冬奥延庆赛区风的预报技巧比较分析*
2022-04-29熊敏诠刘凑华
熊敏诠 冯 文 刘凑华
1.国家气象中心,北京,100081
2.海南省南海气象防灾减灾重点实验室,海口,570100
3.海南省气象局,海口,570100
1 引言
高山滑雪被称为“皇冠上的明珠”,是冬奥最精彩、最受关注、对气象条件要求最严苛的比赛项目。2022 年冬奥高山滑雪项目在北京延庆举行,依托900 m 落差、3000 多米坡面长度的海坨山建设的狭长赛区,每个赛道各个点位气象要素差异较大。对于高山滑雪,气象条件是决定竞赛能否进行的“天花板”,其中,风的预报起关键作用,直接影响到比赛能否正常进行、运动员竞技水平的发挥和人身安全,不仅需要高精度的风速预报,而且风向预报也十分重要,高速运动中竞技者对横风、风切变都非常敏感。
Lorenz(1963)指出不确定性是大气运动的基本特征。复杂地形区,近地面风时、空分布呈现非线性变化,尤其是边界层,受近地层大气湍流活动影响,风的变化不确定性更显著。通过扰动的初始场或物理参数化获得多个预报结果构成的集合预报产品能描述出大气运动的不确定性特点;确定性预报只能提供未来大气运动某个单一的状态,集合预报能反映多种可能。因此,集合预报系统被广泛应用于气象预报业务和科学研究。显然,相对于单值预报,集合预报对风场的刻画更为合理。
由于对计算资源需求大,集合预报产品的时、空分辨率往往比较低,难以预测小尺度的天气过程;另外,初始场、物理参数化过程、模式动力框架等有诸多的不完善共同构成了模式误差和系统性偏差。就近地面气象要素预报而言,从模式产品的直接输出到业务应用之间有较大的距离,模式后处理过程是两者的桥梁,其目标是降低模式的预报误差,提高预报技巧。
回归法是模式后处理过程中常见的方法。出现较早的是MOS 法(Model Output Statistics),根据模式输出的多个变量,使用逐步回归法可有效提高风的短期预报准确率(Glahn,et al,1972);多年来,回归法广泛应用于风的短期预测研究中;Gneiting等(2005)提出了EMOS 技术(Ensemble Model Output Statistics),根据集合成员和离散度,使用多元回归法提高预报精度;Gneiting 等(2008)联合东西和南北风分量建立双变量正态密度函数(即双变量的EMOS);基于双变量的EMOS 技术,Schuhen 等(2012)探讨了风速和风向的相关关系;另外,BMA法(Bayesian Model Averaging)也被用于风向订正(Bao,et al,2010),BMA 法和EMOS 改进法(Sloughter,et al,2010;Thorarinsdottir,et al,2010)相结合进行风速订正;Scheuerer 等(2015)为了获取高分辨率的网格风场预报,将局地风的气候特点融入到“块金效应”中,发挥了重要作用;Holman 等(2018)基于高分辨率的区域模式,使用EMOS 法,提高了海陆交界处的10 m 风短期预测技巧。
传统的回归方法应用中,预报因子间通常有较高相关关系,回归方程易出现不稳定,有多种途径可以解决这个问题:(1)对预报因子做主分量分析,据此建立更可靠的回归方程,称为偏最小二乘回归法(黄嘉佑等,2007;魏凤英等,2010;李庆祥,2020);(2)通过增加扰动量克服共线性问题的岭回归法(王振会等,1994);(3)使用核函数将预报因子映射到高维空间,建立超平面最优回归方程,即支持向量机回归法(魏鸣等,2019)等。伴随着计算机技术的发展,更多改进的回归方法可期。
传统算法都可以使用神经网络法逼近(Masters,1993),McCann(1992)在飓风的短期预测中较早地使用了神经网络法,该方法也普遍被应用于龙卷风(Marzban,et al,1996)、灾害大风(Marzban,et al,1998)、局地风(Kretzschmar,et al,2004)、风切变预警(Kwong,et al,2012)、海面风(Silva,et al,2018)等的预测中。Veldkamp 等(2021)使用卷积神经网络提取环流特征场,在未来48 小时10 m 风的预报中成效显著。粒子群算法(PSO,Particle Swarm Optimization)是基于群体的随机优化技术(Kennedy,et al,1995),具有收敛快、全局搜索能力强且无需获取问题本身的特征信息等优点(Clerc,et al,2002)。在求解权值场过程中,普通神经网络法容易陷入局部极小,而PSO 法进一步完善了训练过程,逼近全局最优解,提高了网络的泛化能力、收敛速度和学习能力(Sheikhan,et al,2013),被应用到月降水量的预测工作中(He,et al,2015)。
模式后处理过程中,训练样本的构成也比较重要;使用相似法选择样本,结合上述算法能明显提高预报误差订正能力。Hamill 等(2006)较全面地介绍了相似理论并对多种技术做了比较;Klausner等(2009)的“相似天”法在风的短期预报中,有高效、实用性强的特点;Monache 等(2013)使用历史预报和观测构建“相似集合”,即AnEn 法(Analog Ensemble),在10 m 大风的短期预报中要明显优于EMOS、逻辑回归法。但是,足够多的观测样本和较高精度的数值预报是相似法应用的基础。
延庆山区冬季风复杂多变,地形、动力、热力作用对风都有重要影响(贾春晖等,2019)。边界层湍流日变化及大气动量传输导致不同海拔的风日变化差异很大(乌日柴胡等,2019)。集合预报可以较好地反映上述不确定特征,但是,在实践中有两个主要难点:一是数值模式不完备,如前所述的初值误差、模式误差、时空分辨率低等,特别是赛道上测点间距小,风的预报降尺度要求高。二是观测资料稀缺;建站时间短,2017 年陆续开展观测,大多是冬季观测值;连续、可靠的观测资料少,并且部分站点位置进行了多次调整,同时存在观测资料质量控制问题。面对这些问题,需要开展如下分析:(1)预报模型能否反映各点位上相差迥异的风矢量,即时、空降尺度效果如何;(2)通过多个角度检验,从整体到细节,分析各类方法的预报产品特点和差异;(3)在有限的历史样本情况下,探索提高风预报能力的有效途径。
2 资 料
欧洲数值预报中心的集合预报产品为12 h 间隔、100 km 空间分辨率、51 个预报成员、850 hPa风的预报。以2017 年12 月—2018 年4 月、2018年12 月—2019 年4 月、2019 年12 月—2020 年4 月的逐日08 时起报(北京时,下同)的产品为训练样本。实际应用中,当进行1—3 d 预报时,使用的原始集合预报产品均向后延24 h;例如当天08 时的24 h 预报,将使用前一天08 时的48 h 数值模式产品。因为要获得6 h 间隔预测,还需将原始的12 h间隔产品通过等差线性插值法,得到6 h 间隔风的预报;那么,未来6、18、30、42、54、66 h 数值模式产品都是插值获得。
海坨山位于北京延庆区与河北赤城县交界处,主峰(大海坨)海拔2241 m,是京北第一高峰,小海坨在大海坨南侧,海拔2199 m;小海坨山南麓是高山滑雪项目比赛场地。观测站点和集合预报格点分布如图1 所示,延庆赛区5 个测点以数字标记,海拔高度从高到低(2200—900 m)的测点依次为:1701、1703、1705、1708、1489,最高处1701 站超过了2000 m,最低点1489 站接近900 m。进行3 s、1、2、10 min 的平均风速和风向的观测,冬奥赛事中,较多地用2 min 平均风,小时平均风指1 h 内的平均风,极大风是1 h 内3 s 瞬时风的最大风速,通常用极大风速代表阵风风速;以下只讨论2 min 平均风的预报技巧。将使用各测点在整点时刻上2 min 平均风观测值、测点上的数值模式预测结果,便可得到完整的训练集。使用双线性插值得到的5 个站点预测值几乎相等,因此,需要进行预报误差订正,才会有应用价值。
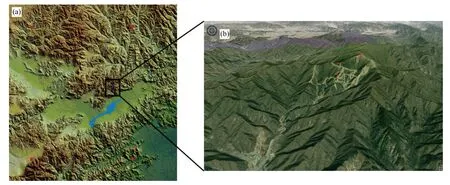
图1 (a)格点(红点)、测站(蓝点)位置和地形;(b)放大后的测站(红点)位置Fig.1 (a)The locations of grids(red)and stations(blue),(b)the enlarged topography of observed stations(red points)
3 方 法
回归法使用一元回归、岭回归法,神经网络法采用Back Propagation 法(以下简称BP 法)、PSOBP 法,共4 种建模方法。
3.1 回归法
回归方程中回归系数求解有梯度下降法和标准方程法。梯度下降法需要选择合理的学习率,并反复迭代才能获得最优解的近似值;标准方程法则不需要学习率和迭代,就能得到全局最优解。因此,将使用标准方程法获得回归系数。
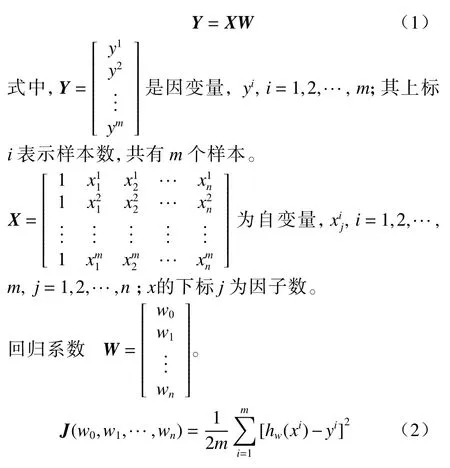
式(2)为代价函数的定义,即预测值hw(xi)和真实值yi之差的平方和。将式(2)写成矩阵表达式(3),可得W(式(4))。
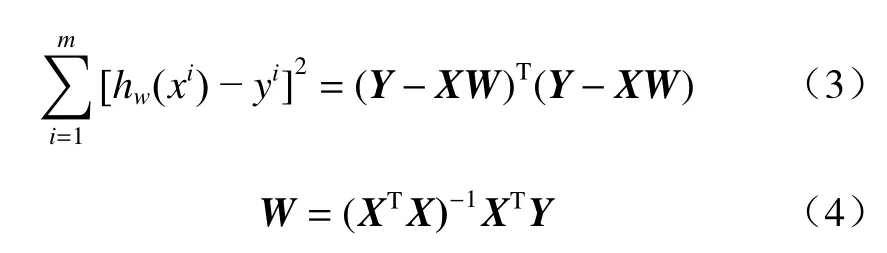
以集合均值(x1)为自变量,2 min 平均风的观测值减集合均值,即预报误差为因变量,式(1)中j取值为1,建立一元回归方程。
若以集合均值(x1)、最大值(x2)、最小值(x3)、三分位值(x4、x5、x6)(分位选取25%、50%和75%)为输入值,这6 个变量存在线性相关,依此建立的多元回归方程有多重共线性问题,式(4)中(XTX)−1计算也会出错,因其不是满秩矩阵,不可逆。岭回归(Gibbons,1981)能有效解决上述问题,将式(4)中增加扰动项λI,λ为岭系数,I是单位矩阵,则(XTX+λI)是满秩矩阵,可以用式(5)计算得到回归系数W。
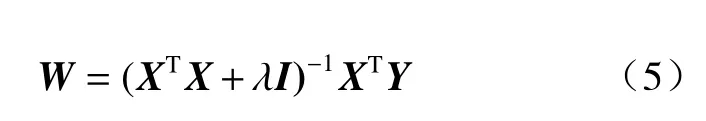
岭系数的选取将影响到岭回归预测精度,λ的取值范围通常是0—1。对延庆赛区5 个测点的6—72 h 时效(6 h 间隔)分别建立岭回归模型,发现大多数模型的岭迹呈现出相似的变化特征;其原因可能是输入的6 个变量都相同,只是输出变量(预报误差)不同,而在较稳定的环流场中,5 个测点的预报误差变化特点可能相似,导致有相近的岭迹。如1701 站点6 h 预报的岭迹(图2),纵坐标是回归系数值的大小,横坐标为λ的变化;岭系数选取各回归系数的岭估计趋于稳定的区间,可得λ=0.7。为了便于不同建模方法的比较,文中的岭系数都设置为0.7。
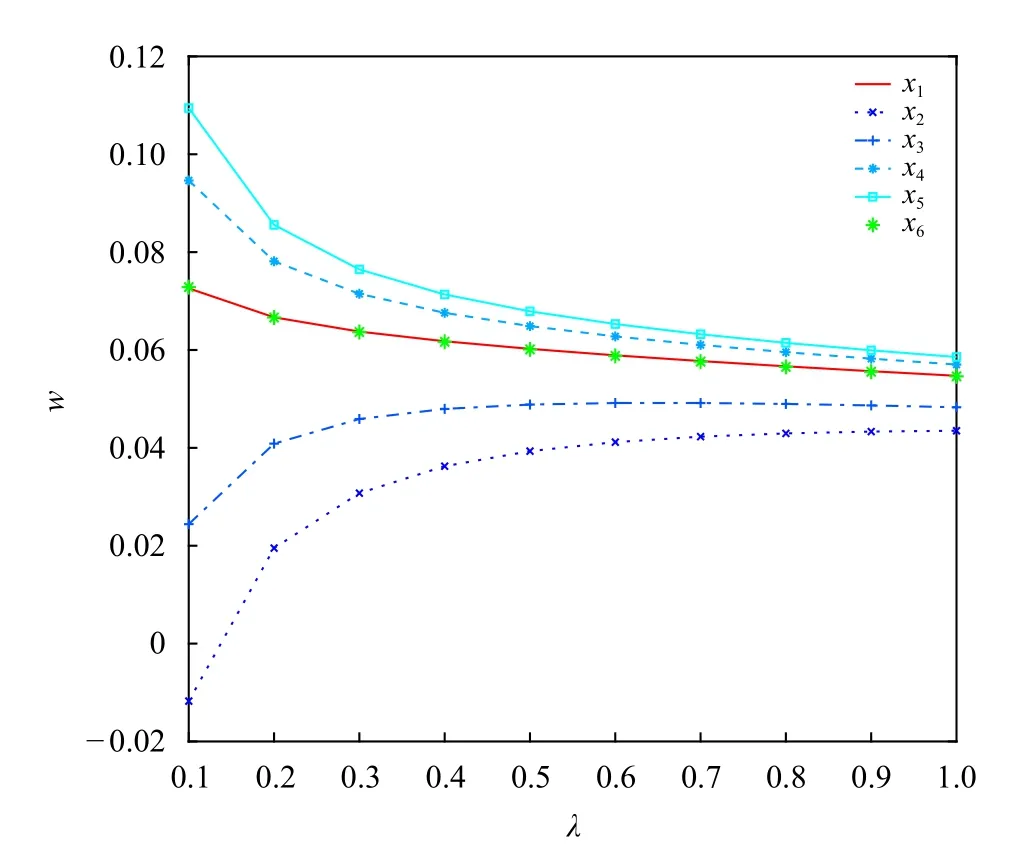
图2 岭迹Fig.2 Ridge trace
3.2 神经网络法
神经网络法采用6-15-1 的网络结构,以上述6 个集合统计特征值为输入节点,隐层设置是15 个节点,输出层为预报误差(熊敏诠,2017,2020;Xiong,et al,2020)。采用BP 法,其特征是误差正向传播、反向传播的反复迭代求解最优权值场的过程,也以式(2)为代价函数;在误差反向传递中学习率为0.05,使用Levenberg-Marquardt 法(简称L-M法)计算误差梯度,在迭代过程中不断优化权值场。
PSO 基本思想(Sheikhan,et al,2013)是:没有体积质量的粒子,在n1维空间以一定的速度飞行,优化函数决定了所有粒子的适应值,通过迭代获得最优解。将每个权值δj(j=1,2,···,n1)看作某个维度,n1就是BP 模型中权值的总个数(此处的网络结构和上述BP 法保持一致)。引进以下4 个符号,δi(k)=表示粒子群中第i个(i=1,2,···,m1)粒子当前的位置,pi(k)=是当前具有最优适应度的位置,表示搜索方向,为群体的最优位置,PSO 算法表示为
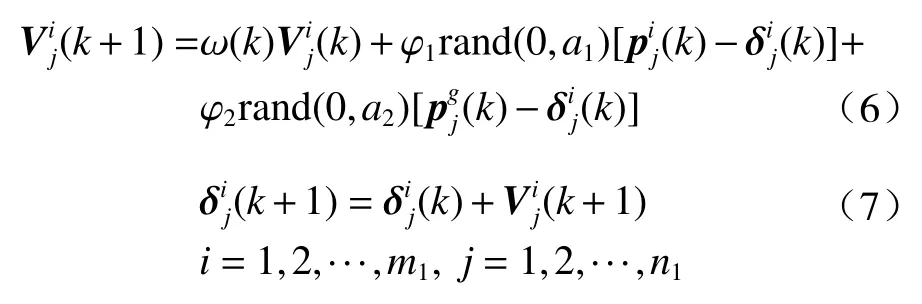
综上所述,可得5 种预报:集合均值为数值模式直接输出(Direct Model Output,简称DMO)、一元回归(Regression,简称REG)、岭回归(Ridge Regression,简称RID)、BP 法、PSO 法(PSO-BP,简称PSO)。REG 法的输入变量只有集合均值,RID、BP 和PSO 法对应的输入和输出变量完全一致。用东西和南北风分量各自建模,训练集是2018、2019、2020 年的1 月15 日—3 月15 日的数值模式预报及相应的实况资料,有效样本一般有175 个(除去缺失数据)。在建模过程中,输入、输出变量都采用Z-Score 标准化,以提高数据的可比性。
4 检验分析
4.1 平均预报误差和预报准确率
在东西、南北风分量预报的平均误差(观测减预测值)对比中,神经网络法(指BP 和PSO 法,下同)总体趋势上(图3a、b 中柱状子图)要优于回归法(指REG 和RID 法)。首先,DMO 预报误差较大,而且随着预报时效呈现周期性变化;如东西向,每隔12 h 就出现误差大值,其中12、36、60 h 预报DMO 偏强6 m/s,24、48、72 h 预 报DMO 偏弱4 m/s;南北向,DMO 预报都偏弱,其中12、36、60 h预报偏弱6.5 m/s。从曲线图来看,不同类(回归和神经网络两类)的方法有一定差异,同类方法之间差异较小;如回归类中,REG 和RID 法的东西向预报误差基本相同,柱状子图显示RID 有微弱优势;南北向,RID 较REG 法也有一定的优势。5 种预报方法相比,BP 法的预报误差总体较小(柱状子图)。
根据中国气象局中短期天气预报质量检验办法(2005 年),风向预报准确率的计算如下:先将风向均分为8 个方位角,当预报和观测的方位角相同,得1 分,相差1 级,得0.6 分,否则,得0 分,据此得到平均值。风速预报准确率是将预报和观测的风向划分成14 个离散的风速等级,预报和观测都处于相同的风速等级则为正确,否则是错误,依此计算平均值。DMO 的预报准确率都比较低,且日变化特征明显(随着预报时效的延长,周期性振荡);如6、24、48、72 h 风向预报的准确率接近于0.2,其他时效都小于0.1。多站点平均来看(图3c、d),RID 法的风向预报准确率(0.3)最高,BP 法的风速预报准确率(0.26)略有优势,具体到逐个预报时效,同类方法趋势相近。
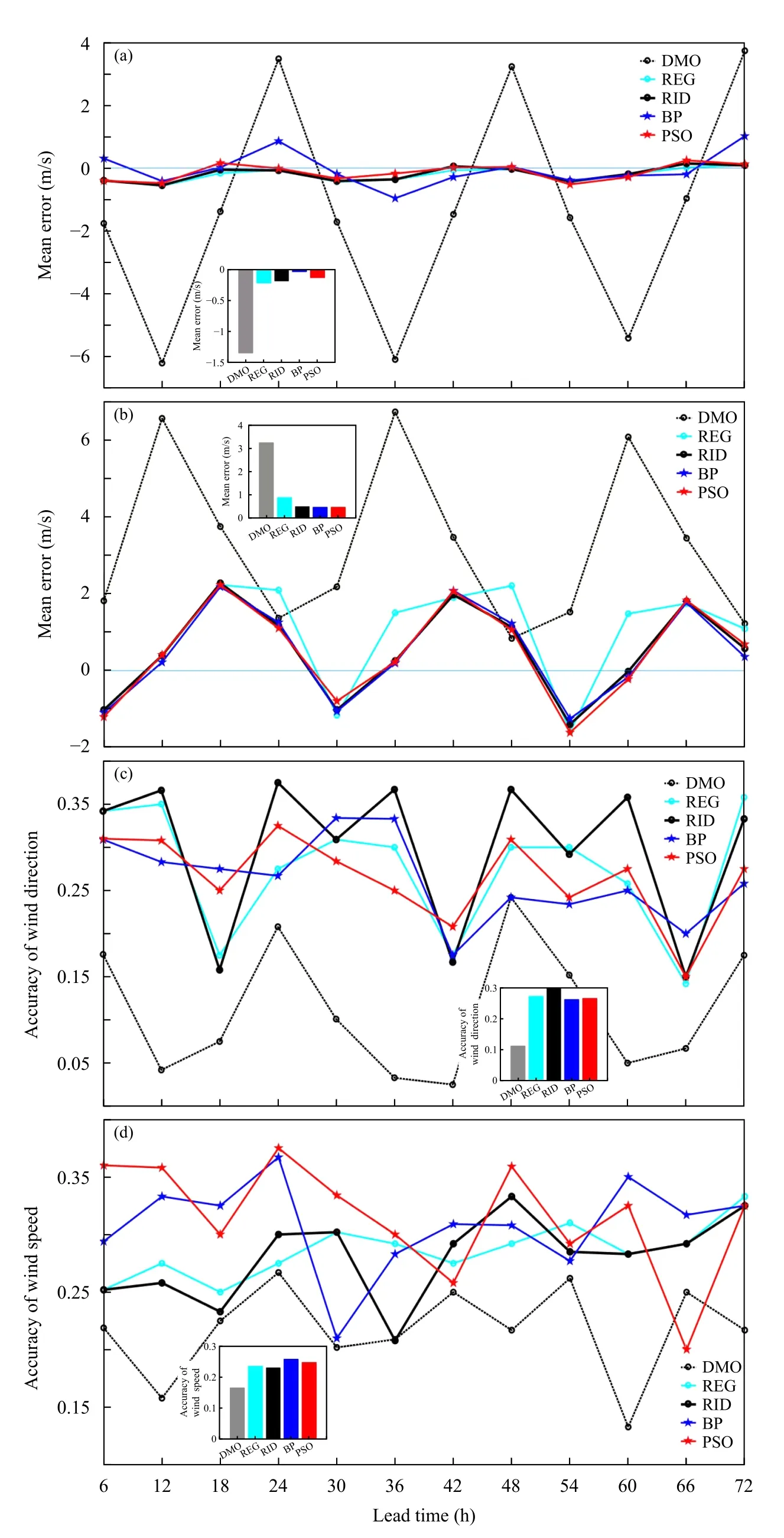
图3 (a)东西风分量的预报平均误差,(b)南北风分量的预报平均误差,(c)风向预报准确率,(d)风速预报准确率Fig.3 (a)Mean errors of east-west wind component forecast,(b)mean errors of south-north wind component forecast,(c)accuracy rates of wind direction forecast,and(d)accuracy rates of wind speed forecast of five stations
4.2 频率关系比较
频率关系图可以直观地展示不同风速情况下预报和观测的接近程度,其由两幅子图构成;第一幅是观测和预报概率分布函数的对比,可得DMO、REG、RID、BP、PSO 五条曲线;第二幅是频率匹配映射关系,图中的对角线为完美预报,即预报和观测的累积概率相同。
合成风频率关系图显示DMO 在不同测点上的累积概率曲线完全相同(图4a1—e1);与实况相比,在1489、1708 测点DMO 风速预报偏大,1701、1703、1705 风速预报偏小;如1708 测点的预报误差最大,实测最大风速只有6 m/s,DMO 预报则超过了12 m/s。神经网络法优于回归法,尤其是在较大风速区,表现出较好的预报能力。在不同的风速区间,PSO 法的预报精度普遍高于BP 法(图4a2—e2),RID 法则略好于REG 法。
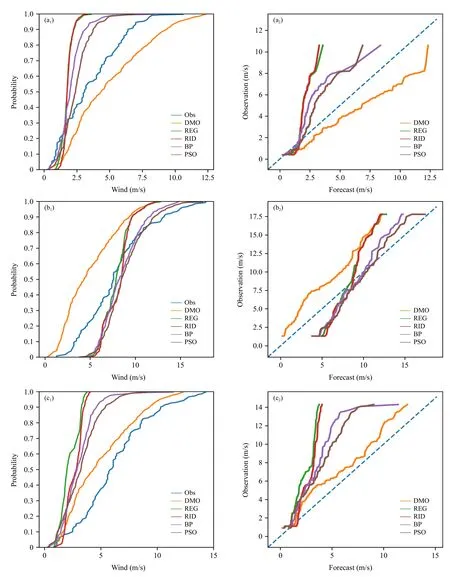
图4 不同测点(a.1489 站,b.1701 站,c.1703 站,d.1705 站,e.1708 站)的合成风频率关系(a1—e1.观测和预报概率分布函数对比,a2—e2.频率匹配映射关系)Fig.4 Frequency diagram:probability distribution function(a1—e1),frequency matching mapping(a2—e2)at five stations(a.1489,b.1701,c.1703,d.1705,e.1708)
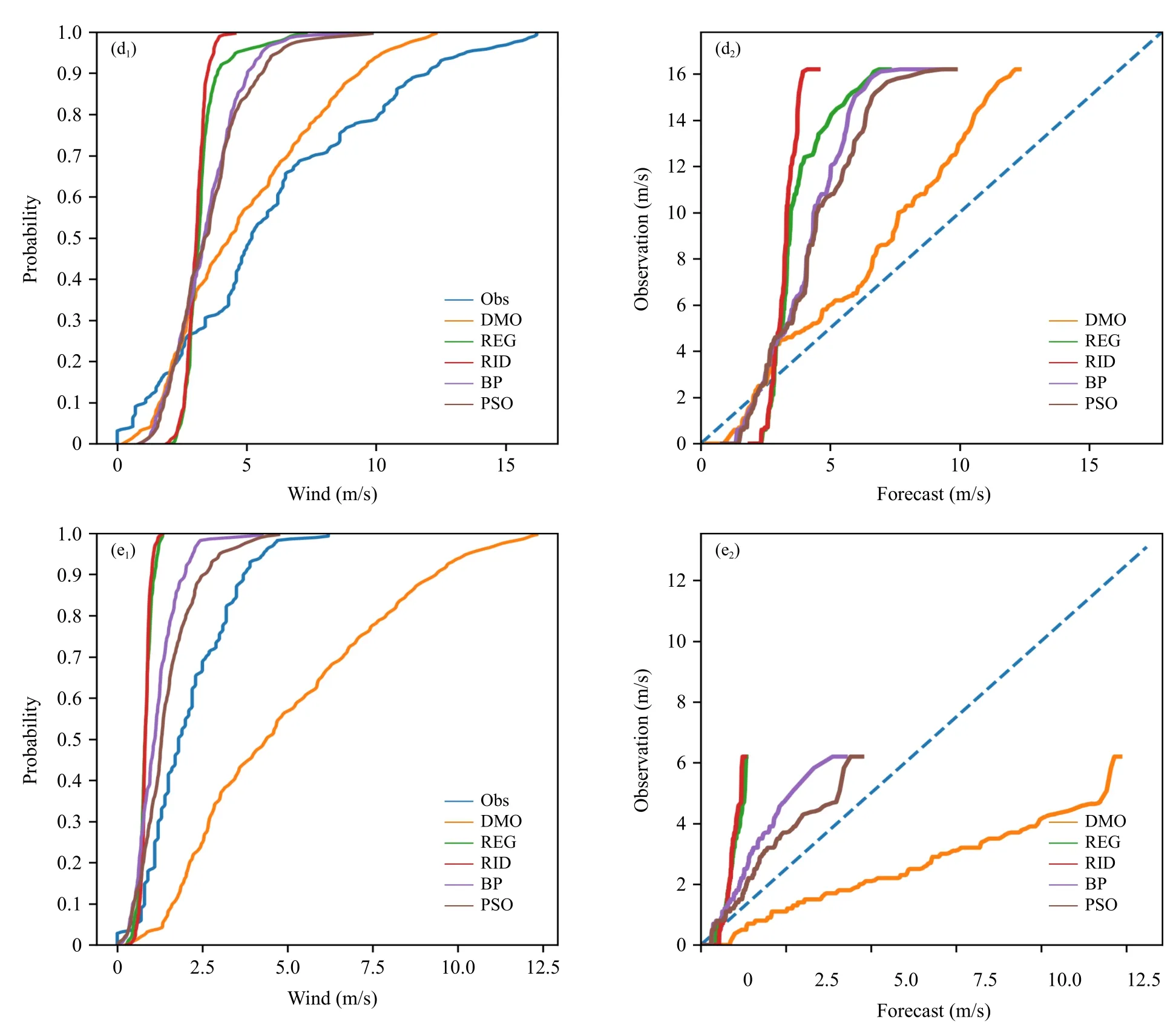
续图 4 Fig.4 Continued
由于是从东西、南北两方向分别建模预测,只有着眼于两方向建模效果,才能得到更合理的解释。上述合成风讨论中,可知REG、RID 法没有达到预期效果,当依据东西、南北向的频率关系(图略)能获悉其主要原因;REG、RID 法同属于回归函数簇,其预测的是数学期望,或者说是平均态,通常以较弱风为主体,而强风是小概率事件,所以,REG、RID 法对较弱风的预报误差订正有效,而难以订正强风预报。
虽然DMO 在1703、1705 测点的合成风预报技巧高,但是,并不意味着建模方法完全失去了订正能力,如神经网络法在1703 站的东西风分量预报接近完美、在1703 和1705 站的南北风分量风速预报技巧明显高于DMO。1703 站的东西风分量(图5a):在弱风区(−3—3 m/s)建模方法优于DMO,表现出较好的订正能力;风速大于3 m/s 时,回归法难以发挥作用;神经网络法表现突出,累积概率曲线和观测线几乎重叠,频率匹配线近似完美。1705 站的东西风分量:观测值是−5—16 m/s,建模法只是在弱风区(−3—3 m/s)有订正能力;对于3 m/s 以上风区,DMO 预报更准确。1703 站的南北风分量:观测值是−14—14 m/s,盛行风大致−9—0 m/s(图5c1),4 种建模方法在盛行风区域表现出了较好的订正能力。1705 站的南北风分量:观测值是−9—5 m/s,回归法在−5—1 m/s 区间对DMO 有正订正效果,神经网络法则在所有区间都有正向作用。
图5 不同测点的东西分量和南北分量的频率关系(a.1703 站东西风分量,b.1705 站东西风分量,c.1703 站南北风分量,d.1705 站南北风分量;a1—d1.概率分布函数,a2—d2.概率匹配映射关系)Fig.5 Frequency diagram:probability distribution(a1—d1),probability match(a2—d2)(a.east-west wind component at 1703,b.east-west wind component at 1705,c.south-north wind component at 1703,d.south-north wind component at 1705)
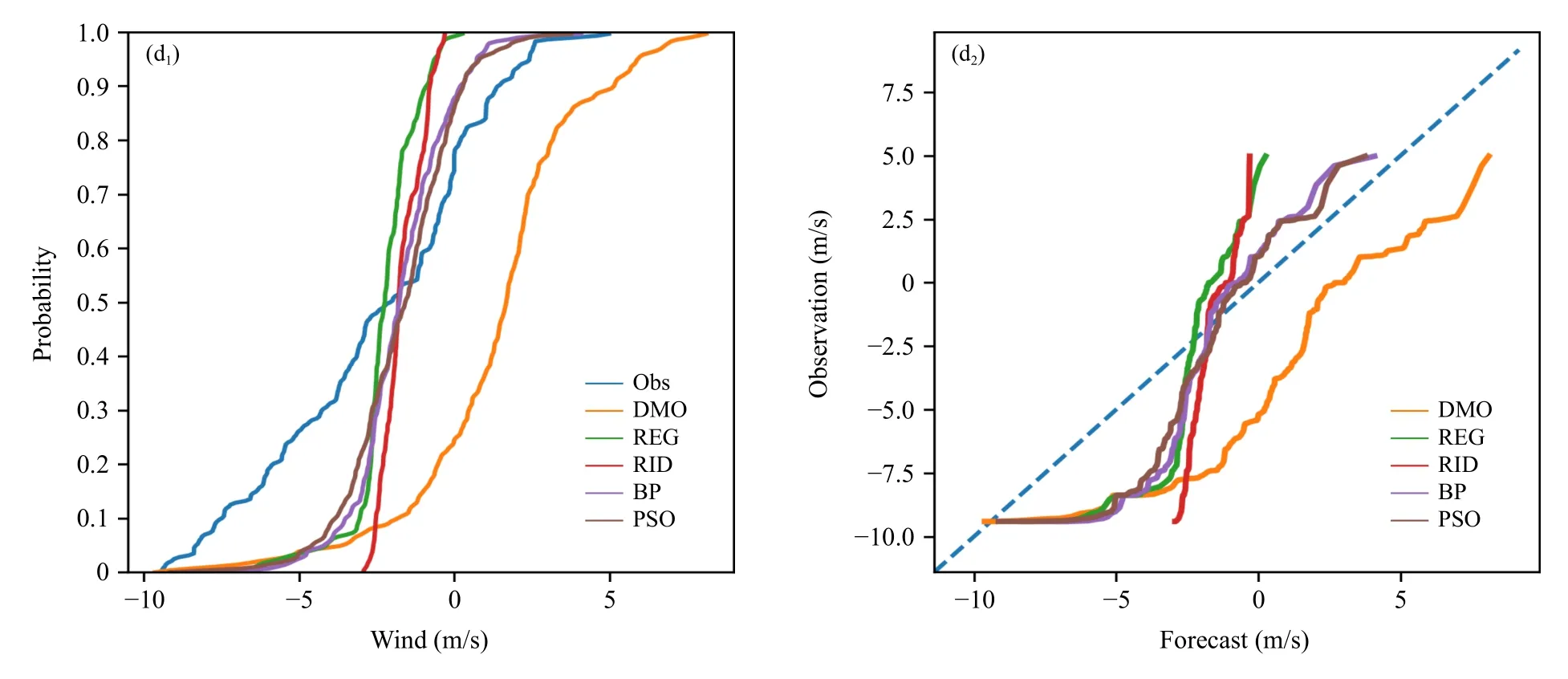
续图 5 Fig.5 Continued
4.3 风矢量分布比较
风矢量分布统计是以环状颜色带表征不同角度上的平均风速、频率和风速一致性变化;环状带距原点的距离表示平均风速的大小;环状带的宽度越宽,即该角度的风发生的频率越大;环状带的颜色表示风的一致性,将某个角度的风速平均值除以其标准差,其数值代表风的一致性,如标准差为0 时,表明该角度的风速都相同,一致率等于1,图中颜色越浅表示一致率越高。以某一个中心角度左右22.5°(即45°夹角)选取样本,计算得到上述数值。
图6 中红色环带是实况风矢量分布,可知不同测站的风分布差异较大,矢量图的色调偏深,说明相同角度的实况风一致率低,即风速振荡幅度大。
矢量分布图展示了不同方位角对应的预报和实况相差程度,不同测点上的DMO 完全相同(图6a1—e1),在大多数的风向上,DMO 预报误差大。在部分方位,DMO 和实况有较好拟合:如1489 站,西北偏北—东北偏东(顺时针,下同)DMO 和实况基本重合;1705 站,西北偏北—东北、西南—正西近似重合;说明原始数值模式产品在部分风向上有较高的预报准确率。但是,DMO 在正东—东南预报偏大。
RID 法(图6a2—e2)有以下特点:平均风较小、风速一致率高、环状带凸起部分的朝向和实况较吻合;盛行风的方位,RID 环带的宽度也较大。RID环带都位于实况环带内部,且色调偏浅,与上述频率关系图到矢量图中具体到每个方位角上的风预报能力基本一致,说明回归法(REG、RID)的优势主要体现在对较弱风(大概率事件)预报订正,对于强风(小概率事件)订正效果较差。针对DMO 在正东—东南大风的预报误差,RID 有较好的订正能力。
PSO 法(图6a3—e3)在弱风和强风区都有一定的订正能力,体现在PSO 环带所围的面积都大于RID,且PSO 的色带也较深,接近实况,即订正后的风速也有较大的振荡幅度;环带的宽度变化和实况分布有较好的对应关系。1701 站,有较高的预报精度(图6b3),在盛行风区,西南—西北(环带较宽区域),PSO 和实况环带间距较小。
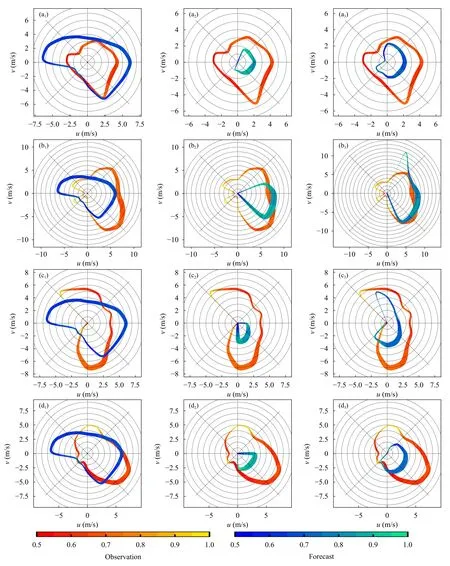
图6 分别用DMO(a1—e1)、RID(a2—e2)和 PSO(a3—e3)方法计算的5 个台站的风矢量分布统计(a.1489 站,b.1701 站,c.1703 站,d.1705 站,e.1708 站)Fig.6 Distributions of wind forecasts by DMO(a1—e1),RID(a2—e2)and PSO(a3—e3)methods at the stations of 1489(a),1701(b),1703(c),1705(d)and 1708(e)
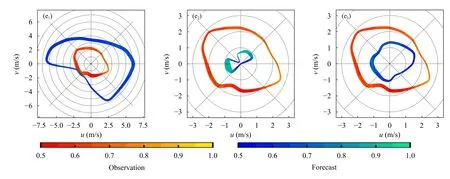
续图 6 Fig.6 Continued
4.4 大风过程分析
当风速大于10 m/s 时,将严重影响到高山滑雪的正常进行,由此,大于10 m/s 设为大风,若多日的逐时2 min 平均出现频次较多,可视为大风过程;依据1701 站的观测,在2021 年2 月15—17 日上午,19—21 日出现两次大风过程。
风预报准确率和稳定性对比(图7)显示了每个预报时效的预报和实况的一一对应关系,水平方向依次是6—72 h 的预报(6 h 间隔);色阶代表风速;图中加粗方框为风向、风速实况值。上述分析表明1701 站的PSO、1705 站的DMO 有较好的预报效果。
DMO 对1701、1705 测点的风向、风速预报都相同(图7a、d)。其中12、24、36、48、60、72 h 是数值模式预测,6、18、30、42、54、66 h 预报则是插值获得,如图所示,插值得到的预报误差偏大。
RID、PSO 法有较强的订正能力。风向订正效果明显;大风过程抑制了边界层湍流活动,实况表现出一致的西北风;对于DMO,受限于较低的时、空分辨率,难以反映出这类局地大风过程,风向偏差大,特别是通过插值得到的DMO,其风向预测紊乱;RID、PSO 法都有较好的订正能力,即便在插值时效上的预报,也能较好地预测出一致的西北风,表明在时间分辨率上有降尺度作用。订正后,风速也趋近于实况;结合风矢量分布,DMO对1701、1705 站预报的西北风都偏小(图7a、d),各时效预报误差偏大。如1701 站在14 日20 时,16 日02、08、20 时,17 日08、20 时,18 日08 时实况出现棕色块(图7a2—f2,粗方框内棕色块表示风速大于12.5 m/s),PSO 法在部分时效也呈现棕色块(图7c2);误差分布图(图7a1—f1)上,相较于DMO,RID、PSO 西北风的预报偏差明显减弱。
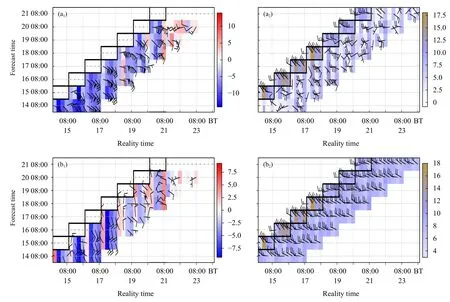
图7 2021 年2 月15—21 日的风(单位:m/s)预报准确率和稳定性对比(a—c.1701 站的DMO、RID、PSO 法预报,d—f.1705 站的DMO、RID、PSO 法预报;a1—f1.预报误差(预报减实况),a2—f2.实况和预报)Fig.7 Accuracy and consistency distributions of wind(unit:m/s)forecast from 15 to 21 Feb 2021(a—c.forecasts by DMO,RID and PSO methods at 1701,d—f.forecasts by DMO,RID and PSO methods at 1705;a1—f1.forecast error,a2—f2.observation and forecast)
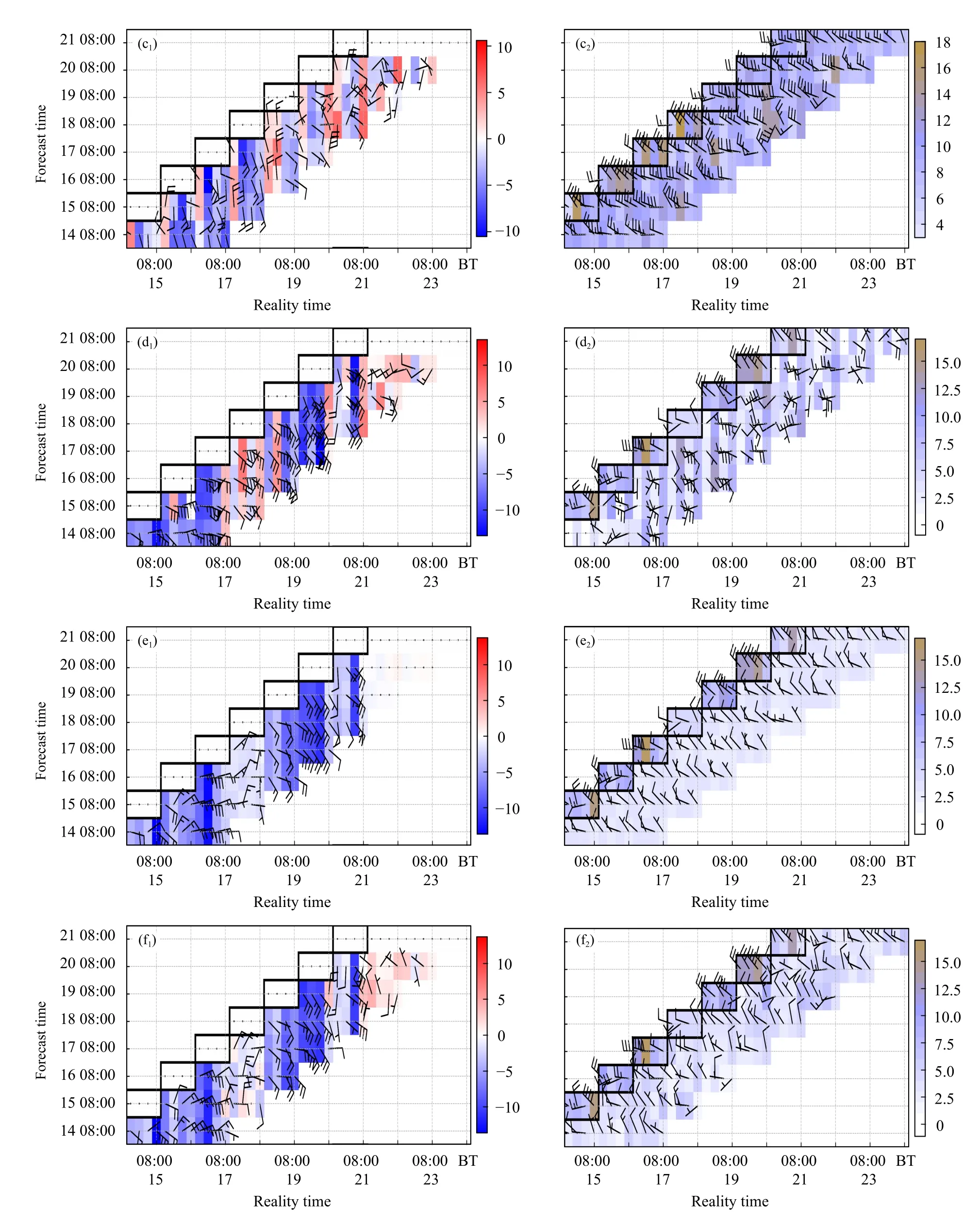
续图 7 Fig.7 Continued
风矢量分布(图6d1)显示1705 测点的DMO 在西北偏北风—东北风、西南风—正西风预报较准确,但这次大风过程的实况是西风—西北风,图6d1只是显示了风速预报偏弱,而无法显示风向预报误差;图7d 则展示了DMO 风向和实况相差悬殊,RID、PSO 则发挥了较好的订正作用。
RID、PSO 法预报偏强(弱)的趋势都比较一致,图7a1—f1的误差分布显示,纵向色阶相似;说明使用相同训练集时,不同的建模方法得到的预报强度变化趋势相同。从图7a、d 可知,DMO 预报主要是正东风—东南风,与风矢量分布图有较好的一致性,说明DMO 在该方位角存在系统性偏差,与此对应的RID、PSO 法得到的是西北风,表明各方法都有较强的系统偏差订正能力;图3c 也印证了各建模方法有较高的预报技巧。
5 小结和讨论
文中讨论了5 种方法在5 个测点上预报风速平均误差、风向准确率、风速频率、风矢量分布和大风过程的差异,得到以下结论。
(1)建模方法明显降低了预报误差、提高了预报准确率。DMO 的东西(南北)向风分量的平均误差是−1.4 m/s(3.3 m/s),建模后,误差为0—0.3 m/s(0.4—0.8 m/s);DMO 的平均风向(风速)预报准确率是0.11(0.16),建模后,提高到0.27—0.3(0.23—0.26)。随着预报时效延长,DMO 预报误差存在周期性、较大幅度的振荡,建模订正后,有效抑制了振荡幅度,预报误差变化趋于平稳。
(2)频率关系揭示了神经网络法的优势。回归法只在大概率事件中(偏弱风)有较好的误差订正能力,在小概率事件(偏强风)中无法有效订正预报误差。神经网络法对不同强度的风预报都能进行有效的订正,而PSO 法获得的预报精度普遍高于BP 法。
(3)通过风矢量分布比较,对于不同方位角的风速,回归法的风速预报明显偏小,且色带颜色偏浅,表明回归法得到的预报变化幅度小。神经网络法对应的环带包含的面积较大、色带颜色偏深,更接近于实况风变化。对大风过程分析表明,DMO的风向、风速预报和实况差别大,建模订正后,改善了预报精度;在预报时效降尺度方面,回归法和神经网络法都有较理想的效果;对于DMO 的系统偏差订正能力上,各方法都有较好的表现。
山区风的预报难度大,较高的预报技巧是建立在对局地风场结构变化特征的理解上;因此,还有诸多深层次的问题值得探索,如在不同环流场中,环境风和山谷风预报技巧、边界层湍流日变化和可预报性问题等。总的来看,神经网络法更有优势,在应用中,要关注以下几个方面:(1)模型超参数优化问题,神经网络法中的参数通常是依据大量的试验得到;采用统一的参数值主要是便于比较,但是,不同站点风的差异大,相同参数无法反映出站点间的差别,只有针对每个站点独立试验比较,才能获得合理的参数提高预报技巧;如PSO 方法涉及较多参数,其优化过程离不开更多细致的分析。(2)只使用单因子(风速统计特征量)作为模型输入量,若引入更多的数值模式预报量,提炼出更丰富的模式信息,可能会进一步提高预报精度。同时,大量的训练样本是提高神经网络法预测精度的有效途径,也是开展相似法预报的基础,随着观测数据的增多,将有助于提高风的预报能力。(3)BP 法优化及其拓展种类众多,是人工智能主要发展方向;如群智能中种群和粒子构造、飞行、适应度函数设计等问题的深入研究,借助于更优良的网络结构,风的预报将更稳定、更精准。
