面向燃煤机组高效灵活运行的智能化配煤掺烧优化决策方法
2022-04-30张海林杨博董玉亮张健袁家海
张海林,杨博,董玉亮,张健,袁家海
(1.中国华能集团有限公司,北京 100031;2.华北电力大学能源动力与机械工程学院,北京 102206;3.华北电力大学经济与管理学院,北京 102206)
为实现碳达峰、碳中和目标,需要逐步建成以新能源为主体的新型电力系统。然而,随着大规模可再生能源接入,电源侧随机性波动增加,维持系统平衡的难度不断加大,灵活调节电源缺乏的问题日益凸显。目前,我国发电装机仍以煤电为主,抽水蓄能、燃气发电等灵活调节电源装机占比不到6%。“三北”地区新能源富集,其风电、太阳能发电装机分别占全国的72%和61%,但灵活调节电源不足3%,调节能力严重不足。因此,近期迫切需要燃煤机组深度挖掘其灵活运行潜力,保证新型电力系统的安全、可靠运行。
燃煤机组灵活性运行能力主要体现在负荷调节深度、升降负荷速率及启停机时间3 个方面。为提高燃煤机组的灵活性,发电企业对燃煤机组进行了一系列的技术改造[1],如深度调峰改造[2-3]、热电解耦改造[4-7]、电源侧配置储能设备[8]及机组运行控制策略改进[9]等。此外,大量研究[10-15]表明,通过配煤掺烧优化也有助于实现机组安全、高效、灵活运行。文献[10]分析了燃煤电厂常用的间断性掺烧、预混掺烧及分磨掺烧方式的特点和不同掺烧方式与混煤燃烧性能的关系。文献[11-12]对配煤掺烧开展试验和数值模拟研究,获得配煤燃烧特性,为机组配煤掺烧安全经济运行提供了依据。文献[13]建立了无约束多目标配煤掺烧优化模型,并利用遗传算法实现最优配煤。文献[14-15]在建立相应配煤掺烧优化模型的基础上,开发了在线配煤掺烧决策系统。总之,当前燃煤机组配煤掺烧主要是通过锅炉配煤掺烧性能试验或配煤优化模型进行决策,在保证锅炉安全运行前提下,机组经济性最佳。然而,新能源电力系统要求燃煤机组更加频繁地参与深度调峰,常规调峰工况的配煤掺烧策略将不再适用。另外,随着煤炭市场供求关系的实时变化,单一煤种标单价(按照发热量折算成标准煤的单价)和不同煤种之间的价格差(标单价差)也将不断变化,当入炉煤的标单价差发生变化时,同样的配煤掺烧策略产生的经济效益也会有很大差异[16]。因此,在当前背景下一方面需要加强燃煤机组深度调峰工况下配煤掺烧智能化决策研究,通过配煤方案的智能灵活调整,支撑机组的灵活运行;另一方面需要充分考虑煤价的动态变化特点,保证配煤掺烧的经济性。
为此,本文提出一种基于动态数据包络分析(dynamic data envelopment analysis,DDEA)和模式匹配(pattern matching,PM)的智能化配煤掺烧优化决策方法。通过动态 SBM(slacks-based measure)模型对燃煤机组运行历史数据进行分时段全局效率评价,通过在动态SBM 模型的输出变量中引入燃煤机组锅炉安全性能指标(炉膛出口烟温、炉膛负压、受热面壁温等)和机组灵活性性能指标(负荷上/下限、负荷变化率),使得全局效率能同时体现经济性、安全性和灵活性的需求。根据评价结果建立可以动态更新的配煤掺烧决策数据库(含运行工况、配煤方案和全局效率)。针对未来某一决策周期,根据机组运行工况参数的预测值,通过PM 模型在数据库中搜索匹配度高的运行工况,并根据全局效率的高低决定下一决策周期的最佳配煤方案。
1 燃煤机组智能化配煤掺烧优化
本文提出的燃煤机组智能化配煤掺烧优化决策框架如图1 所示。

图1 燃煤机组智能配煤掺烧优化决策框架Fig.1 The decision making frame of intelligent coal blending optimization for coal-fired unit
根据图1 决策框架可见,配煤掺烧具体优化决策流程如下:
1)利用机组的历史运行数据,根据功率进行稳态数据筛选,去除非常规运行调整快速变负荷时段的运行数据;
2)选定输入参数、输出参数,建立基于动态SBD 的机组效率数据包络分析(DEA)评价模型,计算获得各历史决策周期机组全局效率值;
3)建立包含机组运行工况、全局效率、混煤方案的机组配煤掺烧优化决策数据库;
4)根据机组电力市场交易后的日前计划负荷曲线、天气预报和当前运行工况,预测下一决策周期机组的运行工况;
5)建立基于余弦相似度的机组运行工况模式匹配模型,在机组配煤掺烧优化决策数据库搜索与下一决策周期运行工况相匹配的模式,并根据各匹配模式的效率值进行优先级排序,将能效最高的模式对应的配煤方案作为下一决策周期的配煤掺烧方案;
6)执行配煤掺烧方案,并根据运行数据进行效果评价,并补充完善配煤掺烧优化决策数据库。
2 配煤掺烧优化决策方法
2.1 运行数据稳态筛选
新型电力系统下,燃煤机组作为高比例可再生能源并网的保障,需要经常对其运行工况进行快速调整以满足电网负荷要求,因而机组运行状态具有非平稳特性。如果机组运行参数在一定时间内能够稳定在某一范围内,则认为机组处于稳态,否则机组处于非稳态。由于非稳态运行参数不具备反映机组真实运行状况的能力,所以在进行机组运行能效评价之前需要把非稳态数据剔除。
本文采用一种滑动窗口方法[17]将电厂数据进行稳态筛选,剔除非稳态数据。滑动窗口表示在数据流上滑动的数据串窗口,且一般沿时间向前滑动。数据窗口的长度保持不变,即随着窗口的不断滑动窗口内的数据量保持不变。因此,整体呈现窗口不断更新第N个数据并舍弃最早数据的先进先出机制。简捷有效的特征使该方法在信息处理方面得到广泛的应用。
从数据统计的角度考虑,当滑动窗口至第N个负荷指令时,窗口内的S+1 个数据的相对标准差需满足一定精度,可认为第N个运行工况处于稳态,即:

式中:δ为无量纲量相对标准差为滑动窗口内S+1个数据的平均值;ε为相对标准差的精度要求。当满足δ<ε时,第N个运行工况满足数据稳态筛选要求。
2.2 动态SBM 数据包络分析模型
DEA 是一种非参数的管理系统效率度量方法。与回归分析(regressive analysis,RA)和随机前沿(stochastic frontier approach,SFA)方法等参数统计方法不同,DEA 可以在不需要设置特殊生产函数或一系列未知参数的情况下获得决策单元(decision making unit,DMU)的全局效率得分。DEA 作为一种简单有效的效率评价方法,在火电机组全局效率评价中得到广泛的应用[18-20]。但由于DEA 忽略了结转活动,不适于衡量长期动态效率。纳入结转活动的动态SBM 模型[21]可用于长期跟踪效率变化,并能够基于整个期间的长期优化来衡量特定时期的效率。动态SBM 数据包络分析模型结构如图2 所示。

图2 动态SBM 数据包络分析模型结构Fig.2 The structure of dynamic slacks-based measure data envelopment analysis model
由图2 可见,假定对k个DMUs(j=1,2,…,k)分别进行T个时段(t=1,2,…,T)的评价,在每个评价时段,DMUs 采用d个输入量(i=1,2,…,d),c个结转量(e=1,2,…,c),得到g个输出量(f=1,2,…,g)。令xijt、yijt分别表示第j个DMU 在第t时段的输入和输出量。zejt表示不良结转值,其中c为不良结转的数量。
生产可能性集合{xit}、{zet}和{yft}可以按下列各式表示:

式中:λjt为周期t的强度变量;xijt、zejt和yfjt均为正向数据;xit、zet和yft均为与强度变量λjt相连接的变量。
输入导向型决策单元DMUo(o=1,2,…,k)的效率可以通过解以下线性规划得到:


考虑到燃煤机组运行中通常在每个运行值(通常为8 h)进行一次配煤掺烧方案调整,并根据运行效率对该值进行考核,本文选取8 h 作为一个决策周期,即T=8 h,每个决策周期又由8 个时段,即8 个决策单元(DMUs)组成。
新型电力系统对燃煤机组运行的经济性、安全性和灵活性提出了更高的要求,因此本文中机组全局效率评价不仅考虑运行经济性,而且考虑安全性和灵活性。对于配煤掺烧,影响每个DMU 全局效率(经济性、安全性和灵活性)的输入变量主要包括人力成本、资产折旧、煤价、煤质、煤耗量、煤热值。表征DMU 全局效率的输出变量主要可以分为3类[22]:经济性、安全性和灵活性。本文选择短期(1 h)运行时段作为决策单元,因此人力成本和资产折旧可以视为常数,不考虑在模型输入变量内。
因此,本文中DMU 选取1 h 入炉煤总热值、水分平均值、灰分平均值、挥发份平均值、硫分平均值和总燃料成本作为输入变量;1 h 上网电量、火检强度平均值、机组出力上下限、最大升降负荷率作为I 类输出变量;炉膛负压指数、炉膛出口烟气超温指数、受热面超温指数、SO2排放超标指数和NOx排放超标指数作为II 类输出变量。其中I 类输出变量为期望输出变量,II 类输出变量为非期望输出变量。
综合以上分析,每个DMU 动态SBM 模型变量见表1。

表1 动态SBM 模型变量Tab.1 Variables of the dynamic SBM model
表1 中,入炉煤总热值可以根据决策单元相应时段内不同种煤入炉量和相应的热值计算得到;入炉煤水分、灰分、挥发份和硫分可由煤质化验数据获得;燃料总成本可根据入炉不同种煤的煤量和煤价计算得到;上网电量可由该时段内上网功率数据计算获得;火检强度可由炉膛燃烧监测系统获得;机组出力上、下限和最大升/降负荷率可根据对应配煤方案下的性能试验得到,并采用运行数据加以更新。
II 类输出变量Vi可根据式(10)进行量化。

式中:ti为第i个II 类输出变量(含多个测点情况)1 h 内超过报警I 限的累积时间,min。
根据以上数据,利用动态SBM 模型可以计算得到8 个决策单元的效率指标,进而获得该决策周期的全局效率指标。
2.3 基于模式匹配的机组配煤掺烧优化决策
利用动态SBM 模型的全局效率评价结果,可构建包含运行工况参数(最大出力、最小出力、平均出力、出力方差、最高气温、最低气温、平均气温、气温方差、空气平均湿度)、全局效率和相应配煤方案的历史决策周期优化决策数据库。优化决策数据库结构见表2。

表2 决策数据库结构Tab.2 The structure of decision database
由于本文只分析不同配煤方案对机组整体效率的影响,因此将运行工况参数作为外部参数。针对下一决策周期,利用日前计划负荷曲线和天气预报计算获得相应的运行工况参数,通过相似度计算搜索出匹配度较高的历史运行工况,并根据全局效率最高作为匹配原则,确定为最佳匹配工况,将其对应配煤掺烧方案作为下一决策周期的最优配煤方案。
本文采用余弦相似度进行模式匹配,即用向量空间中2 个向量夹角的余弦值作为衡量2 个个体间差异大小的度量。余弦相似度取值范围为[-1,1],余弦值越接近1,就表明夹角越接近0,也就是2 个向量越相似,称为“余弦相似性”。
针对2 个运行工况向量α=[w11,w12,…,w1n]和β=[w21,w22,…,w2n],其余弦相似度按式(11)计算:

3 实例分析
某燃煤电厂由2 台亚临界300 MW 纯凝机组组成,机组历史运行数据取自厂级监控系统(SIS),数据间隔为1 min。利用上文滑动窗口方法进行稳态数据筛选。运行数据中,机组功率在稳态过程中变化趋势平稳,在非稳态过程中变化明显,所以将机组功率作为稳态筛选的判别基础。在数据筛选过程中先剔除停机阶段数据,计算出相邻2 组数据的差值后先初步判别是否在规定范围内,然后采用滑动窗口法进行稳态判别,规定窗口长度m=10,相对标准差(relative standard deviation,RSD)的精度要求ε=0.035。以2020 年1 月10 日运行数据为例,稳态筛选前后机组功率曲线如图3 所示。

图3 稳态筛选前后机组功率曲线Fig.3 Change curves of the unit power before and after steady-state screening
对稳态筛选后的数据进行逐小时的DMU 动态SBM 效率评价,其中含非稳态数据的DUM 输出效率为Null。仍以2020 年1 月10 日数据为例,2 台机组整体效率评价结果见表3。
表3 中同时列出了采用数据包络分析CCR 模型计算出的效率,由表2 可以看出,考虑径向和角度的CCR 模型比非径向、非角度的动态SBM 的测评效率值高,存在一定程度高估偏差;同时SBM 模型计算效率值的波动幅度明显,而CCR 模型对机组效率的波动有一定程度掩盖。根据表3 中机组效率评价数值,计算3 个决策周期(8 h)的平均效率,结果见表4。为实现燃煤机组智能化配煤掺烧决策,需要建立包含气温(最大值、最小值、平均值、方差)、湿度(平均值)、功率(最大值、最小值、平均值、方差)、全局效率和配煤方案的各历史决策周期(8 h)数据库。利用机组运行期间当地气象数据(逐时的气温、湿度等),通过数据处理可以得到各决策周期内的最大值、最小值、平均值和方差。
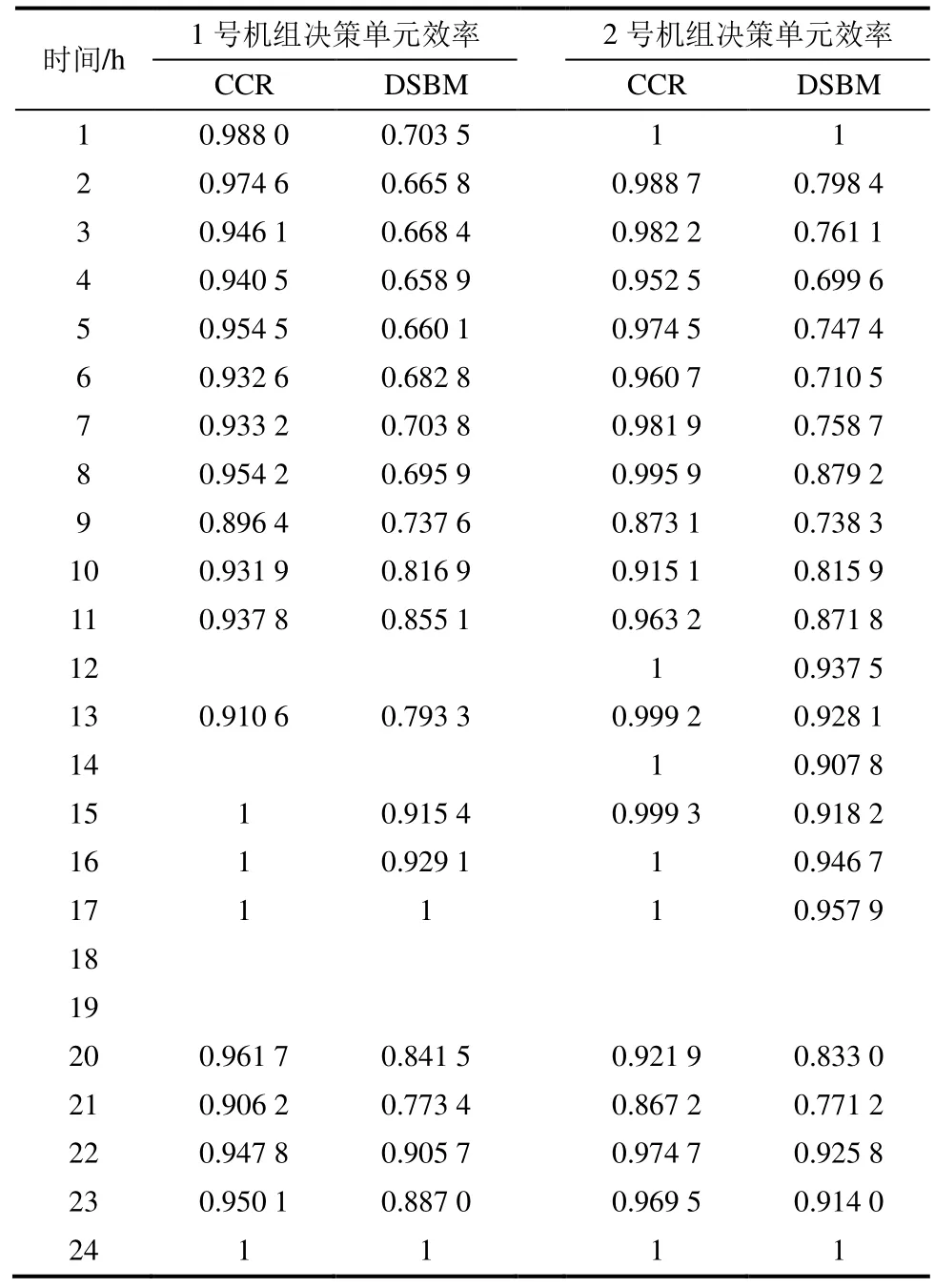
表3 2 台机组整体效率评价结果Tab.3 The whole efficiency evaluation results of the two units

表4 决策周期平均效率Tab.4 Average efficiency of each decision cycle
图4 为处理后的历史决策周期运行工况天气(气温和湿度)数据。图5 为历史决策周期机组功率最大值、最小值、平均值和方差。

图4 历史决策周期运行工况参数(天气)Fig.4 The operating condition parameters (weather) of historical decision cycle
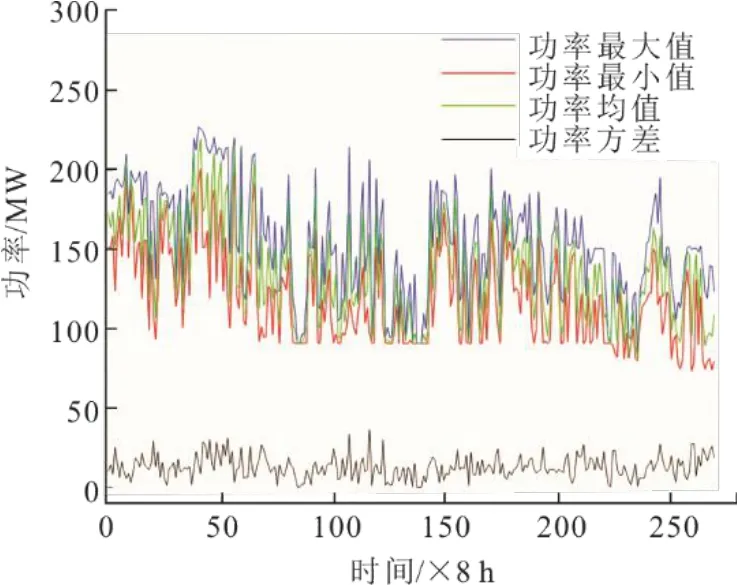
图5 历史决策周期运行工况参数(功率)Fig.5 The operating condition parameters (power) of historical decision cycle
结合各决策周期的全局效率评价结果和采用的配煤方案可得到机组配煤掺烧优化决策历史数据库,部分数据见表5。

表5 燃煤机组配煤掺烧优化决策历史数据库Tab.5 Historical data base of coal blending optimization decision of coal-fired units
对于未来决策周期而言,根据该机组日前计划负荷曲线和天气预报数据,经过数据处理可以得到该决策周期的运行工况参数,利用余弦相似度公式,可以匹配到最相近的4 个工况,然后根据这4 个工况全局效率评价值的大小,便可以决定混煤方案的优先选取顺序。以2021 年1 月的3 个决策周期为例,配煤掺烧优化决策结果见表6。

表6 燃煤机组配煤掺烧优化决策结果Tab.6 Decision results of coal blending optimization of coalfired units
运行中机组依据表5 中优化决策方案进行配煤掺烧调整,运行后根据运行历史数据进行评价,评价结果显示机组同时达到了较高的经济性和运行灵活性,实现了配煤掺烧的优化。
4 结论
配煤掺烧优化是降低燃煤机组发电成本、提高机组运行经济性和灵活性,进而适应新型电力系统要求的重要措施之一。
1)本文提出了一种面向燃煤机组高效灵活运行的配煤掺烧优化决策框架,可以实现机组配煤掺烧的智能化决策。
2)充分考虑煤质(工业分析成分和发热量)、煤价等影响配煤掺烧的主要因素,建立了包括经济性、安全性和灵活性指标在内的基于动态SBM 的燃煤机组全局效率评价模型,使评价结果兼顾了机组运行的经济性、安全性和灵活性。
3)利用对机组历史决策周期的效率评价,建立了燃煤机组配煤掺烧优化智能决策数据库,并给出了基于余弦相似度的运行工况模式匹配方法,实现了配煤掺烧的智能优化决策。
