基于SGD的决策级融合维度情感识别方法
2022-04-25胡新荣陈志恒刘军平何儒汉
胡新荣,陈志恒,刘军平,彭 涛,何儒汉,何 凯
(1.纺织服装智能化湖北省工程研究中心 湖北 武汉 430200;2.湖北省服装信息化工程技术研究中心 湖北 武汉 430200; 3.武汉纺织大学 计算机与人工智能学院 湖北 武汉 430200)
0 引言
实现人机之间高效、智能、和谐的交互需要计算机具备理解和分析人类情绪状态的能力。由于概括人类情感存在复杂性,有效的情感识别仍然是一项艰巨的任务,情感识别技术在其中扮演着重要的角色。人的情感状态随着时间动态变化,并通过音频信号、文本中的语义信息、面部表情、身体姿态以及生理信号等多种方式表现出来[1]。但是,仅依靠单模态信息来判断情感状态会发生混淆,情感识别性能不高。随着机器学习算法的发展,可以充分利用多模态信息之间存在的关联性和互补性,通过融合多模态特征来提高情感识别任务的预测性能。
多模态融合方法是情感识别任务中的一个重要环节,如何更好地融合不同来源的数据形成一致的预测结果是目前面临的挑战。文献[2]使用concatenate方法在不同网络之间进行串联,以实现离散情感识别。文献[3]认为该离散情感描述模型在时间轴上是非连续的,无法精准描述情绪变化过程,且特征级融合方法无法针对不同模态特征选择各自最合适的模型,因此提出一种两阶段的决策级融合方法:第一阶段使用长短期记忆网络(long short-term memory,LSTM)分别对语音和文本特征进行训练;第二阶段将第一阶段的输出结果作为支持向量回归(support vector regression,SVR)的输入,进行决策级融合。
然而,该多模态融合框架存在以下问题:① 使用简单的LSTM很难训练出高质量特征,需要在深度学习建模阶段加强研究。② 需要在语音和文本模态的基础上增加包含情感信息的非语言数据,以提高情感识别的预测值。③ SVR可以有效地解决小样本、高维、非线性等问题,但对缺失数据问题敏感且无法处理大样本。针对上述问题,本文将包含效价维、唤醒维和支配维三个维度的情感空间模型(please-arousal-dominance,PAD)作为情感描述模型[4],结合添加权重因子的多任务学习机制(multi-task learning,MTL)[5],使用深度学习模型分别对语音和文本特征进行训练,利用2D-CNN对动作捕捉(motion capture,Mocap)特征进行训练,最后基于随机梯度下降法(stochastic gradient descent,SGD)进行建模并预测出情感识别结果。在IEMOCAP数据集上的实验结果表明,基于本文提出的LSTM+BiLSTM+CNN多模态情感识别框架,并使用基于SGD的决策级融合方法进行情感识别,一致性相关系数(concordance correlation coecient, CCC)均值有所提升。
1 相关工作
在多模态情感识别领域中,离散情感描述模型和维度情感描述模型是广泛使用的两种模型。其中,离散情感描述模型使用形容词标签将情感表示为独立的情感类别[6-7],例如快乐、悲伤、愤怒、恐惧、厌恶和惊讶六种基本情感。文献[8]提出一种深度双循环编码器模型,对语音和文本信息进行编码,并对特征进行串联;文献[9]提出一种跳跃注意力机制,经过训练可以推断不同模态之间的相关性并进行融合。多模态情感识别领域的大多数研究只采用两种模态进行情感识别[10-11],而文献[12]对三模态情感识别进行了研究,首先使用3D-CNN、text-CNN和openSMILE技术分别对视觉、文本和语音模态进行特征提取,然后使用把径向基函数作为核函数的支持向量机,对不同模态特征进行特征级融合。
离散情感描述模型简单直观,但存在以下不足:情感类别能够表达的情感范围有限;无法度量情感类别之间存在的高度相关性;无法描述情感完整的变化过程[6]。相比之下,维度情感描述模型可以弥补这些不足,该模型把情感看作是逐渐的、平滑的转变,不同的情感映射到高维空间上的一个点。例如,PAD就是通过效价维、唤醒维和支配维三个连续维度将情感刻画为一个多维信号。
目前,多模态情感识别领域的研究呈现出由离散情感描述模型转向维度情感描述模型的趋势[13-14]。文献[15]提出一种带有两个参数的MTL,通过不同的方法对语音和文本数据进行特征提取,然后利用LSTM模型对语音和文本特征进行训练并进行单模态情感识别,最后通过concatenate方法进行网络串联,实现双模态维度情感识别。本文基于改进的多模态情感识别框架和决策级融合方法,在IEMOCAP数据集上进行训练和测试,通过分析效价维、唤醒维和支配维三个情感维度对应的值以及CCC均值,对多模态维度情感识别展开研究。
2 多任务学习机制(MTL)
MTL可以在学习过程中对多个损失函数进行同时优化,并利用多个相关任务中包含的信息来提高模型在各个任务中的泛化能力和性能。因此,本文采用一种可以同时预测效价维、唤醒维和支配维三个情感维度与其真实情感标签之间CCC的MTL方法。将CCC作为预测性能的评价指标,其计算公式为
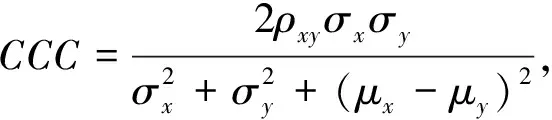
(1)
其中:ρxy是x和y之间的Pearson系数相关性;σ是标准偏差;μ是平均值。
CCC评价指标反映了预测值与真实值的协同变化关系和偏差,取值范围为[-1,1]。相比Pearson相关系数和均方误差,CCC能够更好地反映预测值与真实值的吻合程度[6]。
将CCC损失函数最大化,以使预测值与真实值之间的一致性达到最大,效价维、唤醒维和支配维对应损失函数的加权因子区间为[0.1,0.8],步长为0.1,进行36组线性搜索。
3 实验过程与结果分析
3.1 数据集与实验设置
本实验使用由南加州大学开发的互动式情感二元运动捕捉数据集IEMOCAP[16]。该数据集包含来自10位演员的视听数据,共计12 h,是在男演员和女演员之间通过即兴创作的话题进行对话而录制的,包括视频、语音、Mocap和文本转录,使用的语言是美式英语。数据集中提供了情感类别标签和维度情感标签,本实验使用维度情感标签对情感状态进行分析,并对标签进行归一化处理,将标签分数转换为[-1,1]区间内的浮点值。
使用说话者相关条件下的数据作为实验数据集,分为训练集和测试集两个部分,分别为6 400和2 039条,再将20%的训练数据作为验证集。每次实验重复20次,三个维度对应的值以及CCC均值都取20次实验的平均值,以验证模型的泛化性。Batchsize设置为32,将RMSprop作为优化器进行训练,epoch最大值设为50,使用Early-Stopping功能,当连续10次epoch没达到更高的结果,停止训练。
在训练开始之前,初始化固定随机数,以使每次运行结果一致。实验环境:实验代码用python语言编写,深度学习模型由tensorflow和keras实现,SVR和SGD回归算法由scikit-learn工具包实现,CPU为Xeon Gold系列5218。
3.2 语音情感识别
3.2.1特征提取 在交流过程中人们可以通过感知语音信号中的声学线索,从中提取出所携载的情感属性。语音特征独立于语言内容之外,不会受到文化差异的影响[17]。语音特征分为低级描述特征(low-level descriptors, LLDs)和高级统计特征(high-level statistical functions, HSFs)。实验中语音特征使用pyAudioAnalysis(pAA)特征集[18],pAA是一个开源的python库,提供了音频分析程序,包括特征提取、音频信号分类和内容可视化等。LLDs以帧为单位进行特征提取,每帧总共提取34个特征,例如zero crossing rate, energy, entropy of energy等。以25 ms的窗口大小和10 ms的跳跃大小作为标准对帧进行处理,用于提取语音特征的每条语音数据为16 kHz单通道,最长的发声用于定义帧边距,没有达到帧边距的短发声用0进行填充。将LLDs在独立的语句上进行统计, 包括均值和标准差,得到的HSFs作为语音模型的输入。
3.2.2语音模型 首先使用批量归一化,目的是对输入数据进行处理以加快网络训练,然后添加LSTM层。语音模型由五层堆叠的LSTM组成,每层包含64个神经元,接着添加Flatten层对数据进行压平,最后添加三个仅包含一个神经元的Dense层,用来生成效价维(V)、唤醒维(A)和支配维(D)三个维度的连续值。
3.2.3实验结果 表1列出了语音单模态的实验结果。当MTL对应权重因子比例为0.5∶0.3∶0.2时,CCC均值达到最高,为41.24%,与语音基线模型相比,提升1.64个百分点。该基线模型每层网络包含256个神经元,相比之下,本文构造的网络结构中使用更多的层数,但每层包含更少的神经元,在提升训练速度的同时,唤醒维对应的值也有明显提高。
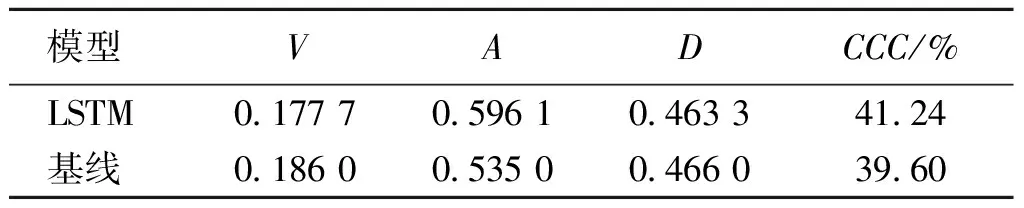
表1 语音单模态的实验结果Table 1 Experimental results of speech single modality
3.3 文本情感识别
3.3.1特征提取 由于计算机无法对文本这类非结构化数据进行直接处理,必须先将文本转换为数值,生成的文本特征是词的向量表示,称为词嵌入。这些值的维度数等于词汇量大小,词嵌入将这些点嵌入到较低维度的特征空间中。在原始空间中,每个词都由一个one-hot向量表示,对应词的值为1,其他词的值为0,值为1的元素被转换为词向量大小范围内的一个点[3]。在此基础上,使用预训练的词嵌入模型Glove对原始词嵌入进行加权[19]。实验中使用维度为300的向量,最大序列长度为100,当序列长度低于100时,用0填充以达到相同的长度。将得到的特征馈送到文本网络中的嵌入层,然后通过深度学习模型训练获取更深层的特征,最后输入到Dense层中进行文本情感识别。
3.3.2文本模型 文本模型中首先添加嵌入层embedding,其次是两层BiLSTM,每层包含64个神经元,然后添加包含64个神经元的Dense层,最后添加三个仅包含一个神经元的Dense层。
3.3.3实验结果 表2列出了文本单模态的实验结果。当MTL对应权重因子比例为0.5∶0.4∶0.1时,CCC均值达到最高,为40.12%,与文本基线模型相比,提升0.62个百分点。该基线模型使用三层网络结构,每层网络包含256个神经元,相比之下,本文构造的网络结构不仅使用更少的层数,并且每层包含更少的神经元,在提升训练效率的同时,唤醒维和支配维对应的值均有提高。

表2 文本单模态的实验结果Table 2 Experimental results of text single modality
3.4 Mocap情感识别
3.4.1预处理 在由IEMOCAP数据集提供的Mocap数据中,每位演员在进行对话的同时都会佩戴Mocap摄像机,对该演员的面部表情以及头部和手部动作进行记录,本实验中使用的Mocap数据包含面部、手部和头部三种。Mocap数据的预处理方法参照文献[2]。首先,对开始时间值和结束时间值之间的所有特征值进行采样,并分成200个按时间顺序排列的数组;其次,对200个数组中的每一个数组求平均(面部165个,头部6个,手部18个);最后,连接所有数组,获得形状为(200,189,1)的三维张量作为深度学习模型的输入。
3.4.2CNN模型 使用五层堆叠的2D-CNN,每个卷积的内核大小为3,步幅为2,分别具有32、64、128、64和32个过滤器,每层之后均添加值为0.2的Dropout层和激活函数ReLU,最后添加Flatten层以及三个仅包含一个神经元的Dense层。
3.4.3实验结果 表3列出了Mocap单模态的实验结果。当MTL对应权重因子比例为0.3∶0.5∶0.2时,CCC均值最高,为27.89%。与使用不添加权重因子的损失函数的实验结果相比,提升1.18个百分点,并且三个维度对应的值均有提高。相比语音和文本的预测结果,Mocap实验的CCC均值是最低的。

表3 Mocap单模态的实验结果Table 3 Experimental results of Mocap single modality
3.5 多模态情感识别
多模态特征融合是抽取不同模态的信息整合为一个稳定的多模态表征的过程,根据融合位置的不同可分为特征级融合和决策级融合。由于特征级融合方法不能针对不同模态的特征选择各自最合适的模型进行预测,因此本文基于决策级融合方法进行多模态维度情感识别。首先利用深度学习模型分别对不同模态特征进行训练,然后对多个模型的输出结果进行融合[17]。本文基于机器学习回归算法对不同模态预测结果之间的复杂关系进行建模,并得到最终的预测值。
3.5.1SVR 利用深度学习模型分别对语音、文本和Mocap特征进行训练,产生的数据点作为SVR的输入,应用回归分析将其映射到给定标签,实现决策级融合。计算公式为
subject towTφ(xi)+b-yi≤ε+ζi,
(2)
其中:xi=[xs[i],xt[i],xm[i]]是深度学习模型对语音、文本和Mocap数据的效价维的预测输出;yi是对应维度的标签;w是权重向量;C是惩罚参数;ζ和ζ*是引入的松弛变量;φ是核函数。选择径向基函数内核作为核函数,其函数表示式为
K(xi,xj)=eγ(xi-xj)2,
(3)
其中:γ定义了单一训练样本能对模型起到多大的影响。将上述过程同样应用于唤醒维和支配维。
3.5.2SGD 在语音和文本的基础上增加Mocap数据的同时,样本数也随之增大,而SVR无法有效处理大样本。因此,本文使用基于SGD的决策级融合方法与SVR算法进行对比实验。基于SGD的决策级融合多模态情感识别如图1所示。
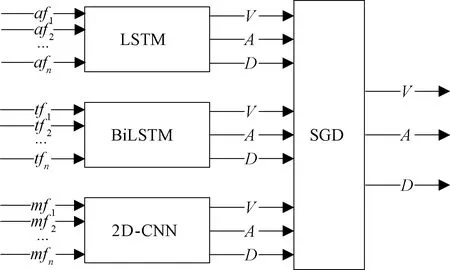
图1 基于SGD的决策级融合多模态情感识别Figure 1 Decision-level fusion multi-modal emotion recognition based on SGD
将训练后的数据点作为SGD的输入,应用回归分析将其映射到给定标签。目标是一个线性评价函数f(x)=wTx+b,其中模型参数w∈Rn,截距b∈R。通过如下的最小化公式给出正则化训练误差:

(4)
其中:L是用来衡量模型拟合程度的损失函数;R是惩罚模型复杂度的正则化项;α>0是一个非负超平面。
3.5.3实验结果 使用基于SVR和SGD的决策级融合方法进行双模态和多模态融合实验,结果列于表4。表中S代表语音,T代表文本,M代表Mocap。可以看出,在双模态实验中,语音加文本组合的CCC均值最高;文本加Mocap组合的CCC均值虽然最低,但是效价维的值高于其他两种组合;语音加文本的组合中,SVR的预测性能要比SGD高,相比双模态基线模型提高了0.51个百分点。

表4 基于SVR和SGD两种决策级融合方法的实验结果Table 4 Experimental results of two decision-level fusion methods based on SVR and SGD
在多模态实验中,由于结合了Mocap特征,样本数量随之增加。通过实验发现,SGD更适合对此时的回归任务进行预测,CCC均值为60.16%,相比双模态基线模型提升了3.66个百分点,验证了本文提出的基于SGD的决策级融合方法对提升情感预测性能的有效性;相比使用SVR进行预测的多模态实验结果,CCC均值提升了1.71个百分点,表现出SGD回归算法在处理大样本上的优势。
将双模态实验和多模态实验结果进行对比,结果表明,添加Mocap数据后,基于SVR和SGD两种融合方法的CCC均值分别提升了1.44个百分点和4.40个百分点,进一步验证了Mocap数据对提升情感识别性能的有效性。此外,发现Mocap数据对三个维度中效价维的值提升最大。
3.5.4其他决策级融合方法 本文还基于其他机器学习回归算法进行多模态融合,实验结果列于表5。其中,普通最小二乘法、岭回归、Lasso、LARS-Lasso、贝叶斯岭回归和主动相关决策理论都属于广义线性模型。可以看出,相比其他机器学习回归算法,SGD展现出明显的优势,三个维度的值均为最高。
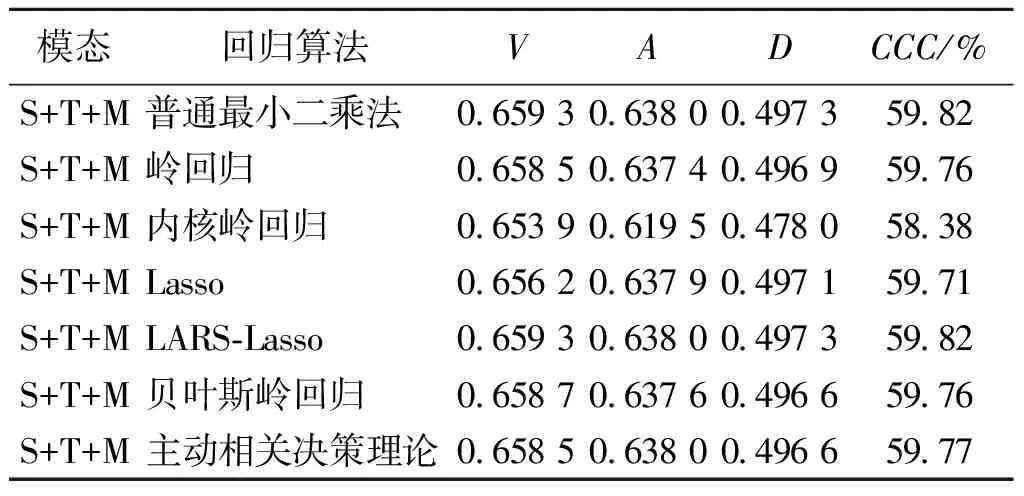
表5 基于其他决策级融合方法的多模态实验结果Table 5 Multi-modal experimental results based on other decision-level fusion methods
4 小结
本文提出一种基于SGD回归算法的决策级融合维度情感识别方法,结合多任务学习机制,利用深度学习模型分别对语音、文本和Mocap特征进行训练,通过在损失函数上添加适当比例的权重因子以及对网络结构进行优化等方法提高单模态情感识别性能。在IEMOCAP数据集上的实验结果表明,使用LSTM+BiLSTM+CNN多模态情感识别框架进行决策级融合,维度情感预测性能有明显提升;基于SGD的决策级融合方法在三个情感维度上都表现出最好的预测性能。但是,由于决策级融合策略无法考虑不同模态之间的情感信息关联,下一步研究将通过利用特征级和决策级两种融合策略各自的优点,使用两者相结合的混合融合策略来实现多模态情感识别。
