MIKU:融合知识图谱的用户多层兴趣模型
2022-05-10段文菁续欣莹岳晓冬刘笑笑
段文菁,谢 珺,续欣莹,岳晓冬,刘笑笑
1(太原理工大学 信息与计算机学院,山西 晋中 030600)
2(太原理工大学 电气与动力工程学院,太原 030000)
3(上海大学 计算机工程与科学学院,上海 200444)
1 引 言
互联网的飞速发展使得信息过载问题亟待解决,个性化推荐作为大数据时代的产物,依据海量的用户行为数据深入挖掘有效信息,满足不同用户的需求,凭借其显著优势受到研究者的青睐,被广泛应用于视频、电商以及新闻等领域.
个性化推荐的核心任务是匹配目标用户的需求,用户兴趣建模作为推荐系统的基础,其构建至关重要,能否建立准确、高效的用户模型决定了个性化推荐的效果.早期的推荐算法以协同过滤[1]为代表,依据群体的历史反馈信息与相似性关系,发掘用户的潜在喜好.随着推荐技术的不断发展,深度学习以其高效的计算能力与优越的可扩展性,迅速在推荐领域占领一席之地,取得了诸多有重要意义的研究成果[2].然而大多算法仅依靠历史交互信息作为输入,交互行为的稀疏性严重制约了用户兴趣的表征,且存在明显的冷启动问题,使得个性化推荐模型有一定的缺陷.
为解决上述局限性,研究者考虑引入不同的辅助信息来提高推荐性能,如用户项目属性[3,4]、评论文本[5]及社交信息[6]等.近年来,以知识图谱为辅助信息的推荐算法,不仅能够提高推荐的精确度,同时为推荐结果提供一定的可解释性,具有重要的研究意义和价值[7].项目端的知识图谱融合多源异构数据,细粒度地刻画项目特征,突出了项目之间的语义联系,同时利用其独特的结构知识,便于挖掘到用户的深层兴趣.然而项目端知识图谱,仅补充了项目的知识,对于无交互历史的新用户,仍存在一定局限.用户的属性信息是其自身的固有信息,相较于历史交互而言,更加稳定且不随时间变化.研究表明[8],用户属性信息中隐含一定的兴趣偏好.融合用户的属性信息不仅可解决用户冷启动问题,在一定程度上可提高推荐系统性能.融合了知识图谱与用户属性信息的结构图如图1所示.通过用户点击的电影记录在项目端知识图谱上链接到其深层的偏好,如电影类型、主演、导演等.

图1 融合知识图谱与用户属性信息的结构图
综合上述分析,本文提出一种融合知识图谱的用户多层兴趣模型(Multi-layer User Interest Model Based on Knowledge Graph,MIKU),该模型以项目端知识图谱和用户属性为辅助信息,从行为兴趣和用户属性两方面对用户建模.由于用户的历史交互仅代表其直接偏好,未展现出用户深层的兴趣点.为了充分挖掘用户的深层兴趣,本文利用知识图谱的结构知识,将用户的行为兴趣分为浅层兴趣与深层兴趣,以用户的历史交互项目为浅层兴趣,历史项目通过图谱的关系路径链接的相关实体作为深层兴趣.由于用户对候选项目兴趣受其历史行为的影响,具有多样性和动态性,采取以不同的加权机制自适应地计算用户对直接行为以及其深层兴趣点的兴趣权重.考虑到新用户在系统中尚未产生历史交互行为,无法分析其行为兴趣,本文综合了用户的多层兴趣与属性特征,全面分析用户特征对其建模,进而生成推荐.在公开的MovieLens-1M数据集上验证,实验结果表明,融合了知识图谱与用户属性的MIKU模型在推荐精度等指标上均有显著提高.
本文的主要贡献:
1)结合项目端知识图谱和用户属性信息,利用知识图谱的结构知识,挖掘用户深层兴趣.同时融合用户固有属性,从多层行为兴趣与用户属性角度全面深入挖掘用户的偏好,提高推荐的精准度,改善了用户冷启动问题.
2)采用不同的自适应加权机制,分别从用户行为对浅层兴趣及深层兴趣建模,有效提取用户交互级别的动态偏好,刻画了用户兴趣的多样性.
2 相关工作
2.1 用户兴趣建模
用户兴趣模型的构建是推荐算法研究的基础,能否获取较为准确的偏好信息是提高推荐精确度的关键.传统的协同过滤算法认为,具有相似行为的用户拥有相近的兴趣,利用项目评分信息计算两用户的相似度.随着数据的不断增长,用户和项目的数据量极为庞大,用户真正有过行为的项目寥寥无几,评分矩阵稀疏,不能很好地表示判定用户间的相似度.近年来,研究者从不同角度引入各种技术方法更深一步探索推荐问题[9-14].文献[9]结合SVM与因式分解模型,旨在解决数据稀疏情况下的特征组合问题,但却忽略了用户的历史行为乃其兴趣的最直观表现;文献[12]利用用户的行为序列挖掘用户的兴趣,以其历史点击项目平均加权作为用户的兴趣表征;文献[13]引入注意力机制为历史项目分配不同的权重加权,表征用户兴趣的多样性.然而交互行为的稀疏性仍制约着用户兴趣的表征,且信息结构单一,无法挖掘到用户深层的兴趣,对于无用户交互记录的新用户,无法给出合理的推荐.结合了辅助信息的推荐系统,可有效解决以上缺陷.文献[14]采用改进的K-means聚类方式对用户属性特征聚类,从相似度角度结合用户属性和用户偏好,缓解冷启动问题的同时,提高了推荐效果.
2.2 融合知识图谱的推荐算法
以知识图谱为辅助信息的推荐系统一般分为基于路径的方法与基于嵌入的方法.基于路径的方法利用图谱的网络结构,构建项目之间的元路径特征.文献[15]引入基于meta-path的隐含特征,来代表用户和项目在不同路径上的连通性.文献[16]将知识图谱视为特殊的异构信息网络,引入加权元路径的概念,针对不同路径的重要程度赋予相应的权重.而基于嵌入的方法[17]侧重于利用知识图谱的结构信息丰富项目或用户的表征.文献[18]通过TransR知识嵌入算法获取实体的语义表示,进而获取更好的物品潜在表示.文献[19]为了弥补一般的实体嵌入独立于推荐任务,将知识嵌入与推荐作为两个交替的任务共同优化,进行多任务推荐.然而这两类方法各有缺陷,基于路径的方法很大程度依赖于预定义的元路径,可扩展性不强.基于嵌入的方法未充分利用图谱的结构关系,缺乏推理能力,忽略成对实体之间关系的语义.文献[20]提出了涟漪网络,首次将基于路径与基于嵌入的方法结合,通过知识图谱探索用户兴趣偏好的传播过程,取得了显著成效,然而该算法仅关注用户的传播偏好,忽略了其历史点击项目以及属性特征对于兴趣建模的重要性,存在一定不足.
本文提出的算法以项目端的知识图谱与用户属性信息为辅助信息,结合基于嵌入与基于路径的推荐算法,既丰富了物品之间的语义关联,又可自动获取路径中的实体联系.利用知识图谱的结构知识挖掘用户的兴趣点,从用户行为中分析其浅层兴趣和深层兴趣.考虑到用户兴趣的多样性,通过对历史行为和知识图谱中的深层兴趣点自适应加权以获取用户的兴趣表征.同时为改善冷启动问题,结合用户的属性信息,有效弥补了用户端的特征信息不足,改善了推荐系统性能.
3 融合知识图谱的用户多层兴趣模型
3.1 相关定义及问题描述
表1给出本文使用的相关符号.

表1 符号标识及说明
定义1.用户-项目交互矩阵Y={yuv|u∈U,v∈V},U={u1,u2,...}和V={v1,v2,...}分别表示用户和项目的集合.
(1)
其中yuv=1表示用户u和项目v之间存在隐式反馈,例如点击、观看、浏览等行为;
定义2.存在知识图谱G,由大量的实体关系三元组(头实体,关系,尾实体)组成(记为
定义3.用户u的历史交互项目集为:δu={v1,v2,...,vNi};
定义4.以用户u的交互项目相关实体集为:εu={et|(eh,r,et)∈G,其中eh∈δu};
定义5.用户u的相关三元组集为:Su={(eh,r,et)|(eh,r,et)∈G,其中eh∈δu}.

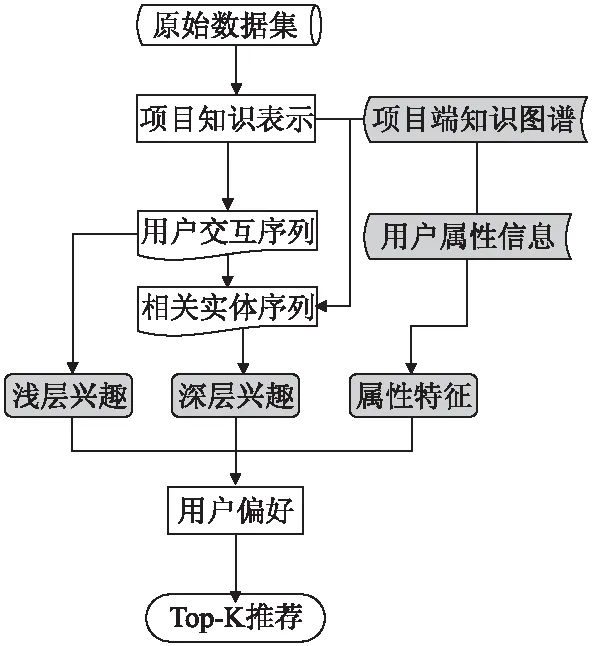
图2 MIKU模型总体流程图
3.2 融合知识图谱的用户多层兴趣推荐算法


图3 MIKU的整体模型图
3.2.1 用户浅层兴趣建模
给定用户u的点击记录δu,由于项目与知识图谱的实体相匹配,对于每个项目vi(i=1,2,...,Ni)通过知识表示学习得到对应的向量表示vi∈d,其中d为向量表示的维度.
为了对用户u的兴趣建模,一般直接平均其点击过的项目特征,为所有历史项目分配统一的权重,如公式(2)所示:
(2)
然而,用户对项目的兴趣是多样化的,考虑到若用户的历史点击中存在较多与候选项目相似的物品,则可认为该用户对候选项目感兴趣程度越大.因此,本文采用自适应加权机制,计算各个交互项目与待推荐项目之间的相关权重,按此权重对各个历史项目的向量进行加权求和,动态刻画用户的历史兴趣.
具体为,以候选项目表示vj∈d为基础,为用户u交互历史项目集δu中每个 vi分配不同的权重并加权平均,获取用户的浅层兴趣表征uH:
(3)
其中αi为自适应加权的权重因子,给定项目vi和vj利用函数H1通过内积形式拟合二者之间的相关性,并通过softmax函数将相关性转化为权重因子:
(4)
3.2.2 用户深层兴趣建模
知识图谱中包含了丰富的实体信息,利用不同实体之间的关联可以挖掘用户的深层兴趣,例如用户m点击过电影vm是由于他对该电影主演感兴趣,为了充分挖掘用户的深层兴趣,本文利用知识图谱的结构知识,以用户历史交互项目通过知识图谱的关系路径,链接到相关实体,挖掘用户对相关实体的深层兴趣.考虑到用户在不同关系下的兴趣度不同,提出基于知识路径加权的用户深层兴趣建模,刻画用户直接点击的历史项目通过在关系路径传递至其相关实体的兴趣.
给定知识图谱G,以用户u的历史点击项目δu为头实体,沿着知识路径链接得到相关实体εu以及历史项目的三元组集Su,通过内积函数H2计算候选项目vj与三元组(ehi,ri,eti)在关系ri下与头实体ehi的权重因子βi:
(5)
其中ri∈d×d为关系ri的张量表示,ehi∈d为项目vi所匹配的头实体的向量表示.通过计算Su中所有三元组的相关权重因子,对于用户链接到的相关实体以对应的概率进行加权求和,从而表征用户的深层兴趣uT:
(6)
3.2.3 用户属性建模
传统推荐只考虑用户-项目评分交互的关联,忽略了用户本身的属性特点.本文综合考虑了用户属性特征和用户兴趣特征,更完善地表征用户,可提高推荐准确率同时有效解决了用户冷启动问题.
属性特征作为用户本身固有的信息,在用户无交互记录时,可作为依据有效表征用户.表2列出MovieLens-1M的用户信息中前5行数据,性别2类,年龄7类,职业21类,具体信息以数值表示,表2中第一行userID为′1′,性别′F′代表女性,年龄′1′代表年龄小于18岁的用户,职业′10′代表该用户为学生.
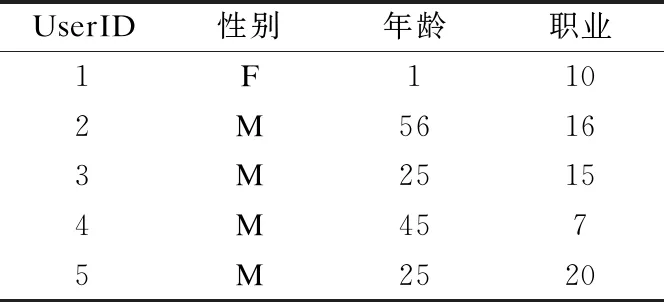
表2 用户属性信息
为了提取用户的属性特征,本文通过用户属性建模,首先将属性信息进行数值化处理,例如把用户性别为′F′映射为1,′M′映射为0.将处理后的数据通过one-hot层转换为稀疏向量,考虑到one-hot类型的特征太过稀疏,会导致网络参数太多,且特征长度不一,不利于后续特征的融合.本文利用嵌入层,以属性特征的稀疏向量表示uage,ugender,uocc作为输入,将其压缩成统一长度的低维稠密向量,最后通过全连接层映射函数Z将不同特征映射至与用户兴趣特征同一隐空间,用户属性特征表示uP为:
uP=Z(uage,ugender,uocc)
(7)
3.3 模型优化
通过对用户的浅层兴趣和深层兴趣建模,同时融入了用户属性特征,可得到用户向量表征u:
u=uH+uT+uP
(8)

(9)
其中σ(x)=(1+e-x)-1为sigmoid函数,an表示神经网络中第n层的激活函数,Wn和bn分别为第n层的权重和偏置.
模型损失函数如公式(10)所示:
(10)
在公式(10)中,第1项为推荐中用户-项目交互行为的预测概率和真实标签之间的交叉熵损失,其中F为交叉熵函数,第2项计算了利用语义匹配模型[21]学习得到实体和关系表征与知识图谱G中的关系为r的示性函数Xr之间误差的平方;最后一项是防止过拟合的正则项,λ1为知识图谱正则项权重参数,λ2为L2正则项参数.
4 实验过程和结果分析
4.1 实验数据集
为测试模型的有效性,本文利用MovieLen-1M电影数据集(1)http://grouplens.org/datasets/movielens/对提出的方法进行验证.MovieLens-1M是推荐领域广泛使用的基准数据集,包含943位用户对1682部电影共计100多万条显示评分数据,电影属性数据以及用户的人口统计学数据(年龄、性别和职业等).考虑到用户的点击历史行为更容易收集,本文将显式评分转化为隐式反馈数据,以用户评分过的电影为正样本,随机采样用户未评分过的电影集合为负样本,对于每个用户而言,正负样本之比为1∶1.
本文使用文献[20]提供的微软Satori知识图谱,以电影关系筛选出符合条件的所有三元组(head,film.film.name,tail),将MovieLens-1M中的电影ID与知识图谱中的头尾实体ID相匹配,构成最终的电影知识图谱,其中涉及的电影及知识图谱数据统计如表3所示.
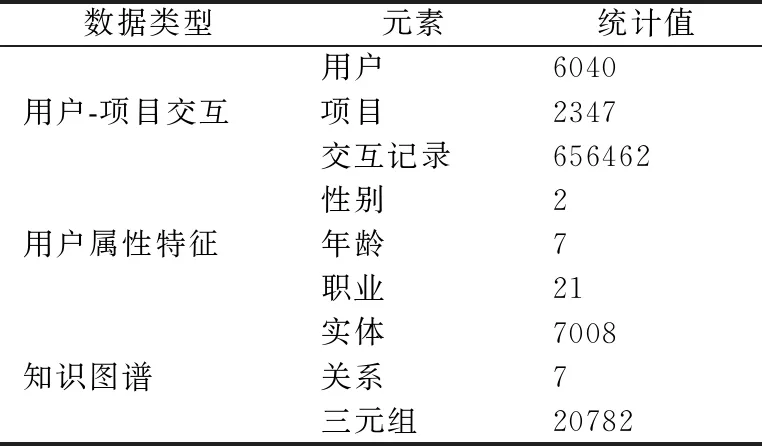
表3 实验数据统计
4.2 实验评价标准
对于推荐系统算法推荐的结果,本文采用3个指标对其进行分析:准确率Precision@K、召回率Recall@K以及综合指标F@K,其中K为推荐的个数.
(11)
(12)
其中R(u)表示根据用户在训练集上的行为给用户做出推荐列表,T(u)表示用户在测试集上的行为列表.
准确率和召回率作为推荐评价的重要指标,相互制约影响,可利用F@K作为二者的调和均值综合评价:
(13)
参数μ表示准确率在评价标准中的重要性,取值范围为[0,+∞),实验中常使用μ=1.
4.3 实验方案设计与结果分析
本文模型采用离线实验,将MovieLens-1M数据集以6:2:2的比例划分训练集、验证集和测试集,每个实验重复5次,取最终的平均结果.实验主要在Top-K推荐场景中,使用学习到的模型为每个测试集中的用户选择前K个预测概率的物品作为推荐结果,利用准确率、召回率和F1值验证本文模型的有效性.
为了验证MIKU模型的有效性,本文使用了如下的基准方法:
LibFM[9]:基于潜在特征因子的矩阵分解模型,本文将用户和物品的原始特征以及依据知识表示方法学到的实体向量作为模型输入;
PER[15]:引入基于meta-path的隐含特征,来代表用户和项目在不同 路径上的连通性;
CKE[18]:结合多源辅助信息的协同过滤方法,从知识库中学习项目的语义表示.本文中仅使用结构化的知识作为输入,无图片和文本知识;
MKR[19]:以知识嵌入任务来辅助推荐任务的多任务特征学习方法;
RippleNet[20]:将用户兴趣类比于“涟漪”扩散,模拟用户兴趣在知识图谱上的偏好传播模型.
模型中涉及到的相关参数如表4所示,为了公平考虑,所有对比基线方法的参数均设置相同.

表4 相关参数
4.3.1 相关参数验证
为了研究向量表示的嵌入维度d和知识图谱正则项权重λ1对推荐结果的影响,实验中分别选取d的变化范围为4-64,λ1的范围为0.001-0.01,保持其他参数不变进行验证,实验结果如图4所示.
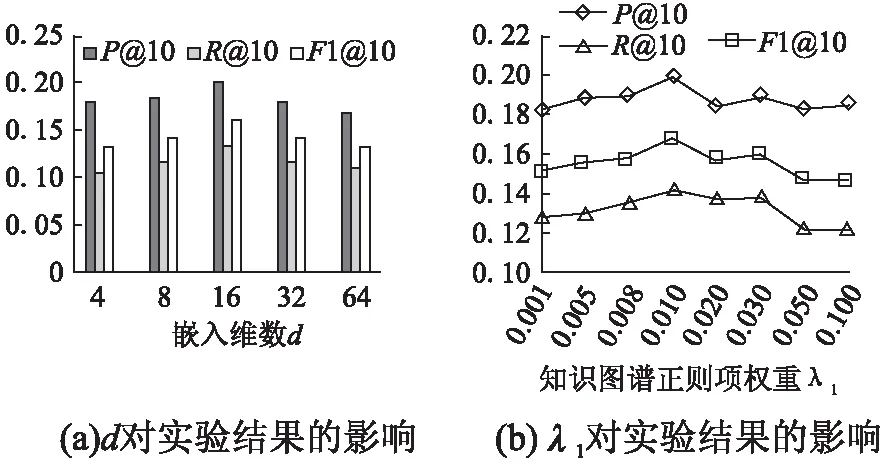
图4 相关参数验证结果
由图4(a)可看出,当推荐个数取K=10时,随着嵌入维度d的增加,准确率 、召回率及F1值都逐渐上升,这是由于维度的增加可使得特征向量编码获得更多有用的信息.然而当嵌入维度大于16之后,时间复杂度大大增加,且模型训练过拟合,3个指标均有所下降.从图4(b)可看出,当λ1=0.01时,该模型效果最佳.由于知识图谱正则项过小无法为模型提供足够的正则化约束,权重过大则会使得目标函数更侧重于知识图谱的优化,导致推荐效果变差.
4.3.2 模型消融实验
为了讨论用户不同模块兴趣对推荐结果的影响,本文使用消融实验,将模型拆分为浅层兴趣、深层兴趣、浅层兴趣与深层兴趣结合3个模块,以不同模块作为用户表征,与MIKU模型进行对比验证,推荐项目的个数K分别取1,2,5,10,20,50,100.图5中的(a)、(b)、(c)分别为不同K值下的准确率、召回率以及F1值变化.
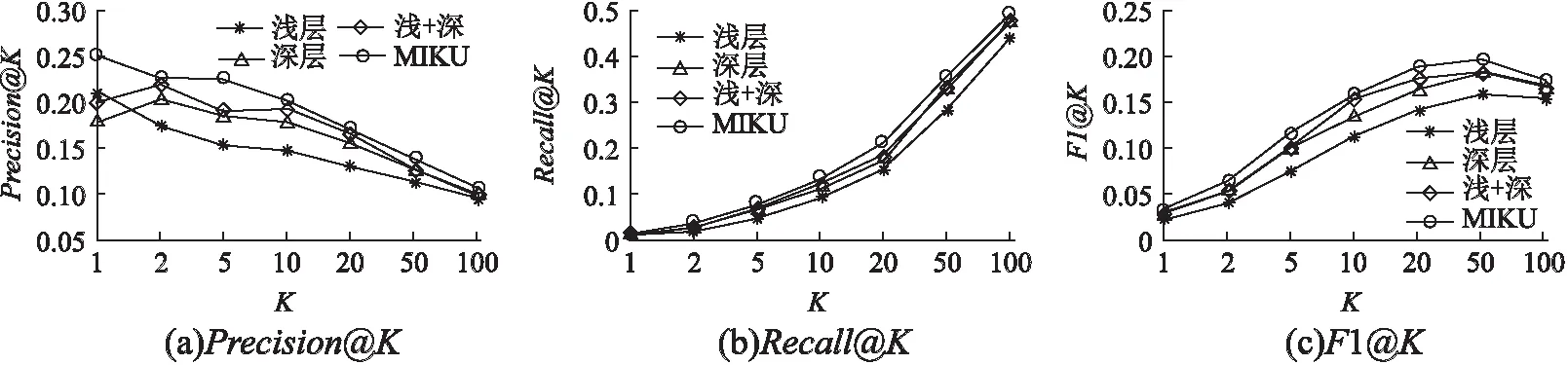
图5 不同K值下的准确度、召回率及F1值
当K=10时,实验结果如表5所示,可以看出利用知识图谱结构信息挖掘的深层兴趣对召回率有明显改善;结合浅层兴趣与深层兴趣,相对于单独模块而言,在3个指标下结果均有提升推荐效果;加入属性信息的算法,在推荐个数较少时,准确率明显提升,说明属性特征的融合,在一定程度上可改善推荐精度.总而言之,综合用户浅层兴趣、深层兴趣与用户属性的MIKU模型,在各个指标上均优于独立模块,有效改善了推荐性能.
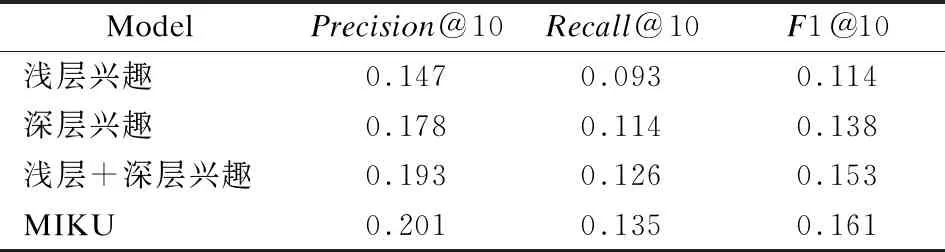
表5 模型内部消融实验结果
4.3.3 不同模型对比
MIKU模型与其他基准模型对比结果如表6所示,为了综合分析模型,取推荐个数K=10.
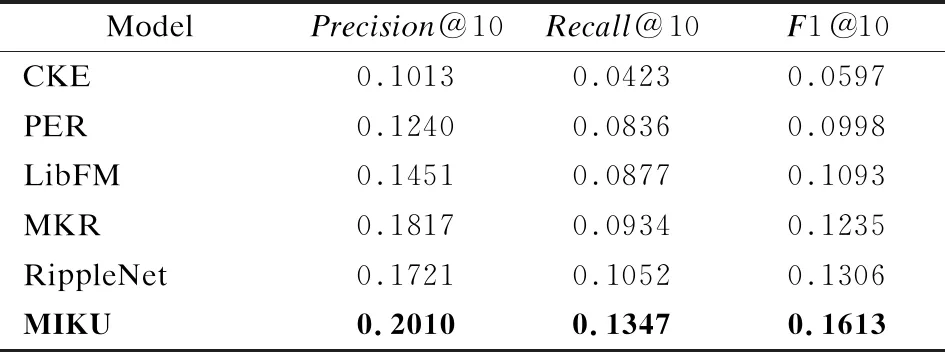
表6 不同模型对比结果
通过观察表6分析可知,CKE由于缺少文本和图像的信息,仅依靠结构化知识提取的特征信息不足以充分刻画物品特征,结果表现最差;PER由于预定义的元路径很难达到最优,相对其他融合知识感知推荐模型而言,结果较差;LibFM作为一种通用的推荐算法,结合了知识图谱中的语义信息表现较好,表明有效利用知识图谱中的知识可提高推荐模型的性能;MKR模型利用多任务学习共享信息,有效提升了推荐性能;RippleNet模型相对于其他模型而言有很强的表现,表明有效利用知识图谱的结构信息对于推荐而言至关重要;本文模型综合3个指标性能提升了约1.9%~3.07%指标,证明了MIKU模型结合知识图谱的语义信息与结构知识,同时融合用户属性特征,全面刻画用户模型,有效提高了推荐结果.
4.3.4 不同生成推荐方法对比
为了进一步研究,利用神经网络学习用户项目之间的复杂关联对推荐结果的影响,本文在生成推荐过程中,使用多层感知机代替用户与项目特征的简单内积来计算预测的点击概率,结果如表7所示.

表7 不同生成推荐方法对实验结果影响
由表7可知,对于融合了多层行为兴趣与用户属性的MIKU模型而言,利用神经网络作为最终的概率预测,便于学习到用户和物品之间复杂的非线性关系,更能挖掘到用户对项目的深层偏好.
5 结束语
本文提出了融合知识图谱的用户多层兴趣模型,为全面刻画用户兴趣,从用户固有属性与交互行为分析用户偏好.一方面以知识图谱为物品侧信息,细粒度描述物品特征,刻画了物品之间的语义联系.另一方面考虑到知识图谱的结构性,通过不同的关系路径自动链接用户的深层兴趣.以用户历史行为的浅层兴趣与用户的深层兴趣结合,深入挖掘交互行为中的兴趣偏好.同时结合了用户属性特征的推荐算法,有助于提高推荐性能,在一定程度上可弥补用户冷启动的缺陷.在今后的工作中,将考虑融合时间因子,从时间层面和兴趣深度两个角度全面刻画用户兴趣,进一步提升推荐系统性能.
