基于softmax激活变换的对抗防御方法
2022-04-18陈晋音吴长安郑海斌
陈晋音,吴长安,郑海斌
(1. 浙江工业大学网络空间安全研究院,浙江 杭州 310023;2. 浙江工业大学信息工程学院,浙江 杭州310023)
0 引言
深度学习具有强大的特征学习能力,这为机器学习和人工智能的发展提供了巨大的机遇。因此,深度学习在众多领域发挥了重要作用,如图像识别[1]、生物建模[2]、疾病诊断[3]、语音识别[4]、自然语言处理[5]等。尤其在计算机视觉领域,Krizhevsky等[6]展示了卷积神经网络在大规模视觉识别系统[7]中的杰出性能,因此深度学习成为计算机视觉领域关注的中心。随着深度神经网络模型的不断改进,以及训练复杂模型所需硬件的持续升级,深度学习得到广泛应用,包括人脸识别[8]、自动驾驶[9]、视频监控[10]、恶意软件检测[11]、无人机和机器人控制[12]等。
随着深度学习技术的深入应用,其中隐藏的安全问题逐渐暴露。Szegedy等[13]率先发现了深度神经网络在图像分类中存在脆弱性——深度模型容易受到图像中细小扰动的对抗攻击,这种细小扰动对人类视觉系统来说几乎是不可察觉的。处于自动驾驶模式的特斯拉汽车,被道路上特定位置的几张贴纸欺骗,自动并入反向车道。在这种安全要求高的应用中,一旦深度模型暴露出漏洞,对乘客和行人都是灾难性的后果。因此,研究深度模型存在的漏洞并提供鲁棒的防御方法是关键。
为了发现深度模型中存在的安全漏洞,学者提出了一系列高效的对抗攻击方法。根据攻击者所能获取模型信息的程度,对抗攻击可分为白盒攻击、灰盒攻击与黑盒攻击。其中,白盒攻击是指攻击者可以获取目标模型的结构、参数、数据集、模型携带防御等所有信息后展开的攻击,如快速梯度符号法[14](FGSM,fast gradient sign method)、MI-FGSM[15]、DeepFool[16]、C&W[17]、基于生成式对抗网络的大规模对抗样本生成器[18](MAG-GAN,massive attack generator via GAN)等;灰盒攻击是指获取模型信息但不了解防御方法;黑盒攻击则是在没有任何模型信息的前提下仅通过查询得到模型输出的类标或对应置信度,利用优化计算或等价模型训练等方法实现攻击,如One-pixel[19]、基于零阶优化的攻击[20(]ZOO,zeroth order optimization)、POBA-GA[21]等。白盒攻击大多存在于实验室的理论研究,对于现在流行的预训练模型和提供API接口的商业模型,黑盒攻击往往具有更大的威胁性[22-23]。因此,实际应用场景中,黑盒攻击比白盒攻击更容易操作,所以,进行黑盒攻击防御研究更具现实意义。
黑盒攻击可分为基于输出置信度的攻击和基于决策边界的攻击[24]。基于决策边界的攻击能获取到的信息更少,攻击操作更困难。在攻击条件上,基于决策的攻击需要对模型的访问次数是基于输出置信度攻击方法的几十倍,甚至上百倍,一定限度上,大量的重复性查询容易暴露,且攻击成功率相对较低。已经有的商用AI服务,包括谷歌的云服务GCE、微软的云计算服务Azure等,它们均提供输出类标及对应置信度,容易受到基于输出置信度的黑盒攻击。与此同时,针对对抗攻击的防御方法研究如火如荼展开。根据防御实施的对象不同,可以分为数据修改的防御[25]、模型修改的防御和附加模型的防御[26]。根据防御操作是否需要对抗样本,可以分为攻击依赖的防御(如对抗训练、扰动蒸馏网络等),攻击无关的防御(如蒸馏防御、数据变换等)。攻击依赖的防御面对特定的对抗攻击具有很好的防御效果,但当攻击策略改变后,防御性能会受较大影响;攻击无关的防御在防御过程中不需要对抗样本支持,对不同攻击制作的对抗样本都能够防御,防御具有一定迁移性。
已有的防御方法在防御成功率上取得了不错的效果,但在实际应用中仍然会遇到以下问题。
1) 攻击依赖性:防御的效果依赖于先前生成的对抗样本,如对抗训练,而且遇到未知的攻击方法生成的对抗样本,则防御成功率受较大影响。
2) 防御代价大:防御的操作大多会影响正常样本的识别准确率,如数据变换随机操作虽然能够破坏对抗扰动,但也干扰了正常样本的识别。
3) 防御成本高:一次防御通常需要重新训练网络或者添加额外的子网络,增加原始模型的复杂性和冗余度,如对抗训练和附加网络防御需要占用大量的时空成本,无法实现轻量级的快速防御。
4) 防御滞后性:防御通常在攻击发生后采用,面对未知攻击,部分防御方法需要再次重新训练,无法实现事前防御。
针对这些问题,本文提出了softmax激活变换(SAT,softmax activation transformation)防御,这是一种针对黑盒攻击的轻量、快速的防御。本文方法通过对输出概率进行重激活实现防御,在不同的图片输入目标模型时,模型输出的概率分布基本相似,导致基于分数的黑盒攻击无效。SAT不参与模型的训练,仅在推理阶段通过对目标模型的输出概率进行重新激活,非常快速、轻量,解决了问题3)。SAT与攻击类型无关,不仅避免了制作大量对抗样本的负担,也实现了攻击的事前防御,解决了问题1)和问题4)。SAT的激活具有单调性,因此不会影响正常样本的识别,解决了问题2)。
本文的主要贡献包括以下4点。
1) 本文提出了一种针对黑盒攻击的快速防御方法,通过在模型的输出层引入softmax激活的变换保护机制,在推理阶段对模型输出进行重激活,具有可验证、低成本的防御优势。
2) SAT防御方法不参与模型训练,不依赖于事前生成的对抗样本,对未知的黑盒攻击仍然具有防御效果,实现了攻击无关和事前防御。
3) 理论证明SAT的单调性,在实现对抗防御的同时不影响目标模型对正常样本的识别准确率,实现了防御代价最小化。
4) 本文在MNIST、CIFAR10和ImageNet数据集上进行了防御验证,对比现在最优防御方法,针对9种黑盒攻击的防御实验,SAT将平均攻击成功率从87.06%降低为5.94%,达到最优防御性能。
1 相关工作
本节主要介绍实验中涉及的对抗攻击方法和对比的防御方法。
1.1 对抗攻击方法介绍
针对深度学习中存在的对抗攻击,根据对手掌握的目标模型信息的多少,可分为白盒攻击和黑盒攻击,具体区别如表1所示。由表1可知,对于面向公众的模型,研究针对黑盒攻击的模型防御能力是有现实意义的。

表1 白盒攻击和黑盒攻击的区别Table 1 The difference between white-box and black-box attacks
黑盒攻击分为基于分数和基于决策边界两种攻击方式[24]。基于分数的黑盒攻击是指攻击者能够获取模型输出的概率,而在基于决策边界的黑盒攻击中,攻击者只能获取到模型输出的类标。基于决策边界的攻击能获取到的信息比基于分数的攻击更少,攻击操作更困难。在攻击条件上,基于决策的攻击需要对模型访问的次数是基于分数的攻击的几十倍,甚至上百倍,大量的重复性访问容易被目标模型所禁止,导致攻击失败。而且从攻击结果上看,即使访问次数不受模型限制,基于决策边界的攻击成功率仍然远低于基于分数的黑盒攻击,所以研究基于分数的黑盒攻击更具有意义。
基于分数的黑盒攻击可以分为梯度估计、模型等价、概率优化3种,以下一一阐述。
基于梯度估计的黑盒攻击:通过观察细微改变输入后分类概率的差异,利用零阶优化法直接估算出模型的梯度,然后沿着梯度方向优化输入,得到对抗样本。该方法首次体现在Chen等[27]提出的ZOO;Tu等[28]提出了ZOO的改进方法Auto-ZOO,利用基于自编码的零阶优化算法大大减少了对目标模型的访问次数;Chen等[29]提出了Boundary++,通过将决策边界攻击Boundary[24]与ZOO相结合的方法弥补了Boundary算法中模型访问次数过多的缺陷。
基于模型等价的黑盒攻击:攻击者训练一个替代模型,该替代模型与目标模型具有相似的分类边界,然后在等价模型上利用白盒攻击方法生成对抗样本,该对抗样本在目标模型上具有类似的攻击效果。该方法首先由Papernot等[30]提出,使用基于雅可比矩阵的数据集增强来合成一个替代训练集。Zhang等[31]将这个想法扩展到基于EEG的BCI,不同点在于使用输入计算的损失来合成一个新的训练集。
基于概率优化的黑盒攻击:在输入样本上直接加随机扰动,利用不同的优化策略最大化非原始正确类的概率来获取对抗样本。典型的方法有Su等[32]提出的单像素点攻击(one-pixel);Ilyas等[33]提出的基于自然进化策略攻击的NES;Chen等[21]提出的基于进化计算的黑盒攻击POBA-GA。
1.2 对抗防御方法介绍
根据防御对象的不同,可以将防御方法分为3种:基于数据修改的防御、基于模型修改的防御和基于附加网络的防御[34]。根据防御方法是否依赖于预生成的对抗样本,可分为攻击相关的防御和攻击无关的防御。
攻击相关的防御中,最为有效的是对抗训练,对抗训练首先由Goodfellow等[35]提出,通过将攻击得到的对抗样本注入训练数据集,用来增强模型的鲁棒性;Kurakin[36]和Madry等[37]提出利用非迭代的快速梯度法产生的样本(如FGSM)进行对抗训练,只会增强针对非迭代攻击的防御鲁棒性,而无法增强针对迭代攻击,如投影梯度下降法(PGD,project gradient descent)的鲁棒性。Madry等[38]提出了针对多步迭代PGD(攻击进行对抗训练的方法),但与之前的对抗训练相比,K-PGD对抗训练大约需要多出K+1倍的计算量。为解决此问题,Shafahi等[39]提出了“免费”对抗训练。
攻击无关的防御,是指在不知道任何先验攻击的情况下执行防御操作。攻击相关防御对特定的攻击具有很好的防御效果,但对其他攻击,防御效果不佳;攻击无关防御通常对所有攻击(已有的和未知的)都具有相似的防御效果。简而言之,攻击相关防御具有局限性和滞后性的缺点,而攻击无关防御具有普适性和超前性的优点,所以攻击无关的防御更具有研究价值。典型的攻击无关防御包括:Xie等[40]提出的随机变换输入样本尺寸的防御;Guo等[41]通过对输入图像进行各种预处理操作提出了Transform防御;Strauss等[42]通过将各种深度网络集成提出了Ensemble防御;Liu等[43]通过在模型各层内注入随机噪声,实现了模型的自集成防御(RSE,random self-ensemble)。
2 深度模型和黑盒攻击的基本定义
2.1 黑盒模型的表示
正常情况下神经网络的前向传播过程可以表示为f:RM→ RN,其中M表示输入的维度,N表示输出的维度。将样本x∈X输入深度模型中进行分类预测,在经过最后一层全连接后得到一个向量Z(x,i),其中i∈{0,1,2,… ,C−1},C表示数据集的分类总数,向量Z(x,i)表示输入x被分类成第i类时的权重值,即得分情况,该向量被称为目标模型的逻辑输出(logits)。为了将每一类的logits值归一化,使用softmax函数对其进行激活,得到包含各类logits值归一化后的概率向量f(x),向量f(x)表示输入x被分类成各类时的概率大小,概率值最大的那一类即模型分类结果。logits向量Z(x,i)通过softmax激活函数转化为概率向量f(x)的计算方式如下。
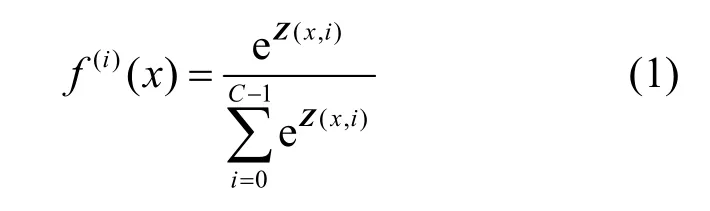
其中,e表示自然底数,x为目标模型的输入,f(i)(x)表示输入被分类为第i类的概率,则目标模型的输出类标表示为yˆ = argmax(f(x)),其中表示x的预测类标,argmax(⋅)返回数值元素值最大的位置的坐标。给定x的真实标签为y,当=y时,则预测正确,反之则预测错误。
2.2 黑盒攻击的表示
在黑盒对抗攻击中,攻击者通常能获取模型各类的输出概率f(x),然后利用不断改变的输入样本x,查询模型的输出,以达到攻击的目的。以图像分类任务为例,具体实现定义为
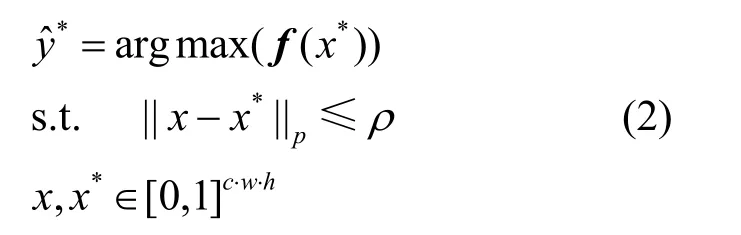
其中,x*表示对抗样本,表示对抗样本的预测类标,ρ表示可允许的对抗扰动尺寸,c表示输入图像的通道,w表示宽度,h表示高度,||⋅ ||p表示计算Lp范数。当=y且≠y时,则对抗样本攻击成功。
本文主要考虑基于分数的黑盒攻击。基于决策的黑盒攻击的查询次数远远高于基于分数的黑盒攻击,且攻击得到的对抗样本扰动一般较大,对基于分数的黑盒攻击实现防御更加具有现实意义。基于分数的黑盒攻击主要包括梯度估计、模型等价、概率优化3种,具体介绍如下。
1) 基于梯度估计的黑盒攻击。通过对细微修改的输入进行重复查询并记录返回值的细微差异,直接估计目标模型的梯度。梯度估计公式如下。
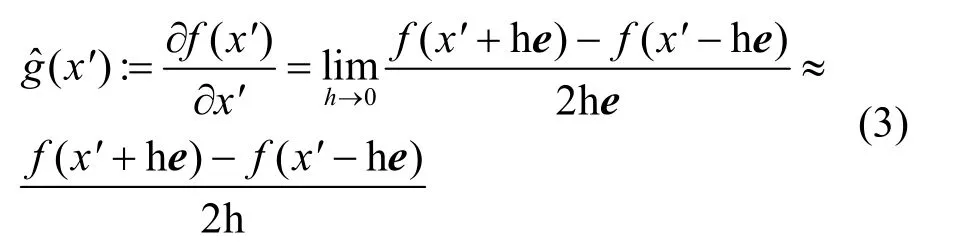
其中,h是一个很小的常数,e是标准基向量,x′表示在生成对抗样本的迭代过程中的中间量,表示估计梯度。最终的对抗样本为x*=x+ξ⋅gˆ(x),其中ξ表示扰动步长。
2) 基于模型等价的黑盒攻击。攻击者首先通过训练一个与目标模型分类边界相似的替代模型,表示为f′(⋅),进一步对替代模型进行白盒攻击得到对抗样本;然后利用得到的对抗样本攻击目标模型。替代模型和目标模型十分相似,因此能够攻击替代模型的对抗样本也能攻击目标模型。替代模型的梯度表示为
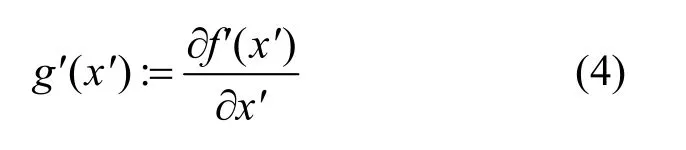
其中,x′表示在生成对抗样本的迭代过程中的中间量,g′(⋅)表示替代模型f′(⋅)的梯度。最终的对抗样本为x*=x+ξ⋅g′(x),其中ξ表示扰动步长。
3) 基于概率优化的黑盒攻击。攻击者利用目标模型的输出概率f(x)作为优化目标,通过判定查询前后优化概率的大小,确定下一步的搜索方向。在限制对抗扰动尺寸的情况下,最小化目标类的输出概率,优化目标如下。
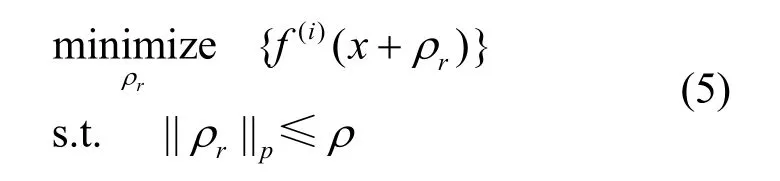
其中,maximize{⋅}表示通过优化ρr实现f(⋅)在真实类i上的概率最小化,ρr的Lp范数受限于ρ。
3 基于激活函数变换的动态防御方法
本节详细介绍基于softmax激活函数变换的对抗防御方法,包括基于概率信息隐私保护防御验证、基于softmax激活函数变换的对抗防御方法SAT、基于可变变换系数实现动态防御,进一步证明SAT在保持良性样本识别的有效性,并分析SAT的算法复杂度。
SAT防御方法的本质是在目标模型的推理阶段进行softmax激活函数变换,通过令任意样本的任意标签的分类概率分布接近,降低模型输出概率信息的泄露风险。以CIFAR10数据集的分类任务,基于ResNet50结构的目标模型为例,基于softmax激活变换的对抗防御方法SAT框架如图1所示。防御前,模型输出的不同类之间的概率差异十分明显,黑盒攻击方法能够通过梯度估计、模型等价、概率优化等操作实现对抗样本的生成,即图1中的“clean”样本经过模型输出概率的反馈生成“adversary”。防御后,原来的输出概率经过SAT激活,从而对不同类之间的概率信息进行脱敏,无法反馈给黑盒攻击方法生成对抗样本,即攻击失败,实现对抗防御。进一步,借助t-SNE降维方法对防御前后的概率分布进行可视化,直观地解释了SAT针对黑盒对抗攻击的防御有效性,是通过增加概率分布的混乱程度实现的。
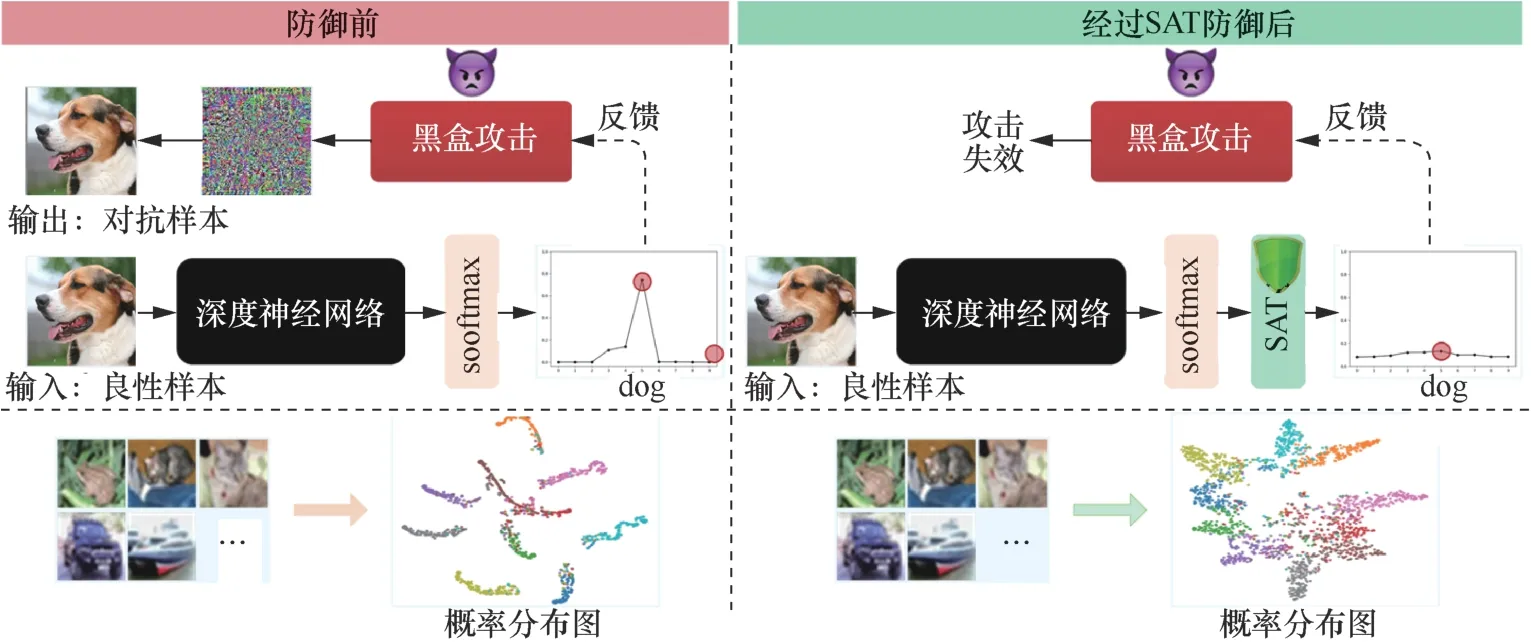
图1 基于softmax激活变换的对抗防御方法SAT框架 Figure 1 The framework of adversarial defense based on activation transformation
SAT不改变目标模型的训练操作,因此具有攻击无关、针对未知攻击进行事前防御的优点;SAT的激活是单调的,因此具有不影响正常样本识别的优点;SAT只需要修改推理阶段的激活函数,因此具有轻量、低成本、快速的防御优点。下面对SAT的具体操作进行详细介绍。
3.1 基于概率信息隐私保护的防御验证
3.1.1 目标模型概率信息保护的指数机制
给定一个数据样本x和一组可能的输出集合Y,概率信息保护的指数机制选择的结果满足以下概率性质。
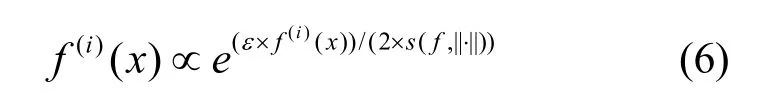
其中,Y={0,1,2,… ,C−1}表示给定输入数据样本x在该机制中的合法输出集合,即数据集的类标集合;i表示输入数据样本x的合法输出,即样本x的真实类标;f(i)(x)表示输入为数据样本x,输出为i时的得分函数,即目标模型的输出概率;e表示自然底数,ε表示隐私保护变换系数;s(⋅,⋅)表示得分函数f(⋅)的敏感度,定义为

其中,xi,xj表示两个不同的样本,计算敏感度时,对数据样本x和x′的距离条件进行松弛,{x,x′}∈X。注意,式(7)中仅用到i类,即样本x和x′被预测为i类的概率差值,x′的真实类标是k,且k≠i。对于给定的x,x′可以是任意样本,因此i和j是不相关的。
3.1.2 针对基于梯度估计的黑盒攻击的防御验证
在基于梯度的黑盒攻击中,对式(3)进行展开,得到
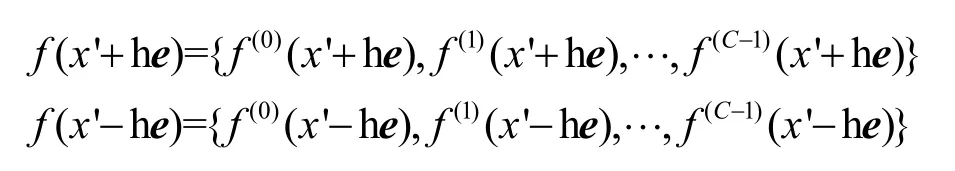
根据式(6),当ε→ 0时,有
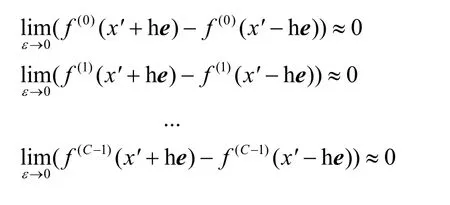
则式(3)估计梯度变为
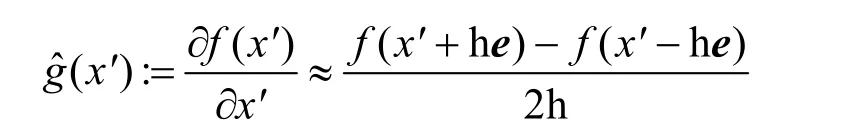
由此可得,SAT令f(x′+he)和f(x′−he)的差异变得足够小,此时攻击者无法对梯度gˆ(x')进行估计,导致无法实现对抗样本生成,能够使这一类攻击失效。
3.1.3 针对基于模型等价的黑盒攻击的防御验证
在基于模型等价的黑盒攻击中,其本质是利用对抗样本在相似模型间的攻击迁移性,因此替代模型和目标模型之间的分类边界拟合程度直接决定了对抗样本的黑盒攻击效果。在替代模型的生成过程中,使用目标模型的输出概率作为真实概率值,实现替代模型的输出概率分布逼近目标模型。基于交叉熵的优化目标定义为
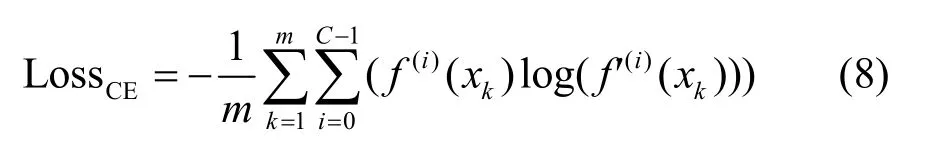
其中,m表示样本个数,xk表示数据集中第k个样本,log(⋅)表示对数函数,f(i)(⋅)和f'(i)(⋅)分别表示目标模型和替代模型预测xk属于第i类的输出概率。最小化 LossCE,能够实现替代模型的输出概率分布接近目标模型的输出概率分布。
当ε→ 0时,进一步松弛样本x和x′的距离,二者属于不同的两个类。为了保护输出概率的隐私安全,输出概率需要同时满足以下两个条件。

其中,i和k分别是样本x和x′的真实类标,i,k∈Y且i≠k,则有
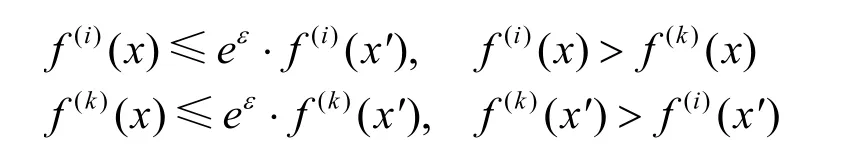
可得
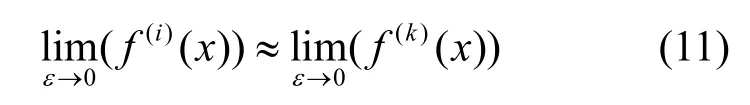
即同一个样本的不同类之间的输出概率十分接近。根据式(11)对式(8)进行变换,可得 即替代模型对目标模型的输出概率的学习是混乱的。对于属于第i类的样本,学习第i类的输出概率值与学习第j类的输出概率值是没有差异的。
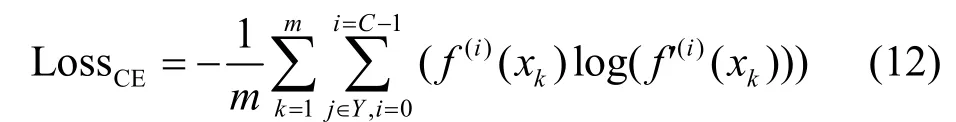
由此可得,SAT通过输出模型概率信息保护的指数机制保护目标模型的输出概率,使替代模型的等价过程出错,能够使这一类攻击失效。
3.1.4 针对基于概率优化的黑盒攻击的防御验证
假设扰动搜索函数为 Search(x, min(f(i)(x) )),表示向着最小化目标概率f(i)(x)的方向优化,返回搜索方向dire ← Search(⋅,⋅)。根据搜索方向更新输入样本xj+1=xj+ dire ⋅ξ,其中xj和xj+1表示迭代前后的样本,ξ表示迭代步长。
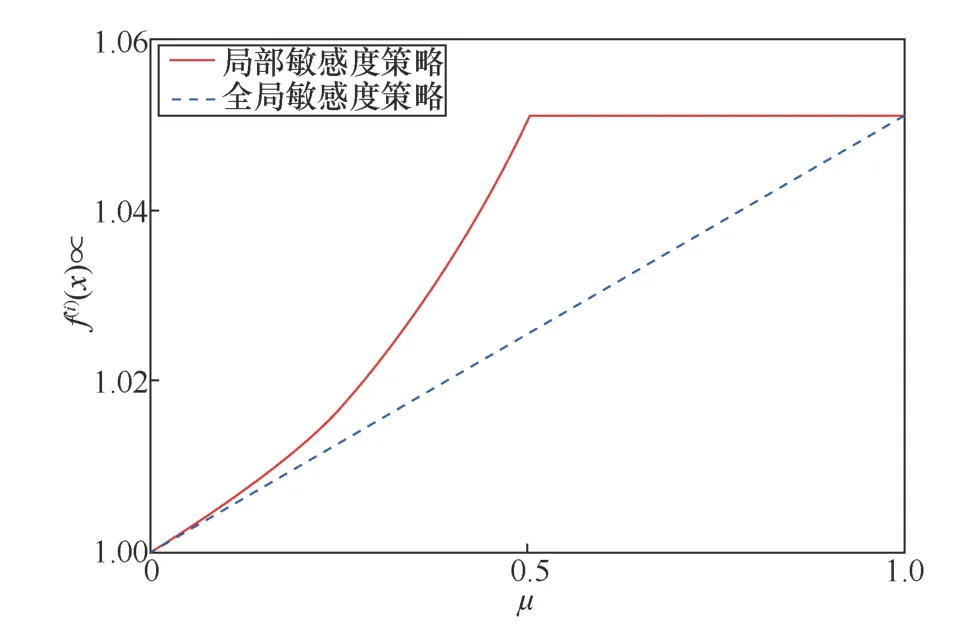
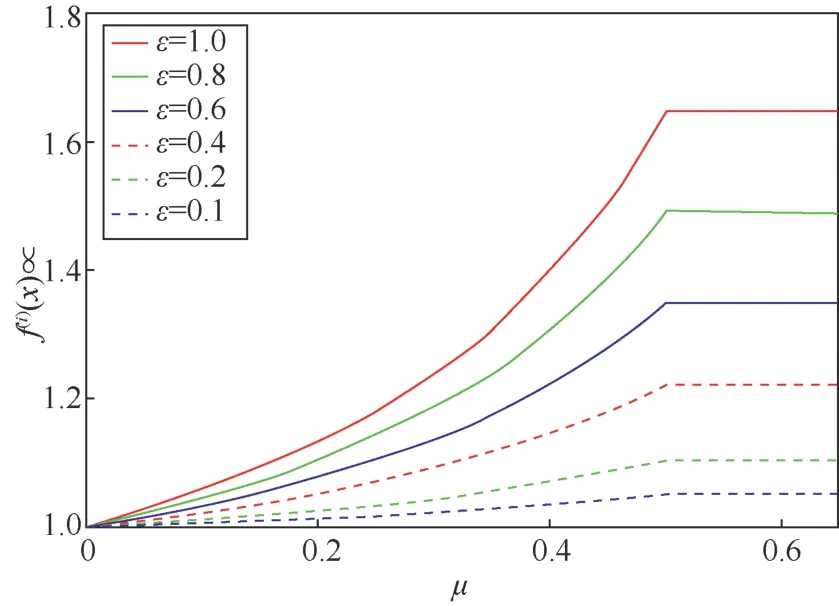
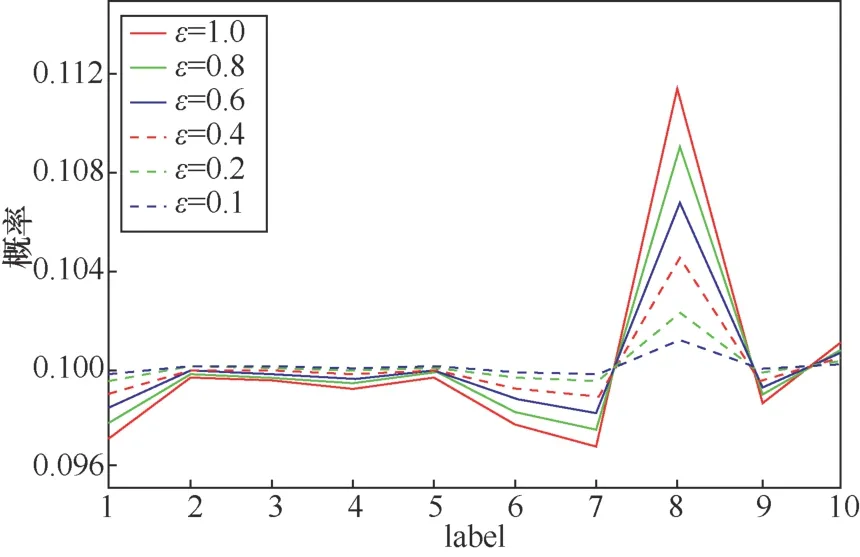
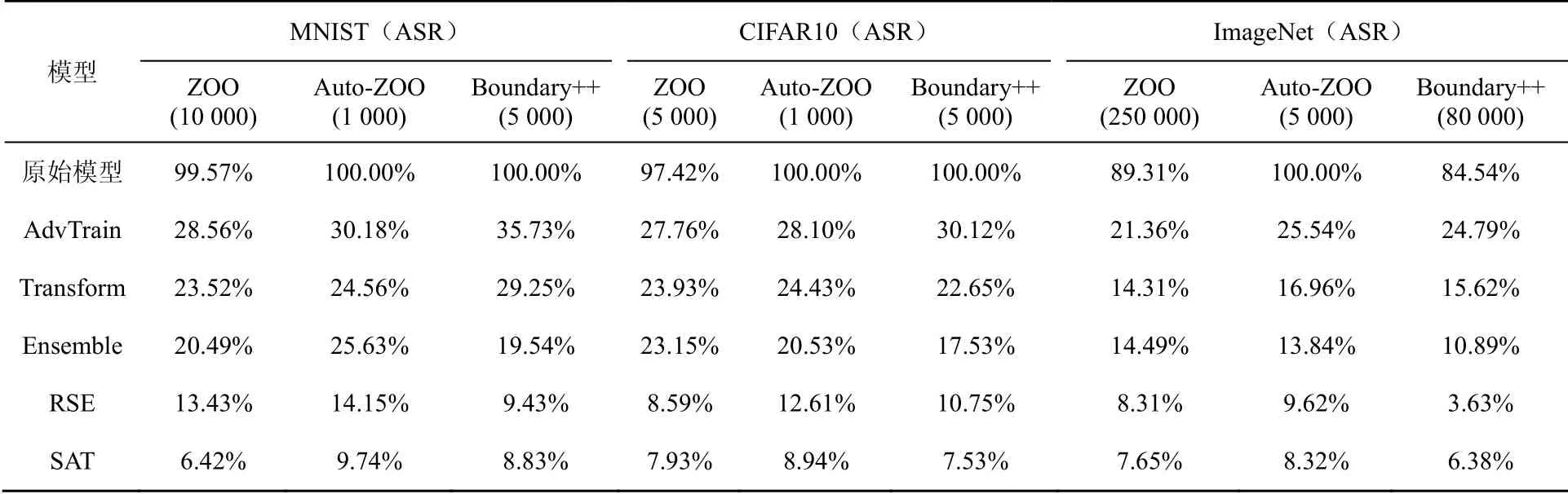
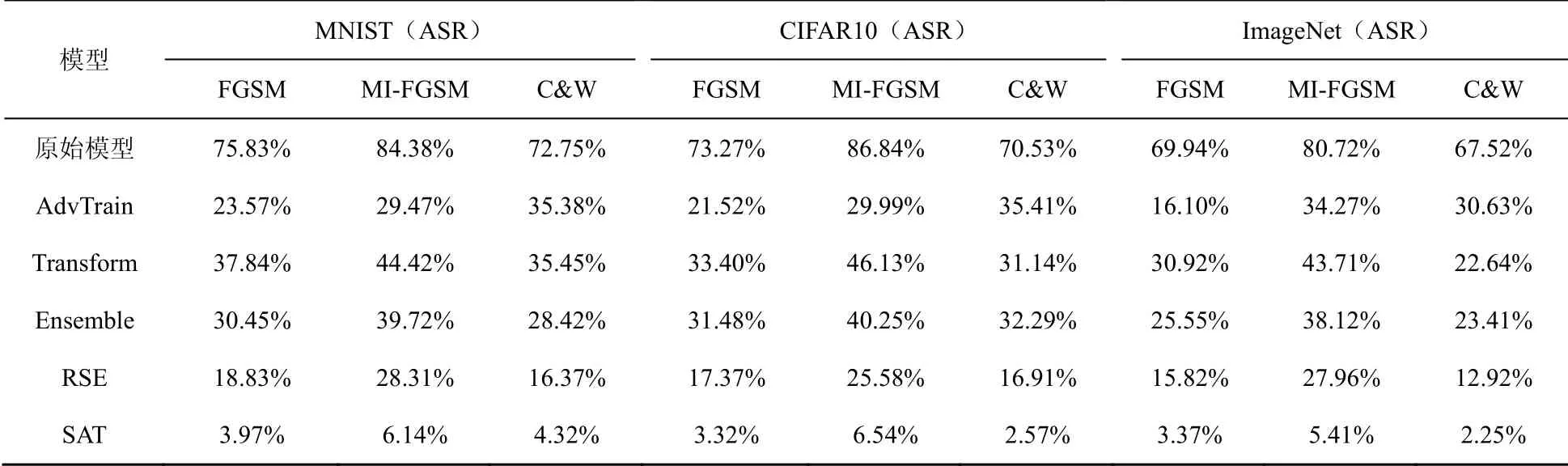
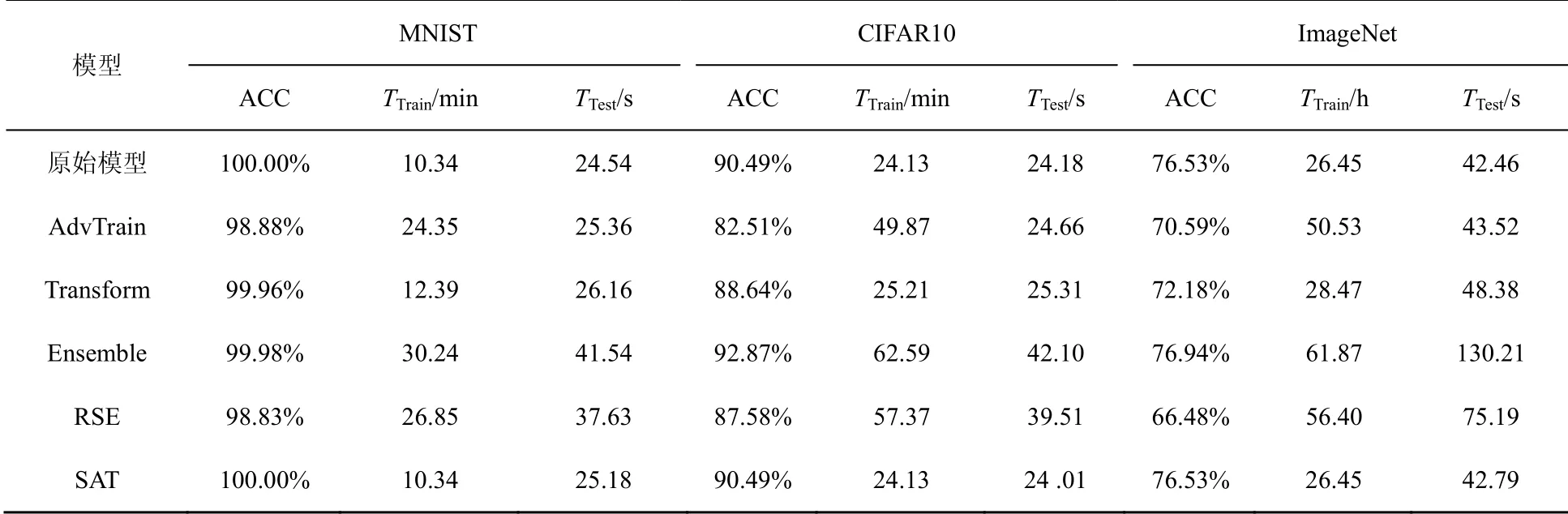
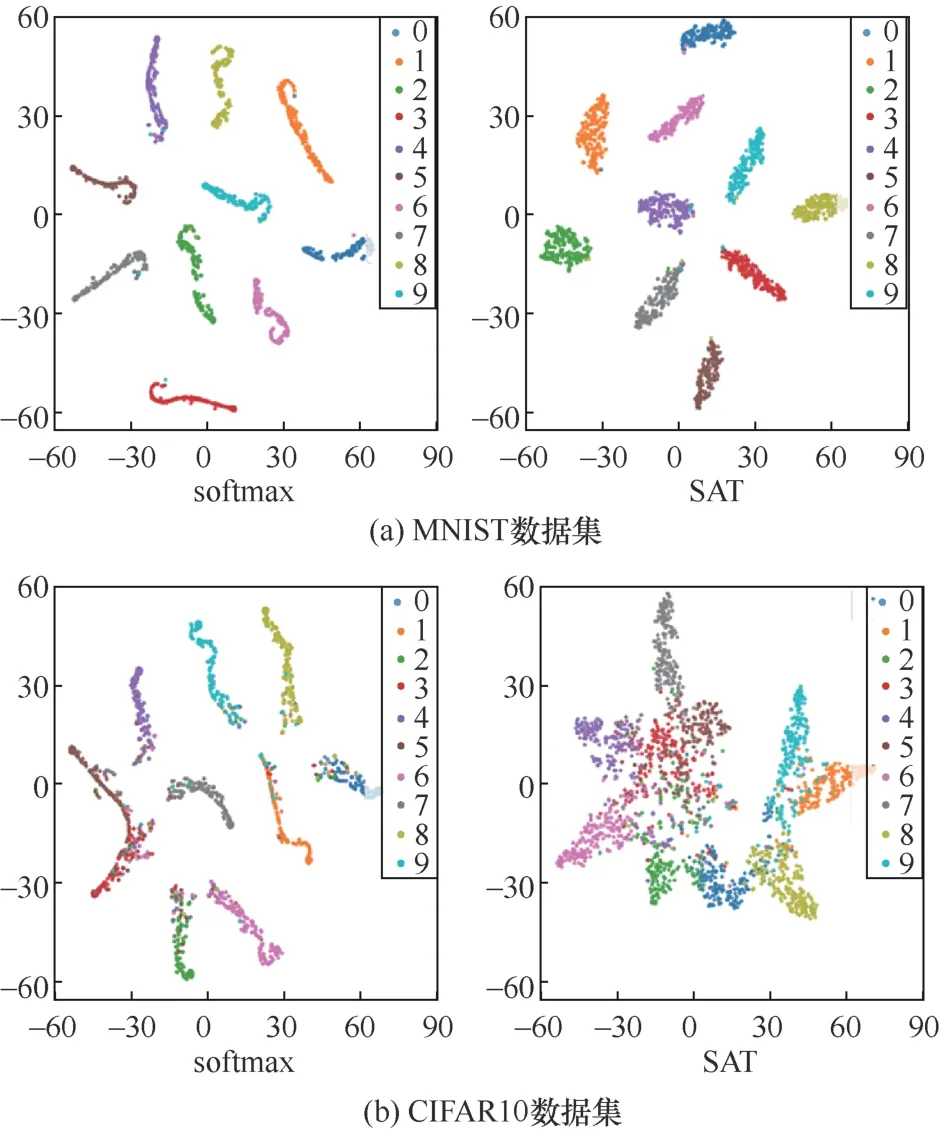
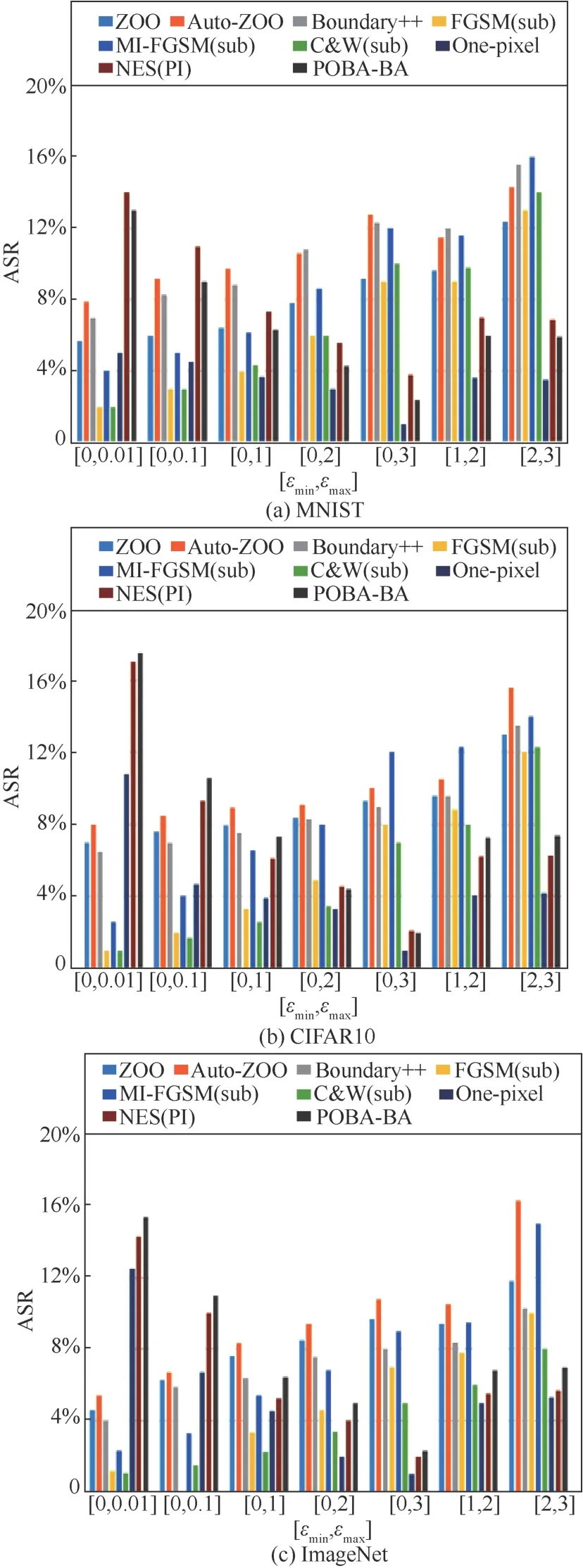
若满足f(i)(xj+1) 为避免Search(⋅,⋅)函数找到dire,SAT使用可变的隐私保护变换系数。根据3.1.1节可得,目标模型真实类的输出概率正比于e(ε⋅f(i)(x))/(2s(f,||⋅||))。若ε改变,则f(i)(x)改变;Search(⋅,⋅)无法知道是更改ε引起的f(i)(x)变小,还是正确的搜索方向dire引起的f(i)(x)变小。 对于任意的ε> 0,εj和εj+1分别表示第j次和第j+1次迭代使用的隐私保护变换系数。存在这样的情况 若Search(⋅,⋅)错误地将此时的dire作为搜索方向,将会使攻击向错误的方向优化。 由此可得,SAT通过可变隐私保护变换系数策略,实现f(⋅)输出的真实类的最高概率值动态变化,令黑盒攻击向错误的方向搜索扰动,从而使这一类攻击失效。 本文基于模型输出概率信息保护的指数机制,设计在目标模型推理阶段的softmax激活变换,实现模型输出概率的隐私保护,达到抵御黑盒攻击的目的,具体实施方案如下。首先,重新定义在对抗攻防中实现概率信息保护的指数机制。 3.2.1 基于概率信息保护的softmax激活变换 进一步设计softmax激活函数SAT,具体公式定义如下。 其中,fSAT(xi)激活函数的输入是softmax函数的输出,最后的预测类标为=argmax(fSAT(x))。 如图1所示,经过softmax函数激活后,推理样本能够被正确识别为“dog”类,且对应类的概率激活十分明显,容易被黑盒攻击利用。而使用SAT激活后,推理样本仍然能够被正确识别为“dog”,但对应类的概率激活趋势十分平坦,能够保护概率信息避免被黑盒攻击利用。 3.2.2 攻击无关性和防御快速性分析 攻击无关性分析:根据防御的具体步骤可知,SAT不参与目标模型的训练,不需要使用对抗样本的任何信息,能够实现攻击无关的事前防御,对用户十分友好。 防御快速性分析:SAT在推理阶段对softmax函数的输出进行重新激活,输入为f(x),涉及的变量包括隐私保护变换系数ε、敏感度s。在确定变量后,SAT的计算十分方便,能够实现轻量快速的防御。 3.2.3 基于局部敏感度的概率信息保护 SAT采用的是局部敏感度策略,令u=f(i)(x) ∈(1/C,1],u′=f(i)(x′)∈ [0,1],则将式(6)变换为如下形式。 其中,x′可以是X中的任意样本,因此存在max{u′}=1,min{u′} = 0。进一步,敏感度可以表示为 得到更新后的概率条件为 使用不同敏感度策略的概率条件分布如图2所示。可以看出,随着输入概率u的变化,全局敏感度策略下的概率条件分布一直上升,上升斜率可以认为基本不变;而局部敏感度策略下的条件概率先上升,且上升速度比全局敏感度策略下更快,达到拐点后保持不变。相比全局敏感度,局部敏感度前半段快速上升能够更好地进行正常样本的识别,后半段的保持不变能够更好地避免黑盒攻击利用多次查询的概率泄露问题。 图2 不同敏感度策略的概率条件分布 Figure 2 Probability condition distribution of different sensitivity strategies 隐私保护变换系数ε衡量隐私信息的泄露程度,ε越小则隐私保护效果越好,但是也会影响原始任务的正常工作。图3直观地显示了不同隐私保护变换系数下的概率分布,ε越小,概率分布越趋于平坦,信息泄露越少。 图3 不同隐私保护变换系数下的概率条件分布 Figure 3 Probability condition distribution under different privacy protection budgets 不同隐私保护变换系数下的输出概率趋势如图4所示。以CIFAR10数据集在ResNet50模型上的输出概率保护为例,图4展示了单张样本在不同ε下的概率信息泄露。当ε变小,输出概率逐渐趋于平缓,等价模型和梯度估计等黑盒攻击方式将会失效。为了保证模型的正常工作,需要令真实类标所在位置的概率值一直保持最大,这就导致基于概率优化的黑盒攻击方法在足够大量的查询次数后,实现有效攻击。 图4 不同隐私保护变换系数下的输出概率趋势 Figure 4 Trend of output probabilities under different privacy protection budgets 为了令基于概率优化的黑盒攻击方法失效,SAT引入了可变隐私保护变换系数策略,即使用变化的ε实现动态的防御。直观地,对于同一张输入样本,真实类的概率值在每次查询时是变化的,如式(13)所示,错误的搜索方向增加了真实类的输出概率,变化的ε降低了真实类的输出概率,且后者的改变程度大于前者,则攻击方法误认为是正确的搜索方向降低了真实类的输出概率,继续往错误的方向搜索,从而使基于概率优化的攻击失效。 SAT虽然降低了真实类的输出概率,但是始终保持真实类的概率高于其他类的概率,这是fSAT(⋅)的单调性决定的。由式(17)可知,当u≥ 0.5时,f(i)(x) ∝eε/2,此时的eε/2是一个常数,因此f(i)(x)的斜率为 0。当u< 0.5时,f(i)(x)∝。此时随着u增加,增加,单调递增。 因此,在输入自变量u∈ (1/C,1]的定义域内,可以认为是单调递增的,能够保持softmax激活中概率最大的值在SAT激活中也是最大,即不会改变原始的预测类标。因此以下结论成立:SAT在降低目标模型概率信息泄露的同时,能够保证原始任务正常工作。 防御方法的复杂度分析包括训练阶段的复杂度和推理阶段的复杂度分析。从图1可以看出,SAT只在推理阶段工作,训练阶段的时间复杂度和空间复杂度都是0。根据式(14)可知,SAT防御是在原始的推理过程中增加了一步计算,增加的存储空间是输入的softmax函数激活,与分类数有关。因此,在推理阶段,SAT增加的空间复杂度是O( 1),增加的时间复杂度也是O( 1)。 本节首先介绍实验的基本设置,包括软硬件环境、数据集、模型、攻击方法、防御方法和度量指标;之后,将本文提出的防御方法与其他方法在9种黑盒攻击方法上进行防御效果的对比,并比较了各个防御方法的防御代价;最后,对实验的防御有效性、参数敏感性进行了分析。 实验硬件及软件平台:i7-7700K 4.20GHz x8 (CPU), TITAN Xp 12GiBx2 (GPU), 16GB x4 memory (DDR4), Ubuntu16.04 (OS), Python(3.6), tensorflow-gpu (1.12.0), keras (2.2.4), torch (0.4.1)和torchvision (0.2.1)。 数据集:实验采用MNIST、CIFAR10和 ImageNet这3个公共数据集。其中,MNIST数据集包括60 000张训练样本和10 000张测试样本,样本大小是28×28的灰度图像,共10类;CIFAR10数据集由50 000张训练样本和10 000张测试样本组成,样本是大小为32×32×3的彩色图片,共10类;ImageNet数据集选取130万张训练样本和5万张测试样本共1 000类进行实验。 深度模型:3个数据集的默认模型均为ResNet50,等价模型均为VGG19,模型集成防御由ResNet50、AlexNet和VGG19组成。 攻击方法:梯度估计为ZOO、Auto-ZOO和Boundary++;等价模型为基于雅克比的模型等价方法,等价模型上的白盒攻击为FGSM、MI-FGSM和C&W;概率优化为One-pixel、NES(PI)、POBA-GA。 防御方法:本文采取4种防御方法作为对比算法,包括对抗训练(AdvTrain)、通道变换(Transform)、模型集成(Ensemble)和模型自集成(RSE)。 AdvTrain:在模型训练阶段,将FGSM和PGD的对抗样本和正常样本混合在一起作为模型的训练集,并重新训练得到防御模型。 Transform:在模型的训练和推理阶段,加入样本变换的预处理操作,操作包括图像压缩和方差最小化操作。 Ensemble:在模型训练和推理阶段,将模型ResNet50、AlexNet和VGG19的输出层进行集合,得到融合了3个模型的Ensemble模型。 RSE:在模型训练和推理阶段,均对模型的各层中加入随机噪声,扰乱模型的梯度信息。 评价指标:本文在验证防御有效性时,采取防御超前性的方法,即对模型先防御后攻击的形式,而非先攻击再利用防御模型重新识别对抗样本,前者更能表现防御模型在面对攻击时的防御效果。实验的评价指标是攻击成功率而非防御成功率。攻击成功率公式如下。 其中,nright表示攻击前模型分类正确的样本数,nadv表示模型分类正确的样本中攻击成功的对抗样本数。攻击成功率越低,表示防御效果越好。 本节实验主要分析SAT在基于梯度估计的黑盒攻击上同其他防御方法的防御效果对比。本文在MNIST、CIFAR10和ImageNet这3个数据集上利用基于梯度估计的3种黑盒攻击(ZOO、Auto-ZOO和Boundary++)直接对6个模型进行攻击,模型分别为不采取防御的原始模型、AdvTrain、Transform、Ensemble和RSE。从实验结果可知,在面对基于梯度估计的不同黑盒攻击方法时,SAT相比其他防御方法具有更强的鲁棒性。具体实验结果如表2所示。 由表2的第二行可得,每一种攻击方法下的括号中都对应一个数字,该数字代表每种攻击方法在攻击不同策略的防御模型时所允许的最大模型访问次数,如第2列中的“ZOO”对应的“(10 000)”,是指利用ZOO攻击每一种防御模型时,最多允许访问防御模型10 000次,超出则视为攻击失败。由于不同攻击方法的攻击性能不一致,实验为了保证每种攻击方法在原始模型上都具有较高的攻击成功率,设定每一个数据集下的每一种攻击方法都对应不同的模型访问次数,该访问次数由对应论文中涉及的访问次数和本次实验中在不防御情况下攻击成功率达到一定指标后的访问次数共同决定。基于梯度估计的黑盒攻击的成功率与允许的模型访问次数有很大关联,通常攻击成功率与被允许的访问次数成正比,所以在实验中,相同攻击方法攻击不同防御模型时设定一样的访问次数,以此更加客观真实地反映不同防御方法的防御效果。 由表2可知,仅仅利用模型输出的概率,3个数据集下的3种攻击方法在攻击原始模型时,攻击成功率都能达到80%以上,甚至在两个小数据集上几乎能达到100%。由此可知,不采取防御措施的原始模型在面对基于梯度估计的黑盒攻击时是脆弱的,防御措施必不可少。在攻击防御模型时,攻击成功率大幅度下降,但是对抗训练的防御效果明显弱于其他攻击方法,这是因为对抗训练是攻击相关性防御,只对特定的攻击有很好的防御作用,其他攻击防御效果不佳。此外,RSE的防御效果优于一般的Ensemble防御,这是因为在RSE中不管是训练阶段还是推理阶段都加了随机扰动,具有随机性的防御模型往往比一般的固定性防御更难被攻击,因为攻击过程中往往会被随机性引到错误的方向,但具有随机性的模型通常会以降低准确率为代价。由表2最后一行可得知,在大多数情况下,SAT的防御效果相比其他防御方法是最优的。 表2 基于梯度估计的黑盒攻击防御效果对比Table 2 Comparison of black box attack defense effects based on gradient estimation 本节实验主要分析SAT在基于模型等价的黑盒攻击上同其他防御方法的防御效果对比。本文通过基于雅克比的模型等价方法用VGG19模型分别拟合6组模型的分类边界,得到对应的6个等价模型,再利用3种白盒攻击方法(FGSM、MI-FGSM和C&W)攻击这6个等价模型获取不同的对抗样本,其中FGSM是通过计算单步梯度快速生成对抗样本的方法,在白盒环境下,通过求出模型对输入的导数,然后用符号函数得到其具体的梯度方向,接着乘以一个步长,得到的“扰动”加在原来的输入上就得到了在FGSM攻击下的样本;MI-FGSM是一种基于动量迭代梯度的对抗攻击方法,用梯度迭代扰动输入,使损失函数最大化,提高生成的对抗性样本的成功率;C&W攻击是一种基于迭代优化的低扰动对抗样本生成方法,通过限制l∞、l2和l0范数使扰动无法被察觉。最后,利用这些对抗样本对6个被等价的目标模型进行攻击。从实验结果可知,相比其他4个防御模型,SAT明显具有更好的防御效果。具体实验结果如表3所示。 由表3可知,在不防御的原始模型中,基于模型等价的黑盒攻击的攻击效果比梯度估计的攻击效果差,这是因为模型等价攻击依赖于对抗样本的迁移性,即使等价模型和原模型的分类边界几乎一致,但其结构以及参数上的差异性仍然会影响对抗样本的迁移效果。通过比较不同攻击方法的攻击成功率,可以观察到,MI-FGSM的对抗样本的迁移性明显优于其他两种方法,这是因为MI-FGSM利用动量迭代的方式生成对抗样本,大大提升了对抗样本的迁移性。此外,AdvTrain对FGSM的防御效果明显优于其他两种攻击方法,这是因为对抗训练的训练集中包含了FGSM在ResNet50上的对抗样本。最后,由表3最后一行可知,SAT在等价模型上的防御效果远优于其他防御模型,因为SAT虚假输出了原始模型的分类边界,等价模型拟合的是扰乱后的边界,并非模型真正的分类边界,所以由该等价模型生成的对抗样本的迁移性很弱。 表3 基于模型等价的黑盒攻击防御效果对比Table 3 Comparison of black box attack defense effects based on model equivalence 本节实验主要分析SAT在基于概率优化的黑盒攻击上同其他防御方法的防御效果对比。本节实验的操作形式类似于4.2节,只是3种攻击方法不同,本节实验在MNIST、CIFAR10和ImageNet这3个数据集上利用基于概率优化的3种黑盒攻击方法(One-pixel、NES(PI)和POBA-GA)直接对6个模型进行攻击。同样,表4中的每一种攻击方法下都对应有被允许的最大模型访问次数。从实验结果可知,在面对基于概率优化的不同黑盒攻击方法时,SAT相比其他防御方法具有更强的鲁棒性。具体实验结果如表4所示。 由表4可知,除One-pixel攻击方法外,其他两种防御方法在原始模型上的攻击成功率近似于4.2节中的ZOO、Auto-ZOO和Boundary++攻击。但One-pixel的成功率远远低于其他两种方法,这是因为One-pixel攻击方法通过只改变若干个像素点(本节实验中小于5个)来生成对抗样本,对于224×224的ImageNet图像,扰动值过小。过小的扰动很容易通过预处理操作被除去,所以Transform在One-pixel上的防御效果远优于其他两种攻击方法。由于RSE在防御过程中均引入随机性扰动,因此在基于概率优化的黑盒攻击防御性能明显优于除SAT外其余防御算法,但引入的随机扰动会对原始模型的分类准确率造成较大的负面影响。表2中RES在MNIST和ImageNet数据集中对One-pixel攻击的防御效果相比SAT更佳,进一步验证了RES防御带入的随机不确定性造成的不稳定性,而SAT则不会有此问题。最后由表2~表4可知,SAT在这3类黑盒攻击上的防御效果稳定优于其他防御方法,为本文方法的理论论证提供了实验支撑。 表4 基于概率优化的黑盒攻击防御效果对比Table 4 Comparison of black box attack defense effects based on probability optimization 本节实验主要分析SAT与其他防御方法的防御代价对比,主要比较防御后模型的原始识别准确率(ACC)、模型训练时间(Ttrain)和模型推理时间(Ttest)。攻击方法使用基于梯度估计的黑盒攻击ZOO,具体结果如表5所示。防御代价包括模型精度损失代价和防御时间代价。模型精度损失通过比较防御前后的原始模型识别准确率,以表5中的ImageNet数据集为例,SAT方法的ACC没有下降,而AdvTrain等方法的ACC下降平均超过6.5%,ACC下降越多,说明代价越大。防御时间代价通过比较防御前后的训练时间和推理时间,以表5中的ImageNet数据集为例,SAT防御后的训练时间和推理时间增长分别为0和0.7%,而AdvTrain等方法的训练时间和推理时间平均增长了86%和55%,训练和推理时间越长,说明防御代价越大。 表5 SAT与其他防御方法的防御代价对比Table 5 Comparison of defense costs between SAT and other defense methods 由表5可知,SAT与原始模型的准确率和训练时间都相同,推理时间也相近,这是因为SAT不需要对模型进行额外的训练,也不会改变概率最高的类标从而影响原模型的准确率,换言之,SAT因为防御效果而额外产生的防御代价为0。防御效果仅次于SAT的RSE,其训练时间远高于SAT,且在ImageNet大数据集上的准确率下降明显。除以上两者之外,其他3种防御方法在防御效果上不如SAT,而且防御代价明显高于SAT。由上所述,SAT是一种快速有效的轻量级防御方法。 本节以MNIST和CIFAR10数据集为例,基于t-SNE图对SAT防御前后的样本分布概率进行可视化,并计算输出概率的类间距离。理论上,经过SAT进行重新激活后,样本的输出概率分布变得十分接近,直观的体现是在分布图上的样本变得更加混乱。但是SAT的单调性保证了正常样本的正确识别。进一步,本节使用类间距离对SAT防御前后的输出概率的类间距离进行计算,理论上类间距离会因为SAT的操作而变得接近,令黑盒攻击误以为能够以较小的代价很容易地实施攻击,但生成的对抗样本在目标模型中是无效的。 本节分别从MNIST和CIFAR10数据集中选取了2 000张正常样本,输入对应的目标模型,分别保存softmax激活后输出的概率向量和SAT激活后输出的概率向量;然后使用t-SNE降维方法对概率向量进行降维并绘制二维可视图,如图5所示。可以直观地看出,经过SAT激活后,样本点的分布变得混乱了。同时,MNIST数据集的ResNet50模型上,类间距离由1.253降低为0.016;CIFAR10数据集的ResNet50模型上,类间距离由0.976降低为0.010。通过增加输出概率分布的混乱程度,减少了模型概率信息的泄露,实现了有效的对抗防御。 图5 不同数据集的目标模型在SAT防御前后的t-SNE分布 Figure 5 t-SNE distribution of target models of different datasets before and after SAT defense 本节主要分析动态隐私预算的变化区间对防御效果的影响。具体实验结果如图6所示,其中,横坐标表示可选的动态变化区间,纵坐标表示攻击成功率,每一个区间都展示了4.2节至4.4节中9种攻击方法的攻击。 由图6可知,基于概率优化的3种黑盒攻击方法的攻击成功率与区间的范围大小有关,与区间中值的大小关系不明显,区间的范围越大,攻击成功率越低,表示防御效果越好。基于梯度估计和模型等价的6种攻击方法的攻击成功率与区间中值的大小有关,与区间的范围大小关系不明显,当区间中值越小时,攻击成功率越低,表示防御效果越好。但总体上,SAT的防御效果对区间的变化并没有非常敏感,为了同时兼顾3类黑盒攻击方法的防御效果,前文实验中ε选取的区间为[0,1]。 图6 动态隐私预算的变化区间敏感性分析 Figure 6 Sensitivity analysis chart of the change interval of dynamic privacy budget 本文提出了一种基于softmax激活变换的攻击无关的可验证防御方法,该方法能够对黑盒攻击实现快速、轻量的防御。所提方法是一种可验证的防御方法,能够基于概率信息隐保护和softmax激活变换推导其防御的有效性和可靠性。SAT不参与目标模型的训练,仅在推理阶段通过对目标模型的输出概率进行重新激活,实现概率信息的隐私保护从而防御黑盒攻击。SAT与对抗攻击无关,避免了制作大量对抗样本的负担,实现了攻击的事前防御。SAT的激活过程具有单调性,因此不会影响正常样本的识别。本文为SAT设计了可变隐私保护变换系数策略,实现了动态防御。实验结果表明,本文提出的对抗防御方法在降低攻击成功率、防御成本、参数敏感性方面优于许多已有的对抗防御方法,因此,本文方法是可行且高效的。 在实验过程中,发现SAT存在一定的问题,即在面对基于类标的黑盒攻击时,SAT无法实现很好地防御,这是SAT不改变模型内部结构也不影响输出类的最大类标造成的。在未来的研究中,将进一步探索针对基于类标的黑盒攻击的高效防御方法。
3.2 基于概率信息保护的softmax激活变换
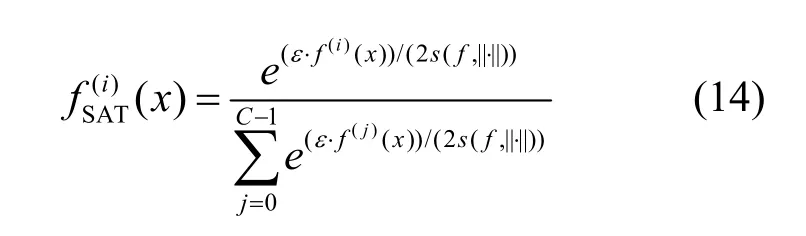
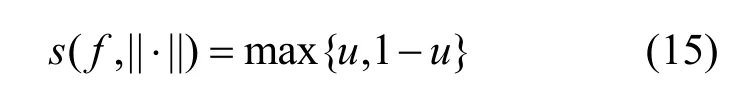
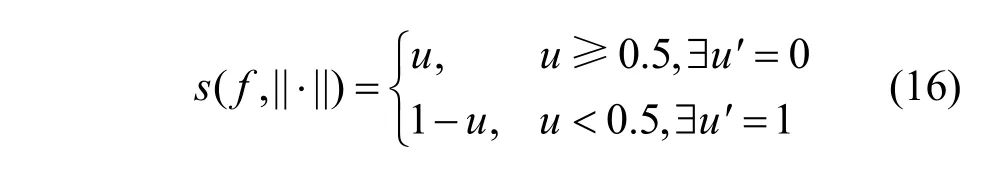
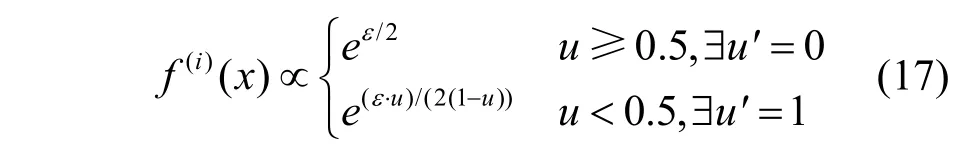
3.3 可变隐私保护变换系数的动态防御
3.4 SAT保持正常样本识别的单调性证明
3.5 SAT的防御复杂度分析
4 实验与结果
4.1 实验设置
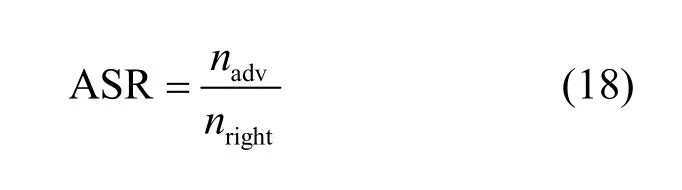
4.2 基于梯度估计的黑盒攻击防御效果对比
4.3 基于模型等价的黑盒攻击防御效果对比
4.4 基于概率优化的黑盒攻击防御效果对比

4.5 SAT与其他防御方法的防御代价对比
4.6 SAT抵御黑盒攻击的有效性分析
4.7 敏感性分析
5 结束语
