基于模糊K线的FCLSTM-vSVR模型的股票价格预测
2022-04-28刘茜阳张亚萌
刘茜阳,宋 燕,张亚萌
(1上海理工大学 理学院,上海 200093;2上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
金融数据是现代经济学不可分割的一部分。在金融市场中,由于具有较高的回报率,股票市场成为最热门的投资领域。股票价格反映了公司的经营状况,为投资者提供了重要的投资参考。为了使利益最大化,降低投资风险,投资者有必要对股票价格进行预测。然而,由于股票市场受到国外市场行情、时事生态和投资者行为及心理等多方面因素的影响,其数据呈现非线性和非平稳特征,这使得预测更具挑战性。因此,长期以来,股票价格预测一直是金融学者研究的重点。
目前,股票预测方法主要包括基本分析法、技术分析法、组合分析法、时间序列分析法、机器学习和神经网络等几大类。传统的股票市场预测技术主要是基于历史股票数据的统计分析,如自回归综合移动平均模型(ARIMA)、自回归条件异方差模型(ARCH)和广义自回归条件异方差模型(GARCH)模型,已被广泛用于金融市场的预测中。但由于股票自身的非平稳与非线性特征,这些统计方法并不能在预测时达到较好的效果。
近几年,随着人工智能领域的发展,机器学习方法在股票市场预测中被广泛应用,并取得了一定的研究成果。其中,人工神经网络(ANN)和支持向量回归(SVR)是预测金融时间序列流行的技术,因为不需要做任何的统计假设条件,可以直接提取数据间的非线性关系。同时,在小样本预测方面,与ANN方法相比,SVR不容易陷入局部最优,因此有较大的优越性。但这些方法在处理输入数据时并不能捕获序列数据的顺序信息,对时间序列问题没有优秀的泛化能力,所以预测效果仍然受到了一些限制。
循环神经网络(RNN)解决了这一问题,因其具备了时序概念,对股票的预测性能更好,但RNN在训练时往往会出现梯度消失或梯度爆炸的问题,这导致时间序列的长期依赖关系很难学习。1997年,Hochreiter等人在论文《Long Short-Term Memory》中,针对RNN不能解决数据的长序依赖的问题进行研究并提出了LSTM模型。但是此LSTM的记忆存储会随序列长度的延伸而增长,最终可能会导致网络崩溃,因此,在2000年针对该问题,Felix等人在LSTM神经元内部增加了遗忘门,使数据在传输时可以保持长时记忆。因此LSTM神经网络被越来越多地应用到金融时间序列的预测中。
此外,基于LSTM神经网络的混合方法也被广泛应用于金融时间序列分析中,并通过与单一模型方法相比获得更高精度的预测结果。然而,大多数混合方法虽然在一定程度上提高了预测精度,但这些方法都是通过对LSTM预测模型的输入进行分析,而没有对于LSTM模型产生的残差进行分析预测。
基于上述问题,本文提出了一种将遗传算法、LSTM网络、模糊K线和改进的支持向量回归算法(vSVR)相结合的混合股价预测模型。第一阶段,该模型首先利用遗传算法对LSTM神经网络的参数进行优化,然后用训练好的LSTM网络产生预测输出。第二阶段,基于模糊K线模型提取到的模糊信息,采用vSVR模型预测误差。最后,将两阶段的预测值之和作为最终的股票价格预测值。本文的贡献主要如下:
(1)对于LSTM网络的部分参数、如时间窗口大小和结构参数的估计,以往通常采用试错法,但效率较低,本文利用遗传算法优化LSTM网络,以选择最佳的窗口大小、神经元数目。
(2)由于股票价格序列可以由K线表示,而且会受到多方面因素的影响,本文利用模糊理论将股票价格数据转换为模糊数据,采用vSVR模型建立预测误差与股票模糊信息之间的映射关系,减小了模型的固有误差。
(3)实验结果显示本文提出模型的预测效果更好,拟合程度更优。
1 背景知识
1.1 LSTM神经网络
近年来,LSTM神经网络已陆续应用于时间序列预测、文本分类等领域中,具有较高的精度。LSTM单元结构如图1所示。由图1可知,LSTM单元控制门结构主要包含遗忘门、输入门与输出门。遗忘门f控制细胞在1时刻的状态有多少信息会被遗忘,输入门i决定有多少新信息将被保存到时刻的细胞状态,输出门o决定输出新细胞状态的信息。其计算过程如下:
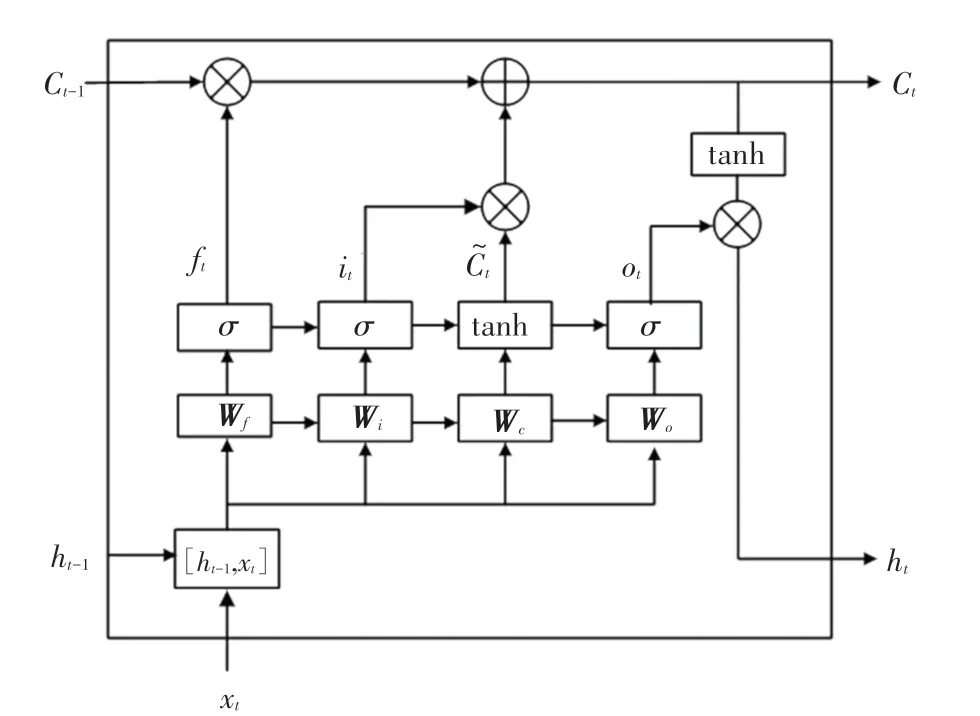
图1 LSTM单元结构Fig.1 The LSTM cell structure


当使用LSTM网络进行股票价格预测时,前期多个时刻的收盘价将作为输入,当前时刻的收盘价作为输出。对于LSTM模型预测而言,时间窗口起着较为重要的作用,每层神经元数也是LSTM模型优化的重要参数。本文利用遗传算法对LSTM模型进行优化,得到时间窗口和隐藏层神经元数的最佳值或接近最佳值。
1.2 vSVR模型
SVR是支持向量机(SVM)在回归问题领域的推广,其中vSVR模型是一种改进的SVR,新参数控制误差分数的上界和支持向量分数的下界,并自动最小化误差参数,这使得更容易通过手动校准来调整参数。对于给定的一组数据点{(,),(,),…,(x,y)},其中x∈R是输入,y∈是目标输出,vSVR模型使用核函数将不可分割的输入数据x映射到高维空间,从而使得目标值与训练数据得到的回归函数()(,())的距离最小,即极小化目标函数:

其中,常数表示错误样本个数占总样本个数份额的上界或支持向量与总样本数比值的下界;()为核函数;和分别表示权重和偏置;表示误差;ξ和为松弛变量;为惩罚参数。
其对偶问题为:

其中,和为拉格朗日乘子,且其值都不为0,(x,x)为核函数。决策函数变为:

相对于传统的经济学模型和基本的机器学习方法,单一的LSTM神经网络的预测精度虽然有所提高,但这并不能满足人们的需求。针对这个问题,本文利用vSVR模型进行残差分析来提高LSTM神经网络的预测精度。
2 基于模糊K线和遗传算法的FCLSTMvSVR股票价格预测方法
2.1 模糊K线
研究可知,经过不断演变,K线图现已形成了拥有完整形式和分析理论的技术分析方法。在K线图中,影线长度和实体长度在识别K线模式上发挥了重要作用。但是,在日常生活中,人们对于K线的描述往往难以做到精确,甚至是模糊的,例如长的、中等的或者是短的。因此,本文将引入Naranjo等人在股票预测中所提到的模糊变量法,即运用模糊集合理论将本文的股票时间序列数据转化为模糊化的数据,并作为vSVR模型的输入,LSTM神经网络的残差作为输出构建vSVR模型。
首先,将K线的3个变量包括上影线、下影线和实体的长度(L、L和L)作为输入数据,R和R作为模糊输出数据,分别表示实体与烛台整体之间的相对大小和相对位置。交易时间中的3个模糊输入可以定义如下:

其中,(),(),(),()分别表示时刻的开盘价、收盘价、最高价和最低价。然后利用式(15)将这3个变量缩放到[0,100]之间,数学公式具体如下:
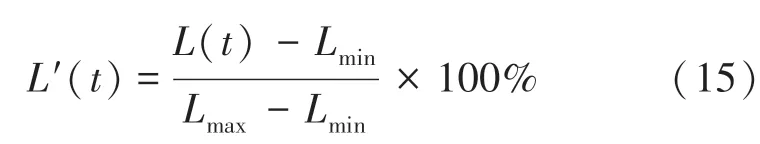
其次,用定义的4个模糊语言变量来描述3个输入变量:NULL、SHORT、MIDDLE、LONG,如图2所示。用5个模糊子集来描述R:DOWN、CENTER_DOWN、CENTER、CENTER_UP、UP,如图3所示。用5个模糊子集来描述输出变量R:LOW、MEDIUM_LOW、MEDIUM、MEDIUM_EQUAL、EQUAL,如图4所示。

图2 Lu、Ll和Lb的隶属度函数Fig.2 Membership function for Lu、Ll and Lb

图3 Rp的隶属度函数Fig.3 Membership function for Rp
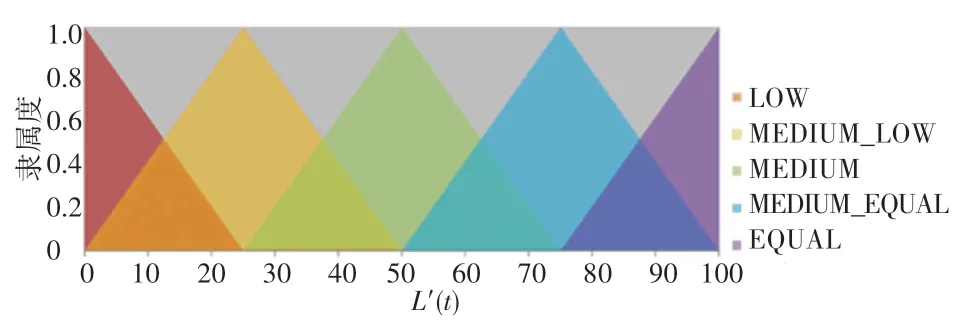
图4 Rs的隶属度函数Fig.4 Membership function for Rs
最后,基于128条IF-THEN模糊规则,详见表1中的部分模糊规则,并用质心法去模糊化得到输出数据。

表1 模糊规则Tab.1 Fuzzy rules
2.2 GLSTM模型
由于LSTM网络在学习过程中使用过去的信息,不同的时间窗口会对模型学习性能的提高起不同的作用。窗口过小,模型会忽略重要信息;窗口过大,模型会对训练数据过度拟合。所以将遗传算法用于优化LSTM模型,以选择最佳的窗口大小、神经元数目,即GLSTM模型。图5给出了GLSTM模型的流程图。

图5 GLSTM模型流程图Fig.5 The flowchart of the GLSTM model

图6 LSTM模型结构Fig.6 The structure of the LSTM model
2.3 FCLSTM-vSVR模型
由于GLSTM网络模型较为单一,本文提出了一种基于模糊K线的FCLSTM-vSVR模型的股票价格预测方法。其中,主模型是基于遗传算法的LSTM网络模型,次模型是vSVR模型。
对于主模型,基于不同的参数设置,LSTM网络模型的预测结果和性能会有所不同。所以本文首先通过遗传算法进行参数寻优,找到模型的最佳时间窗口大小和隐藏层单元数,如2.2节所示。
对于次模型,vSVR模型是一种不依赖于任何先验知识的机器学习非线性回归方法,该模型参数具有明确意义,更利于得到精确的回归解,因此在小样本预测方面具有显著优势。图7描述了FCLSTMvSVR模型的流程图。
图7中,FCLSTM-vSVR残差修正模型的处理流程如下:
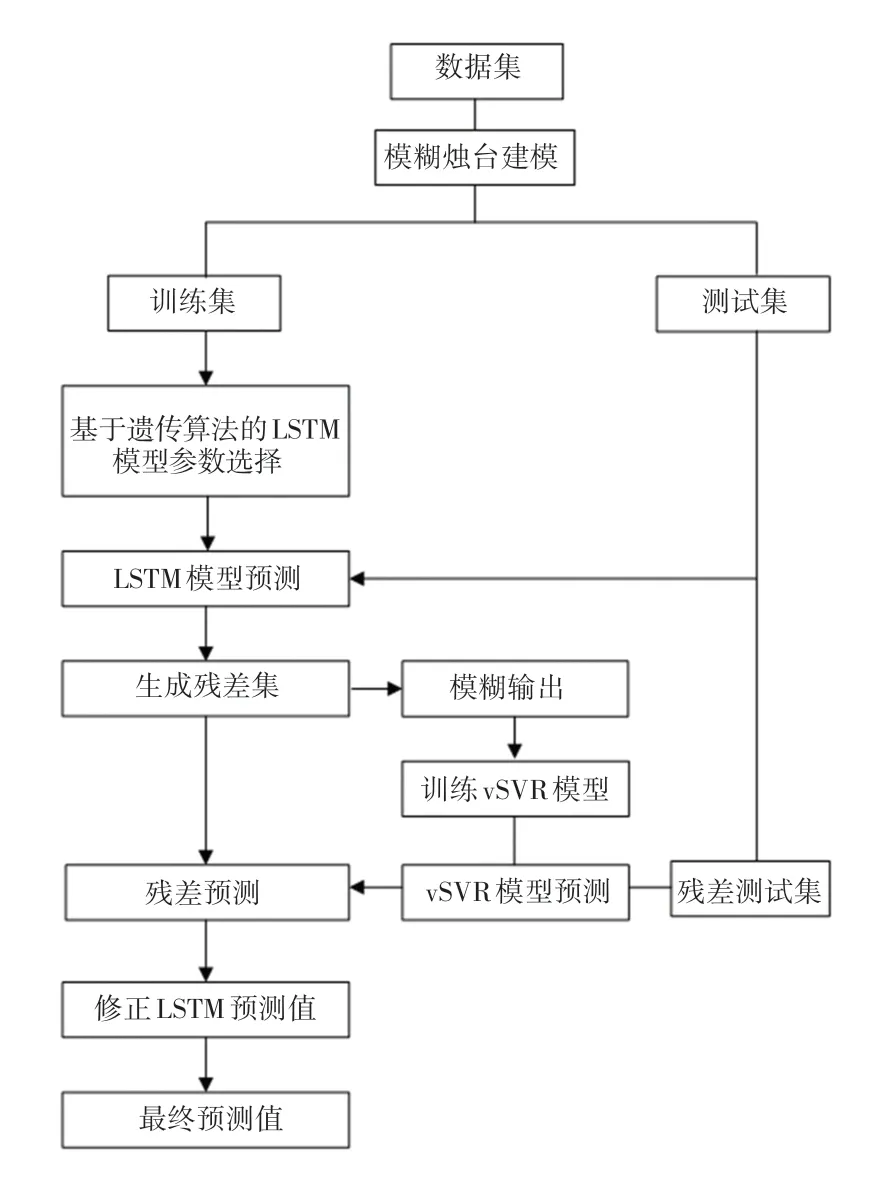
图7 FCLSTM-vSVR模型流程图Fig.7 The flowchart of the FCLSTM-vSVR model
(1)利用数据集原始价格数据建立模糊烛台模型,得到2个模糊输出数据R和R。然后将数据集拆分为训练集和测试集,并利用最大-最小标准化公式进行归一化处理。
(2)将训练集部分划分为验证集,利用训练集建立GLSTM预测模型:
①使用二进制位编码表示时间窗的大小和LSTM神经单元数。
②随机生成初始种群,根据适应度函数和选择进行评估,然后进行交叉和变异,使用赌轮盘选择。在本文中使用均方误差()来计算每个染色体的适应度,输入LSTM模型,在验证集上计算,并返回该值将其作为当前遗传算法解决方案的适应度值,得出最优时间窗口大小及最优神经网络隐藏层单元数。
③重复该过程直至满足终止条件。
(3)将经过良好训练的GLSTM预测模型应用于整个训练集的股票价格预测中,得到不同时刻的预测残差值e,形成历史残差,称为残差集。

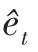
3 实验
为了验证实验结果,本文将设置GLSTM模型、vSVR模型、BPNN模型、ARIMA模型、GLSTM-BPNN模型作为对照,其中GLSTM模型的输入为收盘价历史数据,并对ARIMA模型使用网格搜索法确定最优参数。本节通过股票历史数据验证了FCLSTM-vSVR模型的优越性和稳健性,也对FCLSTM-vSVR模型和其他模型进行了性能比较。所有模型都由Python3.6和TensorFlow实现,电脑的操作系统Windows 10,处理器是英特尔i7-7820HQ(2.90千兆赫)。模型的主要最佳参数是通过在验证集上不断试验和参考相关文献确定的,见表2。

表2 模型的部分参数设置Tab.2 Parameters setting of the model
3.1 数据来源
本文使用从雅虎财经网站获得的5只股票数据集:AAPL、ADI、WTI、GSPC、IXIC。每只股票数据集的时间跨度为2015年1月4日至2020年10月22日。数据集划分为训练集和测试集,其中训练集为80%,测试集为20%。这里,训练集中选择20%数据作为验证集来确定超参数。
3.2 评价指标
为了量化模型的性能,引入了5个指标:平均绝对误差()、平均绝对百分比误差()、均方误差()、均方根误差()、决定系数(),这些指标可以定义如下:
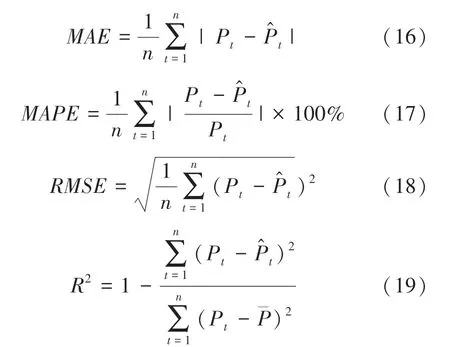
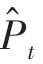
3.3 结果分析
首先通过遗传算法,本文得到LSTM网络的最优结构因素,包括LSTM网络的时间窗口大小和隐藏层的单元数。其中,时间窗口大小取值范围为[5,30],隐藏层单元数取值范围为[10,100]。表3显示了GLSTM模型在各个数据集上的训练得到的参数结果。例如股票AAPL预测的最佳时间窗口大小为6,最佳LSTM隐藏层单元数为80。也就是说,对于股票AAPL,利用过去6个交易日的信息来分析预测是最有效的。

表3 GLSTM模型的时间窗口大小和隐藏层单元数Tab.3 Time window size and hidden layer units of GLSTM model
在得到模型最佳参数基础上,利用提出FCLSTMvSVR预测模型对各个股票数据集进行股价预测,并与其他模型进行对比。表4~表8给出了不同模型在各个数据集上的平均预测误差。对于单一模型,传统的时间序列模型ARIMA的预测效果最差。机器学习vSVR模型的预测效果与BPNN模型的效果相近,而GLSTM模型的预测效果最好。这表明GLSTM模型在具有相同的输入变量下可以获得相比于普通机器学习的模型vSVR和BPNN更好的性能。所以在股票预测中,GLSTM网络模型是一种较好的预测方法。

表4 AAPL上各模型比较结果Tab.4 The evaluation results of different models on AAPL

表5 ADI上各模型比较结果Tab.5 The evaluation results of different models on ADI

表6 WTI上各模型比较结果Tab.6 The evaluation results of different models on WTI

表7 GSPC上各模型比较结果Tab.7 The evaluation results of different models on GSPC
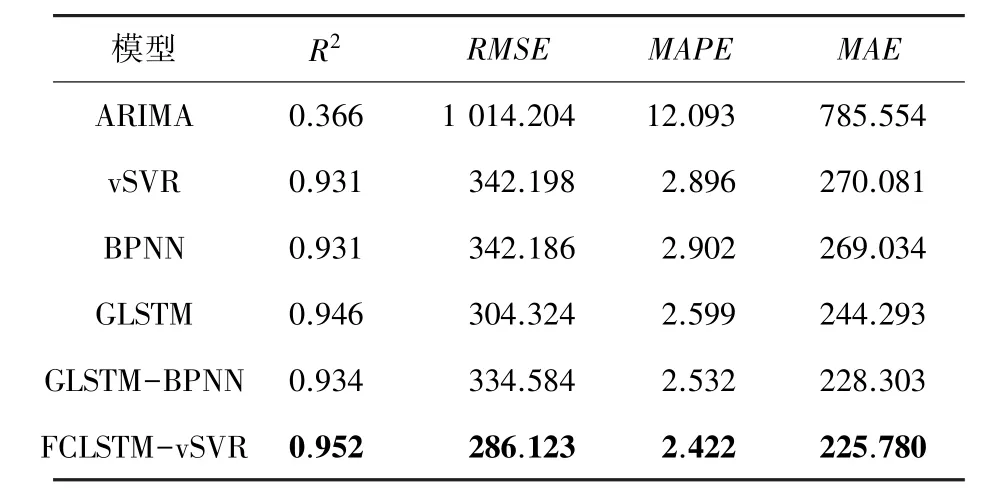
表8 IXIC上各模型比较结果Tab.8 The evaluation results of different models on IXIC
对于混合模型GLSTM-BPNN,在股票GSPC上的结果比其他单一模型的预测效果好,、、、分别为0.923 23、81.552 46、1.924 91、56.304 93,与GLSTM模型相比,精度分别提高了0.86%、4.32%、11.39%、13.21%。但在其他数据集上,模型GLSTM-BPNN结果并不理想,这可能与神经网络参数设置不合理有关。
所有数据集中,与GLSTM模型相比,FCLSTMvSVR的误差指标均保持较低值,也更接近于1,拟合效果更好。这一结果的主要原因是增加了残差分析。结果表明,残差分析是一种能显著提高股价预测精度的方法,残差中具有重要的信息价值,值得进行深入研究。基于模糊烛台建模,2个模糊输出变量(R和R)在残差模型中成功应用,这一结果表明,在数据中的模糊信息对于残差序列也具有影响。与GLSTM-BPNN模型相比,FCLSTM-vSVR的所有指标结果都较好,这表明vSVR模型与BPNN相比,对于小样本具有更精确的回归解。所以,对于股票价格预测,FCLSTM-vSVR模型与其他模型相比具有更好的预测效果。
为了更好地观察模型GLATM-vSVR的性能,在测试集上实际值对于模型预测值的拟合效果如图8所示。


图8 收盘价真实值与FCLSTM-vSVR模型的预测值对比Fig.8 The comparison of the actual closing price values with the predicted value of FCLSTM-vSVR model
由图8可知,提出FCLSTM-vSVR模型得到的预测值与真实值较为接近。但由于市场环境和投资人行为等因素的存在,所以零误差的预测无法实现。但本文提出模型与其他对照模型相比,取得了较为理想的预测效果。
4 结束语
对股票市场的预测可以产生实际的盈利或亏损,因此提高模型的可预测性对投资者来说是非常重要的。在本文中,提出了一种新的基于模糊K线的混合股票价格预测模型,即FCLSTM-vSVR模型。具体来说,首先本文将遗传算法和LSTM网络结合起来考虑股票市场的时间特性和模型的自定义结构因素。利用遗传算法搜索时间窗口大小和神经网络隐藏层单元数的最优或接近最优值。然后,提出了一种降低预测误差的方法来提高GLSTM模型的预测精度。该方法采用模糊K线模型来表示原始价格序列中的模糊信息,vSVR模型建立预测误差与模糊输出因素之间的映射关系。本文选取5个股票数据集,通过对比试验,验证了该模型的可行性。实验结果表明,与基线模型相比,所提出的模型具有更高的预测精度。但使用遗传算法寻找LSTM神经网络模型参数所需时间与计算资源较大。因此,寻找一种更简单的方法来优化LSTM网络参数将是下一步研究的方向。
