基于跨语言数据增强的事件同指消解方法
2022-04-19程昊熠李培峰朱巧明
程昊熠,李培峰,朱巧明
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.江苏省计算机信息技术处理重点实验室,江苏 苏州 215006)
0 引言
事件同指消解任务是自然语言处理领域中一项具有挑战性的工作,是自然语言理解的一个主要基础,如话题检测[1]、信息抽取[2]和阅读理解[3]等都需要用到事件同指消解。事件同指消解负责判断文本中的两个事件句是否指向真实世界中同一件事,并将它们聚合到同一个事件链。以事件S1和S2为例:
S1: The way wecaughtthat guy was by coordinating with our allies.
S2: The same weekend theyarrestedthe guy, we had.
事件S1的触发词是“caught”,事件S2的触发词是“arrested”。虽然两个事件的触发词不同,但中文意思都是“被抓捕”,且二者的施事者与受事者相近。此外,两个事件的事件类型都是“Justice”,因此二者属于同指关系,并入同一个事件链中。
目前,现存的通用语料库都存在规模较小、语言单一的问题。ACE2005英文语料库中含有4 090条事件链,中文语料库中含有2 521条事件链,KBP语料库含有3 335条事件链。语料库规模太小会导致模型无法充分学习,性能低下。为了解决语料库规模较小的问题,目前通用的方法有两种。第一种方法是使用机器翻译工具将源语料库翻译成其他语言,这样既增强了语料库的规模,又可以利用源语料库中的标注信息,从而确保增加语料的标注质量。第二种方法是使用强化学习[4]的方法在一堆未标注的语料上进行自动标注,这种方法可以实现标注语料的自动化,节省成本,增加语料的来源,但是自动标注的质量可能会稍有逊色。本文使用第一种方法进行相关实验。
事件同指消解用于判别两个事件之间是否具有同指关系,但其面临的问题是每个词语通常都会有多个语义。跨语言学习是解决这个问题的一种有效方式,可以借助词语的其他语言形式来明确其语义,补充结构信息,从而帮助模型寻找出事件语义、结构之间的不同与相似之处。一般而言,有两种常用的跨语言学习方法。一种方式是首先在某一语言上训练一个模型,然后把该模型应用到另一种语言。另一种方式是通过共享模型参数进行多语言间的跨语言学习。本文则在语料库数据增强的基础上进行中英文语料的跨语言学习,通过跨语言学习的方法,让中英文互补各自的不足之处,降低翻译质量对实验的影响。
为了解决语料库规模较小、语义多样性以及事件句含有多个事件的问题,本文设计了一种基于跨语言数据增强的神经网络模型ECR_CDA(Event Coreference Resolution on Cross-lingual Data Augmentation)。该方法使用机器翻译工具来扩充语料库规模,解决语料库规模较小的问题。利用事件触发词的依存词和论元自动抽取事件实例短句,解决句中存在多个事件的问题,最大程度地减小无关事件的影响。使用跨语言学习的方法借助中文来明确英文单词的语义,补充结构信息,帮助模型通过多个语言寻找出事件之间语义与结构的不同之处,提升英文事件同指消解任务的性能。
1 相关工作
目前,事件同指消解的研究建立在实体同指消解[5]研究的基础之上,早期的事件同指消解研究大都使用基于概率或者图的传统机器学习方法。Chen等[6]设计的事件对同指消解分类器引入了一系列事件对属性,比如触发词、时态、极性等是否一致。Chen等[7]提出了一种基于图模型的聚类方法,使用最小图切割的方法来优化纠正事件链,将不属于该链的事件句剔除出去。Liu等[8]设计了最大熵分类器,并引入了100多种特征进行实验。Lu等[9]提出了一种基于马尔科夫链的联合推理模型用于纠正分类器产生的错误结果。Liu等[10]设计了一种基于图的模型分类器,将事件合并成一个无向图,然后将非同指的事件从图中剔除出去。在其他领域中,Zhu等[11]使用机器翻译工具将英文语料库和中文语料库翻译成对应的中文语料库和英文语料库来扩充语料库规模,然后使用最大熵分类器对扩充后的中英文语料库同时进行事件抽取。她做过对比实验,用最大熵分类器对原来的语料库进行实验,性能有所降低。传统机器学习方法总体来说所需特征较多,且使用工具抽取的特征中会包含错误信息,对分类器的性能造成不良影响。
如今,神经网络方法已经成为自然语言处理领域的一种主流方法。相较于传统方法,神经网络方法特征工程较少、分类准度高、效率高、可移植性强。Krause等[12]在KBP语料库中首先使用神经网络方法在事件同指消解任务上进行研究,先用卷积池化网络抽取事件句和触发词上下文的特征信息,然后引入事件对匹配特征来辅助判别事件对之间是否存在同指关系。Fang等[13]在KBP语料库中主要使用目前较为火热的注意力机制抽取事件句中的重要信息,并结合事件句之间的线性相似度与事件对匹配特征来判别事件对之间是否存在同指关系。程昊熠[14]使用CNN、Bi-LSTM和注意力机制多角度提取事件特征,在KBP语料上取得了很好的效果。Huang等[15]重点关注事件之间论元的兼容性,发现同指的事件对之间论元的兼容性更强。他首先使用未标注的语料学习事件之间论元的兼容性强弱,然后通过Bi-LSTM的基础模型判断事件之间的同指关系。Urbizu等[16]为了解决巴斯克语语料库规模较小的问题,引入了规模较大的英文语料库,通过跨语言词向量编码的方式扩大训练集的规模,在巴斯克语测试集上的实验结果显示,性能有略微的提升。在其他研究领域中,Ananya等[17]在关系识别任务中,利用单词的词性、依存路径、触发词上下文等信息,通过共享图卷积网络在单一语言的语料库中训练,在其余语言的语料库上进行测试。目前,跨语言方法还未在事件同指消解领域应用,本文在这方面进行了尝试。
2 基于中英跨语言数据增强的事件同指消解模型
为了解决ACE2005语料库规模较小和事件句中存在多个事件的问题,本文提出了一个基于中英跨语言数据增强的事件同指消解模型ECR_CDA。ECR_CDA主要使用机器翻译工具扩充语料库,利用事件触发词的依存词和论元来抽取事件实例短句,并结合事件实例短句间的线性与非线性相似度[18]和事件对特征来辅助判别两个事件句是否同指。该模型主要分为以下6个部分: ①使用Google机器翻译工具扩充语料库;②利用触发词的依存词和论元抽取事件实例短句;③引入词性信息和单词在句中距离触发词的相对位置信息,丰富事件句信息,并结合事件对特征辅助分类器;④对中英文事件句通过共享参数的方式进行跨语言学习;⑤通过激活函数后,将置信度大于0.5的分类作为同指关系;⑥利用事件链上事件之间的传递性设计了全局优化方法。其结构如图1所示。
2.1 数据增强
为了解决语料库规模较小导致神经网络模型无法充分学习的问题,使用机器翻译工具来扩充语料库规模。语料扩充流程如图2所示。
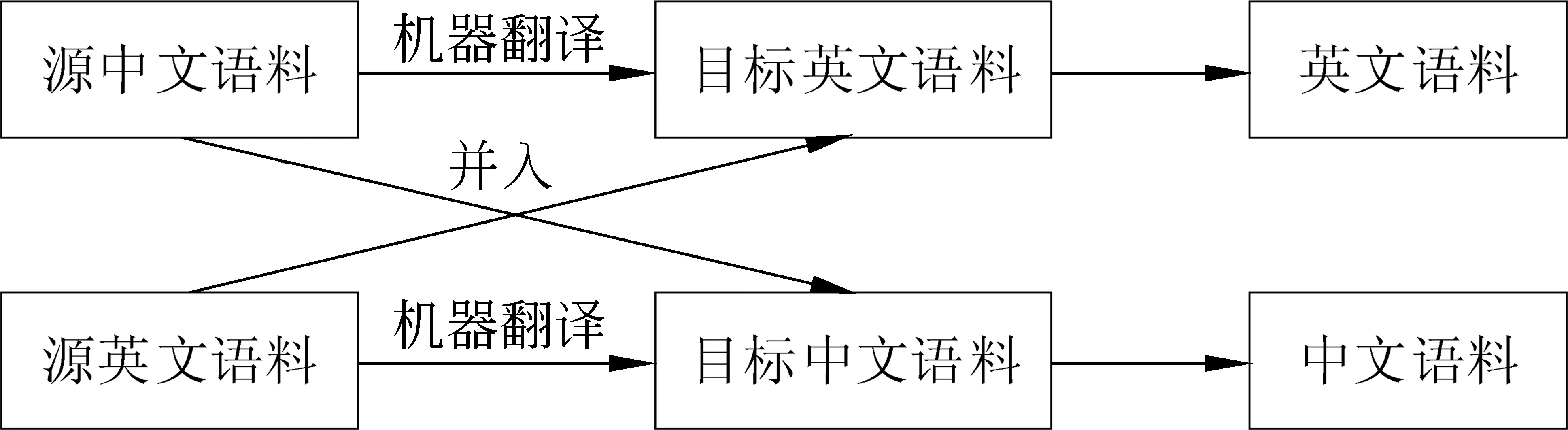
图2 语料扩充流程图
其中,将源中文语料翻译成目标英文语料,并入源英文语料生成英文语料。将源英文语料翻译成目标中文语料,并入源中文语料生成中文语料。触发词是事件同指消解任务中的关键,为了在目标语料中确定触发词的位置,在源语料中事先将触发词用“[]”标注起来。这样,在翻译好的目标语料中,“[]”所标注的词语就是触发词。由于事件匹配特征只需判断属性是否相同,因此事件属性不需要翻译。
2.2 事件实例短句抽取
在事件同指消解任务中所使用的公共语料都存在着一个事件句中存在多个触发词的问题,即句中存在多个事件。事件同指消解任务是判断两个事件之间的同指关系,而模型的输入是两个事件句。如果事件句中存在多个事件,那么无关事件会影响模型的判断。为了解决该问题,并希望用中文来明确英文单词的具体语义,本文设计了中文事件实例短句抽取方法。抽取流程如下:
(1)使用依存词分析工具得出每个词语的依存词。
(2)将触发词对应的依存词单独抽取出来,与论元放在一起,形成边界确定词语组。
(3)查询边界,确定词语组中词语在句中的位置,选取最左侧和最右侧的单词确定事件实例短句的起始与截止位置,从而抽取出该段事件实例短句。
例1: 刚刚宣誓就任的行政长官董建华也应邀参加成立典礼并且致词。
“就任”的边界确定词语组为“宣誓、董建华、应邀,刚刚宣誓就任的行政长官、行政长官”,“成立”的边界确定词语组为“典礼、参加、应邀”。“就任”的事件实例短句为“刚刚宣誓就任的行政长官董建华也应邀”,“成立”的事件实例短句为“应邀参加成立典礼”。可见,事件句中的两个事件就很好地被拆分开来,从而达到抽取出事件实例短句的目的。此外,在实验过程中也尝试计算英文事件实例短句间的相似度,也尝试通过共享参数的方式同时计算英文以及中文事件实例短句间的相似度,但三者之间的实验性能相当,最终选择使用中文事件实例短句。
2.3 输入层
事件中单词之间是相互独立的,为了弥补输入事件顺序结构信息的缺失,为每个单词赋予一个它们各自到触发词的距离作为其位置信息(Loc)。此外,单词的词性信息(POS)代表每个单词所扮演的语法角色,比如某个单词是主语或者形容词等。由于单词、词性信息和位置信息之间一一对应,因此将①事件句(Sen)、②事件句中每个单词的词性信息(POS)、③事件句中每个单词的位置信息(Loc)、④中文事件实例短句(OE)、⑤事件对匹配特征(P)作为输入。
此外,ACE 2005中、英文语料库均提供了事件类型及事件子类型、形态、极性、泛型、时态和触发词。本文利用这些标注信息组成事件对匹配特征: ①事件类型是否一致(type)、②事件子类型是否一致(sub)、③形态是否一致(mod)、④极性是否一致(pol)、⑤泛型是否一致(gen)、⑥时态是否一致(tense)、⑦触发词是否一致(trig)。
对于需要判别是否存在同指关系的事件句(文中的下标1和下标2属于目标英文语料中事件e1和e2的特征信息,下标3和下标4属于目标中文语料中事件e3和e4的特征信息,e1对应e3,e2对应e4),使用英文词向量矩阵得到英文事件句向量Sen1和Sen2,词性标注特征向量POS1、POS2、POS3和POS4,使用中文词向量矩阵得到中文事件句向量Sen3和Sen4,中文事件实例短句向量OE1和OE2。对于单词的位置信息,使用随机的词嵌入矩阵将它随机映射成100维的位置向量Loc1、Loc2、Loc3和Loc4。
首先,将事件句向量、词性向量和位置向量拼接在一起,形成新的事件句向量E1、E2、E3和E4。如式(1)所示。
Ei=Concat(Seni,POSi,Loci)i=1,2,3,4
(1)
将事件对匹配特征和两个事件句在文档内的距离dis融合成向量P,如式(2)所示。
P=Concat(type,sub,mod,pol,gen,tense,trig,dis)
(2)
2.4 跨语言学习模块
通过共享模型参数的方式实现中英跨语言学习,借助中文来解决英文单词中存在语义不明确的问题,使得模型从两种语言上学习到事件之间语义与结构的不同之处。
通过卷积神经网络挖掘出事件句中词与词之间的相互信息C1、C2、C3和C4,如式(3)所示。
Ci=Conv(Ei)i=1,2,3,4
(3)
在对事件句进行卷积操作时,使用Bi-LSTM神经网络获取单词的上下文信息,提取事件句的全局信息H1、H2、H3和H4,如式(4)所示。
(4)
注意力机制目前在自然语言处理领域十分火热,其作用有目共睹。通过给句中每个单词赋予权重,将事件句向量E1、E2、E3、E4和权重WE1、WE2、WE3、WE4做点积操作,可以使得事件句中每个单词的词向量间差异性扩大,从而获得事件句的重要信息A1、A2、A3和A4,如式(5)所示。
Ai=Ei⊙WEii=1,2,3,4
(5)
将互信息、全局信息和重要信息合并在一起,经过卷积池化层得到跨语言学习向量Q1、Q2、Q3和Q4,如式(6)所示。
Qi=ConvAndPool(Concat(Ci,Hi,Ai))i=1,2,3,4
(6)
此外,中文能帮助明确英文的具体语义,帮助模型从多种语言角度寻找出事件之间语义、结构的差异性。因此,本文通过计算两个中文事件实例短句之间的线性相似度与非线性相似度,来更加准确地得到英文事件之间的相似度。相似度计算方法如式(7)所示。
(7)
2.5 输出层
将跨语言学习向量Qi、线性相似度LS、非线性相似度NS和事件对特征向量P拼接在一起形成向量V,如式(8)所示。
V=Concat(Qi,LS,NS,P)i=1,2,3,4
(8)
V向量放入使用Relu激活函数的全连接分类器中,如式(9)所示。
Vh=α(Wh×V+b)
(9)
通过sigmoid层得出事件间的置信度,如果该值大于0.5,则该事件对是同指关系,否则不是同指关系。如式(10)所示。
score=sigmoid(W0×Vh+b0)
(10)
2.6 全局优化
由于事件链存在传递性,事件对之间的关系会相互冲突。例如,有两个同指事件对(ei,ej)和(ej,ek),如果ei和ej同指,ej和ek同指,那么ei和ek就应该同指。但是,模型可能会将ei和ek判定为非同指。为了解决该问题,ECR_CDA模型设计了一个全局优化方法,对事件链进行优化纠正,规则如下: ①如果ei、ej同指,ej、ek同指,则ei和ek同指;②如果ei、ej非同指,ej、ek非同指,则ei和ek非同指;③如果ei、ej同指,ej、ek非同指,则ei和ek非同指;4)如果ei、ej非同指,ej、ek同指,则ei和ek非同指。具体如式(11)所示。
(11)
3 实验
3.1 实验设置
本文使用Google机器翻译工具翻译ACE 2005中英文语料。由于ACE2005中文语料库中负例(非同指的事件对)太多,使得正负例比例严重失调。因此,剔除中文语料库中不含有同指事件对的文档和事件类型不相同的事件对。本文使用Links、MUC[19]、B3[20]和BLANC[21]四种评测方法来评估模型性能,并且报告以上四个指标的均值AVG。
在超参数的设置方面,中文词向量矩阵使用了维基百科的预训练向量,词向量的维度设为300,英文词向量矩阵使用了glove的预训练向量,词向量的维度设为300。为了防止过拟合,Dropout的值设为0.5。将Bi-LSTM神经元设置为50维,CNN神经元设置为100维。
3.2 实验结果
为了体现基于中英跨语言学习的神经网络模型ECR_CDA的优越性,本文使用了3个基准系统。
(1)Liu: Liu[8]在2014年使用传统分类器的方法做的实验;
(2)Krause: Krause[12]在2016年第一次使用神经网络的方法在ACE2005英文语料库上做的实验;
(3)Fang: 使用可分解注意力机制模型在ACE2005英文语料库上做的实验。
实验结果如表1所示。

表1 英文模型性能比较 (单位: %)
从表1可以看出:
(1)与Liu的传统分类器相比,ECR_CDA在4种评测指标上均大幅度超过了Liu。Liu的传统机器学习的方法使用了大量特征,这些使用工具抽取的特征往往会存在一些错误,积攒的错误特征就会使得分类器分类错误。而ECR_CDA这种神经网络方法只使用了少量的特征信息,就在性能上有提升,可以看出神经网络方法的确在某些方面大大优于传统机器学习方法。
(2)与Krause相比,ECR_CDA在4种评测指标上均大幅度超过了Krause。Krause首次使用神经网络方法在ACE2005英文语料库上进行了尝试,他在输入中将事件句和位置信息进行了融合,抽取了触发词前后各3个单词作为输入特征,然后使用CNN提取句内单词与单词之间的局部特征,位置信息的融入正好弥补了CNN忽视句内单词的顺序结构的缺点。但是,CNN只考虑了词与词之间的顺序关系,而判别一对事件句是否同指需要从事件句整体考虑,Krause恰恰忽略了这一问题。因此,ECR_CDA除了使用CNN提取局部特征,还使用Bi-LSTM提取单词的上下文信息,从事件句整体考虑二者的同指关系,ECR_CDA的结果说明了全局信息的重要性。
(3)与Fang相比,ECR_CDA在Links评测指标上提升了9.31%,在性能均值上提升了4.34%。Links是对模型判别的事件对结果进行评测,MUC、B3、BLANC则是评测事件链的结果。Links的大幅度提升表明ECR_CDA模型能较好地区分两个事件句之间的差异性,这是由于ECR_CDA中引入了中文事件实例短句的线性相似度与非线性相似度。该方法不仅最大程度上降低无关事件的影响,而且计算得到的事件句之间的差异性也可以帮助ECR_CDA来判别事件的同指关系。事件对评测指标的提升促进了事件链评测指标的提升,ECR_CDA相较于Fang在事件链上的评测指标均提升3%左右。Fang在输入过程中,将词性信息单独作为一个输入,并没有像ECR_CDA那样与事件句进行拼接。错误的词性信息会影响模型的判别,而词性和单词拼接在一起,会降低错误的词性信息的影响程度。此外,Fang主要依靠注意力机制来提取事件句的重要信息,而忽略了事件句本身的局部信息和全局信息。
3.3 实验分析
为了分析ECR_CDA中各个模块的作用性,设计了4个对比实验进行对比分析,具体如表2所示。其中,①OEM: 没有扩充语料库,没有使用中英跨语言学习方法,没有引入事件实例短句;②NE: 在OEM基础上引入事件实例短句的相似度计算;③OE: 扩充语料库,引入事件实例短句,没有使用中英跨语言学习方法;④ECR_CDA: 既使用中英跨语言学习方法扩充语料库,也引入事件实例短句。
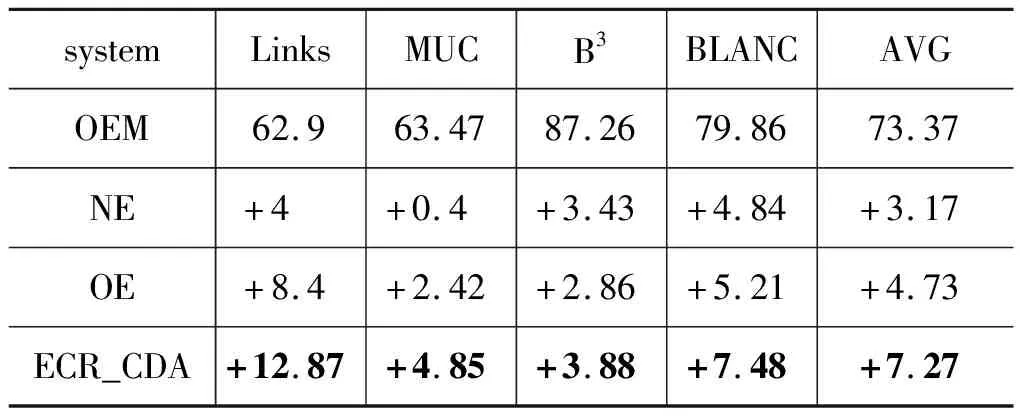
表2 英文对比实验
从表2可以看出:
(1)OEM没有扩充语料,没有使用跨语言方法,且没有引入事件实例短句。NE在OEM的基础上引入了事件实例短句,和OEM相比,在事件对性能Links、B3和BLANC上均提升4%左右,性能均值提升了3.17%。事件实例短句的引入可以消除多余无关词语的干扰,再辅以线性与非线性相似度的计算,均发挥了重要作用。此外,NE与Fang相比,Fang抽取触发词的前后三个单词形成事件短句,和本文抽取的事件实例短句类似。但Fang抽取的事件短句有很大的不稳定性,固定抽取触发词前后三个单词所形成的事件短句中结构信息、事件的论元信息会大大缺失,从而导致该短句是残缺的。而本文提出的事件实例短句抽取方法很好地解决了这一问题。
按照Fang抽取事件短句的方法,对例1中的触发词“就任”抽取的事件短句是: 刚刚宣誓就任的行政长官,触发词“成立”抽取的事件短句是: 也应邀参加成立典礼并且致词。结合例1抽取出来的事件实例短句来看,“就任”抽取的事件短句缺少了很重要的论元“董建华”,“成立”抽取的事件短句多了一个“致辞”,而“致辞”有潜力成为一个事件的触发词,会增加冗余信息。而按照本文提出的事件实例短句抽取方法却很好地解决了这些问题。
(2)OE系统进行了语料库的扩充,没有使用中英跨语言学习方法。性能均值和NE系统相比提升了1.56%。由此可见,语料库的扩充是有效的措施。ACE 2005中英文语料库的来源相同,引入源中文语料库的目标英文语料库可以增大源英文语料库的规模,较小的语料库规模会使得模型无法充分学习,容易出现过拟合的现象,增大语料库的规模恰恰解决了这一问题。事件对性能Links的提升可以看出ECR_CDA可以更好地识别出同指事件对。
(3)ECR_CDA系统既扩充了语料库,又进行中英跨语言学习,在英文语料库上进行了实验。相较于其余两个系统,ECR_CDA在四个评测指标上均有较大的提升。与OE相比,Links提升了4.47%,MUC、B3、BLANC均提升了2%左右,最终性能均值提升了2.54%。ECR_CDA与OE均扩充了语料库的规模,但ECR_CDA同时使用了中英跨语言学习的方法,Links的大幅度提升可以看出中英跨语言学习方法能够帮助模型更好地判定同指关系,Links的提升促进了事件链性能的提升。中文可以帮助明确英文单词的语义,在中英跨语言学习模块训练过程中,中文语义的明确可以从侧面帮助模型更好地学习到英文事件之间的相似与不同之处。同时,中文事件实例短句的相似度计算的引入,可进一步帮助模型对同指关系的判定,如例2所示。
例2: S1: I’m not saying take the threat offorce;S1的中文: 我不是说以武力相威胁;S1的中文事件实例短句:武力。
S2: I’m saying we don’t need to useforceright now;S2的中文: 我是说我们不需要立即使用武力;S2的中文事件实例短句: 我们不需要立即使用武力。
例2中,S1与S2是非同指关系。由于S1与S2的触发词都是“force”,都是否定句,二者的事件类型都是“Conflict”,事件子类型都是“Attack”,模型会将二者误判为同指关系。但引入中文和事件实例短句相似度计算后,由于S1中文与S2中文的相似度非常低,二者的结构信息不同,且中文事件实例短句之间的长度不同、相似度低,模型会将其纠正为非同指关系。中英跨语言学习与中文事件实例短句相似度计算的结合使用,可帮助纠正英文事件同指消解任务的错误判定。
此外,本文同时在ACE2005中文测试集上进行五倍交叉验证实验,使用MUC、B3、BLANC和CEAFe[22]四种评测方法,对四个系统进行对比分析。①Huan[23]: 使用门控注意力机制在ACE2005中文语料上做的实验;②Base: 没有扩充语料,也没有中英跨语言学习;③ECC: 仅仅扩充语料;④ECR_CDA: 扩充语料并做跨语言学习。中文对比实验结果如表3所示。
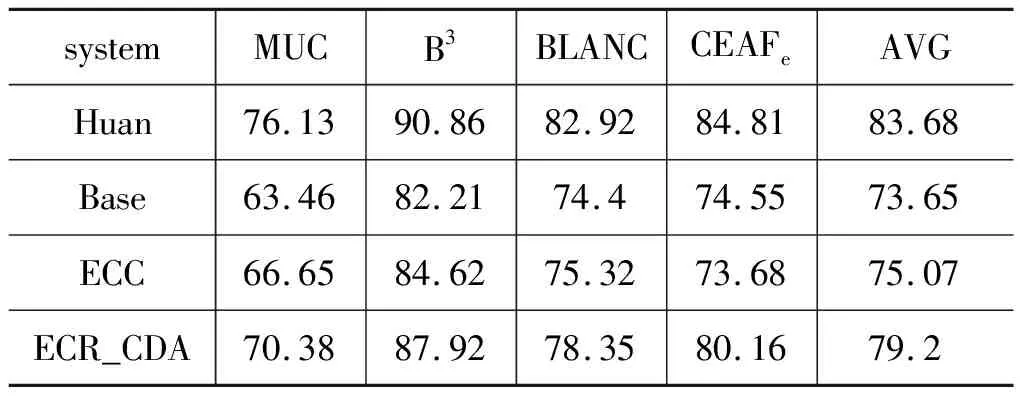
表3 中文对比实验
从表3可以看出: ①与Huan相比,ECR_CDA在各项指标上均有下降,存在以下原因: 中文十分复杂,翻译难度巨大。在将英文翻译成中文的过程中,Google翻译工具翻译得很直白,并没有考虑语言的先后顺序与结构信息,导致翻译的中文事件与英文事件原本的语义差距十分巨大,该现象在翻译长句的时候尤为明显。此外,英文中有许多人名、地名、机构名等缩写名称,这些名称在翻译过程中是个很大的障碍。错误的中文语义与结构信息的引入,给实验带来了很多噪声,严重影响了模型的训练学习。②相较于Base,ECC在四个评测指标上均有小幅度的提升,在性能均值上提升了1.42%。可以看出,适当地扩充语料库规模,可以使得神经网络模型学习得更加充分,从而提升分类准确度。③虽然ECR_CDA较于Huan性能有所下降,但与ECC相比在四个评测指标上均提升了5%左右,性能均值相较于ECC提升了4.13%。由此可见,中英跨语言学习的方法能够帮助模型从多种语言角度弥补各自语言的语义与结构的缺陷,但是还得密切关注引入的额外语料的质量问题,质量低下的语料的引入,会给实验带来噪声,效果往往会适得其反。
4 总结与展望
本文针对语料库规模较小导致模型容易过拟合的问题,使用机器翻译工具扩充语料库规模。针对事件句包含多个事件的问题,设计了事件实例短句抽取方法,依据触发词的依存词和论元抽取事件实例短句,设计了一种基于中英跨语言学习的神经网络模型结构ECR_CDA,使得中英文语义、结构之间相互补充学习,再计算中文事件实例短句之间的线性与非线性相似度来辅助判别同指关系。最后,使用全局优化方法来优化修正事件链。实验结果表明,该跨语言学习方法很好地提升了事件同指消解的性能,优于目前最好的基准系统。未来的工作重点是端到端事件同指消解。
