一种基于文本风格转换模型的医疗辅助咨询平台设计*
2022-04-25宁康林冯志斌
李 慧,宁康林,冯志斌
(火箭军工程大学基础部,陕西 西安 710025)
根据中国《全国医疗卫生服务体系规划纲要(2015—2020 年)》发布信息,医疗卫生资源总量不足、质量不高等问题日益突出[1]。这些问题驱动着医疗行业不断向着智慧医疗的方向发展。然而当前现有的智慧医疗应用方向主要集中在技术性的问题上,而忽略了医患沟通问题。现实生活中,受制于医生的沟通能力和患者的理解能力,医患冲突频发[2],因此使用文本风格转换的技术来辅助医患沟通问题,成为了一种极具吸引力的方案。文本风格转换任务于2012 年提出,最初以“文本释义”的形式出现。文本风格转换是指在保留原句内容的基础上,重新生成包含特定风格属性的文本。XU 等[3]将该任务视为单语的机器翻译,提出监督学习的“现代-莎士比亚”文本风格转换是一种特殊的自然语言生成技术。然而在现实生活中,内容相同但风格不同的句子往往是很难得到的,因此当前文本风格转换的工作主要集中于实现无监督的文本风格转换[4]。当前的无监督文本风格转换主要有3 种实现途径:隐式风格分离[5]、显式风格分离[6]、不分离风格[7]。然而这几类方法均存在性能不稳定的问题,特别是对复杂信息的处理。因此,本文采用一种基于WANG 等[8]无监督文本风格转换模型CTAT 的改进模型Balance-CTAT。并以该模型为基础,配合华为Atlas 200深度学习开发板、麦克风定位阵列、两自由度云台等硬件设备,设计了一种新型的医疗咨询辅助平台。
1 系统的总体方案及硬件设计
基于文本风格转换模型的医疗辅助咨询平台系统的总体功能设计架构如图1 所示。硬件系统主要由4个部分组成,分别是音频定位收集模块、主控处理模块、云台控制模块、人机交互模块。主控模块由华为Atlas 200 深度学习计算卡构成,音频定位收集模块由一个六麦克风定位阵列和拾音麦克风电路构成,云台控制模块则是由STM32F103 和一个360°舵机组成,而人机交互模块则为一块可触控的LCD 显示器。
音频定位收集模块负责不间断处理接收到的声音信号,实时判断出哪个方向有人在请求交流,发送定位信息和交流语音信息给主控模块;主控模块为本系统的决策与控制中心,由华为Atlas 200 深度学习计算卡完成,负责对语音信号滤波、识别和实现文本风格转换算法,并输出信息给人机交互模块。在华为Atlas 200 计算卡上部署的以深度学习模型为基础构建端到端文本风格转化子系统,该子系统收集来自音频收集模块的音频信息和声源定位信息,随后通过对音频信息进行文本风格转换,得到更加便于医生和患者理解的文本信息,并将这些信息显示在人机交互模块上。而同时主控模块接收到的声源方位信息计算出语音发出者相对于本系统的物理位置。随后Atlas 200 根据相对位置计算出云台的转角信息,并将其通过串口传递给对云台进行控制的STM32F103,随后由STM32F103控制板控制云台将人机交互模块转向声源所方向。
1.1 主控模块选型
华为Atlas 200 是一款高性能的AⅠ应用开发板,主要集成了昇腾310 AⅠ处理器,8 位整数算力22TOPS,16 位浮点算力11TFLOPS,附带一块8 GB 的LPDDR4X的内存,并配备1 个GE RJ45 以太网接口、1 个USB2.0接口、1 个USB3.0 接口、2 路摄像头51 pin 接口和40 pin Ⅰ/O 接口,电源电源适配5~28 V,功耗20 W。其算力丰富,能满足大量AⅠ算法的部署场景需求。Atlas 200 电路板及硬件框图如图2 所示。
1.2 音频定位收集模块设计
音频定位收集模块需要提供唤醒人声源的轴向角度信息以及录制的降噪音频信息,现主流可以实现声源定位的音频模块主要有3 类[9],分别是三维麦克风阵列、二维麦克风阵列以及双耳的音频收集模块。本文的音频处理电路框图如图3 所示。设计多路基于运放电路的声音收集处理电路,麦克风获取声音信号后,首先通过低噪声放大器,已达到几乎无损的放大,然后通过AGC 自动增益控制模块,使得幅值达到比较均匀的放大。而后由信号采集模块进行AD 采集,并使用卷积算法进行预处理,广义互相关计算相关性,计算得到时延,最后处理后得出定位信息。音频定位处理电路较为复杂,尤其是左侧每一路声音收集处理电路的可变增益放大器和自动增益控制AGC 电路设计和调试较为复杂。根据本系统特点,仅需要声源的轴向角且从经济可靠的方面考虑,本文采用二维麦克风阵列XFM10621 模块。该模块使用了远场识别和降噪技术,可以使拾音距离达到5 m,可以驱动6 个麦克风阵列,实现360°语音信号采集,并能通过声源定位来确定目标说话人的方向。麦克风阵列示意图如图4 所示,该模块利用麦克风阵列的空域滤波特性,在获得唤醒人声源角度的同时,形成定向拾音波束,并对波束以外的噪声进行抑制,获得降噪的清晰音频,并且还具有回声消除技术,可以将扬声器的声音屏蔽,只接收用户的声音,可以提高声音识别准确度。
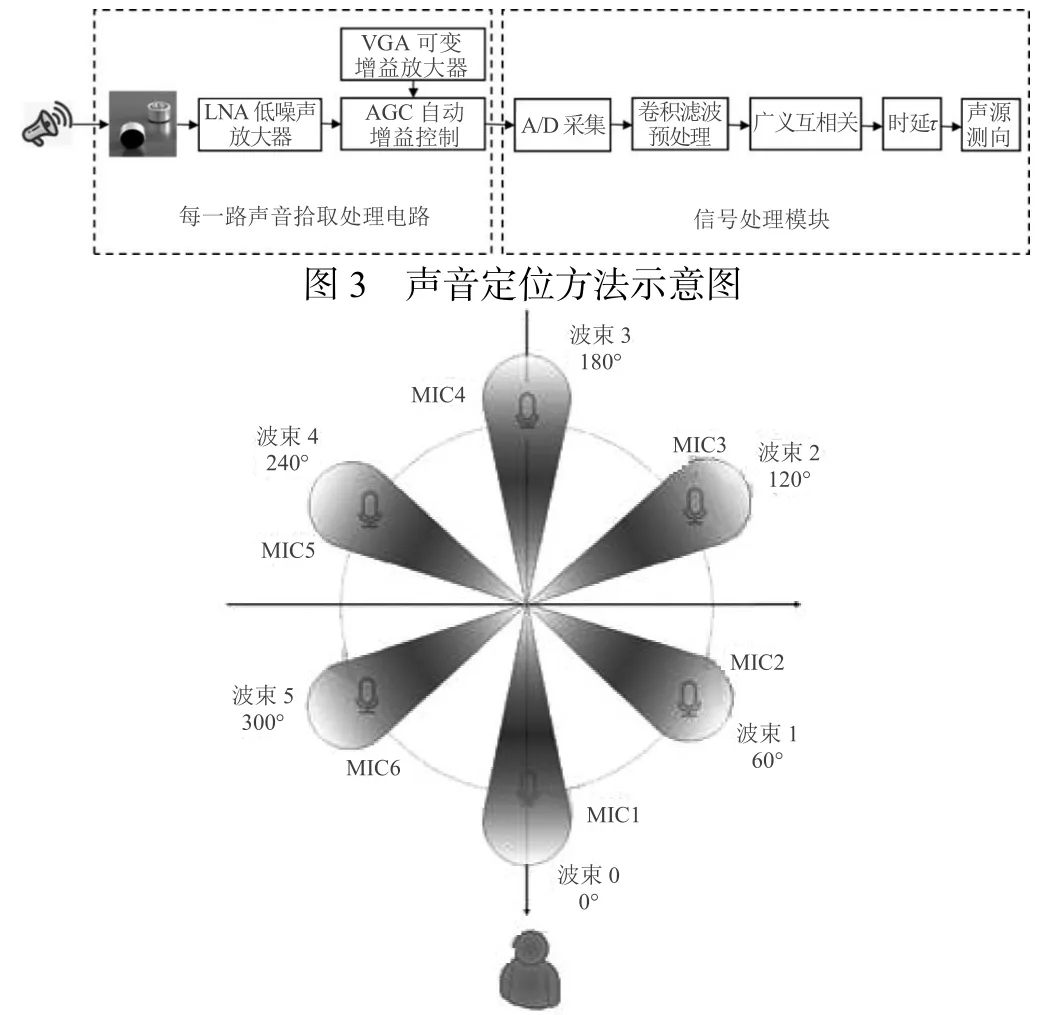
图4 麦克风阵列示意图
1.3 云台控制系统
云台控制系统主要由STM32F103 主控系统、电源降压系统和舵机组成。STM32F103 主控系统主要用于接收并解算声源定位信息,并控制舵机实施转向。电源降压系统主要是满足STM32F103 主控系统以及舵机的不同电压的供电需求,如图5 所示。如图5(a)所示,利用LM1084 稳压芯片将电压降到6.125 V 用于舵机供电,LM1084 参考电压VREF为1.25 V。这个电压通过电阻1 产生恒定电流,恒定电流通过电阻2。通过电阻2 产生的电压降加到参考电压上,从而设定所需的输出电压为:
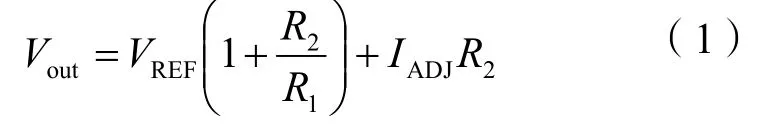
式(1)中:Vout为输出电压;VREF为参考电压;R1和R2分别为电阻1 和电阻2 的电阻值;IADJ为恒定电流,由于R2通常较小(最大不超过120 μA),当R1在100 Ω时,IADJR2可以忽略。
图5(b)是利用TPS7350 芯片将电压降到3.3 V用于给STM32F103 供电。舵机使用DSServo 公司的DS3235,堵转扭矩为35 kg·cm,实现云台控制转向声源所方向。
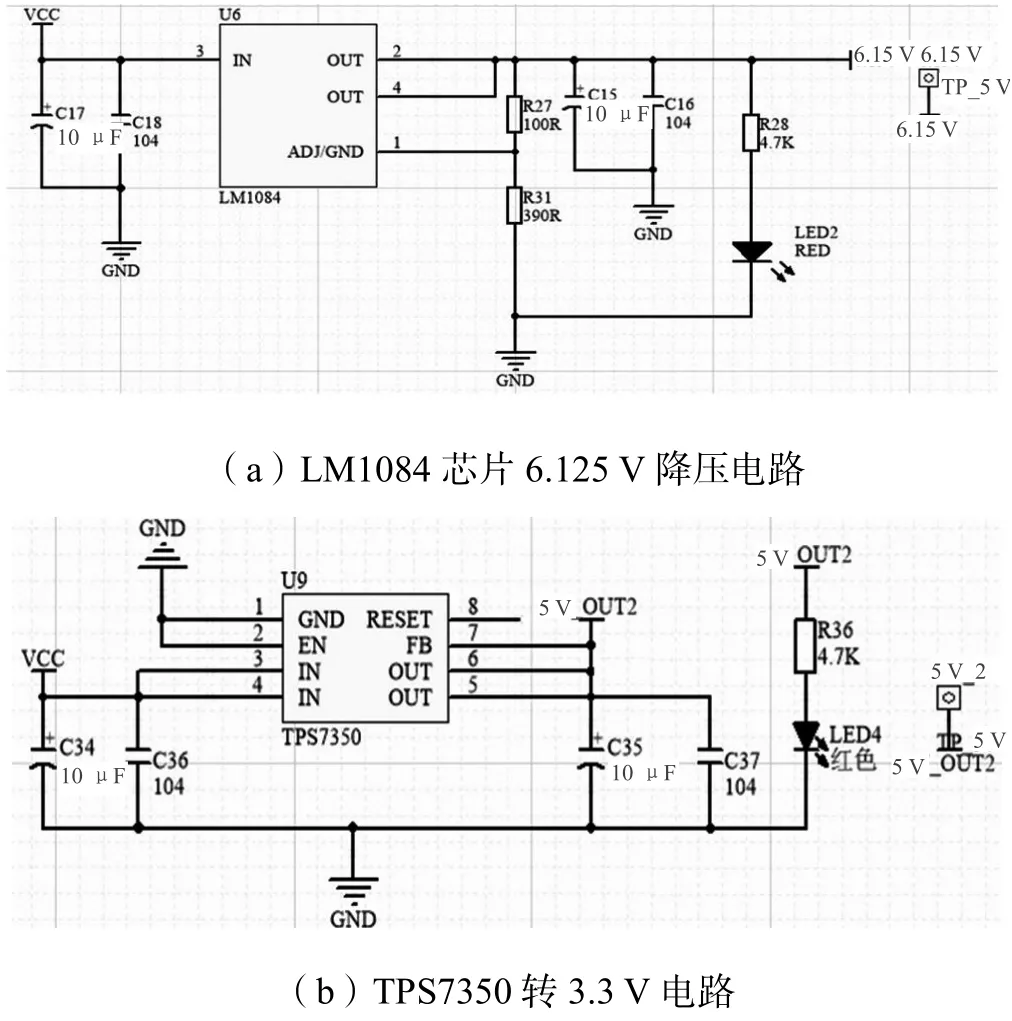
图5 电源降压系统
2 文本风格转换算法设计
2.1 文本风格转换原理
CTAT 模型通过自编码器重建语句,并且利用对抗样例生成技术,实现无监督文本风格转换。模型由3部分组成,分别是编码器、解码器和风格分类器,如图6 所示。E 和D 分别为编码器和解码器,C 为分类器。x为原句,z为潜在表示,x′为模型输出语句,s为原句标签。⊕表示向量拼接操作。分类器的预测标签s′和目标标签t由分类器计算得到梯度值Δ,与z计算得到风格迁移后的潜在表示z′。Lae表示自编码器重建损失,Lc表示分类器损失。
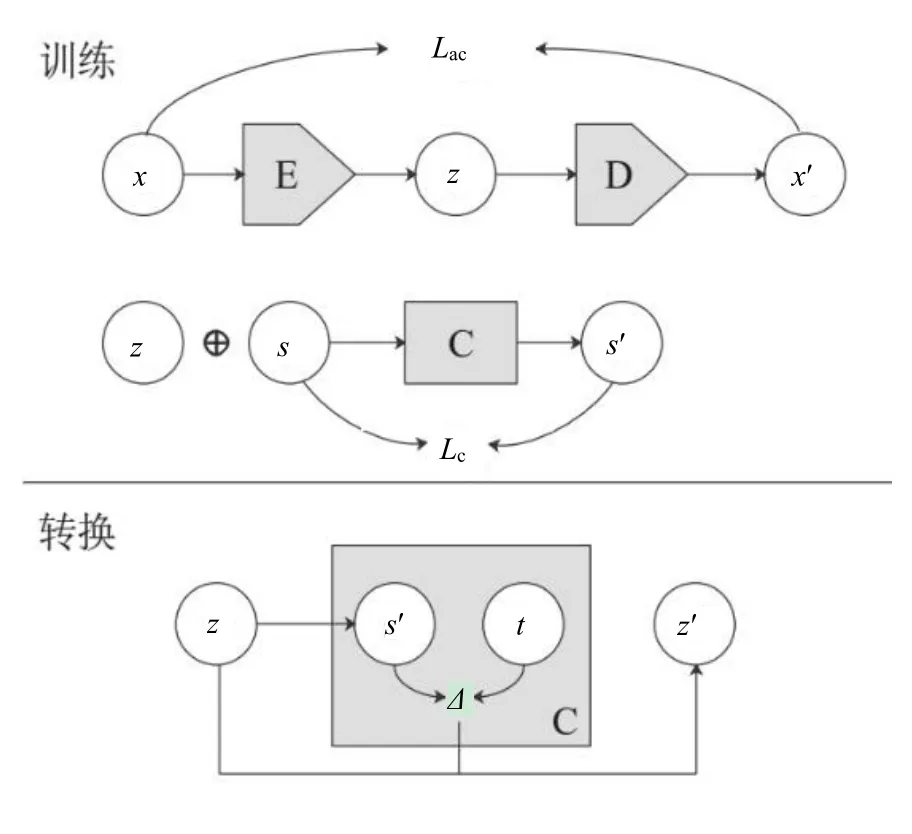
图6 CTAT 模型原理示意图
2.2 文本风格转换模型设计
Balance-CTAT 基于CTAT 模型搭建,并在算法和结构上进行改进,以提升算法性能,具体表现在对风格迁移算法进行显著性优化和修改Transformer 解码器各层注意力头数进行不同层次的信息融合。Balance-CTAT 模型的结构如图7 所示。原句x进入编码器E,编码器中有2 部分,分别是2 个4 头Transformer注意力,然后将其潜在表示为z,进入解码器D 和分类器C,在解码器D 中将原来的2 个4 头Transformer注意力改为单Transformer 注意力和1 个4 头Transformer 注意力,潜在目标z和目标风格s经过分类器进行显著化。
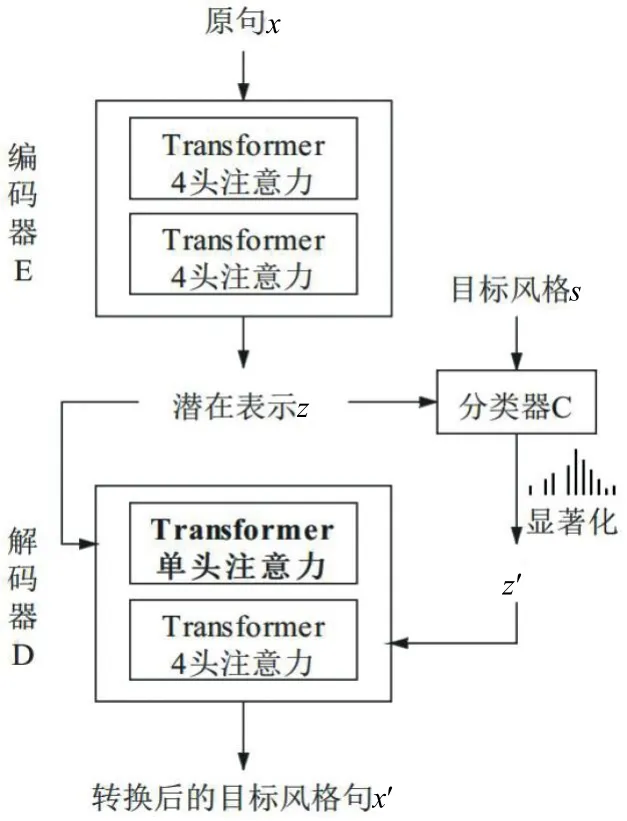
图7 Balance-CTAT 模型结构
2.3 文本风格转换实验结果分析
为了评价提出的Balance-CTAT 模型的有效性,在此采用以下3 个指标来评价:①风格转换精度Acc。风格转换精度用于衡量语句转换到目标风格的准确性,这个数值越大,说明转换精度越高。②内容保留度BLEU。内容保留度用于衡量模型生成语句与目标句的相似性,数值越大越好。③几何平均值GM。几何平均值用于衡量模型的整体性能,数值越大越好。
本文使用Acc、BLEU 和GM 对结果好坏进行评估模型,数值越大,性能越好。实现正负情感转换和浪漫—幽默风格转换任务的实验采用Yelp 数据集对模型进行训练。两种模型测试结果对比如表1 所示。

表1 Balance-CTAT 模型和CTAT 模型测试结果对比
通过对比这3 个评估指标发现:Balance-CTAT 模型与CTAT 模型相比,内容保留度有了显著的提高,几何平均值综合性能提升较大;尽管Balance-CTAT 模型为了提高了内容保留程度,以可接受的程度牺牲部分风格转换精度,但是精度下降所占百分比极小。总体来说,Balance-CTAT 模型用牺牲小部分精度换来了内容保留度的显著提高,几何平均值较大提升,实验效果良好。
3 结论
基于Balance-CTAT 模型,本文设计了一款基于文本风格转换技术的医疗咨询辅助平台。该平台以华为Atlas 200 作为核心主控模块,负责深度学习模型的部署和驱动人机交互模块,以STM32F103 作为下位机负责控制云台,将科大讯飞六麦克风阵列模块作为音频输入模块,并采用多线程并发的方式进行系统程序的开发。该系统可以有效提高内容保留度和流畅度,提升在不同的医患交互场景下的综合性能,能够较好地辅助医患交流,具有广阔的应用前景。
