基于PLS-GRNN的豆粕品质近红外光谱检测研究
2022-05-05王立琦王睿莹陈颖淑罗淑年王伟宁张艳荣
王立琦, 姚 静, 王睿莹, 陈颖淑, 罗淑年, 王伟宁, 张艳荣*
1. 哈尔滨商业大学计算机与信息工程学院, 黑龙江省电子商务与信息处理重点实验室, 黑龙江 哈尔滨 150028
2. 哈尔滨商业大学食品工程学院, 黑龙江 哈尔滨 150028
引 言
豆粕是大豆浸提取豆油后, 经适当干燥和热处理所得副产品, 产量大, 营养丰富, 主要用于禽畜类饲料, 也是生产化肥、 制作食品的辅料, 是重要的期货交易物。 豆粕品质的评价指标主要有水分、 蛋白质、 脂肪、 微量物质(如纤维、 灰分、 氨基酸、 维生素、 碳水化合物、 胡萝卜素等), 其中水分、 蛋白质和脂肪占比高, 是衡量豆粕品质的重要指标, 需要在生产过程中不断检测和调控[1]。
现有的豆粕品质检测方法包括化学分析法、 色谱分析法等, 普遍存在着有毒化学试剂使用多、 操作复杂、 分析时间长等问题, 无法满足实际生产过程快速检测及调控的需求。 近红外光谱(near-infrared spectroscopy, NIR)技术具有无损、 快速、 低成本、 多组分同时分析、 易于实现在线检测等优点, 特别适合生产过程中的质量监控[2]。 近年来, NIR在豆粕品质检测方面应用已有报道。 庄树华[3]、 纳嵘[4]采用近红外分析豆粕蛋白质含量; Leeson[5]等研究了近红外光谱分析法估测豆粕的代谢能; Fontaine[6]等采用近红外光谱法预测豆粕中的氨基酸含量; 王红梅[7]等利用近红外建立豆粕的蛋白质和总氨基酸预测模型; 杨增玲[8]等建立了豆粕含水率、 粗蛋白质量分数的近红外定量分析模型。 上述研究所用样品大多是在实验室人工制备, 而实际生产线上的豆粕产品是多组分同时变化, 变量间相互干扰会影响建模效果。
本研究直接从大豆油脂加工生产线上采集样品, 根据加工过程中实际检测控制需求, 对豆粕中的水分、 蛋白质和脂肪三个主要成分含量建立基于PLS-GRNN的近红外分析模型, 以期能用于实际加工过程快速检测, 及时调整工艺参数, 生产出多等级粕、 专用蛋白粕和功能大豆油等新产品。
1 实验部分
1.1 样品化学值测定
本研究目的是实现加工过程中豆粕品质快速检测及调控, 因此直接从大豆油脂生产线上采集449个有代表性的豆粕样品, 依据GB/T6435—1986《饲料水分的测定方法》, 利用105 ℃烘箱法测定水分含量范围为9.68%~13.26%; 依据GB/T5511—2008《谷物和豆类氮含量测定和粗蛋白质含量计算凯氏法》, 利用凯氏定氮法测定蛋白质含量范围为41.2%~50.9%; 依据GB/T5009.6—2003《食品中脂肪的测定》, 利用索氏提取法测定脂肪含量范围为0.43%~3.75%。
1.2 光谱数据采集
采用瑞士BUCHI公司的NIRMaster型傅里叶变换近红外光谱仪扫描豆粕样品, 光谱范围为4 000~10 000 cm-1, 扫描频率4次·s-1, 分辨率4 cm-1。 为保证样品扫描均匀性, 每份样品重复扫描3次后取平均值, 获得豆粕样品漫反射近红外光谱如图1所示。

图1 豆粕样品近红外光谱图
1.3 光谱去噪
首先利用马氏距离法从449个豆粕样本中剔除91个异常样本, 然后采用小波变换对剩余的358个样本的光谱数据进行降噪处理。 光谱去噪就是在保证光谱数据有用信息的原始真实性前提下, 最大程度地去除各种随机噪声。 利用控制参数反复试验法对小波阈值方式、 分解尺度和小波基进行筛选[9], 根据去噪信号在原信号中的能量占比和去噪信号与原信号标准差对去噪效果进行评价, 以确保去噪前后信号不失真, 计算公式如式(1)和式(2)
(1)
(2)
式(1)和式(2)中,f(n)为原始数据,g(n)为去噪后的数据。 一般perc∝1、 err越小, 降噪效果越好。 然后与移动平均法、 多元散射校正和标准正态变量变换三种常规处理方法对比, 发现基于db6小波基、 2层分解和penalty阈值的小波去噪方式效果最佳, 统计结果如表1所示。
1.4 样本分集
样本集的划分通常有人工选择和计算机识别两种方法。 人工选择是将样本化学值顺序排列, 按一定梯度抽取预测集样本。 计算机识别是根据光谱特性差异或结合化学值来选择校正集样本。 由于本研究为豆粕水分、 蛋白质和脂肪多个成分指标同时检测, 实际样品的三个参数是同时变化的, 人工选择样本分集无法做到同时兼顾每个参数指标, 而且经过尝试发现效果很差。 计算机识别算法常采用Kennard Stone (KS)和Sample set Partitioning based on joint X-Y distance (SPXY)两种, KS算法[10]通过计算样本的欧式距离确定校正集, 但它只考虑光谱数据间的关系, 而不考虑与化学值的关系, 因此在预测未知样本时可能缺乏针对性。 SPXY算法[11]在KS算法基础上改进, 同时兼顾光谱矩阵和浓度矩阵, 以保证最大程度表征样本分布。 本研究采用KS和SPXY两种算法对三个组分的豆粕样本分集, 之后分别对各组分校正集样本建立偏最小二乘(partial least squares, PLS)回归模型, 根据模型的预测效果选择每个组分的最佳样本分集, 有效地避免了人为参与和变量间的相互影响, 两种样本分集方法建模结果如表2所示。 可以看出, 对于水分和蛋白质, KS分集法优于SPXY分集法, 而对于脂肪则是SPXY分集法优于KS分集法。

表2 两种样本分集方法建模结果
表3为最后的样本分集结果, 可以看出, 对于水分、 蛋白质和脂肪三个参数, 其含量化学值的最大值和最小值样本都包含在校正集中, 校正集样本和预测集样本的均值和标准差非常接近, 说明校正集与预测集的样本分布比较均匀, 计算机算法的分集结果符合要求。

表3 样本分集结果
2 结果与讨论
2.1 基于iPLS的特征波段优选
利用近红外光谱仪采集的波长变量有上千个, 其中包含许多与豆粕品质无关的信息, 如果用全谱建模, 会使模型的计算量增大, 稳定性变差, 因此在建立预测模型前, 有必要进行特征波段优选, 剔除光谱中的冗余信息。 利用优选出的特征波长变量建模, 可以降低模型计算复杂度, 提高模型预测性能。
本研究采用区间偏最小二乘法(interval partial least squares, iPLS)进行特征波段提取[12-13]。 将全谱区间分别按20, 30, 40和50依次等宽均分并对每一个子区间建立PLS模型, 采用留一交叉验证法计算模型的交互验证均方差RMSECV作为评判标准, 其最小值对应的子区间即为最佳建模波段。 对应水分、 蛋白质和脂肪不同子区间数的波段选择结果见表4、 表5和表6。

表4 水分iPLS不同子区间数波段选择结果

表5 蛋白质iPLS不同子区间数波段选择结果

表6 脂肪iPLS不同子区间数波段选择结果
表中可见, 无论水分、 蛋白质还是脂肪均为划分20个子区间时对应的特征吸收波段建模效果最好。 图2、 图3和图4分别展示了水分、 蛋白质和脂肪划分20个子区间的iPLS结果, 最终优选出水分、 蛋白质和脂肪的特征波段分别为4 904~5 200, 4 304~4 600和4 304~4 600 cm-1。

图2 水分20个子区间的iPLS建模结果

图3 蛋白质20个子区间的iPLS建模结果

图4 脂肪20个子区间的iPLS建模结果
2.2 基于PLS-GRNN的豆粕组分含量模型建立
2.2.1 GRNN结构
广义回归神经网络(generalized regression neural networks, GRNN)是由美国学者Donald于1991年提出的一种人工神经网络模型[14], 是对径向基神经网络(radial basis function network, RBF)的改进。 GRNN具有很强的非线性映射能力, 在信号过程、 结构分析、 控制决策系统等领域得到了广泛的应用。 但GRNN在近红外定量分析方面研究较少, 应用在豆粕品质定量检测方面还未见报道。 本工作提出建立PLS-GRNN联合模型进行豆粕品质多组分含量同步预测, 旨在提高豆粕品质预测效率和准确性。
GRNN结构如图5所示, 该网络由输入层、 模式层、 求和层和输出层四层构成[15]。 输入层神经元数目等于样本中输入向量的维数, 各神经元是简单的分布单元, 直接将输入变量传递给模式层。 模式层神经元数目等于样本的数目, 各神经元对应不同的样本。 求和层中使用两种类型的神经元进行求和。 输出层神经元数目等于样本中输出向量的维数, 各神经元将求和层的输出相除。

图5 GRNN结构
2.2.2 输入变量确定
在光谱分析过程中, 光谱数据间可能会存在严重的共线性干扰, 因此对输入到网络的光谱数据采取降维处理, 不仅可以减少计算量, 还可以防止网络陷入局部最小。 PLS不仅可以用于模型的建立, 还能用于数据矩阵的分解, 提取最佳主因子, 从而达到降低数据维度的目的。 本研究采用舍-交互验证法, 根据预测残差平方和(prediction residual error sum of squares, PRESS)来确定最佳主因子数, 豆粕各组分的PRESS值随主因子变化趋势如图6所示。 可以看出, 随着主因子数的增加, PRESS值呈明显下降趋势, 当主因子数达到一定值时, PRESS变化趋于平缓, 之后基本不再下降, 因此可确定水分、 蛋白质和脂肪的最佳主因子数分别为8, 8和7, 然后将主因子得分作为GRNN网络的输入变量用于建模。
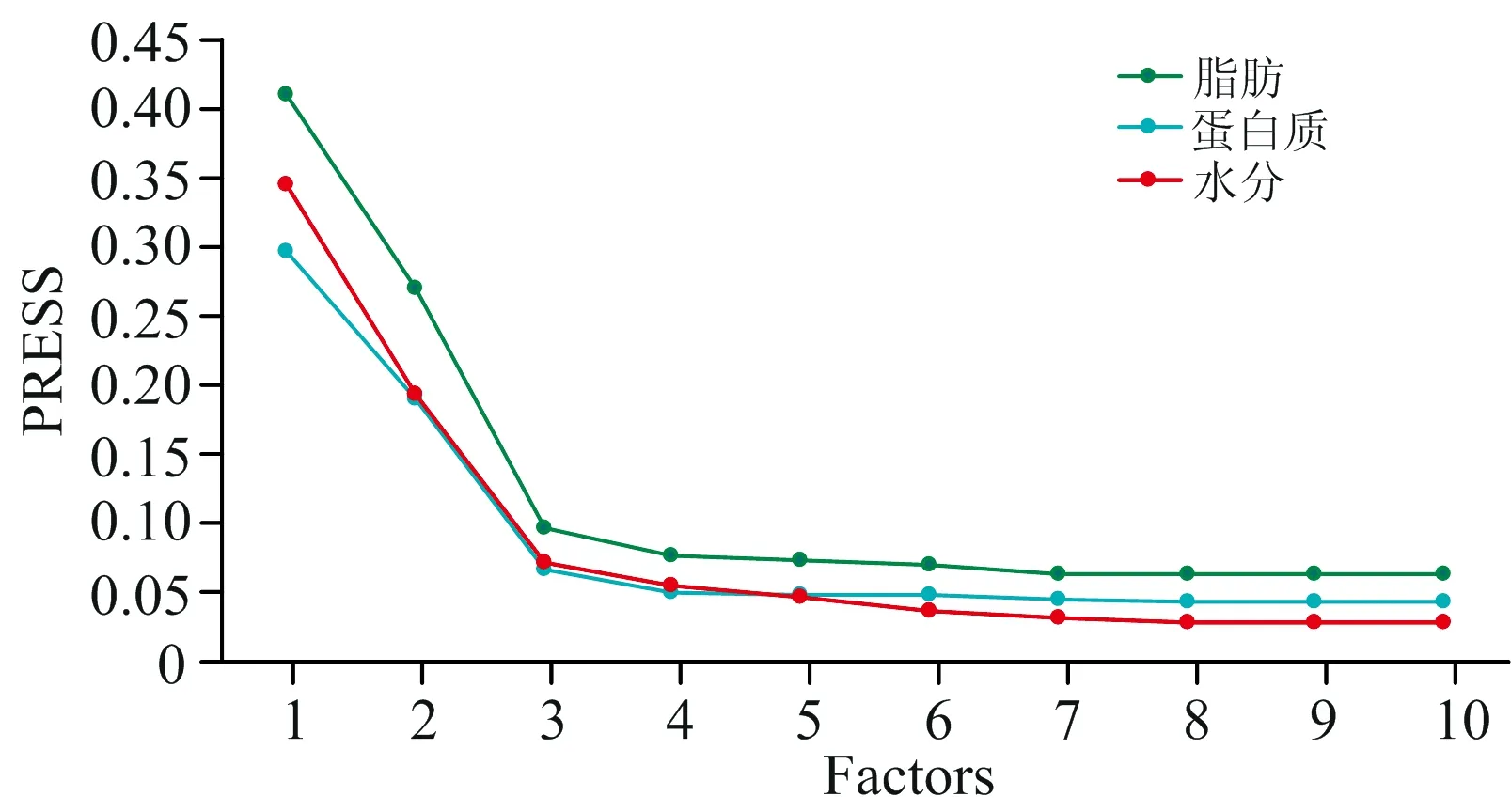
图6 PRESS随主因子变化趋势图
2.2.3 网络参数优化
GRNN具有非常简便的网络参数设置功能, 整个神经网络只需要设置传递函数中的光滑因子就可以调整网络性能[16-17], 而且网络训练过程实际上就是光滑因子的寻优过程。 GRNN传递函数表示为
(3)
式(3)中, spread称为光滑因子, 决定了训练样本的误差和基函数的形状, 其选值大小直接影响模型的预测性能, 常用的寻求最佳spread的方法是k折交叉验证循环法。 本研究设定spread值的范围为0.1~1, 选取4折交叉验证来训练GRNN网络, spread寻优曲线如图7所示, 最小MSE所对应的spread值即为最优值。 图中可见, 水分、 蛋白质和脂肪的最优spread值分别为0.1, 0.2和0.2。

图7 spread寻优曲线
2.3 PLS-GRNN模型预测结果及评价
GRNN网络参数选定后, 将PLS最佳主因子得分作为网络输入变量, 豆粕组分化学值作为输出变量, 建立豆粕品质PLS-GRNN预测模型, 预测效果如图8所示。 可以看出, 水分、 蛋白质和脂肪预测样本均在其各自的拟合线附近均匀分布, 说明PLS-GRNN模型预测效果较好。
最后, 将PLS-GRNN模型与经典的PLS线性模型和BP神经网络非线性模型对比, 结果如表7所示。
由表7可见, 对于豆粕样品三组分来说, 其PLS-GRNN模型的预测效果均优于PLS模型和BP模型, 说明PLS-GRNN模型的泛化能力更好。 其水分、 蛋白质和脂肪的预测集决定系数R2分别为0.976 9, 0.940 2和0.911 1, 预测均方根误差RMSEP分别为0.091 2, 0.383 4和0.113 4, 预测相对标准偏差RSD分别为0.79%, 0.83%和8.53%。 从实验结果来看, 虽然脂肪的RSD低于理想要求, 但也在模型评定标准可用范围之内, 并且从图8也可以看出脂肪的拟合效果也很好, 分析其原因可能是由于豆粕中脂肪含量低, 即使较小的绝对误差也会引起较大的相对误差, 而水分和蛋白质含量较高, 因此相对误差较小, 也可能是三组分间相互影响造成的, 关于脂肪的预测精度问题有待进一步研究改善。

图8 水分、 蛋白质和脂肪的PLS-GRNN模型预测效果

表7 PLS-GRNN与PLS, BP建模效果对比
3 结 论
将PLS-GRNN应用于豆粕品质多组分含量近红外光谱分析。 对小波降噪后的光谱数据进行iPLS特征波段提取, 优选出水分、 蛋白质和脂肪的最佳建模波段分别为4 904~5 200, 4 304~4 600和4 304~4 600 cm-1, 减少了光谱冗余信息, 降低了模型的计算复杂度, 提高了模型效率。 建立了豆粕三组分含量的PLS-GRNN预测模型, 与PLS线性模型和BP非线性模型对比, 发现PLS-GRNN模型效果最佳, 其水分、 蛋白质和脂肪的预测相对标准偏差RSD分别为0.79%, 0.83%和8.53%。 研究表明基于PLS-GRNN的近红外光谱分析用于豆粕品质检测是可行的, 能够用于实际生产过程中的品质监控, 及时调整工艺参数, 以生产出高品质的大豆产品。
