增强边缘梯度二值卷积神经网络的人脸姿态识别
2022-05-10周丽芳
周丽芳,高 剑
1(重庆邮电大学 软件工程学院,重庆 400065)
2(重庆邮电大学 计算机科学与技术学院,重庆 400065)
3(三峡大学 湖北省水电工程智能视觉监测重点实验室,宜昌 443002)
1 引 言
人脸姿态识别作为人脸识别的一个主要分支,近年来得到了广泛和深入的研究,其中最常见的就是基于2D和3D的研究方法.2D方法包括:回归模型、虚拟视图重建、不变特征的提取;3D方法包含:基于像素的模型建立、基于标定点的模型建立.由于提取方式的不同,不变特征的提取又分为基于传统特征和基于深度学习的方法.局部二值模式作为一类有效的纹理描述方法被视为经典的传统特征广泛地应用于人脸姿态识别当中,近年来一系列局部二值模式(Local Binary Pattern,LBP)的拓展方法[1-6]被先后提了出来,包括:基于拓扑结构角度、编码角度、降噪角度、降维角度的扩展.这一类基于传统特征的人脸姿态识别存在特征维度过大、编码方式不鲁棒、对方向信息敏感等缺陷,依然是一个具有挑战性的项目.
深度学习在过去的十多年里取得了显著的成功,面向不同问题的模型[7-11]被先后提出.深度学习作为不变特征的一类有效提取方法同样被运用在人脸姿态识别中.由于深度网络中不同卷积核和偏置的存在,这种学习机制会导致基于深度学习的人脸姿态识别计算量庞大、内存开销大、易于过拟合.日常生活中的自动驾驶汽车、机器人、智能手机和智能摄像头和智能穿戴设备为了部署这种可训练卷积神经网络,也会面临这些问题.为了解决网络大模型化带来的缺点,一些用二值化权重取代实值权重的二值化版本神经网络[12-14]被提出,与实值权重网络相比在计算效率上有很大的提升.
为了让人脸姿态识别更好的提取图像边缘梯度信息同时规避传统方法和深度学习提取特征的缺陷,本文基于MGP(Modified Gradient Pattern)二值算子[15]和改进的DR-LDP(Dimensionality Reduced Local Directional Pattern)算子[16],提出了一种新的二值化卷积神经网络,如图1所示.所提网络结构主要分为3层,第1层ROILBC在LBC[17](Local Binary Convolution)的基础上增加了ROI(感兴趣区域)判断.MGP算子结合了局部邻域中心像素,网络第2层DR-MGPC将MGP和卷积神经网络结合并进行特征降维,很好的提取了人脸姿态图像边缘梯度信息.DR-LDP考虑了局部邻域方向响应值,网络第3层Enhanced DR-LDPC在DR-LDP的基础上提出增强DR-LDP并将其与卷积神经网络进行结合提取人脸姿态图像边缘梯度方向信息,一定程度上解决了人脸姿态识别对图像方向信息敏感的问题.本文提出的DR-MGPC和Enhanced DR-LDPC所提取的特征维度与传统二值模式相比,缩小了4倍(网络结构中池化层的作用),极大的减小了网络计算复杂度.ROILBC和Enhanced DR-LDPC运用了预先定义好的非学习的卷积核,在网络训练过程中极大的减少了参数量,解决了深度学习人脸姿态识别中计算量过大、易于过拟合的问题.传统二值模式只是简单的用局部邻域像素减去中心像素然后再用人为设定阈值的方法来对特征模式取值,本文所提网络结构用卷积神经网络来学习这个过程,有效的规避了基于传统特征的人脸姿态识别中编码方式过于简单、无法挖掘人脸姿态深度信息的缺陷.

图1 本文提出的二值化卷积神经网络结构图
2 ROILBC
ROILBC层运用改进的LBC在输入人脸姿态图像上提取深度局部二值特征并进行归类,根据深度二值特征图谱与输入人脸姿态图像的对比情况选择图像感兴趣区域,作为后续网络层的输入.和LBC不同的是:为了保留原始局部邻域灰度值,ROILBC采用权值为1的可变椭圆形卷积核.人脸重要组成部分(如眼睛、嘴巴)都是椭圆形结构,因此对于人脸图像来说椭圆形感受野具有更强的识别能力.ROILBC中使用tanh激励函数取代传统手工阈值的设定,提取的局部二值特征更加鲁棒.偏置bias的存在使得整个网络在反向传播过程中学习局部二值特征编码的过程.传统局部二值模式:
(1)
激励函数和偏置bias的存在,使得ROILBC中局部二值模式变为LBCP(Local Binary Convolution Pattern):
(2)
A为激励函数,b为偏置bias,pi为局部邻域像素且pc为局部邻域中心像素.
Ojala等人[18]提出统一局部二值模式(ULBP)只考虑了模式中0/1变换次数小于等于2的情况,忽略了模式中0/1变换次数大于4的情况.为了提升特征的鲁棒性并降低特征维度,冀中等人[19]提出增强局部二值模式(ELBP),对特征模式进行重新归类.具体如下:如果模式中0/1变换次数小于等于2,则各个模式单独归为一类,分为2+8×7共58种;如果模式中0/1变换次数等于4,根据包含1的个数进行归类,将包含1的个数相同的归为一类,共5种;最后将模式中0/1变换次数大于4的归为一类,最终形成的特征维度为58+5+1共64维.
与ULBP、ELBP不同,本文通过直观的数据对比,不同模式特征图谱与输入图像的对比情况来对0/1跳变次数进行归类.首先通过对CAS-PEAL-R1姿态数据集进行实验分析可得:LBCP特征中0/1、1/0跳变次数为0和8的模式只占总模式的0.09%和0.1%,跳变次数为6的模式占3.85%,跳变次数为2和4的模式分别占比64.68%和31.28%,其它跳变次数占比均为0.通过不同跳变次数模式特征图谱与输入人脸姿态图像的对比复原分析,跳变次数为2和4的模式对比原图复原情况比较清晰.按照文献[19]将跳变次数为2和4的特征模式按照其中包含1的个数相同的归为一类.其中,跳变次数为2的情况下包含1的个数为3、4、5的模式下对应特征图谱刻画出输入人脸姿态图像的主体框架.同样跳变次数为4的情况下包含1的个数为3、4、5的模式下对应特征图谱刻画出了原图主体轮廓.
综合以上分析最终将跳变次数为2包含1的个数为3、4、5的各个模式单独归为一类(每个模式由于1出现的位置不同又分为8种情况),分为3*8共24类.将跳变次数为4包含1的个数为3、4、5的各个模式单独归为一类共3类,最后将跳变次数大于4的归为一类,最终形成的特征维数为24+3+1共28类.和文献[19]相比特征维度从64维减少到28维,特征维度减少到一半,极大的减小了网络的计算复杂度.传统LBP中跳变次数为0的模式占总模式的10%,LBCP中只占0.09%是因为ROILBC层中偏置bias的存在,导致局部邻域中心像素和邻域像素的灰度值发生了一定的偏置而最终的二值编码相应的发生了变化.
将跳变次数为2包含1的个数为3、4、5的模式统称为CMT(Convert Mode Two),将跳变次数为4包含1的个数为3、4、5的模式统称为CMF(Convert Mode Four),跳变次数大于4的模式统称为CMO(Convert Mode Others),将以上模式的特征图谱交叉融合作为输入人脸姿态图像的感兴趣区域ROI,也就是ROILBC层的输出RFMi(ROILBC Feature Map,i=1,2,…,9):
RFMi=α{β[LBCP(X)]}
(3)
α为特征图谱交叉融合操作,β为特征模式归类操作,X为网络输入人脸姿态图像.RFMi由CMT中任意组合的2种模式和CMF中任意组合的2种模式加上CMO融合而成.CMT占输入图像信息的60%(除去边、角模式)、CMF占30%(除去边、角模式),CMO占3.85%,最终每一个RFMi都能捕获到输入人脸姿态图像信息的65%.传统卷积神经网络经过第一层的卷积后只能采集到输入图像的边、角、轮廓信息,远远达不到本文65%这么大比例的信息,这也是本文ROILBC层将传统二值模式与卷积神经网络结合的优势之处.
3 DR-MGPC
传统人脸姿态识别没有考虑人脸姿态图像的局部边缘梯度信息,因此识别效果有一定的局限性.传统二值模式的编码角度扩展中,有一系列方法就考虑了图像局部邻域边缘梯度信息.首先Jun与Kim提出了LGP算子[20],其基本思想是通过局部梯度进行定义如公式(4)所示:
gi=|pi-pc|
(4)
在LGP的基础上,Choi与Kim进一步提出了MGP算子,MGP首先定义了局部邻域像素灰度与局部邻域像素灰度均值的差异mi,然后以该差异的均值为阈值将局部邻域进行二值化.其次基于MCT(Modifies the Census Transform)变换[21],MGP算子将中心像素与邻域像素一同考虑进行局部二值编码,其定义如公式(5)所示:
(5)
图2给出了在人脸姿态图像瞳孔边缘局部时LGP与MGP编码的对比,从图2可以看出,由于MGP在进行阈值设定时考虑了加入中心像素的邻域灰度均值,所以MGP更好地描述了局部邻域的梯度变化信息.为了进一步说明该问题,图3给出了采用不同阈值时局部邻域边缘梯度提取效果的对比,可以看出同时考虑了中心像素与邻域平均像素时边缘梯度提取的效果最好.

图2 MGP与LGP编码对比

图3 采用不同阈值的局部梯度提取效果对比

(6)
上式中A代表激励函数,⊗代表卷积操作.ROILBC层的输出RFMi作为DR-MGPC层的输入,通过卷积、特征下采样(Average Pooling)操作得到DR-MGPC层的输出DR-MFMi(Dimensionality Reduced MGP Convolution Feature Map),其过程如公式(7)所示(K=5,DR表示特征下采样):
(7)
DR-MGPC层的输出DR-MFMi即提取包含图像降维边缘梯度信息的特征图谱,如图4(右图为左图局部放大效果)所示.可以明显看出眼睛、鼻子、嘴巴的边缘梯度信息已经被提取出来,在一定程度上说明DR-MGPC层充分地发挥了MGP的特点(将邻域中心像素一同进行特征编码,可以有效的提取图像边缘梯度特征).特征下采样算法中kernel size取2×2将提取特征维度缩小4倍,有效的减轻了网络的计算复杂度.

图4 DR-MGPC层提取特征图谱
4 Enhanced DR-LDPC
2010年,Jabid等人[5,6]提出了LDP(局部方向模式)特征描述方法,这种方法类似于LBP编码方法,也为图像的每个像素分配一个8位的二进制编码,但进一步结合了边缘特征的方向性,将图像的边缘信息融入所提取的特征中.对于局部方向模式,在描述图像特征时,往往将图像划分为若干块,然后将不同分块的特征进行级联作为最终的图像特征,从而导致图像特征维数较高.为此,Sriniva等人提出DR-LDP算子,其基本流程是:首先按照LDP的方法得到LDP编码图像;其次,将LDP编码图像划分为3×3的邻域;最后将邻域内LDP值通过XOR编码转换为一个值,从而得到最终的编码.DR-LDP的基本原理是在LDP的基础上降低了图像分辨率.
Enhanced DR-LDPC层运用卷积神经网络操作取代Kirsch掩模卷积方式得到不同方向的响应值,LDP中Kirsch掩模为3×3大小的8个不同的方向,Enhanced DR-LDPC中将其拓展到可变形椭圆patch的16个不同的方向.所以在Enhanced DR-LDPC中LDP被重新定义为ELDP(Enhanced LDP),构造ELDP算子的基本步骤如下:
1)针对3×3的局部邻域,首先将该邻域分别与Kirsch模板(16个方向)进行卷积运算,得到16个方向的边缘响应值;每个边缘响应值分别体现了在不同方向上的重要性,在所有方向上的边缘响应值的重要性并不等同.
2)构造原图像的ELDP编码图像.对原图像中的每个像素点对其16个方向的边缘响应值进行排序,将边缘相应绝对值排名前K位所在方向的二进制编码设置为1,其余(16-K)方向的编码设置为0.若相邻两位响应值的编码相同则设置编码1,不相同设置编码0,从而构成了8位的二进制编码,称为ELDP编码.
3)将ELDP编码图像的直方图作为原图像的ELDP特征.Kirsch模板包含了16个不同方向的边缘梯度检测信息,这16个不同方向的掩模算子集合为{M0,M1,…,M15}.16个Kirsch掩模分别表示16个方向所对应的16条边,东向、西向、南向和北向分别对应直线边,其余方向分别对应折线边.应用16个掩模对图像块进行卷积运算,我们可以获得中心像素的16个边缘响应值{m0,m1,…,m15}.基于该16个响应值,ELDP的定义如公式(8)所示:
mi=I⊗Mi
(8)
上式中,⊗表示卷积,⊙表示判断编码是否相同,mi表示与Kirsch模板第i方向卷积运算后得到的边缘梯度,{|m0|,|m1|,…,|m15|}表示边缘响应值的绝对值,|mK|表示|mi|中第K大的边缘响应值.
利用Kirsch掩模对图像邻域进行卷积运算,每个像素被分配一个8位的二进制编码.与LBP算子不同的是,ELDP在LBP的基础上融入了边缘梯度方向信息,ELDP主要从方向性角度入手,不仅解决了LBP对中心像素点绝对依赖的不足,还能充分利用各邻域像素之间的相互关系.相比LBP算子,ELDP算子对姿态、光照、表情和遮挡等噪声影响的鲁棒性更好.实验表明加入卷积神经网络和增强到16方向的Kirsch掩模使得最终提取的边缘梯度方向信息更加具有鲁棒性.由于Kirsch掩模在文中被增加到16个方向,所以本文实验统一取K=8.与DR-LDP不同的是本文采用下采样(Average Pooling)对提取的边缘梯度方向特征进行降维,由于kernel size为2×2,所以提取的特征维度缩小4倍,减轻了网络的计算复杂度.DR-MGPC层的输出DR-MFMi作为输入,经过卷积提取增强边缘梯度方向特征ELDP、特征下采样进行降维,得到最终的特征图谱EDLFM.其过程如公式(9)所示(DR表示降维操作):
EDLFM=DR[ELDP(DR-MFMi)]
(9)
5 实验及结果分析
5.1 实验环境和数据描述
硬件环境:64位ubuntu16.04操作系统、Intel i9处理器、64GB内存和双Geforce RTX2070 SUPER GPU的计算机.
开发环境:PyCharm.
编程语言:Python.
FERET数据集:FERET数据集为美国国防部发起为了促进人脸识别算法的研究和实用化.数据集包含994个个体的不同姿态的11338张面部图片.
CAS-PEAL-R1数据集:CAS-PEAL-R1数据集为中国先进人机通信技术联合实验室的CAS-PEAL人脸数据集的子集,数据集包含1040个个体的30900张照片,每一个个体有21个不同人脸姿态的图片,除此之外,还包含表情、穿戴物、光照不同影响因数的照片.
5.2 实验设置
由于CAS-PEAL-R1姿态数据集分为两部分(偏转角度不同),所以本文在该数据集上进行两次实验.实验1将CAS-PEAL-R1姿态数据集前101个个体的姿态图片按偏转角度进行实验,实验2将后939个个体的姿态图片按偏转角度进行实验.本文将实验1的前71个个体设置成训练集,后30个个体设置为测试集.将实验2的前639个个体设置成训练集,后300个个体设置成测试集,每个实验的训练集与测试集的比例为7:3.实验3在FERET数据集上按照人脸姿态图片的偏转角度进行实验.为了探究网络的训练效果,本文将超参数Batch Size和Epoch取不同值时识别精度的结果如图5所示.
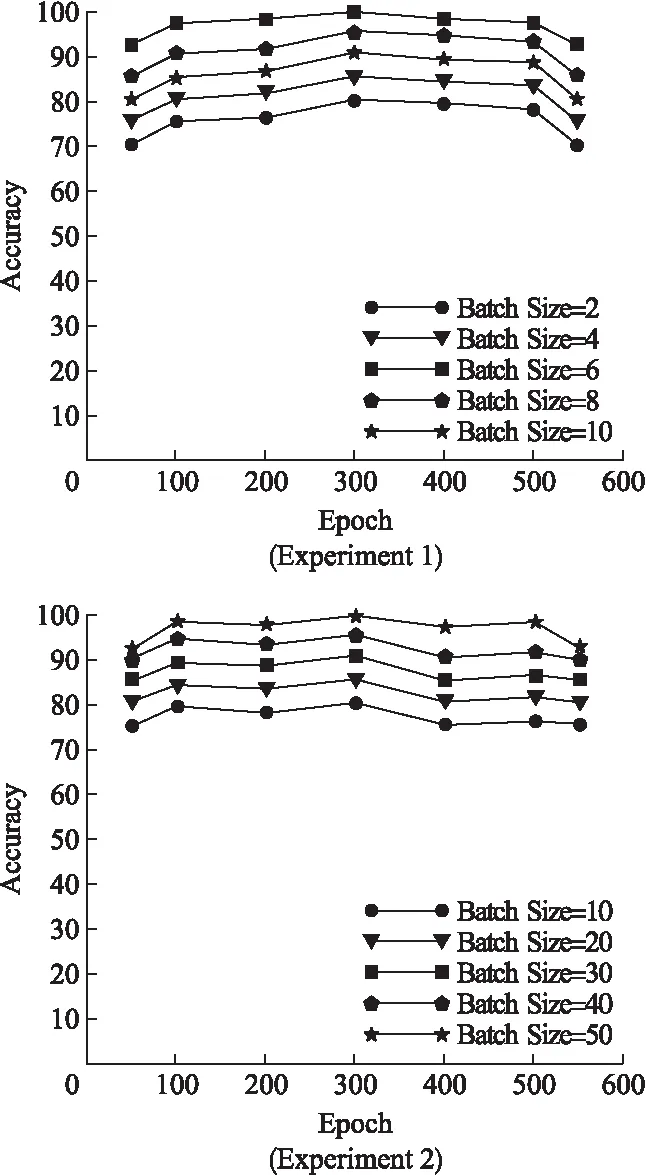
图5 实验1、2超参数取不同值时识别率
从图5可以看出实验1中Batch Size取6、Epoch取300的时候识别精度最高,实验2中Batch Size取50、Epoch取300的时候识别精度最高.
5.3 实验结果及分析
实验1的识别效果如表1所示,本文除了直方图相似度来衡量识别精度,还用到了常态分布比对的巴氏距离法、卡方检验作为衡量依据.实验1在Batch Size取6、实验2在Batch Size取50时随着Epoch的增长其卡方距离的变化情况如图6所示.从图6可以看出随着Epoch的增长其卡方距离在逐渐减小,说明网络学习到了不同人脸姿态间的差异,并通过随机梯度下降法反向传播来减小这种差异.

表1 实验1识别精度
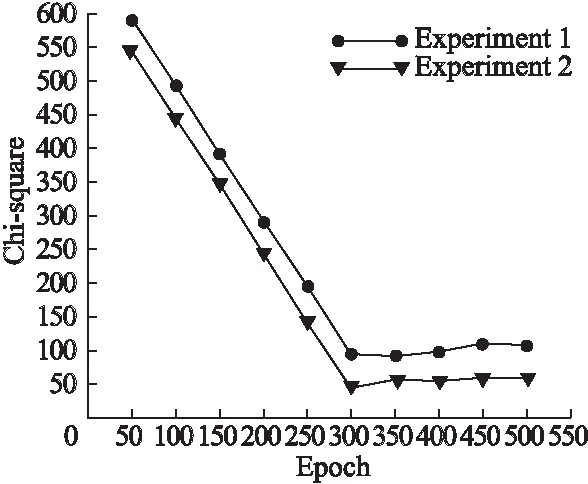
图6 实验1、2中卡方的变化情况
将不同姿态图片经过本文所提网络卷积计算后所得EDLFM特征图谱进行全连接,再进行欧氏距离计算并作为整个网络结构的误差损失函数如公式(10)所示:
Err=Euc[Fcn(EDLFM1),Fcn(EDLFM2)]
(10)
实验1在Batch Size取6、实验2在Batch Size取50时随着Epoch的增长其欧式距离的变化情况如图7所示.通过图像可以看出欧式距离在逐渐减小,从一定程度上说明面网络学习到了不同姿态人脸图像的区别并进行误差反向传播.
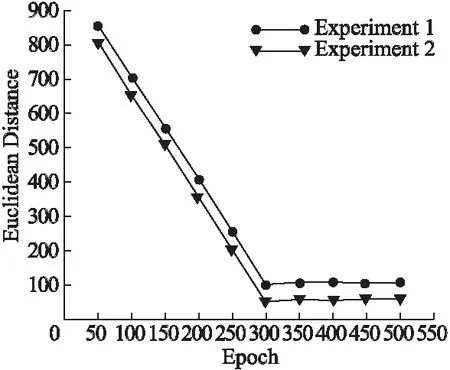
图7 实验1、2中欧式距离的变化情况
文献[17,22-26]没有很好的提取图像边缘梯度特征.为了验证本文所提二值卷积神经网络能够有效地提取人脸姿态图像边缘梯度信息,同时有效地规避传统二值模式与卷积神经网络的缺陷,实验2、实验3本别在CAS-PEAL-R1数据集和FERET数据集与上述所提方法进行对比,对比情况如表2、表3所示.从表2和表3可以看出:传统方法中Huffman-LBP识别效率和运算效率是最好的,p-CNN多任务学习的机制导致各个模块相互促进使得在深度学习方法当中表现最好.基于深度学习的方法由于提取特征更全面,普遍比传统方法表现优异,将二者结合的方法表现最好.本文所提方法结合传统与深度学习来提取特征,ROILBC层和Enhanced DR-LDPC层使用了预定义非学习卷积核使得训练单张图片与其它方法相比耗时最短.除了计算复杂度有所减少,识别精度和其它方法相比也是最优异的,尤其是在大姿态偏转角度时.
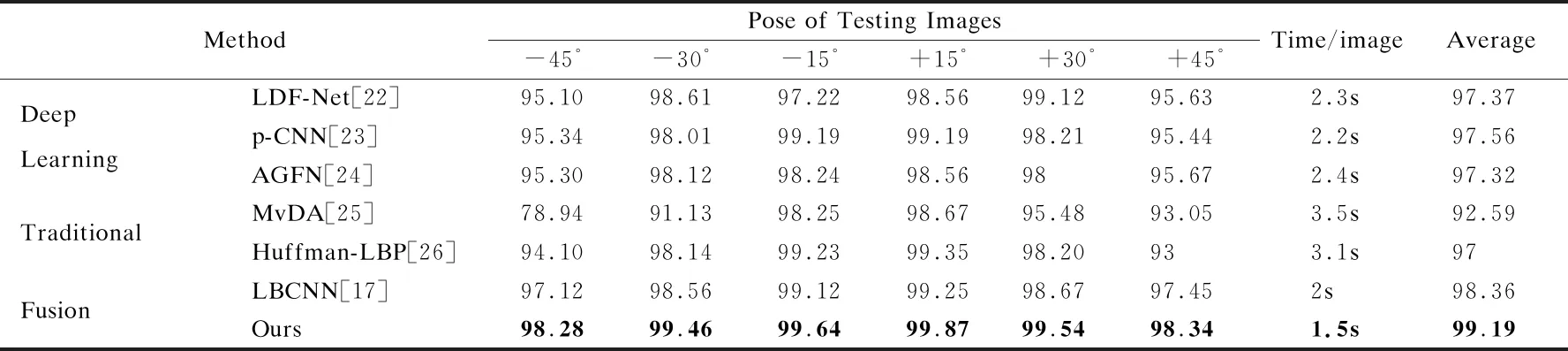
表2 本文所提方法和其它方法在CAS-PEAL-R1数据集上的实验对比

表3 本文所提方法和其它方法在FERET数据集上的实验对比
6 总 结
本文在提取特征时考虑了图像边缘梯度信息,利用传统二值特征的特点构造了一系列预定义非学习的卷积核,减轻了网络计算复杂度.将传统二值模式与深度学习结合提高了特征编码的鲁棒性,同时提高了人脸姿态识别的识别精度和计算效率.目前关于二值模式与深度学习结合的研究还处于探索阶段,本文为该方向提出了一种高效、可行的研究方法.
