多模态特征融合的人脸活体检测算法
2022-05-10靳永强王艺钢梁迎春
赵 洋,许 军,靳永强,王艺钢,梁迎春
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引言
随着科学技术的飞速发展,人脸识别技术广泛应用于安防、商业和金融等领域。人脸识别系统会受到很多非法用户的欺诈性攻击。人脸的活体检测是提高其安全性的一种有效手段,主要作用是区分真实人脸与人脸图像,从而提高系统的安全性。文献[1]提出了一种基于颜色纹理马尔可夫特征和支持向量机递归特征消除的方法,通过判断真实人脸和欺诈人脸之间的像素差异来区分是否是真实人脸。该方法虽然容易实现,成本较低,但是准确率不理想。文献[2]中提出了一种动作活体的检测方法,该方法通过眼睛睁开与否和嘴巴张开与否的动态来判断是否为活体,能达到很高的识别率,但需要用户的高度配合,对用户不太友好,实效性较差。文献[3]中提出了一种基于热红外成像的方法判断真实图像和面具图像的热红外图差异,利用真实人脸与伪造人脸在热红外图上的差异来区分是否为真实人脸,但该方法并不适宜当下大规模应用。
卷积神经网络(Convolutional Neural Networks,CNN)的出现,使图像的特征提取效率显著提高,不仅能得到图像深度层次的语义信息,还能提高模型的泛化能力。文献[4]中提出一种基于深度神经网络(Deep Neural Network,DNN)学习特征进行活体检测的方法,该方法虽然在识别效果方面表现优异,但是面对图像连续帧之间的空间变化,识别效果却不尽如人意。文献[5]中提出了基于MobileNetV2[6]轻量化的人脸识别方法。首先对人脸的LBP,RGB,HSV图分别进行特征提取,将提取到的特征图连接在一起继续提取特征,最后进行识别。该方法可移植性比较理想,但是不能应对复杂的攻击手段。文献[7]中提出了一种基于多模型融合的可见光人脸活体检测方法。该方法虽然取得了不错的效果,但是对局部替换的活体检测任务不是很友好。文献[8]中通过块的局部特征和显著特征相结合的方式达到了人脸防伪的效果,但模型的泛化能力还需要进一步提高。DNN的发展使当今网络能自发地提取人脸的特征信息,而引入注意力机制更能让网络聚焦于重要的信息区域,提高准确率。
针对以上问题,本文提出了一种多模态特征融合的人脸活体检测算法。首先将人脸的RGB图、深度图和红外图分别输入到18层残差网络(Residual Network-18,ResNet18)的前3个模块中进行特征提取;然后分别将每个模态的特征图送到SENet(Squeeze-and-Excitation Network)中进行加权求和,在通道维度上对图像进行拼接;最后将3个模态的图像一起送入特征提取网络进行特征匹配,得到判别结果。采用3个模态图像的原因是:因为活体人脸的反射机制不同,红外图能够很轻松地区分出真实人脸和伪造人脸的差异;深度图通过人脸的3D数据,能避免2D媒介的假脸攻击,提高系统的安全性。通过引入注意力机制,表征于局部信息,找到最需要、最有用的信息,能够提高模型的准确率。
1 人脸活体检测模型
1.1 人脸识别流程
CNN的出现极大地提高了图像在特征提取方面的性能。它主要通过对图像的层层表达,获得图像更深层次的语义信息。浅层的卷积层在特征提取的过程中只会提取到图像的一些边、角和颜色等信息。深层的卷积层能更容易地提取到语义信息。活体人脸和攻击性人脸会在摄像头捕捉的时候因为反射光的不同显现差异。CNN通过对提取到的特征之间的差异判断是真实人脸还是伪造人脸。本文主要采用神经网络并行的方式,将3种模态的图像分别输入网络进行特征提取,得到更加丰富的人脸特征,对提取到的3个模态上的特征进行融合,然后将融合后的特征图送入网络得到语义特征,最后通过决策层进行分类鉴别。人脸识别流程如图1所示。

图1 人脸识别流程Fig.1 Face recognition flow
图1中,人脸检测是在图像或视频中确定人脸的位置;图像预处理是系统对获得的受到各种条件或外部环境干扰的人脸图片进行去噪、修正和过滤等处理;活体检测是检测人脸是否为真实人脸;特征提取是将人脸的信息进行数字化,然后通过转化成特征向量的形式对人脸进行表征[9];人脸识别是对提取到的人脸特征信息进行划分,判断属于数据库中的哪一类别。
1.2 RseNet18网络结构
通常情况下,特征的丰富程度是通过堆叠层的数量(深度)来实现的,但并不是网络层数越多精度越高,而是呈先上升后逐渐降低的趋势,所以并非所有的特征提取任务都适用较深的网络结构。残差网络结构于2015年被提出,并且在ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)分类任务中取得了第一名的优异成绩[10]。ResNet18网络结构如表1所示。
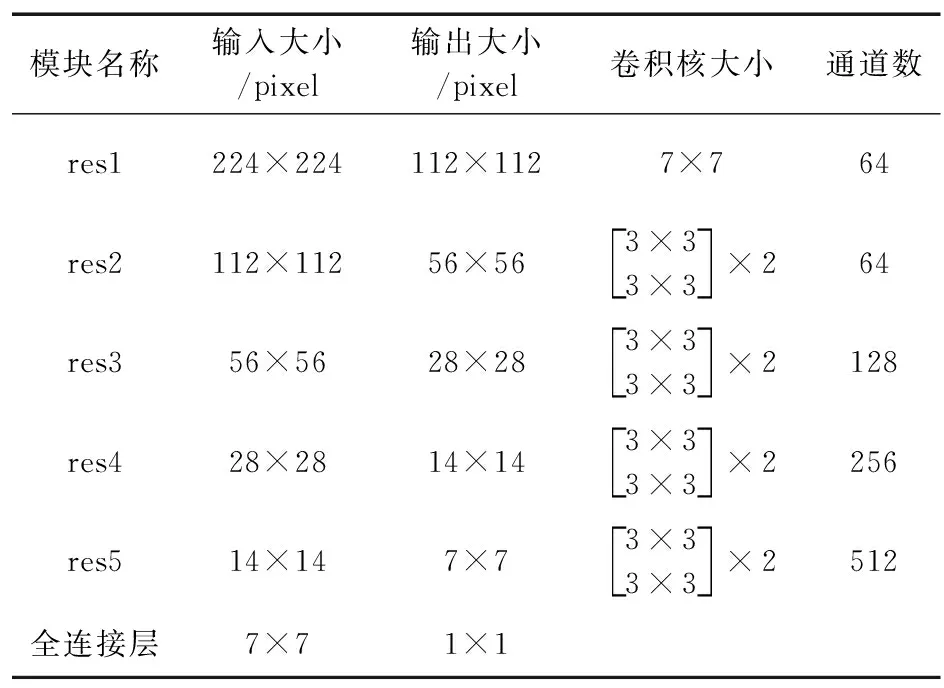
表1 ResNet18网络结构Tab.1 ResNet18 network structure
由表1可以看出,ResNet18由res1,res2,res3,res4,res5和全连接层组成。其中res1中卷积核大小为7×7,通道数(卷积核个数)为64。res2,res3,res4,res5每部分都由2个块组成,每个块执行2次相同的卷积。块内是残差的形式,如图2所示。
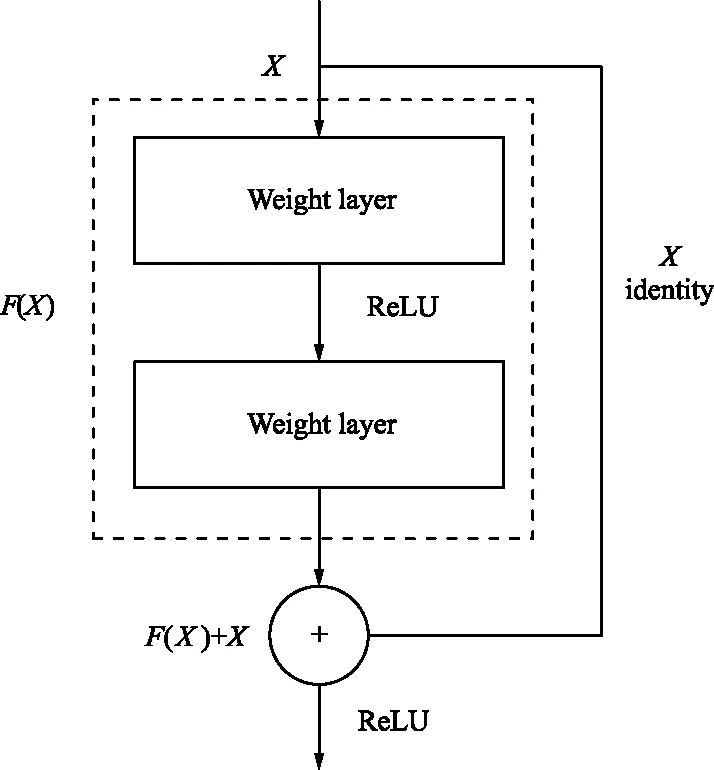
图2 残差结构Fig.2 Residual structure
图2显示的残差结构[11]分别由F(X)部分和X恒等映射部分组成,F(X)由2个卷积层构成,每个卷积层后面都紧跟批量归一化(Batch Normalization,BN)和ReLU激活函数,既加快了模型的收敛速度,又增强了非线性的能力。F(X)将在模型反向传播的过程中学习更新。如果残差趋向于0,那么模型在前向传播的过程中会更倾向于恒等映射X。
2 算法流程
2.1 人脸预处理
在获取人脸图像的过程中,摄像头的像素、背景的复杂程度和光照强度[12]等因素可能会影响整个人脸识别的结果。为了增强系统的鲁棒性,提高模型的准确率,本文需要对图像进行增强[13]。首先要确定人脸位置,通过摄像头获取到视频中的单帧图像,利用图像处理库(Opencv)中Haar级联方法对人脸进行定位,然后通过仿射变换矩阵实现对人脸的对齐。仿射变换矩阵如下:
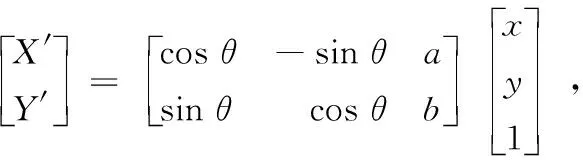
(1)
式中,X′和Y′为矫正后的像素位置;θ为旋转的角度;a,b为水平位移和垂直位移;x和y为原图片的像素位置。通过计算左、右眼中心坐标,求得双眼的倾斜夹角θ,通过逆时针旋转θ°获得对齐后的人脸。人脸校正的过程如图3所示。

图3 人脸校正Fig.3 Face correction
2.2 网络结构优化
残差网络主要解决了随着网络层数的增加,精度丢失的问题。然而,在采用多模态进行训练时,每张模态的图片对检测结果同等重要,而且模型在检测的过程中应该倾向于学习对检测结果重要的特征。如图4所示,本文在ResNet18的基础上,主要做了以下2个方面的改进:
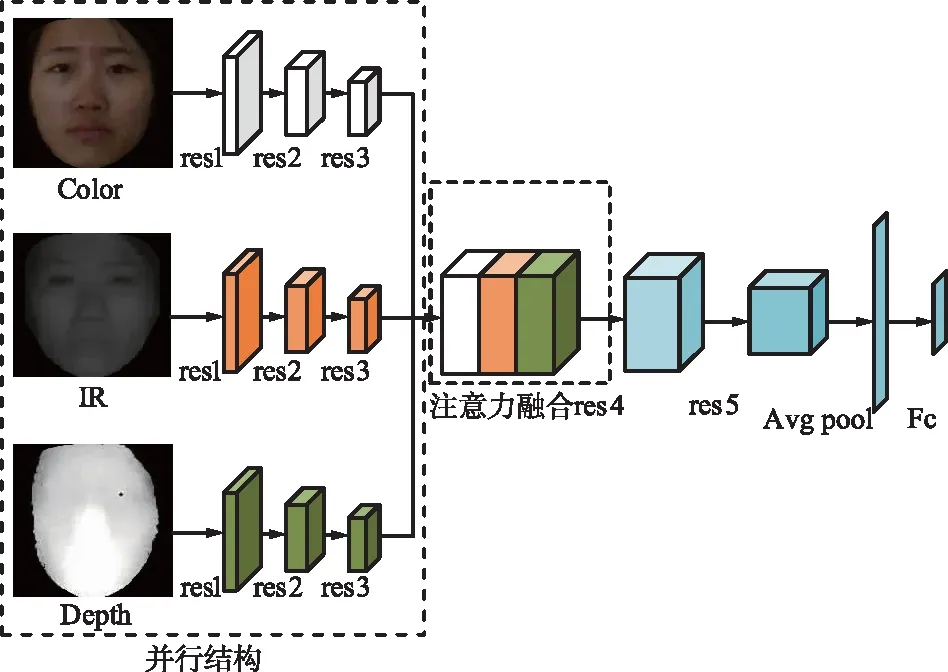
图4 优化的网络结构Fig.4 Optimized network structure
① 采用网络并行的方式对3个模态的图像进行特征提取,一能保证它们对模型同等的重要性并且保持特征之间的独立性;二能提高模型的训练速度。
② 在网络并行模块之后,加入了基于通道注意力机制的特征融合。每个特征图对模型学习的帮助程度不同,添加了通道注意力机制后能够更容易地学习重要的特征,提高识别的准确率。
由图4可以看出,3个模态图像分别经过res1,res2,res3网络提取特征,然后基于注意力机制进行特征融合,送入到res4,res5继续进行特征提取,最后经过自适应的平均池化层和全连接层进行决策分类。
2.2.1 并行层结构
ResNet18网络结构中,采用res1,res2,res3这3个网络模块先进行特征提取,如图5所示。
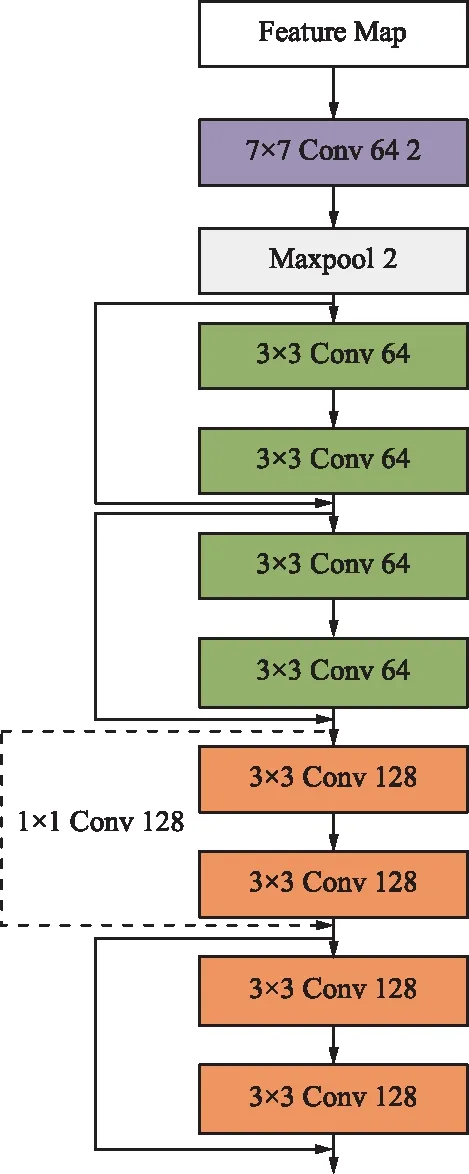
图5 并行层中的残差网络结构Fig.5 Residual network structure in parallel layer
2.2.2 基于注意力机制的特征融合
SENet是一个轻量化的网络[14],并且很容易和别的网络模型结合在一起使用,如图6所示。该网络首先将提取后的特征图经过全局平均池化操作获得一个1×1×C(特征图通道数)的向量。然后经过2次卷积学习得到权重,对权重进行Softmax归一化,既保证了权重大小都为正,又保证了权重都在0~1,权重之和为1。最后将操作生成的权重与原始的特征层相乘,加权到原有的通道上,对原始的特征进行重标定[15]。权重在模型的反向传播中进行训练更新。重要的信息分配的权重大,次要的信息分配的权重小,这样就能得到一个对人脸活体检测贡献度不同的特征层。重要的特征对结果的影响会更大,模型也会更偏向学习这些重要的信息。
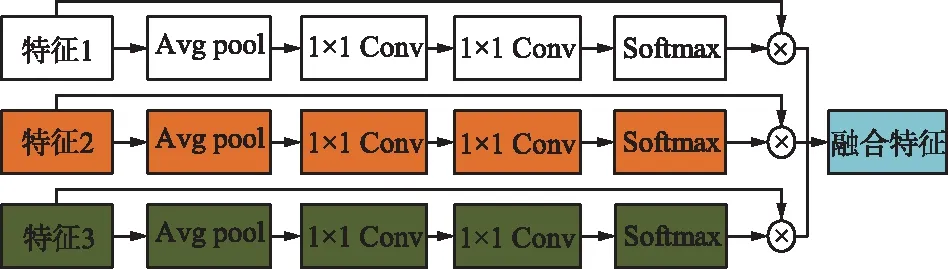
图6 SENet 网络结构Fig.6 SENet network structure
3 实验结果与分析
3.1 实验环境
实验环境为Windows 10操作系统,CPU型号为Intel Core i5-10200H,8 GB内存,GPU型号为NVIDIA GeForce RTX 2060显卡,6 GB显存,编程框架为Pytorch 1.7.0,编程软件为Pycharm。
在实验的过程中迭代次数为90,批量处理图片的大小(Batch size)为16,采用的优化器为随机梯度下降(Stochastic Gradient Descent,SGD)。学习率采用余弦退火函数[16],函数的表达式如下:
(2)
式中,T为总迭代次数;M为保存模型次数;T/M为一个周期的长度(以迭代次数step来算);t为当前迭代次数;ɑ0为初始学习率;ɑ(t)为当前学习率。从式(2)可以看出,虽然余弦函数是周期函数,但是只用到了[cos(0),cos(π)]区间内的值,而该区间周期性重复的操作由mod函数实现。由式(2)计算出的学习率范围为[ɑ0,0],即每个周期内学习率从ɑ0衰减到0。
3.2 数据集
公开的数据集中大部分是RGB人脸图像,这种图像很容易受到攻击,从而影响模型识别的精度。本文选用多模态的人脸活体检测数据库CASIA-SURF作为数据集。数据集中含有RGB图、深度图、红外图3个模态,有1 000个类别,共492 522张人脸。整个数据集中有6种攻击手段,分别是去除眼睛区域的展平打印图片和弯曲打印图片;去除鼻子区域的展平打印图片和弯曲打印图片;去除嘴巴区域的展平打印图片和弯曲打印图片。数据集按照7∶2∶1的比例分成训练集、测试集和验证集[17]。
3.3 评价指标
实验中采用平均分类错误率(Average Classification Error Rate,ACER)和准确率(Accuracy,ACC)作为实验结果的评估指标,平均分类错误率越小、准确率越高表示算法的性能越好。平均分类错误率是指攻击分类错误率(Attack Presentation Classification Error Rate,APCER )和正常分类错误率(Normal Presentation Classification Error Rate,NPCER)的均值[18]。计算方式如下:
(3)
(4)
(5)
(6)
式中,TP为活体人脸判定为活体人脸的数量;TN为非活体人脸判定为非活体人脸的数量;FP为非活体人脸判断为活体人脸的数量;FN为活体人脸判断为非活体的人脸数量。
3.4 实验结果分析
3.4.1 基于注意力机制的特征融合实验
在CASIA-SURF数据集上将基于注意力机制的特征融合和融合特征拼接(Concatenated Features)进行比较,实验结果如表2所示。
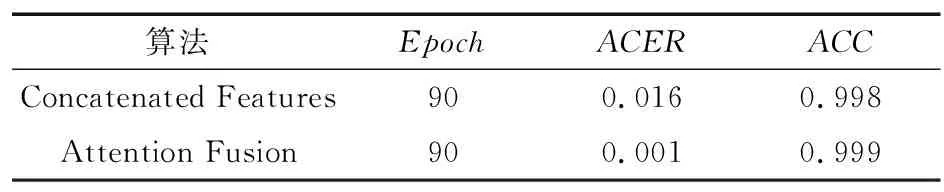
表2 不同融合方法的实验对比Tab.2 Experimental comparison of different fusion methods
从表2可以看出,基于注意力机制的特征融合方式在模型迭代90次后ACER为0.001,ACC为0.999。相比较普通的特征融合方式,本文提出的算法在平均错误率上减少了0.015,在准确率上提高了0.001。实验表明,基于注意力机制的特征融合方式在CASIA-SURF数据集上得到了不错的提升。
3.4.2 不同模态融合对比实验
为了验证不同模态融合对实验结果的影响,本文分别在RGB单模态、RGB+Depth双模态、RGB+IR双模态和RGB+IR+Depths三模态上进行了实验。实验结果如表3所示。
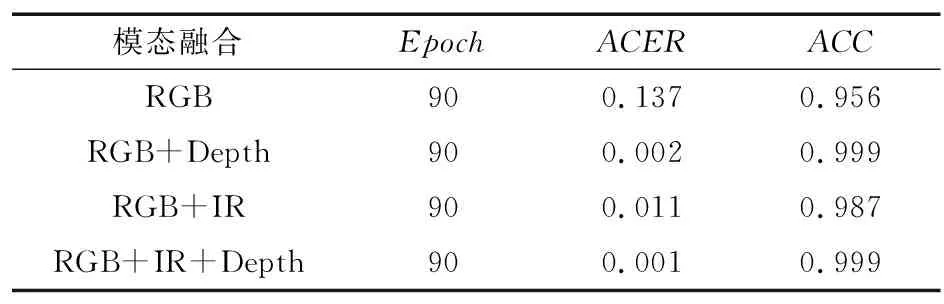
表3 不同模态融合对比实验Tab.3 Comparison experiment of different mode fusion
由表3可以看出,RGB+IR和RGB+Depth双模态图像与RGB单模态图像相比,ACER分别减少了0.126和0.135;ACC分别提高了0.031和0.043。RGB+IR+Depth三模态和RGB单模态相比平均错误率减少了0.136,准确率提高了0.043;与RGB+Depth双模态相比,在准确率相同的前提下,平均错误率减少了0.001。虽然红外图像对模型性能的提升较小,但红外图像具有光照不变性,同时可以在夜间进行识别。实验表明,多模态融合的方式能很好地提高模型的准确率,降低模型的分类错误率。
3.4.3 不同CNN在数据集上的对比实验
为了验证模型的泛化能力,本文在CASIA-SURF数据集上对不同的CNN模型进行了人脸活体检测实验[19-22]。实验结果如表4所示。
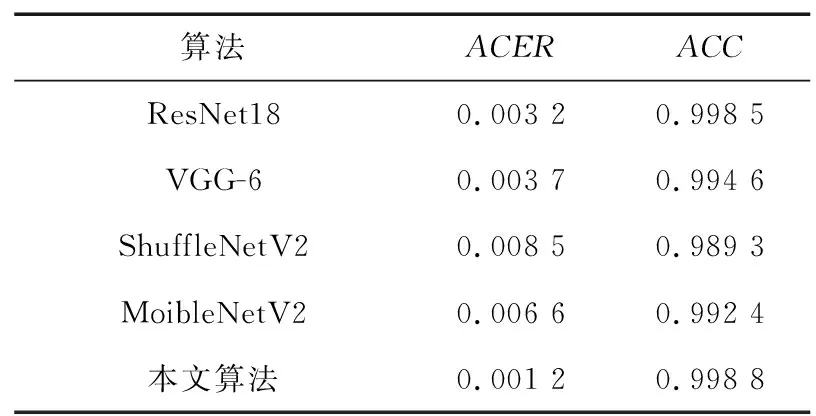
表4 不同CNN在数据集上的对比实验Tab.4 Comparative experiments of different CNN on datasets
由表4可以看出,本文算法相比较其他的算法在平均错误率和准确率上都得到了有效的改进,证明了本文方法的优越性。多模态特征融合的方法提取到的特征更加丰富,模型的鲁棒性更加出色。
3.4.4 与其他活体人脸检测算法的对比实验
为了验证本文算法的优越性,本文与其他活体检测算法进行了对比,实验结果如表5所示。
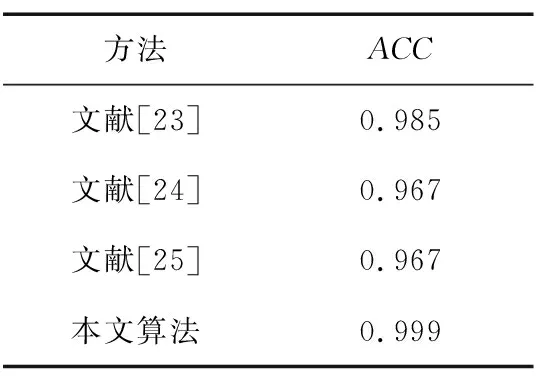
表5 与其他活体人脸检测算法的对比实验Tab.5 Comparison experiment with other face anti-spoofing algorithms
由表5可以看出,文献[23]中的方法通过近红外图像的特征进行人脸活体检测,ACC为98.5%。文献[24]中的方法通过红外人脸中的纹理差异进行人脸活体检测,ACC为96.7%。文献[25]中的方法通过头部姿态和面部表情融合的方式进行人脸活体检测,ACC为96.7%。本文多模态特征融合的方法比以上3个文献分别提高了1.4%,3.2%和3.2%。结果表明,本文提出的算法优于其他活体人脸检测算法。
4 结束语
针对人脸的欺骗性攻击,本文提出了一种多模态特征融合的人脸活体检测算法。该方法使用多模态的方式,每个模态特征提取采用相互并行的方式,加强了图像的表征能力,减少了模型的训练时间;为了提高预测结果的准确率,加快模型的收敛,使用通道注意力机制的方式对模型进行融合,在数据集CASIA-SURF上取得了优异的成绩。
本文以ResNet18网络为基础模型,实现了人脸的活体检测,然而,随着攻击方式、外部环境的变化,提取的特征可能会发生变化从而造成误判。因此,如何提高准确率,避免特征突变对识别结果带来影响,是以后重点研究的问题。
