基于模板的软件缺陷修复推荐方法
2022-05-10薄莉莉朱轩锐孙小兵
薄莉莉,朱轩锐,孙小兵
1(扬州大学 信息工程学院,江苏 扬州 225127)
2(江苏省知识管理与智能服务工程研究中心,江苏 扬州 225127)
3(计算机软件新技术国家重点实验室(南京大学),南京 210023)
1 引 言
软件缺陷种类繁多,产生原因多样,造成结果复杂多变.往往缺陷的修复历经不止一次的操作.通常,针对缺陷修复的问题,使用bug修复模板可以更快速地辅助开发人员解决缺陷问题.
早期的研究提出基于软件缺陷模式产生有效的模板补丁来更准确、更快速地修复bug.例如:Kim等人[1]首先提出了基于模板的自动程序修复(APR),从超过6万个人工补丁中学习并发现了一些常用的修复模板,这些模板能够被补丁所接受,并修复bug.Osman等人[2]提出了一种从代码更改历史中提取bug修复模式的方法,统计修复模式,讨论最常见的模式出现的原因.根据修复模式,可以更好地理解bug修复,提出更有效的bug解决方法.Negara等人[3]第一次提出从细粒度的代码修改序列中识别未知的频繁代码修改模式,并分析修改模式,归纳了10种高级程序转换模式.Zhao等人[4]开发了一种代码更改自动分类工具CTforC,它依据代码更改将其分成5种更改类型和9种更改子类型.虽然这些方法在修复bug方面有一定的帮助,剖析了较常用的修复模式,但是修复模板涉及人工手动分析,模板较单一,能提供的修复信息适合有针对性的代码修复.
目前,深度学习技术广泛应用于缺陷定位、缺陷预测和缺陷修复等方面[5-7].Tufano等人[8]提出使用深度学习的方法从真实程序的错误代码和修复代码中自动学习并生成突变体.他们利用RNN Encoder-Decoder构造一个神经机器转换(NMT)模型,能够确定在哪以及怎样突变源代码,创造了第一个用于自动化的从现有bug修复中学习变体的方法.在文献[9]中,他们还对NMT模型进行了经验性的研究,通过定性分析表明,该模型能够学习和复制各种有意义的代码更改,尤其是重构和bug修复操作.
为了提供细粒度的代码更改,更好地帮助开发人员理解bug、解决bug问题.本文构建了一种自动识别细粒度更改操作的方法,通过分析常用的细粒度代码更改操作并形成修复模板以运用到缺陷修复中.通过研究软件bug模式,开发人员可以在测试过程中更快地对bug进行修复;也可以在开发过程中考虑采用什么样的开发技术预防这些bug模式的再次出现,从而提高软件开发和测试团队的整体水平.
2 技术基础
2.1 细粒度代码更改
为了提高软件的质量,必须尽早的理解bug.了解bug修复的更改操作,可以更好地理解bug的本质.在bug修复的类型中,有很多基于细粒度更改操作的扩展研究,可以使开发人员更好地了解代码更改的性质.Negara等人[3]首先提出从细粒度的代码更改序列中识别先前未知的频繁更改操作模式,并分析修改模式,归纳了10种高级程序转换模式,并利用23位开发人员收集的真实代码进行评估,结果表明10种高级程序转换模式是有效的,并适用于大部分数据.Osman等人[2]发现缺少null的检查和初始化都是反复出现的错误,提出了一种自动提取错误修复模式的新方法.Campos等人[10]从提交修复操作的历史库中找到最常使用的更改操作模式,能够有效地用于bug修复.
2.2 GumTree
GumTree[11]是一个可以生成源代码编辑脚本的工具,编辑脚本表示两个版本的源代码之间的差异.传统上,使用diff命令生成编辑脚本[12].而GumTree将两个版本的源代码作为输入,并生成一个编辑脚本,该编辑脚本包含抽象语法树(Abstract Syntax Tree,AST)的插入、删除、更新和移动的节点,因此被用于许多更高级别的应用程序或进一步的研究中[13-16].GumTree的匹配算法包含两个阶段.第1个阶段,GumTree匹配两个AST的子树.第2个阶段,如果节点具有相同的类型并且节点的两个子树之间的Jaccard相似度超过阈值,则匹配子树中的节点.通过经验研究评估,GumTree可以有效地计算AST上的细粒度编辑脚本,并且比传统的diff命令更易于理解.
由于GumTree比diff命令的解析粒度更细,考虑了语法信息,因此运用GumTree剖析bug修复中使用到的细粒度更改操作.通过对细粒度更改操作进行经验性的研究,提取修复模板.
3 方 法
为了提高软件缺陷修复效率,本文提出一种软件缺陷修复推荐技术.方法流程如图1所示.根据bug源代码,首先定义适用于软件缺陷的修复模板,然后利用基于树的卷积神经网络(Tree Based Convolutional Neural Networks,TBCNN)对bug源代码进行分类,并根据每一类别推荐软件缺陷修复模板.
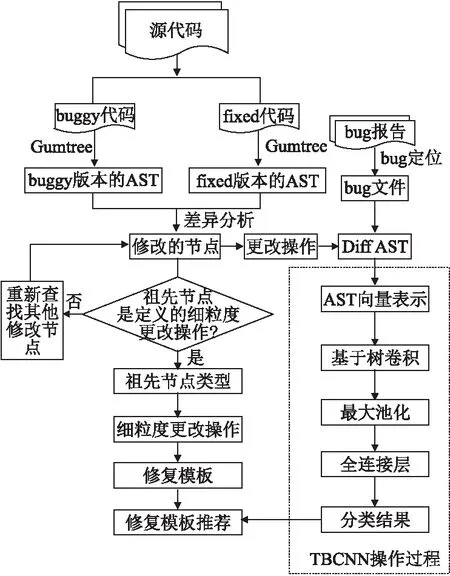
图1 方法流程图
3.1 软件bug修复模板构建
bug与其对应的源代码之间有很强的关联[17].源代码是半结构化的文本,可以确定性地解析成抽象语法树(AST),AST中的每个节点都是程序源代码中的抽象组件.利用Java的AST可以从源码中提取语义信息.
本文利用GumTree工具,获取代码的buggy版本及其对应的fixed版本的两棵AST树之间的差异,从而识别修复过程中已定义的17种细粒度的更改操作.该方法主要依赖GumTree解析代码,节点识别来判断具体的修复更改操作.首先从Github上爬取bug的源代码文件,由于本文的细粒度的更改操作针对Java语言结构,所以仅挖掘源文件中后缀名为.Java的文件并且将其作为GumTree的输入.然后通过GumTree解析buggy版本和fixed版本的差异语句,通过节点ID对应,找到具体的修改节点.差异语句中表示了从buggy版本到fixed版本所修复语句的操作,利用差异语句中的节点ID对应AST树上的节点,很容易找到具体的修复节点.最后对该节点进行祖先遍历判断其细粒度更改操作的类型.通过对祖先节点的搜索,可以清楚地了解到修改的节点具体所属的代码位置,从而可以准确判断出该节点的细粒度更改操作类型.其中删除语句对应buggy版本的AST,插入语句对应fixed版本的AST,而移动语句则需要对应buggy版本和fixed版本的两个AST.例如:某一GumTree解析后的差异语句是“Insert MethodInvocation(358) into InfixExpression:+(359) at 1”,即根据ID对应到fixed版本的AST树,追踪其父节点并判断类型,意为“添加一个方法调用”.在判断每一个差异语句之后,对于每一个bug修复,产生一个对应的修复节点序列.即,解析每一个GumTree输出的差异语句,并转换成我们之前研究[18]中预先定义的17种细粒度更改操作,形成更改操作序列.根据该序列,可以清晰地知道每一次修复基于代码所做的更改操作.
由于在软件开发和维护过程中通常进行软件重用,软件项目中的源代码包含具有一定相似程度的代码片段,会导致在源代码上进行重复/相似的更改以及bug修复,这一点在先前的研究中[19-21]也得到了证实.本文首先提取方法级的更改操作序列,然后利用序列分析每一个序列中使用的细粒度更改操作.提取方法级的更改操作序列主要有4个方面的原因:1)方法很有可能执行一个单独的任务;2)方法级提供了足够有意义的上下文,例如变量、参数和方法调用.较小的代码切片缺少必要的上下文.3)文件或类级别的粒度可能太大.4)任意长度的代码切片(例如diff中的块)可能会使模板更加复杂.此外,现有研究表明[10],缺陷主要发生在if相关语句、方法调用相关语句和赋值语句.因此,基于以上考虑,通过对代码的理解并分析其他常见的软件缺陷补丁中使用的修复模板,本文总结了8个修复模板.利用每个语句级别上重复使用的细粒度更改操作,构建修复模板,使得开发人员更有效地进行bug修复.
在Github上,每个项目都经过多次缺陷修复的提交.将本文的模板和每次提交中的代码进行类型匹配,确认模板是在缺陷代码中进行修复的,最终得出有效的细粒度修复模板.最后对该模板进行统计学分析,确保该模板是有效的,并且可以提高修复效率.下面将对每一种模板进行介绍.
模板1.IC-AS(if条件语句下赋值语句的修改)if条件的改动往往也会牵引该程序结构中其他语句的改动,if条件语句下的赋值语句也随之修改.示例如表1第2行所示.

表1 软件缺陷修复模板示例
模板2.WS-FC(while语句中方法调用的修改)while语句是常用的程序结构,方法调用亦是经常容易修改的细粒度更改操作,因此将其作为一个常用的修复模板.示例如表1第3行所示.
模板3.IC-FC(if条件下的方法调用的修改)if语句是java语言中最常用的程序结构,方法调用修改的频率较高,因此将其作为一个常用的修复模板.示例如表1第4行所示.
模板4.FS-FC(for条件下的方法调用的修改)for语句是java语言中常用的程序结构之一,方法调用是最常见的修改,因此将其作为一个常用的修复模板.示例如表1第5行所示.
模板5.IF(if语句块的添加)在处理异常的情况下,通常会在边界值处理中添加一个if语句块.示例如表1第6行所示.
模板6.RC(重复的操作)在不同的方法中添加相同的块.在bug修复过程中,通常会在不同的地方,添加上相同的代码块,特别是处理异常的情况下.示例如表1第7行所示.
模板7.IF-P(添加if预测指针)这个类别的bug都是修复条件更改,涉及对某个对象添加空指针.这种类型的bug频繁发生.示例如表1第8行所示.
模板8.AS-FC(赋值语句中方法调用的修改)赋值语句中的更改,往往会伴随着方法调用语句的更改.示例如表1第9行所示.
3.2 软件bug修复推荐方法
软件缺陷修复推荐方法利用bug源代码进行代码分类,并为每一分类结果推荐修复模板.首先将得到的bug的buggy版本AST和fixed版本AST进行预处理,将两个AST转换成一个diff-AST.最终得到的diff-AST是在buggy版本的AST中改进的,使其具有更多的修复特征,从而提高基于树的卷积神经网络的分类特征获取的准确性.
然后,运用基于树的卷积神经网络对代码根据修复过程中所包含的细粒度更改操作进行分类.在修复方案推荐的方法构建中,需要对用于分类的bug数据先进行人工标记,依据修复缺陷过程中使用的细粒度更改操作的分类标准在人工干预的情况下将数据标记类别.在我们之前的经验研究[18]中,对大量的bug进行了细粒度更改操作的分析,并将bug根据细粒度更改操作分为不同的类别.本文将8种修复模板作为修复方案推荐类别,通过分析修复代码中的细粒度更改操作将bug数据标记为不同的修复方案类别.
数据标记完成之后,通过该卷积神经网络学习不同修复方案类别的特征,并进行数据的分类.首先,将diff-AST树作为输入,并将AST节点表示为分布式实值向量,用来捕获特征.其向量表示通过编码标准来学习.接着,设计一组子树特征检测器,在整个AST上滑动以提取程序的结构信息,称为基于树的卷积核.然后,应用动态池化来收集树的不同部分上的信息.最后,添加隐藏层和输出层.对于监督分类任务,输出层的激活函数为softmax,结果为每种分类的可能性.最终将可能性值最大的类别作为推荐类别以达到修复模板的推荐.
4 实验评估
4.1 实验对象
实验对象来自Github上爬取的Mozilla项目的源代码文件,包含bug的buggy版本和fixed版本.实验数据依据Bugzilla——一个开源的bug追踪系统(1)https://www.bugzilla.org,该系统关联了Mozilla的bug数据,判断bug是否完成了修复并且有最终的修复代码,即在bug报告中是否包含“diff”.我们使用的是Bugzilla中包含“diff”的bug数据,截止到2018年10月,其数据量为1256.
4.2 实验设置
问题1.本文提出的细粒度修复模板的使用频率以及模板的覆盖范围如何?为了回答该问题,实验中对细粒度的修复模板和真实项目中的commit提交的代码进行匹配,以此判断该修复模板使用的频率.然后统计commit提交的代码中所有的修复片段,计算8种模板使用情况的覆盖范围,以确定本文定义的修复模板的通用性.
问题2.本文推荐的修复模板的精确度如何?为了回答该问题,本实验将通过基于树的卷积神经网络对bug文件进行推荐的修复模板与开发人员生成的补丁中的修复模式进行比较,来评估其准确性.为了衡量推荐方法的准确性,实验选择Mozilla项目中已完成修复的30个bug.我们利用公式(1)作为精确度的度量标准.其中P表示推荐的修复模板的准确率,nco表示能使用推荐的模板正确修复的bug的个数,Nco表示bug片段的总个数.这里的准确率为使用推荐模板正确修复bug的个数与实验中所有bug片段个数的比例,该值越高,表示修复性能越好.
(1)
问题3.本文提出的推荐修复模板是否能有效为开发人员提供bug修复信息?面对真实项目中的大量代码,运用本文推荐的修复模板,能否为开发人员提供有用的修复建议,这是本实验的目的.在实验中,让参评人员根据推荐的修复模板去修复软件bug,筛选有多少建议是可用的,并计算推荐修复模板的有效性.
4.3 实验结果
问题1.本文提出的细粒度修复模板的使用频率以及模板的覆盖范围如何?
通过将这些模板分别和每次commit提交中的代码进行匹配分析,确保这些模板是在真实的项目中经常使用并且是有效的.细粒度模块的使用频率如图2所示.在8种细粒度模板中,IC-AS模板的使用频率最高,占总使用次数的21.83%.在bug修复中,if条件语句的修改,往往会伴随着其他程序结构的修改,例如赋值语句的修改或方法调用语句的修改.IC-FC模板的使用频率为16.91%,如果出现在赋值语句中修改了调用方法或者调用方法的实参,则将其认为是对赋值语句的修改,所以在本文的统计计算中,赋值语句的修改高于对方法调用语句的修改.其次,使用频率较高的模板是AS-FC,占全部使用次数的19.73%.在赋值语句的修改中,简单的赋值语句的修改在少数,即算术表达式和逻辑表达式,大部分还是对复杂的调用方法或者参数的修改.第3个使用频率高的模板是IC-FC,所占比例为16.91%,即if语句中方法调用的修改.其他模板的使用频率分别是,IF为11.64%,FS-FC为10.54%,WS-FC为10.2%,IF-P为5.64%,RC为3.51%.
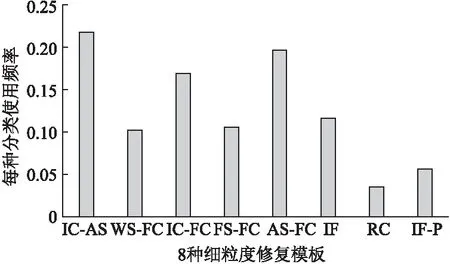
图2 细粒度模板的使用频率
可以发现,在真实的项目中,大部分的模板修改的程序主要是对于if语句的修改,以及方法调用方法的修改.随着软件维护过程中,代码量的不断扩大,修复的程序类型也不止这8种,因此还另外计算了本文的模板在所有的代码修复中所覆盖的范围.在随机选取的项目中的1028个commit提交中,这8种基于细粒度的模板在修复代码中覆盖的范围为67.11%.
综上所述,本文所提出的8种细粒度的修复模板在真实的项目中使用是有效的,并且可以解决一半以上的bug问题,可以帮助开发人员快速地修复bug.
问题2.本文基于树的卷积神经网络推荐的修复方案的精确度如何?
实验中选取的bug数据过滤掉了包含添加大量修复代码、删除大量源代码以及大量修改代码,修复包含明确的细粒度更改操作以至于可以更清晰地了解所推荐的修复方案是否正确.并且这些数据中的修复文件较少,且修复的代码行中结构较为清晰.同时,30个数据不同于基于树的卷积神经网络的训练集和测试集数据.首先30个bug报告将通过bug定位技术确定可疑的代码行,然后将包含可疑代码行的文件利用TBCNN将文件分类,最终选择类别可能性值最高的类别作为可推荐的修复方案,并给出修复意见.该实验针对最终推荐的30个修复方案,做统计分析.即通过推荐的修复方案和正确修复方案的比较,计算本文修复方案推荐方法的准确率.图3表明了在30个bug中,推荐的修复模板在每个bug修复中使用的准确率.
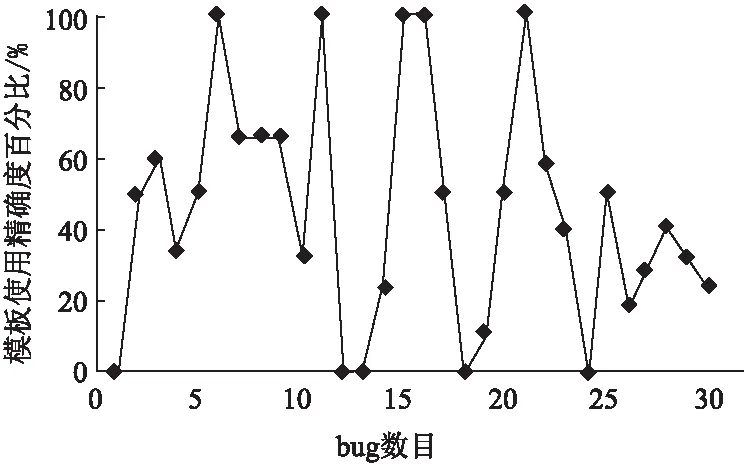
图3 推荐的修复模板使用的精确度
从图3中可以看出,在分析的30个bug中,推荐的修复模板应用于具体的代码修复中,准确率高于50%的达到了一半.这表明本文的细粒度修复模板是有效的,可以用于真实的代码修复中.由于在真实的情况下,一些bug需要修复的代码片段只有一个,或者太多(例如多于20个).这会造成修复模板的推荐受到限制,比如在bug #185165中,只修改了一处,即对if语句中的if条件进行了修改,而在本文的修复模板中不包含这类的修改,因此这会限制模板的使用.为了保证实验验证的有效性,选取的30个bug是随机选取,只过滤掉了因为添加文件而造成的大范围增加代码的情况.而大范围增加代码进行修复的过程并不适合用模板修复,会造成模板的无效性.
在30个bug中,仅有16.67%的推荐的修复模板可以达到准确率100%的效果.造成这个结果的原因主要是,目前本文的修复模板虽然取自真实的项目中,但是在提取的过程中,由于一些技术因素导致模板并不全面,此模板的覆盖范围为67.11%.其次是在真实的项目中,程序结构多种多样,并不绝对的限制在if条件中,而本文提取的修复模板大部分都是针对于if条件的修改,这会影响模板在验证过程中的效果.
问题3.本文提出的推荐修复模板是否能有效为开发人员提供bug修复信息?
在这个研究问题中,旨在验证修复模板是否符合开发人员想要的修复效果,能否为解决bug问题提供一些有效的信息.因此,为了验证这个问题,实验组织者邀请了5位参评者(对bug数据的研究超过两年),根据推荐的修复模板,对推荐的信息有用性从3个等级进行评价:有用、一般有用、无用.其中,“有用”是指能够帮助参评者实现bug问题的修复,“一般有用”是指仅能提供一部分的信息,“无用”是指推荐的信息对参评者起不到指导的作用.
图4给出修复模板有效性评价结果.根据结果可知,通过推荐的修复模板提供的相关修复信息,对30个bug进行评估,其中对于参评者C,有46.67%的模板信息是有用的,43.33%的模板信息是一般有用的,仅有10%的模板信息是无用的.因此,可以认为90%的模板信息是有效的,能够提供一些用于修复的指导意见.在其他参评者的反馈中,可以看出,大部分的修复模板方案是有效的,只有较少一部分提供的模板方案无效.造成这个结果的原因,可能是模板覆盖不全面,小部分的bug仅修复一段代码而这个修复操作不属于本文的模板的覆盖范围.但是,从评价结果可知,本文提出的推荐修复模板方案能有效的提供一些bug修复相关的信息,可以帮助开发人员解决bug问题.
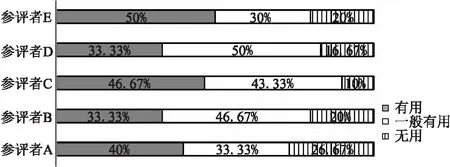
图4 修复模板有效性评价结果
5 有效性威胁
首先,在本实验中,利用基于树的卷积神经网络完成修复模板的推荐,在人工对训练数据进行分类的过程中,可能存在一些人为的误差,没有经过专家认证,从而影响训练数据集的准确性.
其次,在验证过程中,选取的bug数据是随机的,可能会导致模板的适用效果存在误差.另一个有效性威胁是问题2中的参评者的评估存在偏差.为了缓解该问题,实验中涉及的参评者都是具有开发经验并且对bug数据有两年以上的研究.
最后,本实验中的实验对象主要来源于Mozilla项目.虽然本文修复模板的提出是基于现有的大量大规模的经验研究结果,但仍不能保证推荐的模板适用于所有的项目.在接下来的工作中,我们将收集更多开源项目中的缺陷数据,以保障实验数据的充分性,从而进一步提升本文缺陷修复推荐方法的实用性.
6 总 结
本文主要针对bug修复耗时耗力的问题,利用bug报告,提出了一种基于树的卷积神经网络进行缺陷修复方案建议推荐的方法.从bug修复相关的源代码中挖掘修复模板,并利用修复模板为开发人员推荐修复方案.为了验证推荐的修复模板的有效性,本文使用Mozilla的bug数据对修复模板的精确度进行验证,并邀请5名参评者对推荐的修复模板进行评估,结果表明本方法推荐的修复模板能够有效地为开发人员解决bug问题时提供一些修复和指导意见.
