基于轻量级图卷积网络的校园暴力行为识别
2022-04-29邓耀辉
李 颀,邓耀辉,王 娇
(1. 陕西科技大学 电子信息与人工智能学院,陕西 西安 710021;2. 陕西科技大学 电气与控制工程学院,陕西 西安 710021)
1 引 言
我国校园安全在依赖人工巡查的基础上,逐步向智能化方向发展,有关人脸检测[1]与人脸识别[2]系统应用已经非常广泛,然而缺乏成熟的异常行为识别系统。深度学习中基于卷积神经网络的暴力行为识别方法受图像光照和颜色等因素影响较大,识别速度和准确率有待大幅提高[3]。人体骨架序列不受光照和颜色影响,可以表征人体关节点和骨架变化与人体行为的关联信息,但基于骨架数据的图卷积网络的方法识别速度和识别率未能满足实际应用,有望通过改进图卷积网络提高实时性和可靠性。
早期人体行为识别通过专家手工设计特征模拟关节之间的相关性实现[4]。Yang 和Tian 采用朴素贝叶斯最近邻分类器(Naïve-Bayes-Nearest-Neighbor,NBNN)实现了多类动作的识别[5],但手工提取和调参表征能力有限且工作量大;Li和He 等人通过深度卷积神经网络(Convolutional Neural Network,CNN)提取不同时间段的多尺度特征并得到最终识别结果,但映射过程信息丢失、网络参数量庞大[6];Zhao 和Liu 等人通过对原始骨架关节坐标进行尺度变换后输入残差独立循环神经网络(Recurrent Neural Network,RNN)得到识别结果,表征时间信息的能力增强,但易丢失原始关节点之间的关联信息[7];Yan 和Xiong 等人首次提出用图卷积网络(Graph Convolutional Network,GCN)进行行为识别,避免了手工设计遍历规则带来的缺陷[8]。
基于人体骨架的行为识别受光照和背景等因素影响非常小,与基于RGB 数据的方法相比具有很大优势。人体的关节骨架数据是一种拓扑图,图中每个关节点在相邻关节点数不同的情况下,传统的卷积神经网络不能直接使用同样大小的卷积核进行卷积计算去处理这种非欧式数据[9]。因此,在基于骨架的行为识别领域,基于图卷积网络的方法更为适合。从研究到应用阶段的转换,需要在保证准确率的同时实现网络的轻量化:(1)需要在多种信息流数据构成的数据集上分别多次训练,融合各训练结果得到最终结果,增加了网络参数量和计算复杂度;(2)输入的骨架序列中,存在冗余的关节点信息,导致识别速度和识别率降低。
2 轻量级图卷积网络搭建
2.1 图卷积网络
以图像为代表的欧式空间中,将图像中每个像素点当作一个结点,则结点规则排布且邻居结点数量固定,边缘上的点可进行Padding 填充操作。但在图结构这种非欧空间中,结点排布无序且邻居结点数量不固定,无法通过传统的卷积神经网络固定大小的卷积核实现特征提取,需要一种能够处理变长邻居结点的卷积核[10]。对图而言,需要输入维度为N×F的特征矩阵X和N×N的邻接矩阵A提取特征,其中N为图中结点数,F为每个结点输入特征个数。相邻隐藏层的结点特征变换公式为:

其中i为层数,第一层H0=X;f(·)为传播函数,不同的图卷积网络模型传播函数不同。每层Hi对应N×Fi维度特征矩阵,通过传播函数f(·)将聚合后的特征变换为下一层的特征,使得特征越来越抽象。
2.2 轻量级图卷积网络框架
为了使人体骨架序列中的动作特征被充分利用,且在识别准确率提高的同时实现动作识别模型的轻量化,本文提出了一种结合多信息流数据融合和时空注意力机制的轻量级自适应图卷积网络。以输入的人体骨架序列为研究对象,首先融合关节点信息流、骨长信息流、关节点偏移信息流和骨长变化信息流4 种数据信息;接着构建基于非局部运算的可嵌入的时空注意力模块,关注信息流数据融合后人体骨架序列中最具动作判别性的关节点;最后通过Softmax 得到对动作片段的识别结果,网络主体框架如图1 所示。
2.3 多信息流数据融合
现阶段基于图卷积的方法[11]多采用在多种不同数据集下多次训练,根据训练结果进行决策级融合,导致网络参数量大。因此,在训练之前对原始关节点坐标数据进行预处理,实现关节点信息流、骨长信息流、关节点偏移信息流和骨长变化信息流的数据级融合,减少网络参量,从而降低计算要求。
人体骨架序列关节点的定义如公式(2)所示:
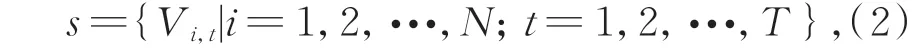
其中:T为序列中的总帧数,N为总关节点数18,i为在t时刻的关节点。融合多信息流之前,需要进行骨架序列s的多样化预处理。关节点信息流由人体姿态估计算法OpenPose 获取到的18 个关节点坐标得到,相对于动作捕获设备成本大幅降低[12-13]。其他信息流数据定义如下。
骨长信息流(Bone Length Information Flow):将靠近人体重心的关节点定义为源关节点,坐标表 示 为Vi,t=(xi,t,yi,t);远 离 重 心 点 的 关 节 点 定位 为 目 标 关 节 点,坐 标 表 示 为Vj,t=(xj,t,yj,t)。通过两关节点作差获取骨长信息流:
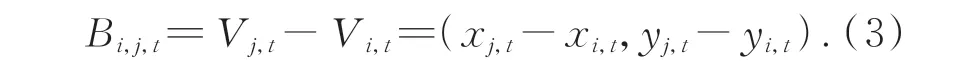
关节点偏移信息流(Joint Difference Information Flow):定义第t帧的关节点i的坐标表示为Vi,t=(xi,t,yi,t),第t+1 帧 的关节点i的 坐 标表示为Vi,t+1=(xi,t+1,yi,t+1),关 节 点 偏 移 信 息 流 可通过对相邻帧同一关节点坐标位置作差获得:
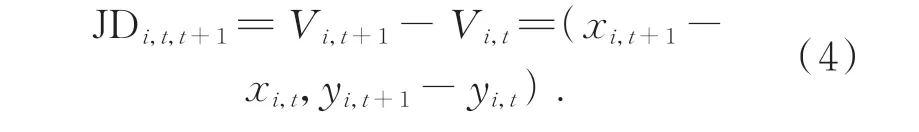
骨长变化信息流(Change of Bone Length Information Flow):相邻两帧中,同一节骨骼由于动作变化导致所表现出的长度不同,由公式(3)定 义 第t帧 的 骨 长 信 息 流 为Bi,j,t,则 第t+1 帧 的骨 长 信 息 流 为Bi,j,t+1,通 过 对 相 邻 帧 同 一 骨 骼 长度作差获得骨长变化信息流:
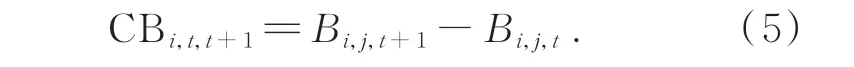
如图2 所示,根据对关节点信息流、骨长信息流、关节点偏移信息流和骨长变化信息流的定义,将多数据流加权融合成单一的特征向量,骨架序列维度由4×T×J×C1变为1×T×J×4C1:
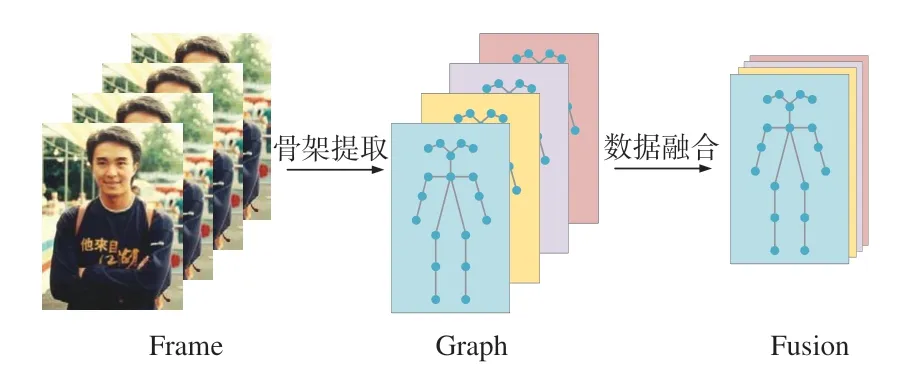
图2 信息流数据融合Fig.2 Data fusion of information flow

其中:权重ω1~ω4由关节点偏移度σ1(σ1∈[0°~360°])和骨长变化度σ2(σ2∈[0~100%])决定,σ1为前一 帧 坐 标 点Vi,t与 后 一 帧 坐 标 点Vi,t+1分 别 和 坐标原点所构成直线的夹角,σ2如式(7)定义:
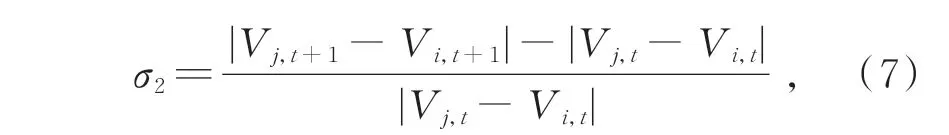
式中:绝对值运算代表骨骼长度,当σ1≥30°且σ2≤50%时,ω1和ω3权值为2,ω2和ω4权值为1;当σ1≤30°且σ2≥50%时,ω1和ω3权值为1,ω2和ω4权值为2;当σ1和σ2都小于阈值时,权值均为1;当σ1和σ2都大于阈值时,权值均为2。通过计算关节点偏移程度以及骨长变化程度,为变化程度大的信息流数据赋予了更高的权重,从而增强了信息流对动作的表征。再使用融合后的单一特征向量表示多信息流数据,将训练次数由4 次减少为1 次,降低了总体参数量,从而提高网络运算速度。
2.4 时空注意力模块构建
在保证网络运算速度提升的基础上,也要保证动作识别的准确性。一段人体骨架序列包含时间域和空间域的所有信息,但是只有对拳打、脚踢和倒地动作具有判别性的关节点关联信息值得关注,注意力机制大多只是去除无关项而关注感兴趣动作区域,但真正的冗余信息来自两个方面:(1)拳打动作发生时,只有肩膀、手肘和手腕3 个关节点相互之间相关性强;脚踢动作发生时,只有髋、膝盖、脚踝跟3 个关节点相互之间相关性强,这些关键关节点与其他关节点相关性弱或不相关。(2)受到暴力拳打或脚踢而倒地后,各关节点偏移幅度较小,前后帧的各关节点相关性几乎不变,无需对后一帧骨架信息进行提取。
将每个关节点偏移度σ1≥30°的关节点定义为源关节点,每次选取一个源关节点,其他关节点则为目标关节点,神经网络中的局部运算方法只能对目标关节点遍历后单独计算两两的相关性,使源关节点丢失全局表征能力。为了表征所有目标关节点对源关节点的相关性,如图3 所示,将非局部运算(Non-local operations)的思想融入时空注意力模块,并在特征输入后添加尺寸为2×2、步长为2 的最大池化层(Maxpool layer),以保证压缩数据和参数数量的同时尽可能保留原有特征。
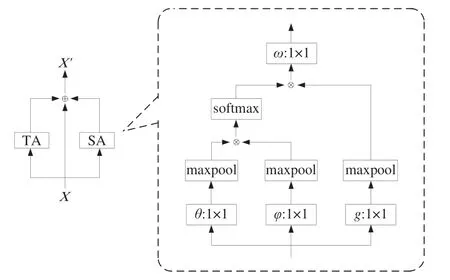
图3 时空注意力模块Fig.3 Spatio-temporal attention module
时空注意力模块(Spatio-temporal Attention Module,STA)包含一个空间注意力模块和时间注意力模块,其中空间注意力模块(Spatial Attention Module,SA)捕获帧内关节相关性,时间注意力模块(Temporal Attention Module,TA)捕获帧间关节的相关性,最终二者与输入特征相加融合。时空注意力模块输出特征的维度和输入相同,因此可以嵌入图卷积网络的网络结构之间。模块功能的实现分为4 个步骤:
(1)输入特征X的维度为T×N×C,其中T、N和C分别对应帧、关节和通道的数目,将空间注意力模块的输入特征表示为zs=[z,z,...,z]∈RT×N×C。
(2)将特征嵌入到高斯函数(θ和φ,卷积内核尺寸1×1)中计算任意位置两个关节i和j的相关性,由j进行枚举,得到关节点i的加权表示:
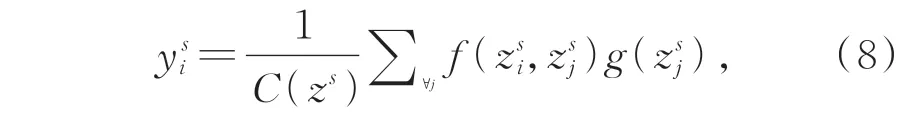
其中:z和z分别表示关节点i和j的特征;函数g用来计算关节点j特征表示,g(z)=Wz,W是待学习的权重矩阵;高斯函数f定义为:


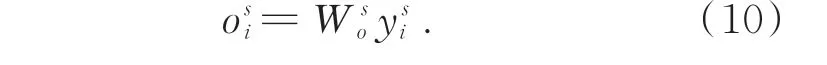
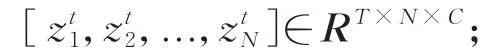
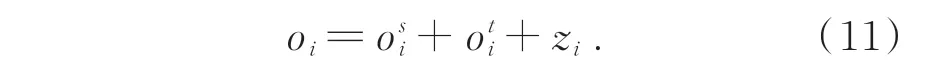
通过基于非局部运算的注意力机制得到具有判别性的关节点时空关联信息,去除了动作区域无关项和输入的冗余关节点信息的干扰,减少了不必要的计算,从而提高了准确率。
2.5 时空特征提取模块构建
为了提取骨架序列在空间和时间维度上的特征,首先利用时空图卷积网络和空间划分策略对动态骨架进行建模,原始表达式为:
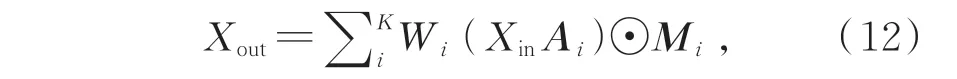
其中,Xin和Xout分别为图卷积输入和输出特征,K为空间域卷积核尺寸,Wi为权重,Ai为关节点i的邻接矩阵,⊙代表点乘,Mi为赋予连接权重的关节点映射矩阵。
使用预先定义好的骨架结构数据无法对所有未知动作准确识别,因此需要设计一种具有自适应性的邻接矩阵Ai,使得图卷积网络模型具有自适应性。因此,为了在网络学习中改变骨架序列图的拓扑结构,将式(12)中决定拓扑结构的邻接矩阵和映射矩阵分成Ai、Hi和Li,自适应图卷积模块框图如图4 所示,输出特征重新构造为:
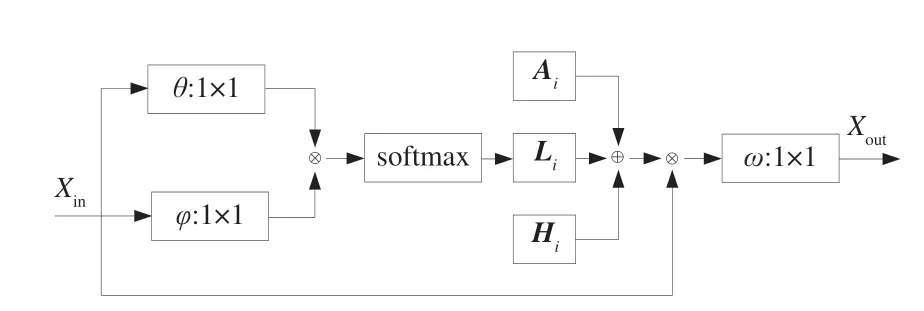
图4 自适应图卷积模块Fig.4 Adaptive graph convolutional module
Xout=∑i KWi Xin(Ai+Hi+Li). (13)
图4 中θ和φ即式(9)中高斯嵌入函数,卷积内核尺寸为1×1;第一部分Ai仍为关节点i的邻接矩阵;第二部分Hi作为对原始邻接矩阵的加法补充,能通过网络训练不断迭代更新;第三部分Li由数据不断驱动更新来学习连接权重,关节点相关性可由式(8)计算得到后与1×1 卷积相乘得到相似性矩阵Li:
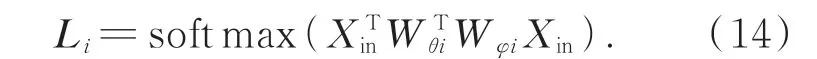
通过以上计算,构建出具有自适应性的图卷积模块,接下来对骨架序列包含的时空信息进行提取。
本文提出的时空特征提取模块如图5 所示。在每次完成卷积操作后通过BN(Batch normalization)层将数据归一化,再通过ReLU 层提高模型表达能力。可嵌入的时空注意力模块STA 已在2.4 一节中搭建完成,将特征输入提取模块后对感兴趣动作关节点进行提取。接着通过具有自适应性的GCN 在空间维度上获得骨架数据中同一帧各关节点的相关性,通过时间卷积网络(Temporal Convolutional Network,TCN)在时间维度上获得相邻帧同一关节点的关系。丢弃层(Dropout)减少隐层结点的相互作用避免了图卷积网络的过度拟合,参数设置为0.5,同时为了增加模型稳定性进行了残差连接。

图5 时空特征提取模块Fig.5 Spatio-temporal feature extracting module
2.6 整体网络结构搭建
如图6 所示,将9 个时空特征提取模块B1~B9进行堆叠,从特征输入X到行为标签Label 输出方向上,BN 层用于骨架图输入后进行标准化,B1~B3输出特征维度为Batch×64×T×N,B4~B6输出特征 维度为Batch×128×T/2×N,B7~B9输出特征维度为Batch×256×T/4×N,其中通道数分别为64,64,64,128,128,128,256,256,256。在空间和时间维度上应用全局平均池化操作(Global Average Pooling,GAP)将样本的特征图大小进行统一,最终使用softmax层得到0~1 的数据进行人体行为的识别。
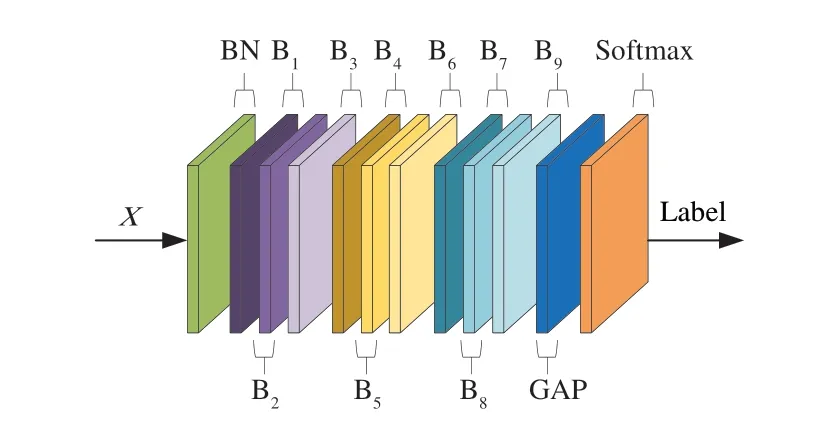
图6 整体网络架构Fig.6 Overall network architecture
3 实验结果与分析
3.1 实验配置
实验平台的配置为8 代i7 CPU,64 G 内存,4 TB 固态硬盘存储,显卡为RTX2080Ti。深度学习框架为PyTorch1.3,Python 版本为3.6。优化策略采用随机梯度下降(Stochastic gradient descent,SGD),每批次训练样本数(Batch size)设置为64,迭代次数(Epoch)设置为60,初始学习率(Learning rate)为0.1,Epoch 达到20 以后学习率设置为0.01。
3.2 行为识别实验
3.2.1 校园安防实景测试
本文面向实际应用,对校园马路、操场和湖边等不同场景制作了12 000 个视频片段,拳打、脚踢、倒地、推搡、打耳光和跪地6 种典型动作各2 000 个,单个时长不大于5 s。所有人员身高、体重和身体比例等方面有所差异,以增强模型的泛化能力。根据实验配置进行训练,图7 为模型的训练损失与综合测试准确率的变化曲线。
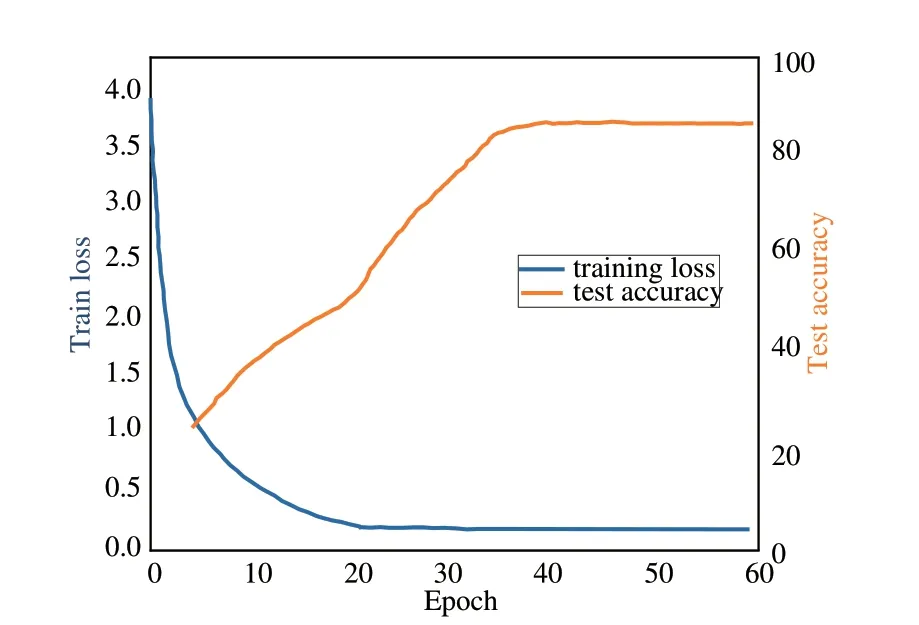
图7 模型训练损失与测试准确率变化图Fig.7 Variation diagram of model training loss and test accuracy
可以看出随着迭代次数的增长,模型的训练损失逐渐下降。当epoch 在20 左右时,由于学习率的下降,测试准确率开始大幅提高;当epoch 超过35 之后,训练损失与测试准确率几乎保持不变。使用训练好的模型分别对6 类动作对应的测试集进行测试,主要识别过程如图8 所示。

图8 6 种典型动作识别过程Fig.8 Six typical action recognition processes
图8 中处理的5 组动作片段从左至右分别为拳打和脚踢、倒地、推搡、打耳光及跪地,图8(a)是原视频;图8(b)是对输入的含有拳打和脚踢动作的视频片段使用OpenPose 进行人体关节点提取,正确匹配各关节点后得到人体骨架;图8(c)是将骨架序列输入本文改进的时空图卷积网络得到动作片段的识别结果。改进后模型的处理速度最大可达20.6 fps,对校园安防实景中拳打、脚踢、倒地、推搡、打耳光和跪地6 种典型动作识别准确率分别为94.5%,97.0%,98.5%,95.0%,94.5%,95.5%,测试结果如表1 所示。
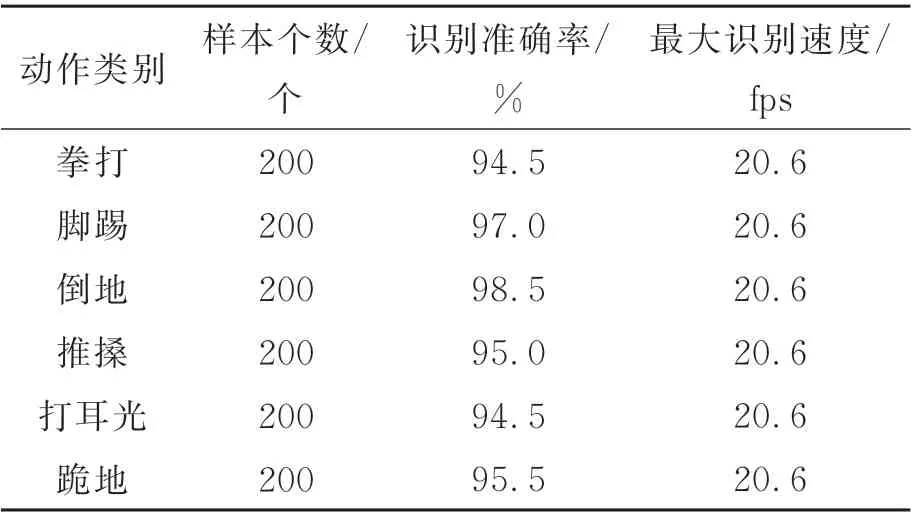
表1 6 种典型动作识别结果Tab.1 Six typical action recognition results
为了验证不同体型(身高、体重和肩宽表示)人员对识别准确率存在影响,选取参与数据集制作的1~6 号实验人员,每次使用由单一实验人员获取的6 种典型动作片段作为训练集,将由其他5 个实验人员获取的6 种动作片段作为测试集,并记录对所有动作的平均识别准确率,实验参数及结果如表2 所示。
由表2 数据可知,使用单一实验人员所拍摄的6 类动作片段作为数据集进行训练,并分别对其他人员的动作片段测试,测试结果最佳仅为85.6%,而使用所有实验人员视频片段识别准确率在94.5%以上,说明了不同人员体型的差异性可以增强模型的泛化能力,即鲁棒性。
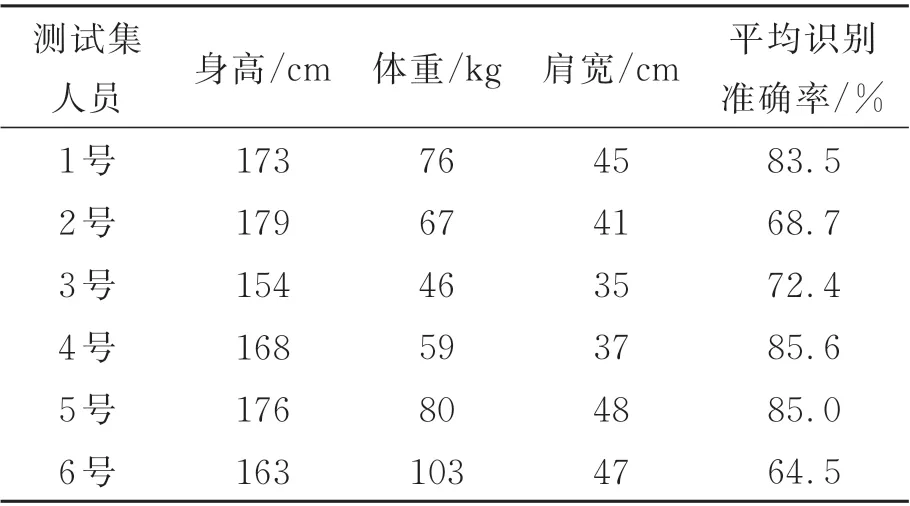
表2 不同体型人员动作识别结果Tab.2 Action recognition results of personnel with different body types
表2 的1~6 号 实 验 人 员 中,2 号 的 体 型 为179 cm/67 kg,身材过瘦;3 号的体型为155 cm/46 kg,身材矮小,但身高体重比例正常;6 号的体型为163 cm/103 kg,身材肥胖;1 号、4 号和5 号体型基本正常。不同体型的人做同一种动作时,姿态检测算法获取的18 个人体骨骼点坐标有差异,从而骨长也会产生差异,关节点信息流、骨长信息流、关节点偏移信息流和骨长变化信息流4 种数据信息也有区别。因为2 号过瘦,各关节点坐标较为集中,而6 号过胖,各关节点坐标较为分散,导致2 号和6 号的平均识别准确率最低,仅为68.7%和64.5%;而3 号身材比例正常,但身高过于矮小,也导致了关节坐标点分布不均匀,72.4%的准确率低于其他正常体型。
综上,在数据集的制作过程中所有人员体型差异的多样性可以增强模型的泛化能力,实验结果也表明本文方法可快速有效地识别出校园暴力的典型动作。
3.2.2 方法对比实验
为了验证本文方法的有效性,采用具有挑战性的UCF101 数据集进行行为识别对比实验。该数据集有101 类动作,13 320 段视频,在人员姿态、外观、摄像机运动状态、和物体大小比例等方面具有多样性。
按照6∶2∶2 的比例,参与训练和验证的视频数据10 656 个,测试视频2 664 个,使用表3中5 种方法进行对比实验,在当前配置下对视频片段处理速度由9.2~15.5 fps 最大提高至19.3 fps,对数据集中101 类动作平均识别准确率以及参数量变化对比结果如表3 所示,并在表4 中给出了数据集中6 种动作的识别准确率。
表3 数据表明:本文方法(无注意力模块)相对于两种卷积神经网络的方法,参数量分别减少约92.6%和94.7%,而识别准确率提高21.4%和4.0%;相对于改进前时空图卷积网络的方法,参数量减少约59.6%,而准确率提高1.2%。说明本文的多信息流数据融合方法可有效减少网络参数量,实现网络轻量化。其中,使用基于非局部运算的时空注意力机制相对于未使用时参数量减少约37.6%,准确率提高2.9%,说明改进后的时空注意力机制可有效减少冗余关节点信息,提高了特征的利用率,从而提高了识别准确率。表4 数据列出了改进后方法在UCF101 数据集中6 种动作的识别准确率。由于该数据集中动作片段来源于不受约束的网络视频,存在相机运动、部分遮挡和低分辨率等影响导致视频质量差,实验中在OpenPose 进行人体关节点提取阶段csv 文件中所存的关节点坐标有部分缺失,因此相较于表1 中实测数据集识别准确率均偏低。

表3 不同识别方法的对比结果Tab.3 Comparison results of different recognition methods
综上,本文方法在保证准确率提升的同时实现了网络的轻量化,从而提高了可靠性与实时性。
4 结 论
针对校园智能安防识别速度和识别率不高导致可靠性和实时性差的问题,本文提出了一种基于轻量级图卷积的人体骨架数据的行为识别方法,通过多信息流数据融合与自适应图卷积相结合的方式,同时通过嵌入时空注意力模块提高特征的利用率,在校园安防实景中对拳打、脚踢、倒地、推搡、打耳光和跪地6 种典型动作识别准确率分别为94.5%,97.0%,98.5%,95.0%,94.5%,95.5%,识别速度最快为20.6 fps,且验证了模型的泛化能力。同时在行为识别数据集UCF101 上验证了方法的通用性,可以扩展至人体其他动作,在参数量比原始时空图卷积网络减少了74.8% 的情况下,平均识别准确率由85.6% 提高到89.7%,识别速度最大提高至19.3 fps,能够较好地完成校园实际安防中出现最多的典型暴力行为识别任务。
