融合全局和局部信息的汉语宏观篇章结构识别
2022-04-19范亚鑫朱巧明褚晓敏李培峰
范亚鑫,蒋 峰,朱巧明,2,褚晓敏,李培峰,2
(1.苏州大学 计算机科学与技术学院,江苏 苏州 215006;2.苏州大学 人工智能研究院,江苏 苏州 215006)
0 引言
当前,自然语言处理的研究内容已经从词汇理解、句法分析等浅层语义分析领域延伸到深层语义理解的篇章分析领域。篇章分析是自然语言处理领域的重点和难点,其主要任务是从整体上分析一篇文章的逻辑结构和篇章单元之间的语义关系,进而从更深的层次挖掘自然语言文本的语义和结构信息。篇章分析有助于理解篇章的中心思想和主要内容,可以提升自然语言处理相关应用的性能,例如,问答系统[1]和自动文摘[2]等。
篇章分析的研究分析可分为微观和宏观两个层面。微观层面研究的是句子和句子、句群和句群之间的结构和关系;宏观层面研究的是段落和段落、章节和章节之间的结构和关系。当前篇章分析主要集中在微观层面,而宏观层面的研究较少。褚等[3]提出了一个宏观篇章结构表示体系。其中,以段落为基本篇章单元(Elementary Discourse Units,EDUs),相邻两个段落以篇章关系连接在一起,并构成更大的篇章单元(Discourse Units,DUs),这些篇章单元层层向上,最终将一篇文章构成一棵完整的篇章结构树。
汉语宏观篇章树库(Macro-level Chinese Discourse TreeBank, MCDTB)[4]对宏观篇章结构进行了标注。本文以MCDTB中的一篇文章(chtb_0282)来说明宏观篇章结构,如图1所示。

图1 chtb_0282内容
其中,p1介绍了推行公务员制度交流会的情况,p2补充了会议时间以及参会人员,p3讲述了李鹏总理肯定了推行公务员制度的成效,p4讲述了李鹏总理提出推行公务员制度要依法办事,p5补充其他参会人员。p2补充了p1描述的交流会的相关信息,因此p1与p2构成补充关系,p3和p4分别阐述了交流会的内容,因此构成了并列关系,其形成的篇章单元对上文(p1和p2构成的篇章单元)进行解说,形成解说关系,p5是对全文的补充,即对p1到p4的信息进行补充。
p1-p5构成的篇章结构树如图2所示。图中,叶子节点(p1-p5)为段落,即宏观篇章结构中的基本篇章单元(EDUs);相邻叶子节点通过篇章关系联系起来,通过连接后构成的节点是篇章单元(DUs),表示两个基本篇章单元之间的关系;箭头指向的是核心,即重要的篇章单元。具体而言,篇章单元之间通过篇章关系相连接,最终形成一棵完整的篇章结构树。本文研究的主要内容就是识别相邻篇章单元之间的结构,并层次化构建篇章结构树。

图2 宏观篇章结构树(chtb_0282)
在MCDTB语料库上,已有的篇章结构识别研究[5-6]都只考虑相邻两个篇章单元的语义关系,如果相邻两个篇章单元语义关系很接近,那么这两个篇章单元就会大概率以某种关系连接起来,形成一个更大的篇章单元,进而层次化地构建篇章结构树。但是这些研究都只考虑局部的上下文信息,而没有将整个文章的语义信息(全局信息)有效运用到篇章结构识别任务中。
在RST-DT[7]的篇章结构识别任务中,Lin等[8]提到,每次考虑相邻两个篇章单元容易受到局部信息的影响,而错误的相邻篇章结构判断会将错误的信息传播到上层,从而影响上层结构的识别。而van Dijk的宏观篇章结构理论[9]也指出,宏观结构是更高层次的结构,表现为篇章整体的语义连贯,每一层的宏观结构都是由下层结构支撑起来的。篇章的宏观语义信息(即全局信息)往往能体现篇章的展开结构,可用于检验一个篇章是否连贯。因此我们认为,在考虑局部信息的同时,全局信息也应该被考虑,用来辅助篇章结构的识别。
基于以往的研究都只考虑局部的上下文信息,且受到宏观篇章结构理论的启发,本文提出一种融合全局和局部信息的指针网络模型,用于自顶向下地识别篇章结构,并构建篇章结构树。在该模型中,我们采用交互注意力机制捕获相邻两个段落之间的语义联系,即局部信息;指针网络的编码层用来捕获整个篇章的语义,即全局信息;而指针网络的解码层用来融合全局和局部信息,为两个段落之间的语义分配一个概率,概率越大,表明这两个段落之间的语义联系越弱,因而需要进行篇章单元的切分。对切分形成的两个篇章单元,根据深度优先原则,递归地进行切分,从而自顶向下地构建完整的篇章结构树。在MCDTB上的实验结果表明,本文模型优于目前性能最好的模型。
1 相关工作
在已有的研究工作中,无论中文还是英文,都更注重微观篇章结构的分析,而对于宏观篇章结构的分析还处于起步阶段。涉及到宏观篇章结构的语料库主要有英文修辞结构篇章树库(RST Discourse Treebank,RST-DT)[7]和中文的汉语宏观篇章树库(MCDTB)[4]。现将两个语料和相关模型介绍如下:
修辞结构篇章树库(RST-DT)以修辞结构理论(RST)为理论依据,标注了385篇《华尔街日报》文章。在该语料库的研究中,Hugo等[10]提出了基于SVM的篇章分析器HILDA,该模型以贪心的方式自底向上构建篇章结构树;Shafiq等[11]等利用动态CRF模型分别构建了句子级别和篇章级别的分析器;Ji和Jacob[12]参考深度学习的做法,采用线性变换将表面特征转换成隐空间,通过移进规约进行篇章解析;Lin等[8]采用指针网络,构建了一个句子级的篇章解析器,但上述研究都是在微观层面。在宏观层面,Caroline和Alex[13]对RST-DT修正和裁剪后采用最大熵模型进行了宏观篇章结构识别。
汉语宏观篇章树库(MCDTB)遵循RST修辞结构理论,对720篇文章进行了宏观篇章信息的标注,包括篇章结构、主次和语义关系等。在MCDTB上进行篇章结构识别,构建完整篇章结构树的研究不多。Jiang等[5]采用序列标注的思想,提出一个基于条件随机场的模型(LD-CM)。该模型对结构和主次进行联合学习,从而自底向上的构建篇章结构树;Zhou等[6]提出了一个基于神经网络的模型(MVM)。该模型从多个角度匹配两个篇章单元之间的语义,从而识别篇章结构,并采用移进规约的方法构建篇章结构树。然而LD-CM是基于传统机器学习的方法,用到了较多的手工特征,考虑相邻两个篇章单元的语义联系;同样MVM也只考虑相邻两个篇章单元的语义联系。这两种方法都只考虑了局部的上下文信息,没有有效运用全局信息辅助篇章结构的识别。
2 PNGL模型
本文提出了一种融合全局和局部信息的指针网络(Pointer Network on Global and Local information,PUGL)的模型,自顶向下地识别汉语宏观篇章结构,其架构如图3所示。该架构包括三个部分: ①段落编码层(Paragraph Encoder Layer,PEL),用来捕获段落的语义表示;②段落交互层(Paragraph Interactive Layer,PIL),用来捕获相邻两个段落的语义联系,即局部信息;③指针网络(Pointer Network),指针网络的编码层用来捕获整个篇章的语义表示,即全局信息。解码层融合局部和全局信息,用来识别篇章结构,并自顶向下地构建篇章结构树。

图3 PNGL模型框架图
对于一篇文章P={p1,p2,…,pm},其中pi是段落词语序列,m是文章的段落数。将pi通过段落编码层(PEL),得到段落编码R={r1,r2,…,rm}。将相邻两个段落的编码通过段落交互层(PIL),得到表示相邻两个段落语义联系的表示H={h1,h2,…,hm-1},hi表示段落pi和pi+1之间的语义联系的紧密程度,即得到了局部信息。同时将ri平均池化之后通过指针网络编码层,指针网络编码层是双向GRU,最后一个时间步输出作为整个篇章的语义表示,即全局信息(例如,e5是段落p1到p5的全局信息,e3是段落p1到p3的全局信息)。
指针网络解码层是单向GRU,我们根据深度优先的原则,使用栈来生成篇章结构树。在第t步,栈顶的篇章单元DU(l,r)出栈。解码层的输入为篇章单元DU(l,r)的语义表示er,即编码层第r个段落的最后一个时间步的输出;解码层的输出为dt,dt和局部信息H进行交互,通过计算注意力来融合全局信息和局部信息,从而为每一个hi分配一个概率,其中l≤i≤r-1。概率越大,表示段落pi和pi+1之间的语义联系越松散,应该在pi和pi+1之间进行切分,形成新的篇章单元DU(l,i)和DU(i+1,r)。切分后段落数大于2的篇章单元入栈,递归地对栈顶篇章单元进行切分,直至栈空。根据切分得到的所有篇章单元构建篇章结构树。
2.1 段落编码层
段落编码层(PEL)用来对段落进行编码,获得段落的语义信息。目前大多数的工作都采用LSTM[14]对输入序列进行编码。LSTM虽然具备一定长序列建模能力,但是在处理宏观篇章单元的时候仍稍显不足。因为宏观篇章单元的最小颗粒度是段落,包含更多的词语,随着词数的增加,使得篇章单元内出现更复杂的词间依赖,而LSTM按照时序来处理文本,当相距很远的词语存在依赖关系时,LSTM很难捕获到这种关系。最近,通过注意力机制直接对输入序列进行编码[15]取得了不错的效果,其计算如式(1)所示。
(1)
在其编码的过程中,序列中的每一个词语都与序列中的其他词语进行匹配计算,因而更容易捕获长距离词语之间的依赖关系。本质上,注意力机制是对输入序列进行加权求和,因而比LSTM保留了更多的原始输入信息。而多头注意力机制允许模型在不同的表示子空间中学习到相关的信息,可以使得模型更好地捕获长远距离依赖关系。因此在PNGL模型中,我们采用多头注意力机制进行段落层编码,如式(2)所示。
(2)

(3)

2.2 段落交互层
段落交互层(PIL)用来捕获相邻两个段落之间的语义联系(局部信息)。一些研究人员通过注意力机制直接对序列之间的交互建模,并提出一些交互注意力机制。例如,Guo等[16]提出一种模拟双向阅读的交互注意力机制,他从人类阅读的角度出发,发现人类在判断两个序列之间的关系时往往需要来回阅读这两个序列,尤其是考虑两个序列中联系比较紧密的词之间的语义联系。受交互注意力机制工作的影响,徐等[17]采用式(1)对序列之间的交互进行建模,并在篇章关系识别任务中取得了不错的效果,因此我们利用多头交互注意力机制获得段落之间交互的语义联系。
对于两个段落p1={x1,x2,…,xm}和p2={x1,x2,…,xn},使用式(3)得到段落编码r1和r2,然后使用式(4)对段落之间的交互进行建模。
(4)
(5)
其中,Wh∈Rdm×3di是参数矩阵。
2.3 指针网络
序列到序列的模型[18]提供了输入序列和输出序列长度可以不同的灵活性,但是由于该模型仍然需要固定输出词表的大小,而输出词表的大小取决于输入序列的长度,从而限制了需要指向输入序列某个位置的问题的适用性。而指针网络[19]通过使用注意力作为一个指向机制解决了这个问题。具体说来,对于输入序列X={x1,x2,…,xn},首先经过编码层得到输出Y={y1,y2,…,yn}。在解码层的每一个时间步t,输出的状态dt会和序列Y进行交互来计算注意力,然后通过softmax层获得关于输入序列的概率分布。因此,在PNGL模型中,我们运用指针网络获得关于文章相邻两个段落之间的语义联系(H)的概率分布,进而确定文章的切分位置。
2.3.1 编码层

2.3.2 解码层
在解码层采用的是一个两层单向GRU。以chtb_0282为例,我们将编码层的输出E={e1,e2,e3,e4,e5}作为解码层的输入。在第t步解码时,篇章单元DU(l,r)出栈,解码层会综合当前篇章的全局信息er和t步之前生成的结构语义信息生成当前状态dt。dt和段落交互层的输出H={h1,hl+1,…,hr-1}进行交互,融合全局和局部信息,通过一个softmax层得到关于H的概率分布,如式(6)所示。
(6)
其中,σ(·,·)是融合全局和局部信息的函数,具体为点积运算;αt为关于H的概率分布。如果通过softmax层后hi被分配的概率值越大,表明段落pi和pi+1之间的语义联系越松散,因此更应该切分开,从而将整个篇章分为两个篇章单元DU(l,i)和DU(i+1,r)。根据深度优先的原则,每一步解码,段落数量大于等于2的篇章单元将继续入栈,递归地对篇章单元进行切分,直至栈空,过程如图4所示。

图4 解码过程
2.4 损失函数
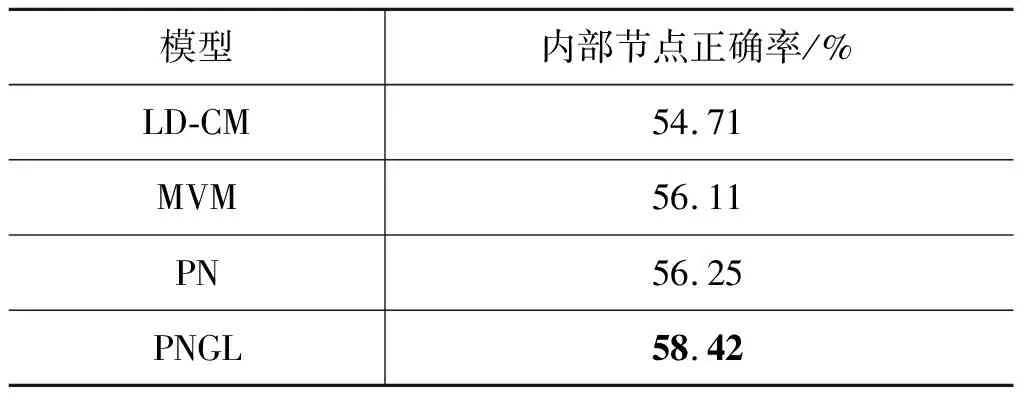
在PNGL模型中,损失函数我们采用负对数似然函数进行计算,如式(7)所示。y (7) 本文在汉语宏观篇章树库(MCDTB)上对模型结构识别的性能进行了评估。MCDTB定义了三大类十五小类篇章关系,并标注了摘要,段落中心句、篇章结构等宏观篇章信息。MCDTB总计有720篇新闻报道的文章,每篇文章的段落数从2到22不等,段落分布如表1所示。 表1 段落分布 我们使用Jiang[5]遵循段落分布划分好的数据集进行试验,其中训练集576篇,测试集144篇。为了与Zhou[6]的实验设置一致,我们将所有的非二叉树都转换为右二叉树。另外,我们遵循Mathieu[22]对RST-DT上篇章结构分析模型的评价标准,同样采用内部节点正确率(等价于micro-F1)来衡量模型性能。我们将词向量维度设置为300,采用Word2Vec[23]进行预训练。段落编码层和段落交互层转换矩阵映射的维度dm和di都被设置为512;段落编码层多头注意力机制中头数h设置为8,其中,dk=dv=dm/h=64;训练过程中batch大小设置为32,dropout率设置为0.5。 本文将文中提出的模型PNGL和基准系统进行了对比,基准系统分为两种:①只考虑局部信息; ②只考虑全局信息。基准系统介绍如下: LD-CM[5]:性能最好的传统模型,只考虑局部信息。该模型采用条件随机场,运用较多的人工特征,考虑相邻两个篇章单元能否合并,贪婪地自底向上识别篇章结构,从而构建篇章结构树。 MVM[6]:性能最好的神经网络模型,只考虑局部信息。该模型从词、局部上下文以及话题这三个角度出发,提出了词对相似度机制来衡量相邻两个篇章单元的语义,并采用移进规约的方法每次考虑相邻两个篇章单元能否合并,从左到右识别篇章结构,从而构建篇章结构树。 PN[8]:我们复现了在RST-DT上表现优异的结构识别模型PN,只考虑全局信息。该模型是一个指针网络,在编码层使用双向GRU对整个文章进行编码,解码层使用单向GRU进行解码,自顶向下地识别篇章结构,构建篇章结构树。 实验结果如表2所示。PNGL模型比仅考虑局部信息的LD-CM模型性能提升了3.71%,比仅考虑局部信息的MVM模型(目前在MCDTB上最好的结构识别模型)性能提升了2.31%,比仅考虑全局信息的PN模型性能提升了2.17%。宏观篇章结构理论[9]指出文章会有一个总摄全篇的主题,并层层分解,由下层命题展开。这说明段落或篇章单元之间的关系并非很松散,都是在对主题进行分层面的展开叙述。 表2 模型在MCDTB上的性能比较 而LD-CM和MVM都仅考虑相邻两个篇章单元联系的紧密程度,但是这两个篇章单元是围绕共同的主题展开的,如果仅仅考虑两个篇章单元之间的联系,模型往往会偏向于将这两个篇章单元合并成更大的篇章单元。而PN模型通过考虑整个篇章单元的语义信息,将篇章单元切分成两个较小的篇章单元。PN模型会对所有可能形成的两个较小篇章单元语义联系的紧密程度进行排序,取语义联系最松散的两个较小篇章单元作为切分结果。但是每个篇章单元往往包含较复杂的段落语义信息,仅仅考虑全局信息,模型很难对两个较小篇章单元之间的语义联系的紧密程度进行正确的排序。 我们的模型PNGL通过改进段落的语义编码,在指针网络编码层学习到更好的全局信息的同时,又考虑相邻两个段落之间语义联系的紧密程度,从而在性能上有所提升,这说明综合考虑全局和局部信息对于识别篇章结构并构建篇章结构树非常有效。 以往的研究表明[8],采用基于转移的方法进行结构识别,往往对于底层的识别能力较好,而对于上层的识别能力较差。主要原因是每一步的识别都只考虑局部信息,这会将错误传播到后续步骤,导致上层的结构识别能力较差。 为了研究局部信息和全局信息分别对底层和顶层结构识别的影响,我们在PNGL模型的基础之上去掉段落交互层,即只考虑全局信息,得到模型PNGL(-local)。我们对只考虑局部信息最好的模型MVM以及只考虑全局信息最好的模型PNGL(-local)在最底下两层内部节点正确率和最顶上三层内部节点正确率(1)由于最顶层的根节点所表示的结构总是固定的,因此我们考虑最顶上三层和最底下两层内部节点正确率来表示模型对于顶层和底层结构识别的性能好坏。进行统计分析,结果如表3所示。 由表3的实验结果可知,相比于只考虑全局信息的模型,MVM在最底下两层节点正确率更高,这说明考虑局部信息对于底层结构识别有帮助。 表3 局部和全局信息分别对底层和顶层结构识别的影响 PNGL(-local)模型在最上三层的节点正确率要高于MVM,说明相比于考虑局部信息的模型,只考虑全局信息对上层结构识别有帮助。因此我们认为在全局信息的基础上加入局部信息可以增强模型对于底层节点的识别能力。 为了研究在全局信息的基础之上融合局部信息对于结构识别的影响,我们在模型PN的基础之上,加入段落交互层,综合考虑全局和局部信息,得到模型PN(+local);而PN和PNGL(-local)都是只考虑全局信息的指针网络模型,它们的区别在于PN采用双向GRU对段落进行编码,而PNGL(-local)采用多头注意力机制对段落进行编码。我们统计了内部节点正确率以及最底下两层内部节点正确率,如表4所示。 表4 加入局部信息后模型识别性能比较 表4实验结果表明,在加入局部信息之后,PN(+local)和PNGL的最底下两层内部节点正确率分别提高了0.61%和5.8%。PNGL相较于PN(+local),性能有明显提升,其原因在于PN(+local)是直接使用双向GRU对段落进行编码,由于多头注意力机制相较于双向GRU更容易捕获长距离单词之间的依赖关系,能保留更多的原始信息,对段落的编码更有效。因此将相邻两个段落的编码输入到段落交互层进行交互,段落交互层就能更好地捕获段落之间的语义联系。通过捕获到更好的局部信息,模型PNGL增强了对底层结构的识别能力,从而从整体上提高模型的性能。 为了比较模型对于长文和短文的识别能力,本文分别统计了长文和短文内部节点正确率,结果如表5所示。从表中数据可知,模型对短文结构的识别性能较好,而对长文结构的识别性能较差。主要原因在于无论采用什么方法构建篇章结构树,都会产生级联错误,而对长文来说,则更加明显。但和只考虑局部信息的模型以及只考虑全局信息的模型相比,模型PNGL综合考虑全局和局部信息,对短文和长文的结构识别性能都有提升。 表5 模型对长短文结构识别性能比较 图5从左到右展示了只考虑局部信息、只考虑全局信息以及考虑全局和局部信息的模型对chtb_0756(文章内容及标准结构树见附录A)的预测结果。MVM应用栈和队列,采用移进规约的方法,考虑栈顶的篇章单元和队首的段落能否合并成一个更大的篇章单元,如果可以合并则采取规约操作,否则采取移进操作。由于MVM只考虑局部信息,在从左到右进行结构识别的时候,未能识别出相邻两个段落之间是否要合并成一个大的篇章单元,因此采用了一系列的移进操作,当队列中为空之后,又采取一系列的规约操作,最终形成如图5左图所示的结构树。 图5 不同模型构建的文章chtb 0756的篇章结构树 PNGL(-local)采用栈数据结构,通过自顶向下的方法递归确定文章的切分位置,从而形成结构树。PNGL(-local)首先会对DU(1,1)和DU(2,5)、DU(1,2)和DU(3,5)、DU(1,3)和DU(4,5)、DU(1,4)和DU(5,5)这四个语义联系的紧密程度进行排序,确定DU(1,4)和DU(5,5)之间的语义联系最松散,然后递归地对DU(1,4)进行以上过程,确定DU(1,2)和DU(3,4)之间的语义联系最松散,最终形成如图5中间图所示的结构树。但由于篇章单元中往往有多个段落,包含的语义信息比较复杂,如果只考虑全局信息,会使得模型很难对相邻篇章单元之间联系的紧密程度进行正确排序。而我们的模型PNGL通过加入相邻两个段落之间的语义联系(局部信息),考虑到了篇章单元边界的信息,从而提升了模型结构识别的能力。 本文针对汉语宏观篇章结构识别任务,提出了一种融合全局和局部信息的指针网络模型PNGL,用于自顶向下地识别篇章结构,构建篇章结构树。其中,段落编码层采用多头注意力机制,可以有效地捕获词语之间的长距离依赖;段落交互层通过多头注意力交互机制捕获段落和段落之间的语义联系,即局部信息;指针网络的编码层用来捕获全局信息,解码层会融合全局和局部信息进行解码,自顶向下地识别篇章结构,构建篇章结构树。在MCDTB上的实验结果表明,我们的模型PNGL比传统机器学习的方法LD-CM性能提高了3.71%,比目前最好的模型MVM性能提高了2.31%,证明了融合全局和局部信息在篇章结构识别任务中的有效性。由于模型识别短文的性能比较好,因此在下一步工作中,我们将融入话题分割的思想,尝试将长文划分成短文本,从而提高长文的结构识别性能。3 实验
3.1 实验设置

3.2 实验结果
4 实验分析
4.1 全局和局部信息的影响


4.2 模型对长短文识别性能比较

4.3 不同模型结构识别的比较

5 总结
