车企舆情正负面情感识别与预测
2022-05-07胡二琴
秦 苗, 胡二琴
(湖北工业大学理学院, 湖北 武汉 430068)
文本挖掘和分析已经成为各行各业研究数据模式的核心问题。对于企业来说,通过对互联网中与自身企业有关的舆情进行分析,能帮助其获得更多的信息,进一步了解客户,预测和增强客户体验,合理改进产品性能[1-2]。HU等[3]通过情感分析挖掘出用户对产品的情感倾向;Dasgupta等[4]通过对三星手机用户评论进行情感分析,得到消费者对手机信息特征的反馈;李琴等[5]基于情感词典对在线景区评论进行情感分析得到情感类别倾向性与门票波动之间客观存在的联系。
目前,汽车制造行业竞争激烈,有效提高汽车的品牌形象和溢价效应对于企业来说至关重要。伴随着互联网的发展,汽车行业的品牌质量、发展规划、创新水平等受到了越来越多的关注[6-7],大量的网络评论中蕴含着广大网民的情感和观点,通过对评论情感进行研究,车企可以深入了解到近期网络舆论倾向,从而进行相应的调整和改进[8-9]。因此,对汽车行业舆情情感进行研究,将会有助于提高车企形象,而对文本情感进行识别是舆情分析的关键。目前,情感识别主要有两类方法:基于情感词典的方法和基于机器学习的方法[10]。李宸严[11]等利用注意力与Bi-LSTM混合算法进行了车企舆情的情感分析。本文主要通过情感词典来对汽车行业的网络舆情进行分析与预测,利用分词绘制词云图、情感分类、主题分析来了解广大网民对汽车行业的关注重点以及正负面情感聚焦。
1 数据来源与数据预处理
本文数据来自“第四届全国应用统计专业学位研究生案例大赛”C题,数据分为训练集与测试集,共99842 条,其文本数据部分展示见图1。

图 1 部分数据展示
该数据的第1列是文本小标题,第2列是正文,第3列是用户ID,第4列是文本的网页链接,第5列是其给定的情感类别。
数据的预处理对本文的分析十分重要,对后续结果分析有很大影响。我们首先依据对文章有高度概括性的标题进行删除,去除与车企无关的舆情。在网上查询与汽车相关的词汇大全,利用该词汇大全计算标题得分,若累积得分为0,则认为该标题是与车企完全无关的报道,需要删除。继而去除文本中的重复数据,认为标题和正文均相同的为重复数据予以删除,最终保留与车企相关的舆情有45324条。然后进行数据清洗,去除数据中无用、停用词和出现频率极高但无实际情感意义的词汇,如“汽车”等。
2 车企舆情热点分析
在数据预处理和“Jieba”分词后,提取分词中的名词词汇,统计词汇出现的频率,将词频按降序排列,选择前100个词绘制词云来直观反映人们的关注点和关注度。

图 2 舆情热点词云图
由图2可见,在与汽车行业相关的舆情中,人们关注较多的是驾驶、新能源、车型、上市、新款,以及丰田、奥迪、吉利等品牌。对测试集进行相同的操作,发现两者在热点词汇上没有太大差异,只是对奥迪的关注减少了而对大众的关注度增加了,另外还增加了对车主的关注。
为进一步了解车企舆情中人们对汽车品牌和汽车功能、配件的关注热点,我们查找了汽车品牌词库大全以及汽车相关配件词汇大全(https:∥pinyin.sogou.com/dict/ cate/index/432)。将文本分词分别与这两组词汇进行匹配,计算频率,取排名前十来分析车企舆情关注最多的汽车品牌和汽车配件,其结果如图3、图4所示。

图 3 车企舆情热点关注品牌Top10

图 4 车企舆情热点关注配件Top10
由图可见,训练集中关注最多的汽车品牌依次是丰田、奥迪、吉利、大众等;关注最多的汽车配件依次是轮胎、发动机、方向盘、轮毂等。对测试集进行相同处理,可见测试集中关注最多的汽车品牌与训练集中大体相同,只是测试集舆情关注的汽车品牌前10少了宝马,多了红旗;在对汽车配件的关注中,两个数据集也大体相同,只是测试集多了转向灯,少了离合器。
3 车企舆情情感倾向分析
文本情感分析可以被视为一类特殊的文本分类问题。目前绝大多数研究将文本的情感倾向性分为正向、负向两种类别。文本情感分类方法主要有机器学习方法、词典匹配方法。机器学习方法中主要用到的是支持向量模型、朴素贝叶斯模型以及神经网络等。这些方法各有优劣。而本文是要进行正、中、负3级分类,不适合用针对二分类的支持向量模型,所以采取情感词典匹配的方法来对情感进行标记。
3.1 提取文本情感特征
在以情感词典为基础的情感分析中,情感词库的选择占据十分重要的地位。高质量的情感词库往往可得到更好的情感分析效果,通常情况下所选取的情感词库是网上下载的正负面情感词汇和正负面评论词汇。但本文的舆情数据并非评论数据而是类似网络小文章形式,这类数据的正负往往在其中带有事件特征,比如文中没有太多的情感性词汇,但由于描述的是一件正面事件,故最终也会评为正向情感。因此若是基于传统的情感词库进行分类效果并不会理想,本文经尝试后发现准确率只有23.19%,故考虑重新提取情感特征构建新的词库再进行情感匹配。
本文通过词频来选择特征。利用词频对处理后的文本分词分别计算权重,并根据权重的大小对分词进行排序,然后剔除一些与文章主题虽直接联系但无实际意义的无用词,如 “汽车”“年”“拉”等。然后统计分词的总词频,从中选取若干个出现频率最高的词汇组成该类别的特征词集;最后去掉每一类中都出现了的词,形成3种类别各自特有的特征词集(即我们用到的特征集合)。特征项的构建步骤见图5。

图 5 特征项的构建流程
由于中立面的词汇没有明显的实际特征,所以我们只进行正面词汇和负面词汇的选取。按词频降序排列后发现,正面词汇中排名在第500的词汇出现频率只有2次,负面词汇中排名在第300的词汇出现频率为5次,表2分别展示了正向词汇排名前100、300、500的末尾词以及负向词汇排名前100、200、300的末尾词。

表2 正向词汇局部展示

表3 负向词汇局部展示
可见,正负向中前300的词频词汇的情感分级都比较明显,初步选择构建的情感词典正负向均取300个词汇。
3.2 文本特征表示
计算词权值的方式有传统的用权重赋值法以及TF-IDF等,TF-IDF的主要思想是:如果某个词在一篇文章中出现频率很高,但在其他文章中极少出现,那么这个词就能很好地区分类别,适合用来作为分类的特征。其公式为:
其中:wik为特征词ik的权重,tfik为特征词ik在文本di中出现的频率,N为总的训练文本数,nk为训练集中词ik出现了的文本数。
实践中发现,用此方法赋以权重比较繁琐,且其不区分正负语料库,而是直接依据每个词在正、负、中性文本中出现的频率来判断其在不同情感中的权重,因此本文采用简单的权重赋值方法,即将所有正向词汇赋以+1的权重,所有负向词汇赋以-1的权重。这样的优点是操作起来比较简单便捷,缺点是忽略了不同词汇在情感程度上的差异。
3.3 文本情感分类
本文利用情感词典来对文本情感进行标注。对具有积极情感的词语赋于+1的权重,对具有消极情感的词语赋于-1的权重,并假定情感赋值可以线性相加。由于标题对文章内容具有高度概括作用,所以选择利用标题来对文章进行情感分类。首先对标题进行分词,然后对分词中包含的情感词加上对应+1或-1的权重。此外,本文加上了否定词和程度副词对情感的影响,最终将得分为正的文本划分为正面情感,得分为负的文本划分为负面情感,其余文本记为中立情感。对训练数据集和测试数据集分别随机抽取10 000条进行情感划分,其准确率达到85.73%,整体效果较好,其混淆矩阵如表4所示。

表4 训练集情感划分混淆矩阵
可见,负向情感正确划分的概率为83.75%,正向情感正确划分的概率为89.19%,对中立情感的文本划分准确率相对低一点。考虑到整体准确率为85.73%,且正向负向情感划分的准确率均不错,故此方法有效。
将同样的方法用于测试集的情感划分,得到准确率为83.62%,整体效果较好,其混淆矩阵如表5所示。

表5 测试集情感划分混淆矩阵
可见,负向情感正确划分的概率为83.77%,中立情感被正确分类的概率为68.68%,正向情感正确划分的概率为89.16%,总体准确率为83.62%。
在此基础上对训练集分类后的正负向情感文本分词统计词频,按频率降序排列选取前100名的词汇绘制词云图见图6、7。

图 6 训练集正向情感文本词云

图 7 训练集负向情感文本词云
对训练集分类后,其正向舆情信息中关注较多的是上市、车型、魅力等,负面舆情信息中关注较多的是销量、二手车、投诉、事故、下滑等,说明分类后的分词效果比较好,有利于后续分析。
对测试集情感划分正负之后也分别提取了正负面的主要词汇,将其与训练集对比并无太大差异,我们将两个数据集正负面提取的词汇取前6个综合为表6。

表6 两个数据集正负面热词对比
可见训练集与测试集在正面情感热词上相差不大,只是训练集中正面舆情增加了对丰田的关注;两个数据集在负面情感热词上相差也不大,只是测试集中的负面舆情减少了对疫情的关注,增加了对达利桑、德罗的关注。
4 车企舆情主题分析
4.1 LDA主题分析模型
LDA模型也叫3层贝叶斯概率模型。它由3层结构组成,分别是文档(d)、主题(z)和词(w)。该模型能够有效挖掘潜藏在数据中的主题,进而分析数据中的主要关注点。
3层贝叶斯结构包括两部分,分别是“文档—主题”和“主题—词”,其中“文档—主题”表示以一定概率来通过文档d生成主题z;“主题—词”表示以一定概率来通过主题z生成词w。若要生成一个文档,文档中每个词出现的条件概率可以分为两部分:

式中,p(w|d)表示文档中分词出现的概率;p(w|z)表示主题中分词出现的概率;p(z|d)表示文档中主题出现的概率。LDA模型则是利用“文档—词语”矩阵来进行训练,由此推测出文档的主题。
4.2 寻找最优主题数
由于中立情感的文本对主题分析没有太大价值,并不能反映一些关键性看法和态度,所以本文选择只对测试集中情感为正向和负向的文本进行主题分析。LDA模型可以用相对较少的迭代就找到最优的主题数。图8展示了不同主题数下的平均余弦相似度,可见无论是正向情感还是负向情感都在主题数选2时,平均余弦相似度最低。因此,对正面数据和负面数据均选择主题数为2来进行主题分析。对测试集进行相同的步骤,发现选择的最优主题数也是2。

(a)正面
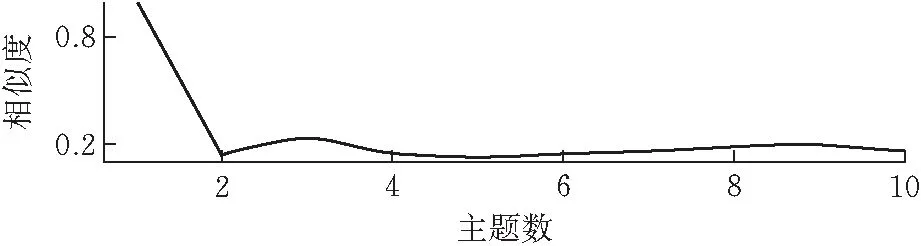
(b)负面图 8 主题间平均余弦相似度
4.3 LDA主题分析
根据概率,在每个主题下生成10个最有可能出现的词语。表7反映了训练集中正面情感数据潜在的主题。主题1中的高频词(即关注点)主要是上市、魅力、车型、比亚迪、奥迪等主要反映人们对车的车型、特质等关注多的方面。主题2中的高频词(即关注点)主要是新款、动力、新能源、吉利等,说明人们对新款的车比较关注,且对它的动力、新能源方面关注较多且好评度较高。

表7 训练集正面舆情数据中的潜在主题
表8反映了训练集中负面情感数据潜在的主题。主题1中的高频词主要是销量、同比、下降、新车、召回、投诉、司机之类,说明很多关于车企的负面舆情都较多提到新车召回、销量下降以及服务投诉。主题2中的高频词主要是二手车、优信、驾驶、自动之类,说明人们对二手车的满意度并不是很高。广大网民对一些新兴的自动驾驶持怀疑态度,对其安全性存在一些顾虑。

表8 训练集负面舆情数据中的潜在主题
对测试集同样提取了两个主题的关键词,其结果与训练数据集主题所体现的关注点相似,只是正面中主题2增加了对设计、品牌、高颜值的关注,也就是对汽车的外形设计上关注较多;负面中测试集增加了对日产和丰田的关注。
5 结论
本文利用情感词典识别和预测汽车行业的舆情情感,并对正面情感和负面情感分别进行主题分析。从分析结果可知,广大网民对汽车行业现状的态度和关注点,发现人们对汽车的车型、魅力等聚焦较多,且对新款车尤为关注;对汽车的动力、新能源等方面具有一定的关注度和好评度,对新车的召回率、部分汽车销量下降情况以及出租车司机因服务不当而遭受投诉等方面带有一定的负面情绪;对二手车的满意度不高,对于新兴的自动驾驶也持怀疑观望态度。
