基于多维特征图知识蒸馏的对抗样本防御方法
2022-04-18邱宝琳易平
邱宝琳,易平
(上海交通大学网络空间安全学院,上海 200240)
0 引言
在计算机视觉方面,尤其是目标识别、无人驾驶等高精度任务下,深度学习提供了强大的算法支持。但是,此类算法的决策存有风险性。Szegedy等[1]发现,攻击者可以根据神经网络模型参数,构造添加了微小扰动的图像。这类图像被称为对抗样本,该图像虽然不会影响到人类的视觉判断,但会改变模型分类结果。例如,在Xu等[2]的工作中,他们仅穿上了一件添加扰动特征图像的衣服,即可蒙骗目标识别网络,顺利在摄像头下“消失”。
对抗样本在计算机视觉领域产生了深远影响,是该领域安全方向的关注重点。主流方法是通过对抗训练提高模型的防御能力。对抗训练基于模拟攻防的思想,针对目标模型生成对抗样本,再使用生成的样本训练神经网络,重复多次后获取稳定的防御模型。但是,主流的神经网络模型结构极为复杂,如ResNet[3]和GoogleNet[4],其具有规模庞大的参数、神经层结构。每次对抗训练都需要极大的算力支持,限制了对抗训练在低算力设备上的应用。所以研究人员期望利用已训练模型,将防御经验泛化到新的视觉任务中,减少对抗训练带来的高算力需求。
知识蒸馏[5]是一种经验迁移方式,可以将教师网络预训练得到的经验有效迁移到学生网络中。整个知识蒸馏过程中学生网络会调整参数,模拟教师的输出,从而达到经验转迁的效果。传统知识蒸馏通过训练,使小型网络在同任务下拥有原大型网络相近的决策能力。
本文基于上述研究工作,提出了一种优化的知识蒸馏算法,该算法将教师网络学习到的鲁棒性经验迁移到新的任务中。算法针对特征图和频域等维度进行改造,并基于类激活映射[6]提出注意力机制,加强关注蒸馏的重要特征,提高模型的防御效果。此外,对抗训练会导致模型在干净样本的准确率有所下降,但通过本文所提算法得到的学生网络,在保持较高鲁棒性的基础上,对干净样本的检测效果显著高于对抗训练,甚至可以媲美仅使用正常样本的无扰动训练。
本文的主要贡献如下。
1) 提出了一种轻量级的对抗样本防御方法。通过知识蒸馏算法,已有鲁棒性特征可以泛化到其他数据集的任务中,无须在新的数据集上重新对抗训练即有不错的防御效果。
2) 利用多维度的特征图优化蒸馏过程,增强防御效果,并提出一种注意力机制,为特征图向量细粒度配比权重,提高泛化能力。
3) 基于方案设计了实验并生成多组对照基线,验证了本文方案的有效性。
1 相关工作
文献[7-8]对对抗样本进行了一些研究,下面介绍常用对抗样本生成方法以及主流的防御方式,并阐述知识蒸馏和类激活映射等相关工作。
1.1 对抗样本生成方法
对抗样本属于图像分类任务中的逃逸攻击(evasion attack)。攻击者通过模型的可微损失函数,精心构造微小扰动,影响分类模型的准确率,主要目标为
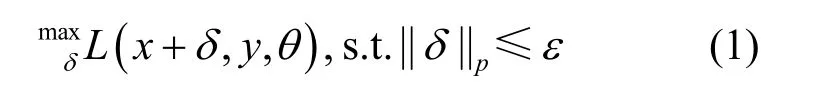
其中,x为图像输入,y为图像x的对应类别标签,θ为模型参数变量,δ为攻击者添加的扰动,L(⋅)为分类器的损失函数,多标签分类任务通常使用交叉熵损失(cross-entropy loss)。‖·‖p为lp范数。优化目标为扰动幅度限制在ε的情况下,寻找扰动δ,使图片分类损失最大。接下来将介绍常用对抗攻击方法。
(1)FGSM攻击
快速梯度符号法[9](FGSM,fast gradient sign method)是一种梯度攻击方法,也是对抗样本生成算法的基础之一。在线性模型中,FGSM期望添加的扰动变化量与模型损失函数的梯度变化方向一致,如式(2)所示。
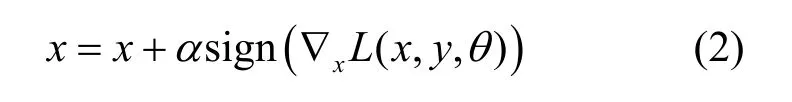
其中,α为超参数,用以调整扰动幅度。sign(⋅)为符号函数,∇x为损失函数的回传梯度。FGSM具有生成对抗样本快,消耗资源少的优点。但是因为只攻击一次,所以攻击效果有限。
(2)I-FGSM攻击
迭代快速梯度符号法[10(]I-FGSM,iterative fast gradient sign method)属于多次迭代的FGSM攻击,初始输入为干净样本,如式(3)所示。多次迭代解决了单次攻击效果不佳的问题。

Clipx{⋅}为截断函数,用以将生成的扰动限制在ε的范围内,如式(4)所示。相较于FGSM,I-FGSM拥有多次迭代的优势,提升了攻击成功率。
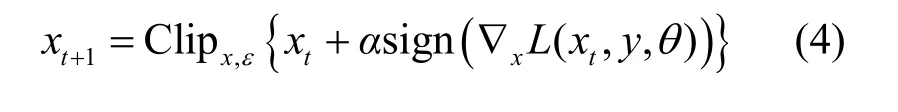
(3)MI-FGSM攻击
动量迭代快速梯度符号法[11](MI-FGSM,momentum iterative fast gradient sign method)引入动量,以累计的速度矢量指引梯度下降。
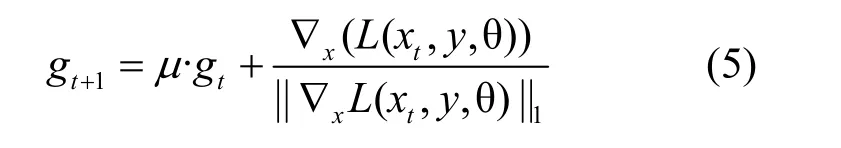
μ为衰减因子,当μ= 0时,MI-FGSM变为I-FGSM。式(5)的第一部分为第t次迭代的动量,以衰减形式累加,记忆之前梯度方向;第二部分为当前的梯度,以l1距离进行归一化处理。两者相加得到最终的动量表示。每次对图像添加的扰动均使用此迭代动量,如式(6)所示。MI-FGSM有效避免了出现过拟合的情况,在黑盒攻击下有很好的鲁棒性泛化能力。
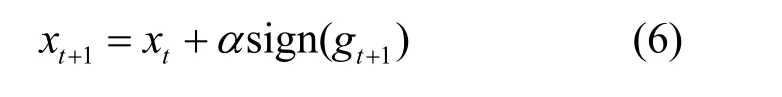
(4)PGD攻击
投影梯度下降[12](PGD,project gradient descent)攻击类似I-FGSM攻击,通过多次迭代获取对抗样本。初始输入为干净样本,如式(7)所示。

PGD攻击的扰动生成函数基于FGSM攻击。迭代中对样本扰动进行约束,以l2或l∞范数为限制生成扰动域,生成的对抗样本被投影到域中,即式(8)中的Px。PGD攻击针对白盒模型的效果极佳,可用作测试模型防御能力的基线算法。
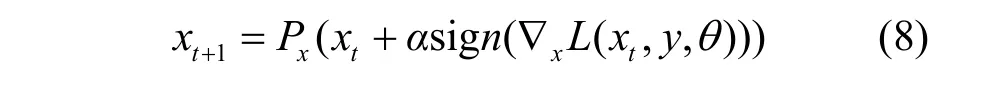
(5)DeepFool攻击
深度欺骗攻击[13](DeepFool attack)是基于超平面分类思想的攻击,可用于非线性模型,相较于FGSM攻击,其具有更强的适应性。深度欺骗攻击算法基于原始图像,将分类器的决策边界线性化。添加扰动,使图像逐步逼近决策边界,并重复迭代增强效果,使样本被错误分类。作为一种早期方法,DeepFool攻击相比FGSM攻击,其适用范围更广,计算速度有所提高。但是需要根据决策边界添加扰动,难以对扰动幅度进行限制。
(6)OPA
单像素攻击[14](OPA,one pixel attack)只改变少数像素点就可以获得较好的攻击效果,其目标函数为
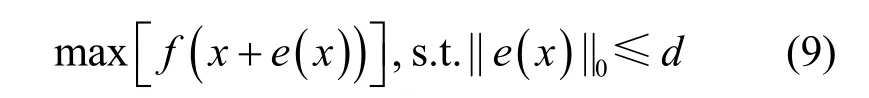
函数e(⋅)为根据原始图像x生成的扰动,作用于原始图像,使目标分类器决策错误标签置信度增大。d为扰动阈值,当d=1时,OPA为严格单像素攻击。在生成扰动中,OPA将当前扰动集合作为父集,随机生成扰动子集合,筛选父子集合中攻击性强的扰动,多次迭代获得最强扰动。相较于通用扰动方法,OPA修改的像素数量更少,仅需要分类标签概率即可拥有较强的攻击性能,适用于黑盒攻击下的小幅度攻击。
(7)C&W攻击
Carlini-Wagner攻击[15(]C&W attack)是针对Hinton[5]的防御蒸馏网络提出的攻击方法,具体目标函数为
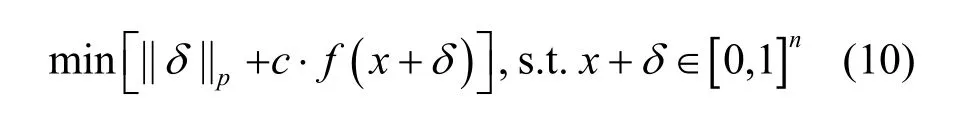
其中,‖·‖p为扰动范数,用以衡量扰度幅度,使用L0、L2、L∞这3种范数进行衡量。目标函数确保扰动幅度小的同时,模型错误分类标签的置信度足够高。C&W攻击迁移能力强,是用于对比实验的基线算法之一。相比于PGD攻击,C&W攻击可以构造出更小的扰动,但复杂度更高。Madry[12]基于C&W攻击损失函数提出PGD形式的C&W攻击,该攻击方便多次迭代,并保留了C&W良好的攻击性能。
1.2 对抗样本防御方法
对抗样本防御的思想是:假设模型输入图片x,添加的对抗扰动为δ,模型输出为f(⋅),期望
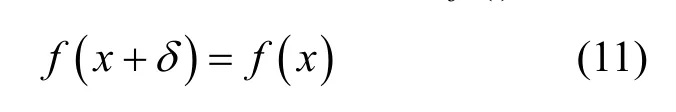
即添加对抗扰动前后,模型输出期望不会受到影响,这种性质被称为模型的鲁棒性。接下来介绍目前主流的对抗防御方法。
1.2.1 基于对抗训练的防御方法
数据扩充是一种经典的神经网络训练方法,其思想是添加数据集,增强模型的决策经验。在对抗防御方面,使用对抗样本扩充数据。主要思路是针对目标模型进行白盒攻击,将生成的对抗样本添加到模型的训练集中,对模型进行重复训练。
Goodfellow[9]提出基于FGSM的对抗训练。训练过程中兼顾原图片和对抗样本的损失。损失函数如下:
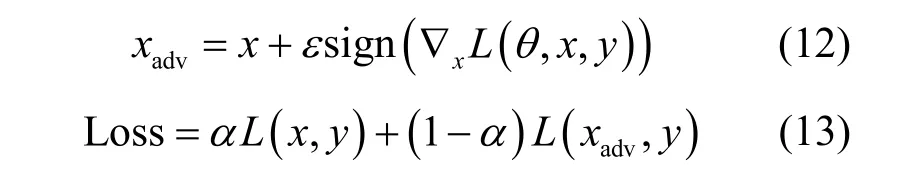
Madry等[12]对此进行优化,使用PGD攻击生成对抗样本,并只关注对抗损失,在白盒和黑盒攻击下均有不错的防御效果。Kannan等[16]在之前工作的基础上进行优化,其不仅约束原始图片和对抗样本的分类损失,而且添加扰动前后图片的相似正则项,保证分类器对原始图片的logits和对抗样本的logits一致。Wang等[17]使用错分类的输入样本进行对抗训练,提高了模型的鲁棒性,该方法针对攻击样本的分类准确率有所提升,但降低了干净样本的分类准确率。
对抗训练是一种非常优秀的防御方法,但需要多次迭代,以提高模型的鲁棒性。训练过程中需要极高的算力需求,在小型计算设备上难以支持。
1.2.2 其他防御方法
Xie等[18]对输入样本随机变换尺寸以及填充,再输入分类模型中,提高了模型防御能力。文献[18]提出的算法使用随机操作预处理,使攻击者无法固定真实输入,降低了攻击风险。随机操作额外计算量小,可与对抗训练结合增强效果。但该算法需要足够大的随机调整空间和填充空间,来提高攻击者的计算成本。
Xie等[19]发现输入对抗样本后,模型的特征图与原始输入差距较大,而且对抗样本的特征图存在噪点,这将影响神经网络模型的决策。该方法在神经网络的特征层添加去噪模块,将特征图预处理再向后传递,并在ImageNet数据集测试其白盒防御能力。同时,文献[19]指出对抗训练是实验取得良好防御效果的必要条件,存在高算力需求。
Xu等[20]通过特征压缩检测输入图像是否为对抗样本,从源头降低对抗样本攻击的风险。该方法减少像素的色位深度,以及平滑像素差距来压缩图像,缩小攻击空间。其复杂度低,不需要对分类模型改造即有一定的防御能力。但阈值设定过于敏感会影响正常样本的输入,Ma等[21]证明特征压缩对于Cifar、ImageNet等彩色数据集效果不佳。
非对抗训练方法通过微调、降噪、压缩等方式预处理,进行对抗防御。但预处理方案难以学习到神经网络的深层特征,需要对抗训练增强防御效果,本质上没有降低学习代价。本文对已有模型进行经验复用,减少对抗训练带来的算力需求。
1.3 知识蒸馏
大型神经网络模型算力需求高,响应速度慢,影响线上部署效率。Hinton等[5]提出一种迁移学习方案,小型网络通过训练,拥有原网络相似的泛化决策能力。Hinton等对softmax函数进行改造,如式(14)所示。
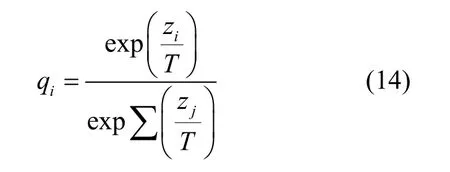
当T=1时,式(14)变为原始的softmax变换。随着T的增大,教师网络和学生网络的输出更容易拟合。并以此为基础约束蒸馏中的软标签损失,如式(15)所示。
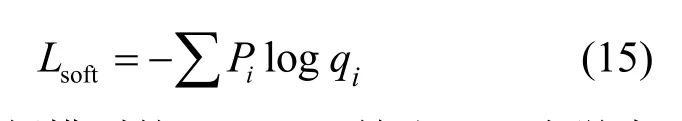
其中,Pi为教师模型的softmax输出,qi为学生模型的softmax输出,将其添加至蒸馏的总损失中,即
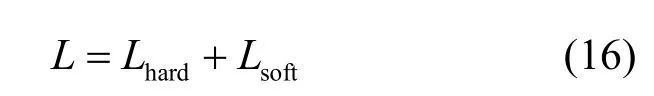
知识蒸馏的总损失分为两类,Lhard约束图片的正常分类,Lsoft约束蒸馏中的相似拟合。通过知识蒸馏,参数简单的学生模型模拟教师模型的输出分布,两者拥有近似的决策能力。模型压缩会使学生网络针对性学习特征,具有一定的防御效果。
Goldblum等[22]和Shafahi等[23]根据Hinton等[5]的工作,从两种角度进行对抗样本防御研究。Goldblum等提出教师网络和学生网络的结构不同,蒸馏后结构简单的学生网络依然有较强的鲁棒性能,方便线上部署。Goldblum等的贡献有两方面:第一根据实验证明使用干净样本进行蒸馏,学生网络可以继承教师的鲁棒性;第二提出一种对抗鲁棒特征蒸馏(ARD,adversarially robust distillation)方案,教师网络的输入为干净样本,学生网络利用自身参数生成对抗样本作为输入,以KL散度约束,借鉴了Shafahi等[24]的方法加速训练,得到的学生网络拥有良好的鲁棒性能。Shafahi等[23]提出一种鲁棒性特征迁移方案,期望模型在先前的数据集对抗训练得到的鲁棒经验,能够泛化到新的数据集任务中,减少新任务的训练消耗。蒸馏过程中教师模型和学生模型结构保持一致,但对应数据集不同,所以不能以softmax的输出logits作为蒸馏约束。Shafahi等认为决策一致的条件下中间特征层的输出相似,利用模型中间输出作为媒介,约束蒸馏过程,其在少量资源消耗的前提下获得不错的防御效果。
1.4 类激活映射
类激活映射(CAM,class activation mapping)属于语义分割(semantic segmentation)领域,可以帮助研究者理解神经网络的决策依据。本文借鉴类激活映射的思想,提出一种针对特征向量的注意力机制,加强对重要特征的关注度。
Zhou等[6]发现,神经网络的最后一层特征层保留着丰富的空间和语义信息。他们将最后的卷积层特征直接通过全局平均池化层(GAP,global average pooling),形成每个特征图的均值,利用全连接层获取每个特征图均值的权重。在需要生成可视化热力图时,提取对应类别的全连接层权重,与特征图加权求和,上采样获取最终图像,如图1所示。
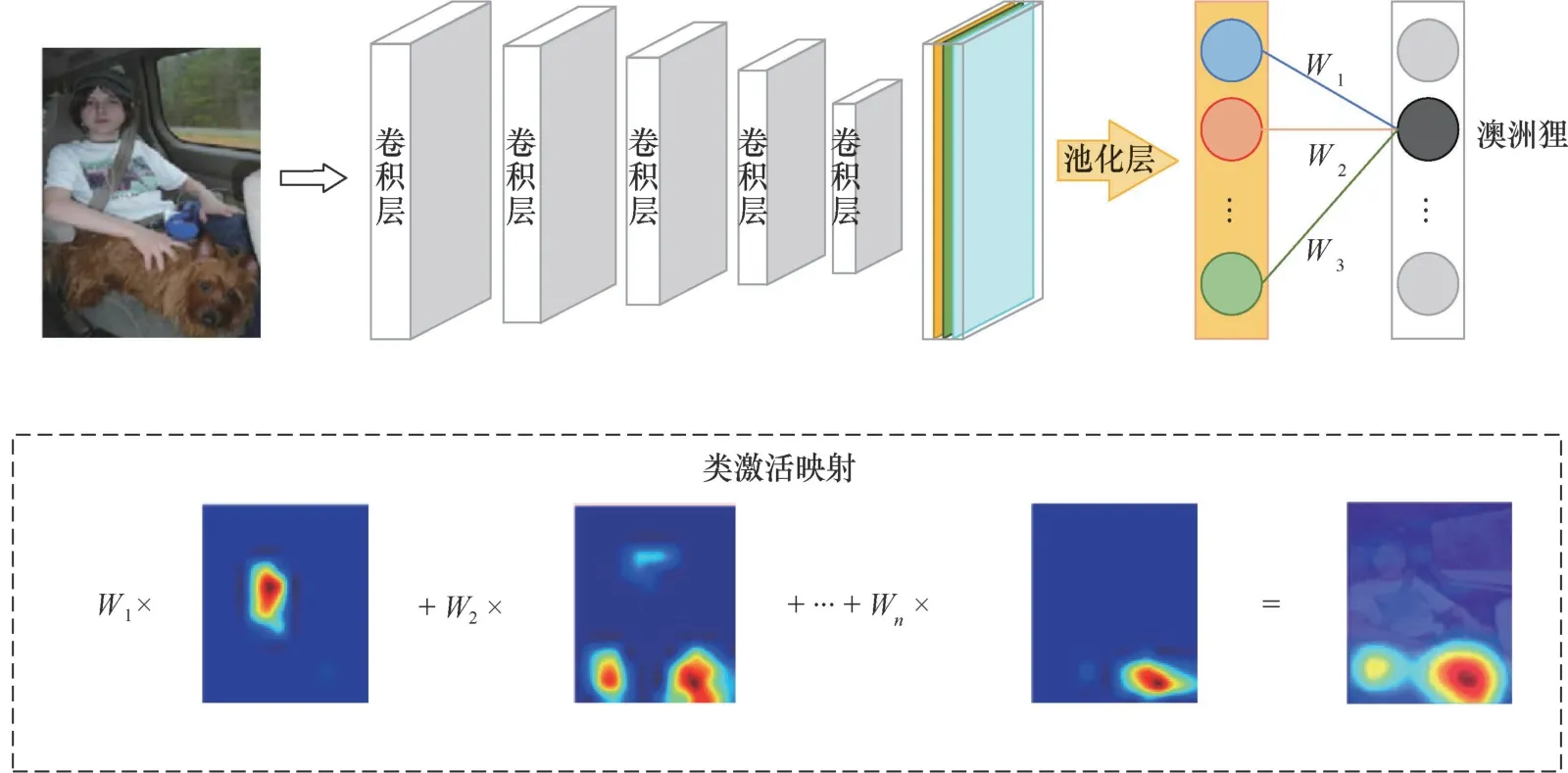
图1 类激活映射机制 Figure 1 Mechanism of class activation mapping
类激活映射在模型可视化方面效果较好,有助于研究者深入理解神经网络模型的决策。Selvaraju等[25]将类激活映射扩展,使用CNN的最后一层卷积层的梯度信息进行判断,扩大映射的使用场景。Chattopadhay等[26]优化了权重计算,使映射定位热力图更加准确。Wang等[27]提出一种基于等变注意力机制(SEAM,self-supervised equivariant attention mechanism)的弱监督语义分割的方法,构建孪生网络,为空间仿射变换后的类激活映射输出提供自监督,并使用注意力机制整合图像信息,在预测图像语义方面有很好的效果。
2 方案设计
本文的目标是利用知识蒸馏将模型在大数据集对抗训练得到的防御经验进行提取,并泛化到其他数据集的任务中,从而减少在其他数据集上的鲁棒性模型训练成本。方案设计主要分为4部分:第1部分利用对抗训练生成教师鲁棒模型;第2部分设计知识蒸馏的整体架构;第3部分使用多维度特征图的蒸馏优化方案;第4部分利用基于注意力机制的特征图完成权重优化。
2.1 对抗训练生成鲁棒模型
在操作知识蒸馏前,教师网络需要学习大数据集的鲁棒性特征,用以在其他数据集任务中进行经验传递。本文使用Madry等[12]提出的方法,进行有监督的对抗训练。训练目标为
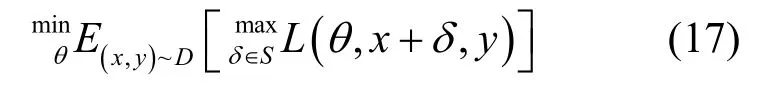
式(17)是基于min-max优化的通用对抗训练方法。其中,θ表示网络结构,δ为生成的对抗扰动,(x,y)为图像及对应标签,L(⋅)为损失函数。具体方案如图2所示,为对抗样本生成部分,期望在限定域中寻求扰动δ,使模型分类损失最大,从而达到分类错误的目的,在此阶段,模型结构θ保持不变。此后,将生成的对抗样本作为输入,训练模型结构θ。多次迭代后,得到最终的鲁棒模型。
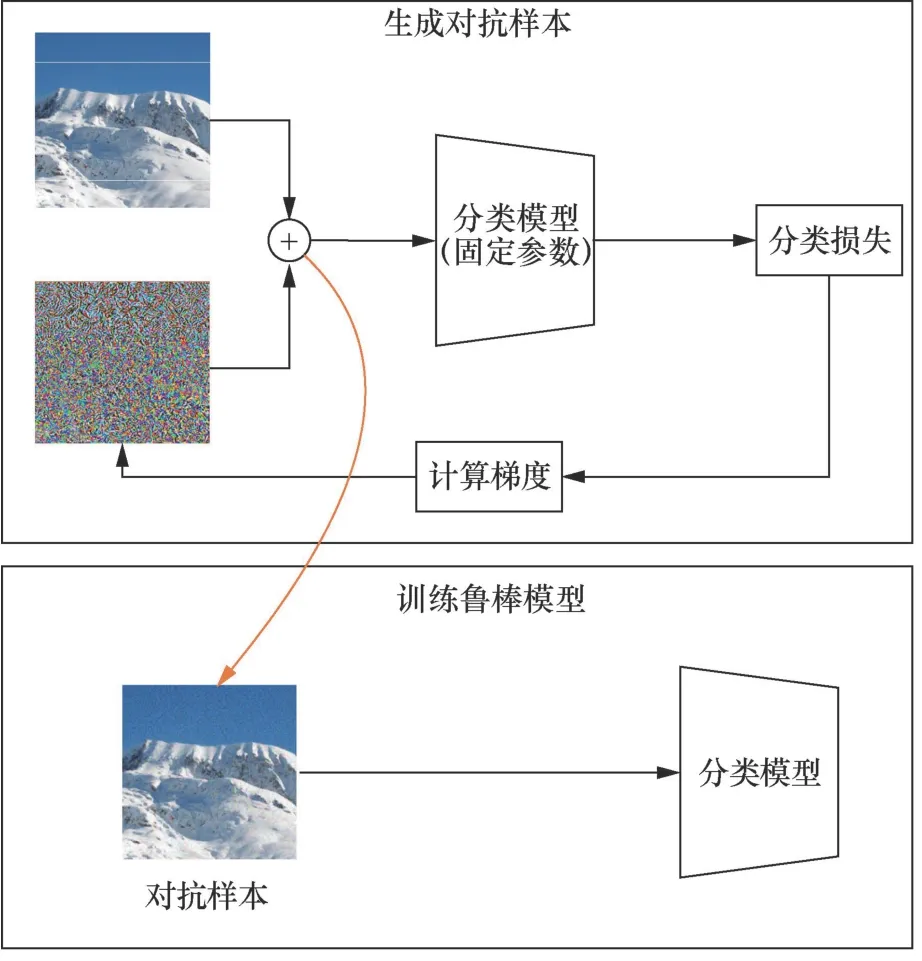
图2 对抗训练流程 Figure 2 Process of adversarial training
Madry等在对抗训练中使用PGD攻击产生对抗样本,生成的防御模型具有良好的鲁棒性。因此Shafahi等[23]的知识蒸馏实验同样采取PGD攻击生成鲁棒模型,为方便与Shafahi的工作做出对比,本文采用PGD攻击方法生成对抗样本,如式(18)所示。
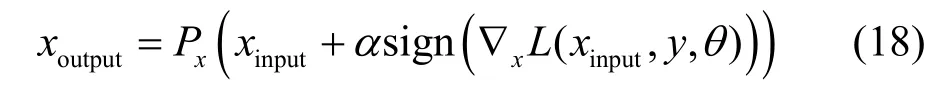
其中,xinput表示上次PGD攻击输出的对抗样本,初始情况下xinput=x,α为超参数,用以调整扰动幅度,sign(.)为符号参数, ∇x为损失函数的回传梯度。生成对抗样本期间神经网络参数θ保持不变。由于实验使用的图像识别任务是多分类任务,神经网络的损失函数使用交叉熵损失。
2.2 蒸馏模型基础结构
本节介绍迁移的整体框架,蒸馏模型由教师网络和学生网络两部分组成。教师网络在较大数据集上进行对抗训练,获得鲁棒模型。之后使用其他数据集的干净样本进行蒸馏操作,期望学生模型能够学习到教师网络的鲁棒性经验。
基于Shafahi等[23]的工作,本文使用一种优化的知识蒸馏方法,如图3所示。教师网络和学生网络结构一致,但教师参数在蒸馏过程中固定。蒸馏任务的目的是在目标数据集进行迁移学习,训练学生网络参数。本文沿用Hinton等[5]的蒸馏损失分类,将损失分为hard target和soft target。教师预训练使用的源数据集和学生目标数据集类别存在差异,本文的soft target没有使用logits进行约束,而是使用神经网络的特征图作为蒸馏项。
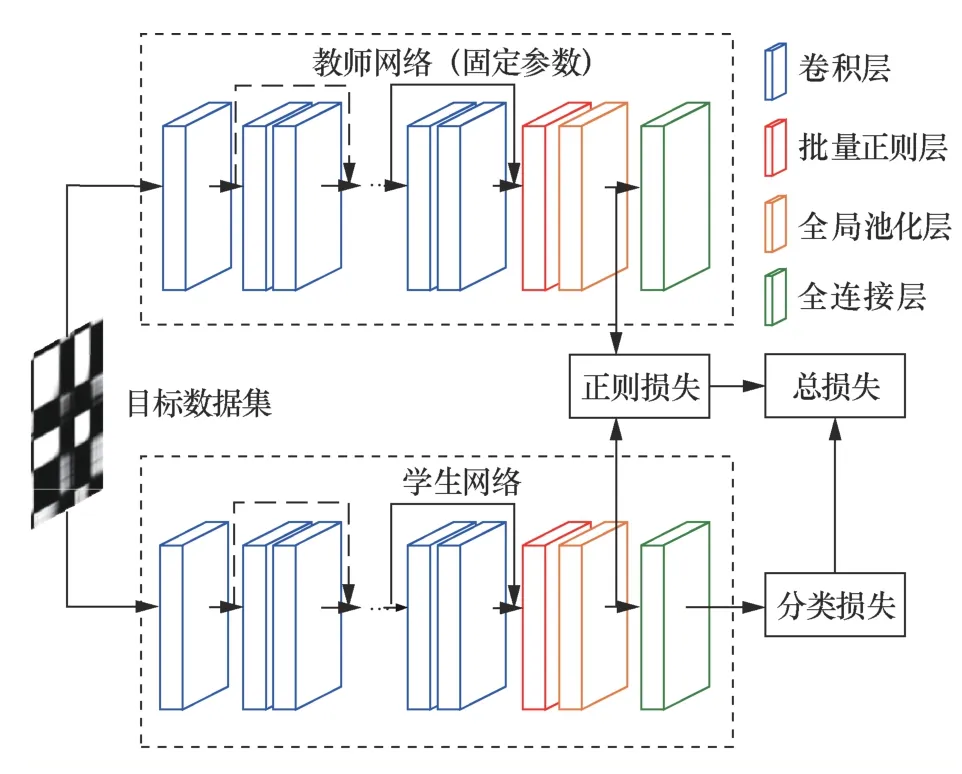
图3 知识蒸馏结构 Figure 3 Model structure of knowledge distillation
分类神经网络中,模型输出前通常使用全局平均池化层和全连接层进行处理。本文设定池化层前的教师网络特征图输出为zteacher,学生网络的特征图输出为zstudent,特征图z对应的池化层输出为zgap。
Shafahi等[23]使用全局平均池化层后的特征联合训练,损失函数如式(19)所示。
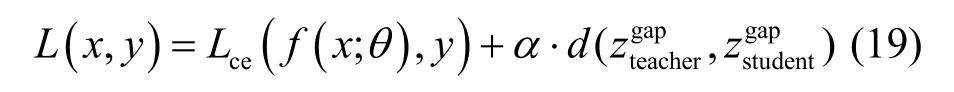
其中,Lce(·)与Hinton蒸馏的hard target相同,使用交叉熵函数记为Lce。第二部分为正则损失,用以拟合蒸馏过程中的特征经验分布,为蒸馏的soft target,记为Lkd。其中α为调整蒸馏损失的超参数,d(⋅)为衡量教师网络和学生网络差距的距离度量,本文使用L2正则衡量。
全局平均池化层将特征压缩、高度提炼,但这样会丢失大量空间和语义信息,不利于鲁棒性经验的迁移。本文强化特征层的语义表达,增强蒸馏效果。
2.3 基于多维度特征图的蒸馏优化
本节从特征图和频域两个维度强化特征层的语义表达。
首先考虑神经网络结构,Shafahi等[23]使用池化层之后的特征作为约束项。全局平均池化层由Lin等[28]提出,使用全局池化层代替全连接层,将每个特征层抽象为单点输出,这样不仅能简化模型参数,加快训练速度,而且减少了全连接层带来的过拟合现象。但高度抽象特征会损失大量的空间和语义信息,也会影响蒸馏效果。因此本文使用池化操作之前的特征图作为蒸馏媒介,soft target即为
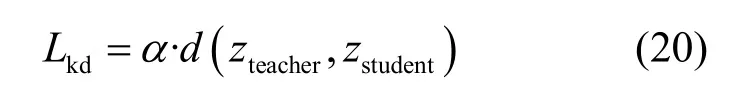
此外,本文利用频域特性增强特征语义。考虑到神经网络的复杂性,本文使用全局池化层之后的特征进行实验,具体是通过N维快速傅里叶变化(FFTN,fast Fourier transform)将该特征转化为频域N维向量。之后利用傅里叶变换的平移操作(FFTShift,fast Fourier transform shift)把零频点移到频谱的中间得到频域特征。频域特征分为实部和虚部,二者拼接得到频域最终表示。本文以特征向量Z∈R1×4进行推演,如图4所示。

图4 特征向量转化为频域特征样例 Figure 4 Example of feature vectors transformed into frequency domain feature
zgap为全局池化层后的输出,zfourier为蒸馏使用的频域特征表示。两者关系为

cat(⋅)为拼接操作,将两个向量按照维度dim = 1进行拼接。频域方面的soft target为
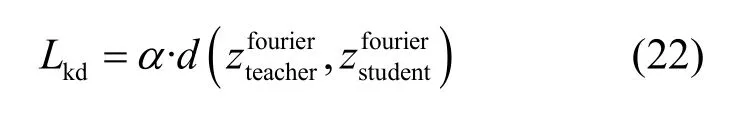
两个维度的特征强化在蒸馏过程中增加了额外计算损耗,所以本文实验不仅验证多维度特征图方案的有效性,而且会记录时间消耗。期望增强特征语义表达的同时,训练时间不会显著提高。接下来,将对特征进行细粒度划分,关注对应类别的敏感特征,从而提高经验利用率。
2.4 特征图权重优化
特征图向量可以理解为滤波器对于输入图像的特征提取。之前的损失函数直接将教师和学生的特征图正则化比对,每个特征向量权重比值一致。本文考虑将教师网络的经验细粒度优化,关注相应类别的敏感特征,以达到更佳的迁移效果。
根据Zhou等[6]的工作,可知在分类任务中,输入特征的显著程度决定了其分类类别。模型对输入生成的类激活映射,有助于了解特征对决策的贡献。在本文的蒸馏过程中,不同类别的样本,对特征层的敏感通道不一致。训练等权重特征向量时,无法最大化利用教师经验。借鉴类激活映射的工作原理,本文提出一种特征向量的注意力机制,加强敏感特征的关注度。
经过2.1节的对抗训练后,教师网络拥有良好的鲁棒性能。固定教师网络的参数,使用目标数据集训练全连接层,具体流程如图5所示。假设池化操作后的特征图Z∈RC,目标分类共有B类,全连接层的参数M∈RB×C满足
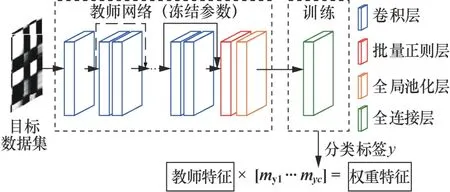
图5 教师特征权重配比流程 Figure 5 Process of obtaining weight for teacher features
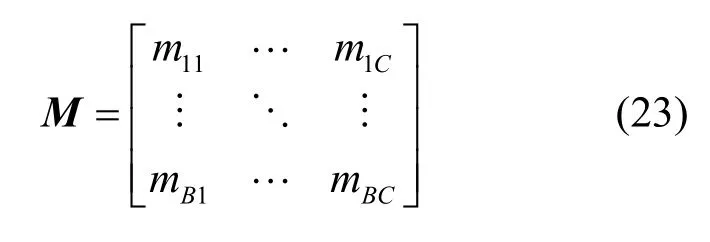
对应样本标签类别为y的权重系数满足
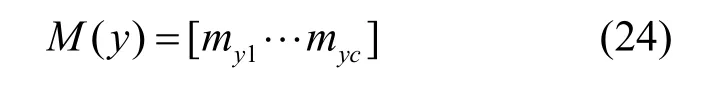
权重系数用于组织特征层向量,使目标数据集的分类为y,即预训练得到的权重表征不同分类对于特征通道的关注度。本文针对特征图向量施加注意力机制,soft target满足
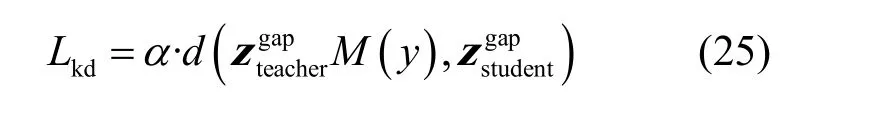
对池化前的特征图Z∈RC×H×W进行蒸馏的场景下,需要将M(y)进行扩展,如下。
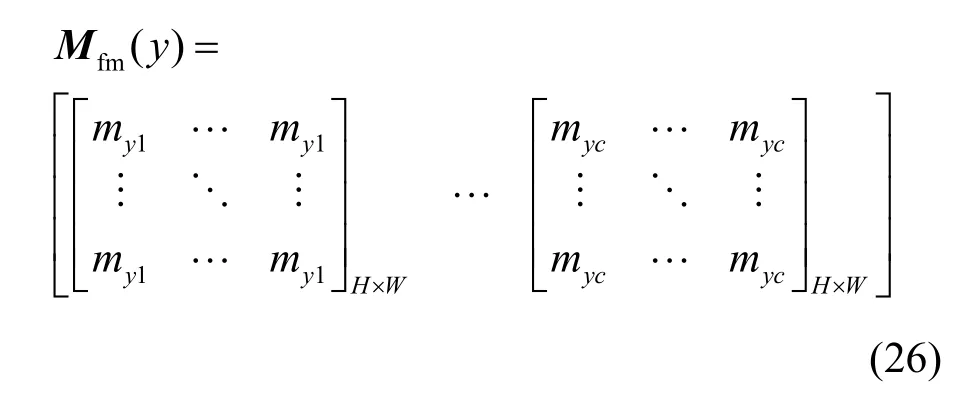
蒸馏的soft target表达式为
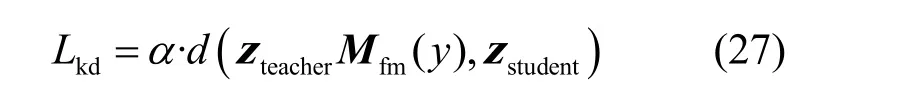
本文将权重系数应用到频域方面。频域特征是针对池化特征的增强,所以训练全连接层时,可将拼接后的频域特征作为全连接层的输入,得到最终的权重系数。训练流程与池化特征处理类似,在此不再赘述。
2.5 小结
本节对蒸馏过程中的特征图进行优化,丰富其空间和语义信息,加强表达效果,并基于类激活映射提出注意力机制,针对不同类别强化部分特征,达到更好的蒸馏效果。最终的损失函数为
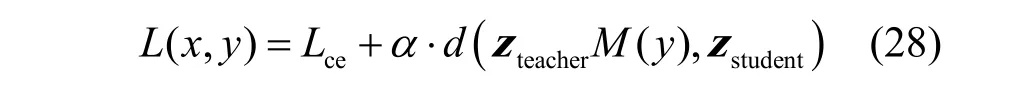
zteacher、zstudent为广义特征向量,M(y)为对应特征形式的权重,α为控制正则损失的超参数。
3 实验设计和结果分析
3.1 实验环境设置
本文实验训练及测试环境为Centos 7.7操作系统,处理器型号为 Intel Xeon Scalable Cascade Lake 8168(2.7 GHz,24核),内存1.5 TB DDR4 ECC REG 2666,GPU为NVIDIA Tesla V100。
本文使用Cifar100和Cifar10数据集进行效果展示,图片尺寸为32×32。教师网络在Cifar100数据集上进行对抗训练,获取鲁棒模型。之后固定教师网络参数,使用Cifar10训练集进行蒸馏训练,在多种算法下测试迁移效果。
预训练阶段,本文使用添加动量(momentum)的SGD[29]算法,momentum为0.9,weight_decay值为 2 × 1 0−4。对抗样本使用L∞的PGD攻击算法生成,扰动幅度单步最大扰动为迭代次数step=7。
知识蒸馏阶段,教师网络和学生网络均选取wide-resnet28[3],学生网络的初始参数与教师保持一致,来加快蒸馏训练。在完成15个epoch训练后,训练集上的损失基本稳定,学生网络能够顺利收敛。以添加权重mask的频域蒸馏训练为例,超参数α= 10,模型在训练集的准确率和损失曲线如图6所示。
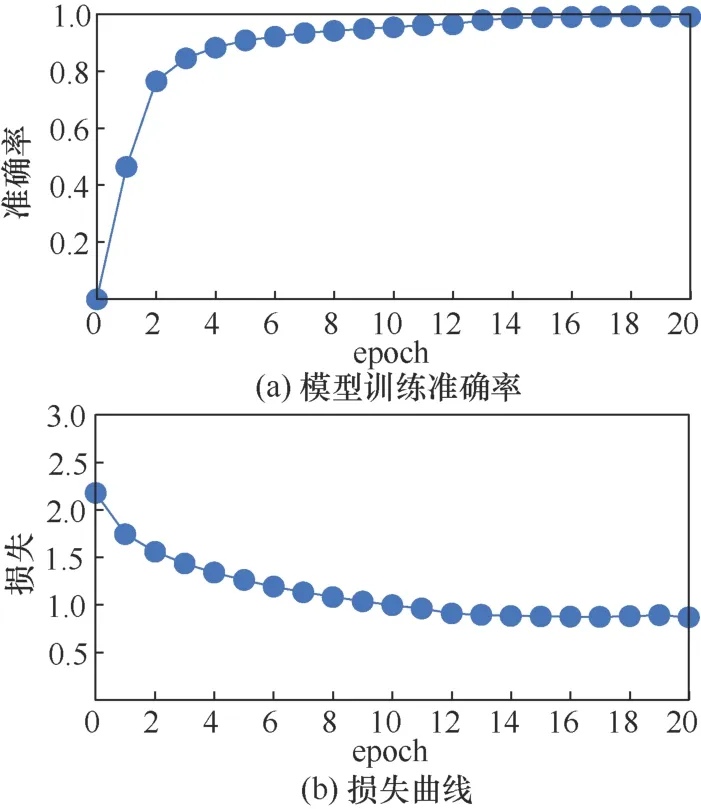
图6 基于频域特征蒸馏的准确率与损失曲线 Figure 6 Accuracy and loss curve on knowledge distillation with frequency
为了证明本文方法的有效性,共设置了3组模型用以比对。第一组使用Cifar10直接训练得到的正常模型;第二组使用Cifar10对抗训练得到的鲁棒性模型;第三组复现Shafahi[23]的工作,用以比对蒸馏效果。3组基线初始参数与学生网络相同,从而确保训练的公平性。
3.2 算法效果
本文使用Cifar10测试集在模型上的准确率,作为判断鲁棒性特征学习效果的依据。模型在样本的分类上准确率越高,说明学习到的鲁棒性特征越强,防御更有效果。本实验使用正常输入、FGSM、PGD、C&W等多种攻击测试防御效果。其中,FGSM最大扰动幅度。PGD攻击选取L2、L∞两种范数攻击,PGD-L2最大扰动幅度ε=1,PGD-L∞最大扰动幅度,步长均为。C&W攻击采用Madry[12]提出的迭代形式,扰动幅度与PGD-L∞相同。PGD和C&W攻击测试5、10、20这3种迭代次数下的防御效果。
Shifahi[23]蒸馏和特征图蒸馏均使用超参数α= 500。频域特征转化幅度较大,不适用同样参数,使用α= 10进行测试。之后进行消融实验去除超参数α的影响。在Cifar10上的准确率如表1~表4所示。
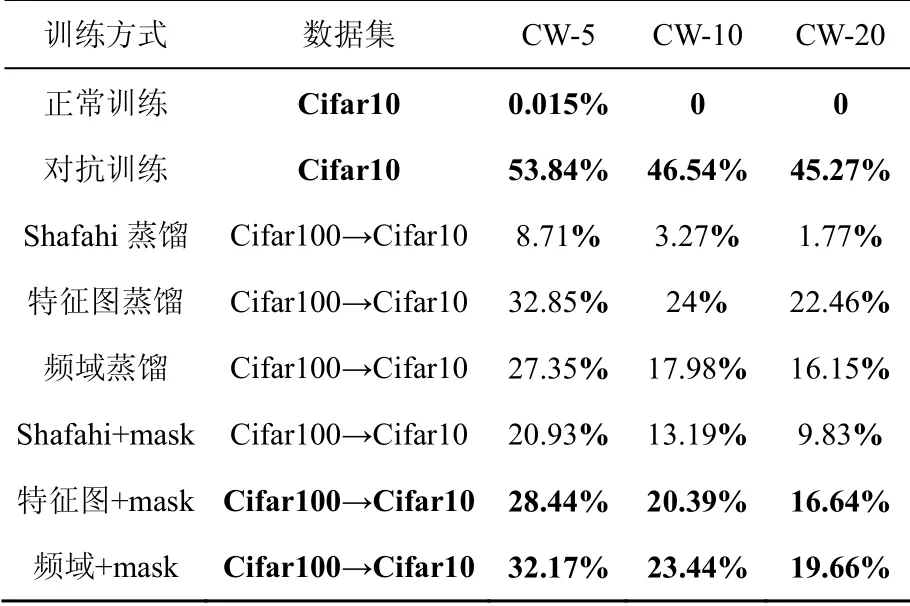
表4 C&W攻击算法在Cifar10上的准确率 Table 4 Accuracy of the C&W attack on Cifar10
干净样本和FGSM攻击在Cifar10上的准确率结果如表1所示。替换特征层后,语义信息更加丰富,偏重拟合鲁棒性特征,导致在干净样本和FGSM下准确率有所下降。使用权重系数mask能有效控制非关键特征,蒸馏过程更具有针对性,准确率均明显提升。权重系数在Shafahi的工作同样有效,FGSM攻击下准确率由46.13%提高到61.30%。本文的方法(采用频域+mask训练)在干净样本上的准确率甚至高于对抗训练,达到94.23%。
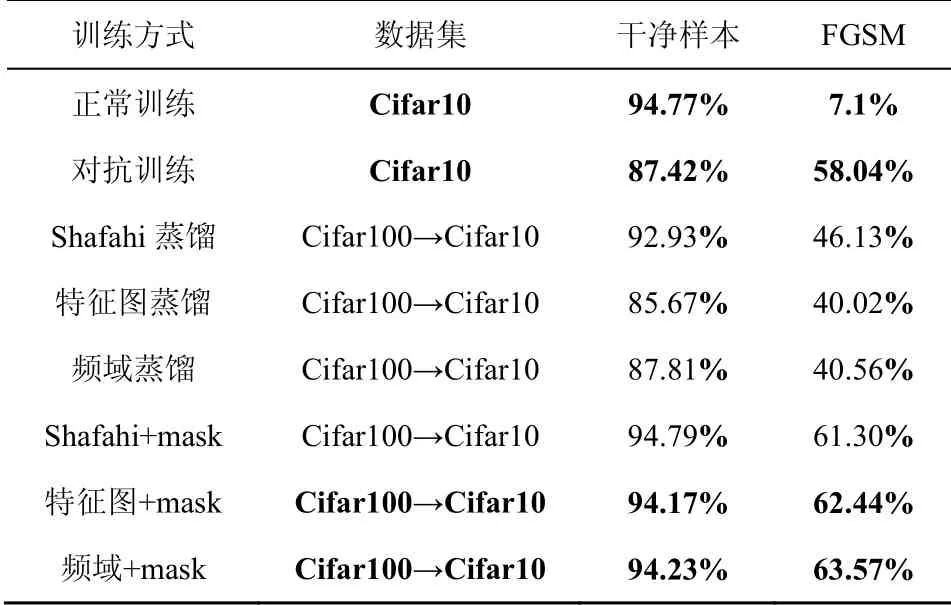
表1 干净样本和FGSM攻击在Cifar10上的准确率 Table 1 Accuracy of the clean and FGSM attack on Cifar10
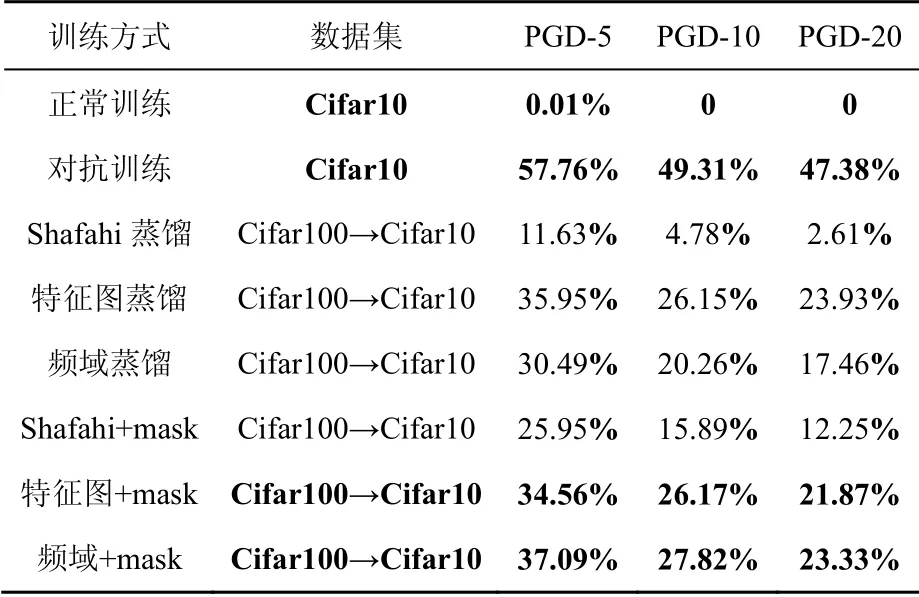
表3 PGD-L∞攻击算法在Cifar10上的准确率 Table 3 Accuracy of the PGD-L∞ attack on Cifar10
本实验验证了Cifar10在PGD攻击和C&W攻击下的准确率,结果如表2~表4所示。相较于FGSM攻击,PGD和C&W攻击强度更高,增强语义的效果更加明显。特征层权重系数也有效提高算法的准确率,在PGD-L2下本文的方法略微高于对抗训练,达到了25.14%,对抗训练只有24.95%。
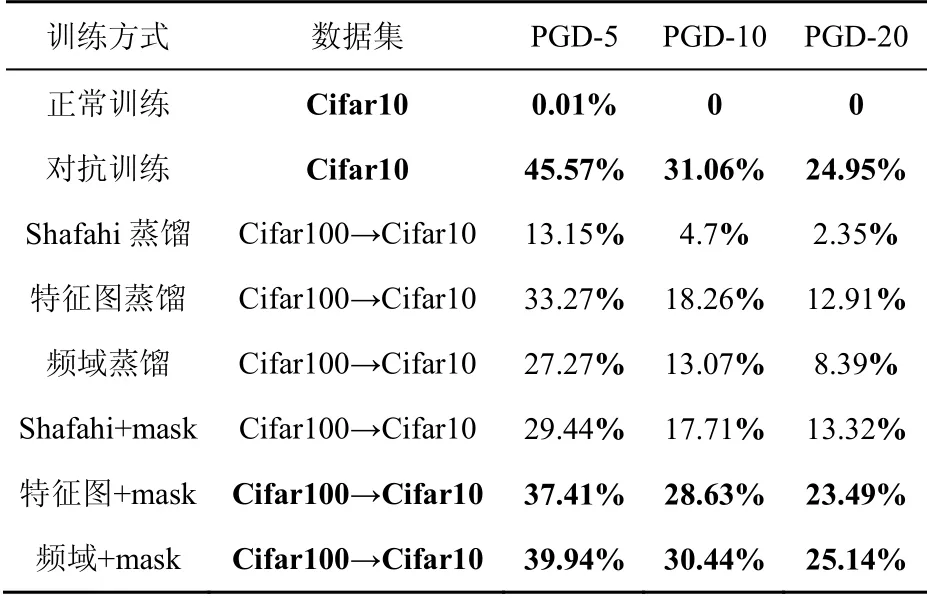
表2 PGD-L2攻击算法在Cifar10上的准确率 Table 2 Accuracy of the PGD-L2 attack on Cifar10
此外,本文以PGD-L∞为例,验证高轮次迭代下的算法效果,结果如图7所示。即使是100次的迭代攻击,频域蒸馏和特征图蒸馏依旧有很强的鲁棒性。
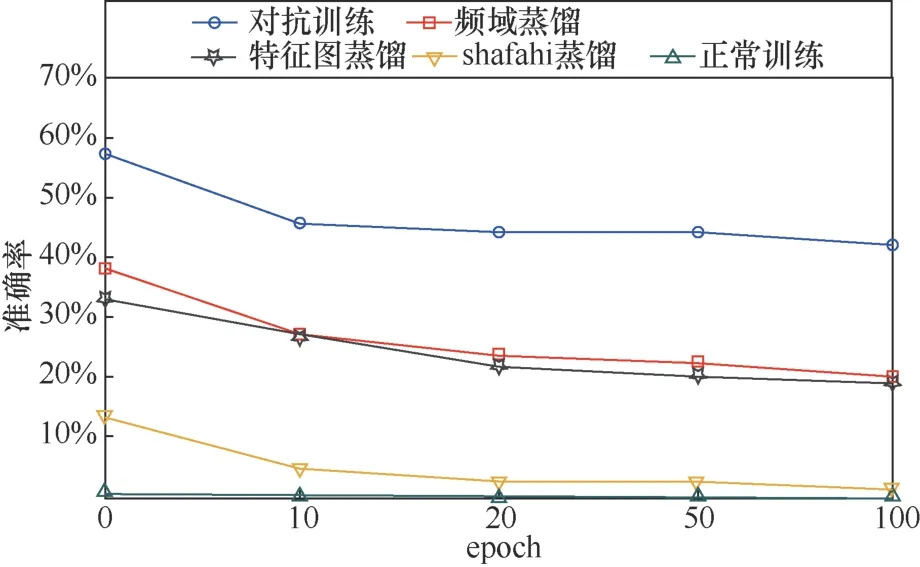
图7 PGD-L∞迭代强度与准确率关系Figure 7 The r elationship between epoch of PGD-L∞ attack and accuracy
3.3 算法耗时
本文对不同算法在Cifar10上的耗时进行比对,如表5所示。本文蒸馏耗时与Shafahi类似,接近正常训练,远小于对抗训练耗时。这种轻量级的蒸馏算法相比于Shafahi工作,防御效果显著提高,算力要求较低。
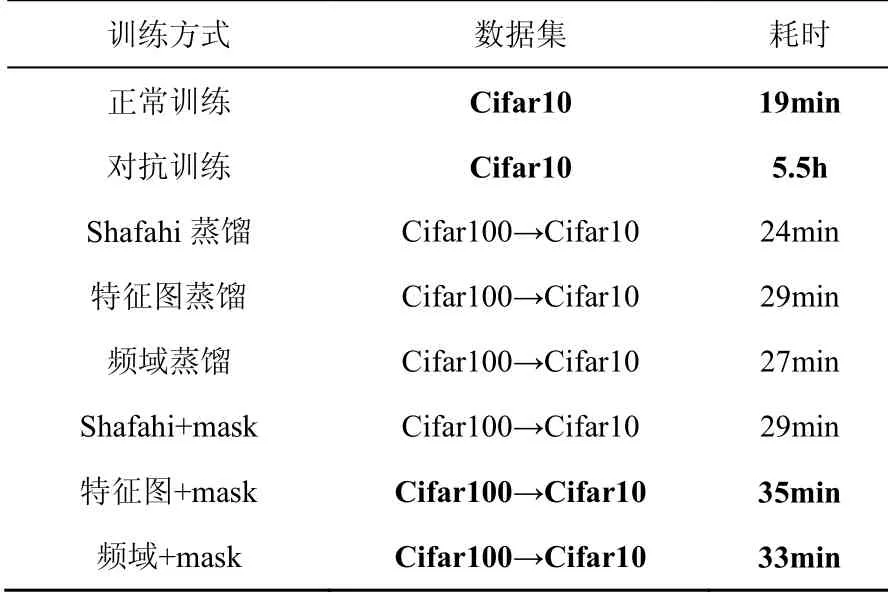
表5 不同算法在Cifar10的耗时情况 Table 5 Time-consuming for Different Algorithms on Cifar10
总体而言,本文通过多维特征图和权重系数mask进行优化,增强防御效果。相比Shafahi的蒸馏有着不错的提升,即使在多次迭代的PGD攻击下,模型依旧拥有良好的防御能力。算法计算耗时较低,接近正常训练。
3.4 消融实验
为了控制超参数α带来的影响,本文对其进行消融实验。选取干净样本、FGSM、PGD-L∞这3种攻击测试不同权重α的蒸馏效果,如 表6~表8所示。
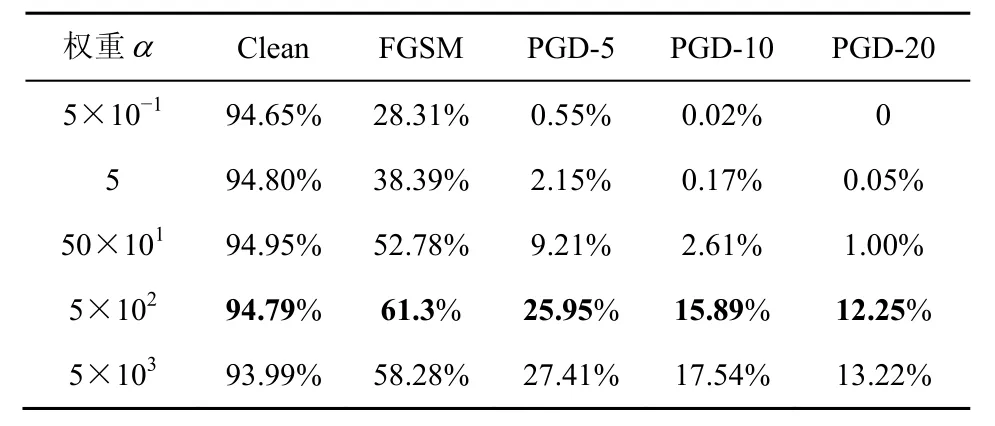
表6 Shafahi+mask基于不同α在Cifar10上的分类准确率 Table 6 Accuracy based on α with shafahi used mask on Cifar10

表7 特征图+mask基于不同α在Cifar10上的分类准确率 Table 7 Accuracy based on α with feature map used mask on Cifar10
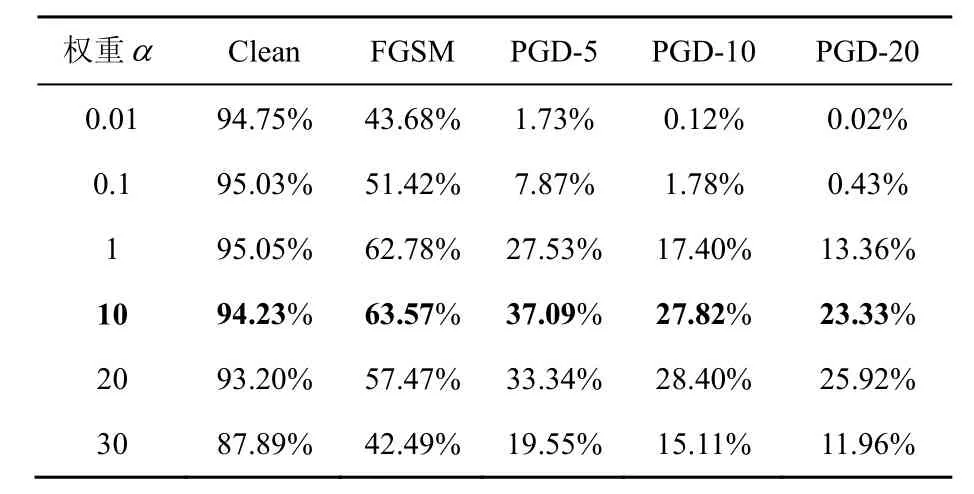
表8 频域+mask基于不同α在Cifar10上的分类准确率 Table 8 Accuracy based on α with frequency used mask on Cifar10
α的增大有助于蒸馏关注soft target,使模型更具有鲁棒性,提高在攻击算法上的准确率,但会降低在干净样本上的准确率。频域特征对于超参数敏感程度更高,小量级下就有优秀的表现。最终,本文选取频域特征下的超参数α= 10,其他蒸馏下超参数α= 5× 10−1。
4 结束语
本文提出一种基于知识蒸馏的轻量级对抗样本防御方法,用以解决多任务下经验复用的问题,更快获取鲁棒性模型。一方面,使用多维度的特征图,获取更丰富的空间和语义信息,增强蒸馏效果;另一方面,使用权重系数对特征层参数细粒度配比,有效利用教师经验。之后,通过对照实验证明了所提算法的有效性。本文算法在高强度的白盒攻击下,准确率均显著高于Shafahi的蒸馏方案,在干净样本上的准确率甚至高于对抗训练,接近模型直接训练的准确率。
本文算法还可以在很多方向进行完善。第一,可以测试在更大数据集如ImageNet方面的迁移学习效果。第二,目前仅利用单层特征进行蒸馏,之后可以拓展到多层同步提取。第三,将对应样本类别的全连接系数作为权重mask,可以研究对于非该类别的mask能否有效。
