结合头部和整体信息的多特征融合行人检测
2022-04-21谢文阳刘焕淋黄美永
陈 勇 谢文阳 刘焕淋 汪 波 黄美永
①(重庆邮电大学工业物联网与网络化控制教育部重点实验室 重庆 400065)
②(重庆邮电大学通信与信息工程学院 重庆 400065)
1 引言
行人检测与行人重识别技术、目标跟踪技术等相结合在自动驾驶、视频监控等领域中有广泛的应用[1–4]。然而实际检测中行人容易产生遮挡、重叠等问题,并且行人距离的远近会导致行人尺度产生较大变化,这些问题严重影响了行人检测的准确率[5]。
目前卷积神经网络广泛应用于行人检测,其中以Faster R-CNN[6]为代表的两阶段检测器和以RetinaNet[7]为代表的单阶段检测器取得了较好的效果。李春伟等人[8]采用多个卷积层的输出进行检测从而降低尺度造成的影响;Lin等人[9]提出特征金字塔的概念并构建了FPN (Feature Pyramid Network),该方法逐渐成为解决尺度变化问题的主要手段[10,11]。针对行人检测中的遮挡问题,Zhang等人[12]提出聚合损失函数使候选框靠近真实边界框以此降低类内遮挡造成的影响;Du等人[13]通过在网络中添加额外的行人特征掩模减少背景像素的干扰;Fei等人[14]通过引入更丰富的上下文信息减少遮挡造成的干扰;Liu等人[15]考虑行人的标注方式,使用预测目标中心点及尺度的方式有效提升了检测准确性,同时该方法可有效减少类内遮挡造成的漏检。Liu等人[16]通过添加密集程度检测模块为非极大值抑制提供更合理的筛选条件,有效提升了密集场景下行人检测的准确性。综上所述,上述方法从多个角度入手解决目标遮挡与尺度过小造成的检测准确性降低的问题,但却忽视了一个重要的方面,即行人的头部往往不易产生类内遮挡,即使躯干部分由于部分遮挡而无法被检测,但此时行人的头部特征依然明显,而该信息对于行人而言尤为重要,如Xu等人[17]便利用头部信息提升行人跟踪的准确性。此外,大多数方法仅使用主干网络最后3层卷积层的输出进行特征融合,而小尺度目标往往在卷积层的较浅层拥有较高激活程度。
针对以上问题,本文构建了一种结合头部和整体信息的行人检测模型。受文献[18]的启发在行人检测的基础上添加行人头部检测分支,并利用CrowdHuman[19]数据集自带的行人头部标签对模型进行训练;考虑到使用矩形边界框标注行人会引入大量背景像素,因此本文参照文献[15]采用中心点对行人头部和整体进行标注;两个检测分支采用不同深度卷积层的输出进行特征融合,从而提供有针对性的特征信息;同时,本文对非极大值抑制算法进行改进,通过添加行人头部的相关判断条件,使行人头部信息和行人整体信息能较好的结合。
2 算法原理设计
图1为本文提出的网络模型结构,该模型由特征提取模块及检测模块组成。特征提取模块除主干网络外还包含5层结构的特征金字塔。对于行人头部和整体,使用该特征金字塔的不同子结构并融合输出的特征;检测模块包含头部检测和整体检测两个分支,以此为基础本文设计了一种融合策略,通过对非极大值抑制算法进行改进使其能较好地融合两个检测分支输出的检测结果。
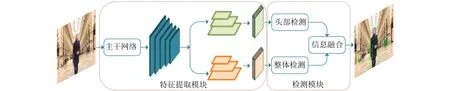
图1 模型总体结构
2.1 特征提取模块
特征提取模块的主干网络采用ResNet50[20],随着网络层数加深输出特征图的分辨率逐层缩小为上一层的1/2。目前大多数方法仅使用主干网络最后3层的输出构建特征金字塔,这种做法将导致大量小尺度目标信息丢失,对此本文构建了具有5层结构的特征金字塔。同时使用该特征金字塔不同子结构的输出进行特征融合,从而为行人头部和整体提供有针对性的特征信息。
图2为本文设计的特征提取模块结构。原始输入图片的大小为H×W,下采样率为l且逐层翻倍,主干网络输出的特征图记为f2-f5,对这4张特征图使用1×1的卷积运算得到特征图F1-F4,对F4使用相同的卷积运算得到特征图F5。其中,特征图F1的通道数为256,后续特征图的通道数逐层翻倍,但保持特征图F4和F5的通道数同为2048,最终形成具有5层结构的特征金字塔。头部检测分支使用特征图F1-F3,对F2和F3进行上采样使其大小与F1一致,融合这3张特征图从而得到用于头部检测的特征图Fhead;整体检测分支使用特征图F3-F5,之后采取的操作与上述类似,但在融合之前采用文献[21]提出的方法对特征图进行归一化,最后得到用于行人整体检测的特征图Fbody。
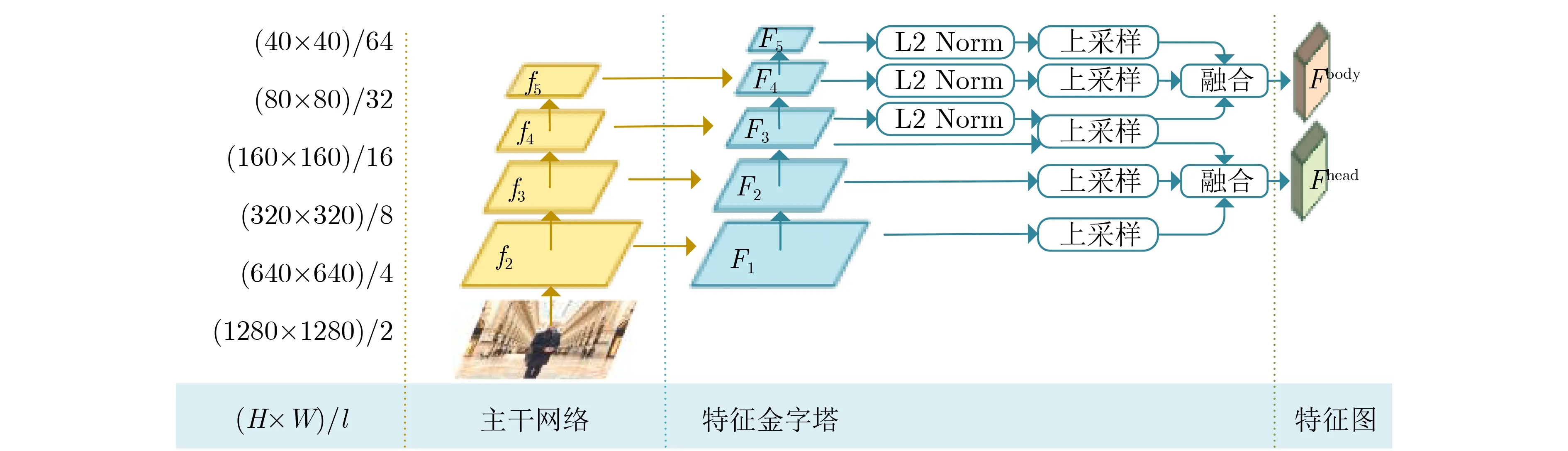
图2 特征提取模块结构
2.2 行人检测模块
对于由信息主导的深度学习方法而言,引入更丰富的信息能有效提升检测准确性。文献[18]在行人矩形边界框中划定一部分区域,将其视作行人头部区域并尝试利用这部分信息,但因无法进行准确标注而只能大概确定头部位置,导致头部信息无法得到有效利用,但这依然为我们提供了新的思路。CrowdHuman[19]是针对密集场景的行人检测数据集,它不仅包含行人整体边界框,还包含对应的行人头部边界框。为有效利用该数据集中的行人头部标签信息,本文在行人检测的基础上添加行人头部检测并构建如图3所示的检测模型。
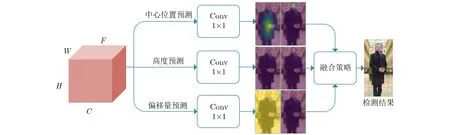
图3 检测模块结构
对于特征提取模块输出的行人整体特征图Fbody,分别使用3个1×1的卷积计算得到3张特征图,对应于行人中心Cbody、行人高度Hbody以及偏移量Obody。行人边界框的宽度采用文献[22]的生成方式,将高度乘以比例因子ε=0.41后得到;对于行人头部特征图Fhead,采用相同方式分别生成头部中心Chead、高度Hhead以及偏移量Ohead,并设置比例因子ε=1得到头部宽度。对于每一个可能存在目标的位置,网络输出6 维的数组{xc,yc,ˆh,xo,yo,s},其中(xc,yc)为目标中心点位置,hˆ为预测目标高度,(xo,yo)为中心点偏移量,s为置信度。
2.3 信息融合策略

测试阶段只保留置信度>0.1的边界框,然后使用非极大值抑制对结果进行筛选。对于每一个行人边界框,判断其头部区域是否存在头部边界框,若存在则选取位于该区域中置信度最高的头部边界框与之配对,如果行人边界框的得分较低但存在头部边界框,且头部边界框的置信度较高,则依然保留该行人整体边界框。
2.4 损失函数设计
本文将中心点预测视作二分类任务并使用交叉熵损失作为损失函数。对位于(i,j)处的第k个行人,参考文献[15]的方式,使用高斯函数G(·)分别生成行人头部高斯掩模Mhead和行人整体高斯掩模Mbody
图4 行人头部区域

将特征图中预测的中心点映射至原图像时存在一定的位置偏差,该偏差对小尺度目标的影响较大,因此本文添加偏移量预测修正该误差,该部分使用Smooth L1作为损失函数,如式(6)所示

3 实验与分析
3.1 实验平台
本文所提算法基于PyTorch深度学习框架实现,软件版本为:PyTorch 1.5.0, CUDA 10.1,Python 3.6和Numpy 1.15.4;硬件平台配置为:Intel Xeon E5 CPU、64 GB内存和4张NVIDIA GTX1080Ti GPU。
3.2 数据集选择
本文选用CrowdHuman[19]、CityPersons[22]及Caltech[23]数据集验证所提算法的有效性。CityPersons数据集包含德国18个城市、3种天气状况下行车采集的共5000张图片,其中2975张用于训练,500张用于验证,1525张用于测试,这些图片共包含约35000个行人,分辨率为2048×1024。Caltech数据集使用车载摄像头拍摄了10 h左右的行车视频,分辨率为640×480,共包含6个训练集(共42782帧)和5个测试集(共4024帧),约有2300个行人并标注了350000个边界框。CrowdHuman是新发布的针对密集场景下人物实例检测的数据集,共包含24370张图片,其中训练集15000张,验证集4370张,测试集5000张,整个数据集共包含470个人物实例,平均单张图片包含约23个人物实例。
3.3 评估标准
对于CrowdHuman数据集,采用平均准确率(Average Precision, AP)、漏检率(Miss Rate, MR)和召回率(Recall)作为评价指标。其中,准确率指正样本被预测为正样本的数目占所有被预测为正样本的样本数目的比例,该指标也称为查准率,值越高说明检测性能越好;漏检率指正样本被预测为负样本的数目与所有正样本的比例,该指标也是较为常用且能代表检测性能的指标,该数值越低说明检测性能越好;召回率指有多少的正样本预测正确,即网络检测出正样本的性能,该数值越高越好。对于CityPersons数据集以及Caltech数据集,采用官方评价标准对算法进行评估,主要采用漏检率指标验证本文算法对不同遮挡程度以及不同尺度目标的检测有效性,同时也对算法的泛化性能以及运行时间进行评估。根据CityPersons数据集和Caltech数据集官方提供的划分标准,这两个数据集可划分为多个子集,划分标准为行人高度和行人被遮挡程度,如表1和表2所示。

表1 Caltech数据集中部分子集划分标准
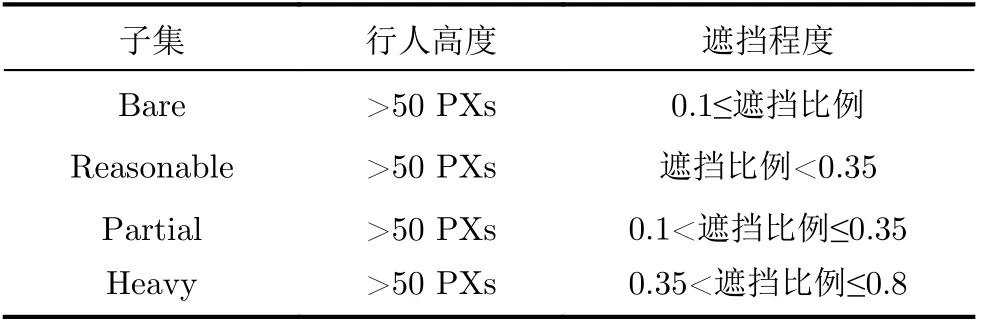
表2 CityPersons数据集中部分子集划分标准
3.4 训练设置
本文模型使用CrowdHuman数据集进行训练,并在全部3个数据集上进行测试。训练阶段通过缩放、裁剪、填充和水平翻转等方式对训练集图片进行处理,分辨率设置为1280×1280,每个训练批次大小为4张图片,训练时使用全部的4张显卡,即每次输入16张图片,迭代次数设置为150。模型训练使用Adam优化器,初始学习率为2×10–4。
测试阶段仅使用一张显卡,对于CrowdHuman数据集,图像分辨率与训练时保持一致,但仅使用缩放的方式对图像进行处理。对于CityPersons数据集和Caltech数据集,测试图像分辨率分别设置为2048×1024和640×480。非极大值抑制阈值与头部边界框保留阈值均设置为0.5,置信度阈值设置为0.1。
3.5 实验设计
3.5.1 对比实验
为验证本文所提方法的有效性,本文选取了在CrowdHuman数据集上有较好表现且具有代表性的RetinaNet[7], FPN[9], Adaptive NMS[16]和JED[24]等4种对比算法进行训练和测试。其中RetinaNet和FPN基于特征金字塔结构能较好解决尺度变化的问题,同时对困难样本有较高的检测准确率;JED为联合行人头部检测和整体检测的方法,通过在两阶段检测器Faster R-CNN的基础上添加新模块实现。实验结果如表3所示。
从表3可以看出,所提算法在CrowdHuman数据集上的检测准确率为87.31%,漏检率为50.16%,与对比算法相比有一定的提升。召回率为93.55%稍低于RetinaNet和Adaptive NMS,但本文算法的准确率和漏检率要优于这两种算法。对比较新的算法JED,本文算法在准确率和漏检率上分别提升约1.4%和2.5%,可见所提方法具有一定优越性。
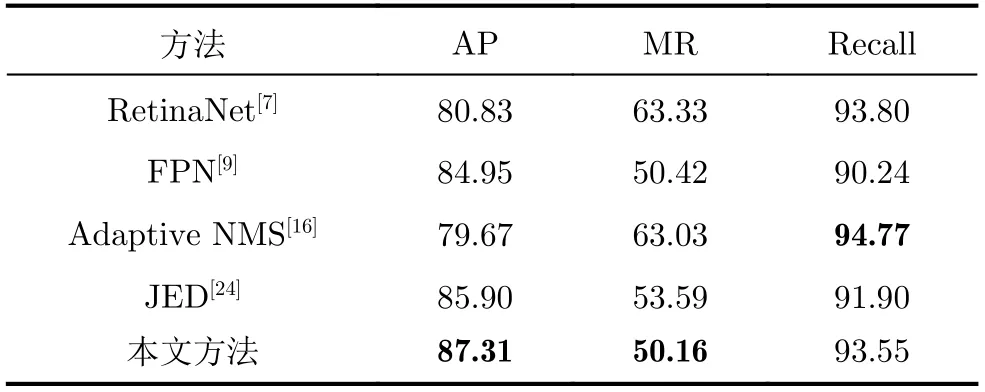
表3 CrowdHuman数据集实验结果(%)
3.5.2 泛化性实验
为验证所提方法的泛化性能以及对不同遮挡程度和不同尺度目标的检测性能,本文在CityPersons数据集上进行对比实验并依据官方标准划分子集,采用漏检率作为评价指标。同时,按照目标所占区域的大小,以像素面积322和962为界将CityPersons数据集划分为Small, Medium和Large3个子集,分别验证算法对小尺度、中等尺度和大尺度行人的检测性能。本文选取了8种对比算法,包含Faster R-CNN[6]等常用方法和ALFNet[25]等主流方法,以及较新的LBST[10]和CAFL[14]方法作为对比,实验结果如表4所示。
从表4可以看出本文算法在大部分子集上取得了较好的检测效果,分别在Reasonable和Partial子集上实现了10.1%和9.8%的漏检率,但在Bare子集和Heavy子集上,本文算法的漏检率要略高于OR-CNN和CSP。分析发现对于Bare子集中的一些行人实例,由于存在行人头部边界框并且其置信度较高,从而导致冗余的行人整体边界框被保留。而严重遮挡的行人几乎无法检测出头部边界框,从而使得本文所使用的头部检测分支无法较好地发挥作用,这可能是本文方法在这两个子集上检测效果不是最优的原因。但注意到其性能并未出现大幅下降,相较于最优结果只差了1%左右。同时算法对小尺度和中等尺度行人的漏检率分别为14.3%和3.5%为最优,表明本文算法对小尺度目标有较好的检测效果。为了进一步验证所提方法的正确性,本文与CSP进行对比并将检测结果可视化,以验证添加头部检测对遮挡问题的改善效果,如图5所示。
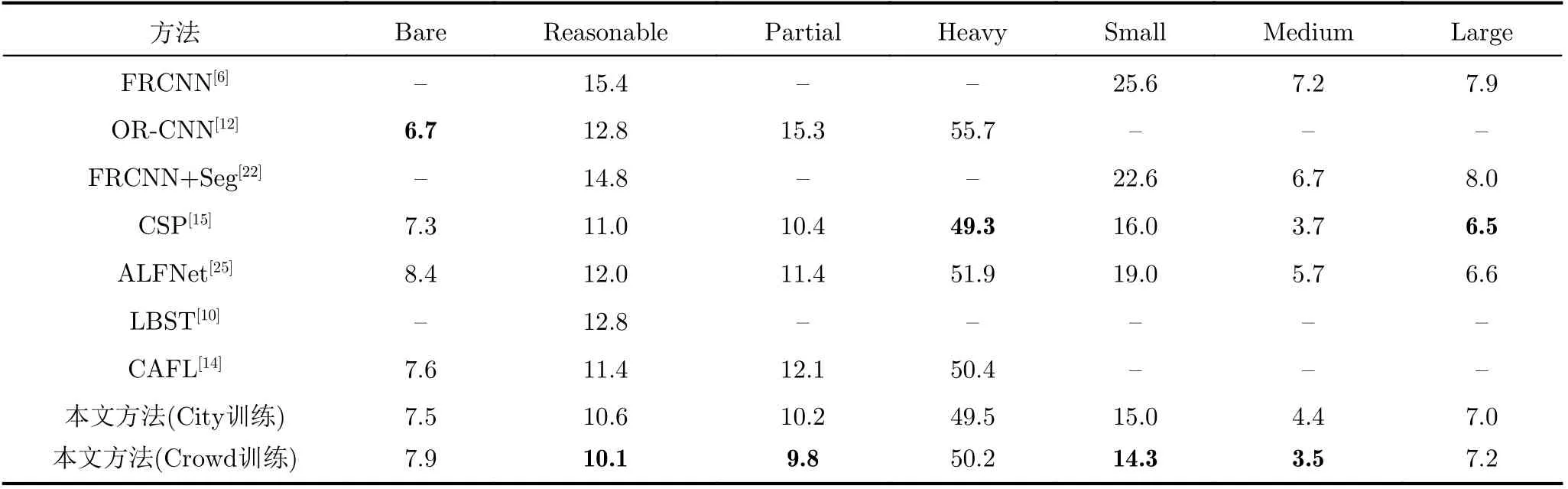
表4 CityPersons数据集漏检率(MR)的实验结果(%)
从图5可以发现,与只使用行人整体中心点进行检测的CSP相比,本文方法对于遮挡行人的检测效果有一定改善。如图中身着黄色上衣的儿童和白色上衣的女士存在较为严重的遮挡。多次检测实验中CSP方法约有一半的概率无法准确检测出这两个目标,而该情况下行人头部较为分明,本文所提方法由于添加了头部检测因此能准确检测出此类行人。

图5 检测效果对比
3.5.3 运行时间
为测试所提方法的运行时间,在相同的实验条件下,本文在Caltech数据集上进行对比实验,并选取F-DNN[13], F-DNN+SS[13], Faster R-CNN+ATT[26]和MS-CNN[27]作为对比算法。依据Caltech数据集的官方划分标准在各个子集上进行实验,实验结果如表5所示。
从表5可以看出,本文方法在大部分情况下取得了较好的检测效果,对于Reasonable, Partial和Heavy子集分别取得了7.73%, 14.55%和48.31%的漏检率,并在Reasonable和Partial子集上取得了最佳效果,在Heavy子集上的表现要稍低于文献[26]所提出的方法,大致与MS-CNN一致,而后者为两阶段检测器。由于本文方法在特征融合部分的上采样使用了反卷积增加了计算时间,如果将其替换为双线性插值,能将速度提升至约0.3 s/帧,但漏检率会稍微增加。在降低漏检率的同时缩短运行时间,是下一步需要继续开展的工作。
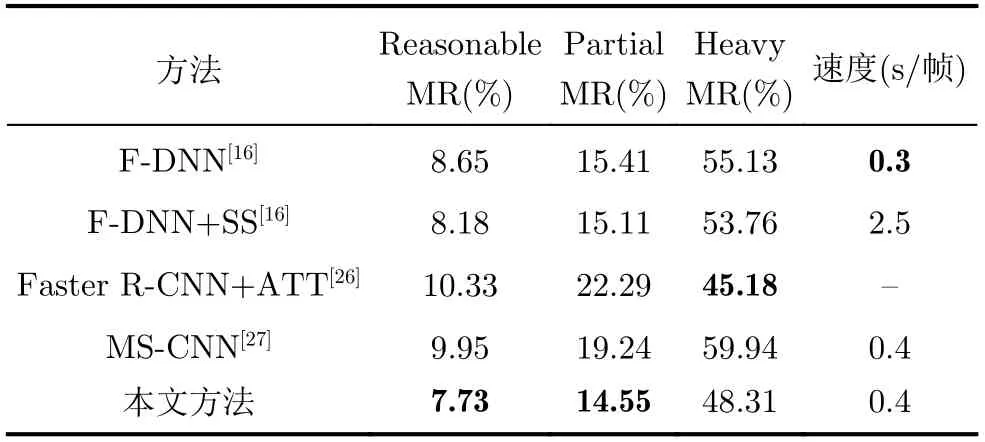
表5 Caltech数据集漏检率MR和速度的实验结果
为验证所提方法在视频中的表现,本文选取连续的4帧视频图像作可视化处理,如图6所示。边界框上的数字表示其置信度且取值范围为[0,1],该值越高表示边界框为所需边界框的概率越大。
从图6可以看出,本文所提方法对连续视频帧有较好的检测效果。观察图6(a)即视频帧1可以发现,虽然行人的尺寸较小且存在约30%的遮挡,但本文方法依然准确检测出其头部和整体。而对于图6(b),行人上身衣服颜色与背景相似,这种情况容易产生漏检,然而此时其头部边界框的置信度较高,因此该行人整体边界框被保留下来。对于图6(c)和图6(d),行人头部特征近乎消失,但本文方法依靠整体检测分支依然准确地将其检测出来,从而可见所提方法具有一定的有效性和稳定性。

图6 实际检测效果
4 结束语
本文设计了一种结合头部和整体信息的行人检测器框架,通过在行人检测的基础上添加头部检测分支并提供针对性的特征信息,对于所获得的行人头部边界框,设定了行人头部区域并利用该区域内的头部信息为非极大值抑制提供更合理的依据。多个数据集上的对比实验表明本文算法具有一定的优势。下一步将着力设计更合理的匹配方式,将每个行人的头部以及身体视为一对进行检测,以增强头部和整体之间的联系,从而实现单分支且有效的行人检测。
