基于多任务学习的测井储层参数预测方法
2022-05-05邵蓉波肖立志廖广志史燕青周军李国军侯学理
邵蓉波, 肖立志*, 廖广志, 史燕青, 周军,, 李国军, 侯学理
1 中国石油大学(北京)人工智能学院, 北京 102249 2 中国石油集团测井有限公司, 西安 710077
0 引言
随着近年来数据科学和人工智能的发展,利用机器学习解决地球物理测井、地震勘探等方面的问题受到广泛重视.相较于传统方法,数据驱动的机器学习方法跳出领域知识,从全新的角度观察数据,探索更大的函数空间,在物理关系未知的情况下对数据和目标进行映射,提供了在高维空间中表征变量之间关系的方法,减少了研究人员对地质地球物理及岩石物理学知识的需求(Bergen et al., 2019).地球物理和人工智能发展的另一个思路是将机理模型融入机器学习之中,既可以提升地球物理机器学习模型的可解释性,又能够更准确地对岩石物理关系进行映射(Reichstein et al., 2019; 肖立志, 2022).已有学者对神经网络在地球物理中的应用展开研究,席道瑛和张涛(1994)使用反向传播神经网络自动识别岩性.近些年,Kohli等(2014)构建了数据驱动的神经网络模型,根据不同偏移距井的测井资料计算渗透率.张东晓等(2018)将LSTM与串级系统相结合,提出串级长短期记忆神经网络(CLSTM),实验表明CLSTM更适用于生成序列式的测井数据.Sultan(2019)采用自适应差分进化(SaDE)方法优化人工神经网络(ANN)的参数,有效地预测了总有机碳(TOC),与传统的估算方法相比神经网络方法更加高效精准.廖广志等(2020)的研究表明卷积神经网络可以用于预测储层微观孔隙结构,且优于单层神经网络模型.Al-AbdulJabbar等(2020)利用人工神经网络(ANN)根据钻井参数预测储层孔隙度,并取得较好的预测效果.Gao等(2020)利用井旁道数据与测井含气性解释结果建立卷积神经网络模型,同时使用迁移学习方法缓解少标签导致的过拟合问题.Liu等(2020)提出了一种基于局部深度多核学习支持向量机(LDMKL-SVM)的岩相分类方法,同时考虑低维全局特征和高维局部特征,自动学习核函数和SVM的参数,结合地震弹性信息预测岩性.Gao等(2021) 提出了一种基于多层感知器(MLP)的低电阻率低对比度(LRLC)储层识别方法,MLP方法解决了LRLC储层与水层的电阻率相似而无法有效识别的问题.金永吉等(2021)将遗传神经网络用于测井曲线重构,实验表明相较于传统方法生成的曲线质量更高.Zhang等(2021)提出了一种“常规测井资料-矿物成分预测-纹层组合类型识别”有监督组合机器学习方法,用于在地质数据有限的情况下预测具有高度垂直异质性的层状页岩的空间分布,构建测井数据与主要矿物成分的映射关系.白洋等(2021)使用分类委员会机器进行致密砂岩流体识别,使流体识别模型预测精度和泛化能力大幅度提高.Dong等(2022)提出了一种基于双深度Q网络(DDQN)的深度强化学习(DRL)方法,在三个常规试井模型中进行自动曲线匹配,结果表明DDQN比监督机器学习算法鲁棒性更好.毕丽飞等(2021)提出了基于标签传播的半监督学习方法并应用于岩性预测,结果表明该模型可以提升小样本类别的准确率.目前多名学者对人工智能和神经网络在地球物理中的应用持乐观态度(Kohli and Arora, 2014; 王昊等, 2020).
在自然语言处理和机器视觉等领域常使用多任务学习的方法提升预测效果.多任务学习可以将多个相关的任务放在一起学习,学习过程中通过一个在底层的共享表示(Shared representation)来互相分享、互相补充学习到的领域相关信息,提升泛化效果(Evgeniou, 2004).共享一般是基于参数(Parameter based)的共享:比如基于神经网络的多任务学习和高斯处理过程;或者是基于约束(Regularization based)的共享:比如均值和联合特征(Joint feature)学习(Jebara, 2011).多任务学习也被视为一种归约迁移(Inductive transfer)(Dietterich et al., 1997).归约迁移(Inductive transfer)通过引入归约偏置(Inductive bias)来改进模型,使得模型更倾向于某些假设.在多任务学习场景中,归约偏置由辅助任务来提供,使模型更倾向于那些可以同时解释多个任务的解,从而提升模型的泛化性能(Dietterich et al., 1997; Argyriou et al., 2008).
机器视觉领域,Sun等(2014)提出了一种联合训练人脸确认损失和人脸分类损失的多任务人脸识别网络DeepID2,网络中共有两个损失函数:人脸分类损失函数和验证损失函数.Zhang等(2014)提出的TCDCN模型以检测脸部特征点为主要任务,辅以4个分任务,相较于单任务模型,TCDCN模型的检测更准确.目标检测领域,Girshick(2015)提出的Fast R-CNN是一个快速物体检测的多任务卷积网络.自然语言处理领域,Collobert等(2008)将语义角色标注、语言模型、词性标签、语块、命名实体标签等任务统一到一个框架中,利用辅助任务中自动学习得到的特征提升语义角色标注的性能.
在地球物理应用中,桑文镜等(2020)提出多任务残差网络,以叠前地震数据预测阻抗和含气饱和度.孙永壮和黄鋆(2021)将多任务学习用于岩性预测和横波速度预测,以横波速度预测为主任务,使用岩性预测任务辅助横波预测任务,从而提升横波速度预测效果.
现有地球物理测井机器学习的研究主要是基于单任务学习,单任务学习的局限性在于面对复杂问题时需要将其分解为多个单一独立的子问题,逐一解决再归纳合并,从而得到原始复杂问题的解(Caruana, 1998).然而地球物理测井中的许多复杂问题内部相互关联,无法分解为单一独立的子问题.此外,如果将储层参数预测分解为单任务处理,会忽略储层参数之间的关联信息.因此相较于单任务机器学习,多任务学习在储层参数预测方面更具优势.本文将多任务学习方法应用于储层参数预测任务,在学习共享多个储层参数之间的信息,使模型具有更好的泛化效果,提升储层参数预测精度.
1 方法
1.1 理论基础
本文使用的多任务模型基于深度神经网络(DNN),DNN可以看作是多层多维度的线性回归和各种线性或非线性激活函数的组合,通过梯度下降等方式根据损失函数的数值调节模型内部的权重(Haykin, 1998; Goodfellow et al., 2016; Michael, 2015).在使用DNN模型进行回归预测时,信息由输入层到输出层逐层运算,单个神经元的计算可以表示为:
(1)
其中,z为神经网络中某一个神经元,xi为上一层第i个神经元,wi为对应的权重,b为偏置权重,m为上一层中神经元个数,W=[w1,w2,…,wm],X=[x1,x2,…,xm]T.W和b统称为模型参数,参数初始化时一般随机赋值.
DNN模型的隐藏层后会连接激活函数δ(z),激活函数的非线性转换使神经网络的拟合能力进一步增强,使模型的预测结果不断逼近真实值(Goodfellow et al., 2016).本文使用的激活函数除线性函数(公式(2)),还有非线性的ReLU函数(公式(3))和SoftPlus函数(公式(4)):
δlinear(z)=z,
(2)
δReLU(z)=max(z,0),
(3)
δsoftplus(z)=lg(1+ez).
(4)
ReLU的非饱和性溃疡有效地解决梯度消失的问题,其单侧抑制提供了网络的稀疏表达能力.SoftPlus可以看作是ReLu的平滑.根据神经科学家的相关研究,softplus和ReLu与脑神经元激活频率函数有神似的地方.也就是说,相比于早期的激活函数(如softmax,tanh等),softplus和ReLu更加接近脑神经元的激活模型(Ciuparu et al., 2020).
深度神经网络多任务隐层参数共享分为硬共享与软共享(Ruder, 2017; Liu et al., 2016).参数的硬共享机制可以应用到所有任务的所有隐层上,保留任务相关的输出层,从而降低过拟合的风险(Caruana, 1993; Baxter, 1997).参数的软共享机制中每个任务都有独立的模型参数,对模型参数的距离进行正则化保障参数的相似(Duong et al., 2015).
研究表明,多任务学习从4个方面提升模型效果(Ruder, 2017):(1)噪声:对主任务而言,相关任务中与主任务无关的信息视作噪声,训练过程中噪声可以提高模型泛化效果;(2)逃离局部最优解:多任务学习中的不同任务的局部最优解常处于不同位置,在梯度传播时相互影响从而可以有效避免模型陷入局部最优解;(3)权值更新:多任务学习中权值更新受多个任务的影响,相较于单任务学习提升了底层共享层的学习速率;(4)泛化:多任务学习有可能影响单个任务的拟合能力,但降低模型过拟合几率,提升模型泛化能力.
总体而言,多任务学习中共享部分越多,噪声与泛化的影响越明显;参与学习的任务数量越多,逃离局部最优解与权值更新的效果越明显.
本文提出的基于多任务学习的测井储层参数预测方法将对几种描述油气藏的重要参数进行预测.传统测井解释方法中用自然伽马(GR)曲线或自然电位(SP)曲线计算地层泥质含量;用泥质校正后的声波时差(AC)、补偿中子(CNL)和密度(DEN)计算地层孔隙度(POR);用电阻率测井值(RT)、孔隙度(POR)及泥质含量来计算含水饱和度(SW);用井径(CAL)进行井眼校正;然后循环迭代,逐次逼近储层参数真实值(雍世和等, 2002).因此选取声波时差(AC)、井径(CAL)、中子(CNL)、密度(DEN)、自然伽马(GR)、电阻率(RT)以及自然电位(SP)作为输入数据,以孔隙度(POR)、渗透率(PERM)与含水饱和度(SW)的预测作为任务,使用多任务学习模型同时对三种储层参数进行预测,不必反复迭代校正储层参数,相较于传统测井解释方法,多任务学习在简化储层参数预测流程,并提升神经网络模型的预测效果与泛化能力.
下面将分析多任务模型损失函数的选取以及几种不同类型的多任务模型,并给出其应用于测井储层参数预测的具体方法.
1.2 多任务损失函数
多任务模型中损失函数的选择需要综合考虑每个任务的特点,并对每种任务分配合适的权重.若不同任务的量纲相同且数据分布区间大致重合或使用归一化等数据预处理方式,可使用常见的均方误差(Mean Square Error, MSE)、平均绝对误差(Mean Absolute Error, MAE)等损失函数,然后根据模型训练情况调整每种任务的权重.若任务间的差异较大或不方便进行数据预处理,适合使用受数据分布影响较小的损失函数,例如平均绝对值百分比误差(Mean Absolute Percentage Error, MAPE).
地球物理测井中,储层参数的数值分布区间不一致,根据本研究所采用的数据集统计得到:孔隙度大多分布于9.71±2.70%;渗透率大多分布于0.23±0.26(0.987×10-15m2);含水饱和度大多分布于66.61±16.75%.若使用MAE作为损失函数,模型训练时损失函数将由含水饱和度MAE主导,导致参数优化时会忽略渗透率和孔隙度对模型的影响,使渗透率和孔隙度拟合效果较差;若对其设置权重,对每个任务损失函数设置合适的权重有一定困难.因此选择MAPE作为损失函数,计算预测值与实际值误差的百分比,将不同储层参数的误差以统一的尺度表示,既可以保证每个储层参数在模型训练过程中都能得到较为充分的训练,又能避免损失函数权重设置不合理.
1.3 同架构多任务储层参数预测模型
首先是泛化性能最强的同架构多任务储层参数预测模型,其特点为除输出层每个储层参数独立计算,其余各层均共享神经元,如图1所示,记作multi_same_α.在multi_same_α中,多任务相互之间有较强的影响,当储层参数之间相关性较高时,权值更新作用显著,可以取得较好的预测效果;当储层参数之间差异较大时,噪声会导致预测效果不理想;由于每个任务没有私有隐藏层,模型对单个任务的拟合能力可能较差.
在神经网络模型中靠近输入层的网络提取的信息较为广泛,靠近输出层的网络提取的信息与输出值的关联性更大.因此将multi_same_α进一步改造,得到另一种泛化性能稍弱,但对单个任务拟合能力更强的同架构多任务储层参数预测模型,其特点在于靠近输入层的隐藏层为共享层,靠近输出层的隐藏层为结构相同的私有层,如图2所示,记作multi_same_β.三个储层参数共同影响共享层的训练,多任务模型中的权值更新方式辅助提升广泛信息提取的效果;每个储层参数的私有层仅受当前储层参数的影响,仅从共享网络的输出中提取与当前储层参数有关的信息,减少其他储层参数对当前储层参数预测效果的影响.该模型的泛化性能和拟合能力取决于私有层结构,一般而言私有层越少泛化性能越好,私有层越多拟合能力越强.
1.4 基于异架构多任务储层参数预测模型
为获得更好的储层参数拟合效果,进一步提出异架构多任务储层参数预测模型,该模型的特点为靠近输入层的隐藏层为共享层,每个储层参数的私有层结构各不相同,如图3所示,记作multi_diff.该模型保留了multi_same_β模型使用权值更新方式辅助提升广泛信息提取效果的优点,并且灵活性更好,每个储层参数可以根据自身特点定制不同的私有层从而更好地从共享网络输出的信息中提取信息.例如声波时差、补偿中子和密度与孔隙度呈近似线性的关系,输入输出之间的映射较为简单,因此孔隙度私有层结构较为简单;含水饱和度受地层电阻率、泥质含量、孔隙度等因素的影响,输入输出之间呈非线性关系,因此含水饱和度私有层结构相对复杂;渗透率与测井曲线之间的映射较难确定,因此渗透率私有层的结构最复杂.multi_diff模型的泛化能力取决于共享层结构,共享层层数越多泛化性能越好,反之亦然.

图1 同架构多任务储层参数预测模型α(multi_same_α)Fig.1 Multitask reservoir parameters prediction model α with the same structure(multi_same_α)

图2 同架构多任务储层参数预测模型β(multi_same_β)Fig.2 Multitask reservoir parameters prediction model β with the same structure(multi_same_β)
2 实例分析
2.1 数据描述与数据处理方式
实验数据来自于某油田的64口井的常规测井数据,该区块为致密砂岩储层,低孔、低渗、低对比度.井眼环境校正和井间标准化等处理过程已由数据提供方完成,进行数据清洗和异常值校正后数据集共包含5571条数据,具体特征分布如表1所示.孔隙度、渗透率与含水饱和度为油田的常规测井处理结果,其交会分析图如图4所示,孔隙度与渗透率呈较强的正相关性,含水饱和度与孔隙度、渗透率之间均存在一定的负相关性.训练集和测试集按8∶2的比例随机划分,训练集中含有4456条数据,测试集中含有1115条数据.
2.2 实验设计
实验中使用的模型及编号如表2所示.三种多任务模型的结构与具体参数设置参见附录表A1—A3,为验证多任务模型储层预测提升效果,构建单任务储层参数预测模型进行对照实验.单任务模型的输入数据与多任务模型相同,仅输出一个储层参数的预测结果.多任务模型中的参数涉及多个任务的计算,而在单任务模型所有参数只涉及一个储层参数的计算,多任务模型训练速度相对缓慢.考虑多任务模型训练速度下降影响,实验中的单任务模型分别训练3000轮和10000轮,多任务模型统一训练10000轮.同架构单任务模型命名方式为“储层参数_same_训练轮数”,具体模型结构与参数设置参见附录表A4.异架构单任务模型具体模型结构与参数设置参见附录表A5.本次实验的模型参数为随机初始化,为保障实验结论的可靠性,所有模型进行5次训练.模型训练使用Adam优化器,该优化方法是基于SGD改进得到的,可以代替经典的随机梯度下降法来更有效地更新网络权重,近些年已成为应用最广泛的神经网络优化算法之一.Adam优化器的优点有:计算效率高;内存需求少;梯度的对角线重缩放不变;适合大数据或大模型的训练;适用于非固定目标;适用于非常嘈杂或稀疏梯度的问题;超参数调节方便(Kingma and Ba, 2014).

表1 实验数据统计分析Table 1 Statistical analysis of experimental data

图3 异架构多任务储层参数预测模型(multi_diff)Fig.3 Multitask reservoir parameter prediction model with different structure(multi_diff)

图4 孔渗饱交会分析图 (a) 孔隙度-渗透率交汇图; (b) 孔隙度-含水饱和度交汇图; (c) 渗透率-含水饱和度交汇图.Fig.4 Cross analysis Figure of porosity, permeability and water saturation (a)Porosity-permeability cross plot; (b) Porosity-water-saturation cross plot; (c) Permeability-water-saturation cross plot.

表2 实验模型统计与编号Table 2 Statistics and numbering of experimental models
模型评价指标使用平均相对误差(MAPE)和平均绝对误差(MAE),误差越小模型表现越好,取5次测试结果评价指标的最大值、最小值与中位数综合衡量储层参数预测效果.由于多任务模型同时输出三种储层参数,无法分割,在计算最大误差值、最小误差值和中位误差值时使用三种储层参数的误差总和.从训练效果看含水饱和度的MAE与孔隙度和渗透率的MAE存在量级上的差别,因而使用MAPE作为模型主要评价指标,MAE用于辅助单个储层参数预测效果的评价.
2.3 实验结果
2.3.1 同架构模型测试结果
同架构的单任务与多任务储层参数预测模型在测试集上的测试效果如表3所示.
根据各项评价指标,训练10000轮的单任务模型预测效果优于训练3000轮的单任务模型;multi_same_α与multi_same_β模型的预测效果优于训练10000轮的单任务模型;multi_same_β模型的预测效果略优于multi_same_α模型.与对照实验中训练10000轮的同架构单任务模型在测试集上的MAPE相比,multi_same_α模型的孔隙度预测效果提升超过30%,渗透率预测效果提升约22%,含水饱和度预测效果提升8%左右;multi_same_β模型的孔隙度预测效果提升超过30%,渗透率预测效果提升约24%,含水饱和度预测效果提升超过10%.

表3 同架构的单任务与多任务储层参数预测模型测试结果Table 3 Test result of single-task and multitask reservoir parameters prediction models with same structure
2.3.2 异架构模型测试结果
异架构的单任务与多任务储层参数预测模型在测试集上的测试效果如表4所示.
在对照实验中,POR_diff_10000模型在测试集上的MAPE明显低于POR_diff_3000模型,若继续训练,该模型或许还有性能提升空间.其余两种储层参数预测模型训练3000轮和10000轮的MAPE差距较小,说明这两种模型已到达性能极限,无法通过训练提升模型性能.对比训练10000轮的对照实验模型在测试集上的预测效果,multi_diff模型孔隙度预测效果基本没有提升,渗透率预测效果提升超过60%,含水饱和度预测效果提升超过10%.
从测试集上的表现来看,异架构多任务储层参数预测模型的综合预测效果优于同架构的多任务模型,就每个储层参数而言:
(1)multi_diff模型、multi_same_α模型和multi_same_β模型中孔隙度的预测效果差别不大,MAPE在6%左右.
(2)multi_diff模型的渗透率在测试集上的MAPE在13%左右,multi_same_α和multi_same_β模型的渗透率在测试集上的MAPE在17%左右.
(3)multi_diff模型的含水饱和度在测试集上的MAPE在6%左右,multi_same_α和multi_same_β模型的含水饱和度在测试集上的MAPE在9%左右.

表4 异架构的单任务与多任务储层参数预测模型测试结果Table 4 Test result of single-task and multitask reservoir parameters prediction models with different structure
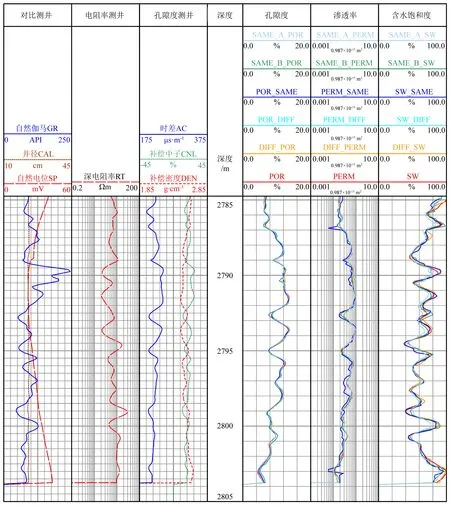
图5 不同网络预测实际应用效果对比图Fig.5 Comparison of practical application performance of different network
实验中使用的各个储层参数预测模型的预测效果图如图5所示.其中,POR、PERM、SW为储层参数标签数据;SAME_A_POR、SAME_A_PERM、SAME_A_SW为multi_same_α模型预测的孔隙度、渗透率和含水饱和度;SAME_B_POR、SAME_B_PERM、SAME_B_SW为multi_same_β模型预测的孔隙度、渗透率和含水饱和度;DIFF_POR、DIFF_PERM、DIFF_SW为multi_diff模型预测的孔隙度、渗透率和含水饱和度;POR_SAME、PERM_SAME、SW_SAME分别为POR_same_10000、PERM_same_10000和SW_same_10000模型的预测值;POR_DIFF、PERM_DIFF、SW_DIFF分别为POR_diff_10000、PERM_diff_10000和SW_diff_10000模型的预测值.从总体预测效果来看孔隙度预测值与标签值最接近;PERM_same_10000模型预测的渗透率与标签值的误差较大,其余模型预测的渗透率和标签值相差不大;三种储层参数中含水饱和度的预测值和标签值差距最大,但总体趋势和标签值相吻合.
3 结论
多任务测井储层参数预测模型可以有效提升单任务储层参数预测模型的预测效果,效果提升幅度与模型结构有关.多任务模型不仅节省计算资源,还简化了储层参数获取流程.
异架构的多任务储层参数预测模型总体预测效果最好,具有可以针对每种储层参数单独设计私有层架构的特点,有良好的研究前景.
我们还进行了迁移学习测井储层参数预测的研究,以孔隙度预测模型作为基础模型对渗透率预测模型和含水饱和度预测模型进行参数迁移.两项实验使用同一个数据集,对比两项实验的结果可以发现,异架构多任务模型的渗透率和含水饱和度预测效果优于迁移学习的渗透率和含水饱和度预测效果(邵蓉波 et al., 2022).多任务学习和基于相关性的迁移学习均是利用储层参数之间的相关性影响模型参数的更迭,从而提升神经网络模型的预测效果.在迁移学习中这种影响是单向的,孔隙度可以影响渗透率预测模型的训练,而渗透率无法对孔隙度预测模型产生影响,使用迁移学习可以控制信息流动的方向.在多任务模型中这种影响是相互的,孔隙度在影响渗透率预测的同时孔隙度的预测也受到渗透率的影响,无法对信息流动方向进行人为限制.因此两种方式各有利弊,可根据实际情况选择合适的模型.根据实验中发现的问题,下一步研究还将从以下几个方面展开:
(1)探究不同类别激活函数之间的适配性对多任务储层参数预测模型效果的影响.
(2)尝试不同模型架构,探究在多任务模型中模型架构对提升储层参数预测效果的影响.
(3)考虑使用参数软共享方式进行多任务学习.
(4)测井数据有较强的序列性,可以考虑将基于异架构多任务储层参数预测模型推广至循环神经网络模型中,例如LSTM和GRU.
(5)借鉴图像处理方式处理测井数据,并将基于异架构多任务储层参数预测模型推广到卷积神经网络模型中.
致谢外审专家对本文提出了建设性的修改意见,课题组郭云龙帮助本文绘图,在此一并致谢!
附录

附表A1 同架构多任务储层参数预测模型α构造与参数Appendix Table A1 Parameters of multitask reservoir parameters prediction model α with the same structure

附表A2 同架构多任务储层参数预测模型β构造与参数Appendix Table A2 Parameters of multitask reservoir parameters prediction model β with the same structure

附表A3 异架构多任务储层参数预测模型结构与参数Appendix Table A3 Parameters of multitask reservoir parameters prediction model with different structure

附表A4 同架构单任务储层参数预测模型构造与参数Appendix Table A4 Parameters of single-task reservoir parameters prediction model with same structure
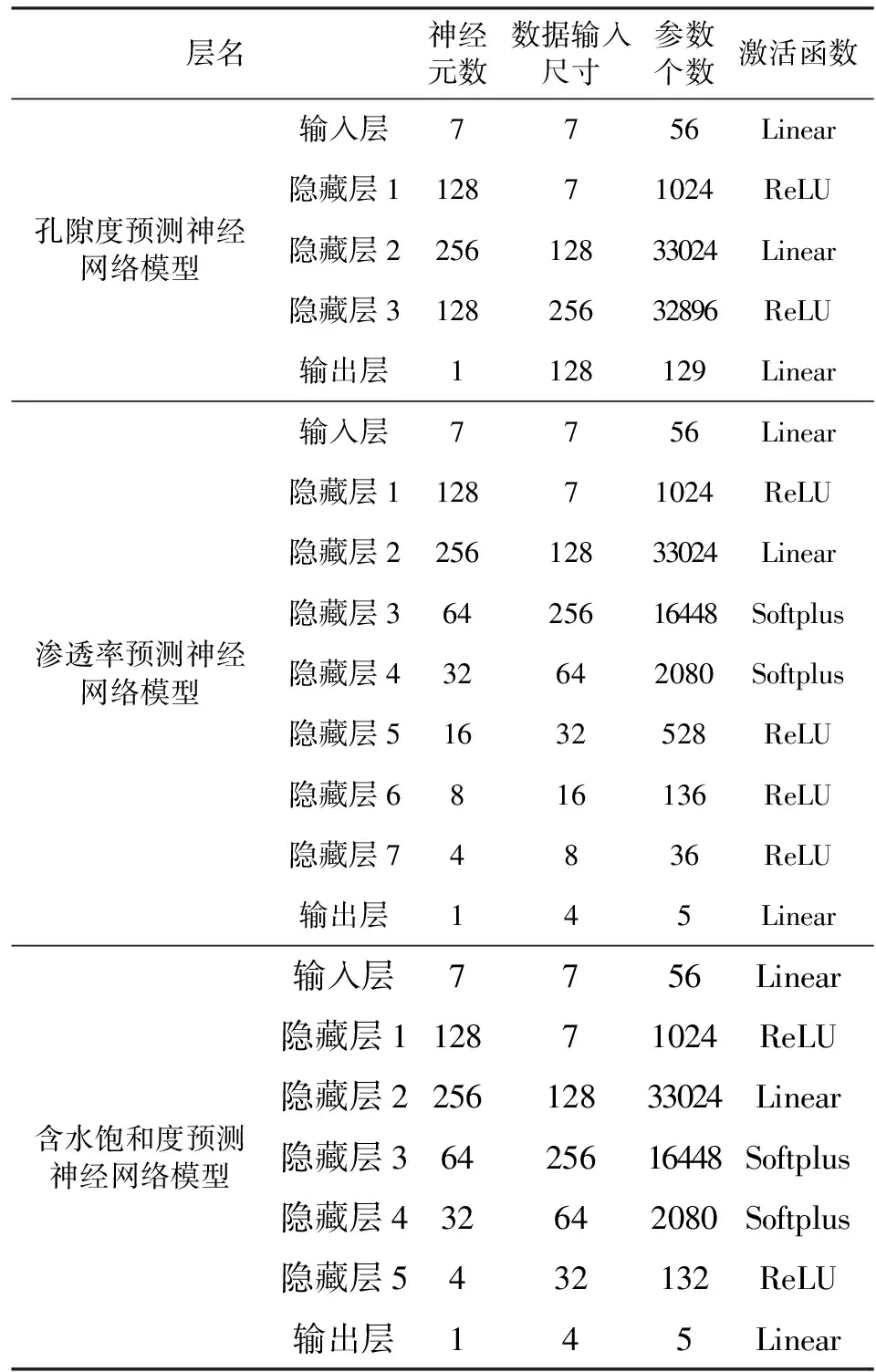
附表A5 异架构单任务神经网络模型结构与参数Appendix Table A5 Parameters of single-task reservoir parameters prediction models with different structure
