基于Bi-LSTM+Attention公共安全危机识别
2022-05-09王志晓李卓淳闫文耀
王志晓,李卓淳,闫文耀
(1.西安理工大学 计算机科学与工程学院,陕西 西安 710048;2.陕西省网络计算与安全技术重点实验室,陕西 西安 710048;3.延安大学 西安创新学院,陕西 西安 710100)
0 引 言
公共安全危机包括人为灾难、自然灾难、社会安全事件和公共卫生事件。这类事件危害公共安全和社会秩序,造成公众生命财产严重损失,公众心理失衡,紧张和恐慌。因此快速准确识别此类事件可以最大程度地减少损失,保障社会稳定。近年来,社交媒体已成为一种人人都能分享事件和向公众宣传故事来提高认知的工具[1],因此利用社交媒体来自动监测公共安全危机变得尤为有效。由于社交媒体在信息传播中的优势,其用途越来越广泛,例如在洪水、地震、海啸等灾难期间的危机准备,响应和恢复,但是尚未意识到社会媒体识别和提供家庭暴力受害者即时支持的潜在好处[2]。
家庭暴力(domestic violence,DV)是女性受伤的主要原因之一,受害者通常不仅遭受身体虐待,而且遭受性,情感和言语虐待。这个问题在世界范围内普遍存在,目前有不少国家和组织创建了家庭暴力危机服务(DVCS),以提供服务的组合,例如危机热线,咨询,倡导和紧急庇护给DV受害者。但是,受害者往往不能有效地利用服务,因为它们需要积极寻求这种支助。社交媒体的可用性使DV受害者可以分享他们的故事并获得整个社会的支持,这为DVCS提供了一个主动接触和支持DV受害者的机会。
该文以公共安全危机中的家庭暴力危机为研究对象。目前而言在中国国内,几乎没有这方面的研究,虽然有很多基于深度学习框架下的课题和研究,但在识别家庭暴力这个方向上,还鲜有突破。在国外,关于DV的研究也是近五年才慢慢开始并逐渐增多的,主要是大学的研究机构和大型社交媒体公司如Facebook、Google等在进行研究。通过收集社交媒体上的信息,用经过相关训练的模型即可推断出哪些人可能正在遭受家庭暴力。除此以外,还有一些社会非盈利组织推出了家庭暴力咨询服务(DVCS),它们通过开发相关APP来识别用户社交媒体上的帖子或动态,判断该用户是否正在遭受家庭暴力或可能将会被家暴。但这类APP很多存在窃取用户隐私、识别不准确等缺点,因此目前许多机构致力于如何更好地定义和更快更准确地发现日常生活中的家庭暴力危机进行研究。总体而言,家庭暴力危机识别的研究这几年已经有明显上升趋势,越来越多的研究者致力于用深度学习的方法去识别DV危机,改善受害者生活。
因此,该文主要完成了以下几类工作:(1)从Facebook上获取家庭暴力受害者发出的帖子,将它们按是否存在家庭暴力危机的标准分类,有则标记为1,无则标记为0,并将它们清洗,做文本预处理;(2)采用Word2Vec生成词向量模型;(3)采用CNN、RNN、LSTM和Bi-LSTM+self-Attention四种深度学习方法对数据集训练生成自动识别家庭暴力危机模型;(4)保存模型与history,对模型训练过程绘图并评估各模型表现;(5)简述主要的研究内容。
1 相关研究
1.1 深度学习
深度学习是人工智能和机器学习研究的最新趋势之一,同时它也是现在最流行的科学研究趋势之一。深度学习方法为计算机视觉和机器学习带来了革命性的进步。新的深度学习技术正在不断诞生,不断刷新最先进的机器学习和现有的深度学习技术纪录。近年来,全世界在这一领域取得了很多关键突破[3]。
有两种主要的深度学习架构,即卷积神经网络(CNN)和循环神经网络(RNN)。两种模型都把序列中的单词嵌入作为输入,输出单词的实值和连续特征向量。 CNN已应用于句子级别的问题和情感分类,与传统的机器学习技术相比,它们表现出更高的性能。而RNN可以对文本序列建模,对多任务学习提升较大[4]。目前RNN有很多改进版本,例如长短期记忆网络(LSTM)、门控循环单元(GRU)和双向LSTM(Bi-LSTM),由于它们具有的长期依赖性和能随时间存储历史信息而广泛用于NLP领域。目前深度学习技术已应用于检测关于歧视和仇恨言论,商品评价,情感分析等方面。
总的来说,深度学习(DL)比以往任何时候都更快地推进了世界的发展,但仍有许多方面值得研究。人们仍然无法完全理解深度学习,如如何让机器变得更智能,更接近或比人类更聪明,或者像人类一样学习[5]。DL一直在解决许多问题,同时将技术应用到各行各业。当今人类仍然面临着许多难题,例如仍有人死于饥饿和贫困,癌症和其他致命的疾病等。希望人工智能和深度学习将更加致力于改善人类的生活质量,通过开展最困难的科学研究,解决各行各业传统方法无法解决的难题,让世界变得更加美好。
1.2 文本分类
文本分类指的是用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记。从一个标注完成的训练文本集合,寻找出一个关系模型,它能很好地反映文本类别与文本表征之间的联系,然后将此训练得到的关系模型应用于新的未知文本用于分类判断[6]。分类器的选择与训练、文本的表达、分类结果的评价与反馈等是文本分类的主要应用场景,而特征提取与文本预处理等步骤均是文本表达技术的分支[7-8]。随着计算机科学技术的发展,统计学习方法在文本分类领域占据绝对统治地位。由于人工智能的迅猛发展,文本分类从依赖于知识的方法逐渐转换为基于机器学习和统计的方法。扎实牢靠的理论基础作为支撑,清晰准确的评估指标以及实际表现出色,都为其中很多技术的发展壮大提供了强有力的帮助。
文本分类主要有两大任务:文本特征提取和标签预测[9]。特征提取的目的是从文本数据中提取重要的词汇,并以合适的形式表示它们,这是机器学习算法进行进一步分析所必需的。主流的文本特征提取方法包括word n-gram,bag-of-opinions,syntactic relations,sentiment lexicon features,Bag-of-Words(BoW)和TF-IDF[10]等。标签预测任务通常涉及在真实标签数据集上训练学习模型,然后应用训练后的模型对未标签新数据进行分类。计算机只有利用统计分类算法得到由样本数据转化而来的向量表示后,才能开始对这些向量进行真正意义上的“学习”过程[11-12]。所以统计分类算法是至关重要的,目前常用分类算法有:SVC,KNN,神经网络,Decision Tree[13]等。
2 家庭暴力危机识别模型实现方法
本章将介绍如何构建家庭暴力危机识别模型以及评价模型表现。由四个阶段组成:数据提取与处理、特征提取、模型构建、表现评估。在以下小节中将具体描述各个阶段的详细信息。
2.1 数据提取与处理
鉴于Facebook是一款全球流行的社交媒体并拥有庞大的用户群体和帖子数量,该文使用了Sudha Subramani整理的DV数据集[1-2]。考虑到个人隐私等问题,该文使用了公共页面上的帖子内容,未披露任何个人信息。
首先对获取到的文本数据进行清洗和标记,去除未含任何文本内容或全为无意义话语等帖子,然后对每条数据标记。这些帖子由人工手动标记,存在家庭暴力危机标记为1,不存在标记为0,最终取得可用于后续模型构建的数据共916条。
2.2 特征提取
由于计算机无法直接理解文本,故需要将文本转化为词向量。假设输入帖子表示为P={x1,x2,…,xn},其中xi是帖子P中的单个单词。首先通过映射每个单词到嵌入矩阵L的索引,将句子转换到特征空间。因此,单词嵌入矩阵表示为Lx∈RD×|V|,其中D是词向量维数,|V|是词汇量[14]。目前有多种词向量方法,如Word2Ve、GloVe、BERT等。该文采用Word2Vec构建词向量模型,并选择以大量Twitter帖子为样本的预训练模型。并对其50维和300维模型进行了表现评估,最终决定使用表现更好的50维模型,作为下一步深度学习模型的嵌入层。
2.3 模型构建
该文一共构建四种模型,CNN、RNN、LSTM和Bi-LSTM+self-Attention。
2.3.1 CNN
在卷积神经网络(convolutional neural network,CNN)中,模型的第一层为嵌入层,它提取信息量最大的n-gram特征并存储每个单词的单词嵌入[15],该文选择训练好的word2vec词向量模型放置于此。卷积层有不同数量的计算单元,通过改变滑动步幅可控制输出特征向量尺寸。使用三个卷积层(三个不同滤波器),分别连接三个池化层,池化层将先前的卷积表示形式转换为更高级别的抽象视图,并生成固定大小的输出[16]。再将结果连接concatenate层进行整合,dropout层可有效防止过拟合问题,flatten层用于将多维输入一维化,最后采用两个全连接层,将原本的多分类输出经过relu和sigmoid激活函数处理,输出变为0或1的二分类。
2.3.2 RNN
循环神经网络(recurrent neural network,RNN)是一种时序性的递归神经网络。它最大的特点在于数据的输入必须满足时间序列的性质,并且采用递归的方法使得序列间进行发展和推进[17]。所循环单元的链式连接使得RNN具有记忆性、参数共享性等一系列与其他神经网络不同的特性,因此RNN十分适合对输入数据为序列式的数据集的非线性特征进行学习。具体运行过程是t时刻输入当前信息并由神经网络模块S接收,之后由S得到t时刻的输出,并且将当前时刻的部分信息传递到下一刻t+1[18]。
2.3.3 LSTM
在RNN中,由于只依靠一条主线记录所有信息,因此在处理具有长距离依赖关系的场景下表现不好,如对一个超长句,RNN很难保持前后的时态一致。为改善提高RNN,出现了长短期记忆神经网络(long short-term memory,LSTM)。LSTM引入了细胞状态,并使用输入门、遗忘门、输出门三种门来控制和保持信息。遗忘门结合上一隐藏层状态值ht-1和当前输入xt,通过sigmoid函数(σ)[19],决定舍弃哪些旧信息。sigmoid值域为(0,1),当其值接近于1时保持信息,当其值接近于0时丢弃一部分信息。其次,输入门和tanh决定从上一时刻隐藏层激活值ht-1和当前输入值xt中保存哪些新信息,并得到候选值ct。然后,结合遗忘门和输入门进行信息的保存和舍弃,得到当前时刻的细胞状态ct。最后,输出门结合tanh决定ct、ht-1、xt中哪些信息输出为本时刻的隐藏层状态ht[20]。LSTM通过上述的方式决定如何舍弃、保持和更新信息,因为最后的结果ht是由多个函数作用并使用RNN未有的求和操作得来的,所以在反向传播过程中不容易产生梯度消失问题[21]。
2.3.4 Bi-LSTM+Attention
LSTM是一种前向传播算法,序列化处理让它在处理信息时必须遵循先后顺序,所以常常只考虑了上文而忽略了下文。在家庭暴力语言环境中,上下文往往是高度关联的,为了既考虑序列前值又考虑序列后值,该文引入了双向长短期记忆网络(bidirectional long short term memory,Bi-LSTM),如图1所示[22]。

图1 Bi-LSTM模型示意图
图1中语句经过嵌入层后,前向的LSTM提取当前时刻的前文特征信息,后向的LSTM提取当前时刻的后文特征信息。Bi-LSTM模型t时刻输入的计算公式如下:
(1)
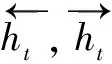
在有关家庭暴力帖子文本识别过程中,每条帖子字数不同,并且存在一些简单重复的情感用语和对识别意义不大的词语等。为提高识别准确率,必须突出关键词和重点词汇,优化特征词提取过程,所以该文在Bi-LSTM的基础上引入Attention机制。注意力机制模拟人脑注意力的特点,核心思想是:对重要的内容分配较多的注意力,对其他部分分配较少的注意力[24]。传统Attention机制模型需要依赖部分外部信息,而self-Attention 机制不需要使用其他外部的信息,它会自动从自身所给的信息训练来更新参数从而给不同信息分配不同的权重[25],因此该文采用self-Attention机制,计算方法如下:

(2)
其中,Q,K,V矩阵分别由输入矩阵乘WQ,WK,WV权重矩阵而得到,计算结果为Attention层输出[26]。
Bi-LSTM+self-Attention模型如图2所示[27]。

图2 基于self-Attention的Bi-LSTM模型结构
2.4 表现评估
最后一步是对每个模型识别家庭暴力有关帖子准确率的评估,该文采用准确率、精度、召回率和F1值作为分类器的评估指标,这四个指标是衡量机器学习模型性能公认的四大指标[28]。采用K折交叉验证的方法进行训练测试,将样本数据分为K份,对每份数据计算评估指标值,对K次计算的结果取平均值得到最终评估结果[29],然后对四种模型训练过程中accuracy和loss率的变化绘图,直观展现和比较各模型训练和测试效果。
3 实验结果与分析
3.1 实验数据
共从Facebook上获取到家庭暴力相关帖子916条,并对它们进行人工标记,有家庭暴力危机标记为1,无标记为0,标注后的数据样例见表1。

表1 家庭暴力数据集样例
在开始训练前,需要对英文文本信息进行分词、清洗、标准化等预处理[30],神经网络中输入的所有文本向量组需要有相同的维度,因此需要对文本进行切割[11]。经统计总单词量为11 085,文本最大长度4 507。考虑到绝大部分文本长度在500以内。在尽量保留文本信息的同时提高训练效率,该文截取500作为文本的长度。取K为10,采取k-fold交叉验证方法生成后续模型的训练用例与测试用例。对训练集用wordcloud可视化,直观反映不同词的重要性特征,见图3。

图3 wordcloud对训练集可视化视图
3.2 实验模型参数设置
该文模型较多,具体参数见表2。其中模型的部分超参数主要是来自于先前论文研究中的经验,如学习速率、Dropout数值。一些参数是根据DV数据集的特性而设置,如最大句子长度和词汇量是统计数据集得到。另外,还有部分参数根据模型训练和硬件的条件配置,如batch、epoch以及优化器的选择。

表2 模型具体参数设置
3.3 模型评估
设置了四个分类器实验对照组,分别使用了CNN、RNN、LSTM和Bi-LSTM+self-Attention(SA-BiLSTM)。使用相同50维word2vec词向量模型作为输入,采用K折交叉验证(K=10)的方法进行训练测试,将样本数据分为10份,对每份数据计算评估指标值,对10次计算的结果取平均值得到最终评估结果。使用准确率(Accuracy)、精度(Precision)、召回率(Recall)和F1值作为分类器的评估指标,最终评估结果见表3。
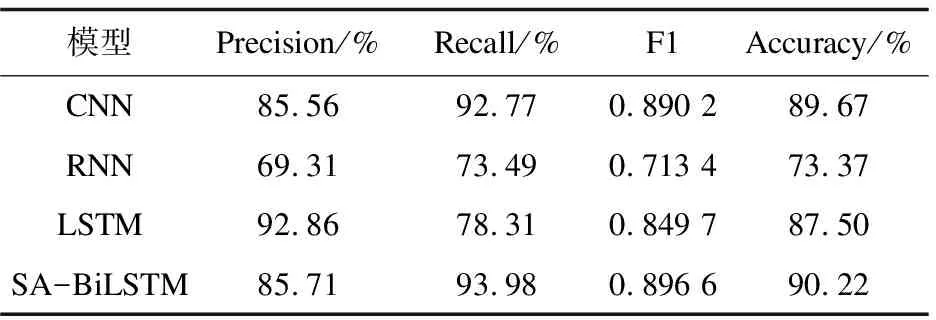
表3 模型评估结果
综合表3实验结果可以发现,RNN在四种模型中各项评估值均为最低,这可能由于RNN梯度消失问题所导致,在给定较长序列的情况下,随着新序列被输入到RNN中,初始序列的信息逐渐消失[8]。CNN模型由于其独特的卷积机制,在四项评估指标上均表现良好,且训练时间是最少的。而RNN无法处理长距离依赖的问题,似乎被它的改进模型LSTM和Bi-LSTM很好地解决了,通过引入细胞状态和遗忘门等机制能让它们选择性遗忘信息。从结果来看,LSTM达到了最高的精度,为92.86%。而SA-BiLSTM由于引入了双向LSTM和self-Attention机制,使得其对文本特征提取更快更精确,召回率、F1值和准确率在四种模型中均为最高,对比来看明显比LSTM提升了性能。接着以训练时期评估了各模型性能,希望训练时间越长,模型越稳定。
然而深度学习模型往往需要很长时间运行,且与计算机算力高度相关[12]。因此绘制了各模型在epochs从1到20各时期的accuracy和loss,见图4。
由图4可以看到,RNN在20个周期的训练中accuracy和loss始终波动较大,且较其他几种模型而言明显accuracy更低loss更高,说明需要更多训练周期才可能收敛。CNN、LSTM和Bi-LSTM在训练开始accuracy和loss有一定波动,随着训练周期增加,accuracy和loss逐渐增加和下降,在平均17个周期后趋于稳定,三种模型的accuracy和loss分别稳定在0.9和0.3左右。

图4 不同时期各模型的accuracy与loss
4 结束语
探索了用深度学习方法自动识别公共安全危机问题,以家庭暴力危机为特定研究对象,提出了基于Bi-LSTM+Attention的家庭暴力危机识别模型。首先从Facebook上获取到相关数据集,构建word2vec词向量模型,然后将SA-BiLSTM模型与其他三种模型进行了对比评估。结果表明除RNN外,CNN、LSTM和SA-BiLSTM三种模型表现均为良好,其中SA-BiLSTM综合表现最好,相较其他模型在此问题上有一定优越性。
尽管该文实现了上述工作,还是有很多不足,可以在后续研究中加以改进与提高。(1)数据集过小。受限于人工标注,以及本题目的研究现状,网络上还没有家庭暴力相关大型数据集。(2)数据集种类单一。只有从Facebook上采集到的英文帖子,还可以从Twitter、微博等获取更多语言种类的相关帖子。对于中文语言,可以采用分词软件先进行分词等文本预处理,再训练生成对应中文词向量模型,调整神经网络模型相关参数以提高中文语料训练效果。(3)可进一步对模型优化,找到各类最佳超参数以达到模型最好效果。(4)应考虑将此模型推广至其他公共安全危机识别问题中。
