面向Lustre集群存储的应用日志分析及系统自动优化框架*
2022-04-21曾令仿唐士程杨力平曾文君
程 稳,李 焱,曾令仿,王 芳,唐士程,杨力平,冯 丹,曾文君
(1.华中科技大学武汉光电国家研究中心,信息存储系统教育部重点实验室暨数据存储系统与技术教育部工程研究中心,湖北 武汉 430074;2.深圳国家基因库,广东 深圳 518120;3.之江实验室,浙江 杭州 311121)
1 引言
大规模集群存储系统中,运行着大量应用任务,各个应用都有其自身的特性,如人工智能、空间/高能物理、基因工程和光子科学等应用都具有不同的I/O模式,它们的负载表现多样化,应用的数据采集、建模、训练、分析和输出等阶段也有其不同的I/O特征和需求,如果所有应用均等对待、不加区分地写入集群存储系统会引发各种问题[1],如资源竞争、性能下降和服务器宕机等。集群存储系统的用户、维护人员、上层应用开发人员和多层存储系统开发人员等需要了解当前应用程序需求与特性[2],获取优化建议,找出并消除效率低下的根源,自上而下优化集群存储系统,为将来系统软硬件设计或购买提供参考[3]。
应用的多样性和快速迭代更新,使得人们对当前系统中应用负载情况不甚明朗,不同系统环境中得出的观察/结论有可能不同。比如,我们在实际应用生产环境中采集了5个Lustre集群存储连续326天的应用日志信息,通过分析发现,运行在实际Lustre集群存储中的应用都是读多写少型,读写I/O在应用运行期间一直同时存在,一天内I/O读写量几乎维持在一个比较稳定的水准。我们的上述发现与文献[3-5]的部分研究结论有所区别,但从宏观角度看来,我们的发现在一定程度上进一步完善了对应用负载访问特征的探究。因此,我们认为,通过更多的探索来丰富/验证已有研究,进一步完善已有资料库,为系统开发人员和系统维护人员提供真实部署系统的特征信息与系统性能优化建议,是非常有意义的;另外,在实际系统优化过程中我们发现,系统具备自动优化能力非常必要。
本文首先介绍常规应用日志采集方案和现有I/O数据分析研究工作,并给出本文日志采集相关信息;然后对应用日志进行探究与分析;对相关问题与发现进行归纳,并给出面向相关应用负载的Lustre集群存储优化策略;最后,针对系统优化过程中的自动化需求,面向Lustre集群存储,设计并实现一个系统自动优化框架SAOF(System Automation Optimization Framework),初步实验表明,SAOF能自动执行资源预留、带宽限定等优化策略。
2 应用日志相关研究
2.1 现有应用日志采集与分析研究
在开发、部署和评估功能时,了解应用特性是帮助架构师、集成人员和维护人员识别性能、可用性、可扩展性问题根源的关键[6]。已有研究工作通过研究数据使用模式,利用高级I/O库,分析并行文件系统客户端的I/O,优化HPC环境的I/O预取[7],它们通常通过使用诸如DARSHAN[8]、LIOProf(Lustre IO Profiler)[9]这类工具对日志数据进行跟踪分析来评估应用的I/O负载。应用的负载一般具有阶段性和周期性[10],利用已有日志对应用负载进行分析处理,既可以最大程度利用已存储的日志信息,又可以不消耗宝贵的在线计算与存储资源。
对应用负载进行优化主要有2个步骤:(1)应用I/O数据的监控与采集;(2)I/O数据的分析。在应用I/O数据的监控与采集方面,已有较多优秀的应用I/O数据监控与采集软件,如应用级I/O监控[8,9]、存储系统级I/O监控[11]和全栈I/O监控工具[12]。这3类工作主要关注相关软件的开发,介绍软件的使用,并且一般都是特有领域自身的监控方案,很少涉及到I/O数据分析[3,4]。
I/O数据分析主要分为2类:(1)单个应用的I/O行为分析[13],其主要探究应用的带宽特性、I/O周期性与重复性、单个作业的I/O行为多样性等。这些研究缺乏全局视角,效益有限,现阶段大多研究倾向于挖掘更多的信息(如存储服务器的信息),来进一步优化系统性能[14]。(2)整个存储系统的I/O行为分析[15],此类研究通过探索最佳文件系统配置或确定系统级拓扑瓶颈,关注存储系统I/O行为,提供相应建议,一般不会分析存储系统上现有活动的负载,通常也没有对元数据服务器、对象存储服务等提供深入的分析,没有过多考虑与HPC系统相关的交互,只提供了整个存储系统级别的高级特征。
针对整个存储系统的I/O行为分析问题,Patel等人[3]利用系统级I/O监控工具LMT(Lustre Monitoring Tool)[16]对美国国家能源研究科学计算中心NERSC (National Energy Research Scientific Computing center)的Edison和Cori超级计算机共享的Lustre集群存储一年内(2018年)所有存储服务器的I/O活动数据进行收集,对采集到的I/O数据的时间、空间与相关性进行了分析,发现了一些有趣的现象,如在NERSC系统中,HPC应用的读I/O负载已经远远超过写I/O负载,写I/O比读I/O更突发,并且对象存储目标机之间的I/O活动存在巨大的负载不平衡,与计算节点一样强大的对象存储服务器一般是空闲的,并且其CPU利用率非常低。
Turner等人[5]利用LASSi(Log Analytics for Shared System resource with instrumentation)工具(Cray公司开发)[17]和SAFE(Service Administration From EPCC)软件(爱丁堡并行计算中心开发)[18]来收集和分析在英国国家超级计算服务ARCHER(Advanced Research Computing High End Resource)中Lustre集群存储上的作业I/O性能数据,分析了不同应用程序对文件系统性能的潜在影响结果,并预测其将如何影响未来的I/O需求,进一步对这项工作未来可能的发展方向进行了概述。另外,作者观察到ARCHER上写入的数据量大概是读取数据量的2倍,不同应用实际写入量与读取量有较大差别。
Patel等人[4]使用应用级的采集工具Darshan[8]收集了一台排名前500的超级计算机上4个月的I/O访问数据进行,对应用I/O的访问、重用和共享特性进行了深入的挖掘和分析,作者总结了10个“发现”,如文件可分为读密集型RH(Read-Heavy,占比约22%)、写密集型WH(Write-Heavy,占比约7%)或读写密集型RW(Read-and Write-heavy,占比约71%),应用负载情况以读为主;读任务比写任务多,并且传输更多的数据量,但单次写任务传输的数据量大概是读任务传输数据量的1.4倍等等。其中一个有趣的“发现”是:现代HPC应用程序在很大程度上倾向于在单个运行期间只执行一种类型的I/O(读或写),但这与假设HPC应用程序在单个运行期间同时具有读取和写入I/O的观点[19]相左。
2.2 国家基因库日志采集与集群存储系统
深圳国家基因库CNGB(China National GeneBank)集群系统存储生物资源和基因数据,对遗传信息进行读取和合成运用。本文使用Prometheus[20]采集CNGB存储服务器应用日志信息,被采集的5个Lustre集群存储的相关信息如表 1所示,其中Lustre集群存储及其客户端的版本信息是该Lustre集群存储2020年6月份的主流版本信息。

Table 1 Basic information of CNGB Lustre cluster storage
5个Lustre集群存储的应用日志信息大小分别是34 244 KB,34 148 KB,34 216 KB,34 692 KB和34 624 KB,总大小为171 924 KB,约168 MB应用日志信息,应用日志实际采集时间段:2019-08-01 00:00:01至2020-06-22 00:00:01,合计326天。
3 国家基因库应用负载特性与相关规律分析
本文针对国家基因库的5个Lustre集群存储应用日志分析,主要探究以下关键问题:
(1)应用读写类型问题;
(2)同一生产环境中,不同Lustre集群存储/应用读写类型的差异性;
(3)读写数据量的变化规律;
(4)异常情况发生的规律性,同一生产环境不同Lustre集群存储的异常情况是否一致;
(5)如何运用应用日志的分析来优化存储系统。
对以上5个关键问题的探究目的是试图弥补现有发现的不足,丰富现有集群系统优化资料库。
3.1 多个Lustre集群存储应用日志分析
图1给出了5个Lustre集群存储读写数据量柱状图,横坐标是Lustre集群存储编号,纵坐标是读写数据量。观察图 1可以发现,运行在5个Lustre集群存储上的应用主要是读多写少类应用,每个Lustre集群存储读写总量比分别是:3.37,4.14,2.15,2.39和5.23,平均读取数据量是写入数据量的3.46倍。不同应用的读写数据量比有较大差异,如集群存储L_C的读数据量是写数据量的2.15倍,而集群存储L_E的则为5.23倍。从图1中可以进一步看出,5个Lustre集群存储应用数据的写入量相差不大,平均44.38 TB,而读取数据量有较大差异。所以,在实际生产环境(主要是生物信息领域)中,应用主要以读应用为主,不同应用的读写数据量有较大差异。

Figure 1 Read/Write data of five Lustre cluster storages
图 2分别给出了5个Lustre集群存储11个月读取和写入数据量趋势图。横向对比每个Lustre集群存储的读取和写入数据量,可以明显看出,随时间变化读取数据量和写入数据量无线性关系,每月的读取和写入数据量不可预测;纵向对比5个Lustre集群存储的读取和写入数据量,发现当月的读取和写入数据量并无直接关系,大量的写入数据量并不一定会带来大量的读取数据量。

Figure 2 Read and write data of five Lustre cluster storage systems during eleven months
总的来说,从各月读取和写入数据量的趋势图可以看出,不同Lustre集群存储上的应用表现出了一致性,即:每个月的读取数据量之间,每个月的写入数据量之间和每个月的读取和写入数据量之间都无特别规律。这也符合客观事实,即用户行为(如启动应用、暂停、停止等操作)无法预测,使得集群存储系统读写数据量整体看毫无规律,给缓存与预取策略的设计带来了挑战。
为进一步探究Lustre集群存储读写数据量之间的关系,本文对比分析了集群存储系统的OST(Object Storage Target)容量、因异常而丢弃(drop)的字节数与异常数量三者之间的联系。
图 3分别给出了5个Lustre集群存储异常drop次数及其对应的数据量,可以明显看出,异常drop次数与其对应的数据量之间没有明确关系,即同一生产环境中,异常情况的发生没有规律,不同Lustre集群存储的异常情况都不可预测,随机性较强。
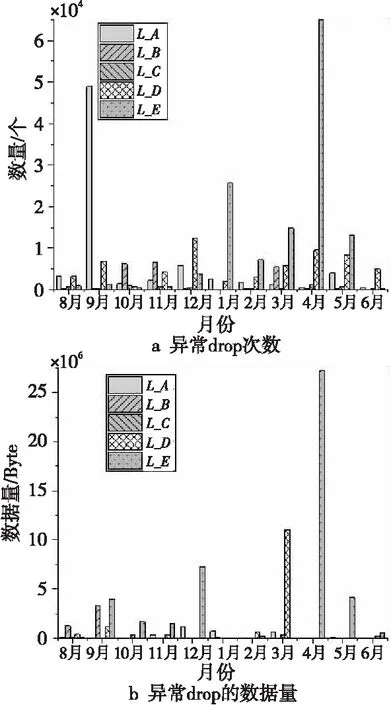
Figure 3 Drop number and drop data of five Lustre cluster storage systems
通过对比5个Lustre集群存储的读写数据量,进一步可以看出,Lustre集群存储异常drop次数和其对应的数据量与Lustre集群存储的读写数据量之间并无联系。这表明,用系统异常来预测或优化系统的读写操作很难获得良好的效果。
为了进一步探究更细粒度的Lustre集群存储应用日志信息,接下来选取集群存储L_A作为研究对象,进行更深入的分析。
3.2 单个Lustre集群存储应用日志分析
从2.1节的统计分析可以看出,5个Lustre集群存储表现比较一致,为了更进一步探究应用日志的特性,本节选取了集群存储L_A的I/O数据量作为研究对象,分别针对集群存储L_A在不同时间尺度下的读写数据量进行量化分析。
图4给出了集群存储L_A不同月份某天1小时内的读取数据量折线图和当天1小时内对应的写入数据量折线图。从图4中可以看出,9月、10月和11月读数据量相比于其他几个月的读数据量偏高,但几乎一致处于偏高水准,比较稳定,而写入数据量仅10月处于偏高水准,并且整个时间段10月的写入数据量都大于其他几个月的写入数据量。通过以上分析可以看出,短时间内(如1个小时),大部分应用的读写数据量大致趋于稳定(偏高的一直处于偏高水准,偏低的一直处于偏低水准,很少呈现出锯齿形)。另外,大多数应用的读写比相当,仅9月和11月的平均读数据量远高于写数据量。少部分应用是读多写少类应用,大部分应用的读写数据量相差不大。为了排除异常drop数据量对读写数据量的影响,本文对相关的drop字节数数据进行了分析,仅发现8月的第60分钟和10月的第40分钟有17.33字节的数据量丢失,相比于真实读写数据量,基本可以忽略不计。

Figure 4 Read and Write data within one hour on a day in different months of L_A
总的来说,类似的应用,I/O模式具有相似性,大多数应用的读写需求量差别不大,仅个别应用有较高的读写需求。
图 5给出了集群存储L_A不同月份某天内的读取数据量和写入数据量折线图。从图5中可以明显看出,相比于图4,图5的折线幅度较大。但是,读取需求高的应用,当天的读取数据量一直偏高(如9月、10月和11月),而写入数据量却呈现锯齿形波动(如1月、2月、4月和5月),这充分验证了HPC领域常见的I/O突发写特性,但没有表现出特定时间段内(一天中)读写数据量集体偏高或偏低的情形,另外,除了9月和11月,大多数应用的读写数据量的比例相当,与1小时内得到的结论相符,对相关drop字节数数据进行了分析,得出了类似1小时读写比例的相关结论。这从侧面证明了在该环境中应用比较稳定,仅有少部分应用是读多写少类应用,大部分应用的读写数据量相差不大。

Figure 5 Read and Write data on a day in different months of L_A
本文也对集群存储L_A不同月份29天内的读写数据量进行了分析,分析发现读取数据量部分应用波动较大,但大部分读取数据量比较稳定,写入数据量虽然相比于读取数据量较少,但与1天内的写入数据量类似,呈现锯齿形波动,另外对相关drop字节数数据进行了分析,得出了类似1小时、1天的读写比例的相关结论。
总而言之,针对当前研究的Lustre集群存储应用,其突发性读取操作较少(如图4a和图5a),突发性写入操作较多(图5b)。另外,根据集群存储L_A在1个小时内、1天内和29天内的读写数据量的各类测试图可以看出,同一个系统中,I/O一直存在,且读取和写入操作是同时进行的。
4 系统优化与讨论
本节将进一步讨论5个关键问题,总结相关发现并与已有文献进行对比,给出系统优化策略和建议;同时,针对系统优化的自动化需求,设计并实现了SAOF,且初步验证了其有效性。
4.1 相关发现总结
第2节对5个Lustre集群存储的应用日志进行了横向(多个Lustre集群存储应用日志)和纵向(单个Lustre集群存储应用日志)对比分析,有以下几点发现:
发现1在国家基因库实际生产环境中,应用主要偏向读多写少型(5个Lustre集群存储,平均读取数据量是写入数据量的3.46倍),另外不同应用总的读写数据量有较大差异(如集群存储L_C的读数据量是写数据量的2.15倍,而集群存储L_E的读数据量是写数据量的5.23倍)。大多数应用的读写数据量相差不大,仅个别应用负载有较高的读写需求。
发现2同一个系统中,I/O一直存在,并且读取和写入操作通常是同时进行的。短时间内(如1个小时),应用的读写数据量大致趋于稳定,即I/O模式具有相似性或周期性。但是,每个月的读取数据量之间,每个月的写入数据量之间无特别规律。
发现3读取数据量偏高的应用,其读取数据量一直偏高,而写入数据量却呈现锯齿形波动,主要表现为I/O突发写特性,但并没有表现出特定时间段内(1天中)读写数据量集体偏高或偏低的情形。
发现4同一生产环境中,异常情况的发生没有规律,不同Lustre集群存储的异常情况都不可预测,随机性较强。因为异常drop的数据量较少,并没有对实际读写数据量产生较大影响。
4.2 对比分析
针对本文的“发现1”已有相关研究,如Patel等人[3]分析发现应用的读I/O负载远远超过写I/O负载,但Turner等人[5]对应用分析发现写入数据量大概是读取数据量的2倍。本文的“发现1”可以与上述研究相互印证。在本文测试的生产环境中,应用偏向于读多写少,不同应用读写负载差异较大,并且有如下补充:大多数应用的读写数据量相差不大,仅个别应用有较高的读写需求。本文的“发现1”在一定程度上进一步完善了应用负载类型相关文献。其中引起负载类型差异的主要原因可能是不同研究机构/数据中心的受众不同,在其系统上运行的应用大多数具有类似性质,使得应用负载总体看来具有了比较偏向的需求(如读多写少、写多读少等),但单个应用可能表现并不明显,即单个应用的读写数据量差异可能并不巨大。
针对本文的“发现2”已有相关研究,如Patel等人[4]发现HPC文件读写表现出周期性,并且应用程序在很大程度上倾向于在单个运行期间只执行一种类型的I/O:读或写。但是,本文的“发现2”通过对应用日志进行详细分析,却发现同一个系统中I/O一直存在,且读取和写入操作通常是同时进行的,短期内读写I/O都比较稳定,具有相似性或周期性,印证了HPC应用程序在单个运行期间同时具有读取和写入I/O的观点[19]。另外,本文的“发现2”进一步给出了长时间读写数据量并无特别规律的现象。
针对本文的“发现3”也有相关研究,如Patel等人[3]观察到写I/O比读I/O更突发,本文也观察到了类似现象,即写入数据量呈现锯齿形波动,而且读取数据量偏高的应用,其读取数据量一直偏高,比较稳定,并且没有表现出特定时间段内(1天中)读写数据量集体偏高或偏低的情形。本文的“发现3”可以看作是对已有研究的补充。
针对本文的“发现4”,分析应用日志并同时分析异常的相关研究较少,但仅对异常进行分析优化系统的研究较多。本文的“发现4”可以作为Lustre集群存储异常优化的一份参考资料。
4.3 系统优化策略
针对“发现1”,读多写少类应用,并且大多数应用的读写数据量相差不大,仅个别应用有较高的读写数据量需求,有如下优化建议:应用分类,数据分级存储,如针对读写数据量差异较大的应用,可以配备高性能硬件设备或大内存,设置预取规则,缩短应用读阶段耗时,优化系统整体性能;而对于读写数据量差异较小的应用,读写数据量相对较少,建议采用缓存算法来优化系统,既可以在一定程度上减少硬件开支,又能合理利用已有高速缓存设备,优化系统读写性能。
针对“发现2”,I/O一直存在读写同时进行的情况,由于写入会影响读取操作,可以采用读写分流策略,另由于短时间的读写数据量比较稳定,但长时间读写数据量之间无特别规律,可能会引起OST端存储负载不均的问题,建议根据短时间读写数据量、底层硬件的读写速度差异与文件系统剩余空间,制定读写分流策略。这样设计可以在保证前端应用读写性能较优的同时,减少后期因OST剩余空间不均衡而引发额外的数据迁移操作,也避免了数据迁移操作对正常I/O读写的干扰。
针对“发现3”,读取数据量比较平稳而I/O表现为突发写的特性,可以采用PCC(Persistent Client Caching)技术[21,22]进行优化。另外,一般应用,如社交软件,会出现白天或夜晚使用用户较多,凌晨使用用户较少,而引起服务器负载不均衡的现象。但是,根据本文的“发现3”,读写数据量未出现某时段集体偏高或偏低的情形,其主要原因是用户群不同。在国家基因库实际生产环境中,应用主要面向生物信息领域,为了最大化资源利用率,节省经济开销,用户和运维人员都倾向于让系统满负荷运行相关任务,这在一定程度上对系统的可用性和可维护性提出了挑战。针对以上挑战,为了确保系统稳定,建议部署监控报警系统,并对相关文件设计数据安全策略(如File Level Redundancy和Erasure Coding等)。
针对“发现4”,根据Lustre集群存储异常的随机性与异常drop数据量的占比可知,如果仅用Lustre集群存储异常来预测或优化系统的读写操作可能无法获得良好的效果。当I/O出现异常时,一般情况下,管理员会查看服务器节点的资源利用率,但根据本文第2节的分析可知,服务器节点的资源利用率是比较稳定的,那么管理员通常会认为异常I/O的应用在MDS或OSS上与其他应用产生了资源争用。针对以上异常问题,建议将服务器端日志与应用程序I/O模式相关联,但困难在于Lustre集群存储实现了客户端页面缓存,在数据回写时,客户端页面缓存会将非常小但连续的I/O重组为大型顺序I/O写入后端存储系统,并且此过程中应用的配置和后端存储系统的监控(只能看到写回的数据)都是透明的。因此建议针对非常小的I/O采用MOD(Data-On-Metadata)机制,在客户端就区分I/O的大小流,在提升小文件读写I/O的同时,减少原有后端存储系统的监控对象,为关联服务器端日志与应用程序I/O模式提供便利。
4.4 面向Lustre集群存储的系统自动优化框架
从前面应用日志分析及系统优化实践中发现,提升系统优化的自动化水平(或者说智能性),能降低系统运维人员的工作强度,提升系统优化效率。
4.4.1 系统自动优化需求分析
根据“发现1”可知,大多数应用的读写数据量相差不大,仅个别应用负载有较高的读写需求,那么在实际环境中,可以根据应用特性为其提供QoS(Quality of Service)保证,设计资源利用规则,即满足其隔离与资源需求。根据“发现2”可知,I/O的周期性可以为存储系统资源利用提供事实依据,即在根据应用特性进行隔离时,依据I/O周期性特性,可以估算出当前正在运行、排队的任务的完成时间、资源需求等,并设置相应的调度策略,进而使得资源利用更具合理性。根据“发现3”可知,同一应用,长时间看,其应用I/O需求比较稳定,这有助于探究和利用Lustre集群存储的系统状态获取命令(lfs/lctl)来分析/获取负载特性,按需提供资源利用服务,并可应对一些应用的突发需求(如checkpoint)。根据“发现4”可知,对OSS端I/O读写数据量的探究可以较好地代表Lustre集群存储的整体I/O状态,一般采用Prometheus常规应用监控,可以避免监控对系统过多影响,或者利用Lustre集群存储提供的已有命令(lfs/lctl),不添加其他监控部件,能进一步减少对系统性能的影响,也能较好地获得Lustre集群存储的状态。
通过剖析以上发现不难看出,不管应用负载如何多变,对存储系统资源的自动管理(特别是资源预留与限定)才是关键。下面将简要介绍现阶段Lustre集群存储的QoS解决方案与任务调度器并分析它们的不足之处。
Lustre集群存储已有较多的QoS解决方案,例如:Lustre集群存储的NRS(Network Request Scheduler)[23]中采用令牌桶过滤器TBF(Token Bucket Filter)进行带宽限制[1]并提供最小带宽保证[24]的NRS-RBF策略;通过对Lustre集群存储原有TBF策略进行扩展,文献[25]提供了依赖规则TBF策略,通过手动设置优化关联任务的远程过程调用RPC(Remote Procedure Call)速率,提供关联任务QoS保障;针对原有TBF策略的一些功能缺乏问题,如只能限制RPC速率,不能对带宽或每秒进行读写操作的次数IOPS(Input/Output operations Per Second)进行限制,仅针对单个OST/元数据目标MDT(MetaData Target),无全局管理方案等问题,文献[26]提出了LIME(Lustre Intelligent Management Engine)框架;以及近期我们提出的利用深度强化学习方法进行端到端I/O调度的方案。但是,以上方案大都未考虑资源预留与已有任务调度器相结合方面的问题。通过对SLURM(Simple Linux Utility for Resource Management)[28]和现有Lustre集群存储的资源规划方案的探究有以下发现:(1)当提交的任务资源请求不满足时,SLURM 会一直等待轮询该任务;(2)并行文件系统(如Lustre集群存储或GPFS(General Parallel File System))为调度器提供读写时,隐藏了管理存储性能所需的许多细节,如后端存储服务器的数据布局策略;(3)很少有作业调度器实现了自动化的(资源预留)调度。
为了保证系统可扩展性和可用性,系统运维人员在执行任务时,为减少资源竞争和任务调度器的失误,常常采用过度分配的方式管理资源。另外,现有Lustre资源管理方案缺乏通过分析存储集群中文件数据位置与工作负载并"自动按需"提供系统服务/优化相关功能。
总的来说,现有方案在Lustre集群存储内部状态的信息(如后端存储服务的资源与数据管理等信息)、存储带宽管理、作业的带宽消耗与面对周期性或临时性任务的资源预留等方面,缺乏自动优化能力。基于以上分析和实际应用需求,面向Lustre集群存储,本文设计并实现了一个系统自动化优化框架SAOF。在实际部署中,SAOF被设计为Lustre集群存储中的一个新实例,它接收来自job管理系统(如SLURM)的读写带宽请求,并通过配置Lustre集群存储的网络请求调度器(NRS),限制已注册计算任务的带宽,在资源满足时保证任务QoS。具体来说,SAOF的主要功能是通过Lustre集群存储常用命令lfs/lctl获取集群存储相关资源信息,并调用Lustre集群存储的NRS-TBF调度器实现资源预留与限定[24]。SAOF的资源预留功能可以为数据迁移预留带宽,缓解OST端存储负载不均和数据迁移等问题;SAOF的资源限定可以达到应用隔离并确保应用QoS的目的。下面将介绍SAOF方案的具体实现。
4.4.2 SAOF设计
图6给出了SAOF的系统架构图。图6中虚线框给出了SAOF的主要组件,包括用来获取前端用户提交的任务信息与任务调度器交互的SAOF frontend API,更新与设置NRS-TBF策略的NRS-TBF Scheduler和当前任务状态的JobState和当前后端集群存储系统状态的ClusterState。SAOF通过高速网络与Lustre集群存储的客户端、服务器互联。SAOF启动后,会周期性的聚合来自作业调度器的请求,收集来自服务器的资源利用情况,根据相应的规则设置NRS-TBF策略,并广播到相应的OSS/MDS。总的来说,SAOF的工作重心是从SLURM获取任务信息,并组合来自集群的资源利用情况,自动构建TBF策略。

Figure 6 Architecture of SAOF
Lustre集群存储默认的最大RPC通常是1 MB,默认4 KB读写情况下,NRS-TBF的1 rate=4 KiB/s的带宽,因此集群系统的总带宽基本上可以稳定地定义为Lbw,也可以通过设定不同的rate来确保不同的带宽需求。图7给出了SAOF框架流程图,其通过剩余带宽判断是否接受新任务或修改已运行任务等级来减少前端调度器的试错,即当∑iminbwi≤Lbw时,接受新任务或改变已有任务优先级;否则把Lustre集群存储资源信息反馈给任务调度器,减少试错,减轻服务器计算、存储和网络压力。其中minbwi表示第i个任务所需要的最小带宽。下面将分别对SAOF的性能隔离、QoS保障和资源预留功能进行测试。

Figure 7 Flow of SAOF
4.4.3 SAOF功能测试与验证
由于国家基因库短期内没有新增系统需求,当前运行的都是生产系统,为了验证本文提出的系统自动优化框架的有效性,在实验室构建一个小型Lustre集群存储对SAOF进行了初步测试。该小型Lustre集群存储主要包括:3个客户端,2个OSS并各自挂载了2个549.0 GB的OST,聚合容量2.1 TB,1个MDS挂载了1个261.4 GB的MDT;操作系统为CentOS 7.5;Lustre集群存储版本为2.12.1;通过1 GB以太网互连。采用FIO(Flexible I/O tester)[29]测试工具(fio-3.7)生成相关任务负载,主要给出了写带宽的测试(读带宽、IOPS也可以通过设定相应的TBF策略获得类似的效果,示例中给出了对应的IOPS测试图)。测试如下所示:
(1) 性能隔离、QoS保障测试。
设计实验如下:假设系统能提供的总写带宽约为500 KiB/s,现在有2个任务A和B,任务A大概需要300 KiB/s的最大写带宽,大概200 KiB/s的最小写带宽,需要传输约200 MiB的数据量,任务B的优先级高于任务A,任务B需要保证300 KiB/s左右的写带宽,需要传输约100 MiB的数据量。
从图 8中可以看出,测试开始时,任务A开始运行,系统提供大概300 KiB/s的最大写带宽,当任务A运行300秒后,任务B开始运行,此时,任务A的写带宽降到200 KiB/s左右,任务B以300 KiB/s左右的写带宽运行,又过了340秒左右后,任务B运行完成,任务A再度恢复300 KiB/s左右的写带宽运行,总共770秒左右后,任务A运行完成。实验结果能较好地满足预期。
通过以上实验验证了SAOF能对特殊任务提供性能隔离并满足其服务质量。

Figure 8 Performance isolation and QoS assurance
(2) 资源预留测试。
设计实验如下:假设系统提供给任务的总写带宽约为500 KiB/s,现有3个任务A、B和C,任务A和任务B同优先级,需求带宽与传输数据量都相同,需要大概250 KiB/s的最大写带宽,100 KiB/s的最小写带宽,需要传输约200 MiB的数据量,任务C的优先级高于任务A和任务B,任务C需要保证300 KiB/s左右的写带宽,需要传输约50 MiB的数据量,并且任务C需要周期性运行(每次传输50 MiB的数据量,总共需要传输3次)。
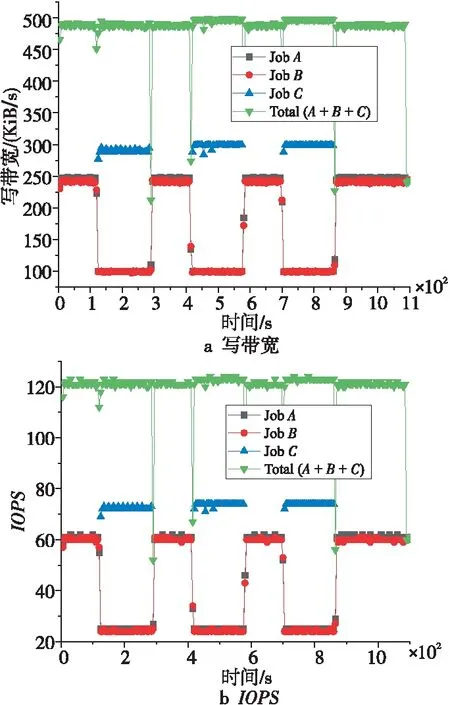
Figure 9 Periodic resource reservation and QoS assurance
图9给出了周期性资源预留与QoS保障测试图。从图9中可以明显看出,任务A与任务B几乎获得了相同的资源在运行,每当任务C开始执行时,任务A和B的写带宽都会下降;另外,系统总的带宽消耗Total(A+B+C),除了在任务调度时有所下降外,其他情况下都能保证大约500 KiB/s的写带宽。
通过以上实验可以验证SAOF能对周期性应用提供资源预留功能,确保应用服务质量。
5 结束语
集群存储系统负责为上层应用提供数据读写与存储服务,良好的集群存储系统应自动适应上层应用按需访问。针对在复杂系统环境以及应用多样性情况,对应用负载的特性挖掘不够完善等问题,本文对实际生产环境的Lustre集群存储的应用日志信息进行了分析。具体来说,采集了国家基因库生产环境中,5个Lustre集群存储连续326天应用日志相关信息,通过对应用日志信息横向(多个Lustre集群存储应用日志)、纵向(单个Lustre集群存储应用日志)和多维度(时间与空间)的对比分析,对现有研究进行补充完善,也为其它系统/应用负载研究提供了参考。通过对5个关键问题的回答与4个发现的分析,结合实际生产环境,给出了系统优化策略建议与切实可行的实施方案。同时,针对系统性能优化自动化需求,设计并实现了SAOF,SAOF通过合理利用应用需求和集群存储带宽资源等信息提供资源预留、带宽限制等功能,初步实验验证了SAOF的有效性。
