结合SENet的密集卷积生成对抗网络图像修复方法
2022-05-10张道畅
刘 强,张道畅
(东北电力大学 理学院,吉林 吉林 132012)
1 引 言
数字图像修复[1]的过程是以一种数学表达式的形式传递给计算机,使得计算机能够自动实现图像修复.早期的图像修复技术通过图像已知区域信息对缺失区域进行填充,主要分为以下几类:基于偏微分(Partial Differential Equation,PDE)和变分(Total Variation,TV)的图像修复方法[1,2]、基于样本的图像修复方法[3,4]、基于变换域的图像修复方法[5-7].传统的图像修复方法仅利用缺失区域周边的已知信息进行修复,当出现大区域缺失或已知区域与缺失区域相似信息较少时,结果会出现较大的偏差;还有一些方法使用人工交互的方式进行修复,这类方法在文物字画等修复问题上应用较为广泛,但面对较大面积的缺失问题时,模型过于依赖草图骨架,修复结果具有局限性,效果不理想.
为了能够更好的利用缺失图像的已知信息,研究学者将自编码器[8](Autoencoder,AE)和生成对抗网络[9](Generative Adversarial Networks,GAN)结合,在一定程度上解决了传统图像修复算法存在的问题.Pathak等人[10]提出了一种命名为Context Encoder的网络用于图像修复,CE算法将自编码器与生成对抗网络进行结合,能够对大区域缺失的图像进行修复,但修复的结果常常出现伪影等现象.Yeh等人[11]设计了一种利用先验误差来进行图像修复的方法,该方法将图像语义分割技术与生成对抗网络相结合,通过引入l2损失和先验损失生成修复图像,但对于结构比较复杂的小数据集仍有语义不连贯的现象.Iizuka等人[12]首次提出双判别网络的算法,利用局部判别网络增强局部纹理清晰度,利用全局判别网络保证全局修复效果的语义连贯.Yu等人[13]提出由粗到细的二级生成网络结构,其中第1个网络进行初始粗略预测,第2个网络引入注意力机制,然后将粗略预测作为输入并对粗略结果精细化.Liu等人[14]提出了部分卷积,即用一个二值化的掩码将经典卷积分为有效卷积和无效卷积,旨在处理图像修复结果颜色不一、模糊等问题.Yu等人[15]针对部分卷积在更新掩码的过程中的缺陷提出门控卷积,该方法通过手绘待修复区间的草图骨架信息来引导修复,但受边界草图的限制,导致修复结果具有局限性.Meng等人[16]利用密集卷积网络(DenseNet)中密集卷积块紧密连接的特性,在降低参数量的同时提取更多的特征信息,但对于纹理结构复杂的图像,修复结果仍有上下文不一致问题.
尽管生成对抗网络在图像修复领域得到了广泛的应用,但该类算法过于依赖生成网络的自生成能力,仍存在许多问题亟待解决.例如当数据集较小时,网络训练容易出现局部过拟合现象;使用人工交互式修复方法时,草图骨架的优劣极大的限制了修复结果,模型泛化能力较差;对于图像纹理结构较为复杂的图像,容易出现模糊、语义不连贯等现象.
针对上述问题,本文基于密集卷积网络[17]中密集卷积块能够加强特征传播、鼓励特征复用的特性,与注意力机制对图像细节修复的指导作用结合,提出一种结合SENet的密集卷积生成对抗网络图像修复方法.生成网络通过密集卷积块进行特征重用,加强特征传递,获取更深层的特征信息;使用池化层代替原有的过渡层,保留更多的有效特征信息;同时,引入SENet[18]中的SE(Squeeze-and-Excitation)模块注意力机制,增强重要特征在修复过程中的指导作用;此外,在编码器和解码器之间引入U-Net的跳跃连接[19](Skip connection),减少由于下采样造成的信息损失,并优化纹理一致性问题;使用MSE损失作为衡量生成图像质量的重要因素,联合MSE损失、对抗损失和总变分损失作为优化生成网络的总损失,进行模型训练.
2 相关理论
2.1 生成对抗网络
生成对抗网络[9](GAN)是Goodfellow等人在2014年提出的.近年来,生成对抗网络(GAN)作为一个热门课题人们已经进行了广泛的研究,并且在一些特定应用上与其它机器学习算法相结合,如半监督学习、迁移学习和强化学习,在图像修复问题上得到了广泛的应用[10-16].
GAN的核心思想来自于博弈论,网络通过生成器和判别器之间的互相欺骗进行优化,最终形成一个纳什平衡的状态.生成对抗网络由生成网络G和判别网络D构成,其结构如图1所示.生成网络G通过学习真实数据的概率分布Pdata映射生成类似真实数据的内容G(z).判别网络D需要尽可能的辨别出输入数据的来源,即对x和G(z)进行分类.当判别网络D无法区分数据来源时,网络达到最优,其目标函数见公式(1):
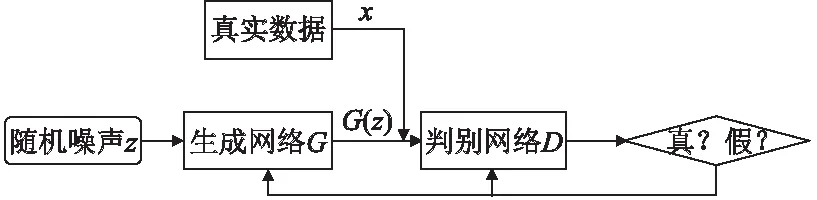
图1 GAN模型
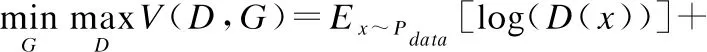
(1)
其中,G表示生成网络,D表示判别网络,E(·)表示数学期望,V表示目标函数,x表示样本,z表示随机噪声,表示真实样本的概率分布,表示生成样本的概率分布.
2.2 DenseNet模型
DenseNet[17]是一种具有密集连接结构的卷积神经网络.该网络由多个密集卷积块和过渡层构成,并且具有让网络更窄,参数更少的特性,这一优点很大一部分原因得益于密集卷积块的设计.在密集卷积块中,之前所有层的输出都是后面该层的输入,通过这种密集连接的形式能够提取更多的特征信息,其结构如图2所示.单个密集卷积块内,层与层之间使用正则化函数BN、激活函数ReLU和卷积函数Conv进行连接,增强结构的泛化能力.

图2 密集卷积块结构
2.3 Squeeze-and-Excitation模块
Squeeze-and-Excitation(SE)模块[18]能够获取特征信息的重要程度,以此来加强特征信息在图像修复法过程中的指导作用,其结构如图3所示.SE模块包括Squeeze和Excitation两个部分.Squeeze操作旨在用一个具有全局感受野的值来表示各个通道特征的重要程度,对每个通道做全局均值池化,得到一个具有全局感受野的特征图;Excitation操作使用全连接层作用于特征图,对每个通道的重要性进行预测,得到的重要程度权重再作用到相应的通道上,构建通道之间的相关性.
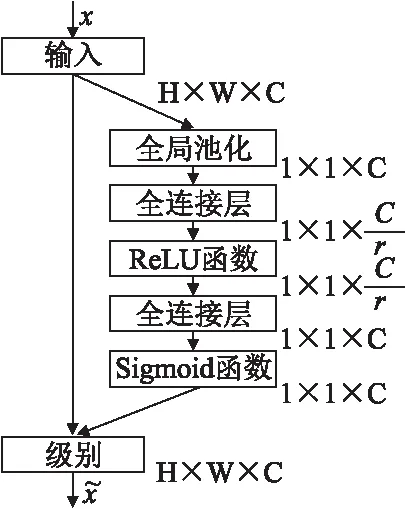
图3 SE模块结构
3 本文方法
现有的图像修复方法对于有较大面积缺失的情况,尤其是在数据集较小或者图像结构相对复杂的图像修复问题上,常出现模糊、伪影、图像语义不连贯等现象.为了更好的处理上述问题,缩短训练周期,提高模型的自生成能力,加强面部纹理细节的修复,本文利用DenseNet优秀的特征提取能力,并结合SE模块增强重要特征在修复过程中的指导作用,优化生成对抗网络的生成器,判别网络使用DCGAN框架进行改进,算法如图4所示.本文算法首先利用带有跳跃连接的编码—解码器对掩码图像提取特征和下采样,再根据重要特征生成与原始图像数据分布类似的输出结果;其次判别网络对结果进行二分类判别,通过不断对抗博弈进而优化网络参数;最后当模型达到稳定后,将对应缺失区域的生成图像填充到待修复的图像中获得修复结果.

图4 本文算法框架图
3.1 生成网络
生成网络G是模型的重要组成部分,该结构使用编码—解码器结构作为基本框架.编码器中使用4个密集卷积块对图像特征进行提取,块与块之间使用带有SE模块的池化层进行连接,SE模块获取各个通道特征的重要程度后,赋予通道权重系数;解码器同样包含4个密集卷积块,密集卷积块对特征进一步筛选,块与块之间使用带有SE模块的反卷积层进行连接,SE模块将筛选后的特征赋予通道权重系数后,传递给反卷积层用来恢复图像数据,解码器的最后一层使用一个1×1的卷积层对图像通道进行限制,最终获得与原始图像尺寸相同的修复结果.
此外,本文方法参考文献[16]在取消传统编码器和解码器之间全连接层的基础上进行改进,删除了密集卷积网络中的过渡层,块与块之间引入注意力机制加强重要特征的指导作用,同时在编码—解码器之间相同尺寸的位置引入U-Net的跳跃连接,减少由于下采样造成的特征丢失,增强网络的生成能力,其结构如图5所示.

图5 生成网络结构
3.2 判别网络
判别网络D是将输入图像进行分类的二分类器.其输入是64×64的真实图像和生成图像,经过4个步长为2,5×5的卷积核进行特征提取,卷积层之间都使用正则化函数BN和激活函数LReLU进行连接,最后一层使用一个线性全连接层进行二分类.判别网络旨在尽可能正确的判别输入图像来自真实图像或者生成图像,最终达到纳什平衡.
3.3 损失函数
损失函数设计是优化网络的关键.本文参考文献[10]的损失函数并在其基础上进行改进.
3.3.1 训练集损失函数
在训练过程中联合MSE损失、对抗损失和TV损失作为训练网络的总损失,提高网络稳定性和修复效果.总损失函数的定义如公式(2)所示:
Losstrain=λMSELMSE+λadvLadv+λTVLTV
(2)
其中,λMSE,λadv和λTV分别表示对应损失项的权重.
MSE损失通过提取的全局特征用来分析推断缺失区域的数据分布,保证整体结构的上下文语义连贯.MSE损失作为损失函数中最重要的组成部分,有效的反映了生成图像和真实图像的差距,其定义如公式(3)所示:
LMSE=(x-G(M⊙x))2
(3)
其中,G表示生成网络;x表示输入的真实图像;M是二进制掩码,值为0的部分表示缺失区域,值为1的部分代表保留区域;⊙代表对应元素相乘.
对抗损失用于加强生成网络和判别网络的博弈过程,旨在让生成图像的数据分布更接近真实图像,使得结果真实性更高.这里对抗损失采用判别网络的目标函数,其定义如公式(4)所示:
Ladv=log(D(x))+log(1-D(G(M⊙x)))
(4)
其中,D表示判别网络.
TV损失在图像修复过程中对图像的平滑度进行约束,改善缺失区域和已知区域叠加时出现的伪影问题,加强边界像素的视觉一致性,其定义如公式(5)所示:
LTV=∑i,j|Gi+1,j(M⊙x)-Gi,j(M⊙x)|
+|Gi,j+1(M⊙x)-Gi,j(M⊙x)|
(5)
其中,i和j表示像素点的坐标.
3.3.2 测试集损失函数
模型测试过程中,使用文本损失和先验损失的联合损失作为总损失,如公式(6)所示:
上博楚简是“上海博物馆藏战国楚竹书”的简称,记载内容主要以儒家类为主,在文字学方面有很大的研究价值。[1]本文主要参考李零先生所著《上博楚简三篇校读记》[2]展开相关讨论。《上博楚简三篇校读记》是以《上海博物馆藏战国楚竹书》第一册为研究对象(内含《子羔》篇“孔子诗论”、《缁衣》及《性情》三部分),李零先生对简文进行辨识分析,有助于我们更好地了解竹简原貌,并能够从中考察汉语史上语气词的使用及发展演变情况。
Lval=λcontextLcontext+λpriorLprior
(6)
其中,λcontext和λprior分别表示对应损失项的权重.
文本损失来自于真实图像和生成图像已知区域的不同,通过已知信息中的数据分布选择更真实的修复结果,其定义如公式(7)所示:
Lcontext=|M⊙G(M⊙x)-M⊙x|
(7)
先验损失是指基于高级图像特征表示的一类惩罚,而不是基于像素的差异,先验损失鼓励修复的图像与从训练集中提取的样本数据分布相似,其定义如公式(8)所示:
Lprior=log(1-D(G(M⊙x)))
(8)
4 实验结果与分析
4.1 数据集与运行环境
本文方法在CelebA数据集上进行模型验证.在CelebA数据集202599张名人人脸图像中随机选取20000张图像作为训练集;随机选取不同于训练集的1000张图像作为测试集.
实验计算平台为AMD R7 4800H CPU 8核16线程和NVIDIA GeForce RTX 2060 6G显存.软件环境为Windows 10,python3.7和TensorFlow v 1.14.
数据集选取中心感兴趣区域的五官部分,经过预处理后形成64×64的有25%中心缺失区域掩码和有约80%随机缺失区域掩码的训练集.实验在两个不同的训练集上迭代40个周期,时间各约10小时.由于设备内存限制,将batchsize大小设置为8.实验中参考文献[11]和文献[16]的建议,参数经过对比实验后选定λMSE=0.999,λadv=0.001,λTV=1×10-6,λcontext=1,λprior=0.003,网络使用Adam迭代器进行训练,学习率设置为2×10-4.
4.2 定性分析
由图6可知,CE算法修复结果图6(c)对于中心缺失区域图像,修复结果模糊,边界有轻微伪影现象,且有少量噪声点分布;对于随机缺失区域图像,眼睛和胡须位置无法保证较好的语义连贯.SI算法修复结果图6(d)对于中心缺失区域图像,虽然利用泊松分布技术解决了修复区域边界的伪影问题,但对于面部细节和眼镜遮挡问题未能得到很好的改善;对于随机缺失区域图像,修复结果模糊不清,且全局上下文一致性较差.DN算法修复结果图6(e)中心缺失和随机缺失虽能够基本恢复图像语义,但全局一致性不高,在眼球和鼻梁等语义细节问题上内容不够准确,缺乏真实性.本文方法修复结果图6(f)无明显模糊,基本没有伪影问题的出现,能够较好的保持图像的上下文语义连贯,而且对于第2、4行有物体遮挡面部的图像,模型仍然可以很好的恢复完整的语义信息.

图6 CelebA数据集上不同方法的修复结果
对比几类算法与本文方法的区别,SI算法过度依赖生成对抗网络的自生成能力,模型训练周期长,且对于面部的鼻梁、胡须等细节位置未能生成语义连贯的修复结果,当使用小数据集时问题更加明显.CE算法、DN算法和本文方法利用图像的已知信息学习真实图像的数据分布规律,但CE算法未能解决缺失区域边界的伪影问题和图像语义的噪声点问题;DN算法基本解决了伪影问题,并在修复效果上有所提升,但对于眼睛的宽窄、眼球的方向、鼻梁的高低等细节问题仍需改进,特别是对于有眼镜和帽子等类似的遮挡物时,修复结果一致性有待提升.本文方法引入密集卷积网络提取全局特征,并结合SENet的SE模块,更好的学习面部纹理细节的数据分布,可以看出本文方法在图像上下文一致、模糊和伪影等问题的处理上优于其他3种方法,修复结果视觉真实性较高.模型训练约40个周期达到稳定,相比较其他3类算法模型训练用时更短.
4.3 定量分析
除视觉定性分析外,实验还对模型修复结果使用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity Index,SSIM)两个指标进行定量分析.PSNR能够对图像的高频细节进行评价,值越大表示修复结果失真越小;SSIM能够反映两者的相似程度,取值在0~1之间,值越大说明修复后的结果与真实图像的相似度越高,即修复的效果越好.
由表1结果可知,将不同算法与本文方法在CelebA数据集上的修复结果分别在25%中心区域缺失和80%随机区域缺失实验中进行比较,所得结果的PSNR和SSIM均具有优势,与定性分析中修复结果的视觉对比一致.
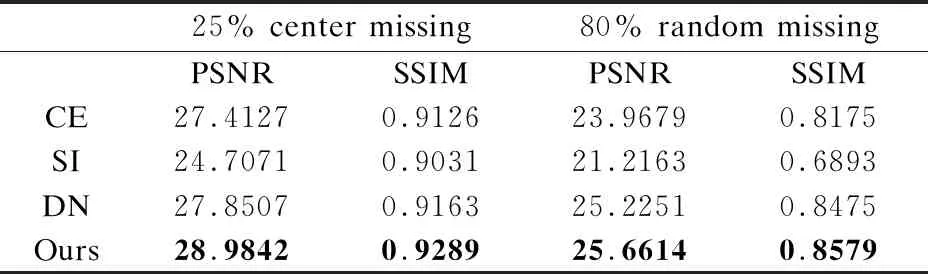
表1 不同修复方法的PSNR和SSIM
4.4 密集卷积块与SE模块的影响
为了证明密集卷积块与SE模块对图像修复的重要作用,在CelebA数据集上进行对比实验,结果如图7所示.图7(a)为原始图像;图7(b)为待修复图像;图7(c)为未使用密集卷积块和SE模块模型结构的修复结果,第1、2行修复区域边缘伪影问题严重,第3、4行生成的图像模糊不清,无法保持良好的上下文一致性;图7(d)为使用密集卷积块模型但未使用SE模块结构的修复结果,第1、2行修复后的图像基本能够恢复图像语义信息,但仍有模糊问题的出现,且对于第2行戴墨镜人脸问题上有语义缺失问题,图像上下文不连贯,第3、4行眉毛、眼眶和牙齿等细节仍有噪声点的出现;图7(e)为本文方法修复结果,SE模块对密集卷积块提取的浅层特征进行重要程度的划分,赋予特征通道权重指导图像修复过程,修复后的图像能够很好的保持全局一致性,且模糊、伪影问题基本得到解决,对于墨镜和侧脸结构性较强的图像细节也能很好的进行修复.

图7 不同结构的修复结果
表2列出了是否使用密集卷积块与SE模块模型的PSNR和SSIM在25%中心区域缺失与80%随机区域缺失的定量分析结果,可以看出本文方法充分利用了密集卷积块特征提取能力以及SE模块的指导作用,既能在定性分析中取得较大的优势,同时在PSNR和SSIM的数值对比上也取得了良好的分析结果.
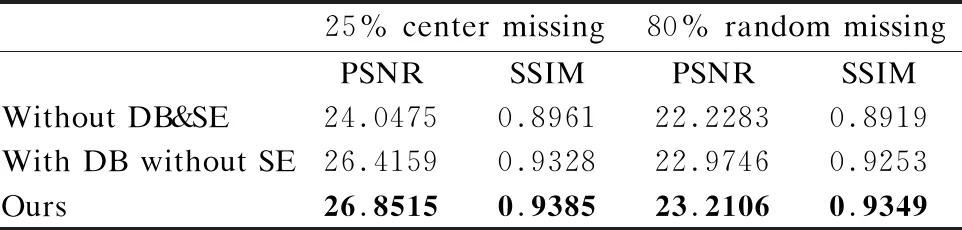
表2 不同结构的PSNR和SSIM
对比不同结构的修复结果发现,密集卷积块能够很好的学习图像全局语义信息,但对于部分细节修复上仍有不足.引入SE模块注意力机制后,修复结果在眉毛、眼睛、牙齿等细节得到改善,与PSNR和SSIM的数据分析结果一致.
5 结 语
本文提出了一个结合SENet的密集卷积生成对抗网络图像修复方法.该方法结合DenseNet中密集卷积块的特征提取能力与SENet中SE模块注意力机制,获取更全面的特征信息;在编码—解码器之间引入跳跃连接,弥补由于下采样造成的特征丢失问题;使用池化层代替密集卷积网络的过渡层,保证更多的特征信息进行传递;联合MSE损失、对抗损失和TV损失构建网络模型,提高网络的修复能力.本文方法通过在CelebA数据集上进行对比实验,在定性分析和定量分析中均优于CE、SI和DN这3种方法.但生成网络过强可能加剧梯度消失问题的产生,因此下一步工作需要对判别网络进行改进,以此应用于高分辨率图像的修复,维系生成网络和判别网络的动态博弈过程.
