SDRNet:基于空间信息恢复的医学图像分割网络
2022-04-15王晓茹田塍徐培容张珩
王晓茹,田塍,徐培容,张珩
北京邮电大学 计算机学院,北京 100876
如何实现医学图像的自动化分析和处理一直以来都是计算机科学领域中的热点研究课题,由于医疗图像本身的复杂性以及对结果极高精确度的要求,该领域的自动化算法往往不能满足临床需要。一方面,医学图像数据通常含有较高比例的不规则小目标,小尺度物体识别精确度往往来说会相对偏低,但往往目标重要性无关乎尺度大小,小尺度物体也是医学图像分析过程中不可忽略的重要部分;另一方面,医生在分析医学图像时,对病变的器官组织边界往往关注更多,如果算法能对目标边界进行准确的定位,这对于医师的辅助作用是显著的。为了减轻医生的工作量,提高工作效率,临床上也迫切需求一种能精确地自动勾画出医疗图像中感兴趣区域的算法,这就是医学图像分割任务。
本文主要研究如何将浅层特征中丰富的空间信息更有效地融合进解码过程中,进而恢复深度神经网络下采样过程中损失的空间细节,从而让深度神经网络能够自动学习到更鲁棒的特征表示,对各种尺度的目标定位更准,整体的分割性能更强。为此,本文提出了一种空间细节恢复网络(SDRNet),设计了一种新颖的空间细节注意分支(SDAB)和特征强化模块(FEM)。经实验验证,通过将2 个新颖的模块结合在一起,SDRNet被证明可以进一步提高LUNA 数据集的整体分割精度。
1 相关工作
深度神经网络近几年大大推动了图像分割领域的发展,其使用卷积以及若干非线性变换来对数据进行高维抽象,但是由于深度神经网络往往存在下采样结构,下采样结构的引入是为了减少计算量,但也同时损失了大量空间信息,尤其是目标边缘和小尺度物体。针对空间信息损失的问题,多层特征融合是目前恢复空间信息的主要方法,多层特征融合是指将卷积网络计算过程中不同尺度的特征通过加和,或者连接的形式融合起来,其中高层特征分辨率低,有强的语义信息,但对细节的感知能力较差;而浅层特征的分辨率更高,包含了更多位置、细节信息。
因此如何有效且高效地融合浅层特征是解决空间信息损失的重要途径。FCN[1]最早将深度神经网络引入图像分割任务,在FCN 架构中,网络中不同分辨率的各层特征经过上采样到同一尺寸后,连接在一起作为最终的特征,这种融合方式没有考虑到多尺度特征,而且浅层特征的选择也缺乏考虑,是多层特征融合的初步尝试。UNet[2]在FCN 的基础上,考虑骨架网络中不同尺度的层次化特征,提出了U 型结构[3-5],这种结构通过在解码器中逐级增加特征的空间分辨率的同时,简单利用连接或者加和的方式融合浅层特征,来填充缺失的空间细节,这种融合方式存在明显的缺陷:浅层特征没有经过编码器的有效编码,其包含的信息是不够有效的,贸然融合会导致精度提升有限甚至降低最终预测精度,UNet 没有给出如何有效融合的方法。基于这个问题,Deeplab[6-7],GCN[8]通过引入空洞卷积以及大卷积核,致力于编码更丰富的空间信息用于恢复。BiseNet[9-10]提出了解决空间信息损失问题的双分支模型,其提出的空间分支中低下采样以及大卷积核编码了丰富的空间信息,通过特征融合模块融合特征,在引入很低的计算量的同时改善了空间信息丢失的问题,ET-Net[11]构造了一个边界信息强化分支用于强化边界分割效果,优化空间定位的精度。
2 空间细节恢复网络结构
全卷积网络浅层特征的分辨率更高,包含了更多位置和细节信息,但这部分信息没有被有效利用起来,因此本文设计了2 个新结构来更有效地恢复丢失的空间信息。利用SDAB 在浅层高分辨率特征上抽取捕获空间细节,利用注意力机制,让解码器更关注分支引入的空间信息,减少不够有效的语义信息的引入。同时提出FEM,结合注意力机制选择性强化特征表达能力,结合辅助损失提升模型对语义信息的表达能力。相对于以前的模型直接融合未经处理的浅层特征的做法来说,进一步降低空间信息融合过程中可能对深层语义信息造成的干扰,整体结构示意图见图1,其中左侧蓝色部分为编码器,右侧其余部分为解码器。

图1 模型整体结构示意
2.1 编码器结构
编码器选择以ResNet50 原型为基础,然后在其基础上进行了调整,在通道数与降采样倍率两者综合取舍后,得到以下编码器设计思路,以更适合医学图像分割的应用场景。相对于ResNet50原型,考虑到医学数据集多为二分类、语义信息相对较少的特点,故将原型中全部通道数减半,防止模型过度复杂,降低过拟合的风险。并且改进后的ResNet50 除去了Encode Block 1 中初始降采样过程,这使得模型的降采样倍率从16 倍缩减到了8 倍,减少编码过程中高降采样倍率导致的空间信息丢失。降采样步骤采用了步长(stride)为2 的卷积核。
2.2 空间细节注意力分支
基于以上讨论,上采样后的到的特征分布,其含有强的语义信息用于分类,同时由于空间信息的缺失导致其是模糊的,直接将编码器中具有强空间信息的浅层特征用传统的融合方式融合,一方面解码器无法有效地理解未经编码的空间信息,另一方面会干扰语义信息的表达。为了解决这些问题,本文设计了SDAB 来解决以上2 个困境。
首先,SDAB 利用大卷积核的卷积操作抽取浅层次特征。由于浅层特征通过堆叠的卷积较少,感受野小,所以选择大尺寸的卷积核尽可能高倍数的扩大感受野。大尺寸卷积核有利于模型对空间信息进行更有效的编码,但由于大尺寸卷积核也必然会引入大量计算量,考虑到浅层特征中丰富的空间信息以及更多的通道数往往仅利于编码更多语义信息这2 个特点,因此在SDAB 中先利用1×1 卷积对特征分布进行通道数压缩,减少计算量,然后再利用大卷积核进行编码,最后还原通道数,得到特征分布F,用于后续操作。
本文设计了一种引导空间信息恢复的结构,利用这种结构来将上文提及的编码后的空间信息融合入上采样后的深层特征分布中。本文选择利用注意力的机制来引导:首先将特征分布F与对应层上采样后的深层特征,利用1×1 卷积与加和的方式简单融合得到Fa,输入空间信号模块提取空间注意向量,在这个模块中,特征将按像素位置分别执行最大池化,与平均池化操作,压扁成一张空间尺寸不变、通道数为1 的特征激活分布。然后用连接的方式搭配中等尺寸的卷积核融合这2 个分布,利用sigmoid 操作得到空间激活量,并与Fa相乘来激活感兴趣的位置,从而获得空间激活后的特征分布。最后将该特征分布与Fa融合,每一个位置的通道最大值与平均值表达对应空间位置的重要程度,提取的目的是获取对应的激活量,更感兴趣的位置其空间激活量往往更高,结构示意见图2,连接表示按通道连接特征,加和表示特征矩阵加法,点乘表示特征矩阵点乘。

图2 空间细节注意力分支结构示意
2.3 特征强化模块
同样的,基于2.2 节对关键问题的讨论,通道往往对应特定的语义响应,因此在通道上可以做相似的处理,减少无效语义信息的引入,强化更有价值的通道,增强模型对语义信息的编码表达能力,从整体上进一步提升分割性能。因此本文提出了FEM 来实现这个目标。
FEM 由通道强化部分和辅助损失共同构成,利用注意力机制,为每个通道分配不同的自适应权重值,选择性激活或抑制通道,结构见图1。
在解码器上采样过程中得到的特征分布被通道强化模块优化后,在训练过程中提前输出用作分类;然后结合辅助损失函数,增强通道强化模块对通道的选择能力;最终增强模型对不同尺度目标的学习能力,能协同提升整个模型的分割性能。
通道强化部分本模块选用全局平均池化来抽取全局上下文,得到注意力权重值向量,这个向量表达每个通道的基础权重值;然后将这个基础权重向量输入1×1 卷积与ReLU 激活函数进行进一步优化,最后利softmax 操作获得最终权重值向量。
辅助损失部分中辅助损失laux1、laux2与主要损失函数lmain均为交叉熵损失函数,计算公式见式(1),总的损失函数L计算见式(2)。

式中:p(x)为 真实的概率分布,q(x)为预测的概率分布,交叉熵损失函数Ecross表达2 个概率分布之间的差异值。训练过程中通过最小化差异值使得预测精度不断提高。

式中:辅助损失laux1、laux2用于协调模型对不同尺度目标的分割能力,通常选取较小比值0.1,即 α和β分别设为0.1 和0.1;而主要损失lmain反映模型最终分割结果与真实值之间的差异,占主导地位,为了平衡两者,主要损失lmain的 权重 λ取为余下的0.8。即 α, β 与 λ分别设为0.1,0.1 和0.8,他们分别权衡辅助损失laux1、laux2与 主损失lmain的权重。
3 实验与结果
3.1 数据集
本文在肺结节分析比赛(LUNA)数据集上评估本文所提出的模型的性能,该数据集包含肺部CT 图像以及对应专业人员手动分割结果,该比赛任务是在肺部CT 图像中对肺部进行查找和测量,对胸部X 射线图像进行分割。整个数据集包含267 张图像,其中训练图像214 张,测试图像53 张。
3.2 训练设置
模型中所有待训练权重均被随机初始化。在训练步骤中,由于GPU 资源的限制,将batch_size设置为1,并使用“poly”学习率调度策略,该策略通过式(3)计算学习率。

式中:lrbase设 置为1 ×10-4,p设定为0.9,itotal设置为1×105。
模型由Adam 优化器进行训练,其动量和权重衰减分别设置为0.9 和0.000 5。利用Tensorflow1.14来构建本文提出的模型,并选择平均交并比(mean IOU,mIoU)RmIoU作为的评估指标,计算公式为

3.3 消融实验
本文提出SDAB 来优化空间信息的抽取与表达,同时降低对语义信息的干扰,提出FEM 来增强模型对语义信息的编码表达能力,优化训练过程。为了验证这2 个模块的性能,本文在LUNA数据集上设计了以下消融实验来进行证明。
定义未嵌入SDAB 和FEM 的SDRNet 为基础(Base)网络,实验结果见表1。SDRNet 在LUNA数据集上的mIOU 值为96.44%,而基础网络的mIOU值为95.83%,在基础网络仅嵌入SDAB 后mIOU值为96.27%,仅嵌入FEM 的mIOU 值为96.09%,可以看出本文提出的2 个模块能进一步提升分割性能。

表1 模块分割性能对比 %
图3 给出了更直观的图片对比,对消融实验中的4 个模型输出的分割结果可视化后,可以看出SDRNet 对边缘细节和小区块的处理很好,这表明本文提出的模块能有效恢复空间信息,优化模型对边缘和小区块的分割性能。

图3 消融实验分割结果可视化示例
3.4 验证FEM 模块的性能
本文设计FEM 来优化训练过程,同时增强模型对语义信息的编码表达能力。FEM 的加入有利于模型收敛到更优的性能,为了验证它对于训练过程的作用,设计如下对比实验:记录加入FEM模块前后模型的训练过程,如图4 所示,其中没有嵌入FEM 的最高mIOU 值为95.83%,嵌入后为96.09%。可以看到基础网络嵌入FEM 后,训练过程更稳定,同时也能收敛到更优的性能。

图4 FEM 验证实验结果
3.5 与其他模型的对比
为了进一步验证本文提出的SDRNet 的性能,SDRNet 分别与FCN[1]、U-Net[2]、M-Net[12]、ETNet[11]进行了对比,实验结果见表2。可以看到,本文提出的SDRNet 实现了最优的mIOU 值96.44%,超越了其他的模型。
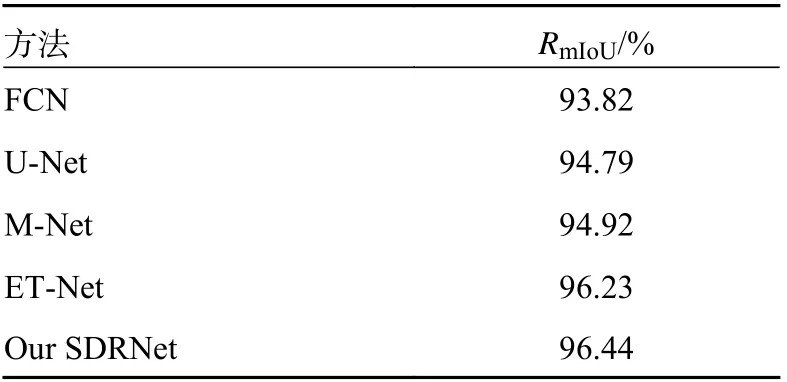
表2 SDRNet 与其他经典的模型性能对比实验结果
4 结论
本文提出了一种空间细节恢复网络SDRNet来解决肺部医学图像分割问题,本文的主要贡献如下。
1)提出了一种能有效提取、融合空间信息,进一步恢复空间细节的模型SDRNet。
2)提出了2 个特定的模块:SDAB 与FEM,2 个模块的加入协同提升了模型的分割性能。
3)LUNA 数据集上的对比实验验证了本文提出的模型的性能,结果表明本文提出的SDRNet性能超越了对比的经典算法。
