基于注意力机制与特征融合的课堂抬头率检测算法
2022-04-18桑庆兵
倪 童,桑庆兵
(江南大学人工智能与计算机学院,江苏无锡 214122)
0 概述
近年来,我国大力推进教育信息化[1],提出以信息技术为支撑,提升教学管理水平的方案。基于此,高校不断完善信息化基础设施建设,视频监控、投影仪、电脑等技术设备被广泛应用于教学场景中。随着人工智能等新兴技术的兴起,有研究人员提出智慧校园[2]的概念,出现了计算机视觉和教育领域相结合的新局面。由基于人脸检测[3-5]实现的课堂考勤[6-7]以及基于行为识别等相关技术实现的动作识别[8-10]已初见成效,抬头率作为衡量课堂听课专注度的重要指标,已逐渐进入研究人员的视野。
目前检测抬头率的方法主要有两种:一是基于人脸检测获取人脸的位置,并通过分类器对获取的人脸信息进行分类以得到头部状态[11];二是基于人脸姿态估计[12]获得面部朝向的角度信息,通过角度反应学生头部状态。上述两种方法均基于人脸进行,因此依赖于人脸获取的情况,但在真实的课堂场景下,由于受光照、监控设备清晰度等各类因素影响,要获得完整清晰的人脸有一定难度,因此基于人脸的方法具有一定局限性。
得益于深度学习的发展,使用深度学习的检测方法[13-15]越来越多,REN 等[16]提出Faster R-CNN 算法,利用RPN 网络并基于Anchor 机制来生成候选框,进一步提升检测精度和检测效率。文献[17]提出YOLOv3 算法,使用3 个尺度的特征图提升小目标的检测效果。但在课堂视频中,人物相对复杂,特征提取较困难,且当学生出现遮挡时,容易出现遗漏目标的情况。
本文引入视觉特征RGB difference,将其与原图提取后的特征相融合,并使用改进的注意力模型(Improved Convolutional Block Attention Module,ICBAM)构建新的特征提取网络。此外,通过设计精炼模块对检测结果进行优化,以提高抬头率检测的准确性。
1 抬头率检测算法
基于注意力机制和特征融合的抬头率检测算法结构如图1 所示。对于一段完整的课堂视频,将其逐帧拆分并作为网络的输入,同时引入RGB difference 视觉特征作为网络的另一支输入,可视化结果如图2 所示(彩色效果见《计算机工程》官网HTML 版),从人眼的角度容易看出其中人物的轮廓。之所以选择引入RGB difference,是因为课堂的监控设备是固定视角,RGB difference 能够弱化背景等静物,保持网络对人物这一动态目标的关注度。原图和RGB difference 被输入加载了ICBAM 的特征提取网络,得到2 个尺寸相同的Feature Map:Fi和Fr,Fi和Fr进行elementwise 加和得到最终的融合 特征图。以融合特征提取网络为backbone,使用YOLOv3 进行头部检测。与人脸相比,头部包含更丰富的视觉信息,且受遮挡等因素的影响更小,对抬头率检测具有重要作用。在获得头部边界框集合后,通过精炼模块对结果进一步优化。

图1 基于注意力机制和特征融合的抬头率检测算法结构Fig.1 Structure of head up rate detection algorithm based on attention mechanism and feature fusion

图2 RGB difference 特征Fig.2 RGB difference feature
1.1 改进的注意力模块
注意力机制从模拟生物学的角度出发,使神经网络具备专注于其输入或特征子集的能力。文献[18]提出卷积块注意力模块(Convolutional Block Attention Module,CBAM),其结构如图3 所示。CBAM 通过通道注意力模块和空间注意力模块依次对输入特征进行处理,并获得精炼特征。在课堂视频中,教室背景和物品并非关注的目标,因此在网络中添加注意力模型能够提升提取有效特征的能力。由于CBAM 使用串型结构,因此空间注意力模块对特征的解释能力在一定程度上依赖通道注意力的输出。此外,CBAM 在通道注意力模块和空间注意力模块的前端均使用MaxPool 和AvgPool,这会损失图像部件之间精确的空间相对关系。基于上述问题,本文提出ICBAM 模型,其结构如图4 所示。

图3 CBAM 模型的结构Fig.3 Structure of CBAM model
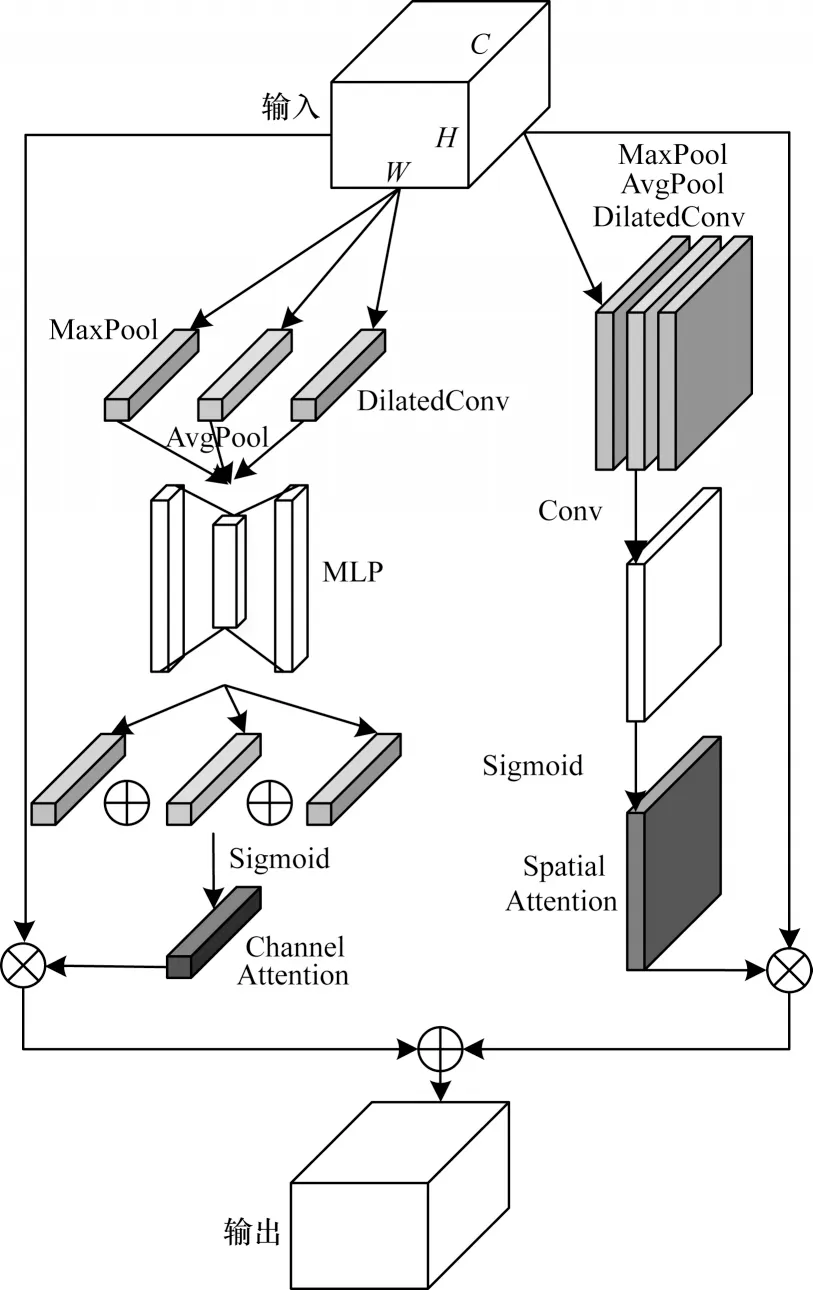
图4 ICBAM 模型的结构Fig.4 Structure of ICBAM model
为避免空间注意力模块对通道注意力模块的依赖,ICBAM 模型使用双流结构。且在网络之后,将通道注意力模块输出的Mc(F)和空间注意力模块输出 的Ms(F) 分别与输入特征图F∈RH×W×C进 行elementwise 乘法操作,得到2 个特征图Fc和Fs,Fc和Fs进行elementwise 加和后得到最终输出特征图Fout,计算公式分别如下所示:

为获取通道注意力模块的输出Mc(F),输入特征图F∈RH×W×C分别在H和W2 个维度做global max pooling 和global average pooling,同时在H和W维度上做膨胀系数r=2,filter_num=C的W×H空洞卷积,这里加入空洞卷积是因为输入特征为粗粒度特征,包含丰富的原始信息,使用空洞卷积可以扩大感受野,过滤冗余特征。空洞卷积的本质是一般卷积的延伸,其输出y[i]可以表示为:
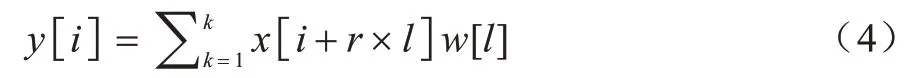
其中:x[·]表示一维输入信号;w[l]为卷积核;l为卷积核大小;r为膨胀系数。
二维空洞卷积的示意图如图5 所示。输入特征经过global max pooling、global avreage pooling 和空洞卷积得到3 个1×1×C的特征图,并将其输入共享权重的多层感知机[19],分别得到映射特征图。

图5 不同膨胀系数的空洞卷积示意图Fig.5 Schematic diagram of cavity convolution with different expansion coefficients
将3 个特征图进行elementwise 加和并用sigmoid函数激活后得到通道注意力模块输出Mc(F)。Mc(F)的计算公式如式(5)所示:

其 中:W0∈RC/r×C;W1∈RC×C/r;C/r为MLP 隐层神经元个数;C为输出层神经元个数。
为获取空间注意力模块的输出Ms(F),输入特征图F∈RH×W×C并在通道维度做global max pooling和global average pooling,随后在W和H维度做空洞卷积。参数设置:膨胀系数r=2;filter_num=1;zero_padding=2;size=3×3。3 个输出特征和在通道维度上concat成一个维度为W×H×3的特征图,然后通过卷积层和sigmoid 函数激活得到最终空间注意力模块Ms(F)。Ms(F)的计算公式如下:
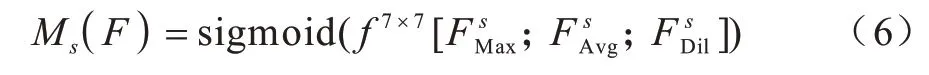
其中:f7×7表示卷积核尺寸为7×7 的卷积层。
与CBAM 模型相比,ICBAM 模型使用了双流结构,剥离了空间注意力模块对通道注意力模块的直接依赖,使两者获得了相同的权重。此外,在2 个注意力模块中加入的空洞卷积扩大了感受野,能够过滤冗余特征。
1.2 精炼模块
精炼模块用于进一步优化检测网络,其主要包括特殊帧判定和相邻帧信息融合两部分。
1.2.1 特殊帧判定
由于视频包含一些抬头和低头姿态切换瞬间的特殊帧,模型在预测时容易将一个目标预测为2 个不同目标,如图6 所示。图6 中叠加的2 个边界框属于特殊叠加,无法在预测时通过非极大值抑制[20]等常规过滤方法解决,因为叠加的2 个边界框置信度相当,模型判定这是2 个不同的目标。为保证后续抬头率计算的精确度,需对头部检测后的基础边界框进行精炼。

图6 边界框叠加Fig.6 Boundary box overlay
特殊叠加的2 个边界框具有位置相近、大小相当、状态分类相反和置信度相当的特点,基于以上特点设计算法,算法流程如图7 所示。

图7 特殊帧判定流程Fig.7 Procedure of special frame determination
算法的具体步骤如下:
步骤1同一帧内,对每一个检测到的头部边界框,搜寻是否存在与其叠加的边界框,若未搜寻到则算法结束;
步骤2判断叠加的2 个边界框是否具有特殊叠加的特点,若满足则为特殊叠加,若不满足则算法结束;
步骤3删除两者中置信度较小的边界框。
1.2.2 相邻帧信息融合
到目前为止,每一帧分析相互独立,结果单一依赖检测神经网络的结果,这容易造成多目标检测不全面的问题。为此,所提模块利用视频时序信息,对相邻两帧头部边界框进行融合,使视频序列构成链式结构。算法流程如图8 所示。

图8 相邻帧信息融合流程Fig.8 Procedure of adjacent frame information fusion
具体如算法1 所示:
算法1相邻帧信息融合

其中:pi表示上一帧第i个头部边界框;ni表示当前帧第i个头部边界框;max_IOU 表示pi与N中所有边界框的最大交并比。
2 实验
2.1 数据集
由于目前在抬头率检测领域没有相关的公开数据集,因此采集课堂视频数据并进行人工标注,自建抬头率检测数据集RDS。RDS 数据集共包含378 个课堂视频片段,每段视频时长10 s 左右。除了对每段视频的抬头率标注外,还以从每20 帧中抽取一帧的方式进行头部边界框标注,标注原则为上至头部顶端,下至下颚,左右至双耳。视频采集摄像机型号为海康威视DS-2CD3321FD-IW1-T,架设位置为讲台上方1 m 处,固定斜向下正面视角。截取视频部分帧作为数据样例,如图9 所示。

图9 RDS 数据样例Fig.9 RDS data sample
2.2 实验环境及参数
硬件环境:Intel Core I5 处理器;NVIDIA GEFORCEE GTX 860 显卡;16 GB 内存。软件环境:anaconda python3.7.1;JetBrains PyCharm Community Edition 2019.1.2 x64,tensorflow1.13.1,opencv,numpy1.12,easydict等。参数说明:本文使用的IOU 阈值为0.5,置信度阈值为0.8,膨胀系数为2,训练初始学习率为1×10-4,结尾学习率为1×10-6,batch size 为8。
2.3 评价指标
为衡量算法输出的准确性,采用平均抬头率误差(mRR Error)作为评价指标。平均抬头率误差是指算法的所有输出抬头率与真实抬头率之差的平均绝对值,该指标能反映算法的输出结果与实际值之间的偏差,mRR Error 越小代表算法的准确性越好。mRR Error 的定义如下:

其中:n表示测试集包含视频总数;Ri表示第i个视频的算法输出抬头率;Ti表示第i个视频的实际抬头率;m为视频包含帧数;rk表示视频第k帧抬头人数;tk表示视频第k帧总人数。
2.4 实验与结果分析
2.4.1 消融实验
为验证RGB difference 特征、ICBAM 和精炼模块对模型性能的影响,对加载上述部件前后的模型进行实验对比,结果如表1 所示,其中“√”表示加载此部件,“—”表示不加载此部件。

表1 不同部件对模型性能的影响Table 1 Influence of different components on model performance %
由表1 可知,RGB difference 特征、ICBAM 和精炼模块对模型性能的提升均有不同程度的促进作用,其中处于较高层次的精炼模块对性能的影响较大,当加载所有部件时,模型性能取得最优。
图10 为训练过程中mRR Error 随着迭代次数变化的曲线图,从中可以看出加载了所有部件的模型相比基础模型的mRR Eerror 更低,效果更好。

图10 mRR Error 随迭代次数变化的曲线Fig.10 Curve of MRR error with the number of iterations
2.4.2 ICBAM 和CBAM 模型的对比实验
本文在CBAM 模型的基础上改进提出ICBAM模型,为比较两者的效果,在其他部件保持一致的条件下进行CBAM 和ICBAM 的对比实验,实验结果表明,加载CBAM 模型的mRR Error 为15.981,加载ICBAM 模型的mRR Error 为15.648,经过改进的ICBAM 的mRR Error 比CBAM 更低。
2.4.3 ICBAM 加载位置对mRR Error 的影响
为比较ICBAM 不同加载位置对mRR Error 的影响,设计3 组不同的位置方案并进行对比:1)仅加载至特征提取网络前端;2)仅加载至后端;3)前端+后端,实验结果如表2 所示。由表2 可知,在特征提取网络前端和后端分别加载ICBAM 的效果最好,且前端部分影响较大,这说明ICBAM 对浅层特征的提取效果更好。

表2 ICBAM 加载位置对性能影响Table 2 Effect of ICBAM loading position on performance %
2.4.4 空洞卷积参数对性能的影响
空洞卷积参数主要是指膨胀系数,实验对使用不同膨胀系数的空洞卷积效果进行对比,结果如表3所示。其中膨胀系数为2 的空洞卷积效果较好,原因可能是膨胀系数较小时,保留的原始信息更完整,进而导致mRR Error 更低。

表3 不同膨胀系数对性能影响Table 3 Effect of different expansion coefficient on Performance %
2.4.5 不同抬头率检测算法对比
表4为注意力和特征融合抬头率检测算法与其他抬头率检测算法在RDS 数据集上的性能对比。运算时间为检测一段帧率为20 frame/s 的10 s 视频片段所用时间。虽然本文所提算法是基于深度学习的方法,在速度上稍慢,但是在准确度上取得了不错的表现。
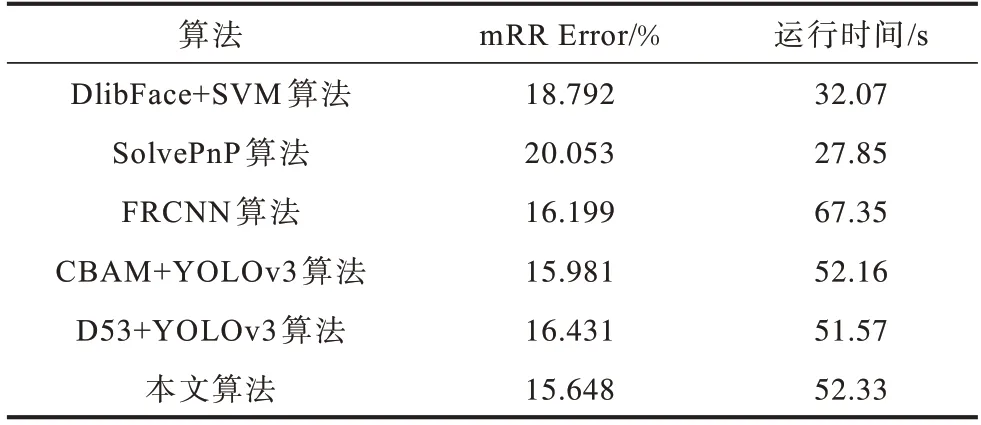
表4 RDS 数据集上不同抬头率检测算法性能对比Table 4 Performance comparison of different head up rate detection algorithms on RDS datasets
本文算法和CBAM+YOLOv3、D53+YOLOv3 均是基于YOLOv3 的算法,因此在检测部分的计算量一致。之所以本文算法相较于这3 种算法较慢有2 个主要原因:1)在特征提取网络中这2 种算法均仅使用原图作为输入,本文算法在逐帧提取特征的同时还需计算并生成每一帧对应的RGB difference 特征,且双流结构的特征提取网络需要更高的计算量;2)本文算法相较于以上2 种算法额外设计了2 个精炼模块以提升检测结果的准确性,因此增加了检测时间。
3 软件实现
在注意力和特征融合的抬头率检测算法的基础上,基于PyQt5+TensorFlow1.13 框架构建课堂行为分析软件。软件主要实现课堂到课人数、课堂抬头率和个人抬头率3 个计算需求,共包含3 个页面:首页(主界面),视频页和分析结果页。
1)首页:用户进入系统后通过首页选择待分析的视频文件,确认分析后等待视频分析完成即可向其他界面查询分析结果。首页仅保留了视频选择和视频分析2 个功能,配置参数及选项均向用户隐藏,有助于提升系统的易用性。分析软件主界面如图11 所示。
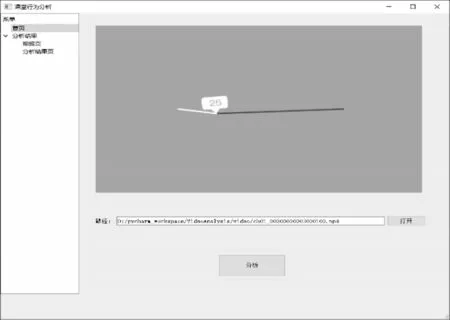
图11 软件主界面Fig.11 Software main interface
2)视频页:视频页以播放器的形式向用户展示分析完成的视频数据,能直观反映分析结果,视频的每一帧会以黄色的矩形框标注低头的学生(彩色效果见《计算机工程》官网HTML 版),以绿色的矩形框标注抬头的学生,矩形框上方的数字表示该学生从视频开始到现在的个人抬头率。视频页支持视频导出功能,界面如图12 所示。

图12 视频页Fig.12 Video page
3)分析结果页:分析结果页展示文本及图表形式的分析结果,包括到课人数、课堂专注度、平均抬头率以及总体抬头率变化折线图,有助于反映课堂的听课情况,若平均抬头率低于50%,则会反馈课堂专注度低,并对课堂专注度和平均抬头率标红(彩色效果见《计算机工程》官网HTML 版),界面如图13 所示。
4 结束语
为提升课堂监督管理质量,本文提出一种结合注意力机制和特征融合的课堂抬头率检测算法。使用RGB difference 视觉特征获得信息更为丰富的深层融合特征,并构建一种改进的注意力模型ICBAM加载至特征提取网络上,提升网络的特征提取能力。此外,在ICBAM 中引入空洞卷积过滤冗余特征,通过设计精炼模块对预测结果进行优化,并在所提算法的基础上设计完成课堂行为分析软件。实验结果表明,本文算法在抬头率检测数据集RDS 上的平均抬头率误差为15.648%,相比于SolvePnP 等主流检测算法具有更低的误差率。下一步将通过提高模型的运行速度,拓展分析软件可以识别的行为种类,从而优化软件的界面设计,以获得更大的应用价值。
