基于Attention机制的BiLSTM诈骗电话识别①
2022-05-10许鸿奎姜彤彤周俊杰张子枫卢江坤
许鸿奎,姜彤彤,李 鑫,周俊杰,张子枫,卢江坤
1(山东建筑大学 信息与电气工程学院,济南 250101)
2(山东省智能建筑技术重点实验室,济南 250101)
随着通信技术的迅速发展,电信网络诈骗犯罪活动也屡禁不止,给国家和人民带来了巨大损失.电话诈骗是电信诈骗的一种,是以电话通信的方式对受害人进行行骗,骗取信任,最后诱导受害人以银行卡、网上转账等方式骗取金钱的犯罪活动.这些诈骗犯罪不仅给受害群众造成经济上的重大损失,更是造成精神、心理上的严重伤害,是人民群众深恶痛绝的犯罪行为.例如,2016年,大一新生徐某某因诈骗电话被骗取9 900元,而导致抑郁猝死;广东省新生蔡某某被骗后跳海身亡.一系列案件让电信欺诈问题成为备受瞩目的社会热点,电信欺诈的影响已经深入到人们的日常生活中.尽管近几年随着国家对此类诈骗案刑事打击和普法宣传力度的不断加大,电信网络诈骗犯罪得到一定程度的遏制,但总体上仍呈现高发态势,在互联网快速发展和智能手机高度普及的新形势下,如何有效治理电信诈骗,是运营商面临的一大挑战.2019年,腾讯联合公安部、工信部和移动、联通、电信等企业,发布了《电信网络诈骗治理研究报告(2019 上半年)》,报告显示,电信网络诈骗呈现日趋专业化、公司化的趋势,2019年上半年,全国各级公安机关共破获电信网络诈骗案件5.8 万起,同比上升3%;共抓获电信网络犯罪嫌疑人5.14 万人,同比上升32.28%.其中,跨平台交易日益增多,发生诈骗最多的两个平台为二手交易平台和婚恋招聘网站,分别占了28%和19%,而电话诈骗占了9%,由此可见,电话诈骗仍占据相当高的比重,通过电话进行行骗仍是犯罪分子主要的诈骗方式之一,有效防范电话诈骗,是遏制电信欺诈的重要手段.
针对国内电信诈骗频发的现状,很多学者也进行了广泛的探究.
传统的防范诈骗电话体系主要是通过对诈骗电话号码的结构进行分析,构建黑白名单库,从而对疑似号码进行拦截处理[1-3],此时的诈骗行为已经发生,只能进行事后分析处理,而且诈骗类型和手段一直在更新,这就存在一定的滞后性,无法在第一时间对诈骗电话进行拦截.
近年来,机器学习迅速发展,已在各个领域得到广泛应用,为电话诈骗的治理带来了新的转机和挑战.张慧嫦等[4]提出基于信令的电话诈骗行为检测方法,采用大数据挖掘的方式,对电话诈骗的行为特征进行分析,对疑似诈骗电话号码进行叫停、拦截等处理.程锦红等[5]提出基于大数据挖掘的防范电话诈骗模型,从诈骗通话的前、中、后三阶段作研判分析,构建基于号码特征和通话行为特征的混合模型,实现了对诈骗行为进行事前预判、事中拦截、事后分析.白晶晶等[6]提出基于大数据挖掘技术构建的电话诈骗识别模型,根据诈骗电话特征,分析通信行为,建立挖掘模型,不仅可以识别诈骗电话号码,而且能够提前预测诈骗行为,同时准确找到诈骗电话来源.
基于以上分析,可以发现,以往的防范诈骗手段大多是从政府和运营商的角度,本文则采用深度学习的方法构建一个诈骗电话识别模型,从用户视角来提高公民的反诈骗意识,当用户接通电话后,首先使用语音处理技术将语音转换为文字,本文对转换后的文字进行研究,利用自然语言处理领域中的文本分类技术来对电话文本进行识别,计算一个电话为诈骗电话的概率.
1 相关工作
文本分类问题是自然语言处理领域的一个经典问题,已广泛应用于垃圾过滤、新闻分类、词性标注、情感分类等领域.文本分类技术的发展经历了从基于规则的方法到机器学习再到深度学习的过程.基于规则的方法是依据预先定义好的规则将文本分成不同类别,例如任何带有关键词“篮球”“足球”的文本就可以划分为体育类,这种方法太依赖专家知识和历史数据,可迁移性差.20世纪90年代初,许多机器学习方法开始成为主流趋势,如支持向量机[7]、朴素贝叶斯[8]、决策树[9]等,在文本分类领域得到广泛应用,使用机器学习方法进行分类,需要两步,第一步是人工提取特征,第二步将特征输入分类器进行分类.但是繁琐的人工特征工程、过度依赖特定领域知识以及不能利用大量的训练数据又限制了其进一步发展.21世纪后,随着深度学习的发展,很多学者开始将神经网络模型引入文本分类任务,并取得了不错的进展.
RNN的线性序列结构使其非常适合用于处理序列数据,但是由于其反向传播路径太长,容易导致梯度消失和梯度爆炸问题,为解决这一问题,Hochreiter 等[10]提出了长短时记忆神经网络(LSTM),引入“门”结构,很大程度上缓解了梯度消失问题.很多学者开始将这种模型用于自己的研究中,黄贤英等[11]提出一种基于Word2Vec和双向LSTM的情感分类方法,利用Word2Vec算法训练词向量,BiLSTM 提取特征,最后用支持向量机(SVM)进行情感分类,取得了良好的分类效果;吴鹏等人[12]提出一种BiLSTM和CRF 结合的网民负面情感分类模型,增加具有情感意义的词向量来提高分类性能;赵明等[13]提出一种基于LSTM的关于饮食健康的分类模型,利用Word2Vec 实现词向量表示,LSTM作为分类模型,自动提取特征,解决了数据稀疏和维度灾难问题.尽管这种循环神经网络结构在处理时序数据的研究上表现出良好效果,但它无法捕获对重点词的关注,因为很多时序数据在时间维度上的重要程度存在一定的差异,因此有学者提出将注意力机制引入自然语言处理领域.
注意力机制[14]来源于人类视觉的选择性注意力机制,最早被用于计算机视觉领域[15],之后有学者将其引入自然语言处理领域,与神经网络模型结合使用来进改善模型性能.例如,Bahdanau 等[16]将其用于神经网络的机器翻译模型,取得了卓越效果;关鹏飞等[17]提出一种基于注意力机制的双向LSTM 情感分类模型,利用注意力得到每个词的权重分布,来提升分类效果;汪嘉伟等[18]将Attention 机制和卷积神经网络结合,利用CNN 捕捉局部特征,注意力机制捕捉文本的长距离关系,结合二者优势,也在一定程度上弥补了CNN的不足,实验结果表明,与CNN 模型相比,分类准确率有提升.本文将注意力机制引入诈骗电话分类模型,来弥补BiLSTM 模型不能准确提取关键信息的不足,以提升分类效果.
2 文本处理
2.1 文本预处理
预处理的主要目的是减少噪声的影响,此阶段主要包括分词、去停用词以及类别匹配3 个步骤.本文选用的分词方法是jieba 分词;去停用词可以在进行分类任务之前过滤掉一些对分类无实际意义的语气助词,提高分类效率;本文的研究属于有监督学习,使用带标签的数据集,所以需要对收集的数据进行人工标注,将数据标记为两类,诈骗和非诈骗,最终得到诈骗数据5 890 条,非诈骗数据6 230 条.
2.2 词嵌入
目前通常用的词嵌入方法是神经网络的分布式表示,神经网络在训练模型的同时可以得到词语的向量表示.使用最普遍的向量表示方法是Word2Vec 算法[19],该算法包含两种模型,CBOW 模型和Skip-gram 模型,CBOW是用上下文词作为输入,来预测当前词,而Skip-gram 则相反,是用当前词来预测上下文词,网络结构分别如图1和图2所示.Word2Vec的思想是训练一个语言模型,该模型以词语的one-hot 形式作为输入,比如输入的一个x=[1,0,0,…,0],训练完得到神经网络的权重v,vx正是所需的词向量,该词向量的维度与隐层节点数一致,本质上也是一种降维操作.Word2Vec得到了一个有效表示词语特征的向量形式,是自然语言处理领域的重要突破.
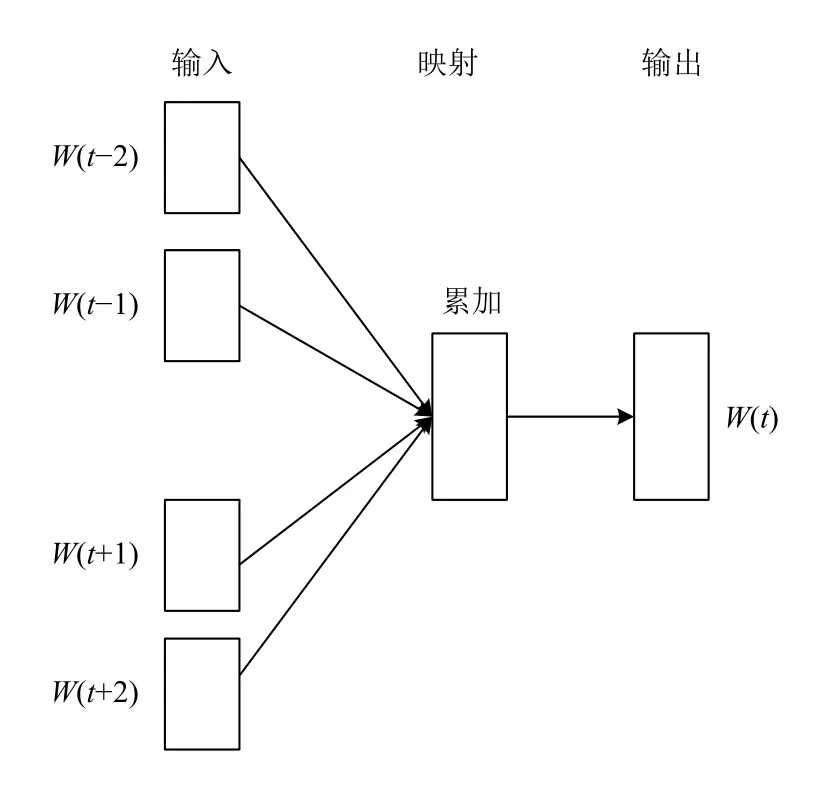
图1 CBOW
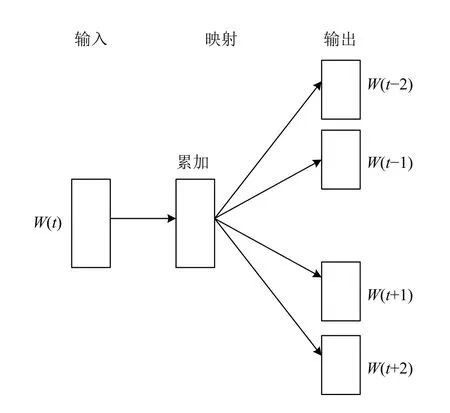
图2 Skip-gram
3 模型构建
3.1 BiLSTM-Attention 模型架构
本文提出了一个基于Attention 机制的BiLSTM 电话文本分类模型,通过引入Attention 机制,建立如图3所示的BiLSTM-Attention 神经网络框架结构,主要由词嵌入层、特征提取层、注意力模块以及Softmax分类层组成.
词嵌入层:将经过预处理后的电话文本数据映射为维度相同的词向量,图3中词向量的维度为6 维.
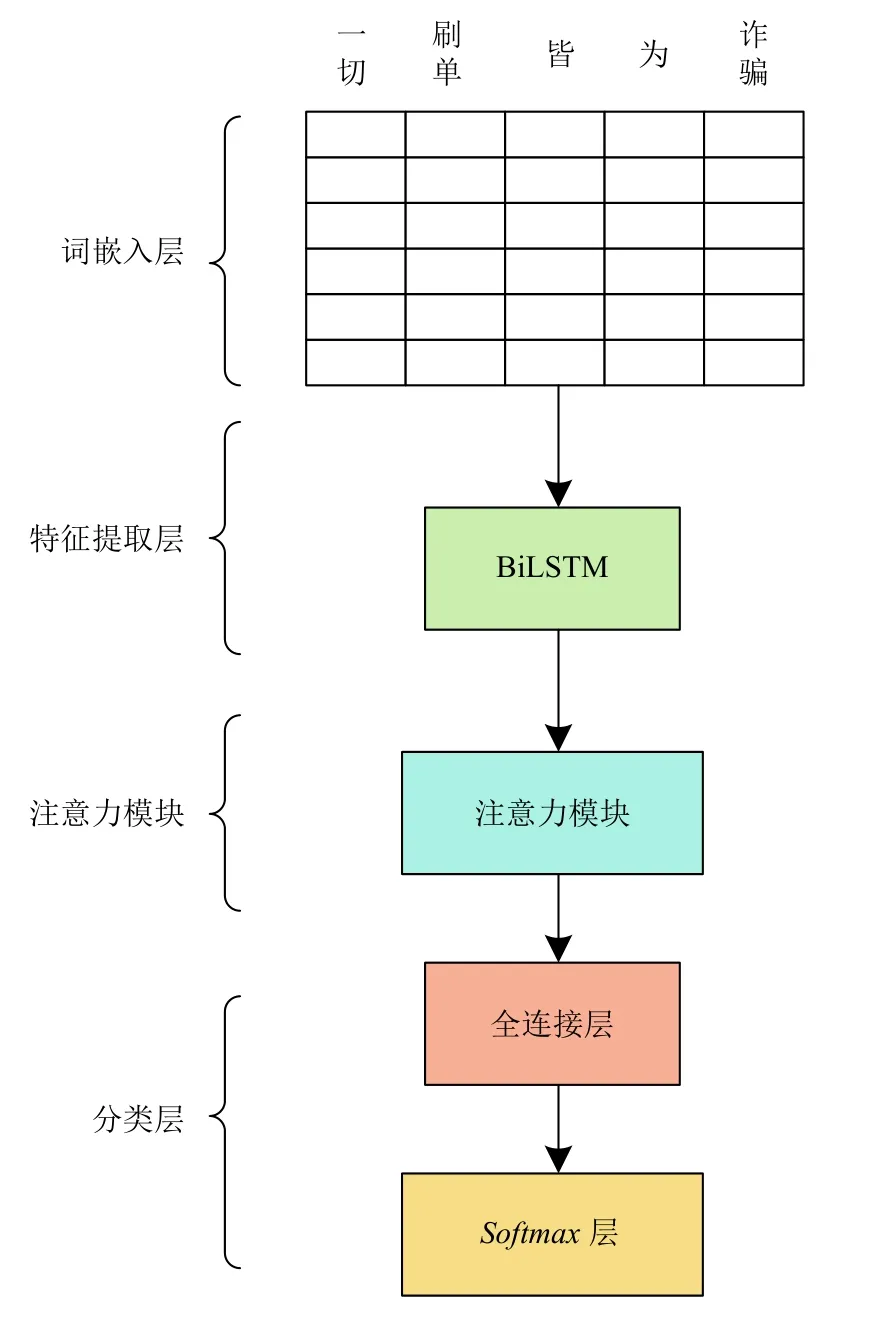
图3 BiLSTM-Attention 模型架构
特征提取层:为BiLSTM 模型,对词向量进行抽象的特征提取,可以得到文本的长距离依赖关系.
注意力模块:为进一步提高模型的拟合能力,引入Attention 机制对特征矩阵进行参数优化,抽取句中单词之间的句法和语义特征,捕获对当前分类任务更为重要的关键词.
分类层:由全连接层和Softmax层组成,输入为经过Attention 机制后得到的句向量,完成对电话文本的分类,得到文本分别为诈骗和非诈骗的概率.
3.2 BiLSTM 层
长短时记忆神经网络(LSTM)是循环神经网络的一种,它可以很大程度上解决梯度消失问题.LSTM 特有的门结构可以让信息有选择性地通过,决定哪些信息应该被保留,哪些信息应该被遗忘.LSTM的内部结构如图4所示.
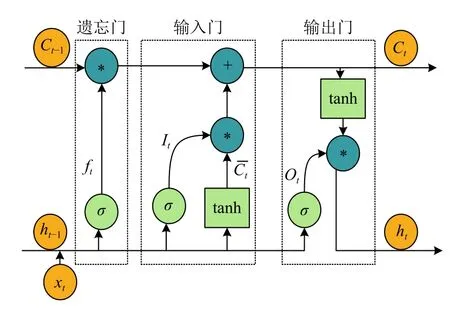
图4 LSTM 结构图
其中,Xt为当前时刻的输入值;Ct-1为上一时刻的单元状态;ht-1为上一时刻的隐层状态;Ct为当前时刻的单元状态;ht为当前时刻的隐层状态.
LSTM的工作过程如下:
第一步是“遗忘门”(forget gate),这一步决定了要保留多少前一时刻的单元状态信息到当前单元,它查看上一时刻的隐层单元状态ht-1和当前时刻的输入Xt,经过Sigmoid 激活函数,得到遗忘门的权重向量Wf,这一计算过程表示如下:
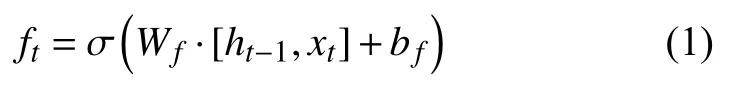
然后是“输入门”(input gate),它决定了要保留多少当前时刻的输入状态Xt到当前时刻的单元状态Ct.这一过程分两步,首先由Sigmoid 激活函数决定更新哪些值,得到决策向量it;然后由tanh 激活函数构建候选向量Vt,由这两个向量来得到更新值,计算过程如下:

当前时刻的单元状态Ct的计算过程如下所示:
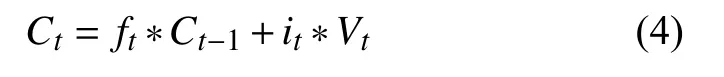
最后一步是“输出门”(output gate),这一步是基于单元状态,决定输出什么.单元状态Ct的决策向量Ot和隐层状态ht的计算过程表示如下:

其中,Wx、Wf、Wo分别代表输入门、遗忘门、输出门的权重向量;bf、bo和bc分别代表输入门、遗忘门、输出门和记忆单元的偏置值;σ(·)表示Sigmoid 激活函数;tanh 表示双曲正切激活函数.
自然语言处理的很多情况下,当前时刻的输出不仅取决于之前的状态,还和未来的状态有关,由于LSTM 只能依据之前时刻的序列信息来预测下一时刻的输出,Graves 等[20]提出双向LSTM,该网络结构由前向和后向的两个LSTM 叠加构成,其结构如图5所示.对于任一时刻,输出由两个方向相反的LSTM的状态共同决定,正向LSTM 能够从前向后捕捉“过去”时刻的信息,反向LSTM 能够从后向前捕捉“未来时刻”的信息,同时还能获取单词之间的长距离依赖特征,真正做到了基于上下文判断,丰富了句子特征,有利于提高分类准确率.
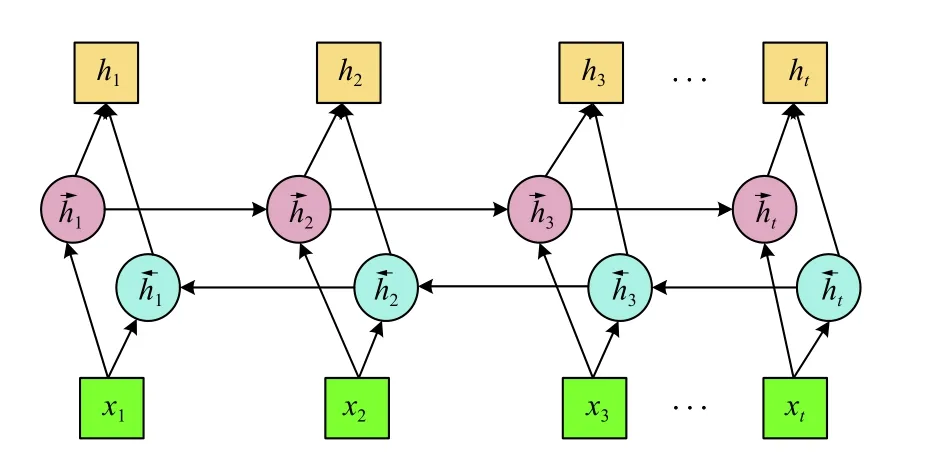
图5 BiLSTM 神经网络结构
在时刻i,网络的最终输出由前向和后向的特征采取按位加和操作得到,如式(7)所示:

3.3 Attention 层
视觉注意力机制是人类视觉所特有的一种大脑信号处理机制.人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,即所谓的注意力焦点,而后会更多关注目标区域的细节信息,抑制其他无用信息.人类通过这种注意力机制,可以快速从大量信息中快速筛选出少量高价值信息,从而极大地提高了视觉信息处理的效率.
深度学习中的注意力机制正是受启发于人类视觉的选择性注意力机制,核心目标也是从大量信息中选择出对当前任务目标更关键的信息,忽略其他不重要的信息.
注意力机制的实质是为每个值分配一个权重系数,其本质思想可以表示为式(8)所示:

其中,Source为已知的某个元素,由<Key,Value>,数据对构成;Query为目标元素.
注意力模型在训练过程中动态调整每个时间步的权重,计算每个单词的权重系数,其计算过程可以表示为下式所示:
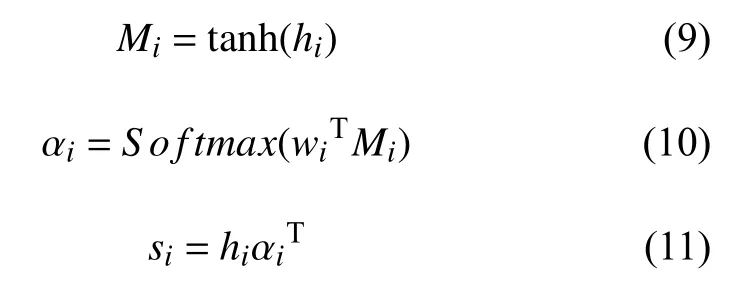
其中,hi为BiLSTM的输出,αi为注意力权重系数,wi为权重矩阵,si为经过注意力机制后的输出向量.
3.4 Softmax 层
本文使用Softmax回归模型作为分类器实现对电话短文本的分类.Softmax回归模型是Logistic 模型在多分类问题上的推广,当类别数为2 时,即为Logistic模型.假设样本输入X={(x1,y1),(x2,y2),…,(xm,ym)},其中,Xi∈Rn,i表示第i个样本的文本向量,维度为n,样本总数为m;yi∈{1,2,…,k}表示第i个样本对应的类别,类别数为k,本文为二分类,所以k=2.判别函数hθ(xi)为:

其中,θ1T,θ2T,…,θkT∈Rn+1表示模型参数;p(yi=k|xi;θ)为当前样本对应第k个类别的概率.
Softmax模型的代价函数为:

其中,j代表某个类别;1{·}表示示性函数,当第i个样本属于第j个类别时,1{y(i)=j}=1,当第i个样本不属于第j个类别时,1{y(i)=j}=0.在实际的工程应用中,一般会用随机梯度下降法来优化最小代价函数,将涉及到J(θ)对各个参数求偏导,经过数次迭代计算得到最优参数,此时的模型即为最佳分类模型.
4 实验与分析
4.1 实验数据集
本文实验所用的数据集一部分是由中国移动设计院提供的,一部分来自百度、微博、知乎问答社区等网站,其中包含诈骗数据5 890 条,非诈骗数据6 000条,诈骗数据与非诈骗数据的比例约为1:1,将其按照7:3的比例分别划分为训练集、测试集,数据集的具体组成情况如表1所示.该数据集来自从网络上搜集爬虫来的近几年出现的各类电话诈骗案件,涉及范围包括刷单、虚假中奖、网贷、彩票股票、快递丢件、冒充海关、冒充警察等为由的诈骗案件,几乎涵盖了所有的诈骗类型.

表1 数据集统计表
4.2 实验环境
本文算法的实现采用基于PyTorch的NLP 框架AllenNLP,AllenNLP是由Allen 人工智能实验室构建和维护的一个开源工具,是专门用于研究自然语言理解的深度学习方法平台.
实验环境如表2所示.

表2 实验环境
4.3 参数设置
实验使用由北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者提供的开源中文词向量语料库sgns.target.word-word.dynwin5.thr10.neg5.dim300.iter5.gz 作为预训练词向量,该词向量维度为300 维,是通过Word2Vec 方法训练得到,训练语料来自百度百科,涵盖各领域[21].
经过反复实验,本文最终选取的最优超参数设置如表3所示.
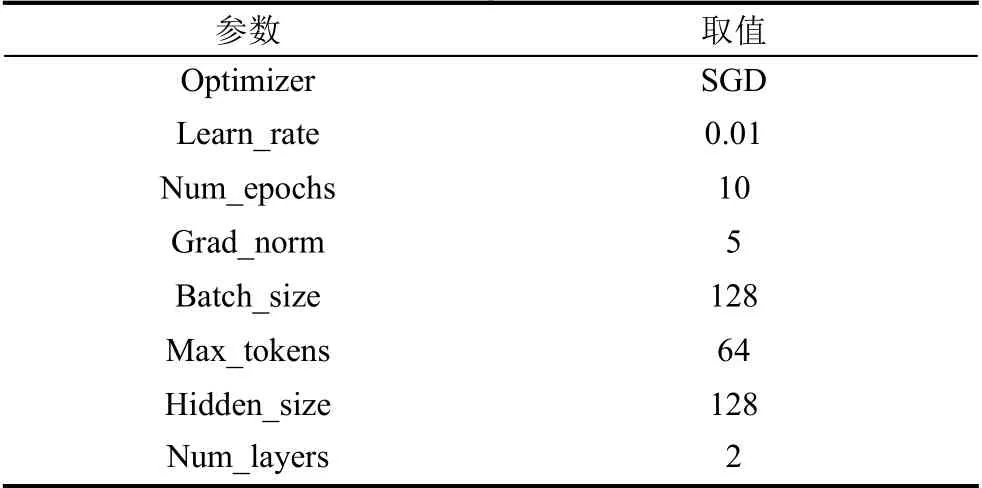
表3 超参数
4.4 评估方法
实验采用的评价指标为准确率accuracy,精确率precision,召回率recall和F1 值.
混淆矩阵,如表4所示.
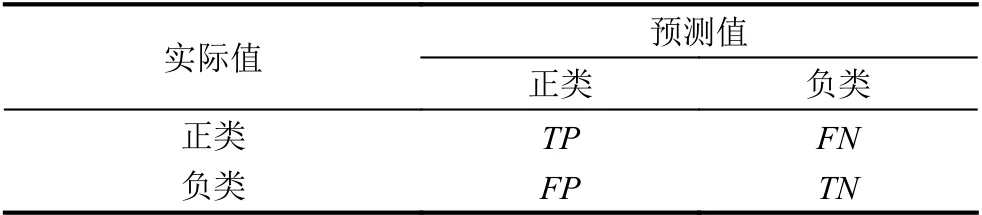
表4 混淆矩阵
1) 准确率是指所有预测为正类占总数的比例.

2) 精确率是指所有正确预测为正类占全部正类的比例.
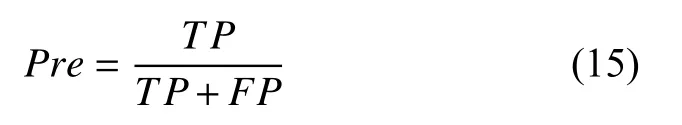
3) 召回率是指所有正确预测为正类占全部实际为正类的比例.
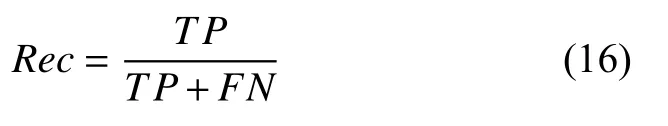
4)F1 值综合了精确率和召回率,把Pre和Rec的权重看作是一样的,是基于两者的调和平均,通常作为一个综合性的评价指标,F1 值越高,代表模型的性能越好.
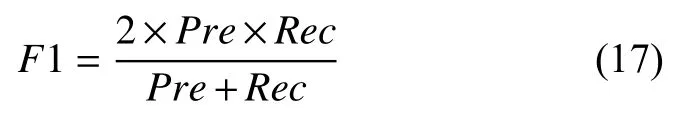
4.5 实验结果
为验证本文提出的基于Attention 机制的BiLSTM电话诈骗识别模型的有效性,在同一数据集下,分别对LSTM,BiLSTM 以及本文提出的BiLSTM-Attention 模型进行了对比实验,实验结果如表5所示.
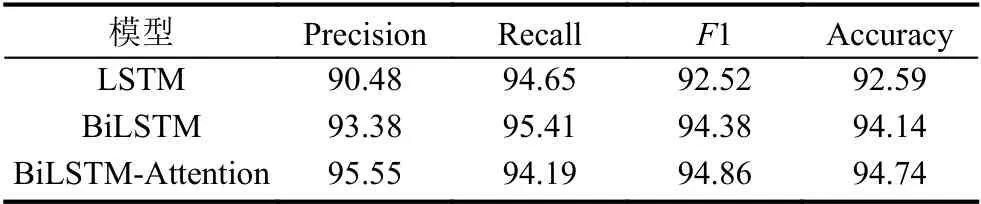
表5 实验结果 (%)
基于以上3 种模型进行对比试验,并针对评价指标精确率、召回率、F1 值以及准确率作对比分析.由表中实验结果可以发现:
1) 本文提出的BiLSTM-Attention 模型的准确率为94.74%,比LSTM 高2.15%,比BiLSTM 高0.6%;F1 值为94.86%,比LSTM 高2.34%,比BiLSTM 高0.48%;
2) 通过LSTM和BiLSTM的对比实验可以看出,BiLSTM的精确率、召回率、F1 值均要高于LSTM,即BiLSTM 模型的分类效果更好.因为前者只是提取了上文信息,而后者提取了上文和下文的信息,特征更丰富,说明基于上下文的判断更有利于分类;
3) 通过BiLSTM和BiLSTM-Attention的对比试验可以看出,BiLSTM-Attention的精确率、F1 值、准确率较BiLSTM,尽管提高不大,但都有显著的提升,但召回率要低于BiLSTM 模型,这一点有待改进,说明注意力机制对实验分类效果具有一定程度的影响.这是因为注意力机制可以通过增大重点词的权重,增加对重点词的关注,突出了对当前诈骗电话分类任务更关键的信息,即进一步捕获经过BiLSTM 提取长距离特征后的重点信息,来提升模型性能,提高分类准确率.
5 结束语
本文提出一种基于Attention 机制的BiLSTM 诈骗电话分类方法,首先对文本进行预处理,包括分词、去停用词等,然后利用预训练词向量模型得到每个词的词向量,输入BiLSTM 模型,提取长距离特征,并通过引入注意力模块进一步捕捉关键信息,来提升模型性能.实验证明,提出的模型较单模型LSTM和BiLSTM,都有显著的提升.同时本文实验也存在一定的不足之处,比如实验数据不足,所提出模型分类效果提升不高等问题.未来的研究中,将考虑从以下几个方面来改进模型,继续搜集更新诈骗信息,扩大数据集;采取下采样的方法增加诈骗数据;针对本研究的小数据特点,采用先进的预训练语言模型来训练,如ELMo、BERT、GPT 等.
