的最小闭包区域对角线距离。
Yolov4 中采用Kmeans 聚类的方式,分别得到3个特征层的9 个不同尺度的先验框,并采用CIOU_Loss 的回归方式,使得预测框回归的速度和精度得到提高。
2 改进的YOLOv4 模块
2.1 小目标检测难点
小目标检测在许多任务中至关重要。 如,从汽车高分辨率场景照片中,检测小的或远处的物体对于安全部署自动驾驶汽车是必要的。
在目标检测实际应用场景中,需要检测的目标的尺寸往往大小不一,即多尺度检测。 多尺度检测要求训练的模型应具有较强的鲁棒性,可以检测出不同尺度的各类物体。 然而在检测过程中,大尺度物体占据图像的面积大,经过多次卷积得到的特征也比较丰富,因此较容易被检测出来。 所以,对于目标检测来说,其难点在于如何精确定位和识别出占据图像比例较小的目标。
小目标物体难以检测的原因可以分成两类:
(1)训练所用的数据集中,小目标物体出现的次数较少。 主要原因有:
①a)数据集包含小目标物体的图片数量较少;
②即使图片中包含小目标物体,但其在一张图片中出现的次数较少,很容易被忽略;
③许多图片本身的分辨率较低、图像模糊,导致其携带的信息较少。
(2)特征提取网络无法很好的提取到小目标的特征。 当输入进来的图片经过不断的卷积和采样,使得图片不断地被压缩,使小目标物体所占据的比例更小,且即使检测框可以检测到小物体所在的位置,也会在检测框内部包含大量不属于小目标的特征。 此外,特征融合网络没有充分利用语义信息和位置信息。
不同阶段的特征图对应的感受野不同,表达的信息抽象程度也不一样。 浅层特征图中含有更多的位置信息,深层特征图中含有更多的语义信息,如何将语义信息和位置信息进行更好的特征融合,得到特征更加丰富的特征层,也是一个亟待解决的难题。
2.2 数据集增强
数据增强就是在现有数据的情况下,让有限的数据通过变换,得到更多有价值的数据。 传统的数据增强方式包括翻转、旋转、裁剪、变形、缩放等。 本文在Mosaic 数据增强方式的基础上,增加了对小目标物体的复制与粘贴,使得场景远处的小目标物体在数据集中占据更大的比例。
首先,在图片中选取一个小目标物体,在图片的任意位置进行多次粘贴。 在复制粘贴过程中,要保证粘贴的位置不能与图像中现有的目标有遮挡,如图4 所示。

图4 小目标的随机增强Fig.4 Random enhancement of small targets
粘贴完成后,利用Mosaic 数据增强方法随机选取4 张图片进行缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。 Mosaic 数据增强实例如图5 所示。

图5 Mosaic 数据增强Fig.5 Mosaic data enhancement
2.3 优化的多尺度特征融合
传统的卷积神经网络,都是自上而下进行的,随着网络层数的加深,图像包含的语义信息也更加丰富。 但与此同时,小目标的特征可能会随着网络层数的加深而逐渐被忽略。 在YOLOv3 当中,通过FPN 中的上采样结构,将深层特征图的语义特征传递给浅层特征图,实现特征融合。 YOLOv4 在此基础上,增加了PANet 结构,将浅层特征图的强定位特征传入深层网络中,进行进一步的特征聚合,得到网络的3 个用于检测的输出层。
本文主要针对解决场景中出现的小目标漏检及误检的问题。 YOLOv4 利用FPN 和PANet 网络将主干特征提取网络中13*13,26*26,52*52 的3 层输出进行融合,得到语义信息和定位信息更加丰富的3 个特征层,然后进行先验框的预测和回归。
浅层的特征图感受野小,比较适合检测小目标。因此,本文算法在传统的YOLOv4 的基础上,将主干特征提取网络的第二层104*104 的输出经过上采样和下采样,再与前3 层输出融合在一起,得到4 个特征层,来提高网络对于小目标物体的检测能力(如图6 中红色虚线部分)。 并且,利用Kmeans 聚类方法,得到适合每个数据集的先验框的宽和高。 根据聚类得到的4 组先验框的大小,将其划分到对应的特征层上,大的先验框分配到深层上,用于检测大物体;小的分配到浅层上,用于检测小物体。
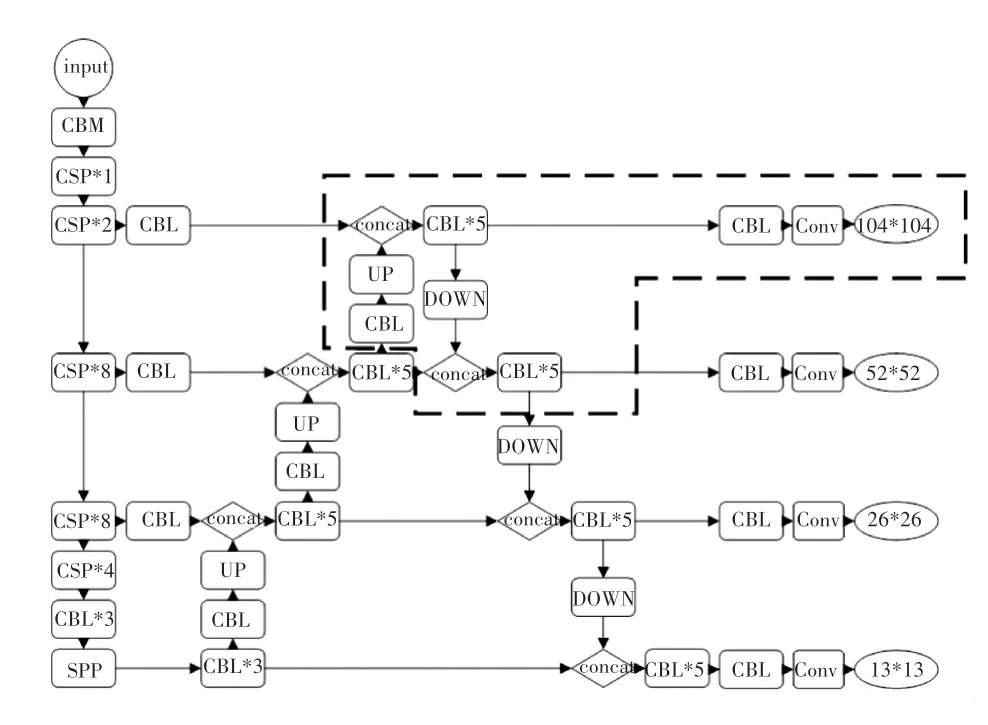
图6 改进的YOLOv4 结构Fig.6 Improved YOLOv4 structure
3 实验效果
3.1 数据集
本文采用了在图像分类、目标检测和图像分割比赛中运用最为广泛的VOC 数据集对网络进行训练。 VOC 数据集共包含人、车辆、动物、室内家具、背景等5 大类,总计21 个小类。
首先,选取vehicle 中的4 个公路交通工具进行检测,分别是bicycle、bus、car、motorbike。 VOC_2007数据集和VOC_2012 数据集分别包含9 963 张和17 125 张尺度丰富的图像,再从中随机挑选出16 551张图片组成VOC_2007+2012 数据集。 这3个数据集中,训练集、验证集、测试集的比例分别为8 ∶1 ∶1。
首先,利用VOC_2007、VOC_2012、VOC_2007+2012 数据集分别对vehicle 中的4 类进行训练。 然后,再对经过数据增强后的3 个数据集进行同样的训练,分别得到结果,进行对比。 最后,将改进的YOLOv4 与其它检测网络进行对比。
3.2 实验效果
为了验证本文所改进的网络在目标检测当中的有效性,在服务器上进行了实验。
图7 中,图7(a)是利YOLOv4 网络在VOC_07+12 数据集上经过100 轮训练后得到的val_loss 最低的权重进行预测后,得到的效果图。 图7(b)为同等条件下,改进的YOLOv4 网络的预测结果。 从两图对比可以看出,改进的yolov4 网络比原始的网络可以检测出更多场景远处的小目标车辆,提升了小目标的检测精度,从而使得整体检测精度有了提升。

图7 检测效果对比图Fig.7 Comparison of detection results
表1、表2 分别为各类检测器在VOC_2007 +2012 数据集和增强VOC_2007+2012 数据集下的检测效果。 其中包括YOLOv3 和YOLOv4,以及将YOLOv4 主干特征提取网络CSPDarkNet53 替换为MobileNetv1、MobileNetv2、MobileNetv3 的轻量化网络YOLOv4_M1、YOLOv4_M2、YOLOv4_M3。 将以上5 种改进的目标检测网络与本文提出的改进YOLOv4 网络作比较,得到的实验结果。
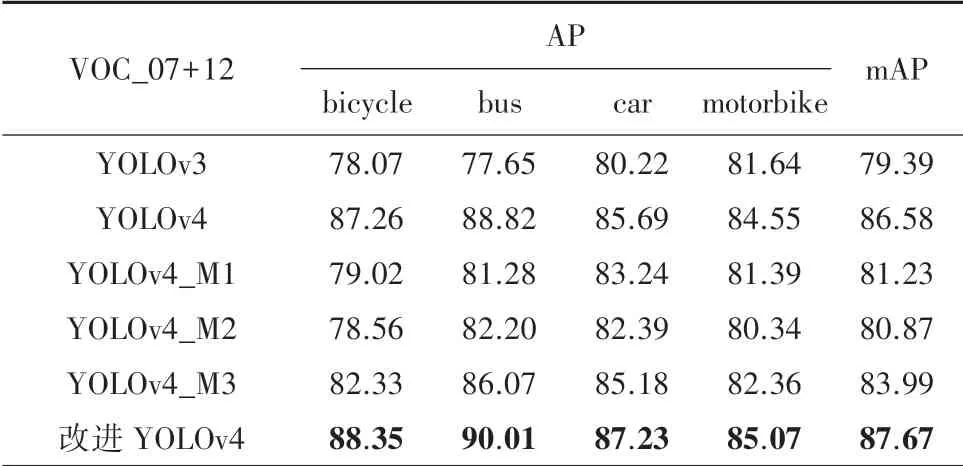
表1 VOC_2007+2012 数据集结果Tab.1 Results on VOC_2007+2012 dataset
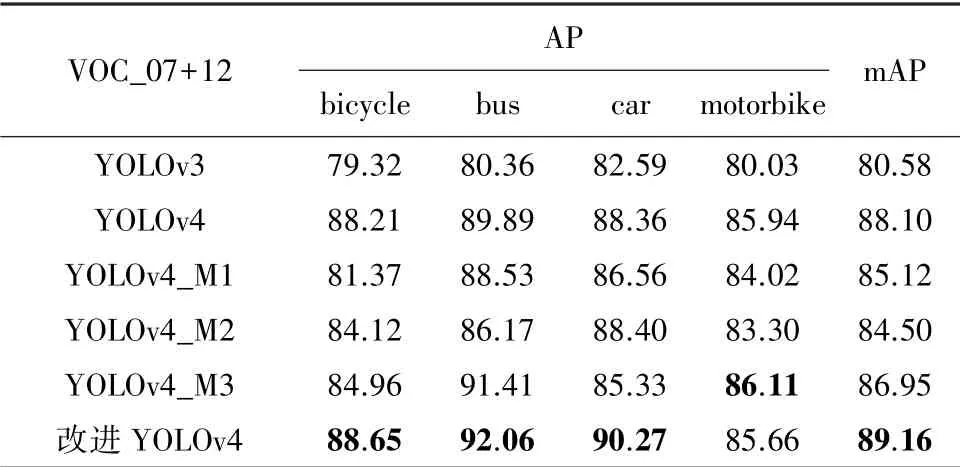
表2 增强VOC_2007+2012 数据集下实验结果Tab.2 Results under the enhanced VOC_2007+2012 dataset
4 结束语
本文在VOC 数据集基础上,筛选出属于Vehicle 的4 类图片,并利用Mosaic 和增加小目标的方式丰富了数据集中的Vehicle。 同时,在YOLOv4算法的基础上,增加了特征输出,使得网络可以在同等条件下检测更多场景远处的小目标物体,提升了整体的检测精度。 最后,利用改进的YOLOv4 在增强的VOC 数据集下进行训练,对4 类交通工具的检测精度均有不同程度的提升。
