基于三者对抗生成网络的人脸转正方法
2022-04-29李壮


摘要:针对大姿态人脸转正的图像生成效果较差问题,文章建立了一种基于生成器、判别器和分类器三者对抗的生成对抗网络(GAN)人脸转正方法。实验中通过引入超参数6进行比例控制生成器和判别器的交替训练,避免模式崩溃并提高了训练效率。大姿态人脸转正实验表明,该方法在CFP数据集对侧脸转正效果的Rank识别准确率达到了68.7%,与 DR-GAN相比提高了4.4%,验证了所提出的方法能够有效生成正面人脸图像且较好地保留人脸的身份特征。
关键词:人脸转正;生成对抗网络﹔三者对抗;分类器;特征提取中图法分类号:TP391文献标识码:A
Face correction method based on three-player adversarial generative network
Ll Zhuang
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306,China)
Abstract: A generative adversarial network (GAN) face correction method based on a three-playeradversarial approach of generator,discriminator and classifier is established to address the problem ofpoor image generation for large pose face correction. The experiments are conducted by introducinghyper-parameters 6 for alternate training of the proportional control generator and discriminator toavoid pattern collapse and improve the training efficiency.For the face turning experiments with largepose,the method achieves 68.7% Rank recognition accuracy for the side-face turning effect in theCFP data-set,which is 4.4% better compared with DR-GAN. It is verified that the proposed methodcan effectively generate frontal face images and better preserve the identity features of faces.
Key words: face transformation,generative adversarial network , triplet adversarial, classifier, featureextraction
1 引言
人脸识别系统主要依赖正面人脸图像判别人物身份,由于人脸本身具有非刚体性,在采集图像时会受到一些外在因素(如光照、视角、表情等)制约,而容易引起系统误判。比如,随着人脸姿态的变化,面部特征会受到不同程度遮挡,视角差异导致人脸转角越大越难以识别其身份。本文研究从大角度姿态的侧脸图像中恢复出正脸图像,以便利用侧面人脸图像进行人物身份识别、人机交互等实际智能应用。
传统人脸转正方法主要基于统计学和图形学,一般通过2D/3D 局部纹理变形或者建模旋转生成正面人脸,但生成图像效果差且耗时长。深度学习方法能使网络模型直接学习端到端的非线性映射,可以将侧脸图像转换成正脸的姿态校正问题视为侧脸到正脸的非线性映射。利用卷积神经网络、自编码网络和生成对抗网络等对侧面人脸图像的特征学习、提取更加细致,可使生成的正面图像的真实性更高。Yin 等[ 1] 提出了一种针对大姿态人脸校正的 FF?GAN ( Face Frontalization Generative Adversarial Network)方法,将3D 形变模型结合到生成对抗网络中以提供人脸形状和外观先验知识。其对非受限数据集的人脸转正适应能力强,但人脸图像生成效果需提高。Huang 等[2] 提出双通道生成对抗网络 ( Two?Pathway GAN ,TP? GAN),利用两个深度卷积网络分别学习侧脸图像的全局结构和局部纹理细节。通过融合两条通路的全局信息与局部特征进行正脸视图的合成,能够更好地保留轮廓细节信息。虽然能获得很真实的人脸转正效果,但其需要在人脸照片中定位人脸五官位置。在训练和测试过程中,需要人工标注劳动力和大的计算机算力,人脸转正时间较长。
为进一步提高侧脸转正生成图像的质量,本文建立了一种三者对抗生成网络的人脸转正方法。针对传统 GAN ,在生成器和判别器中引入自编码结构,并结合分类器形成三者对抗,进行人脸转正。
2 三者对抗的生成网络模型
传统生成对抗网络中生成器通常是简单卷积神经网络,而判别器为二分类器,对于侧脸图像的特征提取和判别能力低,影响图像生成效果。本文在使用生成对抗网络模型的基础上结合自编码技术构建生成器与判别器,对于侧脸信息的特征提取和正面人脸图像的生成有着高效率和高质量的作用。通过引入分类器,参与生成器与判别器的对抗训练,形成三者对抗,以提高特征信息保留能力。
该模型结构如图1 所示。整个网络由三部分组成,分别是生成器 G、判别器 D 和分类器 C 。其中,生成器包含编码器和解码器。c 和 z 分别表示姿态信息和随机噪声,Ip 表示人脸生成图像,Ir表示真实人脸输入图像。判别器 D 和分类器 C 的输入皆为 Ip 和Ir,判别器 D 要使 Ip 和Ir尽可能接近,以提高生成图像的质量。分类器 C 为提前训练好的 Light ?CNN,协助判别器 D 与生成器对抗,以达到有效保留人脸身份特征的目的。首先针对每张人脸图像标记身份信息 yd 和姿态信息yp,即输入带标签的人脸图像样本Ir { yd ,yp };在包含编解码结构的生成器 G 中,编码器将侧脸图像经过卷积层后提取到人脸的综合特征信息,当解码器接收到特征信息和姿态信息后,结合随机噪声进行人脸的正面图像还原;然后将生成图像 Ip 和真实图像Ir分别输入到判别器 D 和分类器 C 中,依靠反馈并与生成器协同对抗训练;最后生成图像逐步修正为輸出目标姿态图像。
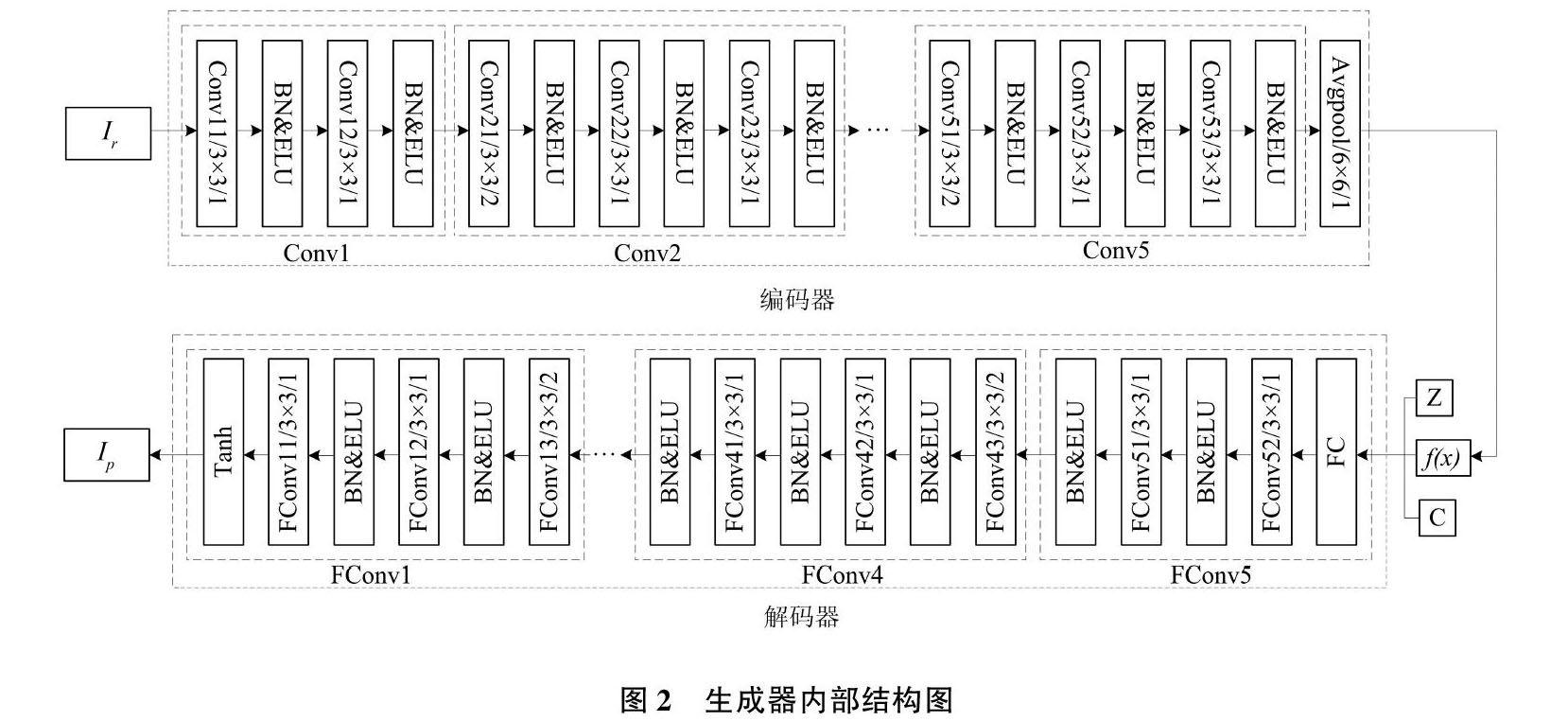
2.1 生成器结构
生成器 G 内部结构如图2 所示,包括编码器和解码器两部分。其中,编码器由 Conv 1、Conv2、Conv3、 Conv4和 Conv5组成,采用小卷积核和深层次的网络结构,以减少网络参数,并增加网络非线性,更适用于侧面人脸的特征提取。输入为真实人脸图像Ir,在 Conv 1 中用卷积核为 3× 3,步长为1 的 Conv 11 和 Conv 12来调节通道数,以线性组合不同通道上的像素点,再进行非线性化处理。在每个卷积层后分别应用 BN(batch normalization )层进行批量归一化来防止过拟合,再经由激活函数指数线性单元( exponential linear unit,ELU)形成特征图;然后依次通过卷积核为3×3,步长为2 的 Conv21、Conv22和 Conv23进行浅层特征提取;再经由 Conv3、Conv4和 Conv5(与 Conv2结构相同)进一步深层次提取特征。最后通过卷积核为6×6,步长为1 的平均池化层输出1×1×320维更具有高层语义的特征向量f( x )。
解码器的主要任务是生成人脸图像,采用数据还原原理,内部结构为反卷积网络。将编码器学习的身份表示特征向量f( x ),和姿态信息 c 和随机噪声 z 融合合成人脸图像。解码器包括5 个,分别为 FConv5、 FConv4、FConv3、FConv2和FConv 1。首先经过由卷积核为3×3,步长为1 的 FConv52和 FConv51以及每个反卷积层后分别应用 BN 层和 ELU 激活函数组成的 FConv5;再经过4 组相同结构反卷积网络 FConv4、 FConv3、FConv2和FConv 1的反卷积操作后,输出生成的正面人脸图像,即 Ip =G(Ir,c ,z )。与前几层不同的是,FConv 11后采用 Tanh 激活函数,最终生成正面人脸图像。生成器的主要目标是增强生成人脸图像的真实性以混淆判别器。生成器损失函数参见式(1):
式中,Ddyd (G(Ir,c ,z ))表示生成器努力将生成图像分类到对应的真实样本所属的类上,Dy(p)t ( G( Ir,c ,z ))则表示生成器将生成样本分类到正确的姿态上。与判别器的目标不同,生成器在训练中须形成对抗。
2.2 判别器结构
模型判别器是一个多任务的卷积神经网络,分类为身份和姿势。输入图像为生成图像或真实图像,其内部采用与生成编码器类似的网络结构,包含 Conv1、 Conv2、Conv3、Conv4和 Conv5五个卷积层和一个池化层。其中,Conv1由卷积核为3×3,步长为1 的 Conv11 和 Conv12组成,Conv2、Conv3、Conv4和 Conv5结构相同。每层卷积引入 BN 层和 ELU 激活函数。经平均池化层进入全连接层再用Softmax对输入的人脸图像进行身份和姿势分类。
当给定一个面部图像样本Ir的标签为是人脸图像的身份类别,yp是人脸呈现的角度类别。此时,判别器输出记为[ Dd ,Dp ],其中 Dd ∈RNd+1 ,Dp∈RNp。判别器中 Nd+1为身份总数用来做身份分类,Np 为离散姿态总数用作姿势的分类。给定一个真实的人脸图像Ir,判别器目标是估计其身份和姿态;当给定来自生成器 Ip =G(Ir,c ,z )合成人脸图像时,判别器试图将 Ip 归类为假时,使用公式(2)作为目标函数,通过在生成器 G 与判别器 D 的训练中,最大化 D 区分生成图像和真实图像能力。判别器区分真实图像Ir和生成图像 Ip 的角度和身份(生成图像的身份被划分为第 N+1类)。
式中,第一项是对真实样本Ir进行身份分类和姿势分类的交叉熵的相反数。第二项为将生成图像分类到假样本交叉熵的相反数。两项之和并最大化它们的和,即最小化分类交叉熵。
2.3 分类器及损失函數
为了保持人脸身份的一致性,很多研究采用在生成器中引入损失函数来实现。本文模型将分类器单独作为一个结构与生成器进行对抗,与判别器形成三者对抗。分类器 C 采用提前训练好的Light?CNN模型。与判别器功能类似,首先输入图像为真实图像Ir和生成图像 Ip 经一个卷积核为5×5 ,步长为1 的 Conv1处理后,通过最大特征图( Max Feature Map ,MFM)稀疏处理,实现通道数减半;然后通过一个由 Conv21、 Conv22以及最大池化操作组成的 Conv2层处理,再经由与 Conv2相同的 Conv3、Conv4和 Conv5处理;最后由全连接层和 MFM 操作后完成特征提取。
分类器和判别器的任务类似,即尽可能地区分生成图像和真实图像。经分类器分别提取的特征记为fidp和fird。分类器的结果标签定义为1 ~2N,其中真实人脸图像对应为前 N 个标签,生成图像对应后 N 个标签。交叉熵损失函数分别对应为:
式中,Ir和 Ip 分别表示真实图像和生成图像,lird和lipd表示真实图像标签和生成图像标签,lird,i表示第i个对应的真实正确标签,i∈{ 1,2...2N }。Ci ( Ir )和 Ci (Ip )分别表示第i个真实的输出标签和生成的输出标签。
分类器损失为两部分加权和,权重为α,同时是身份信息特征的保留损失,分类器的损失参见公式(5):
2.4 比例控制的训练超参数6
生成对抗网络通常有训练过程复杂、训练初期判别器呈明显优势易导致生成器与判别器不平衡、模式崩溃等[3]。为保持生成器和判别器训练的平衡,引入比例控制[4]即:
式中,E[L(G( z ))]和 E[L( x )]分别为生成数据和真实数据逐像素误差的期望值。当生成器与判别器两者达到平衡时,判别器无法判别出真实样本和生成样本,此时两者期望值应尽可能相等。本文训练中为了使生成器和判别器形成更具包容性收敛条件,设置超参数δ且δ∈[0,1],对生成器及判别器进行自定义的平衡训练,通过δ来调节生成效果,以提高网络收敛的速度、训练效率和性能。经过多次实验本文对超参数δ设置为0.8。
3 实验结果与分析
3.1 实验环境与数据
本文实验环境为 Windows 10操作系统,计算机配置为 NVIDIA GeForce RTX 2070显卡。训练和测试采用Pytorch深度学习框架。
实验采用专门用于大姿态人脸验证的 CFP 数据集,涵盖了姿态、表情、装饰物和光照等变化。由500个人组成,每人有10张不同的正脸图像和4 张有差异的侧脸图像[5]。实验中训练数据包含侧脸和正脸,将全部数据集输入模型中,用于训练和生成正面人脸图像。
3.2 模型训练设置
为实现对偏转人脸进行转正且保留对应人脸的身份特征,本文生成器和判别器模型采用交替训练方式,分类器采用预训练Light?CNN设置,用 Adam 算法优化。模型中的基本参数设置如下:选择β1 为 0.5, β2 为0.999的 Adam 优化器,学习率为2×10-5,图像分辨率为96×96时设置 batch size 为16。生成器输入的随机噪声Nz为50维,取自(-1,1)的标准正态分布。数据集的姿势标签分正脸和大角度侧脸,即设置姿态类型总数 Np 为2 。数据集中共有500个人物身份样本,即 Nd =500。比例控制中的超参数δ设置为0.8,训练的迭代次数设置为2000个 epoch。
3.3 实验结果及分析
当判别器正解率大于指定以上即0.9时,则认为判别器足够强且训练有序。随着迭代次数增加判别器判别生成图像逐渐趋近于1 ,表明生成器和判别器有效的互相對抗训练。相反,训练时未进行比例控制则呈现因判别器过强,导致生成器崩塌且判别器一直判别生成图像为假。实验表明,控制生成器和判别器的训练比例可以使模型平稳运行并灵活调度训练,从而提高训练效率。
人脸转正可以作为人脸识别模型的一种预处理操作,因此可以使用人脸识别准确率作为评价指标来评估不同人脸转正方法的身份特征保留能力。识别准确率越高,人脸图像合成过程保留的人脸特征越多,转正效果越好。本文模型加入分类器形成三者对抗,有助于训练时身份特征信息的保留。随着迭代次数增加,与生成器对抗训练过程中,分类器对全局的身份特征信息保留起积极作用。通过反馈不断修正生成图像,提高生成图像质量。分类器中身份信息保留损失的收敛如图3 所示。
为验证模型有效性,实验对比了现有的大姿态人脸转正模型以及本模型的消融实验验证模型的优势和各个组成部分的贡献。采用人脸识别模型Light?CNN作为分类器,并使用距离度量计算生成图像和真实图像之间的相似度。用分类器Light?CNN提取特征进而计算 Rank 识别率 R 作为衡量人脸转正效果的指标。识别实验采用同一数据集 CFP ,其中大多数侧脸为大姿态,一般角度为± 75°~ ±90°。结果表明在这些极端角度上,本文方法获得了更高的识别准确率,验证了本文方法在人脸转正任务上的有效性。
训练中,如果未对模型比例进行控制,生成器和判别器因训练不均衡易导致模型坍塌,加入超参数δ 可有效解决。在不加入分类器的情况下,本文模型生成器和判别器采用自编码结构达到了62.3%的准确率;FF?GAN 将人脸姿态范围扩大到90°,由于其仅仅依赖人脸形状和外观先验知识,因此侧脸识别率仅为54.7%。TP?GAN 虽然在多姿态人脸转正上取得了很好的效果,但对于大姿态人脸转正的识别准确率仍显不足。而本文方法采用了三者对抗的思想,较 DR? GAN[6~ 8]识别率提升了4.4个百分点。
通过定量对比实验,验证了本文方法对人脸转正和身份识别的有效性。本文模型在 CFP 数据集上,在输入同一身份的不同侧脸的同时,该模型可较好地保留身份特征,生成正面人脸图像。
4 结语
本文建立了一种基于三者对抗生成网络的人脸转正方法。利用生成器的自编码结构完成特征提取和人脸图像生成;接着在判别器和分类器的对抗训练下逐步提高图像生成效果,并通过比例控制设置超参数δ 交替训练生成器和判别器,使网络模型更加平稳;采用单独的 Light? CNN 分类器进行三者对抗,以便进一步保留人物的身份特征并提高人脸图像生成质量,加速网络收敛。在 CFP 数据集的实验中表明,本文方法可以更好地解决大角度的侧脸转正识别问题,准确率达到了68.7%,并提高了正面人脸生成质量。本文的论述和实验验证了模型方法的有效性。
参考文献:
[1] Yin X ,Yu x ,Sohn K ,et al.Towards Large?Pose FaceFrontalization in the Wild [ C ] ∥ The IEEE International Conference on Computer Vision ( ICCV),USA:IEEE ,2017:3990?3999.
[2] Huang R ,Zhang S ,Li T ,et al.Beyond Face Rotation:Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal ViewSynthesis [ C]∥ The IEEE International Conference on Computer Vision (ICCV),Italy: IEEE ,2017:2439?2448.
[3] 曹志义,牛少彰,张继威.基于半监督学习生成对抗网络的人脸还原算法研究[ J].电子与信息学报,2018,40(2):323?330.
[4] Cao K,Rong Y,Li C ,et al.Pose?Robust Face Recognition via Deep Residual Equivariant Mapping [ C ]∥ The IEEE Conference on Computer Vision and Pattern Recognition (CVPR),USA:IEEE ,2018:5187?5196.
[5] Chi Nhan Duong ,Khoa Luu,Kha Gia Quach ,et al.DeeAppearance Models: A Deep Boltzmann Machine Approach for Face Modeling [ J ] International Journal of Computer Vision,2018,18(1):1?19.
[6] Luan T,Xi Y,Liu X .Disentangled Representation Learning GAN for Pose?Invariant Face Recognition[ C]∥2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).IEEE ,2017.
[7] Goodfellow I ,Pouget?Abadie J ,Mirza M ,et al.Generativeadversarial nets [ C ] ∥ Proc.Adv.Neural Inf.Process. Syst.2014:2672?2680.
[8] Alex Krizhevsky,Ilya Sutskever,Geoffrey E.Hinton.ImageNet Classification with Deep Convolutional Neural Networks[C]∥ Neural Information Processing Systems Conference (NIPS).IEEE ,2012:432?439.
作者简介:
李壮(1997—) ,硕士,研究方向:图像处理、模式识别。
