使用词对齐半监督对抗学习的汉越跨语言摘要生成方法
2022-05-10余正涛黄于欣
王 剑,张 莹,2,余正涛,2,黄于欣,2
1(昆明理工大学 信息工程与自动化学院,昆明 650500)
2(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
自动文本摘要技术是一种从海量文本中获取重要信息的方法,可以有效缓解信息过载的问题.当前针对中、英等资源丰富语言的单语摘要研究已经取得较好的性能,如Xu等人提出利用卷积自注意力编码的自动摘要模型,根据上下文的局部和全局特征,从不同角度和不同层面提取文本潜在信息,确保模型生成正确流畅的摘要,Wu等人针对事件摘要任务引入Bigram语言模型对提取关键词进行语义扩展得到事件相关的摘要信息.
跨语言摘要是用目标语言来展示源语言新闻的摘要信息,如利用汉语来摘要和展示越南语新闻中的重要信息可以帮助用户快速获取越南语新闻描述的主要内容,对于促进两国交流具有重要意义.目前针对跨语言文本摘要的方法主要有两种:借助机器翻译的管道式方法和借助双语对齐的端到端方法.基于机器翻译的管道式方法的研究动机是:将跨语言自动摘要分为单语言摘要和机器翻译两个步骤,可以先翻译再摘要或先摘要再翻译两种模式.Anton[1]等人通过机器翻译系统将印地语原文档翻译成英语,再利用一个基于英文的多文档摘要和标题生成的交互式系统实现跨语言摘要生成.Wan[2]等人先利用单语摘要方法生成源语言文本摘要,再利用机器翻译生成目标语言摘要.然而,虽然基于机器翻译的跨语言摘要方法可以利用单语的摘要和机器翻译模型,但它受到两个独立子任务的误差累积的影响,前一步骤的误差会影响后一步的性能,制约了摘要的质量.为了避免误差累计的影响,Duan[3]和Ayana等人[4]提出联合优化机器翻译和摘要模型,实现了zero-shot的跨语言摘要.其核心思想是构造翻译到摘要或者摘要到翻译的线性系统,使用现有摘要数据集训练教师模型,为跨语言句子摘要模型提供监督信号,同时还利用目标输入句作为中间桥梁,利用两个方向的注意力权重来指导摘要生成.
上述跨语言摘要方法的研究主要集中在中英等资源丰富语言的研究上,拥有大规模的公共数据集和平行语料可供使用,且翻译技术相对成熟,翻译质量较高,因此基于机器翻译的跨语言摘要可以取得较好的效果.但是针对汉越等资源稀缺语言缺乏高质量的平行语料,翻译效果并不理想,因此依赖机器翻译来实现汉越跨语言摘要较为困难.近年来,也有一些学者提出了基于双语对齐的端到端方法生成跨语言摘要,其思想是借助双语词典和注意力机制来实现双语语义空间软对齐,然后基于序列到序列模型直接生成跨语言摘要.Zhu等人[5]首次提出直接利用Transformer框架来生成跨语言摘要.即直接输入源语言原文解码得到跨语言摘要,利用编码器到解码器的交叉注意力来实现两种语言的对齐.另外该文也验证了基于多任务框架,在共享编码器的基础上,在解码端引入单语摘要或者机器翻译任务作为额外的约束可以有效的提升跨语言摘要的生成质量.后续研究中,Zhu等人[6]进一步改进翻译融入的方式,通过将神经网络模型与外部概率双语词典相结合来提高跨语言摘要性能,其具体过程是:将跨语言自动摘要分解为3个步骤:聚焦(attend)、翻译(translate)和归纳(summarize),具体实现过程为:首先通过注意力机制对原文包含的重要内容词进行聚焦,并得到这些关键词的翻译候选,最后依据翻译候选或者神经概率分布生成摘要.虽然已有的基于双语词对齐的跨语言摘要方法在深度学习框架下取得了很好的性能,但是汉越属于低资源语言,语料资源稀缺,仅依赖基于注意力机制的软对齐方法来实现两种语言的语义空间对齐难度较大.因此本文提出借助双语词典作为外部知识,利用双语词向量对抗训练的方法将汉越双语映射到同一语义空间实现更好的双语对齐,并在此基础上实现跨语言摘要生成.
基于以上思想,本文提出了一种基于词对齐的半监督对抗学习汉越跨语言摘要生成的方法,首先利用Bert编码器分别对输入的汉越文本进行向量表征;然后基于汉越双语词典的半监督对抗学习方法,实现双语词向量在同一语义空间对齐;最后基于注意力机制同时关注双语上下文向量,解码得到目标语言摘要.
2 基于词对齐的半监督对抗学习汉越跨语言摘要模型
如图1所示,本文基于编码器和解码器构成的序列到序列框架(sequence-to-sequence,seq2seq)摘要[7]框架提出的一种跨语言摘要模型,并且在seq2seq模型的基础上增加了一个汉越双语词级映射器以实现双语在同一个语义空间对齐.其中,左右两边分别为越南语编码器Vi_Bert[8]和中文Zh_Bert编码器负责将输入的汉越新闻文本进行向量表征;mapping映射器由鉴别器Diss,Dist和生成器Gens,Gent构成,其任务是将编码器生成的向量映射到同一语义空间下对齐;解码器负责对映射后的向量解码得到跨语言摘要.以越南语为源语言,中文作为目标语言的跨语言摘要任务为例,模型生成摘要的过程是:首先,我们使用编码器获取越南语和中文新闻文本的上下文表示;然后使用映射器将越南语向量映射到中文向量空间下,判别器和生成器共同作用得到生成器生成同一语义空间下的对齐向量;最后,中文解码器对映射向量进行解码生成中文摘要.

图1 基于词对齐的半监督对抗学习汉越跨语言摘要模型图
2.1 编码器
svi=vi_Bert(xvi)
(1)
tzh=zh_Bert(xzh)
(2)
2.2 基于双语词典的半监督对抗学习
经过Bert编码器产生的文本词向量分别为中文和越南语新闻的文本表征,需要实现两种向量在同一语义空间下对齐,将其结果作为解码端的输入.为实现该目标,我们提出借助汉越双语词典的半监督对抗学习的方法,其过程如下:
预训练阶段,首先利用包含L=30000的{si,ti}i∈(1,2,…,L)汉越双语种子词典,训练映射矩阵W:
Ω=‖Ws-t‖2
(3)
其中,s为双语词典的源语言词向量,t为对应的目标语言词向量,Ω表示正则器,用于强制表达式两边的相等性.我们使用随机梯度下降学习W,然后通过最小化经过W转换的源语言单词si的向量表征与双语词典中的目标语言ti之间的平方欧氏距离,来实现双语词向量在同一语义空间下的映射对齐.假设源语言为越南语s,目标语言为中文t,则由越南语映射到中文的映射矩阵为Ws→t.同理可得中文映射到越南文的矩阵为Wt→s.
联合训练阶段,用Bert编码器得到越南语和中文的词向量svi和tzh来训练学习的映射矩W*:
(4)
(5)
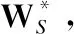
最后,如图2所示,将生成器生成的映射后的越南语向量和中文向量同时提交给判别器来预测每个单词的来源.在这个过程中来优化判别器Diss和Gens:
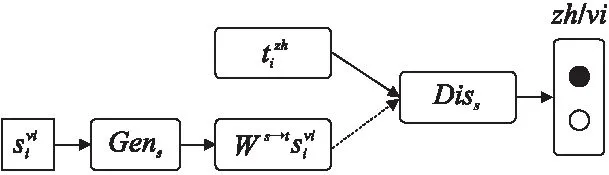
图2 双语词向量对抗训练模型图
(6)

判别器Dist和生成器Gent同理可得:
(7)
训练时,生成器和判别器采取交替训练,即先训练Diss和Dist,然后训练Gens和Gent,不断往复.
2.3 解码器
解码器部分,Masked Multi-head attention中的mask表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果.这一部分的attention计算公式为:
(8)
其中,Q,K,V对应的query,key,value均来自前一层decoder的输出向量.
编码器和解码器通过交叉注意力连接.多头注意力将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来,有助于网络捕捉到更丰富的特征/信息.多头注意力通过点积注意力模块实现,encoder-decoder attention计算方式为:
multihead=contact(head1,head2,…,headi)Wo
(9)
(10)

(11)
除了注意力机制子层之外,解码器的每一层都包含一个完全连接的前馈网络.前馈神经网络模块由两个线性变换组成,中间有一个ReLU激活函数,其对应计算公式为:
FFN(x)=max(w1x+b1,0)w2+b2
(12)
其中,x表示输入序列,w1,w2,b1,b2是需要学习的参数.
2.4 摘要损失计算
进行单语训练时,给定一对越南语文本摘要对(xvi,x′),实验过程中进行最大对数似然率计算,其摘要损失值Lsumms和Lsummt计算公式为:
(13)

(14)
进行跨语言摘要任务训练时,假设给定一对越南语新闻文本和中文参考摘要对(xvi,y′).则其跨语言摘要的损失函数Lclss和Lclst计算公式为:

(15)
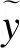
(16)
2.5 模型训练
预训练阶段:进行单语摘要模型和映射器的预训练.首先使用一定数量的越南语和中文新闻语料,分别进行两种语言的单语摘要模型训练.摘要生成模型均采用BertSum[10],经过单语预训练得到的摘要模型,transformer解码器会对两种语言有一定的学习记忆,有利于对映射后的向量解码.然后利用双语词典预训练得到两个映射矩阵W.

表1 模型训练过程伪代码
联合训练阶段:在预训练得到的摘要模型上进行双语映射和跨语言摘要任务的联合训练.如表1所示模型联合训练过程伪代码.
3 实 验
3.1 实验数据
首先我们获取了Hu等人[11]从新浪微博中抽取的LCSTS数据,该语料主要来自于新浪微博.每条语料均由两部分内容构成:短文本内容以及对应的参考摘要.而越南语语料则通过将已获取的LCSTS语料集借助谷歌翻译工具来得到伪平行语料.其中训练集有20万对伪平行语料,测试集有1000对伪平行语料.另外,还借助了互联网爬虫技术从中国新闻网、新华网、新浪新闻等国内新闻网站,以及越南每日快讯、越南经济日报,越南通讯社等越南新闻网站收集新闻,收集的数据包含新闻标题、正文详情、发布时间等信息.获得了2000篇越南语新闻以及对应的10000篇中文可比语料.我们对越南文档使用VnCorenlp(1)https://github.com/vncorenlp/VnCoreNLP进行预处理[12],包括文档切分、分词等过程.对中文文档使用结巴分词进行数据预处理,包括文档切分、分词、去停用词等步骤.
虽然目前还没有汉越双语词典可供使用,但是Facebook muse(2)https://github.com/facebookresearch/MUSE在进行110种语言训练词对抗模型时提供了约含76000个词对的英越双语词典.目前针对中英翻译的效果已经十分成熟,于是我们选择了将英越词典中的英语词表调用谷歌翻译接口将其翻译为中文.并对一词多义和低频词进行了去除处理,最终得到了3万对汉越种子词典.
综上所述,GDM双胎妊娠属于高危妊娠。加强GDM双胎妊娠的管理,控制血糖,选择合适的分娩方式,做到早发现、早应对,进而改善围产结局。
3.2 参数设置
我们使用基于PyTorch的OpenNMT[13]框架,将Bert超参数与文献[10]中的BERT-Base作相同设置.我们模型中编码器是单语预训练的BertSum,解码器是随机初始化的6层Transformer.对于编码器和解码器,使用Adam优化器[14],β1=0.9,β2=0.999,学习率设置为lr=2e-3.将batchsize设置为36,epoch大小设置为8,每3个steps进行一次梯度累加,每1000步保存一次检查点,一共训练20000个steps.在验证阶段对于每个验证步,实验数据迭代100次,并在测试集上报告平均结果.
3.3 评价指标
本文采用摘要任务中广泛使用的ROUGE[15]分值作为评估指标,其工具包已被DUC和TAC等国际会议作为摘要体系的标准评价工具,用于预测生成文本和标准文本之间的接近程度.具体地说,摘要质量将依据模型预测生成的摘要与标准摘要的重叠单元进行量化计算,公式如下:
(17)
其中n代表n-gram的长度,countmatch(n-gram)是模型生成摘要和人工书写的标准摘要中共同出现的n-gram的数量,公式旨在通过计算与参考摘要重叠的系统生成摘要中的n-gram的百分比来衡量系统生成摘要与参考摘要的匹配程度.本文将采用ROUGE评价指标N元共现统计ROUGE-1,ROUGE-2以及句子中最长公共子序列共现统计ROUGE-L,前者预定义n-gram的长度,后者使用最长公共子序列直接进行匹配,因此它自动包括最长的顺序共现,在一定程度上反映了句子结构信息.
3.4 实验结果
3.4.1 不同摘要方法对比实验
为了验证提出的模型在跨语言摘要任务上的性能,本文列举了不同模型在本文收集数据集上的对比实验,结果如表2所示.其中,Pipe_TS方法表示的是先进行原文本翻译,再进行单语摘要任务;Pipe_ST方法表示的是先进行单语摘要,再将生成摘要翻译为目标语言的结果;NCLS[5]方法表示的是借助注意力机制实现双语对齐实现跨语言摘要生成方法;XML_R是一种基于大规模数据的预训练方法[16],能够将不同语言映射在统一的语义空间.和Vi_BERT和ZH_BERT相似,XML_R表示利用XML_R模型作为嵌入层,即将Vi_BERT和Zh_BERT替换为XML_R.Ours为本文提出来的方法.从表2中可以看出,本文提出的基于词对齐的半监督对抗学习跨语言摘要生成模型在越南语到汉语的跨语言摘要生成上,能够有效改善跨语言摘要生成性能,ROUGE值在对比实验方法的结果上都有接近两个百分点的提升,但是在汉语到越南语的跨语言摘要生成效果上略逊于XLM.其可能原因如下:当前基于小语种的翻译技术尚未成熟,对较长的文本进行翻译会造成信息损失,而在源语言上使用基于半监督对抗学习得到的映射矩阵能够在一定程度上保存文本信息,有助于获取文本摘要的高阶特征,这些特征可指导摘要生成中对原文中特定内容的选择.
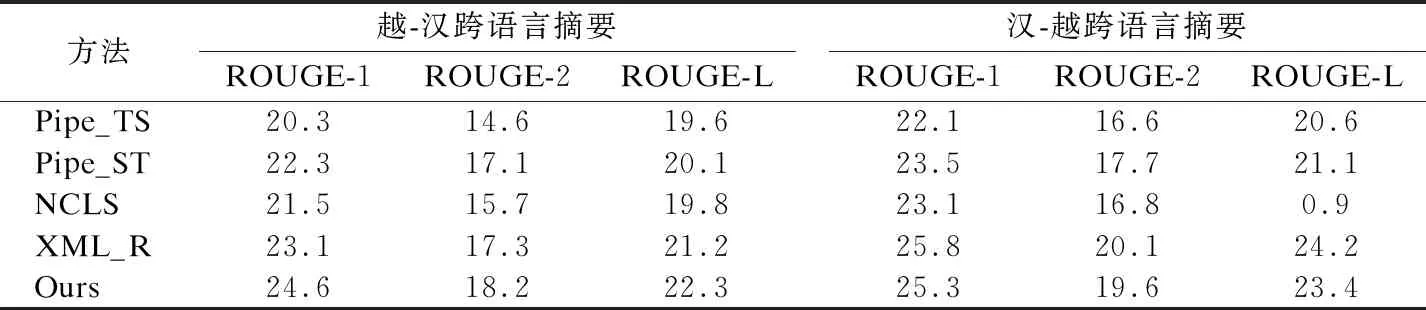
表2 不同摘要生成方法对比实验结果
3.4.2 不同规模词典的对比实验

表3 针对不同规模词典的摘要实验结果
表4为不同实验设置下的消融实验结果.其中,No_vocab_CLS表示不使用双语词典进行双语对抗训练的摘要结果,No_pretrain_CLS表示不进行模型预训练,直接进行跨语言摘要联合训练任务.由表4可以看出,本文提出的基于词对齐的半监督对抗学习跨语言摘要生成方法效果明显高于另外两种方法.其可能原因是:无双语词典的对抗学习对抗时双语对齐效果较差,影响摘要结果.模型不能很好地从小规模文本摘要数据集学习一些单词和语法的含义,尤其是那些低频词,这可以通过预处理阶段来缓解.

表4 消融实验结果
3.4.4 摘要案例分析


表5 管道翻译方法和本文模型摘要结果案例
4 总 结
本文针对越南语这一低资源语种的跨语言摘要的任务,通过利用双语词典来提高模型对两种语言的学习能力,引入双语词向量进行对抗学习来实现双语在同一语义空间对齐.实验结果表明,这种方法能够提升低资源的跨语言摘要效果.在未来的研究学习中,我们将继续探索汉越双语之间更好的对齐方法,结合多语言BERT以及多语言BART等模型来实现跨语言摘要任务,提高跨语言摘要性能.
