特征漂移约束算法在推荐系统中的优化
2022-04-20郑文凤
刘 云,张 轶,郑文凤
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
基于用户动态偏好的推荐算法,推荐系统(recommender system,RS)利用有关用户、项目或用户项目交互历史数据中记录的经验知识和信息向目标用户生成建议。由于用户兴趣和项目偏好是随时间动态变化的,随着新用户和项目数据的不断生成,导致用户和推荐项目之间呈现更复杂的非线性关系。最新的研究表明,在推荐算法中引入不同的特征提取机制,构建有效的模型,可以分析用户兴趣和项目偏好特征之间的关联关系,学习用户偏好的动态变化给出准确的个性化推荐结果[1-2]。
为了从动态用户的偏好变化中捕获用户兴趣和项目偏好特征的概念漂移,构建个性化推荐系统,本文提出特征漂移约束(feature drift constraint,FDC)算法。首先,基于输入样本构建评级矩阵的时间序列,分解评级矩阵为用户特征矩阵和项目特征矩阵[7];其次,用户兴趣随着时间推移变化,通过计算隐藏特征向量的标准偏差,与上一时间点相比来表征概念漂移;再根据概念漂移的大小动态更新用户兴趣和项目偏好特征向量,从而更新推荐模型;最后,计算用户和项目特征向量的内积,得到预测的项目评级,实现项目推荐[8-9]。仿真结果表明,相比于基线算法,FDC算法的推荐准确性和鲁棒性有所提升。
1 算法模型
1.1 推荐系统模型
推荐系统基于用户与系统进行交互期间收集的行为和反馈信息,利用用户动态偏好的推荐算法学习目标用户的偏好变化,向其提供个性化的项目建议,解决信息过载问题[10]。
推荐方法通常分为4类:基于内容、协同过滤、基于知识和混合推荐方法。其中,协同过滤方法基于“偏好和兴趣相似的用户在未来会尽可能更多地呈现出相关性”这种假设而提出,从而依据用户的历史偏好和兴趣为用户生成推荐。本文采用协同过滤中的矩阵分解推荐方法[11],标准模型如图1所示。

图1 推荐系统模型Fig.1 Recommender system model
如图1所示,常用的推荐模型由3个阶段构成,输入数据阶段包含用户集和项目集和与其相关信息的输入。预测阶段通过建模提取输入数据的特征,采用不同的方法计算效用函数F:Users×Items→F0,衡量推荐结果针对一个用户u∈Users和一个项目i∈Items的匹配程度[9],F0表示由用户特征和项目特征计算得到的推荐评分。推荐阶段是预测阶段的扩展,选取最合适的项目支持用户的决策,并向目标用户推荐具有最高预测评分的项目集。
1.2 矩阵分解(MF)
矩阵分解方法通过隐藏特征来表示单个用户和项目,这些隐藏特征从历史评级矩阵R中表征用户和项目的交互作用[12]。其基本方法是将评级矩阵R分解为用户特征矩阵P和项目特征矩阵Q。P和Q分别是m×k和n×k的矩阵,且秩为k,k≤min{m,n}。Pi代表P中的第i列元素,称为用户兴趣特征向量,Qj代表Q中的第j列元素,称为项目偏好特征向量。
根据上述定义可以用每对用户和项目特征向量的点积近似计算每一个评级,
(1)
矩阵分解方法考虑式(1)中P和Q的优化问题如下,
(2)
优化P和Q可以通过SGD算法进行学习,该算法遍历训练集中的所有评分。对每个训练样本Rij,计算相应的预测误差为
(3)
接着对每个循环进行评分,特征向量Pi和Qj采用与梯度相反的方向更新如下,
Pi←Pi+α(eijQj-λPi),
(4)
Qj←Qj+α(eijPi-λQj)。
(5)
其中,α和λ分别是学习参数和调节器参数。在实际推荐应用中,数据分布随时间的变化降低了学习算法对新数据或实时数据的泛化能力。
1.3 概念漂移检测
为了学习随时间变化的用户兴趣和项目偏好,提取目标用户的个性化喜好特征,采用概念漂移检测方法学习用户偏好行为变化的特征漂移,更新提高推荐系统的有效性。Hellinger距离测度通过计算新分布和基线分布之间Hellinger距离变化的幅度判断是否发生特征漂移,每次检测到漂移时都会更新模型。Hellinger距离是分布散度的度量[13],使推荐算法能够检测两个后续时间戳在数据分布之间的变化。
δH(t)=
(6)
其中:d是数据的维度;Li,k和Mi,k分别是特征k对应直方图L和M中堆栈i的频率计数。将当前距离与先前距离之间的差异与阈值进行比较,以确定变化是否足够大而产生概念漂移。
针对用户喜好特征的动态变化,基于时间的协同过滤方法结合概念漂移检测在矩阵分解推荐中解释隐藏特征的概念漂移,提出特征漂移约束算法优化推荐系统模型。
2 特征漂移约束(FDC)算法
基于时间矩阵分解的基本模型,针对用户兴趣和项目偏好特征向量的概念漂移建模,改进动态推荐系统。通过跟踪用户兴趣或项目偏好特征漂移表示推荐系统中用户兴趣和项目吸引力的变化,模型如图2所示。
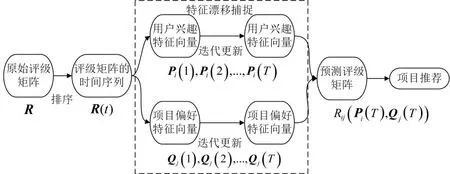
图2 特征漂移约束算法模型Fig.2 Feature drift constraint algorithm model
算法主要步骤如下:
Step1利用训练集的评级反馈构造m×n阶评级矩阵的时间序列R(t),t=1,2,…,T-1;
Step2基于评级矩阵的时间序列R(t)学习用户兴趣特征向量的时间序列Pi(t),以及项目偏好特征向量Qj(t);
Step3利用用户兴趣特征向量的时间序列Pi(t)和项目偏好特征向量的时间序列Qj(t)计算每个用户i以及每个项目j中的概念漂移;
Step4基于步骤3中获得的特征漂移计算加权的用户兴趣和项目偏好向量,更新模型;
Step5使用T时预测的用户兴趣特征矩阵P(T)和项目偏好特征矩阵Q(T)的乘积预测评分矩阵的缺失值。
推荐模型的目标是研究每个用户潜在向量中可能的漂移。概念漂移表示用户对k个项目偏好特征向量的变化,代表了单个项目与k个特征的关联关系。考虑到用户-项目交互的关联时间信息,将用户评价矩阵表示为4元组(user,item,rating,time)。
当评价矩阵的时间标签被删除时,评级用m×n大小的矩阵表示,元素Rij表示真实评价下用户i对项目j的评价,相反,如果用户没有进行评价,则Rij被称为缺失评级。在实际应用中,矩阵R是一个存在许多缺失值的稀疏矩阵。
2.1 FDC算法实现
通过对原始评级矩阵进行排序,构建评级矩阵时间序列R(t),使项目时间标签在相同的尺度上平均划分评级矩阵。为了避免生成更稀疏的数据,采用基于分区的方法保证了数据的生成。又选取滑动窗口的方法,将多个连续切片中的评级组合成单个时间步长。
用户兴趣的特征漂移随着时间变化,当在t时收到一组新的评级时,得到更多的关于扭曲用户兴趣预测模型的信息,因此,必须调整参考模型。为了分析各个用户的用户兴趣特征向量的时间序列,在t=1时,对评级矩阵进行分解,确定用户特征矩阵和项目特征矩阵与时间步长有关[6]。对于每个时间段的用户项目交互,基于FDC算法定义如下,
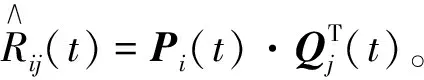
(7)
其中:Pi(t)和Qj(t)分别为原始用户Pi和项目Qj的特征向量。使用该时间步长上观察的评级分别学习Pi(t)和Qj(t)。收到新的评级后,迭代训练模型获得更新的用户兴趣和项目偏好特征向量Pi(t+1)和Qj(t+1),但不是永久更新。为了解决优化问题,采用随机梯度下降(SGD)方法[14]获得优化的学习参数。
(8)
Pi(t)←Pi(t)+α(eij(t)Qj(t)-λPi(t)),
(9)
Qj(t)←Qj(t)+α(eij(t)Pi(t)-λQj(t))。
(10)
每一次新的评级,都会获得有关用户偏好的新信息,从而基于新的评级更新用户和项目相关的特征向量。此方法保持了旧偏好和新偏好之间的平衡,并确保特征向量中的概念漂移得到及时处理。
在真实的推荐系统中,单个用户会在不同的时间点发生兴趣漂移。学习关于这些动态变化的模型都会扭曲预测模型的精度,为了学习偏好的变化,衡量Pi(t+1)与前一时间点Pi(t)相比隐藏特征发生了多少变化,采用Hellinger距离度量计算相似性得分。Hellinger距离测度是一种基于特征的漂移检测方法[13],适应数据分布中逐渐变化和突然变化的概念漂移,表示为
h(Pi(t+1),Pi(t))=
(11)
漂移分数表征用户兴趣是否发生变化或项目内容是否随时间变化。漂移分数越低,发生概念漂移的可能性就越大。通过计算标准偏差SD(h(Pi(t+1,Pi(t)),研究与上一个时间点相比兴趣特征发生了多少变化。在这种情况下,如果满足以下不等式,则发生更新。
h(Pi(t+1),Pi(t))>αSD(h(Pi(t+1),
Pi(t)))。
(12)
其中:参数α控制遗忘旧偏好的敏感性,在每种情况下,α的选择都是特定的,必须通过实验确定。相同的方法也适用于计算项目偏好特征向量Qi(t+1)和Qi(t)的概念漂移。
分析了用户兴趣特征向量Pi和项目偏好特征向量Qj在两个时间点之间的变化后,分别调整用户和项目特征模型。如果新的评级与该用户的兴趣保持一致,则特征向量Pi(t)和Pi(t+1)之间的预期变化最小。如果在对新评级进行训练后影藏向量发生较大变化,则表明用户兴趣已经发生了偏移。针对这种情况,通过乘以一个指数函数更新用户兴趣模型,该指数函数的值取决于用户兴趣的变化率,计算如下,
Pi(t+1)=α-SD(h(Pi(t+1),Pi(t)))Pi(t),
(13)
Qj(t+1)=α-SD(h(Qj(t+1),Qj(t)))Qj(t)。
(14)
该指数函数控制惩罚项的程度,当α>1时,该函数值域为[0,1]。针对高值漂移,指数函数产生较低的值,对历史兴趣的惩罚较高。
时间周期T-1内的用户和项目特征向量已经获得,对T时刻的偏好特征向量预测如下,
Pi(T)=α-SD(h(Pi(t+1),Pi(t)))Pi(T-1),
(15)
Qj(T)=α-SD(h(Qj(t+1),Qj(t)))Qj(T-1)。
(16)
经过时间T时特征向量P和Q的学习,使用特征向量Pi(T)和Qj(T)的内积预测推荐项目的未来预测,
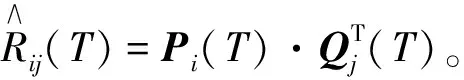
(17)
2.2 FDC算法分析
迭代算法解决推荐问题的伪代码如下,此过程迭代进行直到变量收敛为止。
算法1:特征漂移约束算法(FDC)
输入:
1)用户-项目评级矩阵R
初始化:
2)用户兴趣特征向量Pi(t),项目偏好特征向量Qj(t)
3)隐藏特征数k,学习率α,调节器参数λ
4)whilePi(t),Qj(t)不收敛do
迭代计算:
5)根据式(12)计算用户兴趣特征向量和项目偏好特征向量的概念漂移
6)更新特征矩阵
Pi(t)←Pi(t)+α(eij(t)Qj(t)-λPi(t))
Qj(t)←Qj(t)+α(eij(t)Pi(t)-λQj(t))
7)end while
8)for每个用户udo
9)计算T时刻的特征向量预测
10)根据式(17)计算用户对未来项目的预测评级。
11)end for
输出:

13)使用预测评级为用户提供项目评分。
在此方法的每个步骤中,所有变量均根据其相应公式进行更新。为了证明推荐系统的有效性,通过将评级矩阵划分为训练集和测试集来评估预测算法的性能。采用时间平均均方根误差(time-averaged root mean square error,TRMSE)衡量所提出方法的性能,TRMSE是基于RMSE的评估时间推荐算法的基准指标[15],根据在某一特定时间点之前的评级计算如下,
(18)

3 仿真分析
3.1 数据集及仿真环境
与类似算法仿真一致,仿真分析采用Ciao和Epinions两个真实数据集评估所提方法的性能[16]。这两个数据集是基于带有时间标签信息选择,并广泛用于协作过滤研究项目中,用于在推荐系统中跟踪概念漂移的动态。数据集提供了有关用户、项目、用户偏好评级以及相关的时间标签信息,数据集的统计信息如表1所示。

表1 数据集信息Tab.1 Data set information
为了能够正确检测特征漂移,删除在数据集中出现次数少于20次的用户或项目,并将重点放在现有用户和项目上,用于学习隐藏向量的变化。运行环境为Windows 10,2.6 GHz CPU,8GB内存,Python 3.7。基于时间感知RMSE调整参数,用随机梯度下降算法对所有模型进行训练,至少50次迭代直到收敛。
3.2 时间平均均方根误差分析
为了评估推荐算法预测结果的准确性,对时间平均均方根误差(TRMSE)进行分析,在Ciao和Epinions数据集中评估FDC算法与MF、TSVD++、TMF和MCFTT算法的推荐准确性结果,仿真如图3所示。
图3显示了5种算法算法在两种数据集中的性能,5种算法的TRMSE值随迭代次数的增加都逐渐减小,最终趋于平稳点。但是,不同基准算法的性能在数据集中有所不同,在两种数据集中,FDC和TMF算法对比TSVD++、MF和MCFTT算法表现良好,这表明了相对非时间模型,时间模型因其较长的时间跨度以及对动态偏好的敏感性在推荐系统中存在优势。
另一方面,FDC算法在Ciao数据集中获得了14%的性能改善,而在Epinions数据集中获得了10%的性能改善,与基线算法相比,实现了最佳性能改进。结合Ciao和Epinions两种数据集仿真分析,虽然FDC的初始推荐准确性低于同类算法,但基于时间矩阵分解模型的FDC算法引入概念漂移检测组件,跟踪用户动态偏好特征漂移,使偏好特征提取更接近用户行为存在的稳定结构和不变特征,随着模型学习训练均能获得更低的TRMSE值,表现出更为优异的推荐准确性。
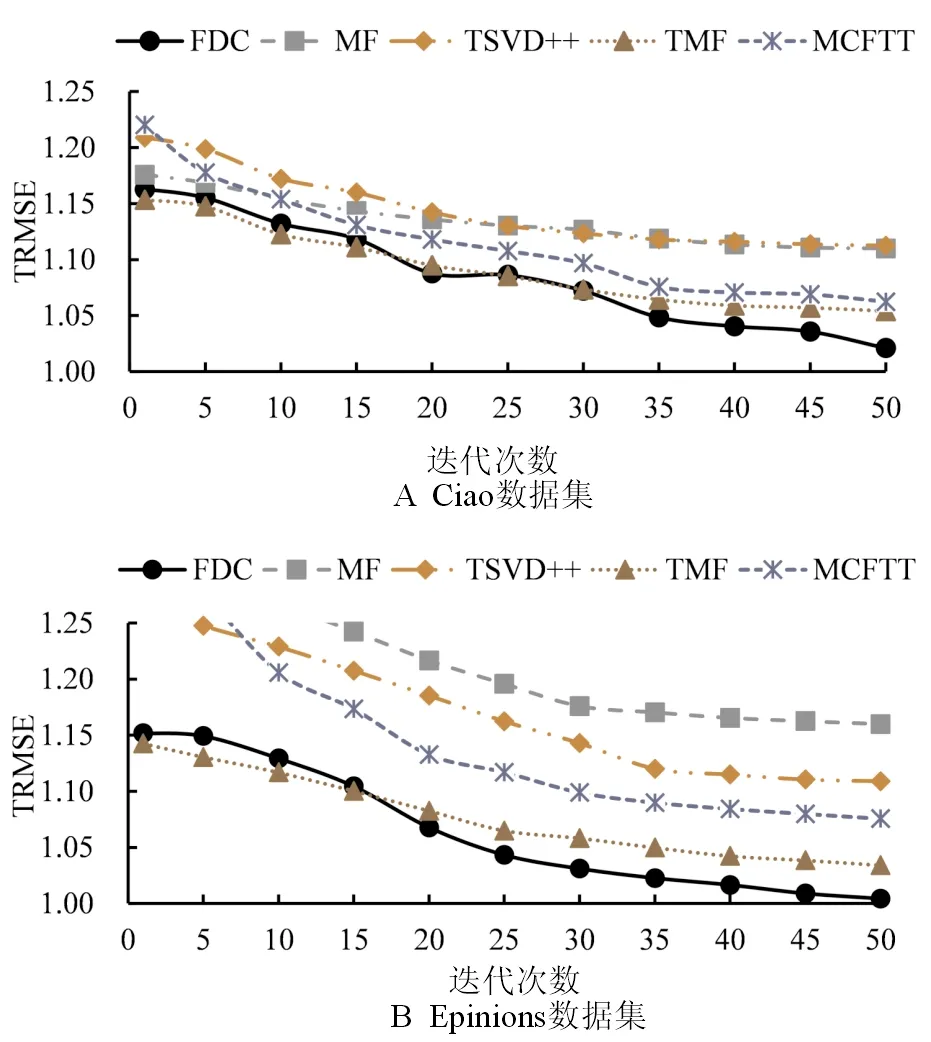
图3 迭代训练对推荐准确性影响分析Fig.3 Analysis of the influence of iterative training on recommendation accuracy
3.3 用户兴趣特征漂移检测有效性分析
对Ciao数据集中的用户63,仿真研究FDC算法相较基线算法对用户兴趣特征变化的概念漂移捕捉的有效性。一方面验证用户兴趣特征向量随时间发生特征漂移的变化,结果如表2所示。另一方面验证FDC算法与对比算法提取的用户兴趣特征向量同原始用户兴趣特征向量的拟合情况,仿真结果如图4所示。 仿真实验中隐藏特征数k=40, 学习率α=0.003, 调节器参数λ=0.01。执行50次SGD迭代捕获每个时间段的特征向量,计算每个时间段的用户兴趣特征向量,参数设置为与基线相同。
表2记录了前5个时间段用户63的5个潜在兴趣特征向量的变化情况,以及预测的下一时间段用户63的兴趣特征向量Pi(6)。对于用户63,FDC预测的用户兴趣特征向量随时间推移发生变化,综合5个特征的变化情况,第4个时间段的用户兴趣特征向量同时间段1的初始用户兴趣特向量相比差异明显,表明用户在第4个时间步长后兴趣偏好发生较大变化。这表明用户倾向于以不同的方式改变自己的行为偏好,即使用户在一段时间内倾向于相同项目,也可能在未来的某个时间改变自己的兴趣偏好,FDC算法能够基于概念漂移检测不断更新用户行为信息,跟踪用户兴趣特征向量的动态变化。
表2 前5个特征下Ciao数据集中用户63的兴趣特征向量变化
Tab.2 User 63 interest characteristics for the first five features in the Ciao dataset

用户兴趣特征向量特征1特征2特征3特征4特征5Pi0.484 70.346 80.486 90.408 50.367 0Pi(1)0.507 80.446 80.576 90.488 50.467 0Pi(2)0.467 80.380 20.579 10.404 30.393 5Pi(3)0.483 50.393 40.445 50.381 30.423 6Pi(4)0.494 80.344 70.474 80.369 90.388 7Pi(5)0.434 40.378 50.569 30.389 50.370 3Pi(6)0.474 00.420 70.558 00.471 10.457 5
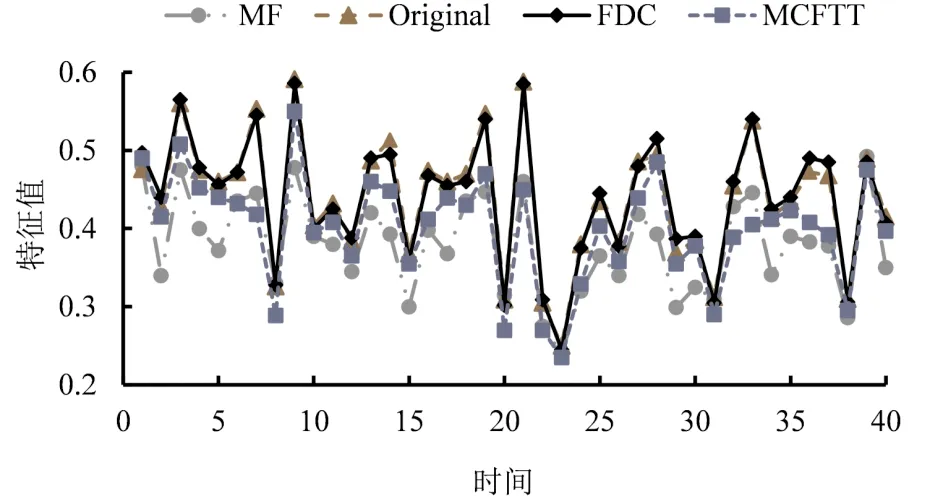
图4 Ciao数据集中用户63兴趣特征向量的变化Fig.4 The changes in user interest characteristics for user 63 in Ciao dataset
从图4可以观察到, 相比MF和MCFTT算法, FDC算法预测的用户隐藏向量与实时用户隐藏向量具有更好的拟合效果, 表现出对概念漂移检测的有效性。 综合用户兴趣特征向量的两种仿真结果, FDC算法在提取用户兴趣特征的基础上, 检测用户兴趣属性变化的概念漂移, 基于测量的单个用户的概念漂移更新用户隐藏兴趣特征向量, 能够有效对抗用户兴趣漂移对推荐系统的影响。
3.4 项目偏好特征漂移检测有效性分析
采用相同方法在Ciao数据集项目80情况下,项目隐藏偏好特征向量随前5个隐藏特征的变化仿真如表3所示,另根据FDC算法预测的项目偏好特征向量变化情况仿真结果如图4所示。
表3 前5个特征下Ciao数据集中项目80偏好特征向量变化
Tab.3 Item 80 preference characteristics for the first five features in the Ciao dataset
项目偏好特征向量特征1特征2特征3特征4特征5Qi0.523 50.703 40.725 50.711 30.523 6Qj(1)0.583 50.802 70.802 70.861 30.503 6Qj(2)0.574 80.717 40.728 40.786 90.498 7Qj(3)0.408 50.646 10.616 30.707 50.431 1Qj(4)0.402 30.617 80.730 50.723 90.485 6Qj(5)0.415 80.655 40.755 90.705 00.472 1Qj(6)0.574 80.797 40.808 40.866 90.508 7

图5 Ciao数据集中项目80偏好特征向量的变化Fig.5 The changes in item preference characteristics for item 80 in the Ciao dataset
表3记录了前5个时段项目80的5个潜在偏好特征向量的变化情况,以及预测的下一时间段项目80的偏好特征向量Qj(6)。从表3可以看出,FDC预测的项目80偏好特征向量随时间推移发生变化。综合5个特征的变化情况,时间段3的项目偏好特征向量同时间段1的初始项目偏好特征向量相比有显著差异,表明在第3时间段后项目偏好发生较大改变。发生这种变化的原因是特定的因素改变了用户对项目隐藏特征的偏好,FDC算法通过学习新项目的隐藏属性特征来捕获项目偏好变化的概念漂移,用于更新项目偏好特征的提取。
从图4可以观察到,相比基线算法,FDC算法预测的项目偏好特征向量与实时项目偏好特征向量具有更好的拟合效果。针对真实数据集中随时间发生的项目偏好变化,FDC算法通过捕获项目属性变化反映出的概念漂移来跟踪用户针对项目偏好的改变,基于项目偏好的变化调整项目偏好模型,实现项目偏好特征的有效提取,提高了推荐系统的鲁棒性。
4 结语
在时间矩阵分解推荐模型中加入概念漂移检测方法,通过捕捉用户兴趣和项目偏好特征的变化情况可有效提升推荐性能。为此,本文提出特征漂移约束 (FDC)算法,首先,依据评级矩阵的时间序列,采用矩阵分解方法将评级矩阵分解为用户特征矩阵和项目特征矩阵;然后,采用随机梯度下降方法训练模型以获得优化的学习参数,计算概念漂移的动态特征加权用于调整模型;最后,结合用户兴趣特征向量和项目偏好特征向量内积,计算得到预测的项目评级,实现有效的推荐目标。在下一步的工作中,面对更复杂的用户喜好变化,需要研究实时特征漂移检测方法来动态学习概念漂移。
