机理与数据驱动的电站锅炉SCR催化剂寿命预测模型研究
2022-04-26胡佳颖喻聪王子良司风琪
胡佳颖,喻聪,王子良, 司风琪
(1.江汉大学智能制造学院,武汉 430056;东南大学能源与环境学院,南京 210096)
在我国,燃煤电厂是氮氧化物(NOx)的主要排放源之一,它会对环境和人体健康造成恶劣影响。目前,电站锅炉普遍采用选择性催化还原法(Selective Catalytic Reduction,SCR)进行烟气脱硝。该方法是在催化剂的作用下,利用NH3将NOx还原为无污染的N2和H2O。其中,催化剂是SCR系统的核心装备,成本最高,且直接影响脱硝效率[1]。厂家保证的催化剂寿命约为24 000小时,但电厂实际气、固两相流环境复杂,燃用煤种、运行方式、尺寸结构等诸多因素的不同会使催化剂的劣化趋势千差万别[2-3]。据统计,我国每年需更换的SCR催化剂体积约10~20万m3,按1.5万元/m3的平均单价核算,总价值约15~30亿元。过早的换装会造成催化剂的浪费与成本的损失,而过晚的换装则会引起电站NOx排放浓度超标及氨逃逸过大,从而影响机组运行的环保性和安全性[4-6]。因此,催化剂的寿命预测有着重要意义。
传统的催化剂寿命评价方法是实验室检测[7-8],该方法是利用机组检修期间从炉内抽取催化剂样本块,并带回实验室检验活性。然而,火电机组一年一小修、四年一大修的检修周期决定取样的时间点较少,不足以支撑催化剂3~5 a生命周期内活性劣化趋势的精确描绘,且炉内大截面烟道存在烟气的不均匀性,所抽取催化剂样本块的活性无法代表整个SCR反应器的脱硝能力,这都会影响评价结果的可信度。为解决这些问题,宋宝玉等[9-10]提出了基于现场性能试验的脱硝装置潜能预测,以对SCR反应器宏观性能进行直接衡量,解决了传统实验室检测法样本代表性不足的问题,且检测次数不再受机组启停影响。然而,现场性能试验成本较高,且为满足每次试验所需的烟气条件,均需向电网申请稳定发电负荷,这将给承担调峰调压任务的火电机组增加额外负担,因此该方法的预测精度同样会受到试验次数的影响。为进一步降低预测成本,学者们又提出基于历史运行数据的催化剂寿命评估方法。一部分学者直接采用机器学习算法评估催化剂的活性[11-14],而另一部分学者将数据挖掘和机理建模相结合,即首先建立催化剂动力学模型[15]或考虑堵塞、磨损、中毒等因素的综合失活机理模型框架[16],再利用电站SCR烟气脱硝系统实际运行数据对模型参数进行辨识,以得到催化剂的活性劣化模型。然而,目前尚未见将这两种模型进行对比与分析的研究。
本文以某电厂SCR脱硝系统3年历史运行数据为样本,通过建立2种异常值剔除程序,对比3种稳态样本识别算法,建立了大数据过滤器,获得了高质量稳态样本集。在此基础上,采用BP神经网络将脱硝效率修正到同一运行水平,以表征催化剂健康状态,并对比了机理模型及ARIMA模型对催化剂劣化趋势的预测精度,进而分析了误差的原因。
1 算法流程
本文以某660 MW电站燃煤锅炉SCR系统单侧反应器3年历史运行数据为样本。算法流程为:
Step1:利用统计法标记停滞点和超限数据。利用一种基于t检验和两种基于R检验的方法,标记出非稳态数据样本。并剔除原始数据中所有异常值和非稳态数据,得到稳态样本集;
Step2:分别采用10 d、20 d、30 d三种时间步长整理出按时间排列的稳态数据子集,在单个时间步长内,假设催化剂寿命变化不大,并基于每个步长区间的数据,分别利用BP神经网络建立脱硝效率与运行工况的静态关系模型;
Step3:基于Step4的关系模型,将每个时间步长的脱硝效率修正到同样的工况水平,此时脱硝效率的变化可表征催化剂宏观性能的变化。
Step4:分别采用机理模型和ARIMA模型对各时间步长的催化剂宏观性能点进行回归,建立催化剂性能劣化模型。
2 大数据过滤器
2.1 异常值剔除
数据挖掘前,对异常值进行甄别并剔除。异常值包括由机组停机或数据传输故障引起的停滞点数据和粗大误差数据。粗大误差数据通过统计法及经验设置上下限进行过滤,各参数限值如表1所示。
以入口NOx浓度为例,图1(a)为NOx数值范围统计,以此确定常规运行区间为150~535 mg/m3,并通过上下限过滤掉超限的数据。图1(b)标记了数值完全不变的停滞点数据。
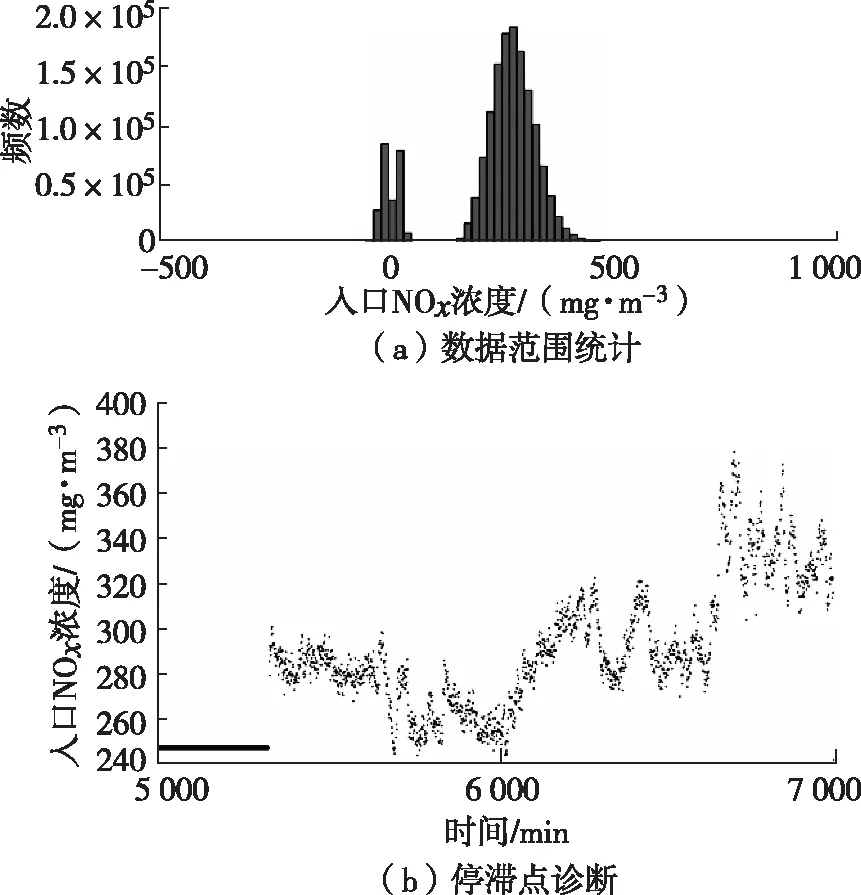
图1 入口NOx浓度异常值诊断
2.2 非稳态点剔除
由于流动延迟及催化剂吸附反应固有的蓄氨机制,SCR过程常处于非稳态状态,而本文是利用静态关系模型将不同时间的脱硝效率修正到同一烟气环境水平,再以此建立催化剂的性能劣化模型。因此,需要通过算法获取稳态样本。
2.2.1 基于t检验的稳态判定
第一种稳态检验算法是基于滑动窗对数据进行t检验[17]。算法可描述为:
xt=mt+μ+at
(1)
式(1)中,xt是时间窗内n个等距采样的数据点;m为斜率,其估计值为时间窗内所有xt-xt-1的算数平均值;t为时间,min;mt为偏移分量;at是白噪声序列;μ是平稳过程假设下的数据平均值,其估计值为:
(2)
式(2)中,n为时间窗内数据的个数。
由m和μ可计算白噪声的标准差σa:
(3)
如果过程数据与其平均值之间的差值小于等于白噪声标准差乘以其统计临界值,可认为这个瞬间的数据点是稳定的,如果大于则不稳定的。
(4)
式(4)中,tcrit为白噪声的统计临界值,yt为t时刻xt数据的稳定性指标。
一个时间窗内数据的稳态值为式(4)中所有yt的平均值。当稳态值大于等于稳态阈值,这个数据点处于稳定状态,稳态因子为1,反之为0。因此,算法中滑动窗口的大小和稳态阈值会影响稳态数据的判定。如图2所示,本文选取一天的负荷数据,分别计算滑动窗口尺寸为10~50对应的稳态识别率(机器正确识别为稳态数据的数目与真实稳态数据数目之比),得到滑动窗口为10时的稳态识别率最高,因此本文窗口大小选择为10。针对同一段原始数据,分别选取稳态阈值为0.75~0.95,得到当稳态阈值取为0.75和0.8时,稳态识别率最高,如图2(b)所示,但考虑到稳态阈值为0.75时的误诊率(机器错误识别为稳态数据的数目与机器识别为稳态数据的数目之比)较大,因此稳态阈值选择为0.8。
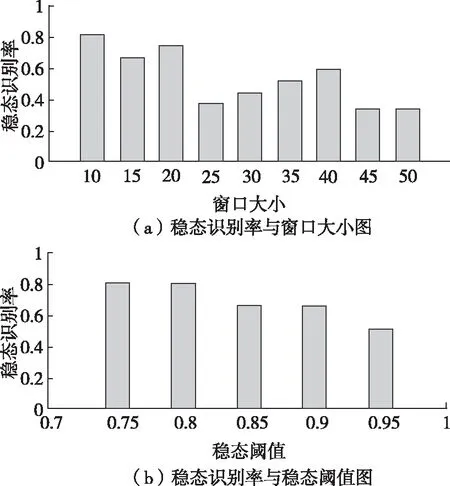
图2 窗口大小和稳态阈值对识别率的影响
2.2.2 第一种基于R检验的稳态判定
第二和第三种稳态检验算法均是基于R检验法。为了减少计算负担,第一种R检验法[18]采用过滤值估计数据的平均值Xf,i:
Xf,i=λ1Xi+(1-λ1)Xf,i-1
(5)
式(5)中,Xi是i时刻的数据值,λ为滤波系数,Xf,i是经一阶滤波后,当前时间序列的滤波值。
第一种计算方差的方法是基于数据和平均值之间的差值加权:
(6)
(7)
(8)
2.2.3 第二种基于R检验的稳态判定
数据平均值为:
(9)
式(9)中,Xi是i时刻的数据值,N为数据个数。
第一种方差估计值为:
(10)
第二种方差估计值为:
(11)
将两种方差之比作为R值:
(12)
对于两种R检验法,R值越小,数据越可能趋近稳定状态。将R值小于稳态阈值时,稳态因子为1,数据状态为稳定,否则稳态因子为0。同样对两种R检验法选择合适的窗口大小和稳态阈值。
2.3 三种稳态诊断算法测试
以1 d的负荷数据作为测试集,对比三种稳态算法的效果,三种稳态算法结果对比如图3所示。对比可知,对于本对象数据集,基于t检验的稳态算法效果最好,能较准确识别出三段数据明显为稳态的区域及一段数据波动但为稳态的区域。第一种R检验法会对部分稳态与非稳态过渡区的数据产生一定误诊,第二种R检验法对数据中的小波动非常敏感,会漏诊较多稳态样本。因此,本文采用t检验法提取原始数据中的稳态样本。
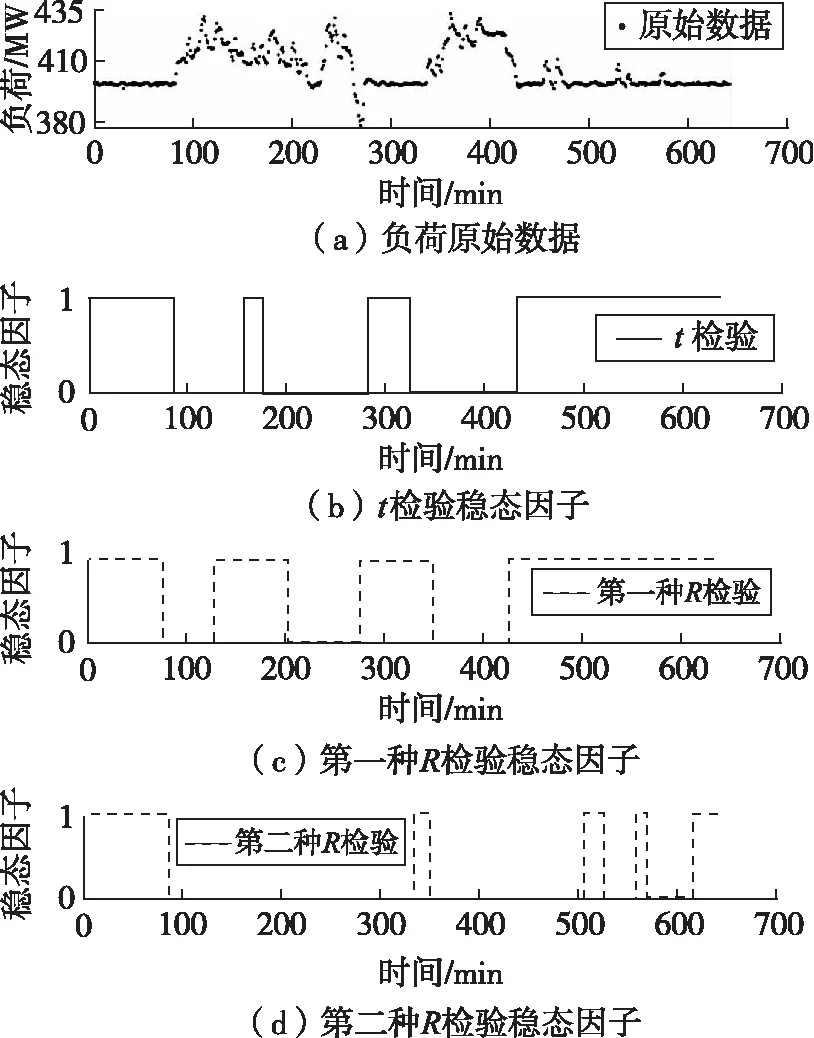
图3 三种稳态算法结果对比
3 寿命预测
3.1 预测思路
对于结构确定的SCR脱硝系统,脱硝效率由两方面因素决定,一个是烟气环境,如空速、温度和氨氮摩尔比等,而这些又由运行参数决定,如负荷和O2量会影响烟气量的大小,从而影响空速;另一方面,脱硝效率还受催化剂自身活性决定,活性越高,脱硝效率越高。火电机组发电负荷受电网调度控制,会不断变化,因此锅炉内的烟气环境也是不断变化。本文的思路是将不同时期的脱硝效率修正到同一烟气环境水平,此时脱硝效率只受活性影响,其变化趋势可表征活性的变化趋势。据此,利用修正后的效率数据分别训练机理模型和数据驱动模型,并利用两个模型预测未来催化剂活性劣化的趋势,结果与真实稳态运行样本比对。
3.2 脱硝效率的修正
对于SCR系统,可认为负荷、O2量、烟温、入口NOx浓度和总尿素量5个参数可决定催化剂所处的烟气环境。本文以大数据过滤器得到的稳态数据为样本,分别以10 d、20 d、30 d为时间步长,将3年的历史运行数据依次分成若干个样本子集。对于每个步长所形成的样本子集,时间跨度较短,如10 d可近似认为催化剂活性无变化,采用BP神经网络建立脱硝效率与5个烟气参数的静态关系模型。BP神经网络的拓扑结构为5-11-1,学习迭代次数为1 000,网络学习精度为0.01。三种时间步长模型集最大、最小和平均误差如图4所示。由图可知,时间间隔为10 d的时候,模型误差最小。
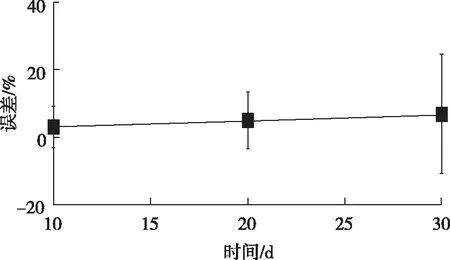
图4 三种时间步长模型集最大、最小和平均误差
选取3年中样本最充足的工况作为修正工况:负荷为494 MW、入口NOx浓度为280 mg/m3、总尿素量为230 L/h、入口烟温为323 ℃、氧量为3.1%。将该数据带入10 d、20 d、30 d三个时间步长下的所有模型中,得到各个时间间隔脱硝效率随时间的变化如图5所示。由图可知,三个步长下,脱硝效率的变化趋势基本相同,证明该步长已足够小,能保证单个步长内活性变化不大的假设成立。考虑到以10 d为周期,所建BP神经网络精度较高,且供后续模型回归的点数较多,因此本文以10 d为步长。
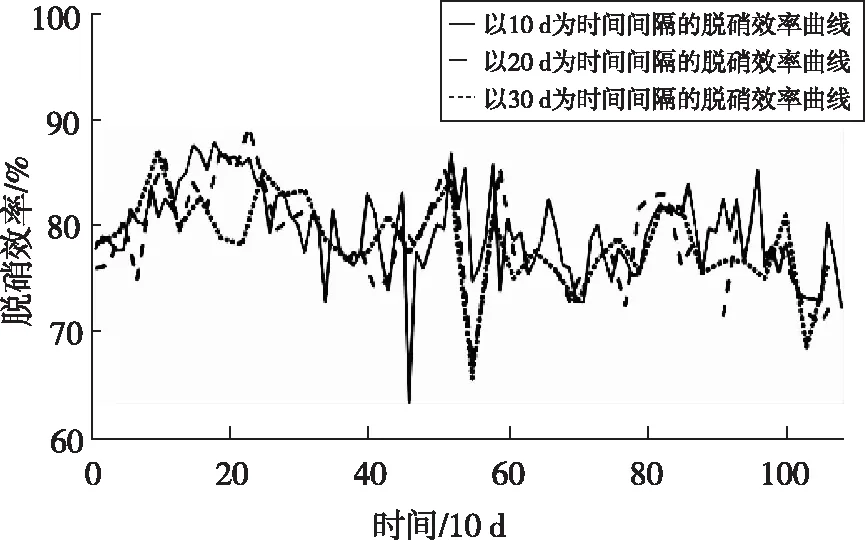
图5 各个时间间隔脱硝效率的变化图
3.3 机理模型框架
催化剂活性的定义为[15]:
(13)
式(13)中,Av为面速度(m/h);MR为氨氮摩尔比;η为脱硝效率(%)。
若催化剂中毒、堵塞、磨损独立造成催化剂失活,则失活模型为[15]:
(14)
式(14)中,Ki为毒性物质i的中毒失活速率系数,%/mol;Ci为毒物沉积速率,mol/h;V为SCR催化剂中V2O5总的物质的量,mol;t为SCR系统的运行时间,h;r为覆盖率,即单位质量堵塞物质所覆盖的面积,m2/kg;A为沉积速率,kg/h;S1为催化剂的比表面积,m2/kg;m为安装催化剂的总质量,kg;G为烟气流量,m3/h;c为磨损系数,即在平均飞灰粒径下单位流量单位流速烟气造成的磨损量,kg/(m5·h-2);v为烟气流速,m/h。
联立公式(13)和公式(14),求解脱硝效率为:
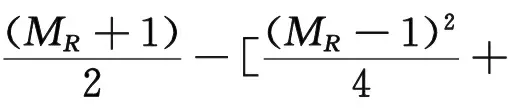
(15)
式(15)中与时间无关的参数提取为常数,并将时间单位统一为10 d,进一步得到:
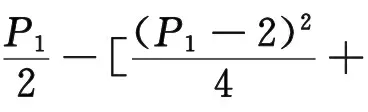
(16)
P1、P2、P3、P4、P5为模型的待定系数,表达式如式(17)所示。机理模型的训练就是利用修正脱硝效率随时间变化的数据训练P1~P5。
P1=MR+1
(17)
3.4 数据驱动模型
采用时序预测模型ARIMA作为数据驱动模型的代表,利用修正后脱硝效率的数据进行回归。对样本集进行一阶差分和二阶差分,发现差别不大,这是由于活性随着时间缓慢变化,因此将ARIMA模型中的d设置为1。图6和图7分别给出了自相关和偏自相关系数的序列图,根据截尾的状态,确定p与q分别取为2和3。
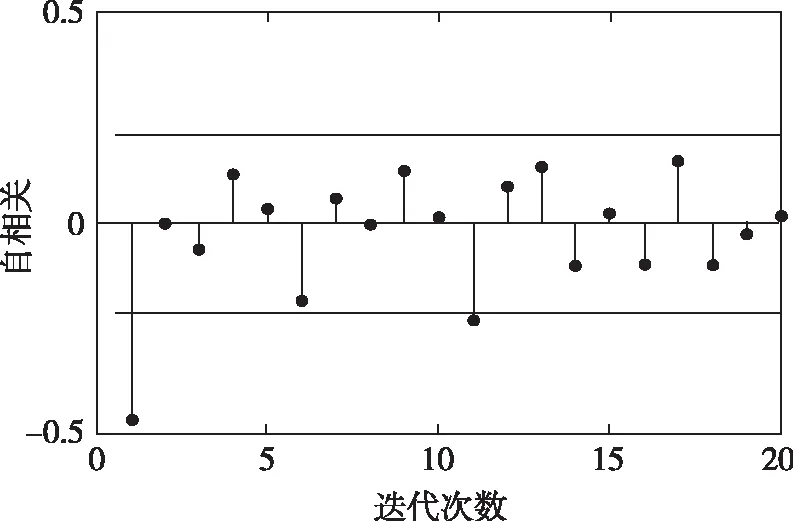
图6 自相关系数的序列图

图7 偏自相关系数的序列图
3.5 模型对比
采用10 d为步长,将3年数据分为108份,利用前90份的样本子集,建立90个BP神经网络,得到90个修正后脱硝效率点,以此训练的机理模型与ARIMA(2,1,3)模型。采用第90~108组的数据验证两个模型预测未来脱硝效率的劣化趋势,ARIMA模型与机理模型预测值对比如图8所示。ARIMA模型预测值的平均相对误差为4.31%,机理模型为7.42%。机理模型误差相对较高,可能的原因是机理模型假设条件较多,诸如烟气分布、飞灰颗粒粒径及浓度分布、飞灰的沉积效应、烟气中碱金属、碱土金属、硫的含量、低温环境等因素及其变化对失活的影响无法充分考虑,因此对模型精度可能会有一定影响。
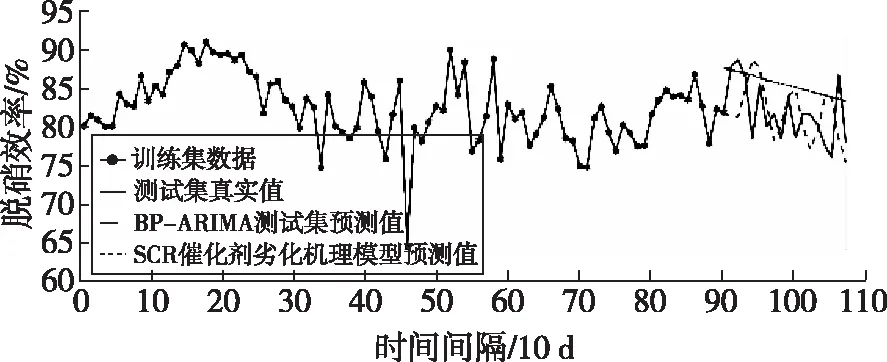
图8 ARIMA模型与机理模型预测值对比
4 结语
本文以某660 MW电站锅炉单侧SCR反应器3年历史数据为样本,结合停滞点诊断、超限点诊断及对比三种稳态点诊断算法,得到大数据过滤器及高质量稳态样本。据此,通过BP神经网络将不同时期的脱硝效率修正到同样烟气水平,以表征催化剂活性的变化,并对比了机理驱动和数据驱动催化剂寿命劣化模型的准确性。主要结论为:
(1)相较于R检验法会对部分稳态与非稳态过渡区数据产生误诊及对数据中的小波动敏感,t检验法的稳态诊断效果较好;
(2)以10 d为步长建立脱硝效率修正模型的效率和精度均较高,且得到的劣化趋势与20 d、30 d模型一致性较好,证明该步长能保证单个步长内活性变化不大;
(3)相较于机理模型框架,ARIMA模型预测精度更高,原因可能是由于电站SCR系统大尺度空间的分布特性及催化剂详细失活机制无法全面考虑。
